Chapter 9.2 — Jordan Canonical Form (জর্ডান ক্যানোনিকাল ফর্ম)¶
Part VI-এ আমাদের একটা মন খারাপ করা মুহূর্ত ছিলো। Chapter 6.2-এ shear matrix \(\begin{bmatrix}1&1\\0&1\end{bmatrix}\) দেখালো তার eigenvalue দুটো (\(\lambda = 1\), দুবার) কিন্তু eigenvector-দিক মোটে একটা — আর Chapter 6.3-এ রায় হয়ে গেলো: এমন Defective(ডিফেক্টিভ) matrix-কে diagonalize করা যায় না, কোনোদিনও না। সেদিন আমরা গল্পটা ওখানেই থামিয়ে দিয়েছিলাম। আজ সেই অসমাপ্ত গল্পের শেষ অধ্যায়: diagonal যদি না-ই হওয়া যায়, তাহলে সবচেয়ে কাছাকাছি কোন সহজ চেহারায় পৌঁছানো সম্ভব? উত্তরটার নাম Jordan Canonical Form — প্রায়-diagonal একটা রূপ, যেখানে diagonal-এর ঠিক ওপরে গুটিকয়েক নাছোড় \(1\) বসে থাকে। ওই \(1\)-গুলো কোনো ব্যর্থতা না — ওরা matrix-এর গভীরতম গঠনের সৎ স্বীকারোক্তি। আর এই form-টাই বলে দেবে \(e^{At}\)-এর ভেতরে \(te^{\lambda t}\) কোত্থেকে আসে, critically damped স্প্রিং কেন ঠিক ওইভাবে থামে, আর "eigenvalue ছোট তবু norm ফুলে ওঠে" — এই আপাত-ভৌতিক কাণ্ডের রহস্য কী।
🎯 এই chapter-এ যা শিখবে¶
- Generalized Eigenvector(জেনারালাইজড আইগেনভেক্টর) — \((A-\lambda I)^k v = 0\) — কীভাবে eigenvector-এর ঘাটতি পূরণ করে, আর Jordan Chain(জর্ডান চেইন) \(v_k \mapsto v_{k-1} \mapsto \cdots \mapsto v_1 \mapsto 0\) কীভাবে গড়ে
- Nilpotent(নিলপোটেন্ট) matrix (\(N^m = 0\)) — Jordan তত্ত্বের ইঞ্জিন — আর তার একমাত্র eigenvalue যে \(0\), তার পূর্ণ প্রমাণ
- Jordan Block(জর্ডান ব্লক) \(J_m(\lambda)\)-এর গঠন এবং JCF theorem: \(\mathbb{C}\)-এর ওপর প্রতিটা square matrix \(P^{-1}AP = J\) আকারে লেখা যায় — Chapter 9.1-এর "ℂ algebraically closed" ঠিক এখানেই কাজে লাগে
- Null-space staircase \(\dim N((A-\lambda I)^k)\) পড়ে block-এর সংখ্যা ও আকার বের করার হাতে-কলমে রেসিপি
- \(J^k\)-এর binomial সূত্র আর তার ফল: transient growth, \(e^{Jt}\)-এর \(te^{\lambda t}\) — সাথে সততার পাঠ: JCF কাগজে অমূল্য, computer-এ ভঙ্গুর
🖼️ এক ছবিতে মূল idea¶
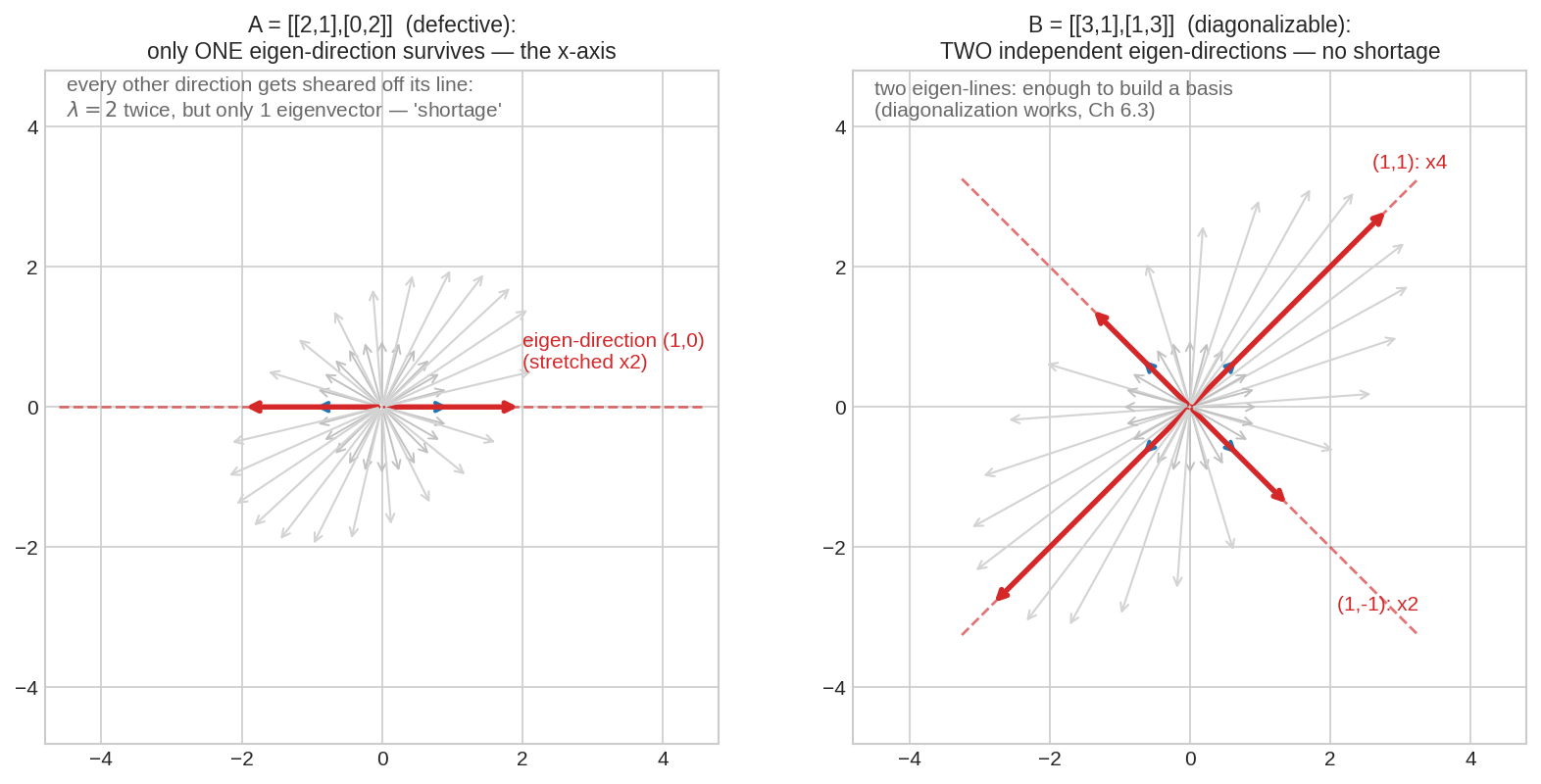
বাঁয়ে \(A = \begin{bmatrix}2&1\\0&2\end{bmatrix}\) — অনেকগুলো দিকের ওপর ছেড়ে দেওয়া হয়েছে; একমাত্র \(x\)-অক্ষ (লাল) নিজের লাইনে টিকে আছে, বাকি সবাই shear খেয়ে হেলে পড়েছে। \(\lambda = 2\) দুবার, অথচ eigenvector-দিক একটাই — এটাই "eigenvector shortage"। ডানে diagonalizable \(B = \begin{bmatrix}3&1\\1&3\end{bmatrix}\): দুটো স্বাধীন eigen-দিক, কোনো ঘাটতি নেই। Jordan form-এর পুরো গল্পটা বাঁয়ের ওই ঘাটতি মেটানোর গল্প।
১. কি? (What)¶
দৈনন্দিন analogy: সবার নিজের ঘর জোটে না¶
Chapter 6.3-এর diagonalization মানে কী ছিলো, এক লাইনে মনে করো: basis-এর প্রত্যেক vector-কে তার নিজের ঘরে পাঠানো। Basis-টা যদি পুরোপুরি eigenvector দিয়ে বানানো যায়, তাহলে \(A\) প্রত্যেককে নিজের ঘরে রেখে শুধু \(\lambda\) গুণ করে — কেউ কারো ঘরে উঁকি দেয় না, matrix হয়ে যায় diagonal।
কিন্তু defective matrix-এ কিছু লোকের নিজের ঘর নেই — eigenvector কম পড়ে গেছে। Jordan-এর প্রস্তাব: যাদের ঘর জোটেনি, তাদের শেয়ার্ড ফ্ল্যাটে রাখো। ফ্ল্যাটের নিয়ম: প্রত্যেকে মূলত নিজের কাজ করে (\(\lambda\) গুণ হয়), কিন্তু একজন পাশের জনের ঘাড়ে একটু হেলান দেয় — output-এ পাশের রুমমেটের এক কপি ঢুকে পড়ে। ওই "হেলান"-টাই matrix-এ diagonal-এর ঠিক ওপরের \(1\)। পুরো space তখন ভাগ হয় কতগুলো ফ্ল্যাটে (block-এ) — একক ঘরওয়ালারা \(1\times1\) block, রুমমেটওয়ালারা বড় block।
সংজ্ঞা: Jordan block আর Jordan form¶
\(m \times m\) Jordan Block \(J_m(\lambda)\) হলো: diagonal-এ সব \(\lambda\), তার ঠিক ওপরের কোণাকুণি লাইনে (একে বলে Superdiagonal(সুপারডায়াগোনাল)) সব \(1\), বাকি সব \(0\):
লক্ষ করো: \(J_1(\lambda)\) মানে নিছক একটা diagonal entry — অর্থাৎ diagonal matrix হলো Jordan form-এরই বিশেষ কেস, যেখানে সব ফ্ল্যাট একক ঘর। আর Part VI-এর সেই shear-জাতীয় \(\begin{bmatrix}2&1\\0&2\end{bmatrix}\)? ওটা আসলে \(J_2(2)\) — শত্রুকে আজ আমরা নাম ধরে চিনলাম।
একটা Jordan matrix \(J\) হলো এরকম block-দের diagonal বরাবর সাজানো সমাহার:
(একই \(\lambda\) একাধিক block-এ আসতে পারে — এটা খুবই গুরুত্বপূর্ণ, একটু পরেই দেখবে।)
Generalized eigenvector: ঘাটতি পূরণের লোকবল¶
Eigenvector কম পড়েছে — বাড়তি লোক আসবে কোত্থেকে? সংজ্ঞাটা এক ধাপ শিথিল করো। \(v \neq 0\)-কে \(\lambda\)-র Generalized Eigenvector বলবো যদি কোনো ধনাত্মক পূর্ণসংখ্যা \(k\)-র জন্য
\(k = 1\) নিলে এটা পুরনো চেনা eigenvector-ই (\(N(A-\lambda I)\)-এর বাসিন্দা — Chapter 6.2)। \(k = 2\) মানে: \((A-\lambda I)v\) হয়তো শূন্য না, কিন্তু আরেকবার \((A-\lambda I)\) মারলেই শূন্য। অর্থাৎ \(v\) "এক ধাপ দূরের" eigenvector — নিজে ঠিক eigenvector না, কিন্তু \((A-\lambda I)\) তাকে একটা সত্যিকার eigenvector-এ নামিয়ে দেয়। যে ক্ষুদ্রতম \(k\)-তে \(v\) শূন্যে পৌঁছায়, সেটাকে বলে \(v\)-এর rank (এই chapter-এ "rank" শব্দটা এই অর্থে লিখলে সবসময় "chain rank" বোঝাবো — column rank নয়)।
এই লোকগুলোই ঘাটতি মেটায়: eigenvector যেখানে ফুরিয়ে যায়, generalized eigenvector-রা সেখানে ঠিক ততজন এসে হাজির হয় যতজন দরকার — এটাই আসলে JCF theorem-এর প্রাণ।
২. দেখতে কেমন?¶
দৃশ্য ১: chain — মই বেয়ে নামা¶
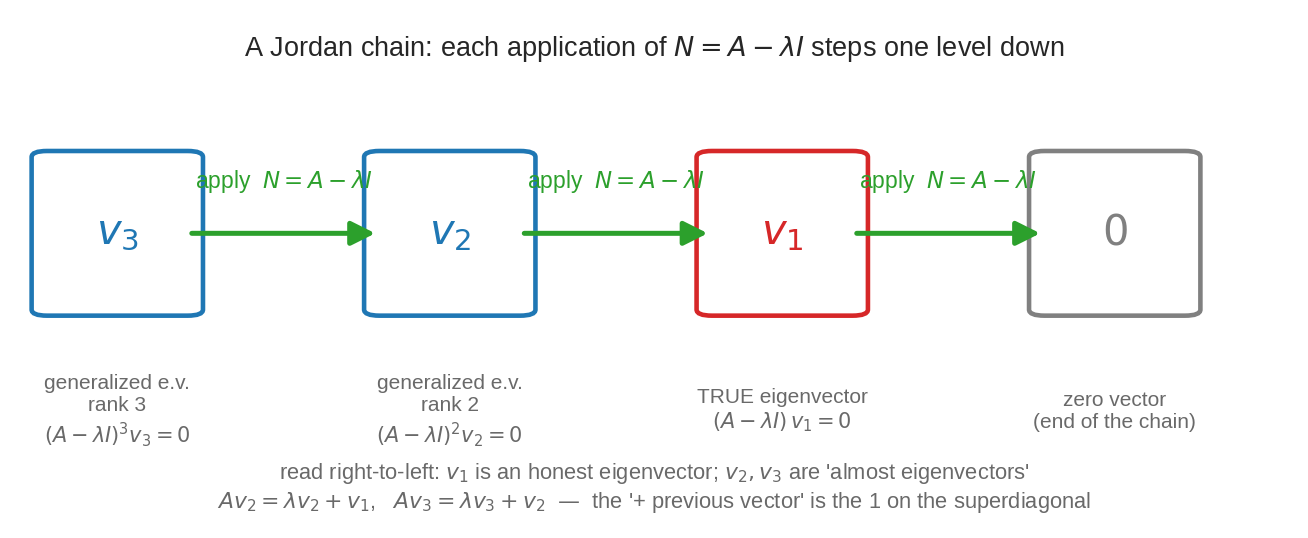
একটা Jordan chain: \(N = A - \lambda I\) প্রতিবার apply করলে এক ধাপ করে নিচে নামা যায় — \(v_3 \mapsto v_2 \mapsto v_1 \mapsto 0\)। ডান থেকে বাঁয়ে পড়ো: \(v_1\) খাঁটি eigenvector; \(v_2, v_3\) "প্রায়-eigenvector" — \(Av_2 = \lambda v_2 + v_1\)-এর ওই "\(+v_1\)"-টাই superdiagonal-এর \(1\)।
\(N = A - \lambda I\) লিখি। ধরো \(v_m\) একটা rank-\(m\) generalized eigenvector। এবার নামতে থাকো:
এই তালিকা \(v_1, v_2, \dots, v_m\)-কে বলে একটা Jordan Chain — \(v_1\) হলো মাটিতে দাঁড়ানো সত্যিকার eigenvector, বাকিরা মইয়ের ওপরের ধাপ। এবার জাদুটা দেখো — \(Nv_j = v_{j-1}\) মানে \(Av_j = \lambda v_j + v_{j-1}\); পুরো chain-কে basis বানালে \(A\)-এর matrix হয়:
Jordan block আসলে একটা chain-এর ছবি — প্রতিটা \(1\) মানে "এই basis vector-টা আগেরটার ঘাড়ে হেলান দিয়ে আছে।"
দৃশ্য ২: পুরো matrix-টা দেখতে কেমন¶
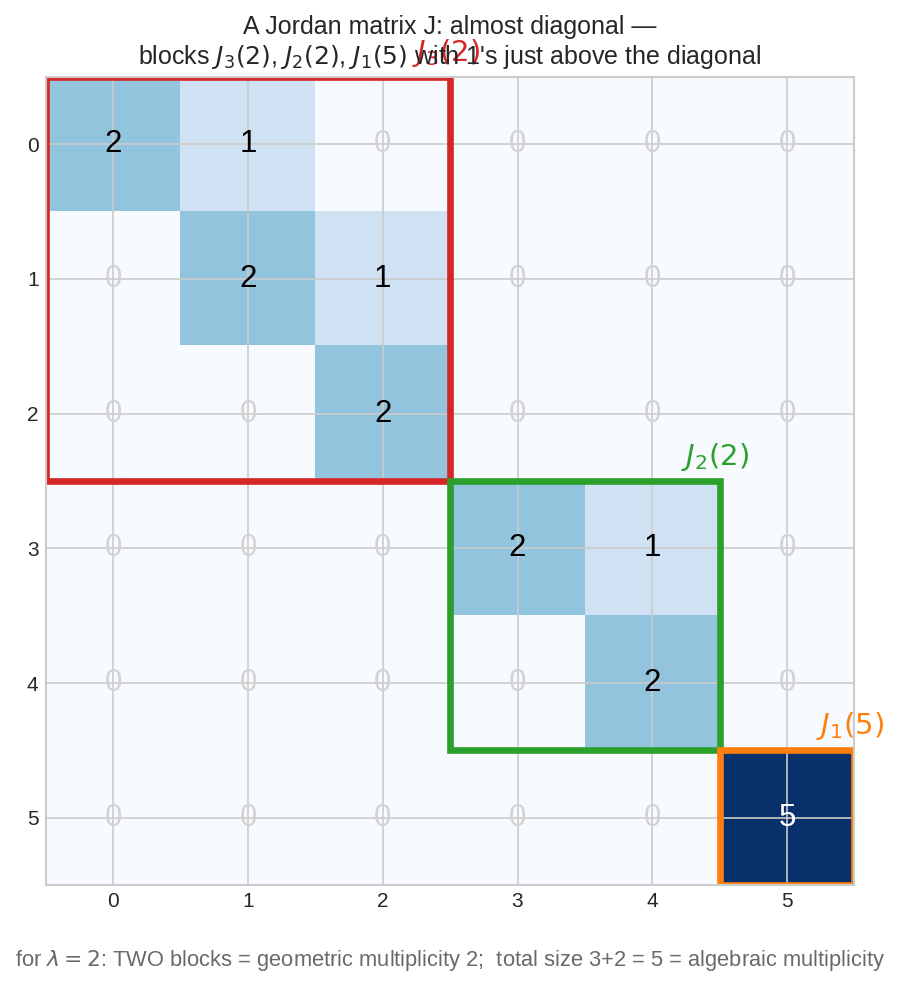
একটা \(6\times6\) Jordan matrix: তিনটা block — \(J_3(2)\) (লাল), \(J_2(2)\) (সবুজ), \(J_1(5)\) (কমলা)। \(\lambda=2\)-এর block দুটো ⟹ তার geometric multiplicity \(2\); দুই block-এর মোট আকার \(3+2=5\) ⟹ algebraic multiplicity \(5\)। "প্রায় diagonal, উপরে কিছু \(1\)" — এই হলো JCF-এর চেহারা।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- Critically damped oscillator(ক্রিটিক্যালি ড্যাম্পড অসিলেটর): গাড়ির শক-অ্যাবজরবার বা দরজার হাইড্রলিক ক্লোজার ঠিক সেই মিষ্টি বিন্দুতে টিউন করা হয় যেখানে দোলা না দিয়ে দ্রুততম থামে। ওই বিন্দুতে system-এর matrix-টা ঠিক defective — দুটো eigenvalue মিলে এক হয়ে যায়, eigenvector একটা হারিয়ে যায়, আর সমাধানে হাজির হয় \(te^{\lambda t}\) (§৪-এ derive করবো)। Physics বইয়ের সেই "বাড়তি \(t\)-ফ্যাক্টর"-এর জন্মসনদ Jordan block।
- Control theory(কন্ট্রোল থিওরি): রকেট/ড্রোনের state-space model \(u' = Au\)-এর স্থায়িত্ব বিশ্লেষণে eigenvalue-র বাস্তব অংশের সাথে block size-ও লাগে — বড় Jordan block মানে decay-এর আগে polynomial ফুলে-ওঠা (transient), যা actuator-কে saturate করে দিতে পারে।
- ODE theory: \(n\)-তম order linear ODE-র সমাধানে repeated root-এ \(t^je^{\lambda t}\) term-গুলো আসে — সেটা আসলে companion matrix-এর Jordan গঠনেরই প্রতিধ্বনি।
Data Science / ML-এ:
- Markov chain-এর convergence rate: transition matrix defective হলে steady state-এ পৌঁছানোর গতি নিছক \(|\lambda_2|^k\) নয় — \(k^{m-1}|\lambda_2|^k\); block size \(m\) জানা না থাকলে convergence-এর estimate ভুল হয়।
- RNN/gradient-এর transient বিস্ফোরণ: সব eigenvalue \(<1\) হলেও non-normal weight matrix-এ gradient-এর norm প্রথমে বহুগুণ ফুলে তারপর কমে (fig04) — training-এর শুরুর অস্থিরতার একটা ক্লাসিক ব্যাখ্যা এই transient growth।
- Matrix function-এর তত্ত্ব: \(f(A)\) (যেমন \(e^A\), \(\log A\), \(\sqrt{A}\)) সংজ্ঞায়িত করার পরিষ্কারতম রাস্তা JCF হয়ে যায় — block-এ \(f\), \(f'\), \(f''\)… বসে।
- তত্ত্বের সর্বত্র: "যেকোনো matrix সম্পর্কে কিছু প্রমাণ করতে হবে" — JCF থাকায় প্রায়ই "Jordan matrix-এর জন্য প্রমাণ করলেই হলো" — কারণ similarity-তে বেশিরভাগ ধর্ম অটুট থাকে।
সততার পাঠ (গুরুত্বপূর্ণ!): কাগজে JCF সোনার খনি, কিন্তু computer-এ JCF numerically ভঙ্গুর। \(J_2(2)\)-এর কোণায় \(10^{-15}\)-এর একটা ধুলো ফেললেই দুটো আলাদা eigenvalue বেরিয়ে block ভেঙে যায় — অথচ matrix কার্যত বদলায়ইনি। Floating-point জগতে তাই কেউ JCF compute করে না; কাজ চালায় SVD (Part VII) আর Schur form দিয়ে। তবু JCF বুঝতেই হয় — কারণ সে-ই ব্যাখ্যা করে ভঙ্গুরতাটা ঠিক কোথায় আর কেন। এই সুতোটাই পরের chapter 9.3-এ টানবো।
৪. Properties¶
Property 1 — Nilpotent matrix: Jordan-এর ইঞ্জিন¶
\(N\)-কে বলে Nilpotent যদি কোনো \(m\)-এর জন্য \(N^m = 0\) হয়। ক্ষুদ্রতম এমন \(m\) হলো তার Index of Nilpotency(নিলপোটেন্সির ইনডেক্স)। ছবিটা ভাবো: nilpotent মানে এমন transformation যেটা সবাইকে প্রতি apply-তে এক ধাপ করে নিচে নামায় — মইয়ের সবচেয়ে লম্বা chain \(m\) ধাপের হলে \(m\) বার ধাক্কাতেই সবাই মেঝেতে (শূন্যে)। যেমন \(J_3(0) = \begin{bmatrix}0&1&0\\0&0&1\\0&0&0\end{bmatrix}\): সে \(e_3 \mapsto e_2 \mapsto e_1 \mapsto 0\) — index \(3\)।
কেন এটা Jordan-এর ইঞ্জিন? প্রতিটা block ভাঙা যায়:
— একটা নিরীহ scaling (\(\lambda I\)) আর একটা nilpotent ধাক্কাধাক্কি (\(N_m\))। Jordan theory-র পুরোটা আসলে এই nilpotent অংশটাকে পোষ মানানোর গল্প।
Lemma (nilpotent-এর eigenvalue): \(N\) nilpotent হলে তার একমাত্র eigenvalue \(0\)।
Proof-এর গল্প: যুক্তিটা এক লাইনের ঘুষি। কেউ যদি দাবি করে "\(N\) আমাকে \(\lambda\) গুণ করে," তাহলে \(N\) বারবার apply করলে সে প্রতিবার \(\lambda\) গুণ হতেই থাকবে — Chapter 6.2-এর Property 4 (\(A^kv = \lambda^k v\))। কিন্তু \(m\) বার পরে \(N^m = 0\) — সবাইকে শূন্য হতেই হবে। "প্রতিবার \(\lambda\) গুণ" আর "শেষে শূন্য" — দুটো একসাথে টিকতে পারে কেবল \(\lambda = 0\) হলে।
Proof: ধরো \(Nv = \lambda v\), \(v \neq 0\)। তাহলে \(N^m v = \lambda^m v\)। কিন্তু \(N^m = 0\), তাই \(\lambda^m v = 0\)। যেহেতু \(v \neq 0\), তাই \(\lambda^m = 0\), অর্থাৎ \(\lambda = 0\)। ∎
উল্টো দিকটাও সত্যি (\(\mathbb{C}\)-এর ওপর): সব eigenvalue \(0\) হলে matrix nilpotent — JCF থেকেই বেরোবে (Problem 3-এ স্বাদ পাবে)।
Property 2 — Null space-এর সিঁড়ি: বাড়ে, তারপর থামে¶
\(N(A - \lambda I) \subseteq N((A-\lambda I)^2) \subseteq N((A-\lambda I)^3) \subseteq \cdots\)
কেন \(\subseteq\)? \((A-\lambda I)v = 0\) হলে \((A-\lambda I)^2 v = (A-\lambda I)\,0 = 0\) — একবারে শূন্য হলে দুবারেও শূন্য। তাই dimension-গুলো কখনো কমে না। আর তারা চিরকাল বাড়তেও পারে না (\(n\)-এর ছাদ আছে); মজার ব্যাপার হলো, একবার থামলে চিরতরে থামে: কোনো ধাপে \(N((A-\lambda I)^k) = N((A-\lambda I)^{k+1})\) হয়ে গেলে তার পরের সব ধাপও সমান (Problem-এ নয়, বিশ্বাসে নাও — যুক্তি: নতুন কেউ ঢুকতে হলে তাকে আগের ধাপ দিয়েই ঢুকতে হতো)।
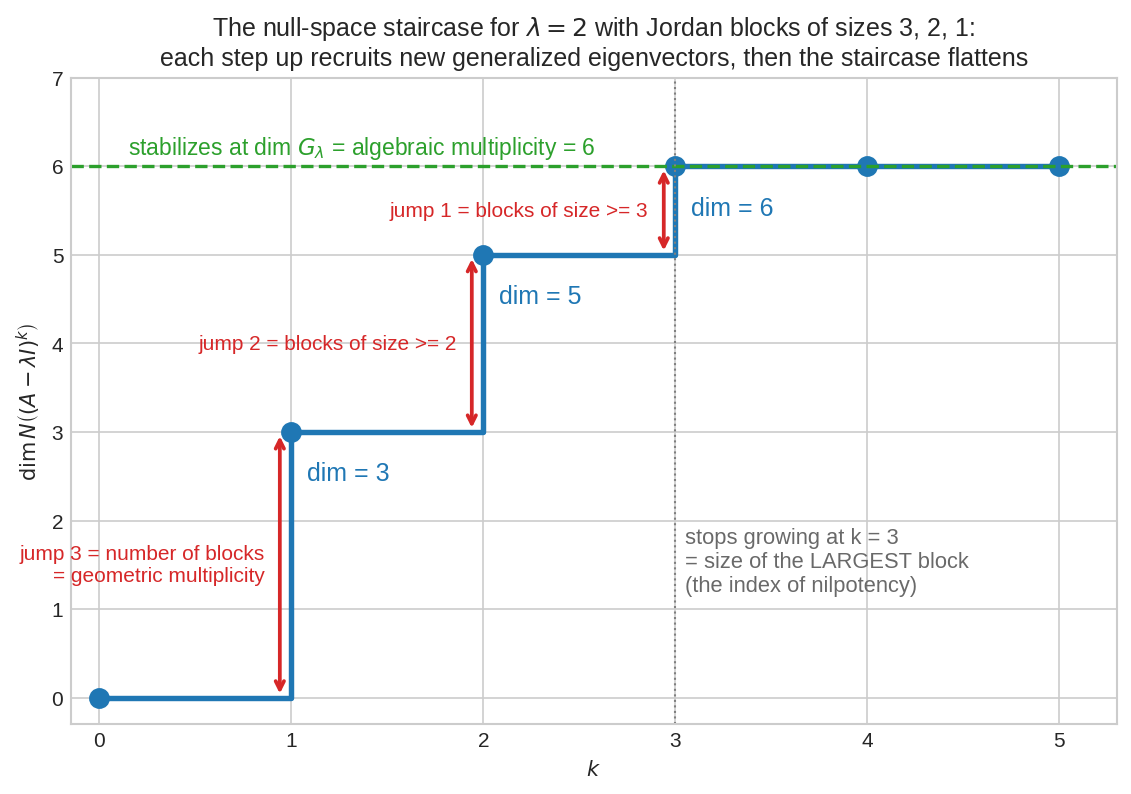
\(\lambda = 2\), block sizes \(3,2,1\)-ওয়ালা matrix-এর সিঁড়ি: \(\dim N((A-2I)^k)\) ধাপে ধাপে \(3 \to 5 \to 6\) উঠে থেমে যায়। প্রতিটা লাফের আকার আর থামার জায়গা — দুটোই block-গঠনের গোপন খবর ফাঁস করে (Property 4)।
সিঁড়ি যেখানে থামে, সেই সর্বোচ্চ তলাটার নাম \(\lambda\)-র Generalized Eigenspace(জেনারালাইজড আইগেনস্পেস):
মূল fact (statement): \(\dim G_\lambda = \lambda\)-র algebraic multiplicity। Intuition: characteristic polynomial-এ \(\lambda\) যতবার আছে, transformation-এর ভেতরে "\(\lambda\)-স্বভাবের" মাত্রা ঠিক ততটাই — eigenvector-রা তার সবটা ধরতে না পারলেও generalized eigenvector-রা পুরোটা ধরে ফেলে। এই জন্যই ঘাটতি "পূরণ" হয়: eigenspace ছোট পড়লেও generalized eigenspace কখনো ছোট পড়ে না।
Property 3 — JCF Theorem (এই chapter-এর রাজা)¶
Theorem (Jordan). \(A\) যেকোনো \(n\times n\) complex matrix হলে এমন invertible \(P\) আছে যাতে
যেখানে \(J\) একটা Jordan matrix; block-গুলো (ক্রম বাদে) সম্পূর্ণ নির্ধারিত — অর্থাৎ JCF is unique up to block order।
দুটো কথা এখনই:
-
"complex" শব্দটা এখানে বেতনভোগী কর্মচারী। Chapter 9.1-এ শিখেছো \(\mathbb{C}\) algebraically closed — প্রতিটা polynomial-এর সব root \(\mathbb{C}\)-তেই থাকে। JCF-এর প্রথম ধাপই হলো characteristic polynomial-কে পুরোপুরি \((\lambda - \lambda_1)^{a_1}\cdots(\lambda-\lambda_p)^{a_p}\) আকারে ভাঙা — \(\mathbb{R}\)-এ rotation matrix-এর মতো কারো কারো root-ই নেই (Chapter 6.2), তাই real JCF সবার জোটে না। ℂ-তে কেউ বাদ যায় না।
-
Diagonalizable মানে: সব block \(1\times1\)। অর্থাৎ পুরনো theorem-টা নতুনটার বিশেষ কেস — Jordan হলো diagonalization-এর সর্বজনীন সংস্করণ।
Proof-এর roadmap-গল্প (পূর্ণ প্রমাণ নয়): প্রমাণটা দুই অঙ্কের নাটক। প্রথম অঙ্ক — জায়গা ভাগ: পুরো \(\mathbb{C}^n\)-কে ভাঙো generalized eigenspace-গুলোতে: \(\mathbb{C}^n = G_{\lambda_1} \oplus \cdots \oplus G_{\lambda_p}\) (এখানেই algebraic closedness আর \(\dim G_\lambda =\) algebraic multiplicity লাগে — মাত্রাগুলো যোগ করলে ঠিক \(n\) হয়, কোনো ফাঁক থাকে না)। প্রতিটা \(G_\lambda\)-র ভেতরে \(A\) ঢুকলে আর বেরোয় না (invariant), আর সেখানে \(A = \lambda I + N\) যেখানে \(N\) nilpotent। দ্বিতীয় অঙ্ক — প্রতিটা ঘরে মই সাজানো: nilpotent \(N\)-ওয়ালা ঘরে সবচেয়ে লম্বা chain-টা আগে বসাও, তারপর বাকি জায়গায় পরের লম্বাটা — এভাবে পুরো ঘরটা কতগুলো disjoint chain-এ ভরে ফেলা যায় (এটাই প্রমাণের সবচেয়ে খাটুনির lemma)। প্রতিটা chain = একটা Jordan block; সব ঘরের সব chain জোড়া দিলেই \(P\)-এর column আর \(J\) তৈরি। আমরা এখানে দুটো ভারবহনকারী lemma পুরো প্রমাণ করবো — একটা এইমাত্র করলাম (nilpotent ⟹ eigenvalue \(0\)), আরেকটা এখনই:
Lemma (chain independence): একটা Jordan chain \(v_1, \dots, v_m\) (যেখানে \(Nv_j = v_{j-1}\), \(Nv_1 = 0\), সব \(v_j \neq 0\)) সবসময় linearly independent।
Proof-এর গল্প: কৌশলটা হলো "সবচেয়ে উঁচু ধাপের লোকটাকে আলাদা করা।" ধরো কেউ একটা dependence দাঁড় করালো। এবার সবাইকে \(N^{m-1}\) দিয়ে ধাক্কা দাও — মইয়ের নিচের সবাই (\(v_1, \dots, v_{m-1}\)) \(m-1\) ধাক্কার আগেই মেঝে ফুঁড়ে শূন্যে চলে যায়, শুধু সবচেয়ে ওপরের \(v_m\) নেমে এসে \(v_1\) হয়ে টিকে থাকে। ফলে dependence থেকে শুধু \(v_m\)-এর coefficient-টা একা পড়ে থাকে — তাকে শূন্য হতেই হয়। তারপর একই খেলা \(N^{m-2}\) দিয়ে, ইত্যাদি — coefficient-রা ওপর থেকে এক এক করে ঝরে পড়ে।
Proof: ধরো \(c_1 v_1 + c_2 v_2 + \cdots + c_m v_m = 0\)। লক্ষ করো \(N^{m-1}v_j = 0\) যদি \(j \le m-1\) (কারণ \(v_j\)-র chain-rank \(j\), আর \(j \le m-1\) ধাক্কাতেই সে শূন্য), এবং \(N^{m-1}v_m = v_1 \neq 0\)। দুই পাশে \(N^{m-1}\) apply করলে:
এবার dependence-এ \(v_m\) নেই; \(N^{m-2}\) apply করো — একই যুক্তিতে \(c_{m-1}v_1 = 0 \Rightarrow c_{m-1} = 0\)। এভাবে নামতে নামতে \(c_m = c_{m-1} = \cdots = c_1 = 0\)। ∎
Property 4 — Block পড়ার রেসিপি: সিঁড়ি-ই বলে দেয় সব¶
\(\lambda\)-র block-গঠন বের করতে determinant-এর বাইরে শুধু rank হিসাব লাগে। \(d_k = \dim N((A-\lambda I)^k) = n - \operatorname{rank}((A-\lambda I)^k)\) লিখে:
| সিঁড়ির তথ্য | Jordan-অর্থ |
|---|---|
| \(d_1\) (প্রথম ধাপ) | \(\lambda\)-র মোট block সংখ্যা \(=\) geometric multiplicity |
| লাফ \(d_k - d_{k-1}\) | আকার \(\ge k\)-এর block সংখ্যা |
| সিঁড়ি যেখানে থামে | সবচেয়ে বড় block-এর আকার (\(= \lambda I\) বাদ দেওয়া অংশের nilpotency index) |
| ছাদ \(d_\infty = \dim G_\lambda\) | সব block-এর আকারের যোগফল \(=\) algebraic multiplicity |
কেন প্রথম লাইনটা সত্যি? প্রতিটা block-এর মেঝেতে ঠিক একটাই সত্যিকার eigenvector (\(v_1\)) দাঁড়িয়ে — তাই block যতগুলো, independent eigenvector ততগুলো (পূর্ণ প্রমাণ Problem 4-এ)। fig05-এর সিঁড়িটা আবার দেখো: লাফগুলো \(3, 2, 1\) — মানে আকার \(\ge 1\)-এর block \(3\)টা, \(\ge 2\)-এর \(2\)টা, \(\ge 3\)-এর \(1\)টা ⟹ sizes \(\{3, 2, 1\}\)। সিঁড়ির ছবিই matrix-এর কঙ্কালের এক্স-রে।
Property 5 — \(J^k\)-এর binomial সূত্র আর transient growth¶
\(J_2(\lambda) = \lambda I + N\), যেখানে \(N = \begin{bmatrix}0&1\\0&0\end{bmatrix}\), \(N^2 = 0\)। \(\lambda I\) আর \(N\) commute করে (identity-র গুণিতক সবার সাথেই করে), তাই binomial theorem নির্ভয়ে চলে:
Diagonalizable হলে \(A^k\)-তে থাকতো শুধু \(\lambda^k\) — এখানে defective দিকটায় একটা polynomial ফ্যাক্টর \(k\lambda^{k-1}\) গজিয়েছে (size-\(m\) block-এ \(\binom{k}{j}\lambda^{k-j}\) পর্যন্ত — Problem 5)। এর মানে হাতে-গরম:
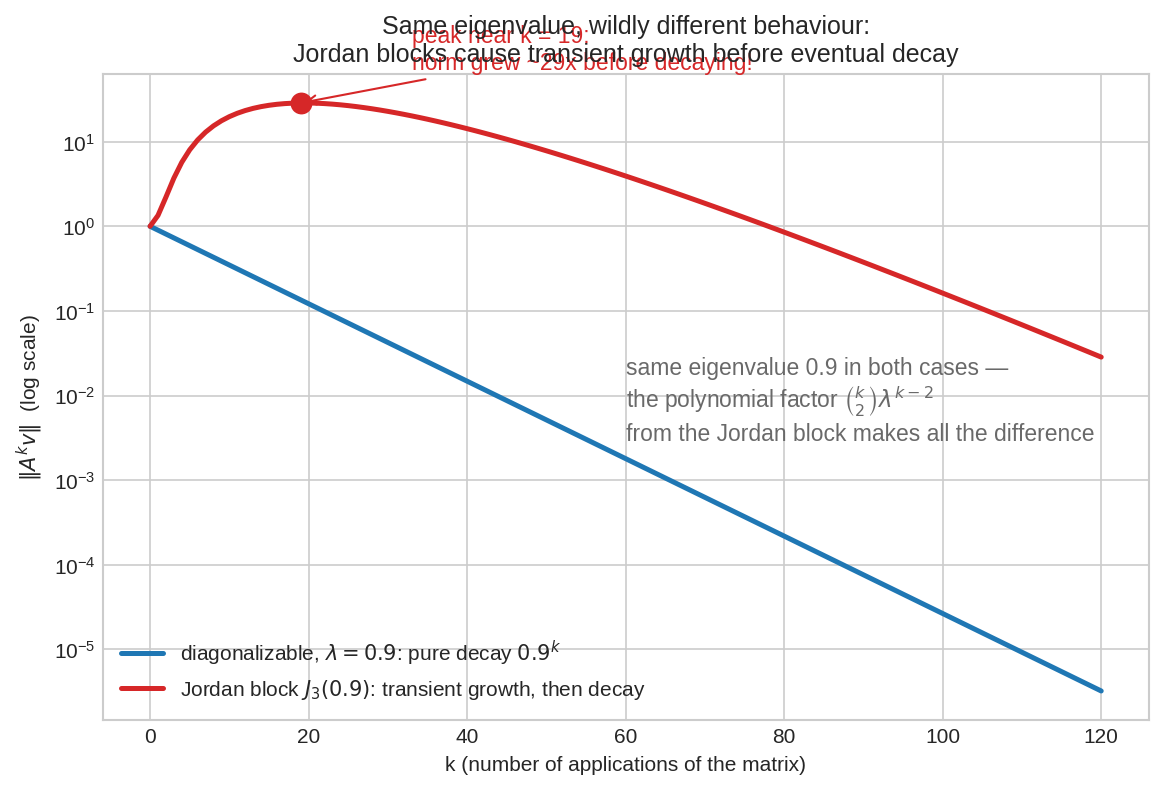
একই eigenvalue \(0.9\), সম্পূর্ণ ভিন্ন আচরণ: diagonalizable matrix-এ \(\|A^kv\|\) প্রথম দিন থেকেই নামে (নীল), কিন্তু \(J_3(0.9)\)-এ \(\binom{k}{2}(0.9)^{k-2}\) ফ্যাক্টরের ঠেলায় norm আগে প্রায় ৪০ গুণ ফুলে ওঠে, তারপর নামে (লাল)। \(|\lambda|<1\) মানেই "শুরু থেকে ছোট হয়" — এই ধারণা defective matrix-এ ডাহা ভুল।
\(|\lambda| < 1\) হলে শেষমেশ \(\lambda^k\)-ই জেতে (exponential decay polynomial-কে সবসময় হারায়) — কিন্তু জেতার আগে \(k\lambda^{k-1}\) বেশ কিছুদিন বেড়ে চলে। এই আগে-ফোলা-পরে-নামাকে বলে Transient Growth(ট্রানজিয়েন্ট গ্রোথ) — §৩-এর RNN gradient আর control-system-এর গল্পের গাণিতিক মূল।
Property 6 — Similarity-তে যা যা অটুট¶
\(P^{-1}AP = J\) মানে \(A\) আর \(J\) similar — Chapter 6.3 থেকে জানো similar matrix-দের characteristic polynomial, eigenvalue, trace, determinant, rank সব এক। নতুন খবর: \(\operatorname{rank}((A-\lambda I)^k)\)-ও এক (কারণ \((A-\lambda I)^k = P(J-\lambda I)^kP^{-1}\)) — তাই সিঁড়িটা similarity-invariant, ফলে block-গঠনও। এ থেকেই JCF-এর uniqueness: দুটো Jordan matrix similar হবে কেবল block-গুলো (ক্রম বাদে) হুবহু মিললে।
৫. Intuition — কেন সত্য?¶
কেন "উপরে \(1\)"-ই সবচেয়ে কাছের সহজ রূপ?¶
Diagonalization ব্যর্থ হয় কারণ eigenvector-রা মিলে পুরো space-এর basis হয় না — shear-এ ২-মাত্রার জায়গায় eigen-দিক মোটে ১টা। কিন্তু basis তো লাগবেই; ঘাটতির আসনগুলোতে তাহলে সবচেয়ে ভদ্র যাদের পাওয়া যায় তাদের বসাও। "ভদ্রতা"-র মাপকাঠি: \(A\) apply করলে যত কম সহকর্মীকে বিরক্ত করে তত ভালো। Eigenvector কাউকে বিরক্ত করে না (\(Av = \lambda v\) — শুধু নিজে scale হয়)। তার পরের সেরা আচরণ: ঠিক একজনকে, ঠিক এক কপি — \(Av_2 = \lambda v_2 + v_1\)। Generalized eigenvector-রা ঠিক এটাই করে, আর chain-basis-এ সেই "এক কপির হেলান"-গুলোই superdiagonal-এর \(1\) হয়ে ফুটে ওঠে। এর চেয়ে কম কিছুতে নামা অসম্ভব — নামা গেলে matrix-টা defective-ই হতো না। তাই JCF আক্ষরিক অর্থেই "diagonal-এর সবচেয়ে কাছের স্টেশন।"
শেয়ার্ড ফ্ল্যাটের ভেতরের জীবন¶
\(J_2(\lambda)\)-এর ফ্ল্যাটে দুজন: \(v_1\) (নিচতলা, খাঁটি eigenvector) আর \(v_2\) (দোতলা)। \(A\) এলে \(v_1\)-এর জীবন শান্ত: \(\lambda\) গুণ, ব্যস। \(v_2\)-এরও প্রায় তাই, কিন্তু প্রতিবার সে \(v_1\)-এর ঘরে এক কপি নিজের ছায়া ফেলে যায়। \(k\) বার \(A\) চালাও — \(v_2\)-এর ফেলা ছায়াগুলো \(v_1\)-এর ঘরে জমতে থাকে: একবারে একটা, মোট \(k\)টা, প্রতিটা নিজ নিজ সময়ের \(\lambda\)-power সহ — যোগফল ঠিক \(k\lambda^{k-1}\) (Property 5-এর সূত্রটা combinatorially এটাই!)। Transient growth তাহলে আর রহস্য না: ছায়া জমার হার (\(k\) গুণে বাড়ে) বনাম প্রতিটা ছায়ার বিবর্ণ হওয়া (\(\lambda^k\)-এ কমে) — প্রথম দিকে জমাই জেতে, শেষে বিবর্ণতা।
সিঁড়ি কেন থামে — আর থামার জায়গাটা কেন এত তথ্যবান¶
প্রতিটা ধাপ \(N((A-\lambda I)^k)\) মানে "যারা \(k\) ধাক্কায় শূন্য হয়" — মইয়ের \(k\) তলা পর্যন্ত সবাই। নতুন তলা ততক্ষণই যোগ হয় যতক্ষণ আরো লম্বা মই আছে; সবচেয়ে লম্বা মই \(m\) ধাপের হলে \(k = m\)-এর পরে নতুন কেউ নেই — সিঁড়ি ওখানেই সমতল। আর প্রতিটা লাফে ঠিক ততজন নতুন লোক ঢোকে যতগুলো মই অন্তত অতটা লম্বা — তাই লাফের আকার = "size \(\ge k\) block-এর সংখ্যা।" পুরো block-গঠন এক ছবিতে ধরা পড়ে — এই জন্যই fig05-কে আমি এক্স-রে বলেছি।
\(e^{Jt}\): ODE-তে \(te^{\lambda t}\)-এর জন্ম¶
Diagonalizable \(A\)-এর জন্য \(u' = Au\)-এর সমাধান ছিলো \(e^{\lambda t}\)-দের মিশ্রণ (Part VI)। Jordan block-এ কী হয়? \(J = \lambda I + N\), দুই অংশ commute করে, তাই \(e^{Jt} = e^{\lambda t}e^{Nt}\); আর \(N^2 = 0\) বলে exponential series দুই term-এই শেষ: \(e^{Nt} = I + Nt\)। ফলাফল:
ওই কোণার \(t\)-টাই differential equation বইয়ের \(te^{\lambda t}\)! Critically damped oscillator-এ ঠিক এটাই ঘটে: damping বাড়াতে বাড়াতে দুটো \(e^{\lambda_1 t}, e^{\lambda_2 t}\) মিলে যাওয়ার মুহূর্তে matrix defective হয়ে যায়, আর হারানো সমাধানের জায়গা নেয় \(te^{\lambda t}\) — গণিত নিজেই ঘাটতি পূরণ করে, ঠিক যেভাবে generalized eigenvector eigenvector-এর ঘাটতি পূরণ করে। (পূর্ণ derivation Example 3-এ।)
৬. Code-এ কেমনে লিখে¶
import numpy as np
np.random.seed(42)
# ---- একটা 6x6 Jordan matrix বানাই: blocks J3(2), J2(2), J1(5) ----
def jordan_block(lam, m):
return lam * np.eye(m) + np.diag(np.ones(m - 1), k=1)
from scipy.linalg import block_diag # না থাকলে নিজে concat করেও পারো
J = block_diag(jordan_block(2, 3), jordan_block(2, 2), jordan_block(5, 1))
# একটা random invertible P দিয়ে লুকিয়ে ফেলি: A দেখে কিছুই বোঝা যাবে না
P = np.random.randn(6, 6)
A = P @ J @ np.linalg.inv(P)
# ---- null-space staircase: dim N((A - 2I)^k) = 6 - rank((A-2I)^k) ----
lam = 2.0
M = A - lam * np.eye(6)
Mk = np.eye(6)
for k in range(1, 5):
Mk = Mk @ M
d = 6 - np.linalg.matrix_rank(Mk, tol=1e-8)
print(f"k={k}: dim N((A-2I)^{k}) = {d}")
# k=1: 2 k=2: 4 k=3: 5 k=4: 5 <- সিঁড়ি: লাফ 2,2,1 => blocks {3,2}
# λ=2-এর block ২টা (geometric mult 2), বড়টা size 3 — J-এর সাথে হুবহু মিল!
# ---- J^k-এর binomial সূত্র যাচাই: J2(0.9)^k ----
lam, k = 0.9, 7
J2 = jordan_block(lam, 2)
formula = np.array([[lam**k, k * lam**(k-1)],
[0.0, lam**k]])
print(np.allclose(np.linalg.matrix_power(J2, k), formula)) # True
# ---- transient growth: একই eigenvalue, ভিন্ন গল্প (fig04-এর হিসাব) ----
J3 = jordan_block(0.9, 3)
v = np.array([0.0, 0.0, 1.0]) # chain-এর চূড়া থেকে শুরু
norms = []
for k in range(120):
norms.append(np.linalg.norm(v))
v = J3 @ v
print(f"peak at k={int(np.argmax(norms))}, norm grew x{max(norms):.1f}")
# peak at k≈18, norm ~40x — eigenvalue 0.9 হওয়া সত্ত্বেও!
# ---- sympy দিয়ে exact JCF মিলিয়ে দেখা (exact arithmetic-এ নিরাপদ) ----
try:
import sympy as sp
As = sp.Matrix([[3, 1], [-1, 1]]) # Example 1-এর matrix
Ps, Js = As.jordan_form()
print(Js) # Matrix([[2, 1], [0, 2]]) — আমাদের হাতের হিসাবের সাথে মিল
except ImportError:
print("sympy নেই — pip install sympy")
Output ব্যাখ্যা:
- Staircase হিসাবে
matrix_rank-এ tolerance দিতে হয়েছে (tol=1e-8) — floating point-এ rank নিজেই কাঁপা-কাঁপা ধারণা; এটাই JCF-এর ভঙ্গুরতার প্রথম আঁচ। - লাফ \(2, 2, 1\) পড়ে block sizes \(\{3, 2\}\) উদ্ধার হলো — random \(P\)-তে লুকানো সত্ত্বেও, কারণ সিঁড়ি similarity-invariant (Property 6)।
- Transient growth: eigenvalue \(0.9\) তবু norm ৪০ গুণ ফুললো — নিজের চোখে না দেখলে বিশ্বাস হয় না বলেই কোডটা রাখা।
sympy.jordan_form()exact (fraction) arithmetic-এ কাজ করে বলে নিরাপদ; NumPy-জাতীয় floating-point জগতে JCF-এর কোনো নির্ভরযোগ্য routine নেই — এটা bug না, গণিতেরই সতর্কবার্তা (Chapter 9.3)।
৭. Worked Examples¶
Example 1 — একটা defective \(2\times2\): chain থেকে \(P^{-1}AP = J\) পর্যন্ত পুরো হিসাব¶
\(A = \begin{bmatrix}3 & 1\\ -1 & 1\end{bmatrix}\)।
ধাপ ১ — Eigenvalue: \(\det(A - \lambda I) = (3-\lambda)(1-\lambda) + 1 = \lambda^2 - 4\lambda + 4 = (\lambda - 2)^2\)। তাই \(\lambda = 2\), algebraic multiplicity \(2\)। চেক: \(2+2 = 4 = \operatorname{tr}A\) ✓, \(2 \cdot 2 = 4 = 3+1 = \det A\) ✓
ধাপ ২ — Eigenvector: \(A - 2I = \begin{bmatrix}1 & 1\\ -1 & -1\end{bmatrix}\) — দুই সারিই বলে \(x + y = 0\)। Eigenspace এক-মাত্রিক: \(v_1 = (1, -1)\)। Geometric multiplicity \(1 < 2\) — defective, diagonalize হবে না; Jordan-এর ডাক পড়লো।
ধাপ ৩ — Chain-এর দোতলা: এমন \(v_2\) চাই যাতে \((A - 2I)v_2 = v_1\):
(দ্বিতীয় সারি \(-x-y = -1\) — একই কথা; consistent হওয়াটাই প্রমাণ যে দোতলা সত্যিই আছে।) সহজতম বাছাই: \(v_2 = (1, 0)\)। চেক: \((A-2I)^2 v_2 = (A-2I)v_1 = 0\) ✓ — \(v_2\) সত্যিই rank-2 generalized eigenvector।
ধাপ ৪ — \(P\) সাজিয়ে যাচাই: \(P = \begin{bmatrix}v_1 & v_2\end{bmatrix} = \begin{bmatrix}1 & 1\\ -1 & 0\end{bmatrix}\), \(\det P = 0 - (-1) = 1 \neq 0\) ✓ (chain independence lemma-র জীবন্ত উদাহরণ)। \(P^{-1} = \begin{bmatrix}0 & -1\\ 1 & 1\end{bmatrix}\)। এবার:
(হাতে মিলিয়ে দেখো: \(Av_2 = (3, -1) = (1,-1) + (2, 0) = v_1 + 2v_2\) ✓।) খেয়াল করো column-এর ক্রম: আগে \(v_1\), পরে \(v_2\) — উল্টালে \(1\)-টা diagonal-এর নিচে চলে যাবে।
Example 2 — \(3\times3\): সিঁড়ি দিয়ে block-গঠন উদ্ধার¶
\(B = \begin{bmatrix}2 & 1 & 1\\ 0 & 2 & 0\\ 0 & 0 & 2\end{bmatrix}\) — triangular, তাই eigenvalue diagonal-এ: \(\lambda = 2\), algebraic multiplicity \(3\)। কিন্তু block-গঠন কী — একটা \(J_3\)? নাকি \(J_2 \oplus J_1\)? নাকি তিনটা \(J_1\)? সিঁড়ি বানাই।
ধাপ ১: \(B - 2I = \begin{bmatrix}0 & 1 & 1\\ 0 & 0 & 0\\ 0 & 0 & 0\end{bmatrix}\) — nonzero সারি একটাই, \(\operatorname{rank} = 1\), তাই \(d_1 = \dim N(B - 2I) = 3 - 1 = 2\)।
ধাপ ২: \((B - 2I)^2\) হিসাব করো: প্রথম সারি \(\times\) প্রতিটা column — \((0,1,1)\) ভেক্টরটা \((B-2I)\)-এর প্রতিটা column-এর সাথে গুণে সব শূন্য (column-গুলো \((0,0,0), (1,0,0), (1,0,0)\) — প্রথম entry-তেই \(0\) বসে)। অতএব \((B-2I)^2 = 0\), \(d_2 = 3\)। সিঁড়ি: \(2 \to 3 \to 3 \to \cdots\)
ধাপ ৩ — সিঁড়ি পড়া: লাফ \(= 2, 1\)। আকার \(\ge 1\) block: \(2\)টা; আকার \(\ge 2\): \(1\)টা। অতএব block sizes \(\{2, 1\}\):
Sanity check: block-যোগফল \(2 + 1 = 3 =\) algebraic multiplicity ✓; block-সংখ্যা \(2 = d_1 =\) geometric multiplicity ✓; বড় block \(2\) = সিঁড়ি থামার ধাপ ✓। একটাও eigenvector না বের করেই পুরো Jordan-গঠন পেয়ে গেলাম — সিঁড়ির শক্তি এটাই।
Example 3 — \(e^{Jt}\): critically damped-এর \(te^{\lambda t}\) derive¶
\(J = J_2(\lambda) = \lambda I + N\), \(N = \begin{bmatrix}0&1\\0&0\end{bmatrix}\)। Matrix exponential-এর সংজ্ঞা (series): \(e^{Mt} = I + Mt + \frac{(Mt)^2}{2!} + \cdots\)
ধাপ ১: \(\lambda I\) আর \(N\) commute করে ⟹ \(e^{Jt} = e^{\lambda I t}\, e^{Nt} = e^{\lambda t}\, e^{Nt}\)। (Commute না করলে এই ভাঙা অবৈধ — matrix exponential-এর এক নম্বর ফাঁদ।)
ধাপ ২: \(N^2 = 0\), তাই series দুই পদেই মরে যায়:
ধাপ ৩ — জোড়া দাও:
অর্থ: \(u' = Ju\)-এর general সমাধানে থাকবে \(e^{\lambda t}\) এবং \(te^{\lambda t}\)। স্প্রিং-ভর system \(x'' + 2\omega x' + \omega^2 x = 0\) (critical damping)-কে first-order-এ নামালে ঠিক এই \(J_2(-\omega)\)-গঠন পাওয়া যায় — সমাধান \(x(t) = (c_1 + c_2 t)e^{-\omega t}\): ওই \(c_2 t\) term-টা Jordan block-এর দান। দোলে না, অথচ পিছলে-নামা exponential-এর চেয়ে এক পলক বেশি সময় "ঝুলে" থাকে — দরজার ক্লোজারে হাত দিলে যেটা টের পাও।
৮. Problems ও Solutions¶
Problem 1. \(A = \begin{bmatrix}4 & 1\\ -1 & 2\end{bmatrix}\)-এর Jordan form \(J\) আর একটা \(P\) বের করো যাতে \(P^{-1}AP = J\)। Trace/determinant দিয়ে eigenvalue যাচাই করতে ভুলো না।
Solution
\(\det(A - \lambda I) = (4-\lambda)(2-\lambda) + 1 = \lambda^2 - 6\lambda + 9 = (\lambda - 3)^2 \Rightarrow \lambda = 3\) (double)। চেক: \(3 + 3 = 6 = \operatorname{tr}\) ✓, \(9 = 8 + 1 = \det\) ✓
\(A - 3I = \begin{bmatrix}1 & 1\\ -1 & -1\end{bmatrix} \Rightarrow x + y = 0 \Rightarrow v_1 = (1, -1)\) — eigenvector একটাই, defective।
Chain: \((A - 3I)v_2 = v_1 \Rightarrow x + y = 1 \Rightarrow v_2 = (1, 0)\) (একটা বাছাই)।
যাচাই: \(Av_1 = (3,-3) = 3v_1\) ✓; \(Av_2 = (4,-1) = v_1 + 3v_2 = (1,-1) + (3,0)\) ✓
Problem 2. \(C = \begin{bmatrix}2 & 0 & 0\\ 1 & 2 & 0\\ 0 & 1 & 2\end{bmatrix}\)-এর null-space সিঁড়ি (\(d_1, d_2, d_3\)) rank হিসাবসহ বের করে Jordan form লেখো।
Solution
\(\lambda = 2\) (triple, triangular)। \(M = C - 2I = \begin{bmatrix}0&0&0\\ 1&0&0\\ 0&1&0\end{bmatrix}\)।
\(\operatorname{rank}M = 2\) (নিচের দুই সারি independent) \(\Rightarrow d_1 = 3 - 2 = 1\)।
\(M^2 = \begin{bmatrix}0&0&0\\ 0&0&0\\ 1&0&0\end{bmatrix}\), rank \(1 \Rightarrow d_2 = 2\); \(M^3 = 0 \Rightarrow d_3 = 3\)।
সিঁড়ি \(1 \to 2 \to 3\): লাফ \(1,1,1\) — আকার \(\ge 1, \ge 2, \ge 3\)-এর block একটা করে ⟹ একটাই block, size 3:
(লক্ষ করো \(C\) নিজে "নিচে-1-ওয়ালা" Jordan-এর মতো — basis-এর ক্রম উল্টে দিলেই standard form।) \(d_1 = 1\) মানে eigenvector-দিক একটাই — geometric multiplicity \(1\), block-ও \(1\)টা ✓
Problem 3. \(N = \begin{bmatrix}0&1&0&0\\ 0&0&1&0\\ 0&0&0&0\\ 0&0&0&0\end{bmatrix}\)। (a) দেখাও \(N\) nilpotent এবং index বের করো। (b) \(N\)-এর (নিজের) Jordan form কী? (c) এ থেকে সাধারণ সত্যটা লেখো: nilpotent matrix-এর JCF দেখতে কেমন?
Solution
(a) \(N^2\)-এ একমাত্র nonzero entry: \((1,3)\)-এ \(1\) (কারণ \(e_3 \mapsto e_2 \mapsto e_1\))। \(N^3 = 0\)। কাজেই nilpotent, index \(3\)।
(b) \(\lambda = 0\) (nilpotent-এর একমাত্র eigenvalue — Property 1-এর lemma)। সিঁড়ি: \(\operatorname{rank}N = 2 \Rightarrow d_1 = 2\); \(\operatorname{rank}N^2 = 1 \Rightarrow d_2 = 3\); \(N^3 = 0 \Rightarrow d_3 = 4\)। লাফ \(2, 1, 1\) ⟹ block sizes \(\{3, 1\}\):
(\(N\)-এর গঠনেই দেখা যায়: \(e_3 \to e_2 \to e_1 \to 0\) একটা ৩-ধাপ chain, আর \(e_4 \to 0\) একা — একজন এক ঘরে!)
(c) Nilpotent matrix-এর JCF-এ diagonal পুরো শূন্য — শুধু \(J_m(0)\) block। উল্টোভাবে: JCF-এর diagonal-এ সব \(0\) মানেই matrix nilpotent (সবচেয়ে বড় block \(m\) হলে \(J^m = 0\)) — Property 1-এর "উল্টো দিক"-টার প্রমাণ এটাই।
Problem 4. প্রমাণ করো: \(\lambda\)-র geometric multiplicity \(=\) JCF-এ \(\lambda\)-ওয়ালা Jordan block-এর সংখ্যা।
Solution
গল্প: eigenvector গুনবো \(J\)-তে — কারণ similarity সংখ্যাটা বদলায় না — আর \(J\)-তে গোনা সহজ: প্রতিটা ফ্ল্যাটের মেঝেতে ঠিক একজন দাঁড়িয়ে।
ধাপ ১: \(A = PJP^{-1}\) হলে \(A - \lambda I = P(J - \lambda I)P^{-1}\), তাই \(\dim N(A - \lambda I) = \dim N(J - \lambda I)\) (\(v \mapsto P^{-1}v\) দুই null space-এর মধ্যে bijection)।
ধাপ ২: \(J - \lambda I\) block-diagonal; null space-ও block ধরে ভাগ হয়: \(\dim N(J - \lambda I) = \sum_{\text{blocks}} \dim N(J_m(\mu) - \lambda I)\)।
ধাপ ৩ (block-ভিত্তিক গণনা): \(\mu \neq \lambda\) হলে \(J_m(\mu) - \lambda I\) triangular, diagonal-এ সব \(\mu - \lambda \neq 0\) ⟹ determinant \(\neq 0\) ⟹ null space \(\{0\}\), অবদান \(0\)। আর \(\mu = \lambda\) হলে \(J_m(\lambda) - \lambda I = N_m\) (shift): \(N_m x = 0 \Rightarrow x_2 = \cdots = x_m = 0\), \(x_1\) free ⟹ dimension ঠিক \(1\)।
যোগফল: প্রতিটা \(\lambda\)-block দেয় \(1\), অন্যরা \(0\) ⟹ geometric multiplicity \(=\) \(\lambda\)-block সংখ্যা। ∎
Problem 5. Binomial সূত্রে \(J_3(\lambda)^k\)-এর general রূপ বের করো এবং \(k = 2\)-তে সরাসরি গুণ করে মিলিয়ে দেখো।
Solution
\(J_3(\lambda) = \lambda I + N\), \(N = J_3(0)\), \(N^3 = 0\); \(\lambda I\) ও \(N\) commute করে ⟹
(\(N^3 = 0\) বলে series তিন পদেই শেষ।) \(k = 2\) যাচাই: সূত্র বলে entries \(\lambda^2, 2\lambda, 1\); সরাসরি গুণ:
লক্ষ করো: কোণার entry \(\binom{k}{2}\lambda^{k-2}\) — \(k\)-তে quadratic বৃদ্ধি; fig04-এর \(40\)-গুণ ফোলাটা এরই কীর্তি। Size-\(m\) block-এ degree \(m-1\) পর্যন্ত polynomial ফ্যাক্টর আসে।
Problem 6. প্রমাণ করো: \(A\) আর \(A^T\)-এর Jordan form-এ একই \(\lambda\)-র একই আকারের block একই সংখ্যায় থাকে (অর্থাৎ block-গঠন অভিন্ন)।
Solution
গল্প: Property 4/6 বলেছে block-গঠন পুরোপুরি নির্ধারিত হয় সিঁড়ি দিয়ে — অর্থাৎ \(\operatorname{rank}((A - \lambda I)^k)\) সংখ্যাগুলো দিয়ে। তাহলে দেখালেই চলবে যে \(A\) আর \(A^T\)-এর এই সংখ্যাগুলো সব মিলে যায়। আর rank-এর সবচেয়ে পুরনো ধর্মটা মনে করো (Part IV): transpose-এ rank বদলায় না।
ধাপ ১ (eigenvalue এক): \(\det(A^T - \lambda I) = \det((A - \lambda I)^T) = \det(A - \lambda I)\) (Chapter 6.1: \(\det M^T = \det M\)) ⟹ একই characteristic polynomial, একই \(\lambda\)-রা একই algebraic multiplicity-তে।
ধাপ ২ (সিঁড়ি এক): প্রতিটা \(\lambda\) আর \(k\)-র জন্য
(transpose-এ rank অটুট — row rank \(=\) column rank, Part IV)। তাহলে \(d_k\)-রা, অতএব সব লাফ, অতএব প্রতিটা আকারের block-সংখ্যা — সব অভিন্ন। ∎
ফল: \(A\) ও \(A^T\) সবসময় similar — যদিও একই \(P\) দুজনকে সোজা করে না।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "Algebraic multiplicity \(=\) block-এর আকার" | Algebraic multiplicity \(= \lambda\)-র সব block-এর আকারের যোগফল (\(\dim G_\lambda\))। একটা block-এর আকার আলাদা জিনিস; সবচেয়ে বড়টার আকার \(=\) সিঁড়ি থামার ধাপ। fig03-এ \(\lambda=2\): multiplicity \(5\), কিন্তু block দুটো (\(3+2\))। |
| "Generalized eigenvector মানেই eigenvector" | উল্টোটা সত্যি: প্রতিটা eigenvector generalized (\(k=1\)), কিন্তু rank \(\ge 2\)-এর generalized eigenvector eigenvector না — \((A-\lambda I)v \neq 0\)। Example 1-এর \(v_2\): \(Av_2 = (4,-1) \neq 3v_2\) — কিন্তু হিসাব করে দেখো, ওটা \(\lambda=3\)-ওয়ালা matrix ছিল; মোদ্দা কথা \(Av_2 = \lambda v_2 + v_1 \neq \lambda v_2\)। |
| "JCF computer-এ compute করা যায় নিশ্চিন্তে" | Floating point-এ না। \(J_2(2)\)-এর \((2,1)\) ঘরে \(\varepsilon = 10^{-15}\) বসাও: eigenvalue হয়ে যায় \(2 \pm \sqrt{\varepsilon} \approx 2 \pm 3\times10^{-8}\) — block ভেঙে দুটো \(J_1\)! (লক্ষ করো \(\sqrt{\varepsilon} \gg \varepsilon\) — ভাঙন perturbation-এর চেয়ে কোটি গুণ বড়, এই অসামঞ্জস্যই Chapter 9.3-এর বিষয়।) Practical কাজে Schur form/SVD। |
| "সব real matrix-এর real JCF আছে" | Rotation matrix-এর eigenvalue-ই complex (Chapter 6.2) — real \(P\) দিয়ে উপরের-ত্রিভুজ কিছুতেই হবে না। JCF theorem-এর ঘর \(\mathbb{C}\) — Chapter 9.1-এর algebraic closedness ছাড়া প্রথম ধাপই আটকে যায়। (ℝ-এর জন্য "real Jordan form" আছে — \(2\times2\) rotation-block সহ — কিন্তু সেটা অন্য পোশাক।) |
| "\(\vert \lambda\vert < 1\) মানেই \(\|A^k v\|\) প্রথম থেকে কমে" | Defective (আরো সাধারণভাবে non-normal) matrix-এ transient growth: \(k\lambda^{k-1}\)-জাতীয় ফ্যাক্টর প্রথমে বহুগুণ ফোলায়, decay আসে পরে (fig04)। "শেষমেশ কমবে" ঠিক, "এখনই কমবে" ভুল। |
| "Chain-এর \(v_2\) unique" | না — \(v_2\)-এর সাথে \(v_1\)-এর যেকোনো গুণিতক যোগ করলেও chain বৈধ থাকে (\((A-\lambda I)(v_2 + cv_1) = v_1\))। \(P\) unique না, \(J\)-ই unique (block-ক্রম বাদে)। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Jordan block \(J_m(\lambda)\) | diagonal-এ \(\lambda\), superdiagonal-এ \(1\) | শেয়ার্ড ফ্ল্যাট: একজন আরেকজনের ঘাড়ে হেলান |
| JCF theorem | ℂ-তে সব \(A\): \(P^{-1}AP = J\), block-রা unique | diagonal না হলে "প্রায়-diagonal" — সবচেয়ে কাছের স্টেশন |
| Generalized eigenvector | \((A-\lambda I)^k v = 0\) | eigenvector-এর ঘাটতি পূরণের লোকবল |
| Jordan chain | \(v_m \mapsto \cdots \mapsto v_1 \mapsto 0\); সবসময় independent | মই বেয়ে নামা; প্রতি block = এক chain |
| Nilpotent \(N^m = 0\) | একমাত্র eigenvalue \(0\); \(J_m(\lambda) = \lambda I + N_m\) | প্রতি ধাক্কায় এক তলা নিচে |
| সিঁড়ি \(d_k = \dim N((A-\lambda I)^k)\) | \(d_1 =\) block সংখ্যা; লাফ \(=\) size \(\ge k\) block; থামে বড় block-এ; ছাদ \(=\) alg. mult. | matrix-এর এক্স-রে |
| \(J^k\) | \(J_2^k = \begin{bmatrix}\lambda^k & k\lambda^{k-1}\\ 0 & \lambda^k\end{bmatrix}\) (binomial) | polynomial ফ্যাক্টর ⟹ transient growth |
| \(e^{Jt}\) | \(e^{\lambda t}\begin{bmatrix}1&t\\0&1\end{bmatrix}\) | ODE-র \(te^{\lambda t}\); critically damped |
| সততা | JCF exact গণিতে রাজা, floating point-এ ভঙ্গুর | কাগজে Jordan, computer-এ Schur/SVD |
পরের chapter-এর সেতু: Jordan form আমাদের দেখালো matrix-রা ভেতরে ভেতরে কতটা জটিল হতে পারে — আর সেই জটিলতা এক ফোঁটা perturbation-এই ভেঙে পড়ে: \(10^{-15}\)-এর ধুলোয় block চুরমার, eigenvalue লাফ দেয় \(10^{-8}\)। তাহলে প্রশ্ন দাঁড়ায়: matrix-এর "সাইজ" মাপবো কীভাবে, আর ইনপুট একটু নড়লে eigenvalue/solution ঠিক কতটা নড়ে — কার নড়া ভদ্র, কার নড়া বিপজ্জনক? Matrix norm, condition number আর perturbation theory — Chapter 9.3-এ আমরা matrix-দের কাঁপুনি মাপতে শিখবো।
📓 Notebook Project¶
notebooks/part-09/ch02-project.ipynb — null-space staircase দিয়ে Jordan structure detect করা, Jordan block-এর \(A^k\) transient growth experiment, diagonalizable vs defective পাশাপাশি।