Chapter 6.3 — Diagonalization (ডায়াগোনালাইজেশন — matrix-কে সহজ রূপে দেখা)¶
আগের chapter-এ আমরা matrix-এর "বিশেষ দিক"গুলো খুঁজে পেয়েছি — eigenvector, যে দিক \(A\)-এর ধাক্কায় ঘোরে না, শুধু লম্বা-খাটো হয়। এবার সেই আবিষ্কারের পুরস্কার নেওয়ার পালা। যদি এমন eigenvector যথেষ্ট সংখ্যায় থাকে যে তারা মিলে একটা basis বানিয়ে ফেলে, তাহলে সেই basis-এর চশমা পরলেই ভয়ঙ্কর-দেখতে \(A\) হয়ে যায় নিরীহ একটা diagonal matrix — শুধু axis বরাবর stretch, আর কিচ্ছু না। এক লাইনের সূত্র \(A = PDP^{-1}\), কিন্তু তার ভেতরে লুকিয়ে আছে Fibonacci-র হাজার বছরের ধাঁধার এক-লাইনের সমাধান, Google-এর PageRank-এর ইঞ্জিন, আর differential equation-এর জগতের মাস্টার-কি। এই chapter-টা তাই পুরো Part VI-এর কেন্দ্রবিন্দু।
🎯 এই chapter-এ যা শিখবে¶
- Eigenbasis(আইগেনবেসিস) — eigenvector দিয়ে বানানো basis — সেই চশমায় linear transformation-এর matrix diagonal হয়ে যায়
- Diagonalization(ডায়াগোনালাইজেশন) \(A = PDP^{-1}\) নিজ হাতে construct করা: \(P\)-এর column = eigenvectors, \(D\)-এর diagonal = eigenvalues
- কোন matrix diagonalizable, কোনটা নয় — \(n\)টা independent eigenvector-এর শর্ত, আর Defective(ডিফেক্টিভ) matrix-এর (যেমন shear) দুঃখের গল্প
- Matrix power-এর জাদু-শর্টকাট \(A^k = PD^kP^{-1}\) — Fibonacci-র closed form আর Markov chain-এর Steady State(স্টেডি স্টেট) বের করা
- Similar Matrices(সিমিলার ম্যাট্রিসেস) — একই transformation, ভিন্ন চশমা — কেন তাদের eigenvalue, trace, determinant হুবহু এক
🖼️ এক ছবিতে মূল idea¶
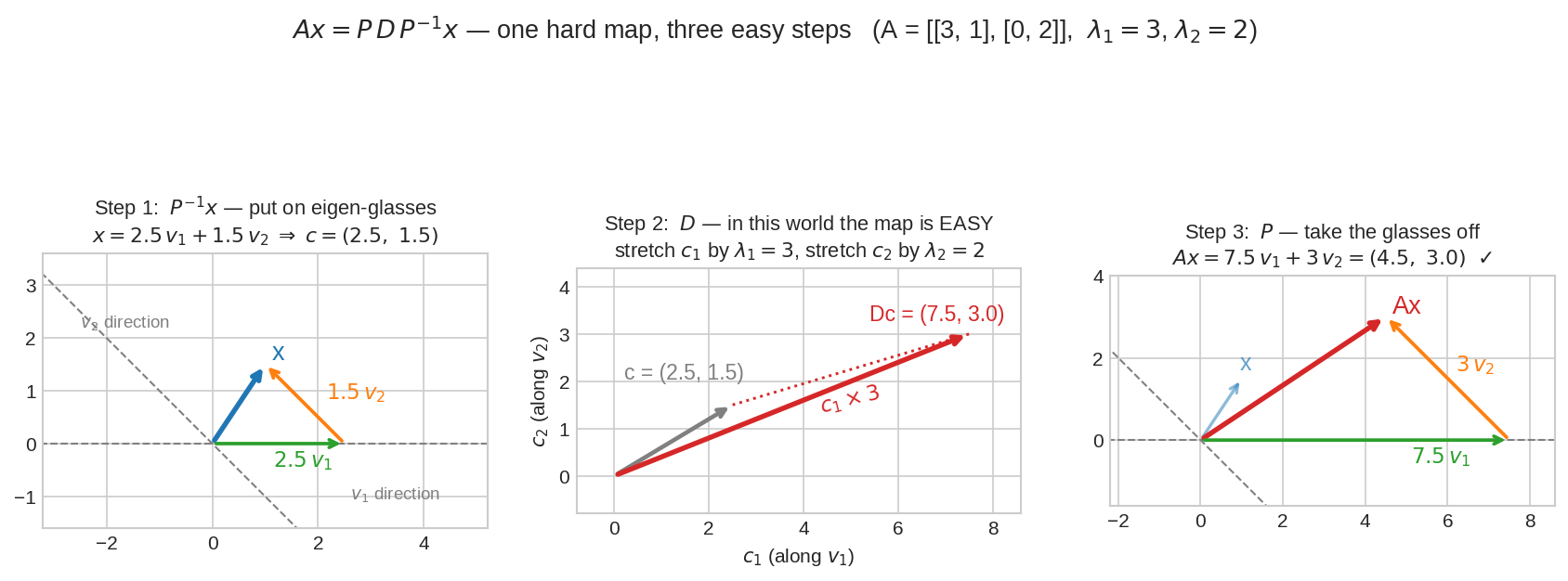
এটাই diagonalization-এর সম্পূর্ণ গল্প: \(Ax\) হিসাব করা মানে তিনটা সহজ ধাপ। ধাপ ১ (\(P^{-1}\)): \(x\)-কে eigenvector-এর ভাষায় পড়ো — "\(v_1\) বরাবর \(2.5\), \(v_2\) বরাবর \(1.5\)"। ধাপ ২ (\(D\)): এই জগতে \(A\)-এর কাজ শুধুই stretch — প্রথম সংখ্যা \(\times 3\), দ্বিতীয়টা \(\times 2\)। ধাপ ৩ (\(P\)): চশমা খুলে standard ভাষায় ফেরত এসো — পেয়ে গেলে \(Ax\)। জটিল matrix, তিনটা সরল ধাপ।
১. কি? (What)¶
দৈনন্দিন analogy: সঠিক চশমা পরলে ঝাপসা জিনিস পরিষ্কার হয়¶
Part IV-এর Chapter 4.3-এ আমরা শিখেছিলাম basis মানে ঠিকানা-ব্যবস্থা — একই vector-কে ভিন্ন ভিন্ন basis-এ ভিন্ন ভিন্ন coordinate দিয়ে লেখা যায়, যেমন একই জায়গার ঠিকানা রাস্তার নামে-ও লেখা যায়, GPS coordinate-এও। আর ভিন্ন basis মানে জগৎটাকে দেখার ভিন্ন চশমা।
এবার ভাবো: চোখের ডাক্তারের কাছে গেছো। একই অক্ষর-চার্ট — কিন্তু ভুল চশমায় সব ঝাপসা, ঘোলাটে, জট পাকানো; ঠিক power-এর চশমা পরামাত্র সব ঝকঝকে। Matrix-এর জগতেও ব্যাপারটা হুবহু তাই: একই linear transformation standard basis-এর চশমায় দেখায় জটিল (ঘোরায়, শিয়ার করে, টানে — সব একসাথে), কিন্তু ঠিক চশমাটা পরলে দেখা যায় সে আসলে শুধু কয়েকটা দিক বরাবর stretch করছে। আর কোনটা সেই "ঠিক চশমা"? আগের chapter-ই উত্তর দিয়ে রেখেছে — eigenvector-দের বানানো basis।
Change of basis — এক মিনিটের recap¶
ধরো নতুন basis \(\{v_1, v_2, \dots, v_n\}\), আর \(P\) হলো সেই matrix যার column গুলো এই নতুন basis vector (standard ভাষায় লেখা):
তাহলে নতুন-ভাষার coordinate \(c\) থেকে standard ভাষায় ফেরা: \(x = Pc\) (কারণ \(x = c_1v_1 + \cdots + c_nv_n\) — column-দের combination, Part III-এর সেই চিরচেনা ছবি)। আর উল্টো দিক, standard থেকে নতুন ভাষায়: \(c = P^{-1}x\)। মনে রাখার সূত্র:
- \(P\) = অনুবাদক, নতুন ভাষা \(\to\) standard ভাষা
- \(P^{-1}\) = উল্টো অনুবাদক, standard \(\to\) নতুন ভাষা
এখন প্রশ্ন: transformation \(A\) (standard চশমায় লেখা) নতুন চশমায় কেমন দেখায়? নতুন-ভাষার input \(c\)-কে আগে standard-এ নাও (\(Pc\)), তারপর \(A\) চালাও (\(APc\)), তারপর ফলাফলকে আবার নতুন ভাষায় ফেরত আনো (\(P^{-1}APc\))। অর্থাৎ নতুন চশমায় transformation-এর matrix:
সংজ্ঞা¶
Diagonalizable(ডায়াগোনালাইজেবল): \(n \times n\) matrix \(A\)-কে diagonalizable বলা হয় যদি এমন invertible matrix \(P\) আর Diagonal Matrix(ডায়াগোনাল ম্যাট্রিক্স) \(D\) পাওয়া যায় যে
কেন্দ্রীয় উপপাদ্য (Guest-এর Theorem 13.1.1-এর আদলে): \(A\) diagonalizable ⟺ \(A\)-এর \(n\)টা linearly independent eigenvector আছে, অর্থাৎ eigenvector দিয়ে পুরো \(\mathbb{R}^n\)-এর একটা basis (eigenbasis) বানানো যায়। আর তখন —
- \(P\)-এর column = সেই eigenvector-গুলো
- \(D\)-এর diagonal = সংশ্লিষ্ট eigenvalue-গুলো, একই order-এ
খেয়াল করো সংজ্ঞাটা আসলে change of basis-এরই বিশেষ কেস: \(D = P^{-1}AP\) মানে "eigenbasis-এর চশমায় \(A\)-এর চেহারা \(D\)" — আর diagonal matrix মানেই শুধু axis-বরাবর stretch। Diagonalization = ঠিক চশমা খুঁজে পাওয়া।
২. দেখতে কেমন?¶
দৃশ্য ১: একই transformation, দুই চশমা¶
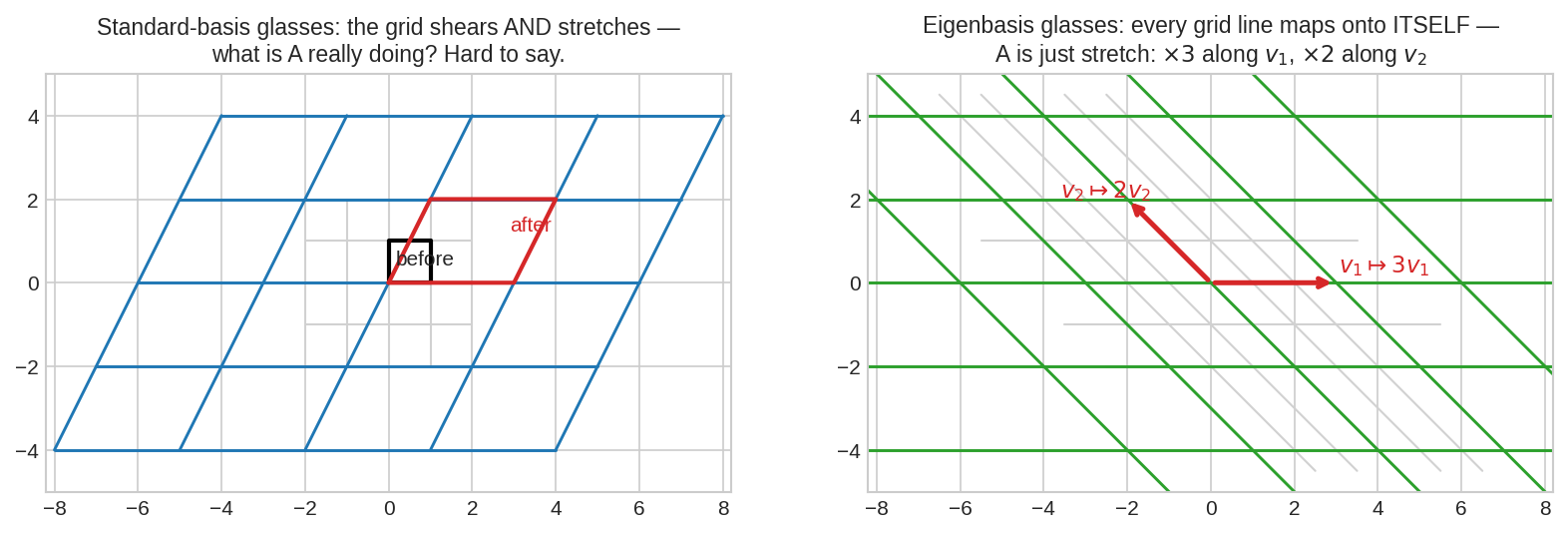
বাঁয়ে standard চশমা: \(A = \begin{bmatrix}3&1\\0&2\end{bmatrix}\)-এর ধাক্কায় বর্গাকার grid শিয়ার-ও খায়, stretch-ও খায় — কালো বর্গটা লাল parallelogram হয়ে যায়, \(A\) আসলে কী করছে বোঝা কঠিন। ডানে eigenbasis চশমা: grid-এর দাগগুলো \(v_1 = (1,0)\) আর \(v_2 = (-1,1)\) বরাবর আঁকা — এবার প্রতিটা দাগ নিজের ওপরেই যায়, শুধু \(v_1\) বরাবর \(\times 3\) আর \(v_2\) বরাবর \(\times 2\) টান। একই \(A\), কিন্তু দ্বিতীয় ছবিতে তার চরিত্র জলের মতো পরিষ্কার।
দৃশ্য ২: যখন চশমাই বানানো যায় না — defective matrix¶
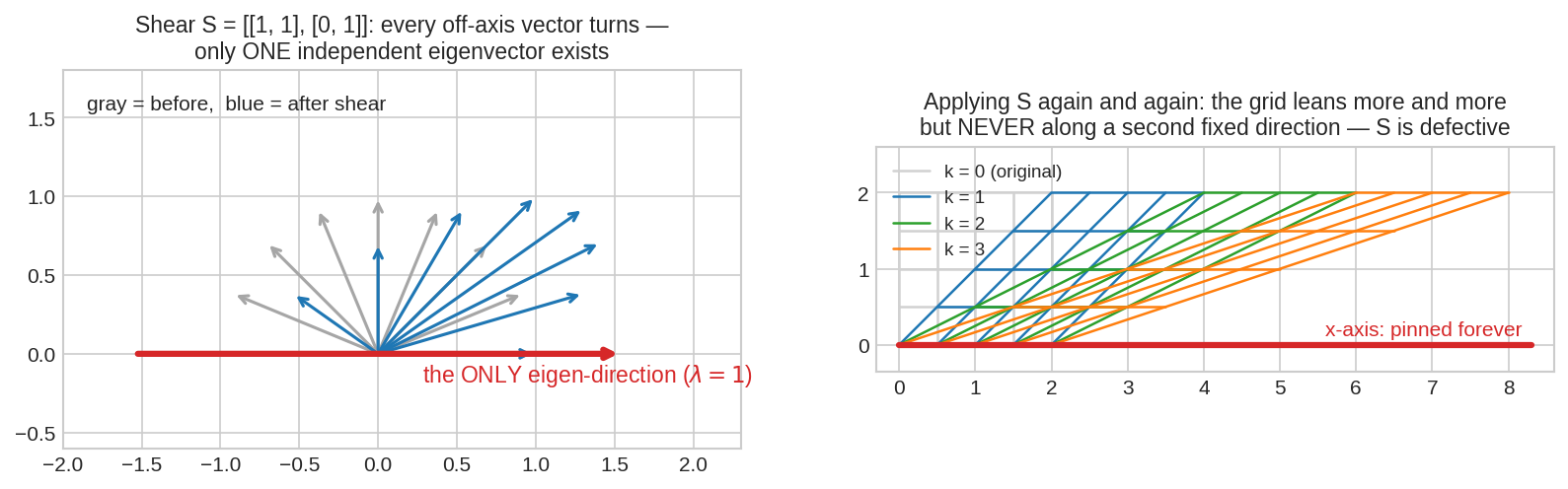
Shear matrix \(S = \begin{bmatrix}1&1\\0&1\end{bmatrix}\)-এর করুণ কাহিনি। বাঁয়ে: ধূসর vector-গুলোর প্রত্যেকে shear-এর ধাক্কায় ঘুরে যায় (নীল) — ঘোরে না কেবল \(x\)-axis-এর ওপরেরগুলো। eigenvalue \(\lambda = 1\) দুইবার (double root), কিন্তু eigenvector-এর দিক মাত্র একটা — দুই dimension-এর basis বানাতে দুটো independent দিক লাগে, আছে একটা। ডানে: বারবার shear করলে grid ক্রমেই হেলে পড়ে কিন্তু কখনোই "শুধু stretch"-এ পরিণত হয় না। এরকম eigenvector-ঘাটতি matrix-কে বলে defective — এদের diagonalize করা অসম্ভব।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- জনসংখ্যা/অর্থনীতির dynamics: "প্রতি বছর শহরের ৯০% থেকে যায়, গ্রামের ৩০% শহরে আসে" — ৫০ বছর পরে কী হবে? উত্তর \(M^{50}x_0\), আর \(M^{50}\) হাতে গুণে বের করা দুঃস্বপ্ন; diagonalization-এ এক লাইনে।
- Fibonacci ও যেকোনো recurrence: \(F_{k+1} = F_k + F_{k-1}\)-এর মতো ধাপে-ধাপে নিয়মকে matrix power বানিয়ে closed form বের করা — \(k\)-তম পদ সরাসরি, লুপ ছাড়া (Worked Example 2)।
- Differential equations: \(\frac{dx}{dt} = Ax\)-এর সমাধান \(x(t) = e^{At}x(0)\) — আর Matrix Exponential(ম্যাট্রিক্স এক্সপোনেনশিয়াল) \(e^{At}\) হিসাব করার একমাত্র সভ্য পথ diagonalization: \(e^{At} = Pe^{Dt}P^{-1}\), যেখানে \(e^{Dt}\) মানে diagonal-এ শুধু \(e^{\lambda_i t}\) বসানো। (Part VII-এর Chapter 7.5-এ পুরো গল্প — এখানে শুধু trailer।)
- কম্পন ও অনুরণন (vibration): সেতু বা building-এর দুলুনির "স্বাভাবিক mode"গুলো আসলে একটা matrix-এর eigenvector; প্রতিটা mode নিজের eigenvalue-র ছন্দে দোলে — diagonalization জটিল কম্পনকে স্বাধীন সরল দোলনায় ভেঙে দেয়।
Data Science / ML-এ:
- Markov chain, PageRank: Google-এর PageRank মূলত একটা বিশাল Markov Matrix(মার্কভ ম্যাট্রিক্স)-এর \(\lambda = 1\)-এর eigenvector; আর "power iteration" যে কাজ করে তার প্রমাণটাই \(M^k = PD^kP^{-1}\) — dominant eigenvalue বাকিদের গিলে ফেলে (Part VII, Chapter 7.4)।
- Recommender-এর low-rank চিন্তার প্রস্তুতি: diagonalization মানে \(A\)-কে সরল টুকরোয় ভাঙা — \(A = \sum_i \lambda_i (\text{rank-1 টুকরা})\)। "বড় matrix = অল্প কয়েকটা গুরুত্বপূর্ণ দিকের যোগফল" — এই চিন্তাই SVD (Chapter 6.6) হয়ে Netflix-ধাঁচের recommender-এ পৌঁছাবে।
- PCA-র ভিত্তি: data-র covariance matrix diagonalize করা মানেই "কোন দিকে data সবচেয়ে ছড়ানো" বের করা — Chapter 6.7-এর পুরোটা এর ওপর দাঁড়িয়ে।
- Optimization-এর চোখ: loss surface-এর Hessian-এর eigenvalue বলে দেয় পেয়ালা কোন দিকে খাড়া, কোন দিকে চ্যাপ্টা — gradient descent-এর গতি এই spectrum-ই নিয়ন্ত্রণ করে (Chapter 6.5-এ আরো)।
৪. Properties¶
Property 1 — Construction: \(AP = PD\) (মনে রাখার আসল রূপ)¶
\(A = PDP^{-1}\) মুখস্থ করার দরকার নেই; দুই পাশে ডান দিক থেকে \(P\) গুণ করো:
Column ধরে ধরে পড়ো — বাঁ পাশের \(j\)-তম column হলো \(Av_j\), ডান পাশের \(j\)-তম column হলো \(\lambda_j v_j\) (diagonal matrix ডান থেকে গুণ মানে column-গুলোকে scale করা, Part III মনে করো)। অর্থাৎ \(AP = PD\) আসলে \(n\)টা সমীকরণের বান্ডিল:
— হুবহু eigenvector-এর সংজ্ঞা! তাই "P-এর column-এ eigenvector, D-তে eigenvalue" কোনো জাদু না, definitions-এর প্যাকেজিং মাত্র। সাবধান: \(D\)-এর \(\lambda_j\) আর \(P\)-এর \(v_j\)-এর order মিলতেই হবে — \(j\)-তম column-এর eigenvalue \(j\)-তম ঘরে।
Property 2 — Diagonalizability-র শর্ত¶
(\(\Rightarrow\): \(P\) invertible মানে তার column-রা independent, আর Property 1 বলছে column-রা eigenvector। \(\Leftarrow\): independent eigenvector-দের column বানিয়ে \(P\) সাজাও — invertible, আর \(AP = PD\) এমনিই সত্য।) এর সবচেয়ে কাজের করোলারি:
কারণ ভিন্ন eigenvalue-এর eigenvector-রা আপনাআপনি independent (প্রমাণ Intuition-এ)। উল্টোটা কিন্তু সত্য নয় — \(I\)-এর eigenvalue \(1, 1\) (repeated), তবু সে diagonalizable (সে তো নিজেই diagonal!)। Repeated eigenvalue মানে "সাবধান, eigenvector গুনে দেখো" — অপরাধ প্রমাণ নয়।
Property 3 — Defective matrix: যাদের চশমা নেই¶
Repeated eigenvalue-এর বেলায় eigenvector-এর ঘাটতি হতে পারে। Shear \(S = \begin{bmatrix}1&1\\0&1\end{bmatrix}\): \(\det(S - \lambda I) = (1-\lambda)^2 = 0\), তাই \(\lambda = 1\) দুইবার। কিন্তু \((S - I)v = 0\) solve করলে \(\begin{bmatrix}0&1\\0&0\end{bmatrix}v = 0 \Rightarrow v_2 = 0\) — eigenvector শুধু \((t, 0)\), এক dimension-এর eigenspace। দুটো লাগবে, আছে একটা — \(S\) defective, diagonalize অসম্ভব (আরেকটা প্রমাণ Problem 2-এ)। ভাষায়: eigenvalue-টার algebraic গুরুত্ব ২ কিন্তু geometric সরবরাহ ১ — চাহিদা-জোগানের এই ফারাকই defectiveness।
Property 4 — Matrix power-এর শর্টকাট: \(A^k = PD^kP^{-1}\)¶
Diagonalization-এর সবচেয়ে নগদ পুরস্কার। \(A^2\) লিখে দেখো — ভেতরে টেলিস্কোপের মতো সব কেটে যায়:
একই যুক্তি বারবার:
\(k\)টা matrix multiplication-এর জায়গায় \(n\)টা সংখ্যার power — এই এক লাইনই Fibonacci closed form, Markov chain-এর ভবিষ্যৎ, সব খুলে দেয়। আর \(k\) বড় হলে কী ঘটে সেটার ছবিটাও পরিষ্কার: যার \(|\lambda|\) সবচেয়ে বড় (dominant eigenvalue), \(D^k\)-তে তার term বাকিদের তুলনায় পাহাড় হয়ে দাঁড়ায় — \(A^k x\) প্রায় পুরোটাই সেই eigenvector-এর দিকে হেলে পড়ে।
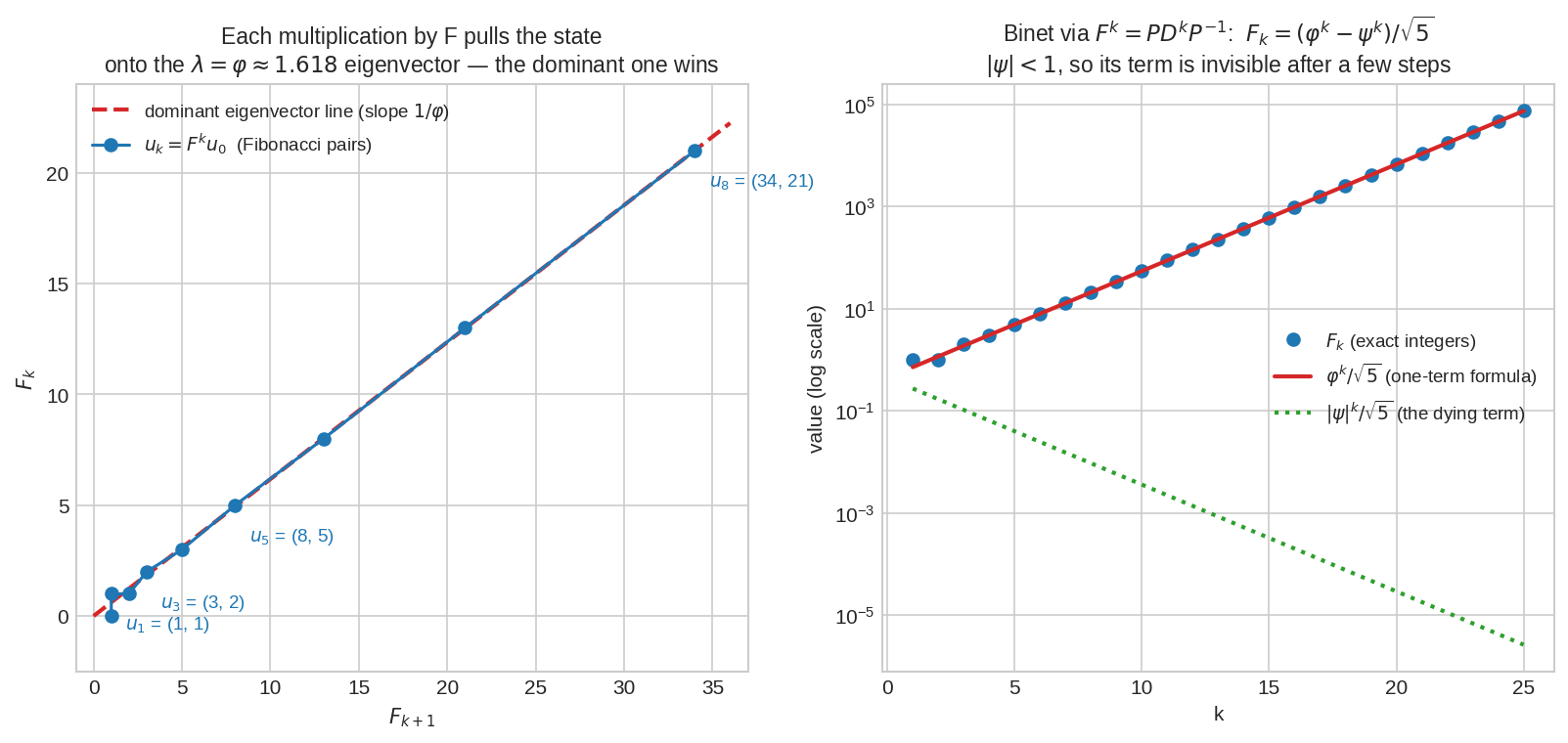
বাঁয়ে: Fibonacci-র state \(u_k = (F_{k+1}, F_k)\) প্রতি ধাপে matrix \(F\)-এর গুণ খেয়ে দ্রুত dominant eigenvector-এর লাইনে (\(\text{slope} = 1/\varphi\)) আটকে যায়। ডানে: Binet-এর সূত্রের দুই term — \(\varphi^k/\sqrt5\) (লাল) বেড়ে চলে আর exact Fibonacci-র (নীল বিন্দু) গা ঘেঁষে থাকে; \(|\psi|^k/\sqrt5\) (সবুজ) কয়েক ধাপেই অদৃশ্য। বড় \(k\)-তে জেতে কেবল বড় \(|\lambda|\)।
Property 5 — Similar matrices: একই আত্মা, ভিন্ন পোশাক¶
\(B = P^{-1}AP\) (কোনো invertible \(P\)-এর জন্য) হলে \(A\) আর \(B\)-কে বলে similar। মানে: দুটো matrix আসলে একই linear transformation, শুধু ভিন্ন basis-এর চশমায় লেখা। চশমা বদলালে সংখ্যাগুলো বদলায়, কিন্তু transformation-এর "আত্মা" বদলায় না — তাই তার জন্মগত পরিচয়গুলো অক্ষত থাকে:
(প্রমাণ Problem 4-এ — এক লাইনের determinant-কারসাজি।) Diagonalizable matrix মানে তাহলে: diagonal matrix-এর সাথে similar — তার সবচেয়ে সাদামাটা পোশাকটাই \(D\)। আর এই invariance উল্টো দিকে detective-এর কাজও করে: দুটো matrix-এর trace বা determinant না মিললেই বলে দেওয়া যায় — এরা এক transformation নয়।
Property 6 — শুধু power না, যেকোনো function: \(f(A) = P\,f(D)\,P^{-1}\)¶
\(A^k\)-এর যুক্তিটা polynomial হয়ে exponential পর্যন্ত গড়ায়:
আর \(e^D\) মানে diagonal-এ শুধু \(e^{\lambda_i}\) — অসীম series মুহূর্তে পোষ মানে। Differential equation \(\frac{dx}{dt} = Ax\)-এর সমাধান তাই eigenvalue-দের হাতে: \(\lambda_i > 0\) হলে সেই mode বিস্ফোরিত হয়, \(\lambda_i < 0\) হলে মিলিয়ে যায়। Part VII-এ ফিরবো — আপাতত জেনে রাখো, diagonalization মানে matrix-এর ওপর calculus করার লাইসেন্স।
৫. Intuition — কেন সত্য?¶
কেন eigenbasis-এ matrix diagonal? (চশমার গল্পটা গণিতে)¶
Basis-এ matrix লেখার নিয়মটা মনে করো (Part IV): \(j\)-তম column = "\(j\)-তম basis vector-এর ওপর transformation কী করে, সেটা ওই basis-এরই ভাষায়"। এখন basis-টা যদি eigenvector-দের হয়? \(L(v_j) = \lambda_j v_j\) — অর্থাৎ \(j\)-তম basis vector-এর ভাগ্যে জোটে শুধু "নিজেরই \(\lambda_j\) গুণ"। eigenbasis-এর ভাষায় এই output-এর coordinate: \(j\)-তম ঘরে \(\lambda_j\), বাকি সব শূন্য। প্রতিটা column-এ একটাই nonzero সংখ্যা, diagonal ঘর বরাবর —
ব্যস। Diagonal হওয়া কোনো কাকতালীয় হিসাব নয় — "eigenvector নিজের দিক ছাড়ে না"-র সরাসরি অনুবাদ। আর উল্টোটাও ফাউ পেয়ে গেলে: কোনো basis-এ matrix diagonal মানেই সেই basis-এর প্রত্যেকে eigenvector।
কেন distinct eigenvalue ⟹ independent eigenvector?¶
দুটো দিয়ে শুরু করি: \(Av_1 = \lambda_1 v_1\), \(Av_2 = \lambda_2 v_2\), \(\lambda_1 \neq \lambda_2\)। ধরো (প্রমাণের খাতিরে) তারা dependent: \(v_2 = cv_1\), \(c \neq 0\)। দুই পাশে \(A\) চালাও:
তাহলে \((\lambda_2 - \lambda_1)v_2 = 0\); কিন্তু \(v_2 \neq 0\) (eigenvector কখনো শূন্য না) — বাধ্য হয়ে \(\lambda_1 = \lambda_2\), যেটা আমাদের ধরে নেওয়ার সরাসরি বিরোধী। অতএব dependent হতে পারে না ∎। (\(n\)টার বেলাতেও একই আত্মা: dependence relation-এর ওপর \(A\) চালিয়ে চালিয়ে একে একে সবাইকে ঝরিয়ে দেওয়া যায়।) Intuition: ভিন্ন \(\lambda\) মানে ভিন্ন "stretch-এর স্বাক্ষর" — এক দিকের ওপর দুই রকম স্বাক্ষর বসতে পারে না।
কেন defective matrix-এর কোনো উপায়ই নেই?¶
মনে হতে পারে "shear-এর জন্য হয়তো আরো চালাক কোনো \(P\) আছে"। নেই — আর তার প্রমাণ similar matrices-এর invariance দিয়েই: \(S\) diagonalizable হলে \(S = PDP^{-1}\), আর \(D\)-এর diagonal-এ বসতো \(S\)-এরই eigenvalues, মানে \(1, 1\) — তাহলে \(D = I\), এবং \(S = PIP^{-1} = I\)। কিন্তু shear তো identity না! স্ববিরোধ ∎। Defectiveness চশমার দোষ না — transformation-টারই দুটো স্বাধীন "শান্ত দিক" নেই; যন্ত্র যত ভালোই হোক, যা নেই তা দেখানো যায় না।
৬. Code-এ কেমনে লিখে¶
import numpy as np
np.random.seed(42)
A = np.array([[3., 1.],
[0., 2.]])
# --- eigenvalue + eigenvector: এক কলেই P আর D-র উপকরণ ---
lam, P = np.linalg.eig(A) # lam = eigenvalues, P-র column = eigenvectors
D = np.diag(lam)
P_inv = np.linalg.inv(P)
print("eigenvalues:", lam) # [3. 2.]
print("A ফিরে পেলাম?", np.allclose(P @ D @ P_inv, A)) # True
# --- matrix power দুই পথে: A^20 ---
k = 20
Ak_direct = np.linalg.matrix_power(A, k) # ১৯টা matrix গুণ
Ak_diag = P @ np.diag(lam**k) @ P_inv # সংখ্যার power + ২টা গুণ
print("দুই পথ মিললো?", np.allclose(Ak_direct, Ak_diag)) # True
print("A^20 =\n", Ak_diag) # [[3.487e+09 3.486e+09]
# [0.000e+00 1.049e+06]] ← 3^20 আর 2^20!
# --- Fibonacci closed form ---
F = np.array([[1., 1.],
[1., 0.]])
lamF, PF = np.linalg.eig(F)
phi = lamF[0] # 1.6180... (সোনালি অনুপাত)
for n in [10, 20, 30]:
print(f"F_{n} =", round(phi**n / np.sqrt(5))) # 55, 6765, 832040 ✓
# --- Markov chain: steady state = lambda=1-এর eigenvector ---
M = np.array([[0.9, 0.3],
[0.1, 0.7]])
lamM, PM = np.linalg.eig(M)
v = PM[:, np.argmax(lamM)] # lambda = 1-এর eigenvector
print("steady state:", v / v.sum()) # [0.75 0.25]
Output ব্যাখ্যা:
np.linalg.eigএকসাথেই \(\lambda\)-দের আর \(P\) দিয়ে দেয় — column order আরlam-এর order আপনাআপনি মিলে থাকে (Property 1-এর সেই সাবধানতা library নিজেই সামলায়)।- \(A^{20}\)-এর diagonal-পথের উত্তর: \(\begin{bmatrix}3^{20} & 3^{20}-2^{20}\\ 0 & 2^{20}\end{bmatrix}\) — eigenvalue-রাই power খেয়েছে, matrix না। বড় \(k\) আর বড় matrix-এ এই পথ শুধু দ্রুতই না, roundoff-ও কম জমে।
- Fibonacci: \(\varphi^n/\sqrt5\)-কে round করলেই exact পূর্ণসংখ্যা — কারণ বাদ-পড়া term \(|\psi|^n/\sqrt5 < 0.5\) সবসময়।
- Markov-এর steady state \((0.75, 0.25)\) কোনো iteration ছাড়াই — শুধু \(\lambda = 1\)-এর eigenvector-কে normalize করা।
৭. Worked Examples¶
Example 1 — গোড়া থেকে diagonalize: \(A = \begin{bmatrix}4&1\\2&3\end{bmatrix}\)¶
ধাপ ১ — eigenvalues (Chapter 6.2-এর যন্ত্রে): \(\text{tr} = 7\), \(\det = 12 - 2 = 10\), তাই
দুটো distinct — Property 2 এখনই গ্যারান্টি দিচ্ছে: diagonalizable।
ধাপ ২ — eigenvectors:
\(\lambda_1 = 5\): \((A - 5I)v = \begin{bmatrix}-1&1\\2&-2\end{bmatrix}v = 0 \Rightarrow v_1 = (1, 1)\)
\(\lambda_2 = 2\): \((A - 2I)v = \begin{bmatrix}2&1\\2&1\end{bmatrix}v = 0 \Rightarrow v_2 = (1, -2)\)
ধাপ ৩ — \(P\), \(D\), \(P^{-1}\) সাজানো:
ধাপ ৪ — যাচাই (\(AP = PD\), সস্তা চেক): \(AP\)-এর column: \(Av_1 = (5,5) = 5v_1\) ✓, \(Av_2 = (2,-4) = 2v_2\) ✓।
বোনাস — \(A^k\) চিরকালের জন্য:
\(k=1\) বসিয়ে পরীক্ষা: \(\frac13\begin{bmatrix}12&3\\6&9\end{bmatrix} = \begin{bmatrix}4&1\\2&3\end{bmatrix}\) ✓ — একটা সূত্র, অনন্ত power।
Example 2 — Fibonacci-র closed form (এই chapter-এর মুকুট)¶
\(F_0 = 0, F_1 = 1, F_{k+1} = F_k + F_{k-1}\)। কৌশল: দুই-ধাপের স্মৃতিকে এক state vector-এ ভরো — \(u_k = (F_{k+1}, F_k)\):
ধাপ ১ — eigenvalues: \(\lambda^2 - \lambda - 1 = 0\) (trace \(1\), det \(-1\)):
ধাপ ২ — eigenvectors: \(F(\lambda, 1) = (\lambda + 1, \lambda) = (\lambda^2, \lambda) = \lambda(\lambda, 1)\) (মাঝে \(\lambda^2 = \lambda + 1\) ব্যবহার করলাম) — তাই \(v_\varphi = (\varphi, 1)\), \(v_\psi = (\psi, 1)\)।
ধাপ ৩ — \(u_0\)-কে eigenbasis-এ ভাঙো: \(P = \begin{bmatrix}\varphi&\psi\\1&1\end{bmatrix}\), \(\det P = \varphi - \psi = \sqrt5\), তাই \(P^{-1}u_0 = \frac{1}{\sqrt5}(1, -1)\), অর্থাৎ
ধাপ ৪ — power ছাড়ো (প্রতি eigenvector নিজের \(\lambda^k\) খায়):
দ্বিতীয় component পড়ো (\(v_\varphi, v_\psi\)-এর দ্বিতীয় entry দুটোই \(1\)):
— Binet-এর সূত্র, diagonalization থেকে চার ধাপে। \(|\psi| < 1\) বলে \(\psi^k\) চোখের পলকে মরে যায়: \(F_k = \text{round}(\varphi^k/\sqrt5)\), আর অনুপাত \(F_{k+1}/F_k \to \varphi\) — সূর্যমুখীর প্যাঁচ থেকে শিল্পকলার সোনালি অনুপাত, সবার উৎস এই dominant eigenvalue (fig03 আবার দেখো)।
Example 3 — Markov chain-এর long run: শহর বনাম গ্রাম¶
প্রতি বছর: শহরের বাসিন্দাদের \(90\%\) শহরেই থাকে (\(10\%\) গ্রামে যায়); গ্রামের \(30\%\) শহরে আসে (\(70\%\) থাকে)। State \(x_k = (\text{শহর-ভগ্নাংশ}, \text{গ্রাম-ভগ্নাংশ})\):
ধাপ ১ — eigenvalues: trace \(= 1.6\), \(\det = 0.63 - 0.03 = 0.6\), তাই \(\lambda^2 - 1.6\lambda + 0.6 = 0 \Rightarrow \lambda_1 = 1, \lambda_2 = 0.6\)। (Markov matrix-এর সবসময় \(\lambda = 1\) থাকে — Problem 6-এ কারণ।)
ধাপ ২ — eigenvectors: \(\lambda_1 = 1\): \(0.9a + 0.3b = a \Rightarrow a = 3b \Rightarrow v_1 = (0.75, 0.25)\) (যোগফল \(1\) বানিয়ে নিলাম)। \(\lambda_2 = 0.6\): \(v_2 = (1, -1)\)।
ধাপ ৩ — শুরুর অবস্থা ভাঙো: ধরো আজ \(20\%\) শহরে: \(x_0 = (0.2, 0.8) = c_1v_1 + c_2v_2\)। চালাকি: দুই পাশের component-যোগফল নাও — \(x_0\)-র যোগফল \(1\), \(v_1\)-এর \(1\), \(v_2\)-এর \(0\); তাই \(c_1 = 1\)! আর প্রথম component থেকে \(0.2 = 0.75 + c_2 \Rightarrow c_2 = -0.55\)।
ধাপ ৪ — ভবিষ্যৎ পড়ে ফেলো:
Steady state: যেখান থেকেই শুরু করো, শেষমেশ \(75\%\) শহরে — শুরুর স্মৃতি \((0.6)^k\) হারে মুছে যায় (১০ বছরে ভুল \(0.6^{10} \approx 0.6\%\)-এ নামে)।
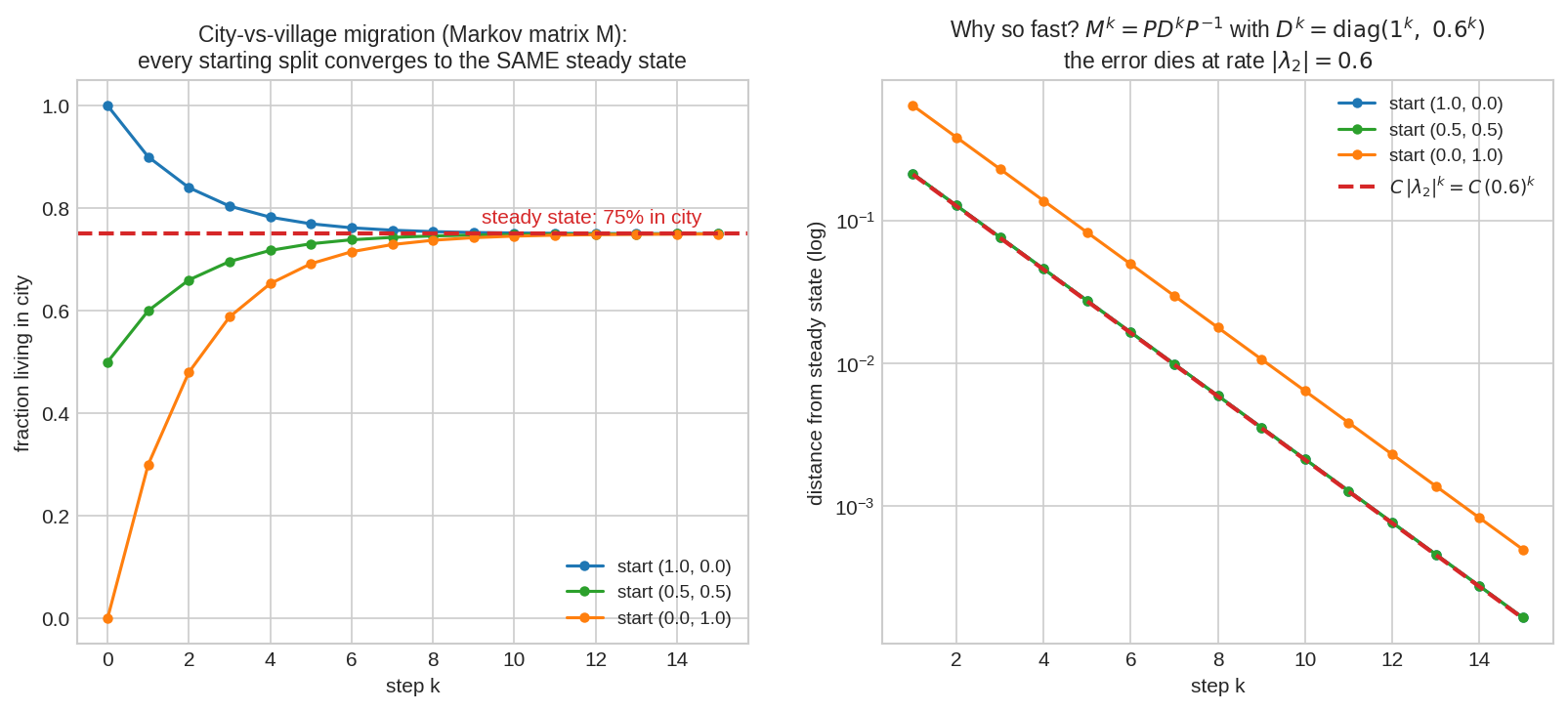
বাঁয়ে: তিনটা সম্পূর্ণ ভিন্ন শুরুর অবস্থা — সবাই একই steady state \((0.75, 0.25)\)-এ মিশে যায়। ডানে: log scale-এ ভুলগুলো সরলরেখা — মানে ক্ষয়ের হার exact geometric, ঠিক \(|\lambda_2|^k = (0.6)^k\); \(M^k = PD^kP^{-1}\)-এর সরাসরি ভবিষ্যদ্বাণী।
৮. Problems ও Solutions¶
Problem 1. \(A = \begin{bmatrix}2&1\\1&2\end{bmatrix}\) diagonalize করো, \(A^k\)-এর সূত্র বের করো, এবং দেখাও \(k \to \infty\)-তে \(\dfrac{A^k}{3^k} \to \dfrac12\begin{bmatrix}1&1\\1&1\end{bmatrix}\)। শেষ matrix-টা চেনা চেনা লাগে? (Part V-এর ভাষায় সে কী?)
Solution
Eigenvalues: trace \(4\), det \(3\): \(\lambda^2 - 4\lambda + 3 = 0 \Rightarrow \lambda = 3, 1\)। Distinct ⟹ diagonalizable।
Eigenvectors: \(\lambda = 3\): \((A-3I)v = 0 \Rightarrow v_1 = (1,1)\); \(\lambda = 1\): \(v_2 = (1,-1)\)।
(\(k=1\) চেক: \(\frac12\begin{bmatrix}4&2\\2&4\end{bmatrix} = A\) ✓)। এবার \(3^k\) দিয়ে ভাগ:
চেনা মুখ: এটা \(v_1 = (1,1)\)-এর লাইনের ওপর projection matrix (Part V: \(\frac{v_1v_1^T}{v_1^Tv_1}\))! বড় \(k\)-তে dominant eigenvalue জেতে — \(A^k\) (normalize করার পর) সবকিছুকে dominant eigenvector-এর দিকে ছুঁড়ে দেয়। এটাই power iteration-এর হৃৎপিণ্ড।
Problem 2. (Guest-এর Review Problem 7-এর আদলে) দেখাও \(J = \begin{bmatrix}\lambda&1\\0&\lambda\end{bmatrix}\) কখনোই diagonalizable না — দুইভাবে: (a) eigenvector গুনে, (b) similar-matrix যুক্তিতে।
Solution
(a) \(\det(J - \mu I) = (\lambda - \mu)^2 = 0\) — একমাত্র eigenvalue \(\mu = \lambda\), দুইবার। Eigenvector:
eigenspace \(= \{(t, 0)\}\) — মাত্র \(1\) dimension। \(2\times2\)-এর জন্য দরকার \(2\)টা independent eigenvector; নেই ⟹ diagonalizable নয় ∎
(b) ধরো \(J = PDP^{-1}\)। \(D\)-এর diagonal-এ \(J\)-এর eigenvalues বসবে (similar ⟹ same eigenvalues), অর্থাৎ \(D = \begin{bmatrix}\lambda&0\\0&\lambda\end{bmatrix} = \lambda I\)। তাহলে
কিন্তু \(J \neq \lambda I\) (কোণার ওই \(1\)টা!) — স্ববিরোধ ∎
মন্তব্য: এই \(J\)-ই Jordan block — প্রমাণিত হলো: repeated eigenvalue + কোণায় \(1\) = diagonalization-এর অতিক্রম-অযোগ্য দেয়াল। (ভালো খবর: এমন block দিয়েই যেকোনো matrix-এর "প্রায়-diagonal" রূপ বানানো যায় — Jordan form; সে graduate-স্তরের গল্প।)
Problem 3. Recurrence: \(x_{k+1} = x_k + 2x_{k-1}\), \(x_0 = 0\), \(x_1 = 1\)। Fibonacci-র কায়দায় closed form বের করো এবং \(x_2, x_3\) দিয়ে যাচাই করো।
Solution
State vector \(u_k = (x_{k+1}, x_k)\):
Eigenvalues: \(\lambda^2 - \lambda - 2 = 0 \Rightarrow (\lambda-2)(\lambda+1) = 0 \Rightarrow \lambda = 2, -1\)।
Eigenvectors: Fibonacci-র মতোই এই আকৃতির matrix-এ \(v_\lambda = (\lambda, 1)\): \(v_1 = (2,1)\), \(v_2 = (-1,1)\)।
\(u_0\) ভাঙা: \((1,0) = c_1(2,1) + c_2(-1,1)\)। দ্বিতীয় component: \(c_1 + c_2 = 0\); প্রথম: \(2c_1 - c_2 = 1 \Rightarrow 3c_1 = 1 \Rightarrow c_1 = \tfrac13, c_2 = -\tfrac13\)।
Power:
যাচাই: \(x_2 = \frac{4-1}{3} = 1\) (recurrence: \(x_1 + 2x_0 = 1\) ✓); \(x_3 = \frac{8+1}{3} = 3\) (recurrence: \(x_2 + 2x_1 = 3\) ✓)। বড় \(k\)-তে \(x_k \approx 2^k/3\) — আবারও dominant eigenvalue-এর রাজত্ব।
Problem 4. (Guest-এর Review Problem 4-এর আদলে) \(B = P^{-1}AP\) হলে প্রমাণ করো: (a) \(\det(B - \lambda I) = \det(A - \lambda I)\) — অতএব eigenvalues এক; (b) \(\det B = \det A\); (c) \(\text{tr}\,B = \text{tr}\,A\)। (সূত্র: \(\text{tr}(MN) = \text{tr}(NM)\)।)
Solution
(a) মূল চাল: \(\lambda I = P^{-1}(\lambda I)P\) — identity যেকোনো চশমায় identity। তাই
Determinant নাও (Chapter 6.1: গুণে ভাঙে, আর \(\det(P^{-1}) = 1/\det P\)):
Characteristic polynomial হুবহু এক ⟹ eigenvalues (multiplicity-সহ) এক।
(b) (a)-তে \(\lambda = 0\) বসাও: \(\det B = \det A\) ∎ (অথবা সরাসরি: \(\det(P^{-1}AP) = \frac{1}{\det P}\det A \det P\))।
(c) \(\text{tr}(B) = \text{tr}\big(P^{-1}(AP)\big) = \text{tr}\big((AP)P^{-1}\big) = \text{tr}(A)\) ∎
অর্থ: trace, det, eigenvalues — এরা transformation-এর জন্মদাগ; চশমা (basis) বদলালেও মোছে না। এ কারণেই Chapter 6.2-এর সেই সূত্র — \(\text{tr} = \sum\lambda_i\), \(\det = \prod\lambda_i\) — কোনো basis-এই ভাঙে না।
Problem 5. (Guest-এর Review Problem 6-এর আদলে) দেখাও similarity একটা equivalence relation: (a) \(A \sim A\); (b) \(A \sim B \Rightarrow B \sim A\); (c) \(A \sim B, B \sim C \Rightarrow A \sim C\)। তারপর দেখাও: \(B = P^{-1}AP\) আর \(v\) যদি \(A\)-এর eigenvector হয় (\(\lambda\)-সহ), তবে \(P^{-1}v\) হলো \(B\)-এর eigenvector, একই \(\lambda\)-তে।
Solution
(a) \(A = I^{-1}AI\) — চশমা না বদলালেও similar ✓
(b) \(B = P^{-1}AP \Rightarrow A = PBP^{-1} = (P^{-1})^{-1}B(P^{-1})\) — এবার চশমা \(P^{-1}\) ✓
(c) \(B = P^{-1}AP\), \(C = Q^{-1}BQ\) হলে
— দুই অনুবাদ পরপর চালানোও একটা অনুবাদ (\(PQ\) invertible, কারণ দুটোই invertible) ✓ ∎
Eigenvector-এর রূপান্তর:
(\(P^{-1}v \neq 0\), কারণ \(v \neq 0\) আর \(P^{-1}\) invertible।) পাঠ: similar matrices-এর eigenvalue এক কিন্তু eigenvector এক নয় — eigenvector-রাও চশমা বদলায়, নিয়মটা \(v \mapsto P^{-1}v\)। "Same transformation, ভিন্ন ভাষায় same দিকের ভিন্ন নাম।"
Problem 6. Markov matrix \(M = \begin{bmatrix}0.8 & 0.1\\ 0.2 & 0.9\end{bmatrix}\) (column-যোগফল \(1\))। (a) দেখাও \(\lambda = 1\) অবশ্যই একটা eigenvalue (সূত্র: \(M^T\)-এর কথা ভাবো); (b) diagonalize করো; (c) প্রমাণ করো যেকোনো probability vector \(x_0\) (উপাদান অঋণাত্মক, যোগফল \(1\)) থেকে শুরু করলে \(M^kx_0\) একই steady state-এ যায় — কোনটায়, কত দ্রুত?
Solution
(a) \(M\)-এর প্রতি column-এর যোগফল \(1\) মানে \(M^T\)-এর প্রতি row-এর যোগফল \(1\), অর্থাৎ \(M^T\mathbf{1} = \mathbf{1}\) (সব-এক vector)। তাহলে \(1\) হলো \(M^T\)-এর eigenvalue; আর \(\det(M - \lambda I) = \det(M^T - \lambda I)\) (Chapter 6.1: \(\det A = \det A^T\)) — তাই \(1\) \(M\)-এরও eigenvalue ∎
(b) trace \(= 1.7\), det \(= 0.72 - 0.02 = 0.7\): \(\lambda^2 - 1.7\lambda + 0.7 = 0 \Rightarrow \lambda = 1, 0.7\)। \(\lambda = 1\): \(0.8a + 0.1b = a \Rightarrow b = 2a \Rightarrow v_1 = \big(\tfrac13, \tfrac23\big)\) (যোগফল \(1\))। \(\lambda = 0.7\): \(0.8a + 0.1b = 0.7a \Rightarrow b = -a \Rightarrow v_2 = (1, -1)\)।
(c) \(x_0 = c_1v_1 + c_2v_2\) লেখো, দুই পাশের component-যোগফল নাও: \(v_1\)-এর যোগফল \(1\), \(v_2\)-এর \(0\), \(x_0\)-এর \(1\) — তাই \(c_1 = 1\), সবসময়! অতএব
শুরু যা-ই হোক, শেষ ঠিকানা \(v_1\); ভুল কমে geometric হারে \(|\lambda_2|^k = (0.7)^k\)। এটাই PageRank-এর গাণিতিক মেরুদণ্ড: ওয়েব-সার্ফার যেখান থেকেই ক্লিক শুরু করুক, দীর্ঘমেয়াদে প্রতিটা পাতায় কাটানো সময়ের ভগ্নাংশ একটাই — \(\lambda = 1\)-এর eigenvector, আর সেটাই পাতার rank (Part VII, Chapter 7.4)।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "সব square matrix-ই diagonalize করা যায়" | না — shear \(\begin{bmatrix}1&1\\0&1\end{bmatrix}\)-এর মতো defective matrix-এর eigenvector-ই যথেষ্ট নেই (Problem 2)। শর্তটা মনে রাখো: \(n\)টা independent eigenvector চাই। |
| "Repeated eigenvalue দেখলেই defective" | না! \(I\)-এর eigenvalue \(1,1\) — তবু সে diagonal-ই। Repeated eigenvalue মানে সতর্কবার্তা: eigenvector গুনে দেখো — ঘাটতি থাকতেও পারে, নাও পারে। |
| "\(A = PDP^{-1}\) আর \(A = P^{-1}DP\) — একই কথা" | Convention গুলিয়ো না। \(D = P^{-1}AP\) (চশমা পরা) ⟺ \(A = PDP^{-1}\) (চশমা খোলা)। \(P\)-এর column = eigenvector হলে সঠিক রূপ \(A = PDP^{-1}\) — মনে না থাকলে \(AP = PD\) থেকে আবার বানাও। |
| "\(P\)-এর column-রা যেকোনো order-এ সাজানো যায়, \(D\) একই থাকবে" | Order জোড়ায় জোড়ায় বাঁধা: \(P\)-এর \(j\)-তম column-এর eigenvalue-ই \(D\)-এর \(j\)-তম ঘরে বসবে। Column ওলটপালট করলে \(D\)-ও একই ভঙ্গিতে ওলটপালট হবে। |
| "Diagonalizable মানেই invertible (বা উল্টোটা)" | দুটো সম্পূর্ণ স্বাধীন ব্যাপার! \(\begin{bmatrix}1&0\\0&0\end{bmatrix}\) diagonalizable কিন্তু singular (\(\lambda = 0\) আছে); shear invertible কিন্তু non-diagonalizable। Invertibility দেখে \(\lambda = 0\) আছে কি না; diagonalizability দেখে eigenvector যথেষ্ট কি না। |
| "Similar matrices-এর eigenvector-ও same" | Eigenvalue same, eigenvector না — সে বদলায় \(v \mapsto P^{-1}v\) নিয়মে (Problem 5)। ভিন্ন চশমায় একই দিকের নামই তো ভিন্ন হবে! |
| "\(A^k\) মানে প্রতিটা entry-র \(k\)-তম power" | কখনোই না — \(A^k\) হলো \(k\) বার matrix গুণ। Entry-wise power শুধু তখনই মিলে যায় যখন \(A\) diagonal — আর সেটাই তো \(A^k = PD^kP^{-1}\) সূত্রের পুরো মজা: \(D\)-তে গিয়েই কেবল power সস্তা হয়। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Diagonalization | \(A = PDP^{-1}\); \(P\)-এর column = eigenvectors, \(D\) = eigenvalues | ঠিক চশমায় সব ঝকঝকে |
| আসল রূপ | \(AP = PD \iff Av_j = \lambda_jv_j\) (প্রতি column) | সংজ্ঞারই প্যাকেজিং |
| কখন সম্ভব | \(n\)টা independent eigenvector ⟺ eigenbasis আছে | distinct \(\lambda\) ⟹ হ্যাঁ (উল্টো নয়) |
| Defective | eigenvector-ঘাটতি — diagonalize অসম্ভব | shear: এক \(\lambda\), এক দিক |
| Matrix power | \(A^k = PD^kP^{-1}\), \(D^k = \text{diag}(\lambda_i^k)\) | power খায় সংখ্যা, matrix না |
| বড় \(k\)-র ভাগ্য | dominant \(\vert \lambda\vert\) জেতে | Fibonacci \(\to \varphi\); Markov \(\to\) steady state |
| Similar | \(B = P^{-1}AP\): same \(\lambda\), trace, det | একই আত্মা, ভিন্ন পোশাক |
| Function of matrix | \(f(A) = P\,f(D)\,P^{-1}\); যেমন \(e^{At} = Pe^{Dt}P^{-1}\) | ODE-র মাস্টার-কি (Part VII) |
পরের chapter-এর সেতু: এই chapter-এ \(P^{-1}\) বের করতে হয়েছে কষ্ট করে — আর fig01-এর eigenbasis-টা ছিল হেলানো, লম্ব না। এখন ভাবো, যদি eigenvector-রা নিজে থেকেই পরস্পর লম্ব হতো? তাহলে \(P\) হতো orthogonal — আর \(P^{-1} = P^T\), inverse-এর হিসাবই উধাও! কোন matrix-দের কপালে এই সৌভাগ্য লেখা থাকে? উত্তরটা অসম্ভব সুন্দর: symmetric matrix-দের — তাদের eigenvalue সবসময় real, eigenvector সবসময় লম্ব, আর diagonalization কখনো ব্যর্থ হয় না। Chapter 6.4: Symmetric Matrices & Spectral Theorem — linear algebra-র সবচেয়ে সুন্দর উপপাদ্যের সাথে দেখা হবে।
📓 Notebook Project¶
notebooks/part-06/ch03-project.ipynb — diagonalization scratch-এ বানানো (eigenvector থেকে \(P\), \(D\) সাজিয়ে \(PDP^{-1}\) যাচাই); \(A^k\) দুই পথে — সরাসরি matrix power বনাম \(PD^kP^{-1}\) — benchmark করে গতির পার্থক্য মাপা; Fibonacci-র closed form দিয়ে \(F_{100}\) পর্যন্ত exact মান; আর Markov chain-এর steady state — iteration বনাম \(\lambda=1\)-এর eigenvector — দুই পথে মিলিয়ে দেখা।