Chapter 10.1 — The Complete Map (পুরো মানচিত্র)¶
অভিনন্দন! 🎉 তুমি Part 0-এর "ম্যাথ ভয় ভাঙা" থেকে শুরু করে Part IX-এর PhD-level theory পর্যন্ত পুরো পথ হেঁটে এসেছ। এই শেষ chapter-টা কোনো নতুন টপিক শেখাবে না — বরং পুরো যাত্রাটাকে এক ছবিতে ধরবে, প্রতিটি Part-এর মূল কথা মনে করিয়ে দেবে, আর বলবে এরপর কোথায় যেতে পারো।
🎯 এই chapter-এ যা শিখবে¶
- পুরো curriculum-এর concept map — কোন ধারণা কোন ধারণার ওপর দাঁড়িয়ে আছে
- প্রতিটি Part-এর ২–৩ বাক্যের সারাংশ ও একটাই মূল takeaway
- "এরপর কি পড়বে" — Axler, Horn & Johnson, Trefethen–Bau, Strang LFD, MIT 18.065: কোনটা কখন কেন
- নিজেকে যাচাই করার self-assessment checklist (প্রতি Part-এর ৩টি প্রশ্ন)
- Capstone Project-এ ঢোকার প্রস্তুতি
🖼️ এক ছবিতে মূল idea¶
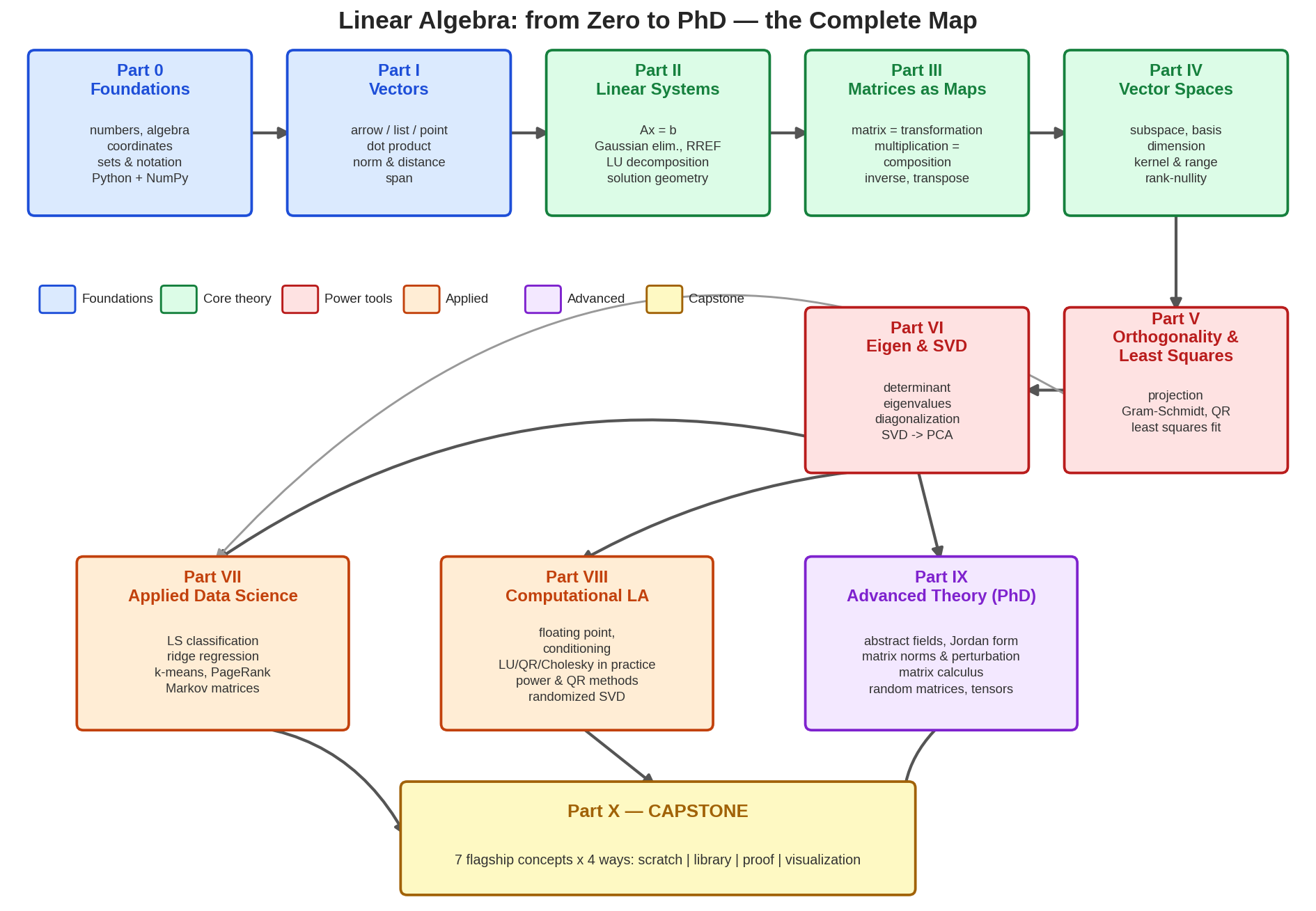
পুরো curriculum এক ছবিতে: নীল = ভিত (Part 0–I), সবুজ = core theory (Part II–IV), লাল = power tools (Part V–VI), কমলা = applied (Part VII–VIII), বেগুনি = advanced theory (Part IX), সোনালি = Capstone। তীরগুলো দেখাচ্ছে কোন Part কোন Part-এর ওপর দাঁড়িয়ে — সব রাস্তা শেষে Capstone-এ মিলেছে।
লক্ষ করো: এটা কোনো এলোমেলো টপিকের তালিকা নয়। একটাই গল্প — vector দিয়ে data লেখা → \(A\mathbf{x}=\mathbf{b}\) solve করা → matrix-কে transformation হিসেবে দেখা → solution-রা কোন space-এ থাকে বোঝা → exact solution না থাকলে projection দিয়ে "সবচেয়ে কাছের" উত্তর → SVD দিয়ে যেকোনো matrix-এর ভেতরটা খুলে দেখা → সেই যন্ত্রপাতি দিয়ে data science।
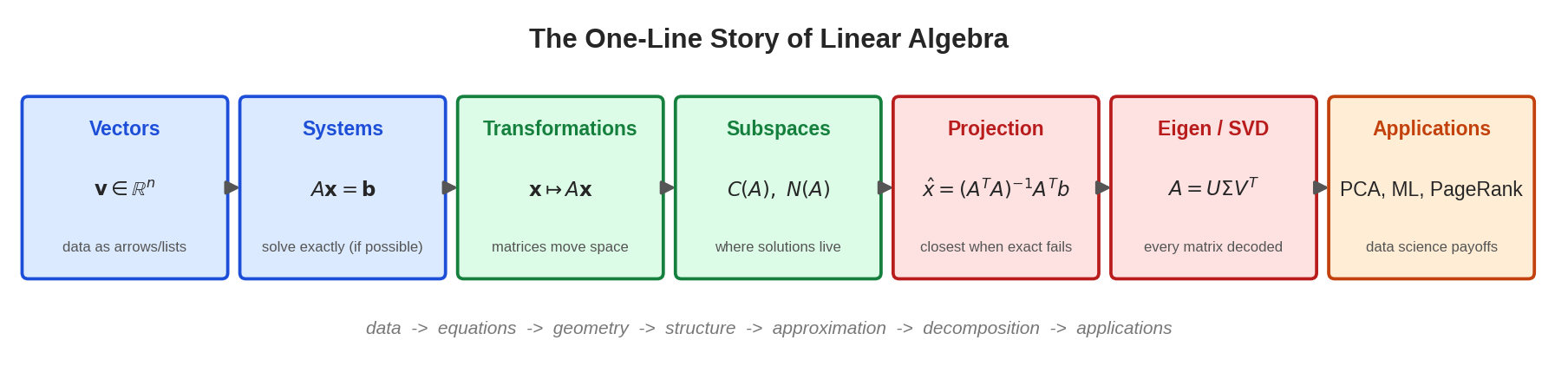
এক লাইনের গল্প: data → equations → geometry → structure → approximation → decomposition → applications।
১. প্রতিটি Part ফিরে দেখা — সারাংশ ও মূল takeaway¶
Part 0 — গণিতের ভিত মেরামত¶
সংখ্যা, algebra, coordinate geometry, set-notation আর Python setup — এই চারটা জিনিস ঝালাই করে আমরা নিশ্চিত করেছিলাম যে \(\Sigma\), \(\in\), \(\mathbb{R}^n\) দেখে আর ভয় লাগবে না। সবচেয়ে বড় উপলব্ধি ছিল "ছবি = সমীকরণ" — প্রতিটা equation একটা geometric ছবি, আর প্রতিটা ছবির পেছনে একটা equation।
মূল takeaway: Notation হলো সংক্ষিপ্ত ভাষা মাত্র — পড়তে জানলেই ভয় শেষ।
Part I — Vectors: সবকিছুর শুরু¶
Vector(ভেক্টর)-কে আমরা তিনভাবে দেখেছি — arrow, list, point — আর শিখেছি একই বস্তুর এই তিন রূপই Linear Algebra-র আসল শক্তি। Dot product দিয়ে similarity মাপা, norm দিয়ে দৈর্ঘ্য-দূরত্ব, আর span দিয়ে "কতদূর পৌঁছানো যায়" — এই তিনটা যন্ত্র পরের সব Part-এ বারবার ফিরে এসেছে।
মূল takeaway: Data মানেই vector; আর \(\mathbf{u}\cdot\mathbf{v}\) মানেই "দুটো জিনিস কতটা একই দিকে?"
Part II — Linear Systems: সমীকরণ সমাধানের শিল্প¶
\(A\mathbf{x}=\mathbf{b}\) — পুরো বিষয়ের কেন্দ্রীয় প্রশ্ন। Row picture (hyperplane-দের ছেদ) আর column picture (column-দের combination) দুই চোখে দেখা শিখেছি, Gaussian elimination আর RREF দিয়ে যন্ত্রের মতো solve করা শিখেছি, আর LU decomposition-এ দেখেছি elimination নিজেই একটা matrix factorization।
মূল takeaway: Solve করা মানে ধাপে ধাপে সহজ system-এ রূপান্তর — আর প্রতিটা ধাপ নিজেই একটা matrix।
Part III — Matrices & Linear Transformations¶
এই Part-এ দৃষ্টিভঙ্গিটাই বদলে গেছে: matrix সংখ্যার টেবিল নয়, space-কে বাঁকানোর যন্ত্র (transformation)। Matrix multiplication কেন ওভাবে define করা — কারণ সেটা function composition; inverse মানে "undo" বোতাম; আর linearity-র দুই শর্ত (\(T(u+v)=T(u)+T(v)\), \(T(cv)=cT(v)\)) পুরো বিষয়ের সংবিধান।
মূল takeaway: Matrix = transformation; multiplication = composition — এই এক লাইনেই Part III।
Part IV — Vector Spaces: Abstract জগতে প্রবেশ¶
\(\mathbb{R}^2\), \(\mathbb{R}^3\) থেকে শুরু করে function space পর্যন্ত — যেখানেই "যোগ করা যায় আর scale করা যায়", সেখানেই vector space। Linear independence-এ শিখেছি অপ্রয়োজনীয় vector চেনা, basis-এ শিখেছি space-এর "coordinate system", আর rank–nullity theorem (\(\dim C(A) + \dim N(A) = n\)) দেখিয়েছে input-এর প্রতিটা dimension হয় output-এ পৌঁছায়, নয় kernel-এ হারায়।
মূল takeaway: Basis হলো চশমা — চশমা বদলালে সংখ্যা বদলায়, vector বদলায় না।
Part V — Orthogonality & Least Squares¶
Projection মানে "ছায়া ফেলা" — আর exact solution না থাকলে ছায়াটাই সেরা উত্তর। Gram–Schmidt দিয়ে যেকোনো basis-কে orthonormal বানানো, QR decomposition, আর normal equations \(A^TA\hat{x}=A^T\mathbf{b}\) — এই hardware দিয়েই regression, data fitting, machine learning-এর দরজা খুলেছে।
মূল takeaway: \(A\mathbf{x}=\mathbf{b}\) solve না হলে হতাশ হয়ো না — \(C(A)\)-তে \(\mathbf{b}\)-এর ছায়া ফেলো, সেটাই least squares।
Part VI — Determinants, Eigenvalues, SVD: রাজমুকুট¶
Determinant = area/volume-এর scale factor; eigenvector = transformation-এ যে দিক বদলায় না; diagonalization = matrix-কে তার সহজতম রূপে দেখা। আর সবার সেরা SVD: যেকোনো matrix \(= U\Sigma V^T\) = rotation × stretch × rotation — যার সরাসরি ফসল PCA।
মূল takeaway: \(A = U\Sigma V^T\) — পৃথিবীর প্রতিটা matrix-এর ভেতরে একটা rotation-stretch-rotation লুকিয়ে আছে।
Part VII — Applied: Data Science-এ Linear Algebra¶
এতদিনের theory এবার মাঠে নেমেছে: least squares দিয়ে classification (প্রথম ML classifier!), ridge regularization, constrained least squares, k-means clustering, graph matrices আর PageRank, Markov matrices। প্রতিটাই দেখিয়েছে — নতুন কোনো জাদু নয়, Part V–VI-এর যন্ত্রপাতিরই চতুর প্রয়োগ।
মূল takeaway: Data science-এর ৮০% হলো least squares আর eigen-decomposition — নতুন পোশাকে।
Part VIII — Computational / Numerical LA¶
Computer-এ math কেন ভুল হয় (floating point, conditioning), বাস্তবে \(A\mathbf{x}=\mathbf{b}\) কীভাবে solve হয় (LU/QR/Cholesky, sparse matrices), eigenvalue কীভাবে বের হয় (power method, QR algorithm), আর আধুনিক randomized methods (randomized SVD, sketching)। শিখেছি: formula জানা আর computer-এ নির্ভরযোগ্যভাবে হিসাব করা — দুটো আলাদা দক্ষতা।
মূল takeaway: \((A^TA)^{-1}\) কাগজে লেখো, কিন্তু code-এ কখনো inverse নিও না — QR/Cholesky ব্যবহার করো।
Part IX — PhD Level: Advanced Theory¶
Abstract field (\(\mathbb{C}\), \(\mathbb{F}_2\))-এর ওপর vector space, diagonalize-না-হওয়া matrix-এর জন্য Jordan form, matrix norm ও perturbation theory (eigenvalue কতটা নড়ে?), deep learning-এর ভাষা matrix calculus, random matrix theory-র Marchenko–Pastur, আর tensor decomposition। এই Part-এর পর তুমি research paper-এর ভাষা পড়তে পারো।
মূল takeaway: Advanced theory মানে নতুন জগৎ নয় — চেনা ধারণাগুলোরই আরো সূক্ষ্ম, আরো সাধারণ রূপ।
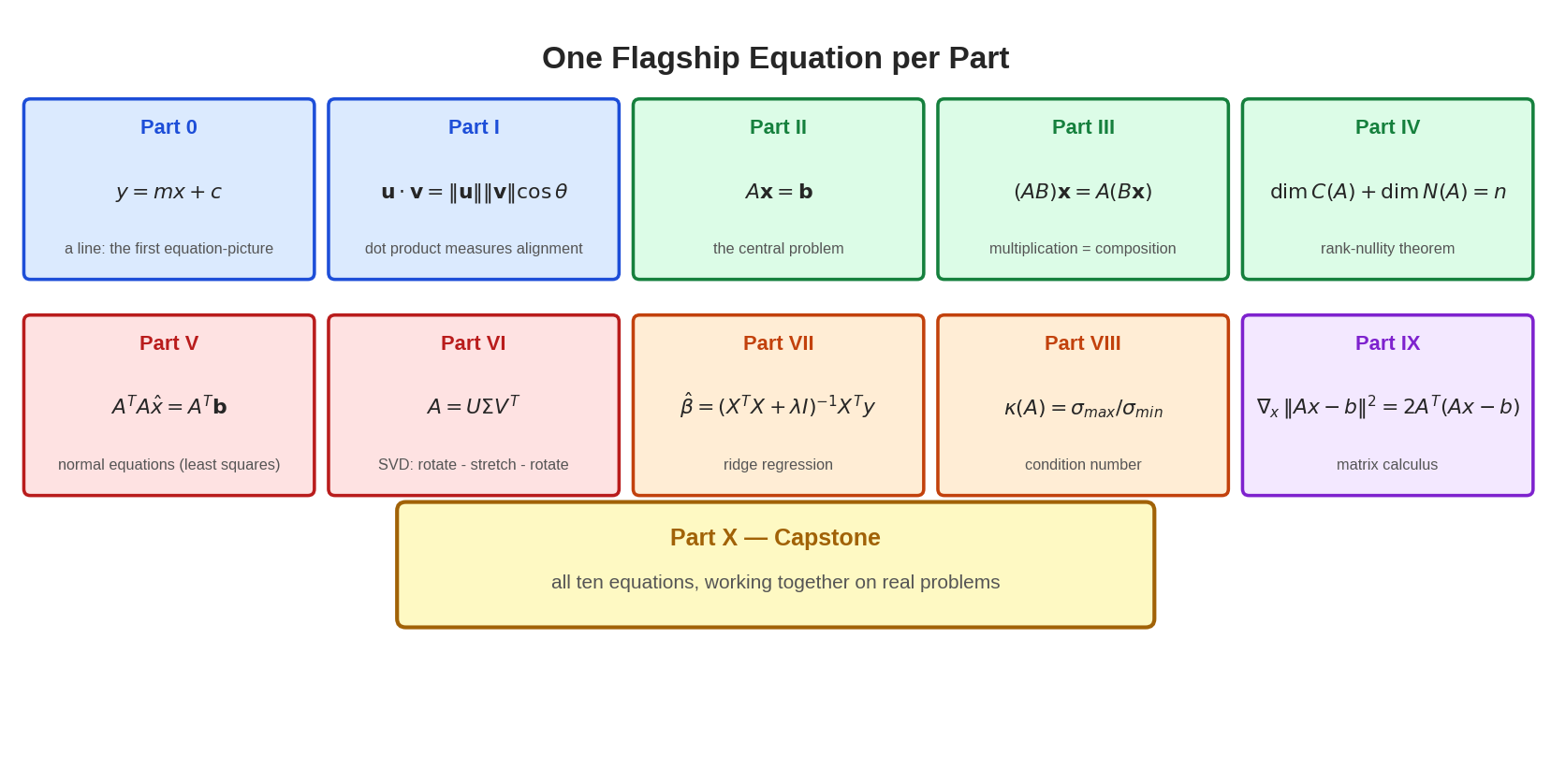
দশটা Part, দশটা flagship equation — এই দশ লাইন মুখস্থ থাকলে পুরো বিষয়ের কঙ্কাল তোমার হাতে।
২. এরপর কি পড়বে? — পাঁচটা ক্লাসিক follow-up¶
তুমি এখন এমন জায়গায় দাঁড়িয়ে যেখান থেকে পৃথিবীর সেরা বইগুলো পড়ার দরজা খোলা। কিন্তু সব একসাথে নয় — কোনটা কখন কেন, সেটাই আসল প্রশ্ন।
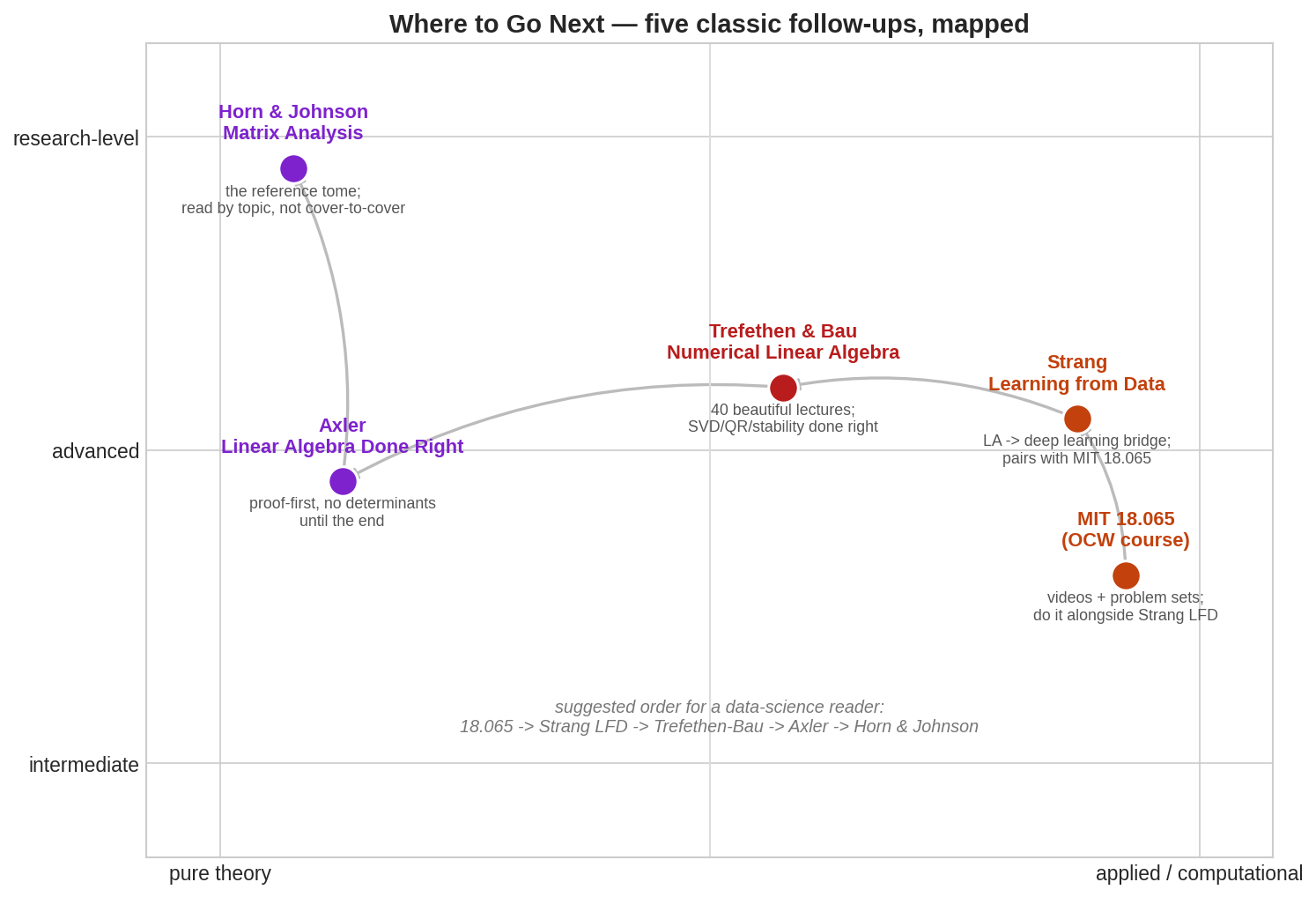
পাঁচটা follow-up-এর মানচিত্র: বাঁয়ে pure theory, ডানে applied; নিচে intermediate, ওপরে research-level। ধূসর তীর = data science পাঠকের জন্য প্রস্তাবিত ক্রম।
| Resource | কখন পড়বে | কেন পড়বে |
|---|---|---|
| MIT 18.065 (Strang, OCW — free videos + problem sets) | এখনই — Capstone শেষ করেই | Part VII–VIII-এর টপিকগুলো Strang-এর মুখে শোনা; problem set গুলোই আসল পরীক্ষা। আমাদের plan-এর "শেষ পরীক্ষা": 18.065-এর problem set নিজে solve করা |
| Strang — Linear Algebra and Learning from Data | 18.065-এর সাথে সাথেই (এটা course-এর textbook) | LA থেকে deep learning-এর সেতু: weight matrices, gradient descent-এর geometry, convolution as matrix — সব এক জায়গায় |
| Trefethen & Bau — Numerical Linear Algebra | Part VIII ভালো লেগে থাকলে, 18.065-এর পরে | ৪০টা ছোট, অপূর্ব লেখা lecture; SVD-first দৃষ্টিভঙ্গি, stability/conditioning-এর সবচেয়ে পরিষ্কার ব্যাখ্যা। Numerical কাজ করতে চাইলে অবশ্যপাঠ্য |
| Axler — Linear Algebra Done Right | Theory-র দিকে ঝোঁক থাকলে; Part IX-এর পরে সবচেয়ে উপভোগ্য | Determinant-কে শেষ পাতায় পাঠিয়ে পুরো theory proof-first ভাবে নতুন করে গড়ে — operator theory-র চোখে LA দেখা। Graduate school-এর প্রস্তুতি |
| Horn & Johnson — Matrix Analysis | সবার শেষে; reference হিসেবে | এটা cover-to-cover পড়ার বই নয় — research-এ যখন কোনো matrix fact দরকার (norm inequality, perturbation bound, canonical form), তখন খুলে দেখার বিশ্বকোষ |
সহজ নিয়ম:
- ML/Data Science-এ যেতে চাও → 18.065 + Strang LFD, তারপর দরকারমতো Trefethen–Bau
- Research/higher study-তে যেতে চাও → Axler আগে, তারপর Horn & Johnson পাশে রেখে paper পড়া শুরু
- দুটোই চাও → ছবির ধূসর তীরের ক্রমটাই অনুসরণ করো: 18.065 → LFD → Trefethen–Bau → Axler → Horn & Johnson
৩. Self-Assessment Checklist — "আমি কি সত্যিই পারি?"¶
প্রতি Part-এর ৩টা করে প্রশ্ন। কাগজ-কলম নিয়ে বসো; যেটায় আটকে যাবে, সেই Part-এ ফিরে যাও। সততাই এখানে একমাত্র নিয়ম।
Part 0 — ভিত¶
- [ ] \(\sum_{i=1}^{n} x_i^2\), \(\mathbf{v} \in \mathbb{R}^5\), \(f: \mathbb{R}^2 \to \mathbb{R}\) — তিনটা notation শব্দে ব্যাখ্যা করতে পারো?
- [ ] \(y = 2x + 1\) আর \(y = -x + 4\) — হাতে এঁকে ছেদবিন্দু বের করতে পারো?
- [ ] NumPy দিয়ে দুটো array বানিয়ে matplotlib-এ plot করতে পারো — documentation না দেখে?
Part I — Vectors¶
- [ ] একই vector-কে arrow, list, point — তিনভাবে ব্যাখ্যা করতে পারো, কখন কোন রূপ কাজে লাগে সহ?
- [ ] \(\mathbf{u}\cdot\mathbf{v} = 0\) মানে কি, আর cosine similarity কেন recommendation system-এ ব্যবহার হয় — বলতে পারো?
- [ ] দুটো vector-এর span কখন পুরো \(\mathbb{R}^2\), কখন একটা লাইন — ছবি এঁকে দেখাতে পারো?
Part II — Linear Systems¶
- [ ] একটা \(3\times 3\) system হাতে Gaussian elimination করে RREF পর্যন্ত নিতে পারো?
- [ ] Row picture আর column picture-এর পার্থক্য একটা উদাহরণে এঁকে দেখাতে পারো?
- [ ] কোন system-এর solution নেই / একটা / অসীম — RREF দেখে চিনতে পারো?
Part III — Matrices as Maps¶
- [ ] \(90°\) rotation, x-axis-এ projection, আর shear — তিনটার matrix মুখে মুখে লিখতে পারো?
- [ ] Matrix multiplication কেন commutative নয় — geometric উদাহরণ দিয়ে বোঝাতে পারো?
- [ ] কোন matrix invertible নয় — determinant না কষেই ছবি (space চ্যাপ্টা হয়ে যাওয়া) দিয়ে ব্যাখ্যা করতে পারো?
Part IV — Vector Spaces¶
- [ ] তিনটা vector linearly independent কিনা — হিসাব করে বের করতে পারো?
- [ ] Basis বদলালে একই vector-এর coordinates কীভাবে বদলায় — একটা উদাহরণে দেখাতে পারো?
- [ ] Rank–nullity theorem statement লিখে একটা concrete matrix-এ যাচাই করতে পারো?
Part V — Orthogonality & Least Squares¶
- [ ] একটা vector-কে আরেকটার ওপর project করার formula লিখে ছবি আঁকতে পারো?
- [ ] Normal equations \(A^TA\hat{x} = A^T\mathbf{b}\) কোথা থেকে আসে — projection-এর ছবি দিয়ে derive করতে পারো?
- [ ] ৫টা data point-এ straight line fit — পুরোটা হাতে (বা numpy ছাড়া code-এ) করতে পারো?
Part VI — Eigen & SVD¶
- [ ] \(2\times 2\) matrix-এর eigenvalue-eigenvector হাতে বের করতে পারো?
- [ ] Diagonalization \(A = PDP^{-1}\) কেন \(A^{100}\) হিসাব সহজ করে — ব্যাখ্যা করতে পারো?
- [ ] SVD-র \(U\), \(\Sigma\), \(V\) — প্রতিটার geometric অর্থ, আর PCA-র সাথে সম্পর্ক বলতে পারো?
Part VII — Applied¶
- [ ] Least squares দিয়ে binary classifier কীভাবে বানায় — ধাপগুলো লিখতে পারো?
- [ ] Ridge (\(\lambda\)) বাড়ালে coefficient-দের কি হয়, কেন — বলতে পারো?
- [ ] PageRank আসলে কোন matrix-এর কোন eigenvector — ব্যাখ্যা করতে পারো?
Part VIII — Computational¶
- [ ] Condition number বড় হলে কি বিপদ — একটা উদাহরণসহ বলতে পারো?
- [ ] Power method কেন সবচেয়ে বড় eigenvalue-তে converge করে — যুক্তি দিতে পারো?
- [ ] Randomized SVD কখন full SVD-র চেয়ে ভালো পছন্দ — trade-off ব্যাখ্যা করতে পারো?
Part IX — Advanced¶
- [ ] কোন matrix diagonalizable নয় — উদাহরণ দিয়ে Jordan form-এর প্রয়োজন বোঝাতে পারো?
- [ ] \(\nabla_x \|Ax-b\|^2\) হাতে derive করতে পারো — dimension check সহ?
- [ ] Marchenko–Pastur law মোটা দাগে কি বলে, ML-এ কেন আসে — দু-লাইনে বলতে পারো?
স্কোরবোর্ড: ২৭–৩০ ✅ = Capstone-এ ঝাঁপ দাও; ২০–২৬ = দুর্বল Part-গুলো এক সপ্তাহ revision; < ২০ = তাড়াহুড়ো নেই — checklist ধরে ধরে ফিরে যাও, বইটা কোথাও পালাচ্ছে না।
৪. এক নজরে¶
| Part | এক লাইনে | Flagship equation |
|---|---|---|
| 0 | ছবি = সমীকরণ | \(y = mx + c\) |
| I | data = vector | \(\mathbf{u}\cdot\mathbf{v} = \|\mathbf{u}\|\|\mathbf{v}\|\cos\theta\) |
| II | কেন্দ্রীয় প্রশ্ন | \(A\mathbf{x} = \mathbf{b}\) |
| III | matrix = transformation | \((AB)\mathbf{x} = A(B\mathbf{x})\) |
| IV | structure of solutions | \(\dim C(A) + \dim N(A) = n\) |
| V | ছায়াই সেরা উত্তর | \(A^TA\hat{x} = A^T\mathbf{b}\) |
| VI | প্রতিটা matrix-এর কঙ্কাল | \(A = U\Sigma V^T\) |
| VII | theory → data science | \(\hat\beta = (X^TX+\lambda I)^{-1}X^Ty\) |
| VIII | computer-এ নির্ভরযোগ্য math | \(\kappa(A) = \sigma_{\max}/\sigma_{\min}\) |
| IX | research-এর ভাষা | \(\nabla_x\|Ax-b\|^2 = 2A^T(Ax-b)\) |
সেতুবাক্য: মানচিত্র দেখা শেষ — এবার নিজের হাতে সব যন্ত্র একসাথে চালানোর পালা। পরের পাতায় Integrative Capstone Project: ৭টা flagship concept, প্রতিটা ৪ভাবে — scratch, library, derivation, visualization।
📓 Notebook Project¶
capstone-project/capstone.ipynb — পুরো curriculum-এর ৭টা flagship concept-এর সম্পূর্ণ working implementation (repo-র capstone-project/ ফোল্ডারে; বিস্তারিত নির্দেশনা capstone.md-তে)।