Chapter 5.4 — Least Squares (লিস্ট স্কোয়ার্স — সবচেয়ে কম ভুলের সমাধান)¶
এতদিন আমরা \(Ax = b\) solve করেছি ধরে নিয়ে যে সমাধান আছে। কিন্তু বাস্তব ডেটার নির্মম সত্য: measurement-এ noise থাকে, সমীকরণ থাকে অজানার চেয়ে বেশি — আর তখন \(Ax = b\)-এর কোনো সমাধানই থাকে না। হাল ছাড়বো? না — প্রশ্নটাই বদলে দেবো: "সবচেয়ে কম ভুল করে এমন \(\hat{x}\) কোনটা?" উত্তরের পুরোটাই আগের তিন chapter-এর ছায়ার গণিত। এই idea-টা এতই শক্তিশালী যে ১৮০১ সালে Gauss এটা দিয়ে হারিয়ে-যাওয়া গ্রহাণু Ceres-এর অবস্থান ভবিষ্যদ্বাণী করে রাতারাতি বিখ্যাত হয়ে যান।
🎯 এই chapter-এ যা শিখবে¶
- Least Squares Problem(লিস্ট স্কোয়ার্স প্রবলেম): \(\min_x \|Ax - b\|^2\) — কী, কেন, কখন
- Projection-এর ছবি থেকে Normal Equations(নরমাল ইকুয়েশনস) \(A^TA\hat{x} = A^Tb\) derive করা (মুখস্থ নয়!)
- Projection Matrix(প্রজেকশন ম্যাট্রিক্স) \(P = A(A^TA)^{-1}A^T\) ও Pseudo-inverse(সিউডো-ইনভার্স) \(A^\dagger\)
- QR দিয়ে least squares — বাস্তবের নিরাপদ রাস্তা
- তিন পদ্ধতিতে (normal equations, QR,
lstsq) একই উত্তর কোডে মিলিয়ে দেখা
🖼️ এক ছবিতে মূল idea¶
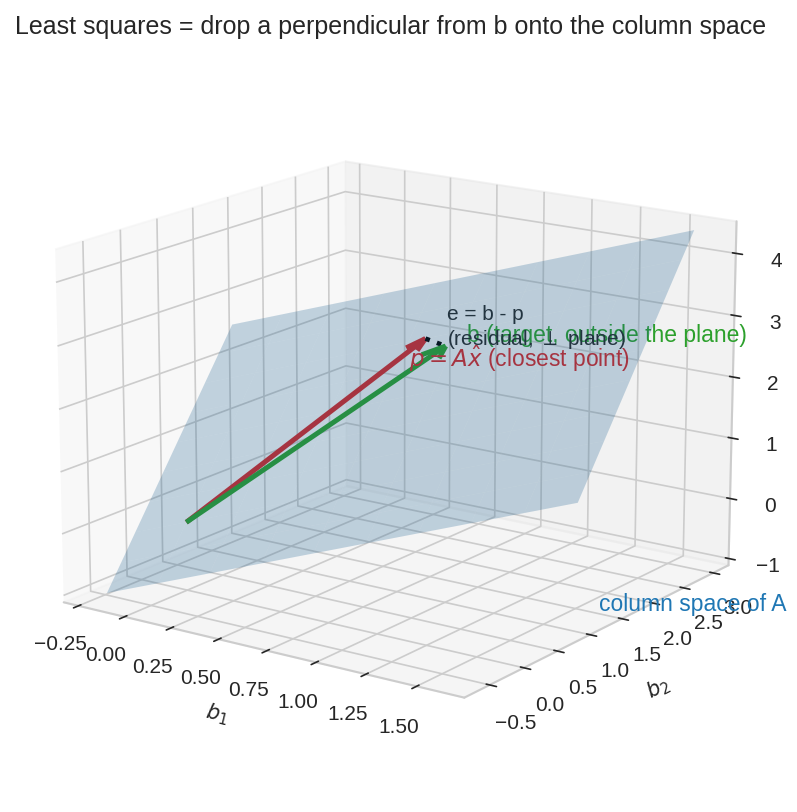
এটাই least squares-এর সম্পূর্ণ গল্প: \(b\) (সবুজ) column space-এর plane-এর বাইরে ভেসে আছে — \(Ax=b\) অসম্ভব। plane-এর ভেতরে \(b\)-এর সবচেয়ে কাছের বিন্দু তার ছায়া \(p = A\hat{x}\) (লাল), আর ভুলটুকু \(e = b - p\) (ডটেড) plane-এর ওপর নিখুঁত লম্ব। Chapter 5.1-এর লাইনের জায়গায় এখন plane — এই যা পার্থক্য।
১. কি? (What)¶
দৈনন্দিন analogy: তিন বন্ধুর ঘড়ি¶
তুমি জানতে চাও এখন ক'টা বাজে। তিন বন্ধুর ঘড়ি বলছে ৯:৫৮, ১০:০১, ১০:০৪। কোনো একটা সময় তিনটা ঘড়ির সাথেই হুবহু মিলবে না — সমীকরণ ৩টা, অজানা ১টা, সমাধান নেই। তুমি কী করো? মনে মনে এমন সময় বেছে নাও যেটা তিনটার সবচেয়ে কাছাকাছি — সম্ভবত ১০:০১-এর আশেপাশে। অজান্তেই তুমি একটা least squares problem solve করলে!
Formal রূপ: \(A\) হলো \(m \times n\), Tall Matrix(টল ম্যাট্রিক্স) — সারি (সমীকরণ) বেশি, column (অজানা) কম, \(m > n\)। এরকম system-কে বলে Over-determined(ওভার-ডিটারমাইন্ড — অতিরিক্ত শর্তে বাঁধা)। প্রায় কোনো \(b\)-র জন্যই exact সমাধান নেই, কারণ \(C(A)\) হলো \(\mathbb{R}^m\)-এর ভেতরে সরু একটা subspace (dim \(n\)), আর \(b\)-এর সেখানে পড়ার "সৌভাগ্য" বিরল।
সংজ্ঞা¶
Residual(রেসিডুয়াল): \(x\) বাছলে ভুলের vector
Least Squares Problem: সেই \(\hat{x}\) খোঁজো যা ভুলের বর্গের যোগফল সবচেয়ে ছোট করে:
\(\hat{x}\)-কে বলে Least Squares Approximate Solution(লিস্ট স্কোয়ার্স আনুমানিক সমাধান)। সাবধান — নামে "solution" থাকলেও সাধারণত \(A\hat{x} \neq b\); সে শুধু ভুলটা যথাসম্ভব ছোট করে। Data fitting-এর জগতে এরই আরেক নাম Regression(রিগ্রেশন) — পরের chapter-এ পুরোটা সেখানেই যাবে।
কেন "বর্গ"? (তিনটা সৎ কারণ)¶
- চিহ্ন মোছা: \(+2\) আর \(-2\) ভুল যেন কাটাকাটি না হয়ে যায় — বর্গ করলে দুটোই জরিমানা পায়।
- গণিত মসৃণ: absolute value-এর মতো কোণা নেই — calculus চলে, উত্তর সুন্দর সূত্রে আসে।
- জ্যামিতি: বর্গের যোগফল = দূরত্বের বর্গ — অমনি পুরো সমস্যাটা "সবচেয়ে কাছের বিন্দু" হয়ে যায়, আর আমরা জানি সেটা মানে ছায়া।
২. দেখতে কেমন?¶
দৃশ্য ১: ডেটার চোখে — যেই লাইন কারো মন রাখে না, সবার কাছে থাকে¶
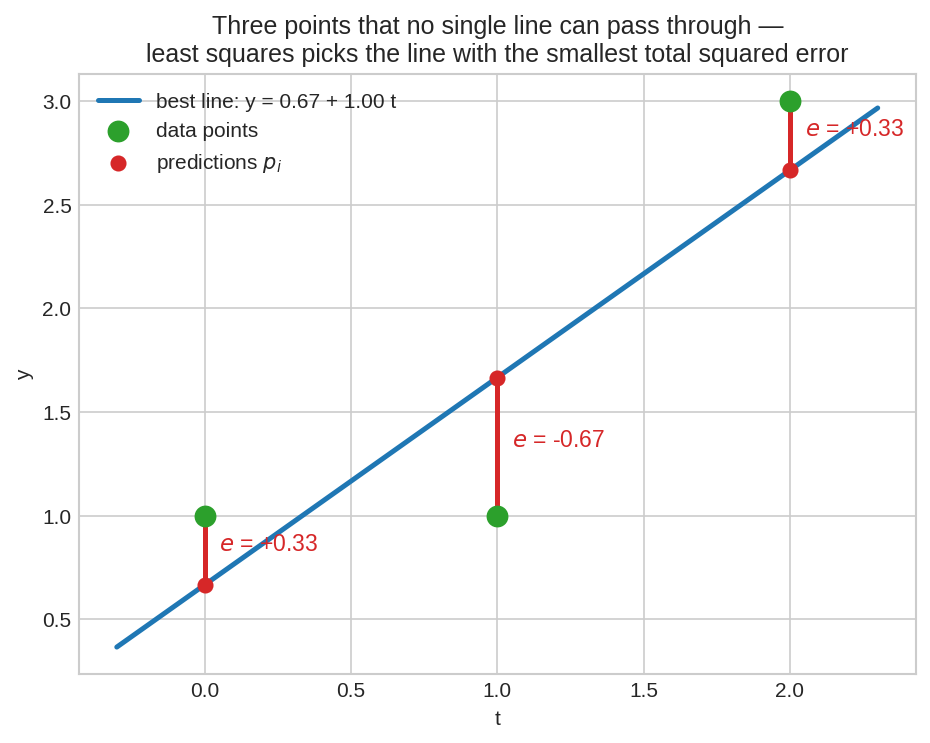
তিনটা বিন্দু \((0,1), (1,1), (2,3)\) — কোনো সরলরেখা তিনটার ভেতর দিয়ে যায় না। least squares লাইনটা (নীল) প্রতিটা বিন্দু থেকে লাল লম্ব-দূরত্বগুলোর (residuals) বর্গের যোগফল minimize করে।
দৃশ্য ২: অজানার চোখে — মসৃণ পেয়ালার তলা¶
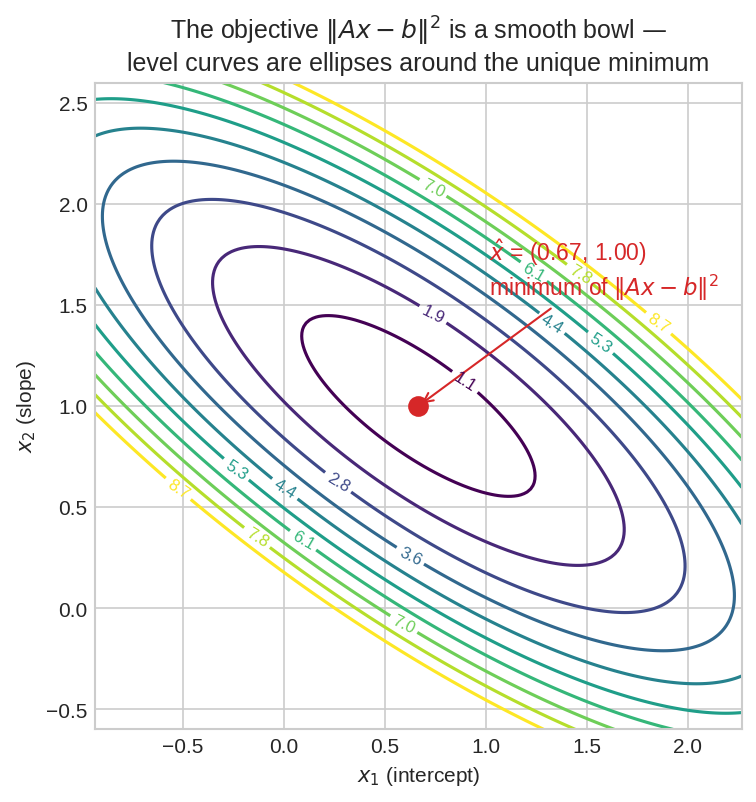
\(x = (x_1, x_2)\)-এর জগতে objective \(\|Ax-b\|^2\)-এর level curve — উপবৃত্তাকার ঢেউ, কেন্দ্রে unique minimum \(\hat{x}\)। (VMLS-এর fig 12.1-এর আদলে, আমাদের নিজের সংখ্যায়।)
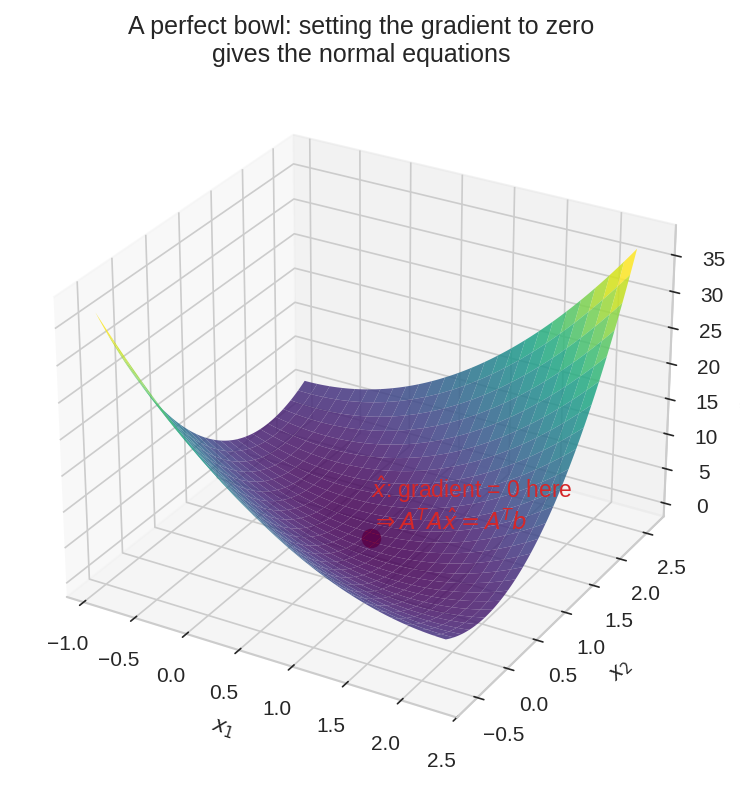
একই জিনিস 3D-তে: objective-টা একটা নিখুঁত পেয়ালা (convex bowl)। তলায় gradient শূন্য — সেখান থেকেই normal equations জন্ম নেবে।
দৃশ্য ৩: প্রমাণের চোখে¶
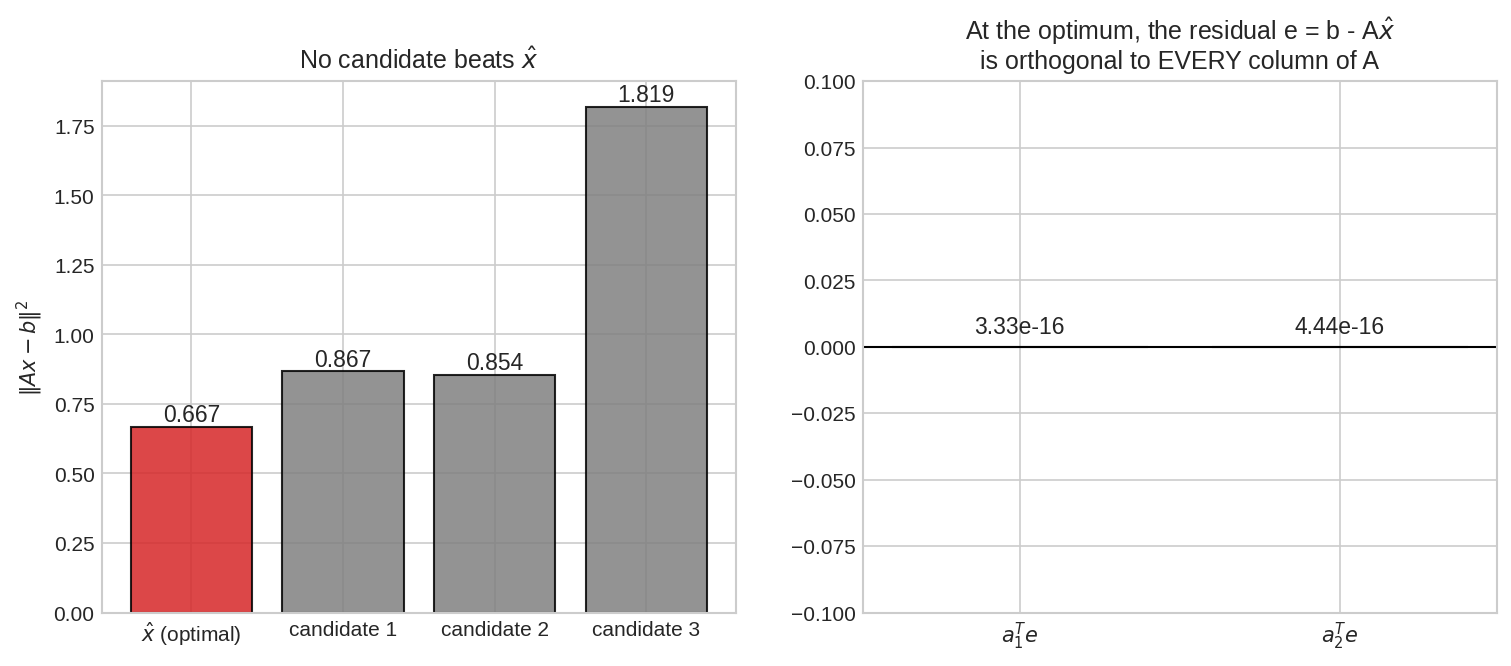
বাঁয়ে: \(\hat{x}\)-এর বিরুদ্ধে তিনজন প্রার্থী — সবার ভুল বেশি। ডানে: বিজয়ীর residual \(e\), \(A\)-এর প্রতিটা column-এর সাথে লম্ব — \(a_1^Te = a_2^Te = 0\) (মেশিনের হিসাবে \(10^{-16}\))।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- GPS: চারটার বেশি satellite থেকে দূরত্ব-measurement, সবগুলোতে noise — তোমার ফোন প্রতি সেকেন্ডে least squares solve করে অবস্থান বের করে।
- জরিপ ও জ্যোতির্বিদ্যা (জন্মস্থান): Gauss-এর Ceres, আর আজো surveying-এ শতাধিক পরস্পর-অসামঞ্জস্য measurement মেলানো হয় least squares-এ।
- Audio/Image denoising: noisy signal-কে "সম্ভাব্য পরিষ্কার signal-দের subspace"-এ project করা।
- Network tomography: internet-এর কোন link কত slow — path-ভিত্তিক দেরি মেপে link-delay estimate (VMLS 12.7-এর গল্প)।
Data Science / ML-এ:
- Linear Regression: least squares-ই তার হৃদপিণ্ড — পরের chapter পুরোটা এটাই।
- Classifier-ও বানানো যায় least squares দিয়ে (Part VII-এ MNIST!)।
- Recommender baseline, trend estimation, forecasting — সবার প্রথম চেষ্টা least squares।
- Deep learning-এর যোগসূত্র: loss function হিসেবে Mean Squared Error মানেই least squares-এর nonlinear সংস্করণ; আর তার শেষ layer-টা প্রায়ই ঠিক এই সমস্যা।
৪. Properties¶
Property 1 — সমাধানের অস্তিত্ব ও এককত্ব¶
\(A\)-এর column গুলো linearly independent হলে least squares সমাধান আছে এবং একটাই:
কেন \(A^TA\) invertible? আগের chapter-এর Problem 5: \(N(A^TA) = N(A) = \{0\}\) ∎। (Column dependent হলে? সমাধান অসংখ্য — সবচেয়ে ছোটটা বেছে নেয় pseudo-inverse, Part VI-এর SVD সেই গল্প বলবে।)
Property 2 — Normal Equations¶
\(\hat{x}\) চেনার সমীকরণ:
নাম "normal" কারণ এর জন্ম residual-এর লম্বতা (normal = লম্ব) থেকে — derivation Intuition-এ। \(A^TA\)-কে বলে Gram Matrix(গ্রাম ম্যাট্রিক্স) — এর \((i,j)\) entry হলো \(a_i^Ta_j\), column-দের পারস্পরিক dot product-এর টেবিল।
Property 3 — Projection matrix \(P\)¶
Best prediction:
\(P\) হলো column space-এ ছায়া ফেলার মেশিন। যাচাইযোগ্য ধর্ম:
- \(P^2 = P\) (ছায়ার ছায়া = ছায়া): \(A(A^TA)^{-1}\underbrace{A^TA(A^TA)^{-1}}_{I}A^T = P\) ✓
- \(P^T = P\) (symmetric)
- \(b \in C(A)\) হলে \(Pb = b\); আর \(b \perp C(A)\) হলে \(Pb = 0\)
- \(I - P\) ফেলে left null space-এ (আগের chapter-এর Problem 6) — residual মেশিন: \(e = (I-P)b\)
Property 4 — Pythagoras ভাঙন¶
\(b\) ভেঙে যায় লম্ব দুই টুকরোয়: \(b = p + e\), তাই
Data Science-এ এটারই নাম "explained + unexplained variation" — \(R^2\) statistic এই ভাঙনেরই অনুপাত (Statistics curriculum-এর regression অধ্যায় মনে করো)।
Property 5 — Orthonormal হলে সব সহজ (\(Q\)-এর পুরস্কার)¶
\(A\)-এর জায়গায় orthonormal-column \(Q\) হলে normal equations-এর \(Q^TQ = I\), তাই
Inverse-ই লাগে না! এটাই আগের chapter-এ Gram–Schmidt শেখার আসল পুরস্কার, আর এ থেকেই QR-পথ:
(প্রমাণ: normal equations-এ বসাও — \(R^TQ^TQR\hat{x} = R^TQ^Tb \Rightarrow R\hat{x} = Q^Tb\), কারণ \(R^T\) invertible। তারপর back substitution।) বড় হিসাবের জগতে এই পথটাই ব্যবহার হয়, কারণ \(A^TA\) বানালে rounding error বর্গগুণ বেড়ে যায় — QR-এ বাড়ে না (Chapter 5.2, Property 3)।
৫. Intuition — কেন সত্য? (Normal equations নিজে বানাই)¶
পথ ১: জ্যামিতি — ছায়ার যুক্তি (Strang-এর প্রিয়)¶
\(Ax\) মানেই column space-এর একটা বিন্দু — \(x\) ঘোরালে-ফেরালে \(Ax\) ঘুরে বেড়ায় গোটা \(C(A)\) জুড়ে। তাহলে least squares প্রশ্নটা হুবহু: \(C(A)\)-এর কোন বিন্দু \(b\)-এর সবচেয়ে কাছে?
Chapter 5.1-এর রাবার-ব্যান্ড যুক্তি এখানেও খাটে: সবচেয়ে কাছের বিন্দু \(p\)-তে পৌঁছালে ভুলের vector \(e = b - A\hat{x}\) subspace-টার ওপর লম্ব হতে বাধ্য। "লম্ব to পুরো column space" মানে প্রতিটা column-এর সাথে লম্ব:
\(n\)টা সমীকরণ একসাথে গুছিয়ে লেখো — column-রা \(A^T\)-এর row:
ব্যস — normal equations বেরিয়ে গেলো, calculus ছাড়াই। FTLA-র ভাষায় আরো সুন্দর: \(A^Te = 0\) মানে \(e \in N(A^T)\) — residual-এর ঠিকানা left null space, যেটা \(C(A)\)-এর orthogonal complement। ছায়া \(p\) পড়লো column space-এ, ভুল \(e\) গেলো তার লম্ব-জগতে — \(b\)-এর নিখুঁত direct-sum ভাঙন (Chapter 5.3, Property 4)।
পথ ২: Calculus — পেয়ালার তলা¶
Objective-টা লিখে ফেলো:
Gradient (Part IX-এ matrix calculus বিস্তারিত; এখানে ফল): \(\nabla f(x) = 2A^TAx - 2A^Tb\)। পেয়ালার তলায় ঢাল শূন্য:
একই উত্তর। দুই পথ দুই দর্শন — জ্যামিতি বলে কোথায়, calculus বলে কীভাবে খুঁজবে (এই gradient-ই gradient descent-এর জ্বালানি)।
পথ ৩: বীজগণিতীয় নিশ্চয়তা — সত্যিই minimum তো?¶
যেকোনো প্রার্থী \(x\) নাও, আর ভাঙো:
(মাঝের cross term মরে গেছে লম্বতায় — Pythagoras!) সমান হয় কেবল \(A(x - \hat{x}) = 0\) হলে, অর্থাৎ independent column-এর বেলায় কেবল \(x = \hat{x}\)-তে। সুতরাং \(\hat{x}\)-ই একমাত্র চ্যাম্পিয়ন ∎ — কোনো fancy optimization theory লাগলো না, শুধু ছায়ার জ্যামিতি।
৬. Code-এ কেমনে লিখে¶
import numpy as np
np.random.seed(42)
# ঘড়ির উদাহরণের বড় ভাই: y = c + d*t মডেল, ৩টা data point
A = np.array([[1., 0.],
[1., 1.],
[1., 2.]]) # column 1: intercept, column 2: t
b = np.array([1., 1., 3.])
# --- পদ্ধতি ১: Normal equations (শেখার জন্য) ---
x_ne = np.linalg.solve(A.T @ A, A.T @ b)
# --- পদ্ধতি ২: QR (বাস্তবের পথ) ---
Q, R = np.linalg.qr(A)
x_qr = np.linalg.solve(R, Q.T @ b) # আসলে back substitution
# --- পদ্ধতি ৩: library ---
x_ls, res, rank, sv = np.linalg.lstsq(A, b, rcond=None)
print("normal eq:", x_ne) # [0.66666667 1. ]
print("QR :", x_qr) # [0.66666667 1. ]
print("lstsq :", x_ls) # [0.66666667 1. ]
# --- ছায়া আর residual ---
p = A @ x_ne # projection = best prediction
e = b - p # residual
print("p =", p) # [0.667 1.667 2.667]
print("e =", e) # [ 0.333 -0.667 0.333]
print("A^T e =", A.T @ e) # [~0 ~0] ← লম্বতা!
print("Pythagoras:", np.linalg.norm(b)**2,
"=", np.linalg.norm(p)**2 + np.linalg.norm(e)**2)
# Projection matrix ও তার ধর্ম
P = A @ np.linalg.inv(A.T @ A) @ A.T
print("P@P == P?", np.allclose(P @ P, P), "| P^T == P?", np.allclose(P.T, P))
Output ব্যাখ্যা:
- তিন পদ্ধতিই দিলো \(\hat{x} = (2/3,\; 1)\) — মানে best line \(y = \frac23 + t\)।
A.T @ eকার্যত শূন্য — normal equations-এর জন্মশর্ত কোডে ধরা।- Pythagoras দুই পাশ সমান (\(11 = 10.667 + 0.333\)) ✓
np.linalg.solve(A.T@A, ...)লিখেছি,inv(A.T@A) @ ...নয় — inverse বানানো ধীর ও ভুল-প্রবণ; solve সরাসরি সমীকরণ ভাঙে। আর সিরিয়াস কাজেlstsq/QR — এরা প্রায়-dependent column-এও ভদ্র আচরণ করে।
৭. Worked Examples¶
Example 1 — পুরো হিসাব হাতে (উপরের কোডের সংখ্যাগুলো)¶
\(t = 0, 1, 2\)-তে মান \(b = (1, 1, 3)\); মডেল \(y = c + dt\), অর্থাৎ:
ধাপ ১ — Gram matrix ও ডান পাশ:
ধাপ ২ — Normal equations solve:
ধাপ ৩ — ছায়া ও ভুল: \(p = A\hat{x} = (\tfrac23, \tfrac53, \tfrac83)\), \(e = b - p = (\tfrac13, -\tfrac23, \tfrac13)\)। চেক: \(e\)-এর যোগফল \(0\) (প্রথম column-এর সাথে লম্ব), \(0\cdot\tfrac13 + 1\cdot(-\tfrac23) + 2\cdot\tfrac13 = 0\) (দ্বিতীয়টার সাথেও) ✓ সর্বনিম্ন ভুল: \(\|e\|^2 = \tfrac19 + \tfrac49 + \tfrac19 = \tfrac23\)।
Example 2 — গড় হলো least squares! (সবচেয়ে ছোট, সবচেয়ে গভীর উদাহরণ)¶
মডেল: একটাই অজানা সংখ্যা \(x\) — সব measurement-কে এক সংখ্যায় ব্যাখ্যা করো। \(A = (1,1,\dots,1)^T\), \(b = (b_1, \dots, b_m)\)।
Normal equations: \(A^TA = m\), \(A^Tb = \sum b_i\), তাই
অর্থ: "গড়" জিনিসটা আসলে সব-এক vector-এর লাইনে \(b\)-এর ছায়া। ঘড়ির ধাঁধার উত্তরও তাই: \((9{:}58 + 10{:}01 + 10{:}04)/3 = 10{:}01\)। আর residual \(e = b - \bar{b}\mathbf{1}\) হলো deviation-from-mean — যার \(\|e\|^2\) statistics-এ variance-এর গুণিতক। Least squares আর statistics এখানে হাত ধরাধরি করে জন্মেছে।
Example 3 — QR পথে একই সমস্যা¶
Example 1-এর \(A\)-তে Gram–Schmidt (Chapter 5.2-এর কায়দায়):
\(q_1 = \frac{1}{\sqrt3}(1,1,1)\), \(R_{11} = \sqrt3\); \(R_{12} = q_1^Ta_2 = \frac{3}{\sqrt3} = \sqrt3\); \(w_2 = (0,1,2) - \sqrt3\cdot\frac{1}{\sqrt3}(1,1,1) = (-1, 0, 1)\), \(R_{22} = \sqrt2\), \(q_2 = \frac{1}{\sqrt2}(-1,0,1)\)।
একই \(\hat{x} = (\tfrac23, 1)\) — কিন্তু লক্ষ করো, কোথাও \(A^TA\) বানাতে হয়নি, inverse নিতে হয়নি; শুধু dot product আর নিচ-থেকে-ওপরে substitution।
৮. Problems ও Solutions¶
Problem 1. \(A = \begin{bmatrix}1\\2\end{bmatrix}\), \(b = \begin{bmatrix}3\\1\end{bmatrix}\) — এক অজানার least squares। \(\hat{x}\), \(p\), \(e\) বের করো এবং Chapter 5.1-এর projection সূত্রের সাথে মিলিয়ে দেখাও এটা একই জিনিস।
Solution
Normal equations: \(A^TA = 1 + 4 = 5\), \(A^Tb = 3 + 2 = 5\), তাই \(\hat{x} = 1\)।
চেক: \(A^Te = 1\cdot2 + 2\cdot(-1) = 0\) ✓
Chapter 5.1-এর সূত্র: \(\text{proj}_a(b) = \frac{a^Tb}{a^Ta}a = \frac{5}{5}(1,2) = (1,2)\) — হুবহু এক!
শিক্ষা: এক-column least squares \(=\) এক লাইনে projection। Least squares আসলে projection-এরই বহু-column সংস্করণ — নতুন কিছু মুখস্থ করার নেই।
Problem 2. \(t = -1, 0, 1, 2\)-তে মাপা মান \(b = (0, 1, 2, 4)\)। \(y = c + dt\) least squares-এ fit করো এবং \(t = 3\)-এ prediction দাও।
Solution
Normal equations:
প্রথমটা থেকে \(c = (7-2d)/4\); বসিয়ে: \(\tfrac{7-2d}{2} + 6d = 10 \Rightarrow 7 - 2d + 12d = 20 \Rightarrow d = 1.3,\; c = 1.1\)।
Best line: \(\hat{y} = 1.1 + 1.3\,t\)। Prediction: \(\hat{y}(3) = 1.1 + 3.9 = 5.0\)।
যাচাই (residual লম্বতা): \(p = (-0.2, 1.1, 2.4, 3.7)\), \(e = (0.2, -0.1, -0.4, 0.3)\); যোগফল \(0\) ✓, \(t\)-ওয়েটেড যোগফল \(-0.2+0-0.4+0.6 = 0\) ✓
Problem 3. দেখাও: least squares residual \(e\)-এর জন্য \(\|e\|^2 = b^Te = b^Tb - b^TA\hat{x}\)। (হিসাব ছোট করার কৌশল হিসেবেও কাজে লাগে।)
Solution
\(e = b - A\hat{x}\) লিখে:
শেষ term শূন্য কারণ \(A^Te = 0\) — normal equations-এর লম্বতা। তাই \(\|e\|^2 = e^Tb = (b - A\hat{x})^Tb = b^Tb - \hat{x}^TA^Tb\) ∎
Geometric পাঠ: \(e\)-এর সাথে \(b\)-এর dot product-ই \(\|e\|^2\) — কারণ \(b = p + e\)-এর \(p\)-অংশ \(e\)-এর সাথে লম্ব; \(b\)-এর "e-দিকের ছায়া" পুরোটাই \(e\)।
Problem 4. (VMLS 12.2-এর আদলে) \(Q\)-এর column orthonormal। প্রমাণ করো \(\min_x\|Qx - b\|^2\)-এর সমাধান \(\hat{x} = Q^Tb\), এবং optimal residual-এর দৈর্ঘ্য \(\|e\|^2 = \|b\|^2 - \|Q^Tb\|^2\)।
Solution
Normal equations-এ \(A = Q\) বসাও:
Residual: Pythagoras (Property 4) থেকে
(মাঝে ব্যবহার করেছি \(\|Q\hat{x}\| = \|\hat{x}\|\) — orthonormal column দৈর্ঘ্য বাঁচায়, Chapter 5.2 Property 3।) ∎
হিসাবের লাভ: সাধারণ least squares-এ লাগে \(\sim 2mn^2\) operation; এখানে শুধু \(Q^Tb\) — \(2mn\)। Orthonormality মানে হাজারগুণ সস্তা।
Problem 5. Weighted least squares: measurement-গুলোর গুরুত্ব আলাদা — minimize \(\sum_i w_i(\tilde{a}_i^Tx - b_i)^2\), যেখানে \(w_i > 0\), \(\tilde{a}_i^T\) হলো \(A\)-এর row। দেখাও সমাধান \(\hat{x} = (A^TWA)^{-1}A^TWb\), যেখানে \(W = \text{diag}(w)\)। (VMLS 12.4-এর আদলে)
Solution
কৌশল: নতুন সমস্যাকে পুরনোতে রূপান্তর। \(D = \text{diag}(\sqrt{w_1}, \dots, \sqrt{w_m})\) ধরো। তাহলে
— এটা \(B = DA\), \(d = Db\) নিয়ে সাধারণ least squares! Normal equations:
(\(A\)-এর column independent হলে \(DA\)-রও তাই — \(D\) invertible — তাই \(A^TWA\) invertible।)
ML যোগ: কম-বিশ্বাসযোগ্য (noisy) sample-কে ছোট \(w_i\) — regression-এ একদম রুটিন কৌশল; আর Part VII-এ regularization-ও একই "সমস্যা সাজিয়ে পুরনো যন্ত্রে ফেলা" খেলা।
Problem 6. Projection matrix \(P = A(A^TA)^{-1}A^T\)-এর জন্য দেখাও: (a) \(Pb = b \iff b \in C(A)\), (b) \((I-P)b = b \iff b \perp C(A)\), (c) \(P\)-এর কোনো তৃতীয় সম্ভাবনা নেই — যেকোনো \(b\)-এর জন্য \(Pb\) আর \((I-P)b\) পরস্পর লম্ব।
Solution
(a) (⇐) \(b \in C(A)\) মানে \(b = Ax\) কোনো \(x\)-এর জন্য। তখন
(⇒) \(Pb = b\) হলে \(b = A\big[(A^TA)^{-1}A^Tb\big]\) — column-দের combination — অতএব \(b \in C(A)\) ✓
(b) \(b \perp C(A)\) মানে \(A^Tb = 0\) (প্রতিটা column-এর সাথে লম্ব)। তখন \(Pb = A(A^TA)^{-1}\cdot 0 = 0\), তাই \((I-P)b = b\)। উল্টো দিকও একই পথে।
(c) \((Pb)^T(I-P)b = b^TP^T(I-P)b = b^T(P - P^2)b = b^T\cdot 0\cdot b = 0\) — এখানে \(P^T = P\) আর \(P^2 = P\) (Property 3) ∎
ছবি: \(P\) আর \(I-P\) মিলে \(b\)-কে ভাগ করে দুই লম্ব জগতে — Chapter 5.3-এর direct sum-এর যন্ত্ররূপ।
Problem 7. Least angle property (VMLS 12.3-এর আদলে): দেখাও \((A\hat{x})^Tb = \|A\hat{x}\|^2\), এবং ব্যাখ্যা করো কেন এর মানে — \(b\) আর \(A\hat{x}\)-এর মধ্যকার কোণ যেকোনো \(Ax\)-এর সাথে \(b\)-এর কোণের চেয়ে ছোট।
Solution
প্রথম অংশ: \(b = A\hat{x} + e\), আর \(e \perp A\hat{x}\) (residual column space-এর সবার সাথে লম্ব):
দ্বিতীয় অংশ: কোণের cosine:
যেকোনো প্রার্থী \(Ax\)-এর জন্য (একই হিসাবের প্রথম ধাপে \((Ax)^Tb = (Ax)^T(A\hat x)\) ব্যবহার করে, Cauchy–Schwarz দিয়ে):
Cosine সবচেয়ে বড় মানে কোণ সবচেয়ে ছোট ∎ — least squares শুধু দূরত্বই নয়, কোণও minimize করে। ছায়ার সাথে মূল জিনিসের কোণই তো সবচেয়ে কম হওয়ার কথা — ছবিটা কল্পনা করো।
Problem 8. Numerical পরীক্ষা (VMLS 12.10-এর আদলে): random \(20\times5\) matrix \(A\) ও random \(b\) বানিয়ে \(\hat{x}\) বের করো; তারপর ৩টা random দিকে \(\hat{x}\) নাড়িয়ে দেখাও প্রতিবার \(\|Ax - b\|^2\) বাড়ে। কোড লেখো।
Solution
import numpy as np
np.random.seed(42)
A = np.random.randn(20, 5)
b = np.random.randn(20)
x_hat, *_ = np.linalg.lstsq(A, b, rcond=None)
best = np.sum((A @ x_hat - b)**2)
print(f"optimal SSE = {best:.6f}")
for k in range(3):
d = np.random.randn(5) * 0.1 # ছোট্ট ধাক্কা
val = np.sum((A @ (x_hat + d) - b)**2)
print(f"try {k+1}: SSE = {val:.6f} (> optimal? {val > best})")
Seed 42-এ output-এ তিনবারই True আসবে — যেদিকেই নাড়াও, পেয়ালার তলা থেকে ওঠা ছাড়া উপায় নেই।
কেন গ্যারান্টিড: Intuition-এর পথ ৩-এর অভেদ:
সমান হতে পারতো কেবল \(Ad = 0\) হলে; independent column-এ \(d \neq 0 \Rightarrow Ad \neq 0\) — অর্থাৎ কঠোরভাবে বড়।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "\(\hat{x}\) পেয়েছি মানে \(A\hat{x} = b\) solve করেছি" | না! সাধারণত \(A\hat{x} \neq b\) — \(\hat{x}\) শুধু ভুল minimize করে। "\(\hat{x}\) solves \(Ax=b\) in the least squares sense" — এই বিভ্রান্তিকর বাক্য দেখলেই সতর্ক হও (VMLS নিজেই সাবধান করেছে)। |
| "\(\hat{x} = A^{-1}b\) লিখলেই হয়" | Tall matrix-এর inverse নেই। সঠিক বস্তু pseudo-inverse \(A^\dagger = (A^TA)^{-1}A^T\) — এবং \(A\) square-invertible হলে সে-ই \(A^{-1}\)-এ নেমে আসে। |
| "Residual মানে \(b\)-এর সাথে লম্ব" | না — \(e\) লম্ব column space-এর সাথে (\(A^Te=0\)); \(b\)-এর সাথে নয় (\(b^Te = \|e\|^2 \neq 0\), Problem 3)। কে কার সাথে লম্ব — ছবিটা এঁকে নাও। |
| "\((A^TA)^{-1}A^T = A^{-1}(A^T)^{-1}A^T = A^{-1}\) — সরল করা যায়" | \((AB)^{-1} = B^{-1}A^{-1}\) শুধু দুটোই square-invertible হলে খাটে; tall \(A\)-এর বেলায় \(A^{-1}\) অস্তিত্বহীন — ভাঙা যাবে না। |
| "Numerically-ও normal equations-ই শ্রেষ্ঠ পথ" | ছোট, ভালো-condition সমস্যায় ঠিক আছে; কিন্তু \(A^TA\) বানালে condition number বর্গ হয়ে যায় — প্রায়-dependent column-এ উত্তর ভেসে যায়। বাস্তবে QR/lstsq (Part VIII-এ গভীরে)। |
| "Column dependent হলেও সূত্র চলবে" | তখন \(A^TA\) singular — inverse নেই, সমাধান অনন্ত। চিকিৎসা: feature বাদ দাও, বা regularization (Part VII), বা SVD-র pseudo-inverse (Part VI)। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| সমস্যা | \(\min_x \|Ax-b\|^2\) (\(A\) tall) | ঘড়ি তিনটা, সময় একটা |
| Normal equations | \(A^TA\hat{x} = A^Tb\) | residual \(\perp\) প্রতিটা column |
| সমাধান | \(\hat{x} = (A^TA)^{-1}A^Tb = A^\dagger b\) | pseudo-inverse |
| ছায়া | \(p = A\hat{x} = Pb\), \(P = A(A^TA)^{-1}A^T\) | \(b\)-এর ছায়া column space-এ |
| Residual | \(e = b - p \in N(A^T)\), \(\|b\|^2 = \|p\|^2 + \|e\|^2\) | ভুল থাকে লম্ব-জগতে |
| QR পথ | \(R\hat{x} = Q^Tb\) (back substitution) | stable, বাস্তবের রাস্তা |
| বিশেষ কেস | \(A=\mathbf{1}\): \(\hat{x} =\) গড়; \(A=Q\): \(\hat{x} = Q^Tb\) | গড়ও একটা ছায়া |
পরের chapter-এর সেতু: যন্ত্র তৈরি — এবার তাকে ছেড়ে দেবো সত্যিকারের ডেটার মাঠে। Feature সাজিয়ে matrix বানানো, straight line থেকে polynomial, "ভালো fit" বনাম "মুখস্থ fit" (overfitting!), আর train/validation-এর সততা-পরীক্ষা — Chapter 5.5: Least Squares Data Fitting — Part V-এর ফাইনাল।
📓 Notebook Project¶
notebooks/part-05/ch04-project.ipynb — normal equations, QR আর np.linalg.lstsq — তিন পথে least squares scratch-এ বানিয়ে মিলিয়ে দেখা; projection matrix-এর ধর্ম (\(P^2=P\), \(P^T=P\)) যাচাই; আর GPS-ধাঁচের একটা ছোট positioning সমস্যা সমাধান।