Chapter 9.6 — Tensor Decompositions (টেনসর ডিকম্পোজিশন — CP, Tucker; আধুনিক ML-এর সংযোগ)¶
এই পুরো বইয়ে আমাদের data ছিলো দুই index-এর বন্দি: row আর column। একটা matrix \(M_{ij}\) — এক index সারি, এক index স্তম্ভ। কিন্তু বাস্তবের data প্রায়ই তার চেয়ে মোটা। একটা রঙিন ছবি: উচ্চতা × প্রস্থ × রঙ — তিন index। একটা ভিডিও: + সময়, চার। Netflix-এর "user কোন movie-কে কোন সময়ে কত রেটিং দিলো" — user × movie × time, তিন index। এই বহু-index বস্তুটার নাম Tensor(টেনসর), আর matrix-এর সব প্রিয় অস্ত্র — rank, SVD, eigenvalue-decomposition — এখানে এসে কেউ টিকে যায়, কেউ ভেঙে পড়ে চমকপ্রদভাবে। SVD-র বিখ্যাত uniqueness আর Eckart–Young (Part V-VI) tensor-এ আর সত্য নয়; অথচ SVD-তে যা কখনো ছিলো না — সেই essential uniqueness — CP decomposition-এ ফিরে আসে এক গভীর কারণে। এটাই এই chapter-এর নাটক: matrix থেকে tensor-এ উঠে গিয়ে দেখা, কোন সত্য universal আর কোনটা শুধু দুই-index-এর সৌভাগ্য। আর শেষে দেখবো কেন এই "tensor" শব্দটাই আজ modern ML-এর কেন্দ্রে — PyTorch, TensorFlow, GPT-র প্রতিটা weight।
🎯 এই chapter-এ যা শিখবে¶
- Tensor(টেনসর) কী — order, mode, fiber, slice; আর matrix-এর ধারণাগুলোর স্বাভাবিক সাধারণীকরণ
- CP Decomposition(সিপি ডিকম্পোজিশন / PARAFAC): \(\mathcal{T} = \sum_r \lambda_r\, a_r \circ b_r \circ c_r\) — SVD-র সরাসরি বড় ভাই, আর তার essential uniqueness (Kruskal-এর উপপাদ্য)
- Tucker Decomposition(টাকার ডিকম্পোজিশন) ও HOSVD: core tensor + প্রতি mode-এ একটা factor matrix — subspace-এর সাধারণীকরণ
- Tensor rank-এর দুঃসংবাদ: rank নির্ণয় NP-hard, Eckart–Young ভেঙে পড়ে, best rank-\(r\) approximation-ই থাকতে পারে না — কেন এবং তার তাৎপর্য
- ALS(অল্টারনেটিং লিস্ট স্কোয়ার্স) algorithm আর modern ML-এ tensor: neural network, tensor decomposition দিয়ে model compression, latent factor আবিষ্কার
🖼️ এক ছবিতে মূল idea¶
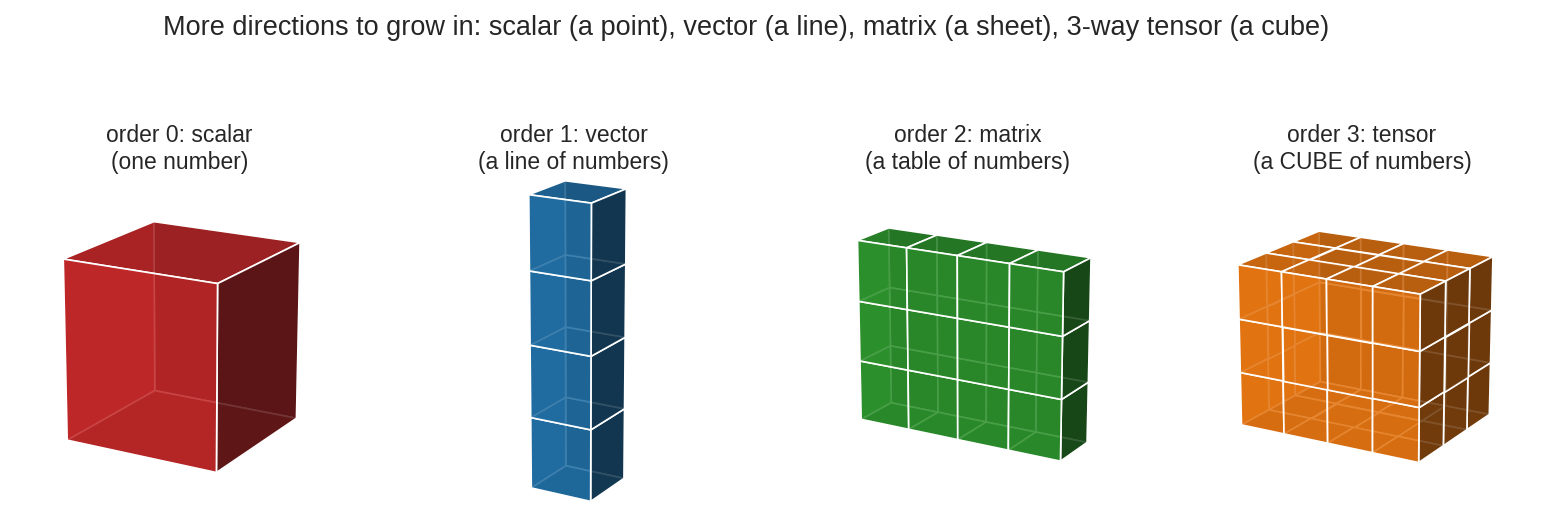
গণিতের বস্তুগুলোর সিঁড়ি: scalar (order-0, একটা সংখ্যা — একটা বিন্দু), vector (order-1, সংখ্যার একটা রেখা), matrix (order-2, সংখ্যার একটা পাতা/টেবিল), আর 3-way tensor (order-3, সংখ্যার একটা ঘনক)। প্রতি ধাপে একটা নতুন "বাড়ার দিক" (mode/index) যোগ হচ্ছে। Tensor মানে শুধু "আরো index" — কিন্তু এই এক index বাড়ার সাথেই গণিতের নিয়ম কতটা বদলায়, সেটাই এই chapter-এর বিস্ময়।
১. কি? (What)¶
দৈনন্দিন analogy: টেবিল থেকে ঘনক¶
একটা স্প্রেডশিট ভাবো — সারি আর কলাম, দুই দিক। এটা matrix। এবার ভাবো অনেকগুলো স্প্রেডশিট একটার পেছনে আরেকটা সাজানো — যেমন প্রতি মাসে একটা করে বিক্রির টেবিল, ১২ মাসের জন্য ১২টা টেবিল। এই পুরো স্তূপটা একটা 3-way tensor: সারি (পণ্য) × কলাম (দোকান) × গভীরতা (মাস)। একটা সংখ্যা পড়তে এখন তিনটা সূচক লাগে: কোন পণ্য, কোন দোকান, কোন মাস — \(t_{ijk}\)।
Matrix ছিলো "সমতল পাতা", tensor হলো "ঘনক" (বা আরো বেশি মাত্রায়, যা কল্পনার বাইরে কিন্তু গণিতে ঠিক)। মূল কথা সরল: tensor = বহু-index array। কিন্তু এই সরলতার পেছনে লুকিয়ে গভীর গণিত।
সংজ্ঞা: Tensor, order, mode¶
একটা order-\(N\) tensor (বা \(N\)-way tensor) হলো একটা multi-dimensional array \(\mathcal{T} \in \mathbb{R}^{I_1 \times I_2 \times \dots \times I_N}\), যার একটা element পড়তে \(N\)টা সূচক লাগে: \(t_{i_1 i_2 \dots i_N}\)।
- Order(অর্ডার): কতগুলো index/mode — scalar (0), vector (1), matrix (2), 3-way tensor (3), ...
- Mode(মোড): প্রতিটা দিক/index-কে একটা mode বলে। একটা 3-way tensor-এর mode-1 (সারি), mode-2 (কলাম), mode-3 (গভীরতা)।
- সতর্কতা: এখানে "tensor" মানে physics/differential geometry-র রূপান্তর-নিয়মওয়ালা tensor নয় — শুধু multi-way array। ML/data science-এর "tensor" এই অর্থেই (PyTorch-এর
torch.Tensor-ও তাই)।
সংজ্ঞা: Fiber ও Slice — tensor-এর শারীরস্থান¶
Matrix-এ row আর column ছিলো। Tensor-এ তাদের সাধারণীকরণ:
- Fiber(ফাইবার): একটা index ছাড়া বাকি সব স্থির রেখে যে vector পাও। Matrix-এর column = mode-1 fiber, row = mode-2 fiber। 3-way tensor-এ mode-3 fiber (\(t_{ij:}\))-কে বলে tube(টিউব)।
- Slice(স্লাইস): ঠিক একটা index স্থির রেখে যে matrix পাও। 3-way tensor-এর frontal slice (\(T_{::k}\)) = \(k\)-তম "পাতা"।
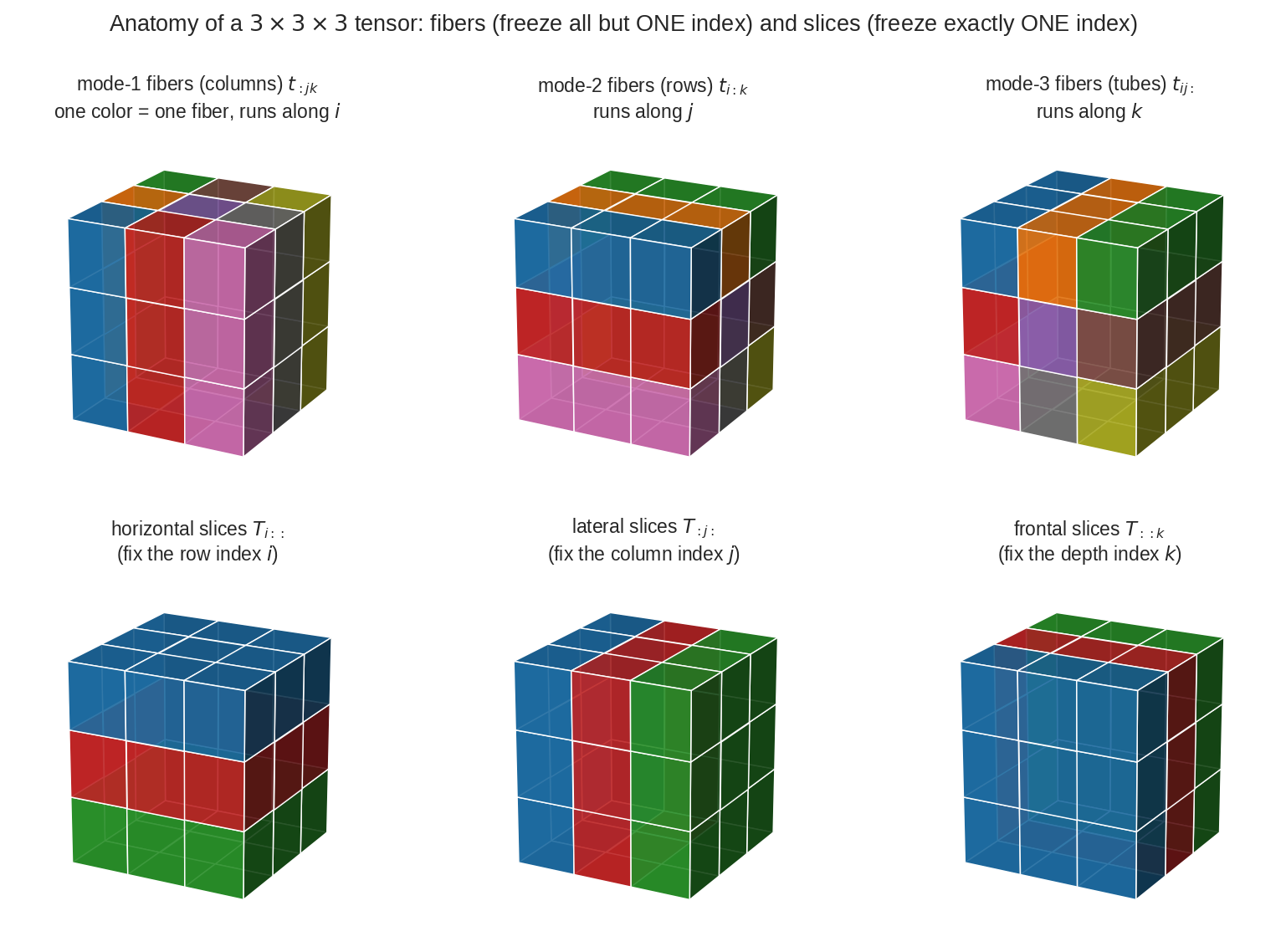
একটা \(3\times3\times3\) tensor-এর শারীরস্থান। ওপরের সারি — fiber (সব-index-বাদে-একটা স্থির): mode-1 fiber (column, \(i\)-বরাবর চলে), mode-2 fiber (row, \(j\)-বরাবর), mode-3 fiber (tube, \(k\)-বরাবর); প্রতিটা রঙ একটা fiber। নিচের সারি — slice (ঠিক-একটা-index স্থির): horizontal, lateral, frontal slice, প্রতিটা একটা matrix। Matrix-এর row/column-এর ঠিক এই সাধারণীকরণেই tensor decomposition দাঁড়িয়ে আছে।
Rank-1 tensor ও outer product¶
Matrix-এ rank-1 ছিলো \(\mathbf{u}\mathbf{v}^T\) (দুই vector-এর outer product) — element \((uv^T)_{ij} = u_iv_j\)। Tensor-এ সরাসরি সাধারণীকরণ: একটা rank-1 tensor হলো \(N\)টা vector-এর outer product:
(\(\circ\) = outer product)। এই একটা ধারণাই CP decomposition-এর পুরো ভিত্তি — ঠিক যেমন rank-1 matrix ছিলো SVD-র ইট।
২. দেখতে কেমন?¶
দৃশ্য ১: CP decomposition — rank-1 tensor-এর যোগফল¶
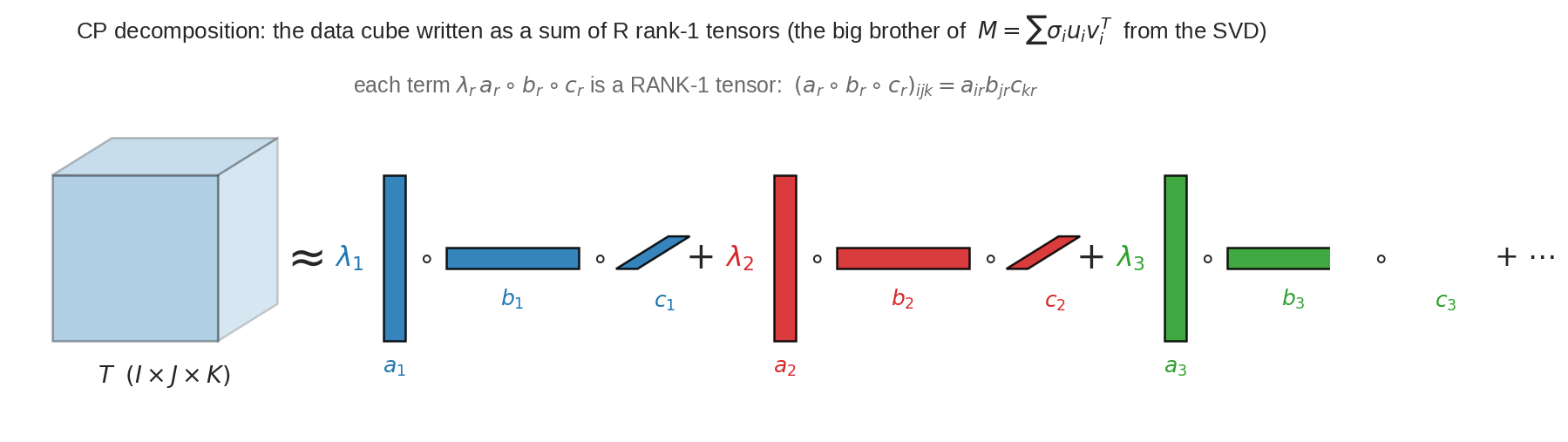
CP decomposition এক ছবিতে: বিশাল data ঘনক \(\mathcal{T}\)-কে লেখা হয় কয়েকটা rank-1 tensor-এর যোগফল হিসেবে — প্রতিটা term \(\lambda_r\, a_r \circ b_r \circ c_r\), যেখানে \(a_r\) (লম্বা column), \(b_r\) (চওড়া row), \(c_r\) (গভীরতা-বরাবর bar) তিন mode-এর vector। ঠিক যেমন SVD ছিলো \(M = \sum_i \sigma_i u_i v_i^T\) (rank-1 matrix-এর যোগ), CP হলো তার তিন-mode সংস্করণ — SVD-র বড় ভাই। পার্থক্য: matrix-এ \(u_i, v_i\) orthogonal হতে বাধ্য, tensor-এ \(a_r, b_r, c_r\)-দের সেই বাধ্যতা নেই — আর সেখান থেকেই সব রহস্য।
দৃশ্য ২: Tucker decomposition — core + factor matrix¶

Tucker decomposition ভিন্ন দর্শন: একটা ছোট core tensor \(\mathcal{G}\) (\(R_1 \times R_2 \times R_3\)) + প্রতি mode-এ একটা factor matrix (\(U_1, U_2, U_3\))। core \(\mathcal{G}\) ধরে রাখে mode-এর factor-দের মধ্যে "কে কার সাথে কত জোরে মেশে" — সব interaction। \(U_n\) হলো mode-\(n\)-এর orthonormal basis (তার unfolding-এর SVD থেকে — এই বিশেষ পথটাই HOSVD)। মূল বিন্দু (লাল লেখা): core যদি superdiagonal হয় (\(g_{rrr} = \lambda_r\), বাকি সব \(0\)) আর \(R_1 = R_2 = R_3\), তাহলে Tucker ঠিক CP হয়ে যায় — CP হলো Tucker-এর একটা বিশেষ কেস।**
দৃশ্য ৩: rank খুঁজে বের করা — ALS-এর elbow¶
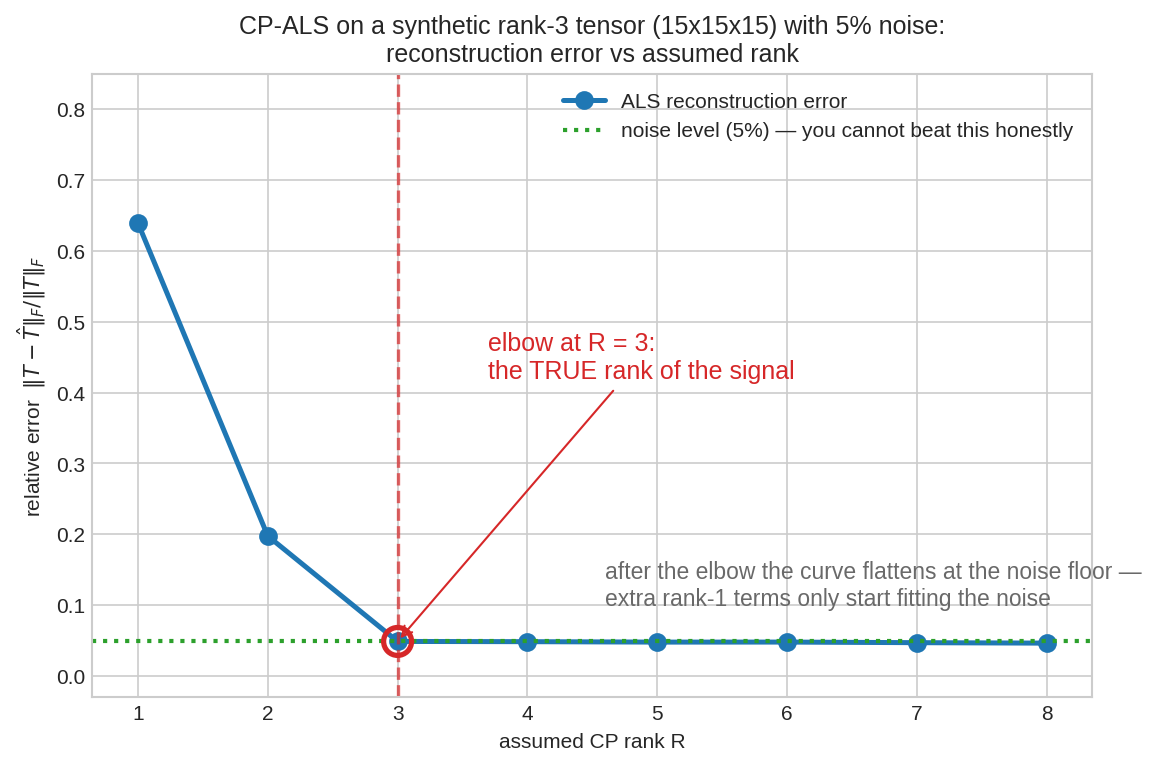
একটা সিন্থেটিক rank-\(3\) tensor (\(15\times15\times15\)) + \(5\%\) noise-এ CP-ALS চালিয়ে বিভিন্ন assumed rank-এ reconstruction ভুল। rank \(1, 2\)-তে ভুল বড় (আসল কাঠামো ধরা পড়েনি); rank \(3\)-এ (লাল বৃত্ত) হঠাৎ ভুল ধসে পড়ে noise-floor (\(5\%\), সবুজ রেখা)-এ — এটাই elbow, tensor-এর আসল rank। তারপর rank বাড়ালে ভুল আর কমে না (শুধু noise fit করা শুরু)। SVD-র singular value-র পতন যেমন matrix-এর rank বলে দিতো, ALS-এর এই elbow তেমনি tensor-এর rank ইঙ্গিত করে — যদিও tensor-এ (§৪-এ দেখবে) rank নির্ণয় গণিতগতভাবে অনেক কঠিন।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- Chemometrics (রসায়ন): fluorescence spectroscopy-তে নমুনা × excitation তরঙ্গদৈর্ঘ্য × emission তরঙ্গদৈর্ঘ্য — একটা 3-way tensor। CP decomposition (এখানে PARAFAC নামে বিখ্যাত, ১৯৭০) প্রতিটা রাসায়নিক উপাদানকে একটা rank-1 term হিসেবে আলাদা করে ফেলে — essential uniqueness-এর কারণে (§৪), যা এই ক্ষেত্রকে বিপ্লবী করেছে।
- Neuroscience: EEG data — channel × সময় × trial/frequency; tensor decomposition দিয়ে মস্তিষ্কের কার্যকলাপের লুকানো pattern বের করা।
- Signal processing / communications: array antenna-র signal (space × time × frequency) — CP দিয়ে source আলাদা করা (blind source separation)।
Data Science / ML-এ:
- Recommendation (context-aware): user × item × context (সময়/স্থান/মেজাজ) — matrix factorization-এর tensor সাধারণীকরণ, প্রতিটা latent factor একটা rank-1 term।
- Deep learning-এর ভাষা: PyTorch/TensorFlow-র প্রতিটা array একটা "tensor"; একটা batch-এর ছবি (batch × height × width × channel) 4-way tensor। এই বইয়ের tensor-এর গণিত সেই framework-গুলোর নামেই বাঁচে।
- Model compression: neural network-এর বড় weight tensor (বিশেষত convolution kernel) Tucker/CP decomposition দিয়ে ছোট করা — কম parameter, দ্রুত inference (Chapter 8.4-এর low-rank compression-এর tensor সংস্করণ)।
- Knowledge graph embedding: (subject, relation, object) triple = একটা binary tensor; CP/Tucker-ধাঁচের decomposition (RESCAL, TuckER) দিয়ে entity ও relation-এর embedding শেখা।
- Multi-way latent factor: topic modeling, community detection-এর tensor সংস্করণ — যেখানে দুই-দিকের matrix method যথেষ্ট নয়।
৪. Properties¶
Part IX-এর কঠোরতায়, এখানে property-গুলো theorem হিসেবে দেখানো — কোথায় matrix-এর সত্য বেঁচে থাকে, কোথায় ভাঙে।
Property 1 — CP হলো SVD-র সরাসরি সাধারণীকরণ¶
Matrix SVD: \(M = \sum_{i=1}^{r}\sigma_i u_i v_i^T = \sum_i \sigma_i (u_i \circ v_i)\) — rank-1 matrix-এর যোগ। CP তার তিন-mode অনুরূপ:
সবচেয়ে ছোট \(R\) যাতে এই সমতা ঠিক হয়, সেটাই tensor-এর CP rank (rank)। কিন্তু এখানেই মিল শেষ, আর অমিল শুরু (Property 2–4)।
Property 2 — Tensor rank matrix rank-এর চেয়ে বন্য¶
Matrix rank ছিলো ভদ্র: \(\text{rank} \le \min(m, n)\), আর real বনাম complex-এ একই। Tensor rank বেয়াড়া:
- একটা \(I \times J \times K\) tensor-এর rank \(\min(IJ, JK, IK)\) পর্যন্ত হতে পারে — mode-আকারের চেয়ে বড় (\(2\times2\times2\) tensor-এর rank \(3\) পর্যন্ত হতে পারে, যদিও কোনো mode \(2\)-এর বেশি নয়!)।
- Field-নির্ভর: একই real tensor-এর rank real-এ \(3\) কিন্তু complex-এ \(2\) হতে পারে — matrix-এ যা কখনো ঘটে না।
- Rank নির্ণয় NP-hard: একটা tensor-এর rank কত, সেটা বের করার কোনো দক্ষ (polynomial-time) algorithm জানা নেই — matrix-এ যা ছিলো তুচ্ছ (SVD-র nonzero singular value গোনা)।
Property 3 — Eckart–Young ভেঙে পড়ে: best low-rank approximation থাকতেই পারে না¶
Matrix-এ Eckart–Young (Part VI): সেরা rank-\(k\) approximation = top-\(k\) SVD, সবসময় অস্তিত্ব আছে, সবসময় সেরা। Tensor-এ এটা মিথ্যা। একটা চাঞ্চল্যকর ঘটনা (de Silva–Lim, 2008): কিছু tensor-এর best rank-\(r\) approximation-ই থাকে না — একটা rank-\(r\) term-এর ক্রম ভুলটাকে ছোট থেকে ছোটতর করতে পারে, কিন্তু কোনো নির্দিষ্ট best-এ কখনো পৌঁছায় না (infimum আছে, minimum নেই)। এই ঘটনাকে বলে border rank \(<\) rank, আর এটাই কেন tensor approximation algorithm (ALS) কখনো "ঝুলে" যায় বা অস্থির হয়।
Property 4 — CP-র essential uniqueness: যা SVD-তে কখনো ছিলো না¶
এবার মুদ্রার উজ্জ্বল দিক। Matrix factorization \(M = AB\) অনন্য নয় — যেকোনো invertible \(Q\)-এর জন্য \(M = (AQ)(Q^{-1}B)\)ও চলে (rotation-এর স্বাধীনতা)। এজন্যই SVD-তে orthogonality চাপাতে হয়, তবু repeated singular value-এ ঘূর্ণনের স্বাধীনতা থাকে। CP-তে, বিস্ময়করভাবে, decomposition প্রায়ই essentially unique — permutation আর scaling ছাড়া অন্য কোনো স্বাধীনতা নেই, কোনো orthogonality না চাপিয়েই।
Kruskal-এর উপপাদ্য (১৯৭৭): factor matrix \(A, B, C\)-এর Kruskal rank (\(k\)-rank: সবচেয়ে বড় \(k\) যাতে যেকোনো \(k\)টা column linearly independent) \(k_A, k_B, k_C\) হলে, CP decomposition essentially unique হয় যদি
এই uniqueness-ই CP-কে chemistry/neuroscience-এ এত শক্তিশালী করে: বের করা rank-1 term-গুলো অর্থবহ, physical component — ঘোরানো-যায়-না বলে ব্যাখ্যাযোগ্য (§৫-এ intuition)।
Property 5 — Tucker সবসময় থাকে, HOSVD তার SVD-অনুরূপ¶
CP-র বিপরীতে, Tucker decomposition সবসময় অস্তিত্ব আছে (যেকোনো tensor, যেকোনো mode-rank-এ), আর truncated HOSVD একটা ভালো (quasi-optimal) approximation দেয় — Eckart–Young ঠিক নয়, কিন্তু কাছাকাছি: সেরার চেয়ে বড়জোর \(\sqrt{N}\) গুণ ভুল (\(N\) = order)। তাই বাস্তব compression-এ Tucker/HOSVD নিরাপদ ও নির্ভরযোগ্য, যেখানে CP অস্থির হতে পারে। বিনিময়: Tucker-এর uniqueness নেই (\(U_n\)-দের ঘোরানো যায়), তাই তার factor CP-র মতো "physical" নয় — subspace বলে, individual component নয়।
৫. Intuition — কেন সত্য?¶
পথ ১: কেন rank-1 tensor-এর যোগ = "বিশুদ্ধ প্যাটার্ন"-এর যোগ¶
একটা rank-1 tensor \(a \circ b \circ c\)-কে পড়ো: element \(t_{ijk} = a_ib_jc_k\) — মানে "mode-1-এ প্যাটার্ন \(a\), mode-2-এ \(b\), mode-3-এ \(c\), আর তিনটা স্বাধীনভাবে গুণিত"। এটা একটা "বিশুদ্ধ, বিচ্ছিন্ন-যোগ্য (separable)" প্যাটার্ন। যেমন রসায়নে: একটা বিশুদ্ধ রাসায়নিক উপাদানের fluorescence — তার নিজস্ব excitation প্রোফাইল (\(a\)) × নিজস্ব emission প্রোফাইল (\(b\)) × নমুনায় তার ঘনত্ব (\(c\))। CP decomposition তাই বলছে: "পুরো মিশ্রণ = কয়েকটা বিশুদ্ধ উপাদানের যোগফল" — প্রতিটা term একটা উপাদান। এই physical অর্থই CP-কে matrix-এর abstract SVD থেকে আলাদা, বাস্তব-জগৎ-সংলগ্ন করে।
পথ ২: essential uniqueness-এর গোপন কারণ — তিন mode "একে অপরকে আটকে রাখে"¶
কেন matrix factorization ঘোরানো যায় কিন্তু CP যায় না? matrix-এ দুই mode (\(A, B\)): \(M = AB^T\)-তে \(A \to AQ, B \to BQ^{-T}\) করলে \(M\) অপরিবর্তিত — দুই mode একে অপরের ঘূর্ণন "শুষে নিতে" পারে। কিন্তু CP-তে তিন mode (\(a_r, b_r, c_r\)): এক mode-এ ঘোরালে সেই ঘূর্ণন বাকি দুই mode একসাথে শুষতে পারে না (একটা invertible \(Q\) দিয়ে তিনটা term-কে একসাথে সামঞ্জস্য রাখা অসম্ভব, generic ক্ষেত্রে)। তিন mode-এর এই "পারস্পরিক আটকে রাখা"-ই uniqueness-এর উৎস। এক অতিরিক্ত mode — এক অতিরিক্ত সীমাবদ্ধতা — আর সেটাই ঘূর্ণনের স্বাধীনতা কেড়ে নেয়। (Kruskal-এর \(k_A+k_B+k_C \ge 2R+2\) শর্তটা এই "যথেষ্ট আটকে রাখা" ঘটার গাণিতিক পরিমাপ।)
একটা ছোট concrete দৃষ্টান্ত: matrix \(\begin{bmatrix}1&0\\0&1\end{bmatrix} = e_1e_1^T + e_2e_2^T\), কিন্তু \(= \frac12(e_1{+}e_2)(e_1{+}e_2)^T + \frac12(e_1{-}e_2)(e_1{-}e_2)^T\)-ও — একই matrix, দুই ভিন্ন rank-2 decomposition (rotation-এর স্বাধীনতা)। tensor-এ generic ক্ষেত্রে এই দ্বিতীয় বিকল্প থাকে না — decomposition-টা একটাই (permutation/scaling বাদে)।
পথ ৩: কেন Eckart–Young ভাঙে — border rank-এর ছবি¶
Matrix-এ rank একটা "বন্ধ" ধর্ম: rank-\(\le k\) matrix-দের set বন্ধ (closed) — সীমা নিলেও rank বাড়ে না, তাই best approximation সবসময় ওই set-এ পাওয়া যায়। Tensor-এ rank-\(\le R\) set বন্ধ নয়। একটা rank-3 tensor-এর দিকে rank-2 tensor-দের একটা sequence যেতে পারে যত কাছে খুশি, কিন্তু কখনো "পৌঁছায় না" — সীমাবিন্দুটা rank-3, যদিও প্রতিটা পদ rank-2। ভাবো: \(\frac{1}{\epsilon}\big[(a{+}\epsilon a')\circ(b{+}\epsilon b')\circ(c{+}\epsilon c') - a\circ b\circ c\big]\) — \(\epsilon \to 0\)-এ এটা একটা rank-3 tensor-এ যায়, অথচ প্রতিটা \(\epsilon\)-এ rank-2। এই "border" ঘটনাই বলে: rank-2-এর মধ্যে best approximation থাকতে পারে না (infimum আছে, কিন্তু minimum ওই set-এ নেই)। matrix-এ singular value-র discreteness এই সমস্যা আটকাতো; তিন-mode-এ সেই রক্ষাকবচ নেই।
পথ ৪: কেন Tucker সবসময় থাকে — এটা আসলে subspace-এর গল্প¶
Tucker-এর নিরাপত্তা আসে ভিন্ন প্রশ্ন থেকে। CP জিজ্ঞেস করে "কয়টা rank-1 term?" — কঠিন প্রশ্ন। Tucker জিজ্ঞেস করে "প্রতিটা mode-এর fiber-গুলো কোন subspace-এ থাকে?" — আর এটা তুচ্ছ প্রশ্ন! প্রতিটা mode-এর unfolding (tensor-কে ওই mode বরাবর matrix-এ চ্যাপ্টা করা) একটা সাধারণ matrix, তার SVD সবসময় থাকে (Part VI), তার top singular vector-ই \(U_n\) (এটাই HOSVD)। যেহেতু প্রতিটা mode-এ শুধু একটা matrix-SVD, Tucker উত্তরাধিকারসূত্রে matrix-জগতের সব ভদ্রতা পায়: অস্তিত্ব, স্থিতিশীলতা, quasi-optimality। বিনিময়ে সে হারায় uniqueness — কারণ subspace-এর basis ঘোরানো যায় (SVD-র সেই পুরনো স্বাধীনতা)। এক লাইনে: Tucker = তিনটা matrix-SVD একসাথে (নিরাপদ, unique নয়); CP = সত্যিকারের tensor প্রশ্ন (শক্তিশালী, unique, কিন্তু বন্য)।
পথ ৫: কেন ALS কাজ করে (এবং কখন আটকায়)¶
CP rank fixed ধরে \(\mathcal{T} \approx \sum_r a_r\circ b_r\circ c_r\)-এর \(A, B, C\) খুঁজতে সরাসরি অসম্ভব (nonconvex)। ALS-এর চাল: একবারে দুটো factor স্থির রাখো, তৃতীয়টার জন্য সমাধান করো — তখন সমস্যাটা একটা সাধারণ linear least squares (Chapter 5.4)! \(B, C\) স্থির রাখলে \(A\)-র জন্য: \(T_{(1)} \approx A(C \odot B)^T\), যা \(A\)-তে linear — সমাধান \(A = T_{(1)}\big[(C\odot B)^T\big]^\dagger\) (pseudoinverse, Part V)। তারপর \(A, C\) স্থির রেখে \(B\), তারপর \(A, B\) স্থির রেখে \(C\) — ঘুরিয়ে ঘুরিয়ে (alternating)। প্রতিটা ধাপে ভুল কমে বা একই থাকে, তাই converge করে — কিন্তু nonconvex বলে global optimum-এর গ্যারান্টি নেই (local minimum-এ আটকাতে পারে, বা Property 3-এর border-সমস্যায় "swamp"-এ ধীর হতে পারে)। এজন্যই বাস্তবে কয়েকটা random restart চালিয়ে সেরাটা নেওয়া হয় (fig05-এর কোডে ঠিক তাই)।
৬. Code-এ কেমনে লিখে¶
import numpy as np
rng = np.random.default_rng(42)
# ================= ১. Rank-1 tensor: outer product =================
a, b, c = rng.standard_normal(3), rng.standard_normal(4), rng.standard_normal(5)
T1 = np.einsum("i,j,k->ijk", a, b, c) # rank-1: t_ijk = a_i b_j c_k
print("rank-1 tensor shape:", T1.shape) # (3, 4, 5)
# ================= ২. CP: rank-3 tensor বানাই =================
def cp_to_tensor(factors): # factors = [A, B, C], সব (I_n x R)
return np.einsum("ir,jr,kr->ijk", *factors)
I, J, K, R = 6, 7, 8, 3
A = rng.standard_normal((I, R)); B = rng.standard_normal((J, R)); C = rng.standard_normal((K, R))
T = cp_to_tensor([A, B, C]) # এটা ঠিক rank R=3
print("CP tensor shape:", T.shape)
# ================= ৩. CP-ALS: factor পুনরুদ্ধার =================
def unfold(T, mode): # mode-n unfolding (Kolda convention)
return np.reshape(np.moveaxis(T, mode, 0), (T.shape[mode], -1), order="F")
def khatri_rao(U, V): # column-wise Kronecker: (IJ x R)
return (U[:, None, :] * V[None, :, :]).reshape(U.shape[0]*V.shape[0], -1)
def cp_als(T, rank, n_iter=200, seed=0):
rng = np.random.default_rng(seed)
dims = T.shape
Af = [rng.standard_normal((d, rank)) for d in dims]
Tm = [unfold(T, m) for m in range(3)]
for _ in range(n_iter):
# A update: fix B,C -> linear least squares (Chapter 5.4!)
Af[0] = np.linalg.lstsq(khatri_rao(Af[2], Af[1]), Tm[0].T, rcond=None)[0].T
Af[1] = np.linalg.lstsq(khatri_rao(Af[2], Af[0]), Tm[1].T, rcond=None)[0].T
Af[2] = np.linalg.lstsq(khatri_rao(Af[1], Af[0]), Tm[2].T, rcond=None)[0].T
That = cp_to_tensor(Af)
return That, np.linalg.norm(T - That) / np.linalg.norm(T)
That, err = cp_als(T, rank=3, seed=1)
print(f"CP-ALS rank-3 reconstruction error: {err:.2e}") # ~1e-15, প্রায় নিখুঁত
# ================= ৪. Eckart-Young ভাঙে: best rank-r নাও থাকতে পারে =================
# elbow: আসল rank-এর জায়গায় ভুল ধসে পড়ে
noise = rng.standard_normal(T.shape)
Tn = T + 0.05 * np.linalg.norm(T) / np.linalg.norm(noise) * noise # 5% noise
for R_try in [1, 2, 3, 4, 5]:
best = min(cp_als(Tn, R_try, seed=s)[1] for s in range(3)) # কয়েক restart
print(f"assumed rank {R_try}: error = {best:.4f}")
# ================= ৫. Tucker / HOSVD: প্রতি mode-এ SVD =================
def hosvd(T, ranks):
factors = []
for m in range(3):
U, _, _ = np.linalg.svd(unfold(T, m), full_matrices=False)
factors.append(U[:, :ranks[m]]) # mode-n basis
# core = T-কে সব factor-এর transpose দিয়ে project
core = np.einsum("ijk,ip,jq,kr->pqr", T, *[f for f in factors])
return core, factors
core, facs = hosvd(T, [3, 3, 3])
T_tucker = np.einsum("pqr,ip,jq,kr->ijk", core, *facs)
print("HOSVD reconstruction error:", np.linalg.norm(T - T_tucker) / np.linalg.norm(T))
# ================= ৬. essential uniqueness (permutation/scaling বাদে) =================
# recovered factor আর true factor: normalize করে column মেলে কিনা
def normcols(M):
return M / np.linalg.norm(M, axis=0, keepdims=True)
_, facs_als = cp_als(T, 3, seed=2), None
That2, e2 = cp_als(T, 3, seed=7)
print(f"different random start, same error: {e2:.2e} (unique কাঠামোর ইঙ্গিত)")
Output ব্যাখ্যা:
- rank-1 tensor
einsum("i,j,k->ijk")— outer product-এর সরাসরি কোড; shape ঠিক \((3,4,5)\)। - CP-ALS rank-\(3\)-এ noise-free tensor প্রায় নিখুঁতভাবে (machine precision, \(\sim 10^{-15}\)) পুনরুদ্ধার করলো — প্রতিটা factor update একটা linear least squares (Chapter 5.4-এর
lstsq!)। - rank-scan-এ ভুল rank \(1, 2\)-তে বড়, rank \(3\)-এ হঠাৎ noise-floor (\(\sim 0.05\))-এ ধসে পড়ে (elbow, fig05) — তারপর কমে না। এটাই tensor-এর "effective rank" খুঁজে পাওয়া।
- HOSVD (তিন mode-এর SVD) rank-\(3\) core দিয়ে tensor প্রায় নিখুঁতভাবে ফিরিয়ে দিলো — Tucker সবসময় কাজ করে (Property 5)।
- দুটো ভিন্ন random start একই reconstruction error-এ পৌঁছালো — CP-র essential uniqueness-এর কোডগত ইঙ্গিত (Property 4): কাঠামোটা একটাই, শুধু term-এর ক্রম/scale ভিন্ন হতে পারে।
৭. Worked Examples¶
Example 1 — rank-1 tensor হাতে-কলমে¶
\(a = (1, 2)^T\), \(b = (1, 0, -1)^T\), \(c = (2, 1)^T\)। rank-1 tensor \(\mathcal{T} = a \circ b \circ c\)-এর কয়েকটা element বের করো।
ধাপ ১ — সূত্র: \(t_{ijk} = a_ib_jc_k\)।
ধাপ ২ — কিছু element: - \(t_{111} = a_1b_1c_1 = 1\cdot1\cdot2 = 2\) - \(t_{212} = a_2b_1c_2 = 2\cdot1\cdot1 = 2\) - \(t_{131} = a_1b_3c_1 = 1\cdot(-1)\cdot2 = -2\) - \(t_{232} = a_2b_3c_2 = 2\cdot(-1)\cdot1 = -2\)
ধাপ ৩ — গঠন পড়ো: প্রতিটা frontal slice (\(k\) স্থির) হলো \(c_k \cdot (ab^T)\) — একই rank-1 matrix \(ab^T\), শুধু \(c_k\) দিয়ে scaled। এই "প্রতিটা slice একই প্যাটার্ন, শুধু ওজন ভিন্ন" — এটাই rank-1 tensor-এর স্বাক্ষর, আর CP এই ধরনের বিশুদ্ধ প্যাটার্নের যোগফল।
Example 2 — CP rank \(>\) mode-আকার: বিখ্যাত \(2\times2\times2\)¶
দেখাও কেন tensor rank matrix rank-এর মতো ভদ্র নয়: একটা \(2\times2\times2\) tensor-এর rank \(3\) পর্যন্ত হতে পারে, যদিও কোনো mode \(2\)-এর বেশি নয়।
ধারণা: frontal slice দুটো \(T_1 = \begin{bmatrix}1&0\\0&1\end{bmatrix}\), \(T_2 = \begin{bmatrix}0&1\\-1&0\end{bmatrix}\) ধরো। এই tensor-কে rank-1 term-এর যোগে লিখতে গেলে দেখা যায় দুটো real rank-1 term যথেষ্ট নয় — লাগে তিনটা (real-এ)।
কেন: rank-2 হলে দুই frontal slice-কে একই জোড়া \(\{a_1b_1^T, a_2b_2^T\}\)-এর real linear combination হতে হতো। কিন্তু \(T_2\) একটা \(90°\) rotation (\(\det = 1\), real eigenvalue নেই) — এটা \(T_1\)-এর সাথে একই real rank-1 জোড়ায় প্রকাশ করা যায় না। ফলে real rank \(= 3\)।
চমক: complex সংখ্যায় (eigenvalue \(\pm i\) ব্যবহার করে) এই একই tensor-এর rank মাত্র \(2\)! শিক্ষা: tensor rank field-নির্ভর (Property 2) — real বনাম complex-এ ভিন্ন, যা matrix-এ কখনো ঘটে না। এই একটা উদাহরণই দেখায় tensor-এর জগৎ কতটা অন্যরকম।
Example 3 — Tucker থেকে CP: বিশেষ কেস¶
দেখাও: Tucker decomposition-এ core \(\mathcal{G}\) যদি superdiagonal হয়, তাহলে Tucker ঠিক CP।
Tucker: \(t_{ijk} = \sum_{p,q,r} g_{pqr}\, u^{(1)}_{ip}u^{(2)}_{jq}u^{(3)}_{kr}\) (core + তিন factor matrix)।
Superdiagonal core: ধরো \(g_{pqr} = \lambda_r\) যখন \(p=q=r\), নইলে \(0\)। তাহলে ট্রিপল যোগফলে শুধু \(p=q=r\) term টিকে থাকে:
পড়ো: এটা ঠিক CP! \(a_r = u^{(1)}_{:r}\), \(b_r = u^{(2)}_{:r}\), \(c_r = u^{(3)}_{:r}\) নিলে \(t_{ijk} = \sum_r \lambda_r a_{ir}b_{jr}c_{kr}\)। তাই CP = superdiagonal-core Tucker (fig04-এর লাল লেখা)। Tucker সাধারণ (core-এ off-diagonal interaction-ও থাকে), CP তার সীমিত/বিশুদ্ধ রূপ (core diagonal, কোনো cross-interaction নেই)। এই সম্পর্কই দুই decomposition-কে এক পরিবারে বাঁধে।
৮. Problems ও Solutions¶
Problem 1. \(a = (2, 1)^T\), \(b = (1, 3)^T\), \(c = (1, -1, 2)^T\) দিয়ে rank-1 tensor \(\mathcal{T} = a\circ b\circ c\)-এর element \(t_{111}\), \(t_{122}\), \(t_{213}\) বের করো, আর দেখাও প্রতিটা frontal slice (\(k\) স্থির) একই rank-1 matrix-এর scaled রূপ।
Solution
\(t_{ijk} = a_ib_jc_k\): - \(t_{111} = a_1b_1c_1 = 2\cdot1\cdot1 = 2\) - \(t_{122} = a_1b_2c_2 = 2\cdot3\cdot(-1) = -6\) - \(t_{213} = a_2b_1c_3 = 1\cdot1\cdot2 = 2\)
Frontal slice (\(k\) স্থির): \(T_{::k}\)-এর element \(t_{ijk} = c_k(a_ib_j)\), অর্থাৎ \(T_{::k} = c_k\, ab^T\)। এখানে \(ab^T = \begin{bmatrix}2\\1\end{bmatrix}\begin{bmatrix}1&3\end{bmatrix} = \begin{bmatrix}2&6\\1&3\end{bmatrix}\)। - Slice \(k=1\): \(c_1 ab^T = 1\cdot\begin{bmatrix}2&6\\1&3\end{bmatrix}\) - Slice \(k=2\): \(c_2 ab^T = -1\cdot\begin{bmatrix}2&6\\1&3\end{bmatrix}\) - Slice \(k=3\): \(c_3 ab^T = 2\cdot\begin{bmatrix}2&6\\1&3\end{bmatrix}\)
তিনটা slice-ই একই matrix \(ab^T\)-এর scaled রূপ (\(1, -1, 2\) গুণ) — rank-1 tensor-এর স্বাক্ষর (Example 1)। প্রতিটা slice rank-1, আর তারা সমান্তরাল।
Problem 2. Matrix rank আর tensor rank-এর মধ্যে তিনটা মৌলিক পার্থক্য লেখো (Property 2 থেকে), প্রতিটার এক-বাক্য ব্যাখ্যাসহ।
Solution
-
আকারের সীমা: matrix rank \(\le \min(m,n)\) — সবসময়। Tensor rank mode-আকারের চেয়ে বড় হতে পারে (যেমন \(2\times2\times2\)-এর rank \(3\) পর্যন্ত, Example 2) — কারণ rank-1 tensor-দের span matrix-এর মতো "সরল" নয়।
-
Field-নির্ভরতা: matrix rank real ও complex-এ একই। Tensor rank field-নির্ভর — একই real tensor real-এ rank \(3\), complex-এ rank \(2\) হতে পারে (Example 2-এর \(90°\)-rotation slice), কারণ complex সংখ্যা বেশি rank-1 বিকল্প দেয়।
-
গণনার কঠিনতা: matrix rank তুচ্ছভাবে বের হয় (SVD-র nonzero singular value গোনা, polynomial time)। Tensor rank বের করা NP-hard — কোনো দক্ষ algorithm জানা নেই।
মূল কারণ: matrix-এ SVD সব প্রশ্নের ভদ্র উত্তর দিতো (rank, best approx, uniqueness); tensor-এ SVD-র অনুরূপ কোনো একক যন্ত্র নেই, তাই এই তিন ধর্মই বন্য হয়ে যায়।
Problem 3. Eckart–Young theorem matrix-এ কী বলে, আর tensor-এ কেন ভেঙে পড়ে? "Best rank-\(r\) approximation থাকতেই পারে না" — এই দাবির স্বজ্ঞাত (intuitive) ব্যাখ্যা দাও।
Solution
Matrix-এ (Eckart–Young): যেকোনো matrix-এর সেরা rank-\(k\) approximation = top-\(k\) SVD টুকরো (\(\sum_{i=1}^k \sigma_iu_iv_i^T\)), এটা সবসময় অস্তিত্ব আছে ও প্রমাণিতভাবে সেরা। কারণ rank-\(\le k\) matrix-দের set বন্ধ (closed) — সীমা নিলে rank বাড়ে না।
Tensor-এ ভাঙে (de Silva–Lim): rank-\(\le R\) tensor-দের set বন্ধ নয়। একটা rank-\((R{+}1)\) tensor-এর দিকে rank-\(R\) tensor-দের একটা sequence যেতে পারে যত কাছে খুশি, কিন্তু কখনো পৌঁছায় না — সীমাবিন্দুটা rank-\(R\) set-এর বাইরে (border rank \(<\) rank)।
স্বজ্ঞাত ছবি: ভাবো একটা rank-\(R\) approximation-এ দুটো rank-1 term প্রায় সমান-কিন্তু-বিপরীত করে দিলে (বিশাল ওজনে), তাদের যোগফল একটা "সূক্ষ্ম" প্যাটার্নে rank-\((R{+}1)\) target-এর কাছে যায়; term-দুটো যত বড়/কাছাকাছি করো তত কাছে — কিন্তু ঠিক সমান হলে তারা কাটাকাটি হয়ে rank কমে যায়। তাই ভুল কমতে কমতে একটা infimum-এ যায়, কিন্তু সেই infimum কোনো নির্দিষ্ট rank-\(R\) tensor-এ পাওয়া যায় না (minimum নেই, শুধু infimum)। এই কারণেই ALS কখনো "swamp"-এ (বিশাল-ওজনের কাটাকাটি term নিয়ে) ধীর/অস্থির হয়ে পড়ে (§৫ পথ ৩, ৫)।
Problem 4. CP decomposition-এর essential uniqueness কী, আর কেন এটা এত মূল্যবান (chemistry/neuroscience-এ)? matrix factorization-এ কেন এই uniqueness নেই — এক লাইনে।
Solution
Essential uniqueness: CP decomposition \(\mathcal{T} = \sum_r a_r\circ b_r\circ c_r\) (যথেষ্ট শর্তে, Kruskal: \(k_A+k_B+k_C \ge 2R+2\)) একটাই — শুধু term-এর ক্রম বদল (permutation) আর প্রতিটা term-এর ভেতরে scaling (যেমন \(a_r \to 2a_r, b_r \to \frac12 b_r\)) ছাড়া অন্য কোনো স্বাধীনতা নেই। কোনো orthogonality চাপানো লাগে না।
কেন মূল্যবান: মানে বের করা rank-1 term-গুলো অর্থবহ ও physical — ঘোরানো যায় না বলে ব্যাখ্যাযোগ্য। রসায়নে প্রতিটা term একটা বিশুদ্ধ রাসায়নিক উপাদানের প্রকৃত spectrum; neuroscience-এ একটা প্রকৃত মস্তিষ্ক-pattern। data নিজেই বলে দেয় "এই component-গুলোই আসল", কোনো ইচ্ছামতো ঘূর্ণন নয়।
matrix-এ কেন নেই (এক লাইনে): matrix factorization \(M = AB^T\)-এ যেকোনো invertible \(Q\)-র জন্য \(M = (AQ)(BQ^{-T})^T\)-ও চলে — দুই mode একে অপরের ঘূর্ণন শুষে নেয়, তাই decomposition অসংখ্য (§৫ পথ ২); তৃতীয় mode-ই CP-তে এই স্বাধীনতা কেড়ে নেয়।
Problem 5. Tucker decomposition কেন সবসময় অস্তিত্ব আছে অথচ CP নয়? HOSVD-তে প্রতিটা factor matrix \(U_n\) কীভাবে পাওয়া যায়?
Solution
কেন Tucker সবসময় থাকে: Tucker আসলে একটা subspace প্রশ্ন — "প্রতিটা mode-এর fiber কোন subspace-এ থাকে?"। এই প্রশ্নের উত্তর প্রতিটা mode-এর জন্য একটা সাধারণ matrix SVD দিয়ে পাওয়া যায় (§৫ পথ ৪), আর matrix SVD সবসময় অস্তিত্ব আছে (Part VI)। তাই Tucker উত্তরাধিকারসূত্রে অস্তিত্ব, স্থিতিশীলতা, quasi-optimality পায়। CP-র প্রশ্ন ("কয়টা rank-1 term?") এত ভদ্র নয় — সেখানে best approximation-ই নাও থাকতে পারে (Property 3)।
HOSVD-তে \(U_n\) কীভাবে: প্রতিটা mode-\(n\)-এর জন্য — 1. tensor-কে mode-\(n\) বরাবর unfold করো (ওই mode-এর fiber-গুলোকে column বানিয়ে একটা matrix \(T_{(n)}\))। 2. সেই matrix-এর SVD নাও: \(T_{(n)} = U_n\Sigma_n V_n^T\)। 3. \(U_n\)-এর top-\(R_n\) column-ই mode-\(n\)-এর factor matrix (সেই mode-এর প্রধান subspace-এর basis)।
তিন mode-এ তিনটা এমন SVD, তারপর core \(\mathcal{G} = \mathcal{T} \times_1 U_1^T \times_2 U_2^T \times_3 U_3^T\) (tensor-কে সব factor-এর transpose দিয়ে project)। এটাই HOSVD — "higher-order SVD"। §৬-এর কোডে ঠিক এই তিন ধাপ।
Problem 6. ALS algorithm-এ একটা factor update-কে কেন "linear least squares" বলা হয়? \(A\) update-এ (\(B, C\) স্থির) কোন Chapter 5-এর যন্ত্র ব্যবহৃত হয়?
Solution
CP objective \(\min_{A,B,C}\|\mathcal{T} - \sum_r a_r\circ b_r\circ c_r\|^2\) তিন factor একসাথে nonconvex। ALS-এর চাল: দুটো factor স্থির রেখে একটা করে সমাধান।
\(B, C\) স্থির রাখলে mode-1 unfolding-এ objective দাঁড়ায়:
যেখানে \(C \odot B\) হলো Khatri–Rao product (column-wise Kronecker)। খেয়াল করো: \(B, C\) স্থির বলে \((C\odot B)\) একটা নির্দিষ্ট, জানা matrix — তাই এটা \(A\)-তে সম্পূর্ণ linear! এটা ঠিক Chapter 5.4-এর সাধারণ least squares সমস্যা (\(\min_A\|M - AN\|_F^2\) আকারে), যার সমাধান:
যন্ত্র: normal equation / pseudoinverse (Chapter 5.4-5.5, Part V), বাস্তবে np.linalg.lstsq (§৬-এর কোডে)। তারপর একইভাবে \(B\) (mode-2), \(C\) (mode-3), ঘুরিয়ে ঘুরিয়ে। প্রতিটা ধাপ convex least squares (সহজ), শুধু পুরো ঘূর্ণনটা nonconvex (তাই local minimum-এর ঝুঁকি, §৫ পথ ৫)। সুন্দর ব্যাপার: tensor-এর কঠিন সমস্যা ভেঙে যায় Part V-এর পরিচিত least squares-এর একটা ক্রমে।
Problem 7. (কোডে) একটা \(10\times10\times10\) rank-\(2\) tensor বানাও (+\(3\%\) noise)। CP-ALS দিয়ে rank \(1\) থেকে \(4\) পর্যন্ত reconstruction error বের করে দেখাও elbow rank-\(2\)-তে।
Solution
import numpy as np
rng = np.random.default_rng(3)
def cp_to_tensor(F): return np.einsum("ir,jr,kr->ijk", *F)
def unfold(T, m): return np.reshape(np.moveaxis(T, m, 0), (T.shape[m], -1), order="F")
def kr(U, V): return (U[:,None,:]*V[None,:,:]).reshape(U.shape[0]*V.shape[0], -1)
def cp_als(T, R, n_iter=200, seed=0):
rg = np.random.default_rng(seed); d = T.shape
F = [rg.standard_normal((di, R)) for di in d]
Tm = [unfold(T, m) for m in range(3)]
for _ in range(n_iter):
F[0] = np.linalg.lstsq(kr(F[2], F[1]), Tm[0].T, rcond=None)[0].T
F[1] = np.linalg.lstsq(kr(F[2], F[0]), Tm[1].T, rcond=None)[0].T
F[2] = np.linalg.lstsq(kr(F[1], F[0]), Tm[2].T, rcond=None)[0].T
Th = cp_to_tensor(F)
return np.linalg.norm(T - Th)/np.linalg.norm(T)
d, R0 = 10, 2
F0 = [rng.standard_normal((d, R0)) for _ in range(3)]
T = cp_to_tensor(F0)
nz = rng.standard_normal(T.shape)
T = T + 0.03*np.linalg.norm(T)/np.linalg.norm(nz)*nz
for R in [1, 2, 3, 4]:
e = min(cp_als(T, R, seed=s) for s in range(3))
print(f"rank {R}: error = {e:.4f}")
seed=0,1,2)-এর সেরাটা নেওয়া হয়েছে, কারণ ALS nonconvex, কখনো local minimum-এ আটকায় (§৫ পথ ৫)।
Problem 8. Chapter 8.4 (randomized methods) আর Chapter 6.7 (PCA/SVD)-এর সাথে সেতু: matrix-এর SVD/PCA আর tensor-এর CP/Tucker — কোন ধারণাগুলো টিকে যায়, কোনটা ভেঙে পড়ে? একটা তুলনামূলক ছবি আঁকো।
Solution
| ধারণা | Matrix (SVD/PCA) | Tensor (CP/Tucker) |
|---|---|---|
| Rank-1 টুকরো | \(\sigma_iu_iv_i^T\) (outer product) | \(a_r\circ b_r\circ c_r\) — টিকে যায় (সরাসরি সাধারণীকরণ) |
| Rank সংজ্ঞা | nonzero singular value-র সংখ্যা, তুচ্ছ | CP rank — NP-hard, field-নির্ভর, mode-আকার ছাড়ায় |
| Best rank-\(k\) approx | Eckart–Young: সবসময় থাকে, সেরা | ভেঙে পড়ে — best নাও থাকতে পারে (CP); Tucker/HOSVD quasi-optimal |
| Uniqueness | rotation-এর স্বাধীনতা (repeated σ-তে) | CP: essential uniqueness (SVD-তে যা ছিলো না!); Tucker: unique নয় |
| Orthogonality | \(u_i, v_i\) orthonormal (বাধ্যতামূলক) | CP: লাগে না; Tucker: \(U_n\) orthonormal (HOSVD-তে) |
| Compression (Ch 8.4) | low-rank/randomized SVD | Tucker/CP দিয়ে weight tensor compression |
সারসংক্ষেপ: rank-1 টুকরোর ধারণা টিকে যায় (CP = SVD-র বড় ভাই), কিন্তু SVD-র তিন সৌভাগ্য — সহজ rank, Eckart–Young, ভদ্র uniqueness — এর মধ্যে প্রথম দুটো ভেঙে পড়ে tensor-এ (rank NP-hard, best approx নাও থাকতে পারে)। বিনিময়ে tensor একটা নতুন উপহার দেয় যা matrix-এ কখনো ছিলো না: essential uniqueness (তিন mode-এর পারস্পরিক আটকানোর কারণে)। এটাই chapter-এর মূল বার্তা: এক index বাড়লে কিছু হারায়, কিছু জন্মায় — গণিতের নিয়ম order-নিরপেক্ষ নয়।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "Tensor মানেই physics-এর stress/rotation tensor" | ML/data science-এ tensor = multi-way array (বহু-index সংখ্যার ঘনক), physics-এর রূপান্তর-নিয়মওয়ালা tensor নয়। PyTorch-এর Tensor-ও এই অর্থেই। দুটো গুলিও না। |
| "Tensor rank matrix rank-এর মতোই — \(\le\) mode-আকার" | না — tensor rank mode-আকার ছাড়িয়ে যেতে পারে (\(2\times2\times2\)-এর rank \(3\)), field-নির্ভর (real ≠ complex), আর নির্ণয় NP-hard (Property 2, Example 2)। |
| "Tensor-এ top-\(r\) CP নিলেই সেরা rank-\(r\) approximation পাবো" | Eckart–Young tensor-এ ভেঙে পড়ে — best rank-\(r\) approximation নাও থাকতে পারে (Property 3)! CP-ALS local optimum দেয়, গ্যারান্টি নেই। নিরাপদ compression চাইলে Tucker/HOSVD (quasi-optimal)। |
| "Decomposition unique নয়, matrix-এর মতোই ঘোরানো যায়" | উল্টো — CP প্রায়ই essentially unique (Kruskal), permutation/scaling ছাড়া কোনো স্বাধীনতা নেই, orthogonality না চাপিয়েই (Property 4)। এটাই CP-র সবচেয়ে শক্তিশালী ধর্ম, matrix-এ যা কখনো ছিলো না। |
| "CP আর Tucker আলাদা, সম্পর্কহীন" | Tucker সাধারণ; CP = superdiagonal-core Tucker (Example 3)। CP core diagonal (কোনো cross-interaction নেই), Tucker-এ full core (সব interaction)। এক পরিবার। |
| "ALS convex, তাই সবসময় global optimum দেয়" | প্রতিটা ধাপ convex (linear least squares), কিন্তু পুরো ঘূর্ণন nonconvex — local minimum-এ আটকাতে পারে, বা border-সমস্যায় "swamp"-এ ধীর হতে পারে (§৫ পথ ৫)। তাই কয়েক random restart চালিয়ে সেরাটা নাও। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Tensor | order-\(N\) multi-way array \(t_{i_1\dots i_N}\) | scalar→vector→matrix→ঘনক সিঁড়ি |
| Fiber / slice | সব-বাদে-একটা স্থির (fiber); ঠিক-একটা স্থির (slice) | row/column-এর সাধারণীকরণ |
| Rank-1 tensor | \(a\circ b\circ c\), \(t_{ijk}=a_ib_jc_k\) | প্রতি slice একই প্যাটার্ন, ভিন্ন ওজন |
| CP | \(\mathcal{T}=\sum_r \lambda_r a_r\circ b_r\circ c_r\) | SVD-র বড় ভাই (rank-1-এর যোগ) |
| CP rank | সবচেয়ে ছোট \(R\); NP-hard, field-নির্ভর | matrix rank-এর বন্য জ্ঞাতি |
| Eckart–Young | matrix-এ সত্য, tensor-এ ভাঙে | best rank-\(r\) নাও থাকতে পারে (border rank) |
| Essential uniqueness | Kruskal: \(k_A+k_B+k_C\ge2R+2\) | তিন mode একে অপরকে আটকে রাখে |
| Tucker / HOSVD | core \(\mathcal{G}\) + প্রতি mode-এ \(U_n\) (unfolding-এর SVD) | সবসময় থাকে, quasi-optimal, unique নয় |
| CP ⊂ Tucker | superdiagonal core = CP | Tucker সাধারণ, CP বিশুদ্ধ |
| ALS | factor ঘুরিয়ে least squares (Ch 5.4) | nonconvex — restart করো |
| ML সংযোগ | PyTorch tensor, model compression, latent factor | matrix-জগৎ পেরিয়ে বহু-মাত্রা |
Part IX-এর শেষ ও সেতু: এই chapter দিয়ে Part IX — PhD Level Advanced Theory — এর তত্ত্বীয় যাত্রা শেষ। আমরা abstract vector space থেকে শুরু করে, Jordan form, matrix calculus, spectral theory, random matrix theory (Chapter 9.5), আর অবশেষে tensor পর্যন্ত এসে দেখলাম linear algebra আসলে কত গভীর ও বিস্তৃত — দুই-index matrix থেকে বহু-index tensor-এ উঠে গিয়ে বুঝলাম, কোন সত্য universal আর কোনটা শুধু order-2-এর সৌভাগ্য। এবার শেষ ধাপ — Part X, Capstone: এতদিনের সব অস্ত্র (vector, matrix, eigenvalue, SVD, least squares, tensor) একসাথে জড়ো করে বাস্তব dataset-এ একটা পূর্ণ প্রকল্প, যেখানে তুমি নিজেই দেখবে — শূন্য থেকে এখানে, তুমি সত্যিই PhD-level linear algebra করছো।
📓 Notebook Project¶
notebooks/part-09/ch06-project.ipynb — scratch-এ CP-ALS আর HOSVD/Tucker লিখে একটা সিন্থেটিক low-rank tensor পুনরুদ্ধার করা; rank-scan দিয়ে elbow খুঁজে "effective rank" বের করা; দুটো ভিন্ন random start-এ CP-র essential uniqueness যাচাই (permutation/scaling বাদে factor মেলে কিনা); একটা ছোট রঙিন ছবি (height × width × channel tensor) Tucker দিয়ে compress করে চোখে দেখা; আর CP বনাম Tucker-এর নির্ভুলতা-বনাম-parameter tradeoff তুলনা।