Chapter 7.1 — Least Squares Classification (লিস্ট স্কোয়ার্স ক্লাসিফিকেশন — তোমার প্রথম ML Classifier)¶
Part V-এ আমরা least squares দিয়ে সংখ্যা predict করেছি — বাড়ির দাম, তাপমাত্রা, বিক্রি। কিন্তু বাস্তবের অনেক প্রশ্নের উত্তর সংখ্যা নয়, সিদ্ধান্ত: এই email-টা spam নাকি নয়? এই transaction-টা fraud নাকি সৎ? ছবিটা "৩" নাকি "৭"? আজ দেখবে — সেই পুরনো least squares যন্ত্রটাই, একটা ছোট্ট চালাকিতে (\(\pm 1\) label + sign function), হয়ে যায় তোমার জীবনের প্রথম machine learning classifier। নতুন কোনো গণিত লাগবে না; লাগবে শুধু Chapter 5.4–5.5-এর normal equations আর একটু সাহস।
🎯 এই chapter-এ যা শিখবে¶
- Classification(ক্লাসিফিকেশন) problem কী, আর regression-এর সাথে তার পার্থক্য কোথায়
- Least Squares Classifier(লিস্ট স্কোয়ার্স ক্লাসিফায়ার): \(\hat{f}(x) = \text{sign}(x^T\beta + v)\) — label-কে \(\pm 1\) সংখ্যা বানিয়ে regression চালানো
- Confusion Matrix(কনফিউশন ম্যাট্রিক্স), error rate, true/false positive rate — classifier-এর রিপোর্ট কার্ড পড়া
- Decision Threshold(ডিসিশন থ্রেশহোল্ড) সরিয়ে false alarm বনাম miss-এর দর কষাকষি
- One-vs-Others(ওয়ান-ভার্সাস-আদারস) কৌশলে \(K\)-class classification: \(\hat{f}(x) = \operatorname{argmax}_k \tilde{f}_k(x)\)
🖼️ এক ছবিতে মূল idea¶
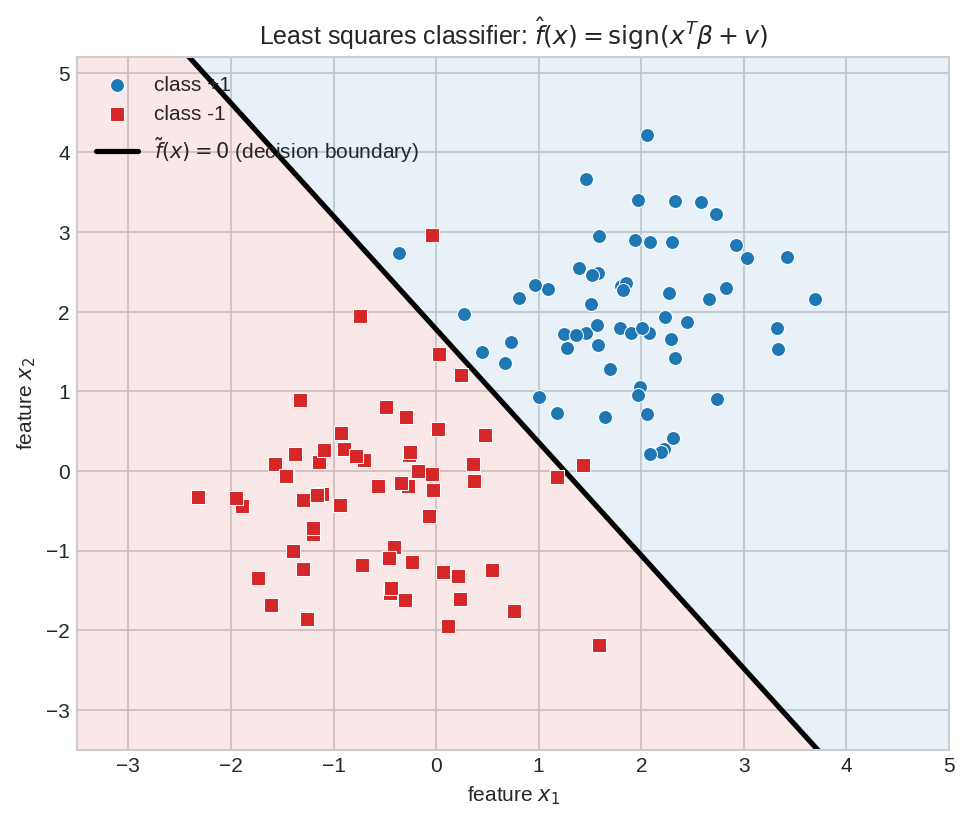
দুই দলের data (নীল বৃত্ত = class \(+1\), লাল বর্গ = class \(-1\))। Least squares একটা affine function \(\tilde{f}(x) = x^T\beta + v\) fit করে; কালো লাইনটা হলো \(\tilde{f}(x) = 0\) — decision boundary। লাইনের যেপাশে পড়বে, sign সেই দলের নাম বলে দেবে। পুরো classifier-টা এই এক লাইনের ছবি।
১. কি? (What)¶
দৈনন্দিন analogy: দারোয়ানের চোখ¶
তোমাদের building-এর দারোয়ান চাচা প্রতিদিন শত শত মানুষ দেখেন। কাউকে দেখেই তিনি সিদ্ধান্ত নেন — "ভেতরে যেতে দেবো" নাকি "জিজ্ঞাসাবাদ করবো"। তিনি কি কোনো সংখ্যা হিসাব করেন? আসলে করেন — অজান্তে! পোশাক, হাঁটার ভঙ্গি, চেনা মুখ কিনা — সব মিলিয়ে মনে মনে একটা "সন্দেহ-স্কোর" বানান, আর স্কোর একটা সীমা পেরোলেই সিদ্ধান্ত উল্টে যায়। এটাই classification-এর হৃদয়: feature থেকে স্কোর, স্কোর থেকে সিদ্ধান্ত।
Part V-এর regression-এ আমরা predict করতাম \(y \approx\) সংখ্যা। Classification-এ outcome \(y\) নেয় মাত্র কয়েকটা মান — একে বলে Label(লেবেল) বা categorical outcome। সবচেয়ে সরল কেস: দুটো মান — spam/not-spam, রোগ আছে/নেই। একে বলে Boolean Classification(বুলিয়ান ক্লাসিফিকেশন) বা binary classification।
সংজ্ঞা¶
Label দুটোকে সংখ্যা বানাও: \(y = +1\) (true) এবং \(y = -1\) (false)। এখন data \((x^{(1)}, y^{(1)}), \dots, (x^{(N)}, y^{(N)})\)-তে সাধারণ least squares data fitting (Chapter 5.5) চালাও — যেন \(\pm 1\) গুলো আসল সংখ্যাই:
\(\tilde{f}\) (টিল্ডা-ওয়ালা) হলো continuous স্কোর-মেশিন — সে যেকোনো real সংখ্যা দিতে পারে (\(0.87\), \(-0.03\), এমনকি \(1.4\))। চূড়ান্ত সিদ্ধান্ত নেয় Sign Function(সাইন ফাংশন):
এই \(\hat{f}\)-ই Least Squares Classifier। ভেতরে regression, বাইরে সিদ্ধান্ত — sandwich-এর মতো।
যেখানে সিদ্ধান্ত বদলায় — \(\tilde{f}(x) = 0\), অর্থাৎ \(x^T\beta + v = 0\) — সেই set-টা একটা Decision Boundary(ডিসিশন বাউন্ডারি): \(\mathbb{R}^2\)-তে সরলরেখা, \(\mathbb{R}^3\)-তে plane, \(\mathbb{R}^n\)-এ hyperplane (Chapter 2.4-এর পুরনো বন্ধু!)।
২. দেখতে কেমন?¶
দৃশ্য ১: স্কোরের দুই পাহাড়¶
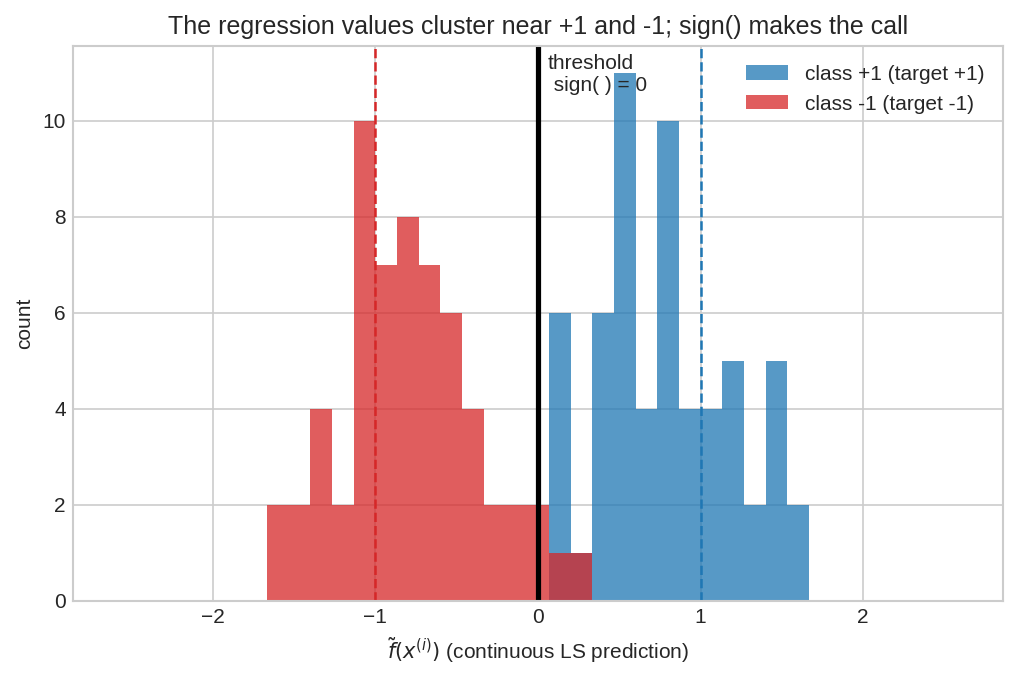
Training data-র সব \(\tilde{f}(x^{(i)})\)-এর histogram। নীল দল জমেছে \(+1\)-এর আশেপাশে, লাল দল \(-1\)-এর আশেপাশে — least squares ঠিক এটাই চেয়েছিল। মাঝের কালো দাগ (\(0\)) হলো বিচারকের কাঠগড়া: ডানে পড়লে \(+1\), বাঁয়ে পড়লে \(-1\)। দুই পাহাড় যত দূরে, classifier তত আত্মবিশ্বাসী।
দৃশ্য ২: থ্রেশহোল্ড সরালে কী হয়¶
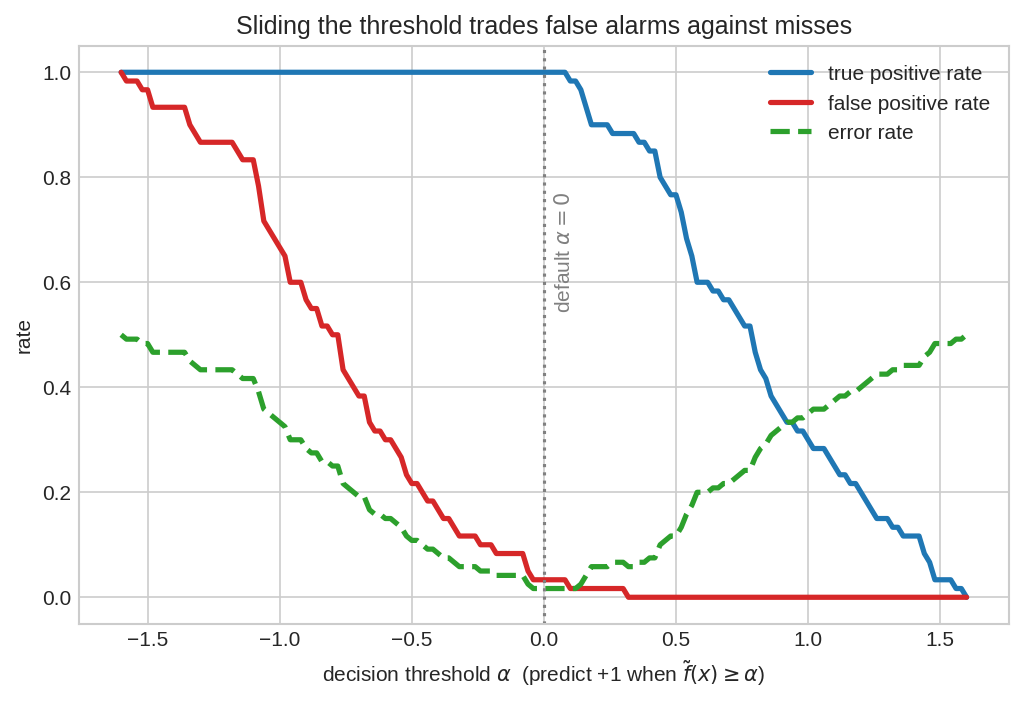
সিদ্ধান্তের নিয়ম বদলে করো: "\(\tilde{f}(x) \ge \alpha\) হলে \(+1\)"। \(\alpha\) ডানে সরালে (কড়া বিচারক) false positive কমে কিন্তু true positive-ও কমে; বাঁয়ে সরালে উল্টো। সবুজ ড্যাশ লাইন (মোট error rate) সাধারণত \(\alpha = 0\)-র কাছেই সবচেয়ে কম — কিন্তু cancer screening-এর মতো ক্ষেত্রে আমরা ইচ্ছে করে \(\alpha\) কমাই, যেন একটা রোগীও miss না হয়।
দৃশ্য ৩: তিন দলের দেশভাগ¶
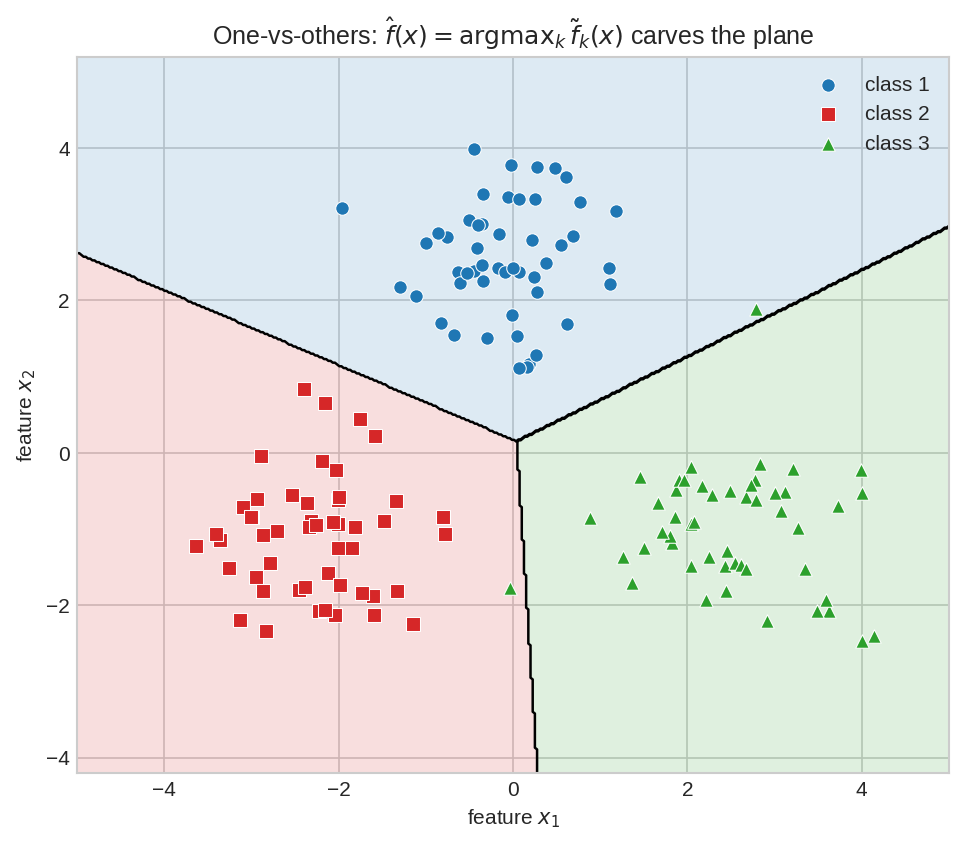
তিনটা class, তিনটা one-vs-others স্কোর-মেশিন \(\tilde{f}_1, \tilde{f}_2, \tilde{f}_3\)। প্রতিটা বিন্দুতে যার স্কোর সবচেয়ে বড়, দেশটা তার — plane ভাগ হয়ে গেছে তিনটা অঞ্চলে, সীমানাগুলো সরলরেখার টুকরো।
দৃশ্য ৪: ছবিও তো vector!¶

\(8\times 8\) ছবির প্রতিটা pixel একটা feature — ছবি মানেই \(\mathbb{R}^{64}\)-এর vector (Part I-এর প্রতিজ্ঞা মনে আছে?)। ওপরের সারি: তিনটা অঙ্কের "template"; নিচে: noise-মাখা বাস্তব sample। Notebook project-এ এই data দিয়েই আমরা digit classifier বানাবো।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে (VMLS ch 14-এর গল্পগুলো আমাদের ভাষায়):
- Spam filter: email-এর শব্দগণনা (word count) feature vector; \(y=+1\) মানে spam। তোমার inbox প্রতি মিনিটে এই যুদ্ধ লড়ছে।
- Fraud detection: গ্রাহকের খরচের ধরন + এই transaction-এর বৈশিষ্ট্য → fraud (\(+1\)) নাকি সৎ (\(-1\))। Bank-এর দারোয়ান চাচা।
- রোগ নির্ণয়: বয়স, test result, symptom → রোগ আছে/নেই। এখানে false negative-এর দাম মারাত্মক — threshold সরানোর আসল কারণ।
- Communications decoder: পাঠানো bit \(0/1\), receiver পায় noisy measurement — decode করা মানেই classify করা।
Data Science / ML-এ:
- MNIST digit recognition: \(28\times 28 = 784\) pixel-এর vector → ১০টা class। Least squares one-vs-others এখানে ~৮৬% accuracy পায় — deep learning-এর যুগেও চমৎকার baseline।
- Baseline model: নতুন classification project-এ সবার আগে least squares/linear classifier চালানো এখনো standard practice — এর চেয়ে খারাপ কিছু বানালে বুঝবে গলদ আছে।
- Deep learning-এর যোগসূত্র: neural network-এর শেষ layer-টা প্রায়ই ঠিক এই \(x^T\beta + v\) — আগের layer-গুলো শুধু ভালো feature বানায়। আর logistic regression, SVM — সবাই একই "affine স্কোর + threshold" পরিবারের সদস্য, শুধু loss function আলাদা।
৪. Properties¶
Property 1 — Classifier মানেই hyperplane দিয়ে দেশভাগ¶
\(\hat{f}(x) = \text{sign}(x^T\beta + v)\)-এর decision boundary \(\{x : x^T\beta + v = 0\}\) একটা hyperplane, যার normal vector হলো \(\beta\) (Chapter 2.4)। \(\beta\)-র দিকে গেলে স্কোর বাড়ে, উল্টো দিকে কমে। তাই \(\beta_j\)-এর চিহ্ন পড়া যায় মানুষের ভাষায়: \(\beta_7 < 0\) মানে "feature 7 যত বড়, \(-1\) হওয়ার সম্ভাবনা তত বেশি" — model-টা ব্যাখ্যাযোগ্য (interpretable)।
Property 2 — স্কোরের মাপ = আত্মবিশ্বাস¶
বিন্দু \(x\) থেকে boundary-র লম্ব দূরত্ব (Chapter 5.1-এর projection):
অর্থাৎ \(|\tilde{f}(x)|\) যত বড়, বিন্দু boundary থেকে তত দূরে — সিদ্ধান্ত তত নিরাপদ। \(\tilde{f}(x) = 0.02\) মানে "কোনোমতে \(+1\)" — এই সংখ্যাটাই multi-class-এ কাজে লাগবে।
Property 3 — স্কোরের গড় = label-এর গড়¶
Feature matrix-এর প্রথম column \(\mathbf{1}\) (constant feature)। Normal equations বলে residual প্রতিটা column-এর সাথে লম্ব (Chapter 5.4), বিশেষত: \(\mathbf{1}^T(y - A\hat\theta) = 0\), অর্থাৎ
দুই দল সমান হলে (\(N_+ = N_-\)) স্কোরের গড় ঠিক শূন্য — histogram-টা ভারসাম্যে থাকে। দল অসমান হলে (spam-এর মতো) গড় সরে যায় — সেজন্যই skewed data-তে threshold tune করতে হয়।
Property 4 — Threshold সরানো = boundary-কে parallel ঠেলা¶
\(\hat{f}(x) = \text{sign}(x^T\beta + v - \alpha)\) মানে শুধু \(v\) বদলানো — boundary হয় নিজের সাথে parallel সরে, দিক বদলায় না। \(\alpha\) বাড়ালে: true positive rate ↓ এবং false positive rate ↓ (দুটোই monotonically) — এই দর কষাকষির লেখচিত্রই ROC curve-এর কাঁচামাল (ছবি §২-এ)।
Property 5 — One-vs-others অঞ্চলগুলো convex¶
Multi-class নিয়ম \(\hat{f}(x) = \operatorname{argmax}_k \tilde{f}_k(x)\)-এ class \(k\)-এর অঞ্চল:
প্রতিটা শর্ত \(\tilde{f}_k(x) - \tilde{f}_j(x) \ge 0\) একটা linear inequality (halfspace), আর halfspace-দের intersection convex — তাই প্রতিটা class-এর দেশ একটা convex polyhedron। ছবি §২-এর সোজা সীমানাগুলো কাকতালীয় নয়, উপপাদ্য।
৫. Intuition — কেন সত্য? (কেন regression দিয়ে classification চলে?)¶
পথ ১: ছায়ার ভাষায়¶
Label vector \(y = (\pm 1, \dots, \pm 1)\) হলো \(\mathbb{R}^N\)-এর একটা বিন্দু — cube-এর একটা কোণা। Least squares তাকে project করে feature matrix \(A\)-এর column space-এ (Chapter 5.4-এর ছবি হুবহু)। ছায়া \(A\hat\theta\) হলো "linear জগতে \(y\)-এর সবচেয়ে কাছের অনুবাদ"। তারপর sign() প্রতিটা coordinate-কে ঠেলে দেয় তার সবচেয়ে কাছের \(\pm 1\)-এ — nearest neighbor snap। পুরো পদ্ধতিটা তাই দুই ধাপের approximation: আগে subspace-এ ছায়া, তারপর cube-এর কোণায় snap।
পথ ২: দুই পাহাড়ের দর কষাকষি¶
Least squares চায় \(+1\) দলের সব স্কোর \(+1\)-এর কাছে আর \(-1\) দলের সব স্কোর \(-1\)-এর কাছে জড়ো করতে। যদি একটা hyperplane সত্যিই দুই মেঘকে আলাদা করতে পারে, তাহলে "নীল মেঘকে \(+1\) উচ্চতায়, লাল মেঘকে \(-1\) উচ্চতায়" রাখা ramp function \(\tilde f\) পাওয়া সহজ — আর তার শূন্য-সমতল ঠিক দুই মেঘের মাঝ দিয়ে যায়। ঢালু ramp-এর zero-crossing-ই boundary — এটাই fig01-এ দেখেছো।
পথ ৩: সততার স্বীকারোক্তি — কেন এটা perfect না¶
Squared loss-এর এক অদ্ভুত স্বভাব: \(y = +1\)-এর জন্য \(\tilde{f}(x) = 3\) হলে সে \((3-1)^2 = 4\) জরিমানা করে — অথচ সিদ্ধান্ত তো নিখুঁত ছিল, বরং অতি-সঠিক! মানে least squares "বেশি ভালো"-কেও শাস্তি দেয়। এজন্য দূরের কিন্তু সঠিক-দিকের বিন্দুরা boundary-কে অকারণে টেনে বাঁকায়। Logistic regression আর SVM ঠিক এই দুর্বলতাটাই সারায় (এই বইয়ের বাইরে, কিন্তু দিকটা এখন তুমি নিজেই দেখতে পাচ্ছো)। তবু: সহজ, দ্রুত, এক লাইনে সমাধানযোগ্য — baseline হিসেবে অপরাজেয়।
Multi-class-এর intuition: তিন বিচারকের রায়¶
\(K\) class-এর জন্য \(K\)টা আলাদা Boolean প্রশ্ন বানাও — "class 1 নাকি বাকিরা?", "class 2 নাকি বাকিরা?", ... প্রতিটার জন্য আলাদা least squares স্কোর-মেশিন \(\tilde{f}_k\)। নতুন \(x\) এলে তিনজনেই স্কোর দেয়; যেমন \(\tilde{f}_1(x) = -0.7,\; \tilde{f}_2(x) = +0.2,\; \tilde{f}_3(x) = +0.8\)। বিজয়ী সবচেয়ে বড় স্কোর — এখানে class 3 (আর দ্বিতীয় অনুমান class 2)। লক্ষ করো: sign() নয়, argmax — কারণ একাধিক মেশিন positive বলতে পারে, বা সবাই negative; আত্মবিশ্বাসের তুলনাই তখন একমাত্র বিচার্য। Property 2 বলেছিল \(\tilde f_k(x)\) মানে আত্মবিশ্বাস — সেটাই এখানে কাজে লাগলো।
৬. Code-এ কেমনে লিখে¶
import numpy as np
np.random.seed(42)
# --- দুই মেঘের synthetic data (fig01-এর data) ---
n = 60
Xp = np.random.randn(n, 2) * 0.9 + [2.0, 2.0] # class +1
Xm = np.random.randn(n, 2) * 0.9 + [-0.5, -0.5] # class -1
X = np.vstack([Xp, Xm])
y = np.hstack([np.ones(n), -np.ones(n)])
# --- Least squares classifier: regression on +/-1 labels ---
A = np.column_stack([np.ones(len(X)), X]) # [1, x1, x2]
theta, *_ = np.linalg.lstsq(A, y, rcond=None)
v, beta = theta[0], theta[1:]
print("v =", v.round(3), " beta =", beta.round(3))
ftilde = A @ theta # continuous scores
yhat = np.where(ftilde >= 0, 1, -1)
# --- রিপোর্ট কার্ড: confusion matrix ও metrics ---
Ntp = np.sum((y == 1) & (yhat == 1))
Ntn = np.sum((y == -1) & (yhat == -1))
Nfp = np.sum((y == -1) & (yhat == 1))
Nfn = np.sum((y == 1) & (yhat == -1))
print(f"confusion: TP={Ntp} FN={Nfn} / FP={Nfp} TN={Ntn}")
print(f"error rate = {(Nfp + Nfn) / len(y):.3f}")
print(f"true positive rate = {Ntp / (Ntp + Nfn):.3f}")
print(f"false positive rate = {Nfp / (Nfp + Ntn):.3f}")
# --- স্কোরের গড় = label-এর গড় (Property 3 যাচাই) ---
print("mean score:", ftilde.mean().round(6), "| mean label:", y.mean())
Output ব্যাখ্যা:
- Seed 42-এ পাবে
v ≈ -0.266,beta ≈ [0.183, 0.204]— দুই feature-ই positive weight, অর্থাৎ ডান-ওপরে গেলে \(+1\) (নীল মেঘ ওদিকেই থাকে)। - মেঘ দুটো প্রায় আলাদা, তাই error rate ছোট (এই data-তে \(\approx 0.008\) — ১২০-এ ১টা ভুল)।
- শেষ লাইনে দুটো গড় হুবহু সমান (\(0.0\)) — Property 3 কোডে ধরা পড়লো: normal equations মিথ্যা বলে না।
- খেয়াল করো
np.linalg.lstsq— Chapter 5.4-এর সেই একই যন্ত্র; classification-এর জন্য নতুন কোনো solver লাগেনি।
৭. Worked Examples¶
Example 1 — এক feature, হাতে-কলমে পুরো classifier¶
Data: \(x = -2, -1, 1, 2\)-তে label \(y = -1, -1, +1, +1\)। Model: \(\tilde{f}(x) = v + \beta x\)।
ধাপ ১ — Least squares setup (Chapter 5.4-এর ছকে):
ধাপ ২ — Normal equations solve: \(4v = 0 \Rightarrow v = 0\); \(10\beta = 6 \Rightarrow \beta = 0.6\)।
ধাপ ৩ — Classifier পড়ো: \(\hat{f}(x) = \text{sign}(0.6x)\) — boundary \(x = 0\)। চার বিন্দুর স্কোর: \(-1.2, -0.6, +0.6, +1.2\) — sign নিলে চারটাই সঠিক, error rate \(0\)। আর স্কোরগুলো দেখো — \(\pm 1\)-এর দুই পাশে সুষমভাবে ছড়ানো, histogram-এর দুই পাহাড় ক্ষুদ্র সংস্করণে।
Example 2 — Confusion matrix থেকে রিপোর্ট কার্ড¶
একটা spam filter-কে \(N = 200\) email-এ পরীক্ষা করা হলো, যার \(40\)টা আসলে spam। ফলাফল: \(N_{tp} = 30\), \(N_{fn} = 10\), \(N_{fp} = 8\), \(N_{tn} = 152\)।
| \(\hat{y} = +1\) (spam বলেছে) | \(\hat{y} = -1\) | মোট | |
|---|---|---|---|
| \(y = +1\) (আসল spam) | 30 | 10 | 40 |
| \(y = -1\) | 8 | 152 | 160 |
- Error rate \(= (10 + 8)/200 = 9\%\)
- True positive rate (recall) \(= 30/40 = 75\%\) — চারটা spam-এর তিনটা ধরছে
- False positive rate \(= 8/160 = 5\%\) — ভালো email-এর ৫% ভুল করে junk-এ পাঠাচ্ছে (এটাই ব্যবহারকারীর সবচেয়ে বড় রাগের কারণ!)
- Precision \(= 30/38 \approx 78.9\%\) — "spam" রায়ের প্রতি ৫টার ৪টা ঠিক
লক্ষ করো: error rate মোটে ৯% শুনতে ভালো, কিন্তু সব email-কে চোখ বন্ধ করে "not spam" বললেও error হতো \(40/200 = 20\%\) — তুলনার এই ভিত্তিরেখা (baseline) ছাড়া কোনো সংখ্যাই অর্থবহ নয়।
Example 3 — Multi-class argmax-এর রায়¶
তিন class-এর one-vs-others মেশিন একটা নতুন \(x\)-কে স্কোর দিলো:
মেশিন 1 ও 2 দুজনেই বলছে "আমার দল" (দুটোই positive)! sign() দিয়ে রায় হয় না। argmax বলে: \(0.3 > 0.25\) — রায় class 1, তবে সামান্য ব্যবধানে (\(0.05\)); অর্থাৎ সিদ্ধান্ত নড়বড়ে, দ্বিতীয় অনুমান class 2। এই "ব্যবধান = আত্মবিশ্বাস" পড়তে পারাটাই multi-class classifier ব্যবহারের আসল দক্ষতা।
৮. Problems ও Solutions¶
Problem 1. Data: \(x = -2, 0, 1, 3\)-তে label \(y = -1, -1, +1, +1\)। Least squares classifier \(\hat{f}(x) = \text{sign}(v + \beta x)\) fit করো, decision boundary কোথায় বের করো, আর দেখাও চারটা বিন্দুই সঠিক classify হয়।
Solution
(হিসাব: \(\sum x_i = 2\), \(\sum x_i^2 = 4+0+1+9 = 14\), \(\sum y_i = 0\), \(\sum x_iy_i = 2+0+1+3 = 6\)।)
Normal equations: \(4v + 2\beta = 0 \Rightarrow v = -\beta/2\); বসিয়ে: \(2(-\beta/2) + 14\beta = 6 \Rightarrow 13\beta = 6\)।
Boundary: \(v + \beta x = 0 \Rightarrow x = \tfrac{1}{2}\)। স্কোরগুলো: \(x=-2: -\tfrac{15}{13}\), \(x=0: -\tfrac{3}{13}\), \(x=1: +\tfrac{3}{13}\), \(x=3: +\tfrac{15}{13}\) — sign মিলিয়ে চারটাই সঠিক ✓
লক্ষ করো: data এবার symmetric নয় (\(x\)-এর গড় \(0.5\)), তাই boundary-ও সরে গিয়ে দুই দলের মাঝামাঝি \(x = 0.5\)-এ দাঁড়িয়েছে — least squares নিজেই ভারসাম্য খুঁজে নেয়।
Problem 2. একটা রোগ-শনাক্তকারী classifier-কে \(N=500\) রোগীতে পরীক্ষা: আসল রোগী \(50\) জন। ফলাফল: \(N_{tp} = 42\), \(N_{fp} = 30\)। (a) পুরো confusion matrix লেখো। (b) error rate, true positive rate, false positive rate, precision বের করো। (c) হাসপাতাল বলছে "একটা রোগীও যেন miss না হয়" — threshold \(\alpha\) কোন দিকে সরাবে, আর তার মূল্য কী?
Solution
(a) \(N_{fn} = 50 - 42 = 8\); \(N_{tn} = 450 - 30 = 420\)।
| \(\hat{y}=+1\) | \(\hat{y}=-1\) | মোট | |
|---|---|---|---|
| \(y=+1\) | 42 | 8 | 50 |
| \(y=-1\) | 30 | 420 | 450 |
(b) Error rate \(= (8+30)/500 = 7.6\%\); TPR \(= 42/50 = 84\%\); FPR \(= 30/450 \approx 6.7\%\); precision \(= 42/72 \approx 58.3\%\)।
(c) Miss মানে false negative — কমাতে হলে \(+1\) বলা সহজ করতে হবে: \(\alpha\) কমাও (বাঁয়ে সরাও)। মূল্য: false positive বাড়বে — বহু সুস্থ মানুষকে অতিরিক্ত test-এর ঝামেলায় ফেলা হবে। §২-এর fig03-এ এটাই দুই curve-এর একসাথে ওঠা: screening test-এ এই দামটা আমরা জেনেশুনে দিই।
Problem 3. Feature matrix-এর প্রথম column \(\mathbf{1}\)। প্রমাণ করো least squares classifier-এর স্কোরের গড় সবসময় label-এর গড়ের সমান: \(\frac1N\sum_i \tilde{f}(x^{(i)}) = \frac1N\sum_i y^{(i)}\)। এর থেকে দেখাও: দুই class-এর sample সংখ্যা সমান হলে স্কোরের গড় ঠিক \(0\)।
Solution
Least squares residual \(e = y - A\hat\theta\), আর normal equations বলে \(A^Te = 0\) — residual \(A\)-এর প্রতিটা column-এর সাথে লম্ব (Chapter 5.4, Intuition পথ ১)।
প্রথম column \(\mathbf{1}\), তাই বিশেষভাবে:
দুই পাশ \(N\) দিয়ে ভাগ করলেই ফল ∎
সমান দলে \(\sum y^{(i)} = N_+ - N_- = 0\), তাই স্কোরের গড়ও \(0\) — histogram-এর দুই পাহাড় শূন্যের দুই পাশে ভারসাম্যে ঝোলে।
শিক্ষা: regression-এর প্রতিটা উপপাদ্য classification-এও বিনামূল্যে চলে আসে — কারণ ভেতরের যন্ত্রটা একই।
Problem 4. ছয়টা validation নমুনার স্কোর ও আসল label: \((\tilde{f}, y) = (1.4, +1), (0.6, +1), (0.2, -1), (-0.1, +1), (-0.5, -1), (-1.2, -1)\)। (a) \(\alpha = 0\)-তে confusion matrix ও error rate। (b) \(\alpha = 0.4\)-তে আবার করো। (c) কোন \(\alpha\) ভালো — নির্ভর করে কীসের ওপর?
Solution
(a) \(\alpha = 0\): \(\hat{y} = +1\) যখন \(\tilde{f} \ge 0\): স্কোর \(1.4, 0.6, 0.2\) → \(+1\); বাকি → \(-1\)। ফল: TP \(=2\) (\(1.4, 0.6\)), FP \(=1\) (\(0.2\)), FN \(=1\) (\(-0.1\)-এর আসল label \(+1\)), TN \(=2\)। Error rate \(= 2/6 = 33.3\%\)।
(b) \(\alpha = 0.4\): \(+1\) পায় শুধু \(1.4, 0.6\)। ফল: TP \(=2\), FP \(=0\), FN \(=2\) (\(0.2\)? না — ওর label \(-1\); miss হলো \(-0.1\)-ওয়ালা আর... সাবধানে: label \(+1\)-ওয়ালা স্কোর \(1.4, 0.6, -0.1\); এর মধ্যে \(-0.1 < 0.4\) → FN। label \(-1\)-ওয়ালা \(0.2, -0.5, -1.2\) সবাই \(< 0.4\) → সব TN।) সুতরাং TP \(=2\), FN \(=1\), FP \(=0\), TN \(=3\)। Error rate \(= 1/6 = 16.7\%\)।
(c) এই ছোট্ট set-এ \(\alpha=0.4\) error কমালো, কিন্তু TPR-ও কমেছে (\(3\)-এ \(2\))। কোনটা ভালো নির্ভর করে কোন ভুলের দাম বেশি তার ওপর: spam filter-এ FP दामी (ভালো mail হারানো), রোগ-শনাক্তে FN দামী। মোট error rate একমাত্র বিচারক নয় — এটাই এই problem-এর আসল পাঠ।
Problem 5. তিন-class classifier-এর parameter: \(\tilde{f}_1(x) = 1 - x_1\), \(\tilde{f}_2(x) = x_1 - x_2\), \(\tilde{f}_3(x) = x_2 - 0.5\)। (a) \(x = (0.4, 0.3)\) আর \(x = (2, 1.8)\)-কে classify করো। (b) class 1 ও class 2-এর সীমানার সমীকরণ বের করো।
Solution
(a) \(x = (0.4, 0.3)\): \(\tilde{f}_1 = 0.6\), \(\tilde{f}_2 = 0.1\), \(\tilde{f}_3 = -0.2\) → argmax = class 1 (স্বচ্ছন্দ জয়)। \(x = (2, 1.8)\): \(\tilde{f}_1 = -1\), \(\tilde{f}_2 = 0.2\), \(\tilde{f}_3 = 1.3\) → class 3। (মেশিন ১ জোর গলায় "আমি না" বলছে — negative স্কোরও তথ্য।)
(b) সীমানা যেখানে দুই স্কোর সমান এবং দুটোই বাকিদের চেয়ে বড়:
— একটা সরলরেখা (Property 5-এর convex দেশের একটা দেয়াল)। এই রেখার ওপরে যে অংশে \(\tilde{f}_3\) ছোট, শুধু সেটুকুই আসল সীমানা।
Problem 6. (XOR — বিখ্যাত ব্যর্থতা) চারটা বিন্দু: \((1,1)\) ও \((-1,-1)\)-এর label \(+1\); \((1,-1)\) ও \((-1,1)\)-এর label \(-1\)। (a) দেখাও \(\tilde{f}(x) = v + \beta_1x_1 + \beta_2x_2\) model-এ least squares solution \(v = \beta_1 = \beta_2 = 0\) — classifier অকেজো। (b) নতুন feature \(x_3 = x_1x_2\) যোগ করলে কী হয়?
Solution
(a) \(A\)-এর column: \(\mathbf{1}\), \(x_1 = (1,-1,1,-1)\), \(x_2 = (1,-1,-1,1)\); \(y = (1,1,-1,-1)\)। Columnগুলো পরস্পর orthogonal: \(A^TA = 4I\)। আর
তাই \(\hat\theta = \tfrac14 A^Ty = 0\) — স্কোর সর্বত্র \(0\), sign() সবাইকে \(+1\) বলে, error \(50\%\): কয়েন-ছোড়ার সমান ∎
জ্যামিতিক কারণ: label-এর ধরন কোণাকুণি (checkerboard) — কোনো সরলরেখাই এই চার বিন্দু ঠিকভাবে ভাগ করতে পারে না; দোষ least squares-এর নয়, linear boundary-র।
(b) \(x_3 = x_1x_2\)-এর মান চার বিন্দুতে \((1, 1, -1, -1)\) — হুবহু \(y\)! তখন \(\tilde{f}(x) = x_1x_2\) নিখুঁত classifier (error \(0\))। শিক্ষা: feature engineering (Chapter 5.5) classification-এও প্রাণ — সঠিক নতুন feature অসম্ভবকে সম্ভব করে। Neural network এই নতুন feature বানানোটাই automatic শেখে।
Problem 7. Property 2 প্রমাণ করো: \(x_0\) থেকে hyperplane \(\{x: x^T\beta + v = 0\}\)-এর লম্ব দূরত্ব \(|x_0^T\beta + v| / \|\beta\|\)। (Hint: boundary-র যেকোনো বিন্দু \(z\) নাও, \(x_0 - z\)-কে \(\beta\)-র ওপর project করো।)
Solution
Boundary-র বিন্দু \(z\) মানে \(z^T\beta + v = 0\)। Hyperplane-এর normal দিক \(\beta\) (Chapter 2.4), তাই \(x_0\)-এর লম্ব দূরত্ব হলো \(x_0 - z\)-এর \(\beta\)-দিকের ছায়ার দৈর্ঘ্য (Chapter 5.1-এর সূত্র):
(শেষ ধাপে \(\beta^Tz = -v\) বসিয়েছি।) \(z\) যেটাই নিই ফল একই — সংজ্ঞাটা সুসংগত ∎
অর্থ: \(\tilde{f}(x_0) = \beta^Tx_0 + v\) হলো দূরত্বেরই scaled রূপ — স্কোর পড়া মানেই মাপা, boundary থেকে কে কত দূরে।
Problem 8. (কোডে) Seed 42-এ দুটো মেঘ বানাও যাদের কেন্দ্র কাছাকাছি — \((1, 1)\) ও \((0, 0)\), প্রতিটা \(\sigma = 1\), \(n = 100\) করে। Least squares classifier fit করে error rate বের করো; তারপর threshold \(\alpha \in \{-0.4, 0, 0.4\}\)-তে TPR ও FPR তুলনা করো।
Solution
import numpy as np
np.random.seed(42)
n = 100
X = np.vstack([np.random.randn(n, 2) + [1, 1],
np.random.randn(n, 2)])
y = np.hstack([np.ones(n), -np.ones(n)])
A = np.column_stack([np.ones(2 * n), X])
theta, *_ = np.linalg.lstsq(A, y, rcond=None)
f = A @ theta
for alpha in [-0.4, 0.0, 0.4]:
yh = np.where(f >= alpha, 1, -1)
tpr = np.mean(yh[y == 1] == 1)
fpr = np.mean(yh[y == -1] == 1)
err = np.mean(yh != y)
print(f"alpha={alpha:+.1f}: TPR={tpr:.2f} FPR={fpr:.2f} err={err:.3f}")
Seed 42-এ output (আনুমানিক): \(\alpha=-0.4\): TPR \(\approx 0.95\), FPR \(\approx 0.62\); \(\alpha=0\): TPR \(\approx 0.76\), FPR \(\approx 0.25\), err \(\approx 0.245\); \(\alpha=+0.4\): TPR \(\approx 0.44\), FPR \(\approx 0.07\)।
পাঠ: মেঘ দুটো ঢুকে গেছে একে অপরের ভেতরে — কোনো linear classifier-ই এখানে জাদু দেখাতে পারবে না (\(25\%\)-ই প্রায় সেরা)। threshold ঘোরালে error প্রায় একই থাকে, শুধু কোন ধরনের ভুল করবো সেটা বদলায়। Data-র overlap-ই সীমা ঠিক করে দেয় — model নয়।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "Classifier-এর output \(\pm 1\), তাই regression-এর সাথে সম্পর্ক নেই" | ভেতরের \(\tilde{f}(x)\) একদম সাধারণ least squares regression — output \(0.87\) বা \(-1.4\) যা খুশি; sign() বাইরে বসানো টুপিমাত্র। \(\tilde f\) আর \(\hat f\)-এর পার্থক্য গুলালে সব গুলিয়ে যাবে। |
| "\(\tilde{f}(x) = 0.9\) মানে \(90\%\) সম্ভাবনা" | না! \(\tilde{f}\) probability নয় — \(1\)-এর বেশি, \(-1\)-এর কম, সবই হয়। সম্ভাবনার ভাষায় কথা বলা model চাইলে logistic regression লাগবে (Statistics curriculum দেখো)। এখানে \(\tilde f\) শুধু "আত্মবিশ্বাস-স্কোর"। |
| "Least squares error rate-ই minimize করে" | সে minimize করে squared error — error rate-এর একটা সহজ বিকল্প (surrogate)। এমনকি সঠিক-কিন্তু-দূরের বিন্দুকেও জরিমানা করে (Intuition পথ ৩)। তাই ভালো, কিন্তু optimal নয়। |
| "Accuracy \(95\%\) মানেই দুর্দান্ত classifier" | Class অসমান হলে ফাঁকা বুলি: data-র \(95\%\) যদি \(-1\) হয়, সব-\(-1\)-বলা অলস classifier-ও \(95\%\) পায়। সবসময় baseline-এর সাথে তুলনা করো, আর TPR/FPR আলাদাভাবে দেখো। |
| "Multi-class-এ প্রতিটা \(\tilde{f}_k\)-র sign() নিলেই হয়" | দুটো মেশিন একসাথে positive হলে? সবাই negative হলে? sign() অচল — নিয়ম হলো argmax: সবচেয়ে আত্মবিশ্বাসী মেশিনের রায়ই রায়। |
| "Training error কম মানেই ভালো model" | Chapter 5.5-এর সেই একই ফাঁদ: আসল পরীক্ষা unseen data-তে (validation/test)। Classification-এও overfitting হয় — feature বেশি হলে training-এ নিখুঁত, বাস্তবে ফেল। পরের chapter-এ এর ওষুধ। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Boolean classification | \(y \in \{-1, +1\}\), model \(\hat{f}: \mathbb{R}^n \to \{-1,+1\}\) | দারোয়ানের সিদ্ধান্ত |
| Least squares classifier | \(\hat{f}(x) = \text{sign}(x^T\beta + v)\); ভেতরে সাধারণ LS fit | regression + sign-টুপি |
| Decision boundary | \(x^T\beta + v = 0\) — hyperplane, normal \(\beta\) | দুই মেঘের মাঝের দেয়াল |
| আত্মবিশ্বাস | \(\vert \tilde{f}(x)\vert = \|\beta\| \times\) (boundary থেকে দূরত্ব) | স্কোর যত দূরে, রায় তত পাকা |
| রিপোর্ট কার্ড | confusion matrix; error rate, TPR, FPR, precision | ৪ ঘরের টেবিল |
| Threshold tuning | \(\text{sign}(\tilde{f}(x) - \alpha)\): boundary parallel সরে | কড়া/নরম বিচারক |
| Multi-class | one-vs-others: \(\hat{f}(x) = \operatorname{argmax}_k \tilde{f}_k(x)\) | \(K\) বিচারকের সর্বোচ্চ রায় |
পরের chapter-এর সেতু: Problem 8-এ দেখলে — feature বাড়ালে training-এ জাদু, বাস্তবে ধোঁকা। ওষুধটা হলো model-এর লাগাম: fit-ও ভালো চাই, parameter-ও ছোট চাই — দুটো objective একসাথে। দুই নৌকায় পা দেওয়ার এই গণিতই multi-objective least squares, আর তার সবচেয়ে বিখ্যাত সন্তান Ridge Regression — Chapter 7.2-এ।
📓 Notebook Project¶
notebooks/part-07/ch01-project.ipynb — Part VII-এর flagship project-এর প্রথম কিস্তি: synthetic digit-ধাঁচের (\(8\times8\) pixel) data বানিয়ে least squares binary classifier scratch-এ, তারপর one-vs-others দিয়ে ৩-digit multi-class classifier — confusion matrix, error rate, আর ভুল-হওয়া ছবিগুলো চোখে দেখা।