Chapter 8.3 — Eigenvalue Algorithms (আইগেনভ্যালু অ্যালগরিদম — power method, QR algorithm)¶
Part VI-এ eigenvalue শিখেছিলে একটা সুন্দর সমীকরণ দিয়ে: \(\det(A - \lambda I) = 0\) সমাধান করো, মূলগুলোই eigenvalue। কাগজে \(2\times 2\)-তে চমৎকার। কিন্তু কম্পিউটারে \(1000 \times 1000\) matrix-এ ওই characteristic polynomial বের করে তার মূল খোঁজা এক সংখ্যাগত দুঃস্বপ্ন — এত বাজে যে কোনো পেশাদার library এটা করেই না। তাহলে Google-এর PageRank কীভাবে ওয়েবের বিশাল matrix-এর প্রধান eigenvector বের করে? তোমার PCA কীভাবে covariance matrix-এর eigenvalue পায়? উত্তর দুটো অবিশ্বাস্য সরল অথচ শক্তিশালী algorithm: Power Method(পাওয়ার মেথড) আর QR Algorithm(কিউআর অ্যালগরিদম)। প্রথমটা একটামাত্র eigenvector-এর দিকে টেনে নেয় বারবার গুণ করে; দ্বিতীয়টা — গণিতের সবচেয়ে সুন্দর algorithm-গুলোর একটা — Chapter 8.2-এর QR factorization-কেই বারবার ঘুরিয়ে সব eigenvalue একসাথে বের করে। আজ দেখবে কীভাবে।
🎯 এই chapter-এ যা শিখবে¶
- কেন \(\det(A - \lambda I) = 0\) কম্পিউটারে চালানো যায় না — Wilkinson-এর ধাক্কা (polynomial root-এর ভয়ংকর অস্থিরতা)
- Power Method: বারবার \(A\) দিয়ে গুণ + normalize → dominant eigenvector; গতি নির্ভর করে \(|\lambda_2/\lambda_1|\)-এর ওপর
- Inverse Iteration(ইনভার্স ইটারেশন) ও Shifted Inverse Iteration(শিফটেড ইনভার্স ইটারেশন) — যেকোনো eigenvalue-কে target করা, shift যত কাছে তত দ্রুত
- QR Algorithm: \(A_k = Q_kR_k\), তারপর \(A_{k+1} = R_kQ_k\) — বারবার করলে matrix ত্রিভুজ হয়ে যায়, diagonal-এ সব eigenvalue ভেসে ওঠে
- Rayleigh Quotient(রেইলি কোশেন্ট) দিয়ে eigenvalue-র নির্ভুল অনুমান, আর কেন এই algorithm-গুলো iterative হতে বাধ্য
🖼️ এক ছবিতে মূল idea¶
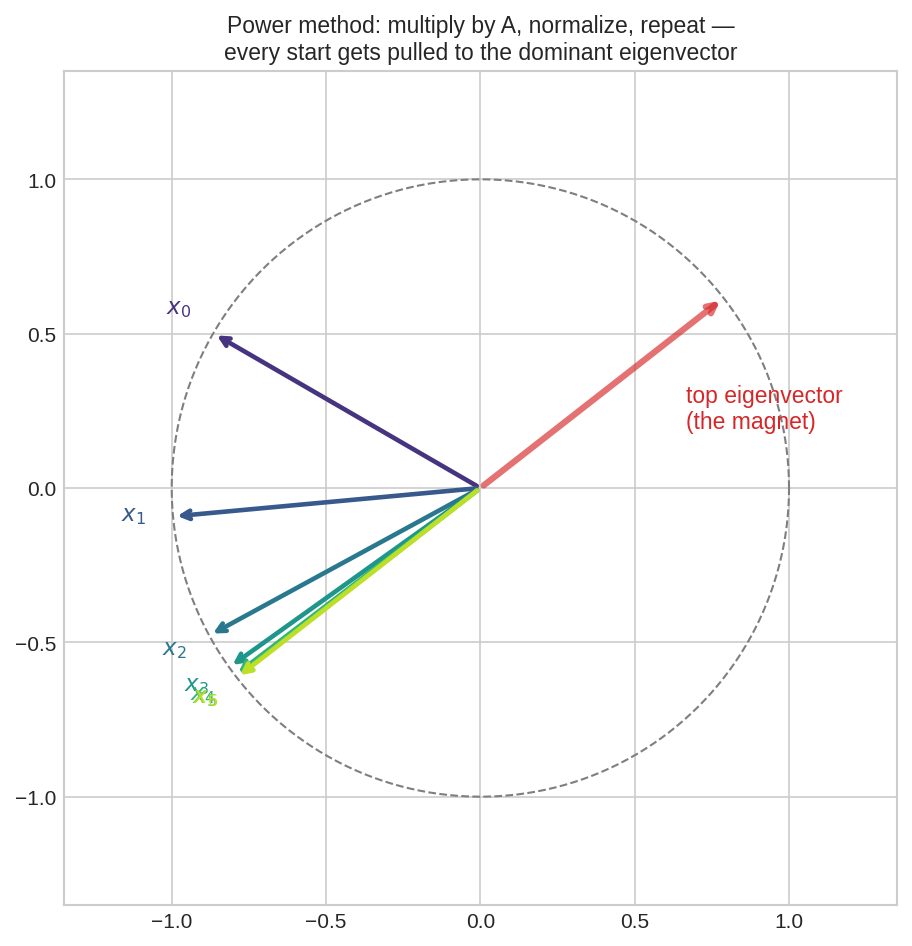
একটা random vector \(x_0\) (গাঢ় রঙ) নাও। বারবার \(A\) দিয়ে গুণ করে normalize করো — \(x_1, x_2, \dots\) (হালকা থেকে উজ্জ্বল রঙে ঘুরছে)। প্রতিটা গুণ vector-টাকে একটু একটু করে টেনে নেয় লাল তীরের দিকে — dominant eigenvector, যেন সেটা একটা চুম্বক। মাত্র কয়েক ধাপে যেকোনো শুরু-বিন্দু সেই চুম্বকে আটকে যায়। এটাই power method-এর পুরো গল্প: গুণ, normalize, পুনরাবৃত্তি।
১. কি? (What)¶
দৈনন্দিন analogy: গুজব যেভাবে ছড়ায়¶
একটা ক্লাসরুমে অনেকগুলো গুজব ঘুরছে — কিছু জোরালো, কিছু দুর্বল। প্রতিদিন প্রত্যেকে যা শুনেছে তা প্রতিবেশীকে বলে (এটাই "\(A\) দিয়ে গুণ")। কিছুদিন পর কী হয়? সবচেয়ে "সংক্রামক" গুজবটাই সবাইকে গ্রাস করে, বাকিগুলো মিলিয়ে যায়। Power method ঠিক তাই: \(A\) দিয়ে বারবার গুণ করা মানে সিস্টেমকে বারবার "একই নিয়মে বিকশিত" করা, আর যে দিকটা সবচেয়ে বেশি বাড়ে (সবচেয়ে বড় eigenvalue-র eigenvector) সেটাই শেষে সব দখল করে।
কেন iterative? — সংখ্যাগত অনিবার্যতা¶
Part VI-এ eigenvalue পেতে \(\det(A - \lambda I) = 0\) সমাধান করেছি। একটা \(n \times n\) matrix-এর characteristic polynomial degree \(n\)-এর। কিন্তু গণিতের এক গভীর সত্য (Abel–Ruffini theorem): degree \(\ge 5\) polynomial-এর মূল বের করার কোনো সাধারণ সূত্র নেই — quadratic formula-র মতো কিছু নেই। তাই \(n \ge 5\)-এই eigenvalue বের করা অবশ্যই iterative (আন্দাজ করে করে কাছাকাছি যাওয়া) হতে বাধ্য — এটা algorithm-এর অলসতা নয়, গণিতের নিয়ম। Power method আর QR algorithm এই iteration-কেই বুদ্ধিমানের মতো করে।
সংজ্ঞা: Power Method¶
Dominant eigenvalue \(\lambda_1\) (মানে \(|\lambda_1| > |\lambda_2| \ge \dots\)) আর তার eigenvector \(v_1\) বের করার recipe:
- একটা random unit vector \(x_0\) থেকে শুরু করো;
- পুনরাবৃত্তি: \(x_{k+1} = \dfrac{Ax_k}{\|Ax_k\|}\) (গুণ, তারপর normalize যাতে বিস্ফোরণ না হয়);
- \(x_k \to v_1\) (dominant eigenvector);
- eigenvalue অনুমান Rayleigh quotient দিয়ে: \(\lambda_1 \approx x_k^T A x_k\) (যখন \(x_k\) unit vector)।
সংজ্ঞা: QR Algorithm¶
সব eigenvalue একসাথে পেতে (Francis, ১৯৬১ — বিংশ শতকের সেরা ১০ algorithm-এর একটা):
- \(A_0 = A\);
- পুনরাবৃত্তি: \(A_k = Q_kR_k\) (QR factorization, Chapter 8.2), তারপর উল্টো ক্রমে গুণ: \(A_{k+1} = R_kQ_k\);
- \(A_k\) ধীরে ধীরে upper triangular (symmetric হলে diagonal) হয়ে যায়;
- eigenvalue-গুলো \(A_k\)-এর diagonal-এ ভেসে ওঠে।
খেয়াল করো: প্রতিটা \(A_{k+1} = R_kQ_k = Q_k^{-1}(Q_kR_k)Q_k = Q_k^{-1}A_kQ_k\) — এটা একটা similarity transformation (Part VI), তাই সব \(A_k\)-এর eigenvalue একই। আমরা শুধু eigenvector-এর basis ঘুরিয়ে যাচ্ছি, যতক্ষণ না matrix-টা এমন basis-এ এসে দাঁড়ায় যেখানে eigenvalue diagonal-এ স্পষ্ট।
Rayleigh Quotient — eigenvalue-র সেরা অনুমান¶
Vector \(x\)-এর জন্য Rayleigh quotient:
\(x\) যদি ঠিক eigenvector \(v\) হয় (\(Av = \lambda v\)), তাহলে \(R(v) = \frac{v^T\lambda v}{v^Tv} = \lambda\) — হুবহু eigenvalue। আর \(x\) eigenvector-এর কাছাকাছি হলে \(R(x)\) eigenvalue-র খুব কাছাকাছি (symmetric matrix-এ ভুল \(O(\|x - v\|^2)\) — দ্বিগুণ ভালো)। তাই power method-এর প্রতি ধাপে \(R(x_k)\) হলো eigenvalue-র সবচেয়ে ভালো অনুমান।
২. দেখতে কেমন?¶
দৃশ্য ১: গতি নির্ভর করে দুই eigenvalue-র অনুপাতে¶
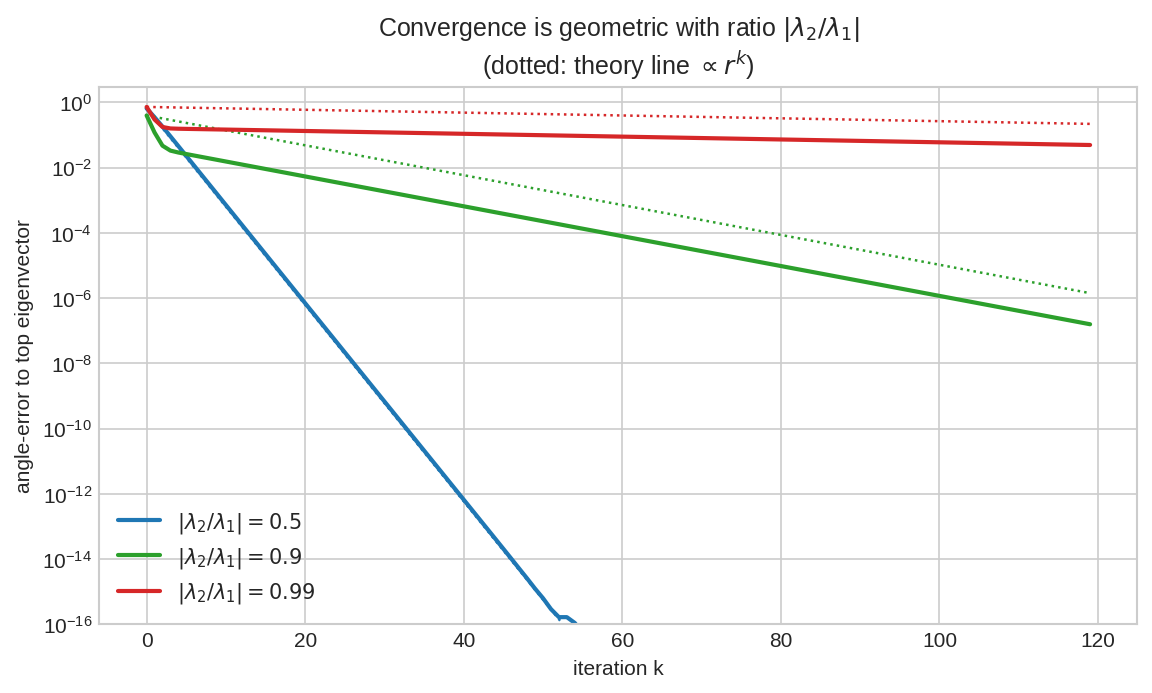
Power method কত দ্রুত converge করে? নির্ভর করে \(|\lambda_2/\lambda_1|\)-এর ওপর। অনুপাত \(0.5\) (নীল) হলে প্রতি ধাপে ভুল অর্ধেক — দ্রুত। \(0.9\) (সবুজ) হলে ধীর। \(0.99\) (লাল) হলে প্রায় স্থবির — দুই বড় eigenvalue প্রায় সমান, চুম্বক দুর্বল। বিন্দু-রেখাগুলো (dotted) তত্ত্বের ভবিষ্যদ্বাণী \(\propto r^k\) — simulation হুবহু মিলেছে। শিক্ষা: eigenvalue-দের ফাঁক (gap) যত বড়, power method তত দ্রুত।**
দৃশ্য ২: QR algorithm — off-diagonal গলে যায়¶
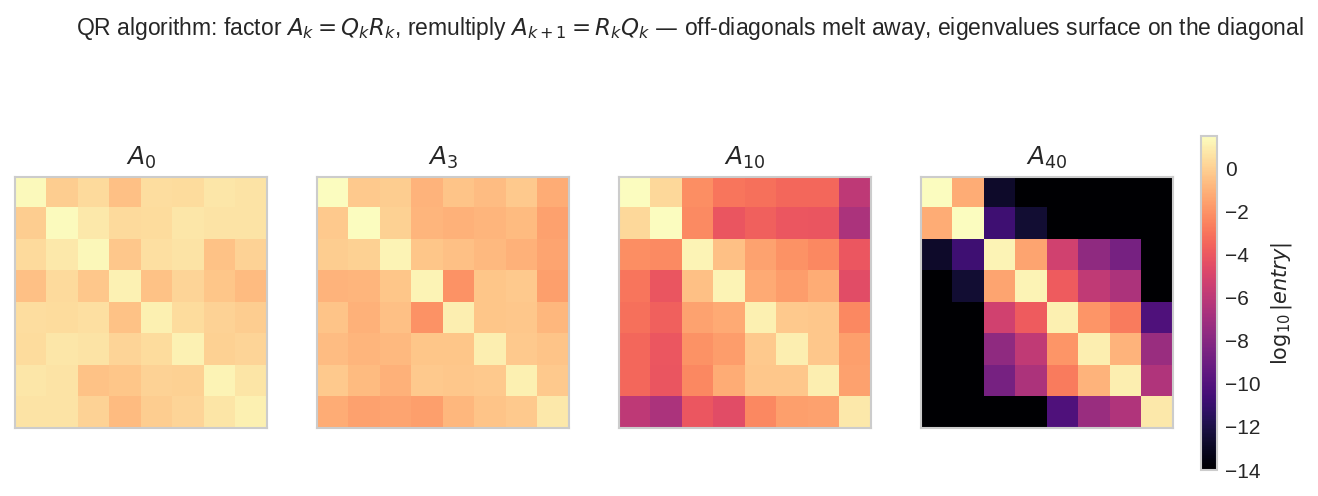
চারটা snapshot: \(A_0\) (শুরু, সব ঘরে মান), তারপর \(A_3, A_{10}, A_{40}\)। রঙ = entry-র লগ-মাপ (উজ্জ্বল = বড়, কালো = প্রায় শূন্য)। বারবার \(A_k = Q_kR_k \to A_{k+1} = R_kQ_k\) করলে off-diagonal ঘরগুলো একে একে কালো হয়ে যায় (গলে যায়), আর \(A_{40}\)-এ শুধু diagonal-ই উজ্জ্বল থাকে — সেই diagonal-এর সংখ্যাগুলোই eigenvalue। কোনো polynomial, কোনো determinant লাগেনি — শুধু বারবার QR।
দৃশ্য ৩: কেন characteristic polynomial নয় — Wilkinson-এর ধাক্কা¶
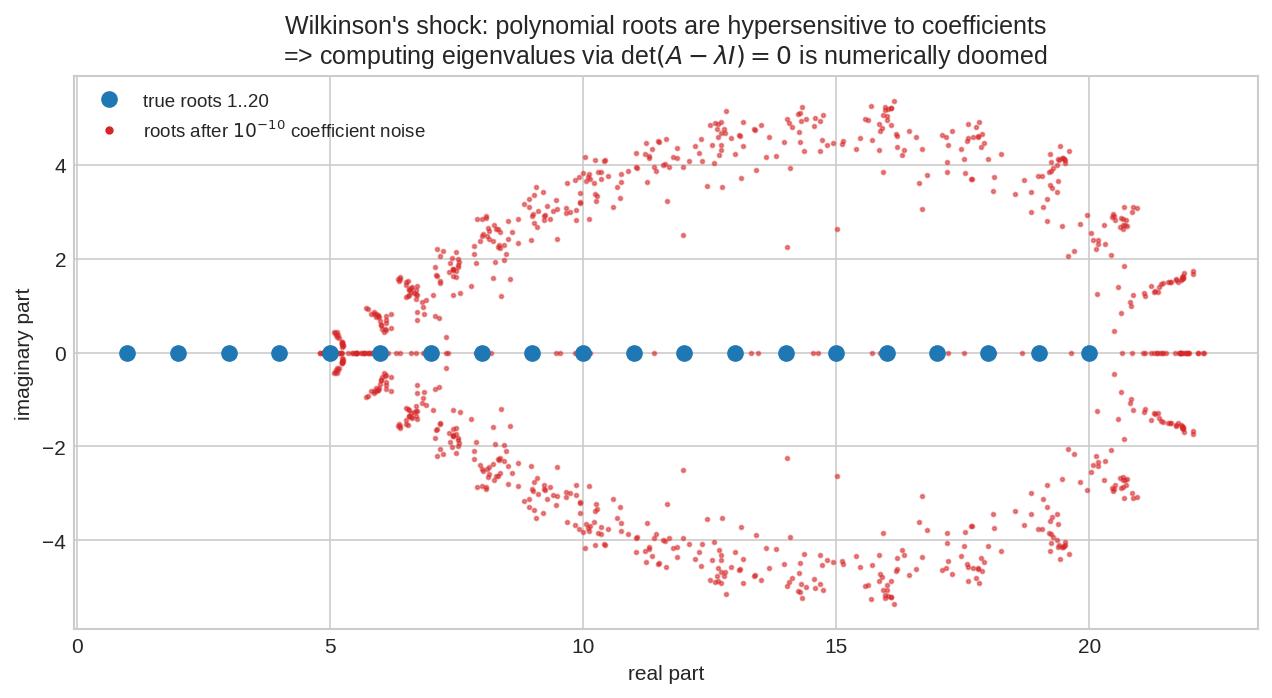
নীল বিন্দু: একটা polynomial-এর ঠিক মূলগুলো \(1, 2, \dots, 20\) (সব বাস্তব, সুন্দর করে সাজানো)। এবার coefficient-গুলোতে মাত্র \(10^{-10}\) (এক কণা ধুলো!) পরিমাণ noise যোগ করে মূল বের করো — লাল বিন্দুগুলো। মূলগুলো ছিটকে গেছে, কিছু তো complex plane-এ উড়ে গেছে! এটাই Wilkinson-এর বিখ্যাত আবিষ্কার: polynomial-এর মূল তার coefficient-এর প্রতি ভয়ংকর সংবেদনশীল। তাই \(\det(A - \lambda I) = 0\)-এর coefficient বের করে মূল খোঁজা = সংখ্যাগত আত্মহত্যা। সরাসরি matrix-এ কাজ করা (power/QR) নিরাপদ।
দৃশ্য ৪: ভালো shift = টার্বো বুস্ট¶
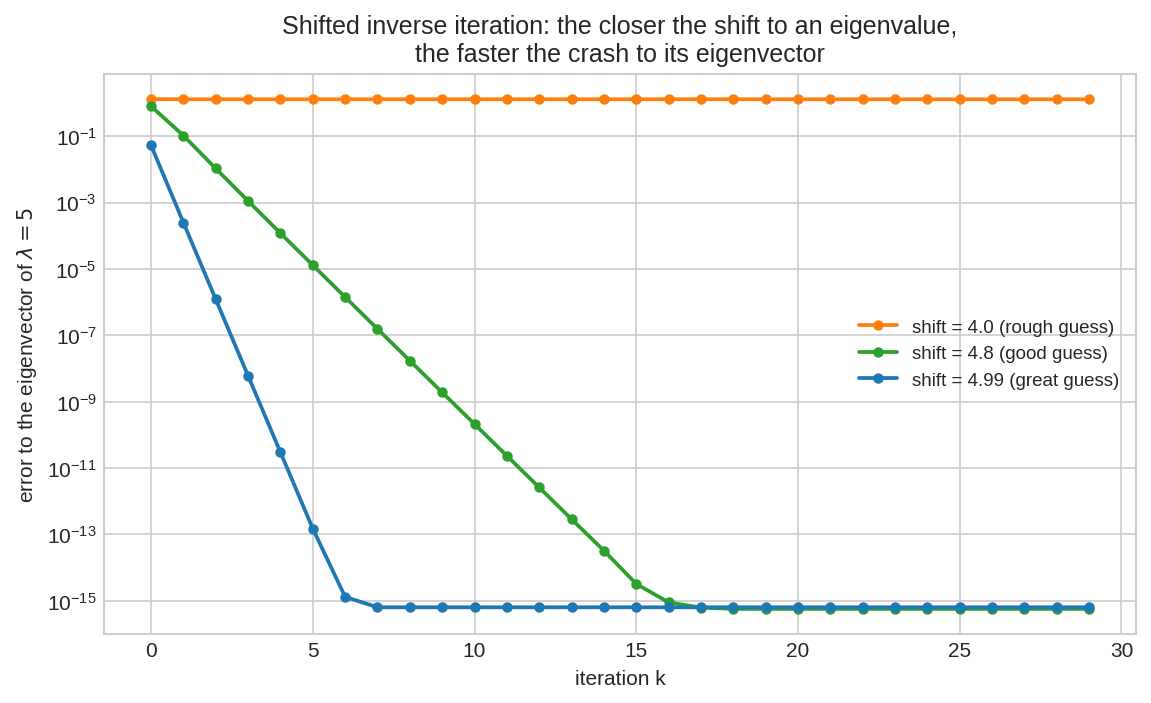
Shifted inverse iteration-এ আমরা target eigenvalue-র কাছাকাছি একটা shift \(\mu\) বেছে \((A - \mu I)^{-1}\)-এ power method চালাই। Shift যত target-এর কাছে, তত দ্রুত। এখানে target eigenvalue \(5\): shift \(4.0\) (কমলা, মোটামুটি আন্দাজ) ধীর; \(4.8\) (সবুজ) দ্রুত; \(4.99\) (নীল, প্রায় নিখুঁত আন্দাজ) — মাত্র ২-৩ ধাপে convergence। শিক্ষা: একটা ভালো আন্দাজ থাকলে shifted inverse iteration চোখের পলকে eigenvector ধরে ফেলে।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- Google PageRank: পুরো ওয়েবটা একটা বিশাল (বিলিয়ন-বিলিয়ন) sparse matrix; কোন পেজ কত গুরুত্বপূর্ণ = সেই matrix-এর dominant eigenvector। Google power method-এর একটা রূপ (power iteration) দিয়েই এটা বের করে — এত বড় matrix-এ আর কোনো পথ নেই।
- কম্পন ও অনুরণন (structural/mechanical): সেতু, ভবন, বিমানের ডানা কোন frequency-তে কাঁপে = stiffness matrix-এর eigenvalue। ভুল frequency-তে বাতাস বইলে সেতু ভেঙে পড়ে (Tacoma Narrows!) — তাই eigenvalue হিসাব জীবন বাঁচায়।
- Quantum mechanics: একটা system-এর সম্ভাব্য energy level = Hamiltonian operator-এর eigenvalue (Chapter 6.2, 9.5-এও দেখেছো)। রসায়নবিদরা অণুর energy বের করতে বিশাল matrix-এর eigenvalue বের করেন।
Data Science / ML-এ:
- PCA: covariance matrix-এর top-\(k\) eigenvector = principal component (Chapter 6.7)। বাস্তবে scikit-learn এগুলো power method / QR-এর দ্রুত সংস্করণ (বা randomized SVD, §৮.৪) দিয়ে বের করে — কখনো determinant দিয়ে নয়।
- Spectral clustering: graph-এর Laplacian matrix-এর কয়েকটা ছোট eigenvector = cluster structure — এখানে shifted inverse iteration (ছোট eigenvalue target) কাজে লাগে।
- Spectral embedding / dimensionality reduction: Laplacian eigenmaps, diffusion maps — সবই matrix-এর কয়েকটা নির্দিষ্ট eigenvector, iterative method দিয়ে বের করা।
- Markov chain-এর stationary distribution: transition matrix-এর \(\lambda = 1\)-এর eigenvector = দীর্ঘমেয়াদি বণ্টন — power method-এর সরাসরি প্রয়োগ (PageRank-ও আসলে এটাই)।
৪. Properties¶
Property 1 — Power method dominant eigenvector-এই যায়¶
যেকোনো (প্রায় সব) শুরু-vector \(x_0\)-কে eigenvector-এর ভাষায় লেখা যায়: \(x_0 = c_1v_1 + c_2v_2 + \dots\) (\(c_1 \ne 0\))। \(A\) দিয়ে \(k\) বার গুণ করলে প্রতিটা \(v_i\)-এর সাথে \(\lambda_i^k\) গুণ হয়:
\(|\lambda_2/\lambda_1| < 1\) বলে বাকি সব term মিলিয়ে যায় — টিকে থাকে শুধু \(v_1\)। এটাই "চুম্বক"-এর গণিত (§৫-এ পূর্ণ argument)।
Property 2 — গতি geometric, হার \(|\lambda_2/\lambda_1|\)¶
প্রতি ধাপে \(v_1\)-এর দিকে ভুল কমে \(|\lambda_2/\lambda_1|\) গুণে (§২-এর ছবি)। তাই:
- eigenvalue-দের gap বড় (\(\lambda_1\) অন্যদের চেয়ে অনেক বড়) → দ্রুত;
- gap ছোট (\(\lambda_1 \approx \lambda_2\)) → হতাশাজনক ধীর।
\(d\) digit নির্ভুলতা পেতে দরকার \(\approx d / \log_{10}(|\lambda_1/\lambda_2|)\) ধাপ। এই gap-নির্ভরতাই shift-এর প্রয়োজন জন্ম দেয় (Property 4)।
Property 3 — Inverse iteration সবচেয়ে ছোট eigenvalue ধরে¶
\(A\)-এর eigenvalue \(\lambda\) হলে \(A^{-1}\)-এর eigenvalue \(1/\lambda\) (একই eigenvector) — Part VI। তাই \(A\)-এর সবচেয়ে ছোট \(|\lambda|\) হলো \(A^{-1}\)-এর সবচেয়ে বড় — মানে \(A^{-1}\)-এ power method চালালে (inverse iteration) সবচেয়ে ছোট eigenvalue-র eigenvector পাই। বাস্তবে \(A^{-1}\) বানাই না (Chapter 8.2!), বরং প্রতি ধাপে \(Ax_{k+1} = x_k\) solve করি (একবার LU factor করে রেখে সব ধাপে reuse)।
Property 4 — Shift eigenvalue বাছাই + গতি দুটোই দেয়¶
\((A - \mu I)\)-এর eigenvalue হলো \(\lambda_i - \mu\)। এতে inverse iteration চালালে (shifted inverse iteration) সবচেয়ে দ্রুত converge হয় সেই eigenvector-এ যার \(\lambda_i\) shift \(\mu\)-এর সবচেয়ে কাছে (কারণ \(\lambda_i - \mu\) তখন সবচেয়ে ছোট, \(\frac{1}{\lambda_i - \mu}\) সবচেয়ে বড়)। Convergence হার \(\left|\frac{\lambda_i - \mu}{\lambda_j - \mu}\right|\) — \(\mu\) যত কাছে, তত ছোট, তত দ্রুত (§২-এর টার্বো-ছবি)। এই একটা কৌশল দিয়ে যেকোনো eigenvalue target করা যায়, আর ভালো shift-এ বিদ্যুৎবেগে।
Property 5 — QR algorithm = "লুকানো" power iteration সবগুলো একসাথে¶
QR algorithm আসলে একটা চতুর চাল: প্রতিটা \(A_{k+1} = R_kQ_k = Q_k^{-1}A_kQ_k\) একটা similarity transform (eigenvalue অপরিবর্তিত), আর গভীরে এটা সব eigenvector-এ একসাথে orthogonal power iteration চালায় — বড় eigenvalue-গুলো ওপরে "স্থির" হয়ে বসে, তাই matrix triangular হয়ে যায়। বাস্তব library (LAPACK) এতে shift যোগ করে (Wilkinson shift) — প্রতি iteration-এ সবচেয়ে ছোট eigenvalue-টা এক ধাপে "locked" হয়ে যায়, ফলে মাত্র \(O(n)\) iteration-এ, মোট \(O(n^3)\) খরচে সব eigenvalue।
৫. Intuition — কেন সত্য?¶
পথ ১: Power method-এর চুম্বক — eigenvector-এর ভাষায়¶
ধরো \(A\) symmetric (Part VI), তাই তার eigenvector \(v_1, \dots, v_n\) একটা orthonormal basis (সম্পূর্ণ অক্ষব্যবস্থা)। যেকোনো \(x_0\)-কে এই basis-এ লেখো:
এবার \(A\) দিয়ে বারবার গুণ — প্রতিটা eigen-দিকে গুণ হয় সেই দিকের eigenvalue:
\(\lambda_1\) সবচেয়ে বড় (মানে) বলে \(\lambda_1^k\) সবচেয়ে দ্রুত বাড়ে — \(k\) বড় হলে প্রথম term বাকি সবকে সংখ্যাগতভাবে ডুবিয়ে দেয়। ভাবো: \(\lambda_1 = 3, \lambda_2 = 1\) হলে \(10\) ধাপে \(\lambda_1^{10} = 59049\) বনাম \(\lambda_2^{10} = 1\) — প্রথমটা ৬০ হাজার গুণ বড়! Normalize করলে (দৈর্ঘ্য \(1\) রাখা) টিকে থাকে শুধু \(v_1\)-এর দিক। চুম্বক আসলে এই "সবচেয়ে দ্রুত বাড়ে বলে সব দখল করে" — জ্যামিতিতে দেখেছো fig01-এ।
পথ ২: shift কেন গতি বাড়ায় — ফাঁক প্রসারিত করা¶
Power method-এর ধীরতা আসে \(\lambda_1 \approx \lambda_2\) থেকে (ফাঁক ছোট, চুম্বক দুর্বল)। Shift এই ফাঁককে আপেক্ষিকভাবে বড় করে। ভাবো তোমার target \(5\), আর আরেকটা eigenvalue \(4.5\) — inverse iteration-এ এদের "বড়ত্ব" হয় \(\frac{1}{|5 - \mu|}\) আর \(\frac{1}{|4.5 - \mu|}\)। \(\mu = 4.99\) নিলে: প্রথমটা \(\frac{1}{0.01} = 100\), দ্বিতীয়টা \(\frac{1}{0.49} \approx 2\) — অনুপাত \(50\) গুণ! মানে target eigenvector এখন \(50\) গুণ "জোরালো চুম্বক"। এক ধাপেই প্রায় locked (fig05-এর নীল বক্ররেখা)। ভালো shift = কৃত্রিমভাবে বিশাল eigenvalue-gap তৈরি।
পথ ৩: QR algorithm কেন triangular বানায় — সততার স্বীকারোক্তি¶
পুরো প্রমাণ সূক্ষ্ম, কিন্তু হৃদয়টা এই: \(A_{k+1} = R_kQ_k\)-তে \(R\) (upper triangular) আর \(Q\)-এর জায়গা বদলানো ছোট্ট চাল ধীরে ধীরে বড় eigenvalue-গুলোকে ওপরের-বাঁয়ের কোণে "ঠেলে" তোলে। গভীরে, \(A^k\)-এর QR factorization-এর \(Q\)-অংশ ঠিক সেই orthogonal basis-এ রূপ নেয় যেখানে \(A\) triangular দেখায় — অর্থাৎ QR algorithm গোপনে সব eigenvector-এ একসাথে power iteration চালাচ্ছে, orthogonality বজায় রেখে (যাতে সবাই dominant-এ ধসে না পড়ে)। বড়টা ওপরে, ছোটটা নিচে — এভাবে সাজানো matrix-ই upper triangular, আর তার diagonal-এ eigenvalue (Part VI: triangular matrix-এর eigenvalue = diagonal entry)। পূর্ণ প্রমাণ Trefethen–Bau-তে; এখানে ছবি (fig03)-ই যথেষ্ট বিশ্বাস।
পথ ৪: কেন Rayleigh quotient এত ভালো¶
Symmetric matrix-এ \(R(x) = \frac{x^TAx}{x^Tx}\)-এর একটা জাদুকরী ধর্ম: eigenvector \(v\)-এর কাছে এটা একটা স্থির বিন্দু (critical point) — সেখানে gradient শূন্য। তাই \(x\) eigenvector থেকে \(\epsilon\) দূরে থাকলে \(R(x)\) eigenvalue থেকে মাত্র \(\epsilon^2\) দূরে (Taylor-এ linear term নেই বলে)। মানে eigenvector-এর অনুমান \(10\%\) ভুল হলেও eigenvalue-র অনুমান মাত্র \(1\%\) ভুল — দ্বিগুণ নির্ভুল। এজন্যই power method-এ eigenvalue পড়তে সবসময় Rayleigh quotient ব্যবহার করা হয়, শুধু \(Ax_k/x_k\)-এর ratio নয়।
৬. Code-এ কেমনে লিখে¶
import numpy as np
rng = np.random.default_rng(42)
# একটা symmetric matrix বানাই (eigenvalue জানা)
n = 5
Q, _ = np.linalg.qr(rng.standard_normal((n, n)))
true_eigs = np.array([8.0, 5.0, 3.0, 2.0, 1.0])
A = Q @ np.diag(true_eigs) @ Q.T
v1_true = Q[:, 0]
# ---------- ১. Power Method: dominant eigenvalue + eigenvector ----------
def power_method(A, n_iter=100, tol=1e-12):
x = rng.standard_normal(A.shape[0]); x /= np.linalg.norm(x)
lam_old = 0.0
for k in range(n_iter):
y = A @ x
x = y / np.linalg.norm(y)
lam = x @ A @ x # Rayleigh quotient
if abs(lam - lam_old) < tol:
return lam, x, k
lam_old = lam
return lam, x, n_iter
lam, v, iters = power_method(A)
print(f"power method: lambda1 = {lam:.6f} (true 8.0) in {iters} iters")
print("eigenvector aligned:", abs(v @ v1_true) > 0.999) # ± দিক মিলেছে
# ---------- ২. Convergence হার = |lambda2/lambda1| ----------
ratio = true_eigs[1] / true_eigs[0] # 5/8 = 0.625
print(f"theory ratio |l2/l1| = {ratio:.3f} (ছোট gap হলে ধীর হতো)")
# ---------- ৩. Shifted Inverse Iteration: middle eigenvalue (3) target ----------
import scipy.linalg as sla
def shifted_inverse_iter(A, mu, n_iter=50):
n = A.shape[0]
M = A - mu * np.eye(n)
lu, piv = sla.lu_factor(M) # একবার factor, বহু solve (Ch 8.2!)
x = rng.standard_normal(n); x /= np.linalg.norm(x)
for _ in range(n_iter):
x = sla.lu_solve((lu, piv), x)
x /= np.linalg.norm(x)
return x @ A @ x, x
lam3, _ = shifted_inverse_iter(A, mu=3.2) # 3-এর কাছে shift
print(f"shifted inverse iter (mu=3.2): lambda = {lam3:.6f} (target 3.0)")
# ---------- ৪. QR Algorithm: সব eigenvalue একসাথে ----------
def qr_algorithm(A, n_iter=200):
Ak = A.copy()
for _ in range(n_iter):
Q, R = np.linalg.qr(Ak)
Ak = R @ Q # উল্টো ক্রমে গুণ
return np.diag(Ak)
eigs_qr = np.sort(qr_algorithm(A))[::-1]
print("QR algorithm eigenvalues:", np.round(eigs_qr, 4))
print("true eigenvalues :", true_eigs)
print("match:", np.allclose(eigs_qr, true_eigs, atol=1e-6))
# ---------- ৫. কেন characteristic polynomial নয় (Wilkinson) ----------
roots_true = np.arange(1, 11, dtype=float)
coeffs = np.poly(roots_true)
coeffs_noisy = coeffs * (1 + 1e-10 * rng.standard_normal(len(coeffs)))
roots_noisy = np.sort(np.roots(coeffs_noisy).real)
print("max root shift from 1e-10 coeff noise:",
np.abs(roots_noisy - roots_true).max()) # noticeably nonzero!
Output ব্যাখ্যা:
- Power method দ্রুত \(\lambda_1 = 8.0\)-তে পৌঁছায় (gap \(8\) vs \(5\) ভালো, তাই কম iteration), আর eigenvector
v1_true-এর সাথে aligned (True)। - ratio \(5/8 = 0.625\) — মাঝারি gap; \(\lambda_1\) যদি \(8.1\) আর \(\lambda_2\) যদি \(8.0\) হতো, ratio \(0.988\) হয়ে power method প্রায় থেমে যেত (Property 2)।
- Shifted inverse iteration \(\mu = 3.2\)-এ চালিয়ে middle eigenvalue \(3.0\)-তে পৌঁছায় — power method একা যা কখনো পারতো না (সেটা শুধু dominant \(8\) ধরতো)। খেয়াল করো:
lu_factorএকবার,lu_solveবহুবার (Chapter 8.2-এর factor-reuse)। - QR algorithm একসাথে পাঁচটা eigenvalue দিলো, সবগুলো true মানের সাথে মিলেছে (
True) — কোনো polynomial, কোনো determinant ছাড়াই। - শেষে Wilkinson: মাত্র \(10^{-10}\) coefficient noise-এ মূলগুলো লক্ষণীয়ভাবে সরে গেছে — এই অস্থিরতাই কেন আমরা কখনো characteristic polynomial দিয়ে eigenvalue বের করি না।
৭. Worked Examples¶
Example 1 — হাতে-কলমে power method (দুই ধাপ)¶
(জানা: eigenvalue \(3\) ও \(1\), dominant eigenvector \(\frac{1}{\sqrt2}(1, 1)^T\)।)
ধাপ ১: \(Ax_0 = \begin{bmatrix} 2 \\ 1 \end{bmatrix}\); দৈর্ঘ্য \(\sqrt5 \approx 2.236\); normalize: \(x_1 = (0.894, 0.447)^T\)। Rayleigh: \(R(x_1) = x_1^TAx_1\)। হিসাব: \(Ax_1 = (2.236, 1.789)^T\), \(x_1^T(Ax_1) = 0.894(2.236) + 0.447(1.789) \approx 2.80\)।
ধাপ ২: \(Ax_1 = (2.236, 1.789)^T\); দৈর্ঘ্য \(\approx 2.864\); normalize: \(x_2 = (0.781, 0.625)^T\)। Rayleigh: \(Ax_2 = (2.186, 2.030)^T\), \(R(x_2) = 0.781(2.186) + 0.625(2.030) \approx 2.98\)।
পর্যবেক্ষণ: eigenvalue-র অনুমান \(2.80 \to 2.98 \to\) (আরো ধাপে) \(3.00\); eigenvector \((1,0) \to (0.894, 0.447) \to (0.781, 0.625) \to\) ক্রমশ \((0.707, 0.707)\)-এর দিকে। চুম্বক টেনে নিচ্ছে। gap \(3/1 = 3\) বড় বলে দ্রুত।
Example 2 — QR algorithm এক ধাপ¶
ধাপ ১ — QR factorization। প্রথম column \((3, 1)^T\), দৈর্ঘ্য \(\sqrt{10}\)। Gram–Schmidt (Chapter 8.2-এর QR):
(যাচাই: \(QR = A\) ✓, \(Q^TQ = I\) ✓।)
ধাপ ২ — উল্টো ক্রমে গুণ: \(A_1 = RQ = \frac{1}{10}\begin{bmatrix} 10 & 6 \\ 0 & 8 \end{bmatrix}\begin{bmatrix} 3 & -1 \\ 1 & 3 \end{bmatrix} = \frac{1}{10}\begin{bmatrix} 36 & 8 \\ 8 & 24 \end{bmatrix} = \begin{bmatrix} 3.6 & 0.8 \\ 0.8 & 2.4 \end{bmatrix}\)।
পর্যবেক্ষণ: off-diagonal \(1 \to 0.8\) — ছোট হচ্ছে! diagonal \((3, 3) \to (3.6, 2.4)\) — সত্যিকারের eigenvalue \(4\) ও \(2\)-এর দিকে সরছে। আরো কয়েক ধাপে off-diagonal \(\to 0\), diagonal \(\to (4, 2)\)। ছবিতে (fig03) এই "গলে যাওয়া"-ই বড় আকারে দেখেছো।
Example 3 — কোন algorithm বাছবে?¶
তিনটা পরিস্থিতি, প্রতিটার জন্য সেরা যন্ত্র:
- (a) PageRank: বিলিয়ন-বিলিয়ন node-এর sparse matrix, দরকার শুধু একটা (dominant) eigenvector। → Power method — sparse matrix-vector গুণ সস্তা, একটাই eigenvector চাই, নিখুঁত মানানসই।
- (b) ছোট (\(50 \times 50\)) matrix, দরকার সব eigenvalue: → QR algorithm — একবারে সব, \(O(n^3)\)-এ, নির্ভরযোগ্য (LAPACK-এর
eigএটাই করে)। - (c) বিশাল sparse matrix, দরকার শূন্যের কাছের ৫টা eigenvalue (spectral clustering): → Shifted inverse iteration (\(\mu \approx 0\)) — target-এর কাছের eigenvalue দ্রুত ধরে, sparse solve দিয়ে (Chapter 8.2)। পুরো QR চালানো এখানে অপচয় (সব eigenvalue লাগে না)।
মূল নীতি: কত eigenvalue লাগবে (এক/কয়েক/সব), কোন অংশের (বড়/ছোট/মাঝের), আর matrix dense না sparse — এই তিন প্রশ্নই algorithm বাছাই করে দেয়।
৮. Problems ও Solutions¶
Problem 1. \(A = \begin{bmatrix} 4 & 1 \\ 1 & 4 \end{bmatrix}\)-এ \(x_0 = (1, 0)^T\) থেকে power method-এর প্রথম দুই ধাপ হাতে চালাও (normalize সহ), আর প্রতি ধাপে Rayleigh quotient দিয়ে eigenvalue অনুমান করো। (জানা: dominant eigenvalue \(5\)।)
Solution
ধাপ ১: \(Ax_0 = (4, 1)^T\), দৈর্ঘ্য \(\sqrt{17} \approx 4.123\), \(x_1 = (0.970, 0.243)^T\)। Rayleigh: \(Ax_1 = (4.123, 1.940)^T\), \(R(x_1) = 0.970(4.123) + 0.243(1.940) \approx 4.47\)।
ধাপ ২: \(Ax_1 = (4.123, 1.940)^T\), দৈর্ঘ্য \(\approx 4.557\), \(x_2 = (0.905, 0.426)^T\)। Rayleigh: \(Ax_2 = (4.045, 2.608)^T\), \(R(x_2) = 0.905(4.045) + 0.426(2.608) \approx 4.77\)।
eigenvalue অনুমান \(4.47 \to 4.77 \to\) (ক্রমশ) \(5.0\); eigenvector \((1,0) \to (0.970, 0.243) \to (0.905, 0.426) \to (0.707, 0.707)\)। gap \(5/3 \approx 1.67\) — মাঝারি, তাই কয়েক ধাপ লাগে।
Problem 2. Power method কত দ্রুত converge করবে যদি eigenvalue হয় (a) \(10, 2, 1\); (b) \(10, 9.9, 1\)? প্রতি ধাপে ভুল কত গুণে কমে, আর ৬ digit নির্ভুলতা পেতে মোটামুটি কত ধাপ?
Solution
Convergence হার \(= |\lambda_2/\lambda_1|\) (Property 2)।
(a) হার \(= 2/10 = 0.2\) — প্রতি ধাপে ভুল \(5\) গুণ কমে (খুব দ্রুত)। ৬ digit (\(10^{-6}\)) পেতে: \(0.2^k < 10^{-6} \Rightarrow k > 6/\log_{10}(5) \approx 6/0.70 \approx 9\) ধাপ।
(b) হার \(= 9.9/10 = 0.99\) — প্রতি ধাপে ভুল মাত্র \(1\%\) কমে (হতাশাজনক ধীর)। ৬ digit পেতে: \(0.99^k < 10^{-6} \Rightarrow k > 6/\log_{10}(1/0.99) \approx 6/0.00436 \approx 1376\) ধাপ!
শিক্ষা: দুই বড় eigenvalue প্রায় সমান হলে power method প্রায় অকেজো — এই ঠিক ক্ষেত্রেই shifted inverse iteration (কৃত্রিম gap তৈরি) বাঁচায়।
Problem 3. কেন আমরা eigenvalue বের করতে \(\det(A - \lambda I) = 0\)-এর মূল খুঁজি না? Wilkinson-এর উদাহরণের আলোকে দুই বাক্যে ব্যাখ্যা করো, আর iterative method কেন নিরাপদ বলো।
Solution
Polynomial-এর মূল তার coefficient-এর প্রতি ভয়ংকর সংবেদনশীল (ill-conditioned): Wilkinson দেখিয়েছেন degree-\(20\) polynomial-এ coefficient-এ মাত্র \(10^{-10}\) পরিমাণ ধুলো (unavoidable floating point rounding, Chapter 8.1) যোগ করলেই মূলগুলো বিশাল দূরত্বে সরে যায়, কিছু complex plane-এ উড়ে যায় (fig04)। তাই \(\det(A - \lambda I)\)-এর coefficient বের করে তার মূল খোঁজা মানে একটা well-conditioned সমস্যাকে (eigenvalue) একটা ill-conditioned সমস্যায় (polynomial root) রূপ দেওয়া — সংখ্যাগতভাবে আত্মঘাতী।
Power method আর QR algorithm সরাসরি matrix-এ কাজ করে (কোনো polynomial বানায় না), তাই এই অস্থিরতা এড়ায় — এরা matrix-vector গুণ আর orthogonal transform-এর মতো stable operation ব্যবহার করে (Chapter 8.1-এর stable algorithm)।
Problem 4. \(A\)-এর eigenvalue \(\{6, 4, 1\}\) আর তোমার target eigenvalue \(4\)। Shifted inverse iteration-এ (a) shift \(\mu = 3.9\) নিলে convergence হার কত (কোন eigenvector-এর দিকে, কত দ্রুত)? (b) shift \(\mu = 4.5\) নিলে? কোনটা ভালো, কেন?
Solution
Shifted inverse iteration সবচেয়ে দ্রুত converge করে target (\(\mu\)-এর নিকটতম eigenvalue)-এ, হার = \(\left|\frac{\lambda_{\text{target}} - \mu}{\lambda_{\text{2nd nearest}} - \mu}\right|\)।
(a) \(\mu = 3.9\): eigenvalue থেকে দূরত্ব: \(|4 - 3.9| = 0.1\) (নিকটতম), \(|6 - 3.9| = 2.1\), \(|1 - 3.9| = 2.9\)। দ্বিতীয় নিকটতম \(6\) (\(2.1\))। হার \(= 0.1/2.1 \approx 0.048\) — প্রতি ধাপে ভুল ~\(20\) গুণ কমে, খুব দ্রুত।
(b) \(\mu = 4.5\): দূরত্ব: \(|4 - 4.5| = 0.5\) (নিকটতম), \(|6 - 4.5| = 1.5\), \(|1 - 4.5| = 3.5\)। হার \(= 0.5/1.5 \approx 0.33\) — প্রতি ধাপে ভুল \(3\) গুণ কমে, অনেক ধীর।
(a) ভালো — shift target (\(4\))-এর যত কাছে, target eigenvalue-র "কৃত্রিম বড়ত্ব" তত বেশি, gap তত বড়, convergence তত দ্রুত (Property 4)। সতর্কতা: \(\mu\) ঠিক \(4\)-এ নিলে \((A - \mu I)\) singular (solve ভেঙে পড়বে) — তাই কাছে, কিন্তু ঠিক ওপরে নয়।
Problem 5. QR algorithm-এর প্রতি ধাপ \(A_{k+1} = R_kQ_k\)-এ প্রমাণ করো eigenvalue অপরিবর্তিত থাকে। (Hint: \(A_k = Q_kR_k\) থেকে \(R_k = Q_k^{-1}A_k\) বসাও।)
Solution
\(A_k = Q_kR_k\) থেকে \(R_k = Q_k^{-1}A_k\) (যেহেতু \(Q_k\) orthogonal, invertible)। বসাই:
এটা একটা similarity transformation (Part VI)। আর similarity transformation eigenvalue সংরক্ষণ করে: যদি \(A_kv = \lambda v\) হয়, তাহলে
অর্থাৎ \(\lambda\) এখনও eigenvalue (eigenvector শুধু \(Q_k^{-1}\) দিয়ে ঘুরে গেছে)। তাই প্রতিটা \(A_k\)-এর eigenvalue হুবহু একই — QR algorithm শুধু basis ঘোরায় যতক্ষণ না eigenvalue diagonal-এ স্পষ্ট হয়। (\(Q_k\) orthogonal বলে \(Q_k^{-1} = Q_k^T\), তাই এই transform সংখ্যাগতভাবেও stable — Chapter 8.1।)
Problem 6. Rayleigh quotient \(R(x) = \frac{x^TAx}{x^Tx}\) symmetric \(A\)-তে eigenvector-এর অনুমানকে "দ্বিগুণ নির্ভুল" করে বলা হয়। \(A = \begin{bmatrix} 3 & 0 \\ 0 & 1 \end{bmatrix}\)-এ eigenvector \(v = (1, 0)^T\) থেকে \(10\%\) সরানো \(x = (\cos\theta, \sin\theta)\), \(\theta = 0.1\) rad নিয়ে যাচাই করো: eigenvector-এর ভুল \(\sim 0.1\), কিন্তু \(R(x)\) eigenvalue \(3\) থেকে কত দূরে?
Solution
\(x = (\cos 0.1, \sin 0.1) \approx (0.995, 0.0998)\) — eigenvector \((1,0)\) থেকে কৌণিক ভুল \(\approx 0.1\) (মানে \(\sin\theta \approx 0.0998\))। এটা unit vector, তাই \(R(x) = x^TAx\):
eigenvalue \(3\) থেকে ভুল \(\approx 0.020\)।
তুলনা: eigenvector-এর ভুল \(\approx 0.0998 \approx 0.1\) (linear order), কিন্তু eigenvalue-র ভুল \(\approx 0.020 \approx (0.1)^2 \times 2\) — বর্গ order (এখানে \(3 - 1 = 2\) gap দিয়ে scaled)! eigenvector-এর ভুল অর্ধেক করলে eigenvalue-র ভুল চার ভাগের এক হবে। এই \(O(\epsilon^2)\) নির্ভুলতাই Rayleigh quotient-কে eigenvalue অনুমানের সেরা যন্ত্র বানায় (§৫ পথ ৪) — power method-এ সবসময় এটাই ব্যবহার করো।
Problem 7. (কোডে) \(n = 6\)-এর একটা symmetric matrix বানাও eigenvalue \(\{12, 9, 5, 3, 2, 1\}\) দিয়ে। (a) power method দিয়ে dominant eigenvalue বের করে \(12\)-এর সাথে মেলাও; (b) QR algorithm দিয়ে সব ৬টা eigenvalue বের করে মেলাও।
Solution
import numpy as np
rng = np.random.default_rng(1)
n = 6
Q, _ = np.linalg.qr(rng.standard_normal((n, n)))
true = np.array([12., 9., 5., 3., 2., 1.])
A = Q @ np.diag(true) @ Q.T
# (a) power method
x = rng.standard_normal(n); x /= np.linalg.norm(x)
for _ in range(200):
x = A @ x; x /= np.linalg.norm(x)
print("(a) dominant:", round(x @ A @ x, 4), "(true 12)")
# (b) QR algorithm
Ak = A.copy()
for _ in range(300):
Qk, Rk = np.linalg.qr(Ak); Ak = Rk @ Qk
print("(b) all eigs:", np.round(np.sort(np.diag(Ak))[::-1], 4))
print(" match:", np.allclose(np.sort(np.diag(Ak)), np.sort(true), atol=1e-5))
12.0 (dominant, gap \(12/9\) ভালো বলে দ্রুত); (b) [12. 9. 5. 3. 2. 1.], match True। শিক্ষা: power method একটাই (সবচেয়ে বড়) দেয়, QR algorithm একবারে সবগুলো — কোনটা চাই তার ওপর যন্ত্র বাছাই (Example 3)।
Problem 8. একজন বলছে: "আমার \(A\) symmetric না, তবু আমি QR algorithm চালিয়ে eigenvalue পেয়ে গেছি — কিন্তু কিছু eigenvalue complex।" এটা কি ঠিক হতে পারে? symmetric আর non-symmetric matrix-এ QR algorithm-এর ফলাফলের পার্থক্য কী?
Solution
হ্যাঁ, ঠিক হতে পারে। Non-symmetric real matrix-এর eigenvalue complex হতে পারে (Part VI: শুধু symmetric matrix-এর সব eigenvalue বাস্তব — spectral theorem)। যেমন rotation matrix \(\begin{bmatrix} 0 & -1 \\ 1 & 0 \end{bmatrix}\)-এর eigenvalue \(\pm i\)।
পার্থক্য: symmetric \(A\)-তে QR algorithm-এ \(A_k\) পুরো diagonal হয়ে যায় (সব eigenvalue diagonal-এ, বাস্তব)। Non-symmetric \(A\)-তে \(A_k\) upper triangular হয় না পুরোপুরি — বরং "quasi-triangular" (real Schur form): diagonal-এ কিছু \(1\times 1\) block (বাস্তব eigenvalue) আর কিছু \(2\times 2\) block (এক জোড়া complex conjugate eigenvalue)। ওই \(2\times 2\) block থেকেই complex eigenvalue আসে। তাই বন্ধুর ফলাফল সম্পূর্ণ সঠিক — non-symmetric matrix-এ complex eigenvalue প্রত্যাশিত, আর QR algorithm সেগুলোও ঠিকঠাক ধরে (real arithmetic-এই, \(2\times 2\) block-এর মাধ্যমে)।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "Eigenvalue পেতে \(\det(A - \lambda I) = 0\) সমাধান করো — Part VI তো তাই শিখিয়েছে" | তত্ত্বে ঠিক, কম্পিউটারে কখনো নয়। Polynomial-এর মূল coefficient-এর প্রতি অতি-সংবেদনশীল (Wilkinson, fig04)। বাস্তবে সরাসরি matrix-এ power/QR চালাও — কোনো library determinant দিয়ে eigenvalue বের করে না। |
| "Power method সব eigenvalue দেয়" | না — শুধু একটা (dominant, সবচেয়ে বড় মানের)। সব চাই? QR algorithm। মাঝের/ছোট eigenvalue চাই? shifted inverse iteration। |
| "Power method সবসময় দ্রুত converge করে" | গতি নির্ভর করে \(\vert \lambda_2/\lambda_1\vert\)-এর ওপর। দুই বড় eigenvalue প্রায় সমান হলে (gap ছোট) প্রায় থেমে যায় (Problem 2b) — তখন shift লাগে। |
| "QR algorithm-এর QR মানে Chapter 8.2-এর QR-এর সাথে সম্পর্ক নেই" | ঠিক একই QR factorization! QR algorithm সেই factorization-কে বারবার ঘুরিয়ে চালায় (\(A_k = Q_kR_k \to R_kQ_k\))। এক অস্ত্র, দুই কাজ (system solve + eigenvalue)। |
| "eigenvalue পড়তে \(x_k\) আর \(Ax_k\)-এর ratio নিলেই হয়" | Rayleigh quotient \(\frac{x^TAx}{x^Tx}\) ব্যবহার করো — symmetric matrix-এ এটা eigenvector-এর ভুলের বর্গ order-এ নির্ভুল (Problem 6), সরল ratio-র চেয়ে বহুগুণ ভালো। |
| "shifted inverse iteration-এ প্রতি ধাপে \((A - \mu I)^{-1}\) বানাতে হয়" | কখনো না (Chapter 8.2!) — একবার \((A - \mu I)\) LU-factor করে রাখো, প্রতি ধাপে শুধু substitute। inverse বানানো ধীর ও অস্থির। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| কেন iterative | degree \(\ge 5\) polynomial-এর মূল-সূত্র নেই (Abel–Ruffini) | eigenvalue বের করা মানেই আন্দাজ-করে-এগোনো |
| Power method | \(x_{k+1} = Ax_k/\|Ax_k\|\) → dominant eigenvector | random vector চুম্বকে আটকে যায় |
| Convergence হার | \(\propto \vert \lambda_2/\lambda_1\vert\) প্রতি ধাপে | gap বড় = দ্রুত, gap ছোট = স্থবির |
| Rayleigh quotient | \(R(x) = \frac{x^TAx}{x^Tx}\); ভুল \(O(\epsilon^2)\) | eigenvector-এর ভুলের বর্গে নির্ভুল |
| Inverse iteration | \(A^{-1}\)-এ power method → সবচেয়ে ছোট eigenvalue | ছোটটা ধরতে matrix উল্টাও (factor করে!) |
| Shifted inverse | \((A-\mu I)^{-1}\): \(\mu\)-এর নিকটতম eigenvalue দ্রুত | ভালো shift = কৃত্রিম বিশাল gap = টার্বো |
| QR algorithm | \(A_k = Q_kR_k \to A_{k+1} = R_kQ_k\) → সব eigenvalue | off-diagonal গলে যায়, diagonal-এ eigenvalue |
| কেন poly নয় | Wilkinson: root coefficient-এর প্রতি অতি-সংবেদনশীল | এক কণা ধুলোয় মূল complex plane-এ উড়ে যায় |
পরের chapter-এর সেতু: এতক্ষণ আমরা eigenvalue/eigenvector আর \(Ax = b\) নিখুঁতভাবে (deterministic algorithm-এ) বের করেছি। কিন্তু data science-এ matrix-গুলো এত বিশাল (\(10^6 \times 10^6\)) যে পুরো SVD বা eigen-decomposition চালানো অসম্ভব — অথচ প্রায়ই আমাদের দরকার শুধু প্রথম কয়েকটা singular vector (top-\(k\) PCA, low-rank approximation)। তাহলে উপায়? এক চমকপ্রদ ধারণা: matrix-টাকে random projection দিয়ে ছোট করে ফেলা, তারপর সেই ছোটতে নিখুঁত কাজ করা। এলোমেলো সংখ্যা দিয়ে নির্ভুল উত্তর — শুনতে অসম্ভব, কিন্তু কাজ করে অবিশ্বাস্য ভালো। এটাই Randomized Methods — randomized SVD আর sketching — Chapter 8.4-এ, numerical linear algebra-র সবচেয়ে আধুনিক অস্ত্র।
📓 Notebook Project¶
notebooks/part-08/ch03-project.ipynb — scratch-এ power method, shifted inverse iteration আর QR algorithm লিখে numpy-র eig-এর সাথে মেলানো; convergence হার \(|\lambda_2/\lambda_1|\)-এর ওপর নির্ভরতা প্লট করা; একটা ছোট PageRank-ধাঁচের stochastic matrix-এ power method চালিয়ে "সবচেয়ে গুরুত্বপূর্ণ node" বের করা; আর Wilkinson-এর polynomial দিয়ে root-instability নিজে দেখা।