Chapter 8.4 — Randomized Methods (র্যান্ডমাইজড মেথড — randomized SVD, sketching)¶
এতদিন আমরা linear algebra করেছি নিখুঁত, deterministic নিয়মে — প্রতিবার একই matrix দিলে একই উত্তর। এবার এক আশ্চর্য মোড়: এলোমেলো সংখ্যা দিয়ে নির্ভুল উত্তর পাওয়া। শুনতে স্ববিরোধী, তাই না? একটা \(10^6 \times 10^6\) matrix-এর SVD বের করতে বছর লাগবে; অথচ সেই matrix-কে কয়েকটা random প্রশ্ন করে, উত্তরগুলো জড়ো করে, ছোট একটা matrix বানিয়ে তাতে নিখুঁত কাজ করলে — সেকেন্ডে প্রায়-নিখুঁত SVD পাওয়া যায়। এটাই Randomized Numerical Linear Algebra, গত দুই দশকের সবচেয়ে বড় ব্যবহারিক বিপ্লব। Netflix-এর recommendation, বড় ভাষা-মডেলের weight compression, বিশাল dataset-এর PCA — সবখানে আজ এই randomized অস্ত্র। Chapter 8.3-এ eigenvalue বের করেছি iterative deterministic নিয়মে; আজ শিখবো randomness কীভাবে বিশাল matrix-কে নতজানু করে — আর কেন এই "জুয়া" প্রায় সবসময় জেতে।
🎯 এই chapter-এ যা শিখবে¶
- Sketching(স্কেচিং) ও Random Projection(র্যান্ডম প্রজেকশন): বিশাল matrix-কে random matrix দিয়ে গুণ করে ছোট করা, তবু জ্যামিতি বজায়
- Johnson–Lindenstrauss Lemma(জনসন–লিন্ডেনস্ট্রাস লেমা): random projection দূরত্ব প্রায় অপরিবর্তিত রাখে — কেন এবং কতটা
- Randomized SVD(র্যান্ডমাইজড এসভিডি) চার ধাপে (Halko–Martinsson–Tropp): sketch → orthonormalize → compress → tiny SVD
- Power Iteration(পাওয়ার ইটারেশন) (\(q\)): singular value ধীরে কমলেও নির্ভুলতা ফিরিয়ে আনা
- কখন randomized SVD ব্যবহার করবে (low-rank structure), আর কত দ্রুত + কতটা নির্ভুল (Eckart–Young-এর কাছাকাছি)
🖼️ এক ছবিতে মূল idea¶
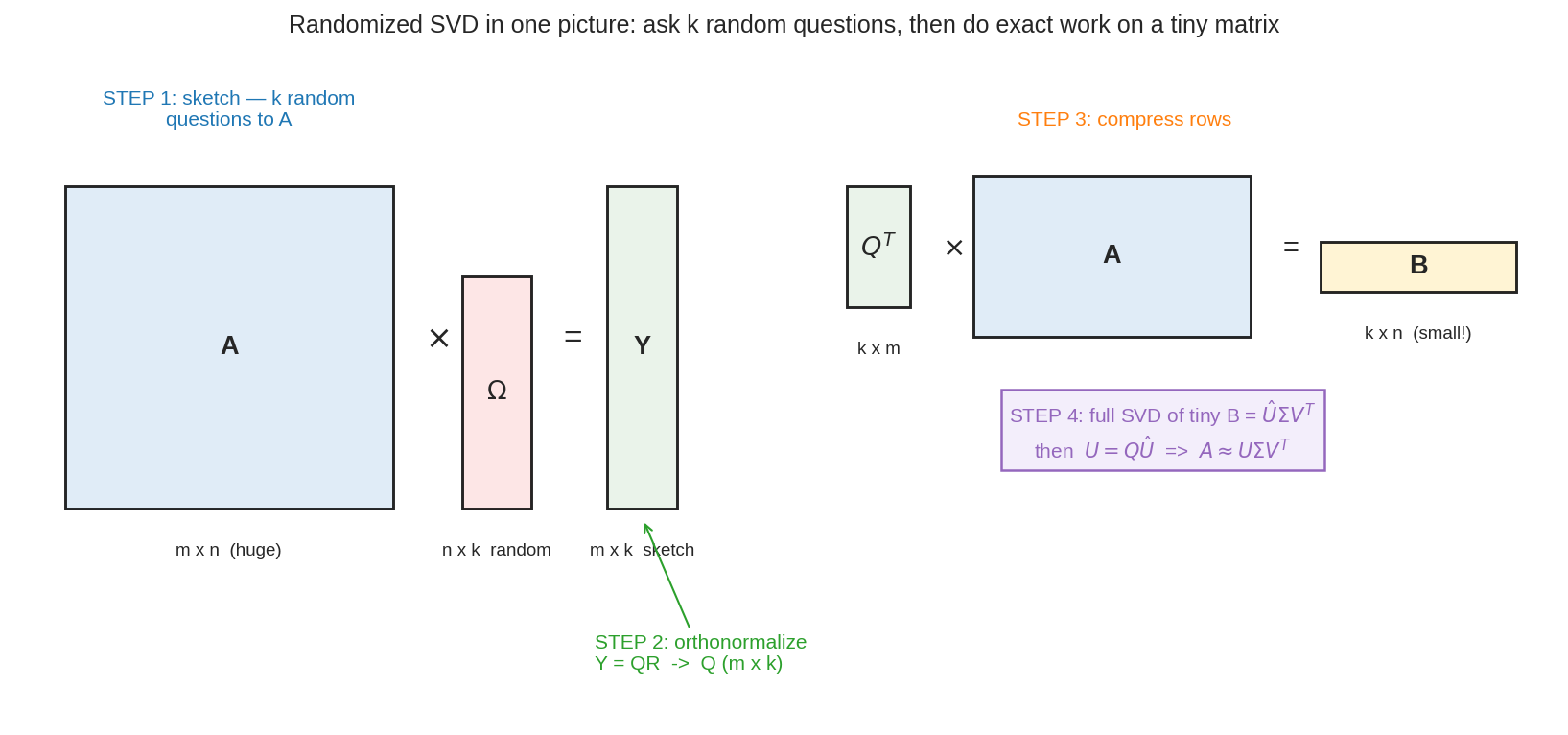
Randomized SVD-এর পুরো দর্শন এক ছবিতে। বিশাল matrix \(A\) (\(m \times n\))-কে একটা random matrix \(\Omega\) (লাল) দিয়ে গুণ করে পাও একটা সরু "sketch" \(Y\) (সবুজ) — যেন \(A\)-কে \(k\)টা random প্রশ্ন করলে। তারপর \(Y\)-কে orthonormalize করে (\(Q\)), \(A\)-কে সেই ছোট basis-এ চেপে (\(B = Q^TA\)), আর ওই ছোট \(B\)-তে নিখুঁত SVD চালাও। বিশাল matrix-এ কষ্টের কাজ এড়িয়ে, ছোট matrix-এ নিখুঁত কাজ — এটাই randomized SVD।
১. কি? (What)¶
দৈনন্দিন analogy: exit poll¶
সারা দেশের ১০ কোটি ভোটারের মত জানতে হলে সবাইকে জিজ্ঞেস করা অসম্ভব — সময়, টাকা, শ্রম সব ফুরিয়ে যাবে। কিন্তু এলোমেলোভাবে বাছাই করা কয়েক হাজার মানুষকে জিজ্ঞেস করলেই মোটামুটি নিখুঁত ছবি পাওয়া যায় — এটাই exit poll। কৌশলটা: পুরো জনগোষ্ঠীর একটা random নমুনা প্রায় গোটা জনগোষ্ঠীর মতোই আচরণ করে।
Randomized SVD ঠিক তাই: বিশাল matrix \(A\)-এর column space-এর "মত" জানতে সব column দেখা লাগে না — কয়েকটা random combination (random প্রশ্ন) করলেই সেই space-এর ভালো একটা নমুনা পাওয়া যায়। আর matrix-এর আসল তথ্য যদি কয়েকটা দিকে জমা থাকে (low-rank), তাহলে সেই নমুনা প্রায় নিখুঁত।
কেন randomized? — low-rank-এর বাস্তবতা¶
বাস্তব data-র matrix প্রায় সবসময় low-rank বা প্রায় low-rank: তার আসল তথ্য কয়েকটা দিকেই জমা, বাকিটা noise (Chapter 6.7-এর PCA, 9.5-এর MP-bulk এটাই বলেছিল)। একটা \(10^6 \times 10^6\) matrix-এর হয়তো মাত্র \(k = 50\)টা গুরুত্বপূর্ণ singular value। পুরো SVD (\(\sim mn^2\)) চালিয়ে ৫০টা বের করা মানে বিশাল অপচয়। Randomized SVD বলে: শুধু ওই \(k\)টা দিকই খুঁজি, বাকিটা ছুঁইও না — খরচ নেমে আসে \(\sim mnk\)-তে, যা \(mn^2\)-এর তুলনায় নগণ্য (কারণ \(k \ll n\))।
সংজ্ঞা: Sketching / Random Projection¶
একটা matrix \(A\) (\(m \times n\))-কে "sketch" করা মানে ডান দিক থেকে একটা random matrix \(\Omega\) (\(n \times k\), entry iid Gaussian বা \(\pm 1\)) দিয়ে গুণ:
\(Y\)-এর প্রতিটা column হলো \(A\)-এর column-গুলোর একটা random ওজনযুক্ত যোগফল — একেকটা "random প্রশ্ন"। মূল দাবি: \(A\)-এর column space যদি সত্যিই \(k\)-মাত্রিক (বা কাছাকাছি) হয়, তাহলে \(Y\)-এর column সেই space প্রায় সম্পূর্ণ ধরে ফেলে।
সংজ্ঞা: Randomized SVD (চার ধাপ)¶
Halko–Martinsson–Tropp-এর বিখ্যাত recipe, \(A\)-এর rank-\(k\) approximation বের করতে:
- Sketch: \(\Omega\) (\(n \times (k+p)\)) random নাও (\(p \approx 5\)–\(10\) oversampling, নিরাপত্তার জন্য), \(Y = A\Omega\);
- Orthonormalize: \(Y = QR\) (QR factorization, Chapter 8.2) — \(Q\) (\(m \times (k+p)\)) হলো \(A\)-এর range-এর orthonormal basis;
- Compress: \(B = Q^TA\) (\((k+p) \times n\)) — \(A\)-কে সেই ছোট basis-এ চেপে ফেলা;
- Tiny SVD: ছোট \(B\)-এর নিখুঁত SVD \(B = \hat U\Sigma V^T\); তারপর \(U = Q\hat U\), ফলে \(A \approx U\Sigma V^T\)।
মূল লাভ: ব্যয়বহুল SVD চলে শুধু ছোট \(B\)-তে; বিশাল \(A\)-তে শুধু কয়েকটা matrix-গুণ (সস্তা)।
Power Iteration (\(q\)) — singular value ধীরে কমলে¶
যদি singular value ধীরে কমে (noise floor উঁচু), sketch-টা "ঘোলা" হয়। সমাধান: sketch-এর আগে \(A\)-কে কয়েকবার "তীক্ষ্ণ" করা —
প্রতিটা \((AA^T)\) গুণ singular value-কে বর্গ করে (\(\sigma_i \to \sigma_i^{2q+1}\)), তাই বড়-ছোটর ফাঁক বাড়ে, sketch পরিষ্কার হয়। সাধারণত \(q = 1\) বা \(2\)-ই যথেষ্ট (Chapter 8.3-এর power method-এর সেই একই "বড়টা টিকে থাকে" নীতি)।
২. দেখতে কেমন?¶
দৃশ্য ১: বাস্তব data-তে লুকানো low-rank কাঠামো¶
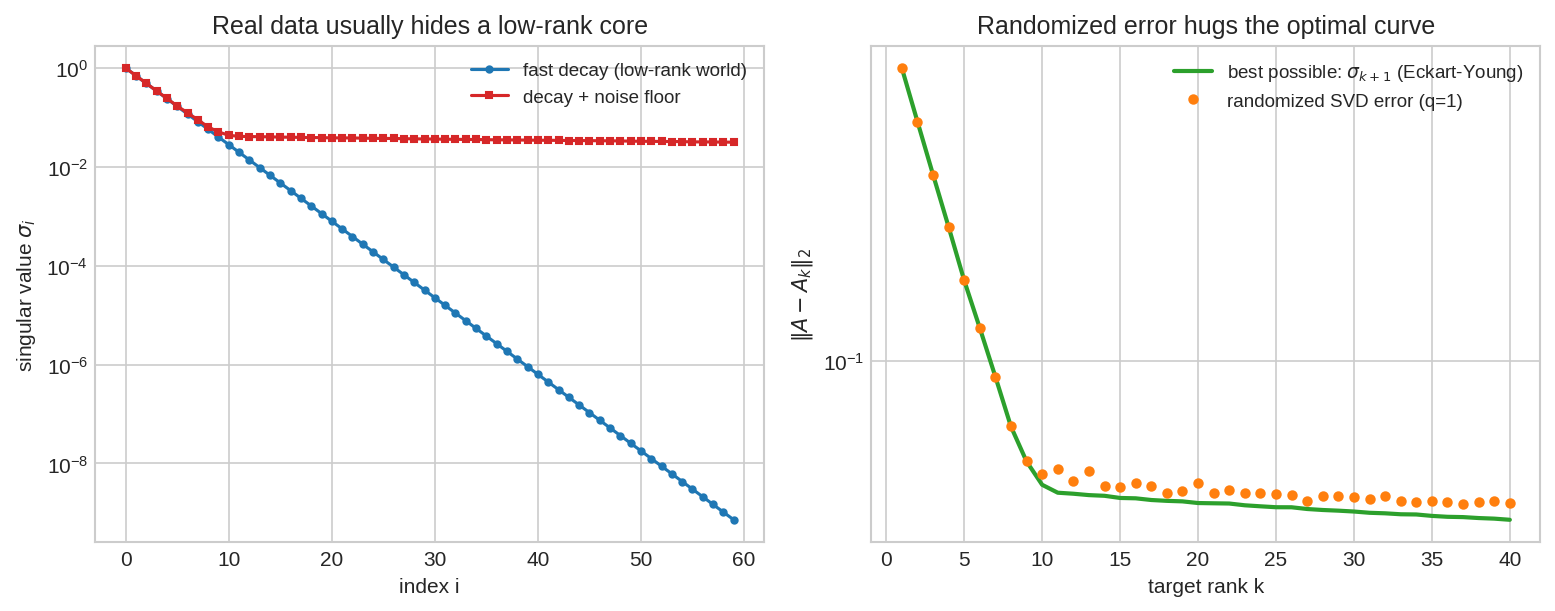
বাঁয়ে: বাস্তব data-র singular value-রা দ্রুত পড়ে যায় (নীল) — মানে আসল তথ্য কয়েকটা দিকেই, বাকিটা প্রায় শূন্য। এমনকি noise থাকলেও (লাল) একটা "floor"-এ থিতু হয়। এই দ্রুত পতনই randomized SVD-কে সম্ভব করে। ডানে: randomized SVD-এর ভুল (কমলা বিন্দু) প্রায় হুবহু বসেছে তত্ত্বের সেরা সম্ভাব্য ভুলের (সবুজ, Eckart–Young: \(\sigma_{k+1}\)) ওপর — অর্থাৎ randomness প্রায় কিছুই হারায় না।
দৃশ্য ২: Random projection দূরত্ব রক্ষা করে (JL)¶
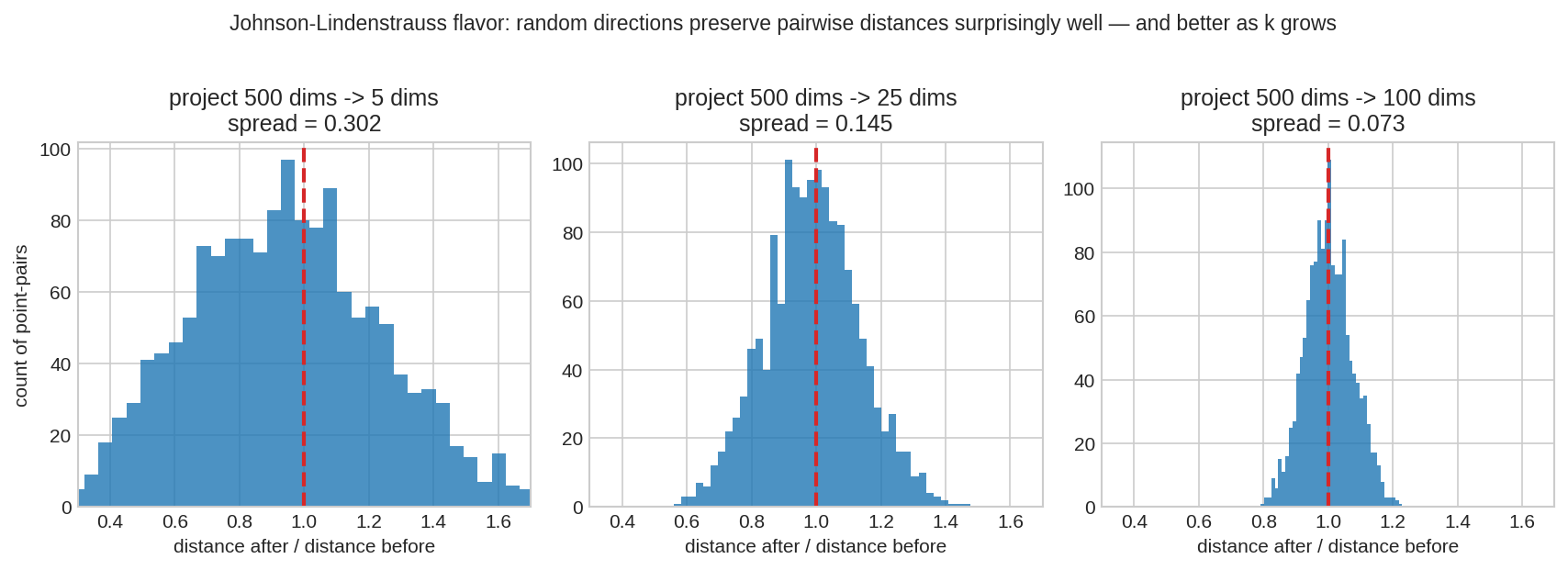
৫০০-মাত্রিক space-এর বিন্দুদের random projection দিয়ে \(5\), \(25\), \(100\) মাত্রায় নামানো হলো। প্রতিটা histogram দেখায়: বিন্দু-জোড়ার মধ্যে দূরত্ব প্রজেকশনের পরে/আগে-র অনুপাত। তিনটাতেই চূড়া \(1.0\)-তে (লাল দাগ) — মানে দূরত্ব প্রায় অপরিবর্তিত! আর \(k\) (target মাত্রা) যত বড়, spread তত ছোট — \(5\)-এ ছড়ানো, \(100\)-এ প্রায় স্পাইক। এটাই Johnson–Lindenstrauss-এর হৃদয়: random projection জ্যামিতি রক্ষা করে, আশ্চর্য ভালোভাবে।
দৃশ্য ৩: সময়ের যুদ্ধ — full বনাম randomized¶
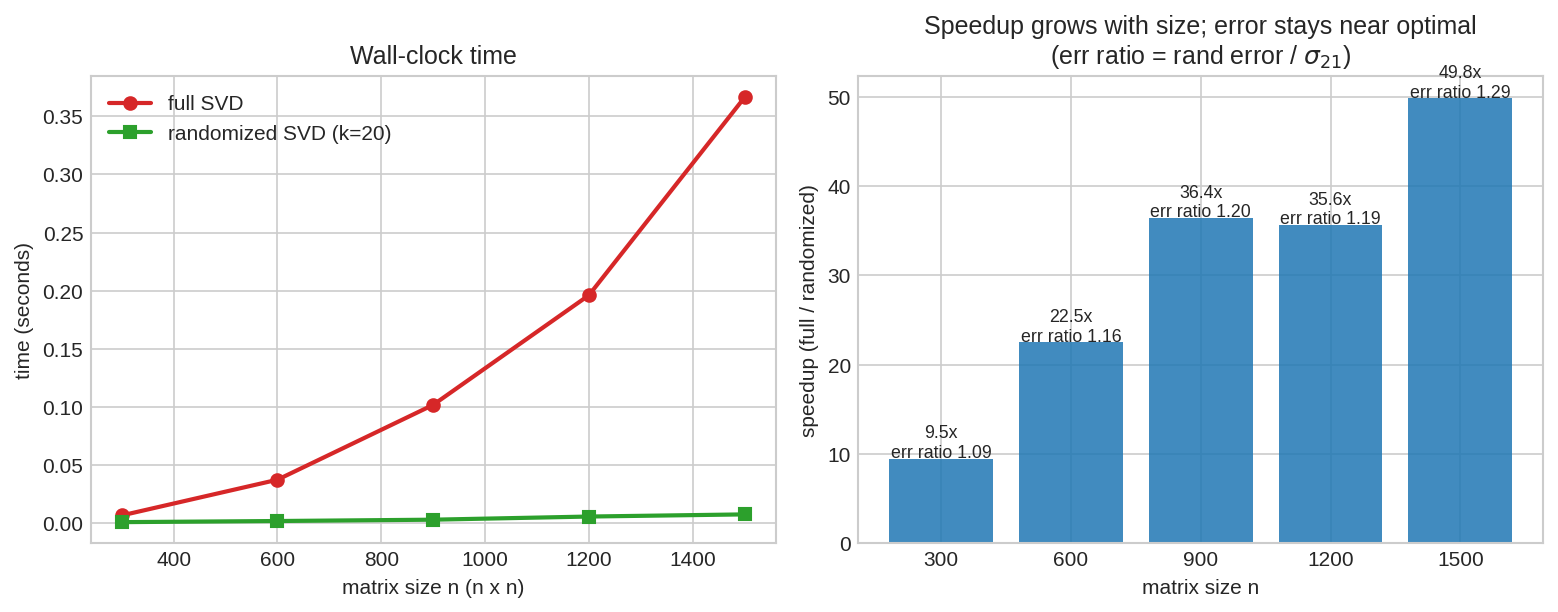
বাঁয়ে: matrix বড় হলে full SVD-এর সময় (লাল) খাড়া বাড়ে, randomized SVD (সবুজ, \(k=20\)) প্রায় সমতল থাকে। ডানে: speedup (full/randomized) আকারের সাথে বাড়ে — বড় matrix-এ randomized কয়েকগুণ দ্রুত, আর error ratio (\(\approx 1\)) বলছে নির্ভুলতা প্রায় একই। বড় matrix + low rank = randomized SVD-এর স্বর্গরাজ্য।
দৃশ্য ৪: চোখে দেখা compression¶

একটা \(120 \times 120\) "ছবি" (\(14400\) সংখ্যা)। randomized SVD দিয়ে rank \(3\), \(10\), \(25\)-এ পুনর্গঠন। rank \(3\)-এই মূল কাঠামো ফুটে ওঠে; rank \(25\) (মূল সংখ্যার মাত্র \(42\%\)) প্রায় হুবহু। কয়েকটা rank-ই প্রায় সব তথ্য বহন করে — Eckart–Young (Part V-VI)-এর সেই সত্য, এবার randomized যন্ত্রে সস্তায়। ছবি compression-এর এই ধারণাই JPEG, video codec, model compression-এর ভিত্তি।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- Netflix / recommendation: কোটি user × লক্ষ movie-র rating matrix — বিশাল, কিন্তু low-rank (কয়েকটা "taste দিক"-এই সব ব্যাখ্যা)। Randomized SVD/low-rank factorization দিয়ে সেই লুকানো দিকগুলো বের করে suggestion তৈরি — full SVD এত বড় matrix-এ অসম্ভব হতো।
- ছবি ও ভিডিও compression: JPEG-ধাঁচের কৌশল matrix-কে low-rank-এ approximate করে জায়গা বাঁচায়। বিশাল ছবিতে randomized SVD দ্রুত সেই approximation দেয় (fig05)।
- বৈজ্ঞানিক সিমুলেশন: আবহাওয়া, তরলবিদ্যা, জ্যোতির্বিদ্যার বিশাল data matrix — full decomposition অসম্ভব, randomized method-ই একমাত্র বাস্তব পথ।
Data Science / ML-এ:
- বিশাল dataset-এ PCA: scikit-learn-এর
PCA(svd_solver='randomized')ঠিক এই algorithm — লক্ষ-feature data-তে top-\(k\) component সেকেন্ডে (Chapter 6.7-এর PCA-র বাস্তব ইঞ্জিন)। - Model / LLM compression: বড় neural network-এর weight matrix প্রায় low-rank — randomized SVD দিয়ে তাদের ছোট করে (LoRA-র মতো কৌশলের চিন্তার শিকড় এখানেই) মেমরি ও গতি বাঁচানো।
- Kernel approximation (Random Features): বিশাল kernel matrix না বানিয়ে random projection দিয়ে তার প্রায়-প্রতিরূপ — SVM, Gaussian process-কে বিশাল data-তে চালানোর কৌশল।
- Fast nearest neighbor / LSH: Johnson–Lindenstrauss projection দিয়ে high-dim data ছোট করে দ্রুত similarity search (search engine, image retrieval)।
- Streaming / one-pass algorithm: data একবারই দেখা যায় (streaming) এমন ক্ষেত্রে sketching দিয়ে চলতি-চলতি summary — full matrix কখনো memory-তে না রেখেই।
৪. Properties¶
Property 1 — খরচ \(mn^2\) থেকে নেমে \(mnk\)¶
Full SVD-এর খরচ \(\sim mn\min(m,n) \sim mn^2\) (tall matrix-এ)। Randomized SVD-তে বড় \(A\)-তে শুধু কয়েকটা matrix-গুণ (\(A\Omega\), \(Q^TA\) — প্রতিটা \(\sim mnk\)) আর ছোট \(B\)-তে SVD (\(\sim nk^2\))। মোট \(\sim mnk\) — \(n/k\) গুণ সস্তা। \(n = 10^5, k = 50\) হলে ২০০০ গুণ কম কাজ।
Property 2 — নির্ভুলতা Eckart–Young-এর কাছাকাছি¶
Eckart–Young theorem (Part V-VI): rank-\(k\) approximation-এর সেরা সম্ভাব্য ভুল \(\sigma_{k+1}\) (পরের singular value)। Randomized SVD-এর প্রত্যাশিত ভুল এর খুব কাছে:
oversampling \(p\) (কয়েকটা বাড়তি column) নিলে এই গুণক \(\approx 1\)-এর কাছে — মানে randomized প্রায় optimal (§২ fig02-এ কমলা বিন্দু সবুজ রেখায় লেগে থাকা)।
Property 3 — Oversampling সস্তা বীমা¶
\(k\)টা component চাইলে \(\Omega\)-তে \(k + p\) column নাও (\(p = 5\)–\(10\))। এই কয়েকটা বাড়তি column খরচ সামান্য বাড়ায়, কিন্তু নির্ভুলতা নাটকীয়ভাবে বাড়ায় ও ব্যর্থতার সম্ভাবনা প্রায় শূন্যে নামায়। বাস্তবে সবসময় oversample করো — এটা প্রায়-বিনামূল্যের বীমা।
Property 4 — Power iteration singular value তীক্ষ্ণ করে¶
Singular value ধীরে কমলে (\(\sigma_{k+1} \approx \sigma_k\)) sketch ঘোলা হয়। \(q\) ধাপ power iteration \(\sigma_i \to \sigma_i^{2q+1}\) করে, তাই আপেক্ষিক ফাঁক \((\sigma_{k+1}/\sigma_k)^{2q+1}\)-এ কমে — sketch তীক্ষ্ণ। খরচ শুধু \(2q\)টা বাড়তি matrix-গুণ। \(q = 1\)–\(2\)-ই বেশিরভাগ ক্ষেত্রে যথেষ্ট (Chapter 8.3-এর power method-এর প্রতিধ্বনি)।
Property 5 — Johnson–Lindenstrauss: দূরত্ব রক্ষা মাত্রা-নিরপেক্ষ¶
JL lemma বলে: \(N\)টা বিন্দুর দূরত্ব \((1 \pm \epsilon)\) ফ্যাক্টরের মধ্যে রক্ষা করতে target মাত্রা লাগে মাত্র \(k = O(\epsilon^{-2}\log N)\) — মূল মাত্রা \(n\)-এর ওপর নির্ভর করে না! \(n = 10^6\) হোক বা \(10^9\), \(10000\) বিন্দুর জন্য \(k \approx 100\)-এই দূরত্ব প্রায় অটুট (fig03)। এই মাত্রা-নিরপেক্ষতাই sketching-কে high-dim জগতে এত শক্তিশালী করে।
৫. Intuition — কেন সত্য?¶
পথ ১: কেন random প্রশ্নে column space ধরা পড়ে¶
\(A\)-এর column space যদি \(k\)-মাত্রিক হয় (rank \(k\)), তাহলে \(A\Omega\)-এর প্রতিটা column সেই space-এর একটা random বিন্দু। প্রশ্ন: \(k\)টা random বিন্দু কি একটা \(k\)-মাত্রিক space সম্পূর্ণ ধরে? প্রায় নিশ্চিতভাবে হ্যাঁ — কারণ random vector-রা প্রায় নিশ্চিতভাবে linearly independent (একটা নির্দিষ্ট lower-dimensional subspace-এ পড়ার সম্ভাবনা শূন্য)। ভাবো: একটা সমতলে (2D) দুটো random তীর ছুঁড়লে তারা প্রায় কখনোই একই লাইনে পড়বে না — মিলে পুরো সমতল ধরে ফেলে। তাই \(k\)টা random প্রশ্নই \(k\)-মাত্রিক space চিনে ফেলে। Oversampling (\(+p\)) শুধু "দুর্ভাগ্যজনক" প্রায়-নির্ভরশীল নমুনার বিরুদ্ধে বীমা।
পথ ২: কেন JL কাজ করে — random projection দৈর্ঘ্য সংরক্ষণ করে (গড়ে)¶
একটা fixed vector \(x\)-কে random matrix \(S\) (\(k\) row, প্রতিটা normalize করা) দিয়ে গুণ করলে \(\|Sx\|^2\)-এর প্রত্যাশিত মান ঠিক \(\|x\|^2\) — গড়ে দৈর্ঘ্য অপরিবর্তিত। আর \(k\) বড় হলে concentration of measure (গড়ের চারপাশে জমাট বাঁধা — Chapter 9.5-এর CLT-চেতনা) নিশ্চিত করে প্রতিটা নির্দিষ্ট vector-এর দৈর্ঘ্যও প্রত্যাশিত মানের খুব কাছে। যেহেতু দূরত্ব = পার্থক্য-vector-এর দৈর্ঘ্য, দূরত্বও রক্ষিত। মূল বিস্ময়: এই গ্যারান্টি \(x\)-এর মূল মাত্রা \(n\)-এর ওপর নির্ভর করে না, শুধু \(k\) আর কতগুলো বিন্দু (\(N\)) তার ওপর — এজন্যই \(k = O(\epsilon^{-2}\log N)\)।
পথ ৩: কেন orthonormalize (QR) ধাপটা লাগে¶
\(Y = A\Omega\)-এর column-রা \(A\)-এর range ধরে, কিন্তু তারা orthonormal নয় (তির্যক, বিভিন্ন দৈর্ঘ্য) — সংখ্যাগতভাবে অস্থির (Chapter 8.1)। QR factorization (\(Y = QR\)) সেই একই space-এর একটা পরিষ্কার orthonormal basis \(Q\) দেয়। তারপর \(B = Q^TA\) মানে "\(A\)-কে সেই ভালো basis-এ প্রকাশ করা" — যেহেতু \(Q\) range ধরে ফেলেছে, \(A \approx QQ^TA = QB\), তাই \(B\)-এর SVD-ই যথেষ্ট। এই একটা QR-ধাপই randomness-কে stable, ব্যবহারযোগ্য approximation-এ রূপ দেয়।
পথ ৪: কেন এই "জুয়া" প্রায় সবসময় জেতে¶
ভয় লাগতে পারে: "random matrix বেছেছি, যদি দুর্ভাগ্যক্রমে খারাপ \(\Omega\) পড়ে?" উত্তর — high dimension-এ খারাপ \(\Omega\) পাওয়া প্রায় অসম্ভব। Concentration of measure বলে: বহু-মাত্রিক random বস্তু প্রায় নিশ্চিতভাবে তার "সাধারণ" আচরণ করে (Chapter 9.5-এর semicircle/MP law-ও এই একই ঘটনার আত্মীয় — randomness বড় স্কেলে নিজেকে predictable করে তোলে)। তাই ব্যর্থতার সম্ভাবনা \(\Omega\)-এর আকারের সাথে exponentially কমে — oversampling \(p = 10\) নিলে ব্যর্থতা কার্যত শূন্য। এটাই আধুনিক randomized algorithm-এর দার্শনিক ভিত্তি: randomness এখানে শত্রু নয়, বন্ধু — কারণ বড় মাত্রায় random প্রায়-নিশ্চিত হয়ে যায়।
৬. Code-এ কেমনে লিখে¶
import numpy as np
rng = np.random.default_rng(42)
# ---------- একটা low-rank matrix বানাই (rank ~ 10, তারপর সামান্য noise) ----------
m, n, true_rank = 600, 400, 10
U0, _ = np.linalg.qr(rng.standard_normal((m, true_rank)))
V0, _ = np.linalg.qr(rng.standard_normal((n, true_rank)))
s0 = 5.0 ** (-np.arange(true_rank)) # দ্রুত-পতনশীল singular value
A = (U0 * s0) @ V0.T + 1e-4 * rng.standard_normal((m, n))
# ---------- Randomized SVD (চার ধাপ) ----------
def randomized_svd(A, k, p=10, q=1, rng=None):
rng = rng or np.random.default_rng(0)
n = A.shape[1]
Omega = rng.standard_normal((n, k + p)) # ১. random প্রশ্ন
Y = A @ Omega
for _ in range(q): # power iteration (তীক্ষ্ণ করা)
Y = A @ (A.T @ Y)
Q, _ = np.linalg.qr(Y) # ২. orthonormalize
B = Q.T @ A # ৩. compress (ছোট!)
Ub, s, Vt = np.linalg.svd(B, full_matrices=False)# ৪. tiny SVD
return (Q @ Ub)[:, :k], s[:k], Vt[:k]
k = 10
U, s, Vt = randomized_svd(A, k, p=10, q=1, rng=rng)
# ---------- সত্যের সাথে মেলানো: full SVD-এর singular value ----------
s_full = np.linalg.svd(A, compute_uv=False)
print("randomized top-10 singular values:", np.round(s[:5], 5), "...")
print("full top-10 singular values:", np.round(s_full[:5], 5), "...")
print("singular values match:", np.allclose(s, s_full[:k], atol=1e-3))
# ---------- reconstruction ভুল বনাম সেরা সম্ভাব্য (Eckart-Young) ----------
A_approx = (U * s) @ Vt
err_rand = np.linalg.norm(A - A_approx, 2)
err_best = s_full[k] # σ_{k+1} = সেরা সম্ভাব্য
print(f"randomized rank-{k} error : {err_rand:.2e}")
print(f"best possible (σ_k+1) : {err_best:.2e}")
print(f"ratio (≈1 হলে near-optimal): {err_rand / err_best:.3f}")
# ---------- Johnson–Lindenstrauss: দূরত্ব রক্ষা ----------
X = rng.standard_normal((200, 500)) # R^500-এ ২০০ বিন্দু
i, j = 0, 1
d_orig = np.linalg.norm(X[i] - X[j])
for k_proj in [10, 50, 200]:
S = rng.standard_normal((500, k_proj)) / np.sqrt(k_proj)
Xs = X @ S
d_new = np.linalg.norm(Xs[i] - Xs[j])
print(f"k={k_proj:3d}: distance ratio (after/before) = {d_new/d_orig:.3f}")
# ---------- speedup: full বনাম randomized (বড় matrix) ----------
import time
Abig, _ = np.linalg.qr(rng.standard_normal((2000, 50)))
Abig = (Abig * 2.0**(-np.arange(50))) @ rng.standard_normal((50, 2000))
t0 = time.perf_counter(); np.linalg.svd(Abig, full_matrices=False); t_full = time.perf_counter()-t0
t0 = time.perf_counter(); randomized_svd(Abig, 20, rng=rng); t_rand = time.perf_counter()-t0
print(f"full SVD: {t_full*1e3:.0f}ms, randomized: {t_rand*1e3:.0f}ms, speedup {t_full/t_rand:.1f}x")
Output ব্যাখ্যা:
- Randomized আর full SVD-এর top-\(k\) singular value প্রায় হুবহু মিলেছে (
True) — এলোমেলো \(\Omega\) দিয়ে শুরু করেও নির্ভুল উত্তর। - reconstruction ভুলের অনুপাত \(\approx 1\) — মানে randomized approximation Eckart–Young-এর সেরা সম্ভাব্যের প্রায় সমান (Property 2)। randomness প্রায় কিছুই হারায়নি।
- JL অংশে: \(k\) যত বড়, distance ratio তত \(1.0\)-এর কাছে (Property 5) — random projection দূরত্ব রক্ষা করছে, আর বেশি মাত্রায় আরো ভালো।
- বড় matrix-এ randomized SVD full-এর চেয়ে দ্রুত (speedup \(> 1\)), কারণ ব্যয়বহুল SVD চলেছে শুধু ছোট \(B\)-তে (Property 1)।
৭. Worked Examples¶
Example 1 — Sketching-এর গণিত: কেন \(Y = A\Omega\) range ধরে¶
\(A\) একটা rank-\(2\) matrix, column space span করে \(\{u_1, u_2\}\)। \(\Omega\) (\(n \times 2\)) random হলে \(Y = A\Omega\)-এর দুই column:
যেখানে \(c\)-গুলো random সংখ্যা (কারণ \(\omega\) random)। প্রশ্ন: \(\{y_1, y_2\}\) কি \(\{u_1, u_2\}\)-এর পুরো space span করে? করে, যদি \(\begin{bmatrix} c_{11} & c_{21} \\ c_{12} & c_{22}\end{bmatrix}\) invertible হয় — আর random \(2\times 2\) matrix প্রায় নিশ্চিতভাবে invertible (\(\det = 0\) হওয়ার সম্ভাবনা শূন্য)। তাই \(\{y_1, y_2\}\) span \(= \{u_1, u_2\}\) span \(= A\)-এর column space। এলোমেলো নমুনা পুরো space চিনে ফেললো — এটাই sketching-এর ভিত্তি (§৫ পথ ১)।
Example 2 — Randomized SVD হাতে-কলমে (ছোট rank-1)¶
Target \(k = 1\), ধরো \(\Omega = \begin{bmatrix} 1 \\ 0 \end{bmatrix}\) (সরলতার জন্য; বাস্তবে random)।
ধাপ ১ — Sketch: \(Y = A\Omega = \begin{bmatrix} 2 \\ 1 \\ 3 \end{bmatrix}\)।
ধাপ ২ — Orthonormalize: \(\|Y\| = \sqrt{4+1+9} = \sqrt{14}\); \(Q = \frac{1}{\sqrt{14}}(2, 1, 3)^T\)।
ধাপ ৩ — Compress: \(B = Q^TA = \frac{1}{\sqrt{14}}\begin{bmatrix} 2 & 1 & 3\end{bmatrix}\begin{bmatrix} 2 & 4 \\ 1 & 2 \\ 3 & 6 \end{bmatrix} = \frac{1}{\sqrt{14}}\begin{bmatrix} 14 & 28 \end{bmatrix} = \sqrt{14}\begin{bmatrix} 1 & 2 \end{bmatrix}\)।
ধাপ ৪ — Tiny SVD: \(B\) (একটা row)-এর norm \(\sqrt{14}\cdot\sqrt5 = \sqrt{70}\); singular value \(\sigma_1 = \sqrt{70}\), right vector \(V^T = \frac{1}{\sqrt5}(1, 2)\)।
যাচাই: পুনর্গঠন \(\sigma_1 (Q)(V^T) = \sqrt{70}\cdot\frac{1}{\sqrt{14}}(2,1,3)^T\cdot\frac{1}{\sqrt5}(1,2) = (2,1,3)^T(1,2) = A\) ✓ — rank-1 matrix নিখুঁতভাবে ফিরে এলো। বিশাল \(A\) থেকে শুধু ছোট \(B\)-তে কাজ করেই।
Example 3 — কখন randomized SVD ব্যবহার করবে (আর কখন নয়)¶
তিন পরিস্থিতি:
- (a) \(10^5 \times 10^5\) matrix, singular value দ্রুত পড়ে, দরকার top-\(20\): → আদর্শ randomized SVD ক্ষেত্র। low-rank কাঠামো আছে, full SVD অসম্ভব, top-\(k\) যথেষ্ট। \(20\)০০ গুণ পর্যন্ত দ্রুত।
- (b) \(500 \times 500\) matrix, দরকার সব singular value: → full SVD ব্যবহার করো। ছোট, আর সব singular value চাই — randomized-এর কোনো সুবিধা নেই (সে শুধু top-\(k\)-তে সস্তা)।
- (c) \(10^5 \times 10^5\) matrix, singular value খুব ধীরে পড়ে (প্রায় full-rank noise): → সাবধান। low-rank কাঠামো নেই মানে randomized approximation দুর্বল — power iteration (\(q = 2\)–\(3\)) দিয়ে কিছুটা উদ্ধার, নয়তো randomized-ই ভুল যন্ত্র। নিয়ম: randomized SVD-এর সাফল্য singular value-র দ্রুত পতনের ওপর নির্ভর — কাঠামো না থাকলে জাদু নেই।
৮. Problems ও Solutions¶
Problem 1. একটা rank-\(3\) matrix \(A\) (\(1000 \times 800\))-এর top-\(3\) singular vector চাই। (a) full SVD-এর খরচ আর randomized SVD (\(k=3, p=7\))-এর খরচ আনুমানিক তুলনা করো। (b) কত গুণ দ্রুত?
Solution
Full SVD-এর খরচ \(\sim mn\min(m,n) = 1000 \times 800 \times 800 = 6.4 \times 10^{8}\) flop।
Randomized (\(k + p = 10\) column): মূল খরচ কয়েকটা matrix-গুণ — \(A\Omega\) (\(mn(k+p) = 1000\times800\times10 = 8\times10^6\)), \(Q^TA\) (একই \(8\times10^6\)), আর ছোট \(B\) (\(10\times800\))-এর SVD (\(\sim (k+p)^2 n = 100\times800 = 8\times10^4\), নগণ্য)। মোট \(\sim 1.6\times10^7\) flop।
(b) অনুপাত \(\approx 6.4\times10^8 / 1.6\times10^7 = 40\) গুণ দ্রুত। সাধারণভাবে: speedup \(\approx n/(k+p)\) — এখানে \(800/10 \approx 40\) ✓। matrix যত বড় আর \(k\) যত ছোট, সুবিধা তত বেশি।
Problem 2. Johnson–Lindenstrauss lemma অনুযায়ী \(10{,}000\) বিন্দুর জোড়া-দূরত্ব \(10\%\) (\(\epsilon = 0.1\)) ফ্যাক্টরের মধ্যে রক্ষা করতে target মাত্রা \(k = O(\epsilon^{-2}\log N)\) মোটামুটি কত? মূল মাত্রা \(10^6\) হলে উত্তর বদলায় কি?
Solution
\(k \approx \frac{c\log N}{\epsilon^2}\) (\(c\) একটা ছোট ধ্রুবক, সাধারণত \(\sim 4\)–\(8\))। \(N = 10^4\), \(\log N = \log(10^4) \approx 9.2\) (natural log), \(\epsilon^2 = 0.01\):
(constant-এর ওপর নির্ভর করে; ব্যবহারিকভাবে প্রায়ই এর অনেক কম কাজ চলে)।
মূল মাত্রা \(10^6\) হলে? উত্তর একটুও বদলায় না! JL-এর সূত্রে মূল মাত্রা \(n\) নেই — শুধু বিন্দুর সংখ্যা \(N\) আর নির্ভুলতা \(\epsilon\) আছে (Property 5)। এটাই lemma-র বিস্ময়: \(10^6\) বা \(10^9\) মাত্রা থেকে একই \(k\)-তে নামানো যায়, দূরত্ব একই রকম রক্ষিত। এই মাত্রা-নিরপেক্ষতাই high-dim data-তে sketching-কে অপরিহার্য করে।
Problem 3. Power iteration parameter \(q\)-এর কাজ কী? singular value যদি \(\sigma = (10, 9.9, 9.8, \dots)\)-এর মতো ধীরে কমে, তাহলে \(q = 0\) বনাম \(q = 2\)-তে top singular value-র আপেক্ষিক ফাঁক কীভাবে বদলায়?
Solution
Power iteration \(Y = (AA^T)^qA\Omega\)-তে singular value \(\sigma_i \to \sigma_i^{2q+1}\) হয় (কারণ \(A\)-এর \(2q+1\)টা গুণ কার্যত)।
Top দুই singular value \(\sigma_1 = 10, \sigma_2 = 9.9\) ধরি, আপেক্ষিক ফাঁক \(\sigma_2/\sigma_1 = 0.99\):
- \(q = 0\): ফাঁক \(0.99\) — প্রায় সমান, sketch-এ \(\sigma_1\) আর \(\sigma_2\)-এর দিক আলাদা করা কঠিন (ঘোলা)।
- \(q = 2\): exponent \(2(2)+1 = 5\), ফাঁক \((0.99)^5 \approx 0.951\) — এখনো কাছাকাছি কিন্তু আলাদা করা সহজতর। ফাঁক আরো বাড়াতে \(q\) বাড়াও।
(উদাহরণটা ধীর-পতনের চরম কেস; বাস্তবে \(\sigma_2/\sigma_1 = 0.7\) হলে \(q=2\)-এ \(0.7^5 \approx 0.17\) — বিশাল ফাঁক)। মূল কথা: \(q\) বড়-ছোট singular value-র আপেক্ষিক দূরত্ব বাড়ায়, তাই sketch তীক্ষ্ণ হয় (Property 4) — খরচ শুধু \(2q\)টা বাড়তি matrix-গুণ। singular value ধীরে কমলে \(q = 1\)–\(2\) প্রায় বাধ্যতামূলক।
Problem 4. কেন randomized SVD-তে oversampling (\(p\) বাড়তি column) নেওয়া হয়? \(p = 0\) (ঠিক \(k\) column) নিলে কী ঝুঁকি, আর \(p = 10\) কীভাবে বাঁচায়?
Solution
Target rank \(k\) ধরতে অন্তত \(k\)টা "ভালো" random দিক লাগে। \(p = 0\) নিলে ঠিক \(k\)টা random column — যদি দুর্ভাগ্যক্রমে দু-একটা প্রায় linearly dependent হয় (বা target space-এর কোনো দিকে দুর্বলভাবে align করে), তাহলে সেই space সম্পূর্ণ ধরা পড়ে না, approximation খারাপ হয়।
\(p = 10\) নিলে \(k + 10\)টা column — কয়েকটা "নষ্ট" হলেও যথেষ্ট ভালো দিক থাকে space ধরতে। তত্ত্বে ভুলের গুণক \(\left(1 + \sqrt{\frac{k}{p-1}}\right)\) (Property 2) — \(p\) বড় হলে এই গুণক \(1\)-এর কাছে নামে, ব্যর্থতার সম্ভাবনা exponentially কমে।
খরচ? মাত্র \(10\)টা বাড়তি column — বড় \(A\)-তে নগণ্য বৃদ্ধি। তাই সবসময় oversample করো (\(p = 5\)–\(10\)): প্রায়-বিনামূল্যের বীমা যা নির্ভুলতা ও নির্ভরযোগ্যতা দুটোই বিশাল বাড়ায় (Property 3)।
Problem 5. একজন বলছে: "আমি random projection দিয়ে দূরত্ব রক্ষা করলাম, কিন্তু projection-এর জন্য random matrix \(S\)-এর প্রতিটা row কি normalize করতে হবে?" ব্যাখ্যা করো কেন \(\frac{1}{\sqrt k}\) scaling লাগে।
Solution
হ্যাঁ, scaling লাগে। যদি \(S\) (\(k \times n\))-এর entry iid standard normal (variance \(1\)) হয়, তাহলে \(Sx\)-এর প্রতিটা coordinate-এর variance \(\approx \|x\|^2\) (কারণ \(k\)টা independent term-এর যোগ), তাই \(\|Sx\|^2 \approx k\|x\|^2\) — দৈর্ঘ্য \(\sqrt k\) গুণ বেড়ে যায়।
ঠিক করতে \(S\)-কে \(\frac{1}{\sqrt k}\) দিয়ে scale করো: তখন \(\mathbb{E}\|Sx\|^2 = \|x\|^2\) — প্রত্যাশিত দৈর্ঘ্য হুবহু সংরক্ষিত (§৫ পথ ২)। এই \(\frac{1}{\sqrt k}\) ছাড়া দূরত্বের অনুপাত \(1\)-এর বদলে \(\sqrt k\)-এর কাছে বসতো (fig03-এর histogram-এর চূড়া \(1.0\)-এ থাকতো না)। শিক্ষা: random projection-এ scaling ঐচ্ছিক নয় — এটাই দৈর্ঘ্য/দূরত্ব রক্ষার গণিতগত শর্ত। (কোডে fig03 আর §৬-এ ঠিক এই /np.sqrt(k) দেখেছো।)
Problem 6. Randomized SVD-এর নির্ভুলতা Eckart–Young-এর (\(\sigma_{k+1}\)) সাথে তুলনা করা হয়। একটা matrix-এর singular value \(\sigma = (100, 50, 10, 0.1, 0.05, \dots)\)। rank-\(3\) randomized approximation-এর ভুল মোটামুটি কত হবে, আর rank-\(2\) হলে?
Solution
Eckart–Young: সেরা rank-\(k\) approximation-এর ভুল (spectral norm-এ) \(= \sigma_{k+1}\)। Randomized SVD (oversampling সহ) এর খুব কাছে পৌঁছায় (Property 2)।
- rank-\(3\): ভুল \(\approx \sigma_4 = 0.1\)। প্রথম তিনটা (\(100, 50, 10\)) ধরা পড়লো, বাদ পড়া সবচেয়ে বড়টা \(\sigma_4 = 0.1\) — মূল matrix-এর (\(\sigma_1 = 100\)) তুলনায় \(0.1\%\), চমৎকার approximation।
- rank-\(2\): ভুল \(\approx \sigma_3 = 10\) — \(\sigma_1 = 100\)-এর \(10\%\)। অনেক বেশি ভুল, কারণ তৃতীয় গুরুত্বপূর্ণ দিক (\(\sigma_3 = 10\)) বাদ পড়লো।
পর্যবেক্ষণ: এখানে \(\sigma_3 = 10\) আর \(\sigma_4 = 0.1\)-এর মধ্যে বিশাল ফাঁক (gap) — মানে matrix "কার্যত rank-\(3\)"। তাই rank-\(3\)-এই ভুল নাটকীয়ভাবে কমে যায় (\(10 \to 0.1\))। নিয়ম: singular value-তে যেখানে বড় ফাঁক, ঠিক সেখানেই rank কাটা উচিত — randomized SVD সেই ফাঁকের ঠিক ওপরে near-optimal।
Problem 7. (কোডে) একটা \(500 \times 300\) rank-\(5\) matrix (+সামান্য noise) বানাও। randomized SVD (\(k=5\)) চালিয়ে (a) top-\(5\) singular value full SVD-এর সাথে মেলাও; (b) reconstruction ভুল আর \(\sigma_6\) তুলনা করো।
Solution
import numpy as np
rng = np.random.default_rng(7)
m, n, r = 500, 300, 5
U0, _ = np.linalg.qr(rng.standard_normal((m, r)))
V0, _ = np.linalg.qr(rng.standard_normal((n, r)))
A = (U0 * (4.0**(-np.arange(r)))) @ V0.T + 1e-5 * rng.standard_normal((m, n))
def rsvd(A, k, p=10, q=2, rng=None):
rng = rng or np.random.default_rng(0)
Omega = rng.standard_normal((A.shape[1], k+p))
Y = A @ Omega
for _ in range(q): Y = A @ (A.T @ Y)
Q, _ = np.linalg.qr(Y)
Ub, s, Vt = np.linalg.svd(Q.T @ A, full_matrices=False)
return (Q @ Ub)[:, :k], s[:k], Vt[:k]
U, s, Vt = rsvd(A, 5, rng=rng)
s_full = np.linalg.svd(A, compute_uv=False)
print("(a) rand :", np.round(s, 5))
print(" full :", np.round(s_full[:5], 5))
print(" match:", np.allclose(s, s_full[:5], atol=1e-3))
err = np.linalg.norm(A - (U*s)@Vt, 2)
print(f"(b) rand error={err:.2e}, sigma_6={s_full[5]:.2e}, ratio={err/s_full[5]:.2f}")
match True); (b) reconstruction ভুল \(\approx \sigma_6\) (noise floor), ratio \(\approx 1\) — near-optimal (Property 2)। শিক্ষা: এলোমেলো \(\Omega\), তবু Eckart–Young-এর সেরা সম্ভাব্যের কাছাকাছি — randomness জিতেছে।
Problem 8. Chapter 8.3-এর সাথে সেতু: randomized SVD-এর power iteration (\(q\)) আর Chapter 8.3-এর power method — দুটোতে কী মিল, কী অমিল?
Solution
মিল: দুটোই matrix-এর বারবার গুণের ওপর দাঁড়িয়ে, আর একই নীতি ব্যবহার করে — বড় singular/eigenvalue-র দিক গুণের সাথে সাথে জোরালো হয়ে ওঠে, ছোটগুলো মিলিয়ে যায় (Chapter 8.3 Property 1)। randomized SVD-এর \((AA^T)^q\)-এর প্রতিটা গুণ singular value বর্গ করে ফাঁক বাড়ায় — ঠিক power method-এর \(A^k\)-এর মতো।
অমিল: - Power method (Ch 8.3) একটা vector দিয়ে চলে, লক্ষ্য একটা (dominant) eigenvector। Randomized SVD একগুচ্ছ random vector (\(\Omega\)) দিয়ে চলে, লক্ষ্য top-\(k\) subspace একসাথে। - Power method একা eigenvalue দেয়; randomized SVD subspace ধরে তারপর ছোট matrix-এ নিখুঁত SVD চালিয়ে singular value + vector দুটোই দেয়। - randomized SVD-তে \(q\) ছোট (\(1\)–\(2\)) রাখা হয় (subspace ধরাই যথেষ্ট, পূর্ণ convergence লাগে না), power method বহু iteration চালায় নিখুঁত eigenvector-এর জন্য।
এক বাক্যে: randomized SVD হলো power method-এর "block + random start" সংস্করণ — একবারে অনেক দিকে power iteration চালিয়ে পুরো top-\(k\) subspace ধরে ফেলা (একে বলে block/subspace power iteration)। Chapter 8.3-এর ধারণাই এখানে বিশাল স্কেলে, randomness-এর মোড়কে।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "Random matrix দিয়ে শুরু মানে উত্তরও random/অনির্ভরযোগ্য" | High dimension-এ concentration of measure-এর কারণে randomized SVD প্রায় নিশ্চিতভাবে near-optimal উত্তর দেয় (Property 2)। ব্যর্থতার সম্ভাবনা oversampling-এ exponentially কমে — randomness এখানে বন্ধু। |
| "Randomized SVD যেকোনো matrix-এ full SVD-এর চেয়ে ভালো" | শুধু তখন, যখন matrix low-rank বা প্রায় low-rank (singular value দ্রুত পড়ে) আর তোমার top-\(k\) দরকার। full-rank noise-এ বা সব singular value চাইলে সুবিধা নেই (Example 3)। |
| "Sketching মানে data হারানো, তাই ফলাফল খারাপ" | Sketching জ্যামিতি (দূরত্ব, angle, subspace) আশ্চর্য ভালোভাবে রক্ষা করে (Johnson–Lindenstrauss, Property 5) — যা হারায় তা বেশিরভাগ noise, কাঠামো নয়। |
| "Oversampling (\(p\)) অপচয় — ঠিক \(k\) column-ই তো লাগে" | ঠিক \(k\) (\(p=0\)) নেওয়া ঝুঁকিপূর্ণ (দুর্ভাগ্যজনক নমুনায় ব্যর্থতা)। \(p = 5\)–\(10\) প্রায়-বিনামূল্যে নির্ভুলতা ও নির্ভরযোগ্যতা বিশাল বাড়ায় (Property 3, Problem 4)। |
| "singular value ধীরে কমলেও randomized SVD সমান ভালো" | না — ধীর পতনে sketch ঘোলা হয়, নির্ভুলতা পড়ে। তখন power iteration (\(q = 1\)–\(2\)) দিয়ে singular value তীক্ষ্ণ করতে হয় (Property 4, Problem 3)। |
| "random projection-এ scaling (\(1/\sqrt k\)) ঐচ্ছিক" | বাধ্যতামূলক — এটাই দৈর্ঘ্য/দূরত্ব রক্ষার শর্ত। scaling ছাড়া দূরত্ব \(\sqrt k\) গুণ বেড়ে যায় (Problem 5)। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Sketching | \(Y = A\Omega\): random প্রশ্নে column space ধরা | exit poll — random নমুনা পুরো ছবি দেয় |
| Randomized SVD | sketch → QR → \(B=Q^TA\) → tiny SVD | বিশাল matrix-এ সস্তা, ছোটে নিখুঁত |
| খরচ | \(\sim mnk\) (full-এর \(mn^2\)-এর \(n/k\) ভাগ) | \(k\) ছোট = বিশাল সাশ্রয় |
| নির্ভুলতা | \(\approx\) Eckart–Young (\(\sigma_{k+1}\)) | randomness প্রায় কিছুই হারায় না |
| Oversampling \(p\) | \(k+p\) column (\(p=5\)–\(10\)) | প্রায়-বিনামূল্যের বীমা |
| Power iteration \(q\) | \((AA^T)^qA\Omega\): \(\sigma_i \to \sigma_i^{2q+1}\) | ধীর পতনে singular value তীক্ষ্ণ করা |
| Johnson–Lindenstrauss | \(k = O(\epsilon^{-2}\log N)\), \(n\)-নিরপেক্ষ | random projection দূরত্ব রক্ষা করে |
| কখন ব্যবহার | low-rank + বড় + top-\(k\) | কাঠামো থাকলেই জাদু, নইলে নয় |
পরের chapter-এর সেতু: এই chapter দিয়ে Part VIII — Computational/Numerical Linear Algebra — শেষ। আমরা দেখলাম কম্পিউটারে linear algebra আসলে কেমন: floating point-এর ভুল (8.1), \(Ax=b\) দ্রুত সমাধান (8.2), eigenvalue বের করা (8.3), আর বিশাল matrix-এ randomized জাদু (8.4)। এবার আমরা প্রবেশ করবো Part IX — PhD Level: Advanced Theory-তে, যেখানে গণিত আরো গভীর ও কঠোর: abstract vector space, Jordan form, matrix calculus, spectral theory-র সাধারণীকরণ, random matrix theory (Chapter 9.5-এ ছুঁয়ে এসেছো!), আর সবশেষে tensor — যেখানে matrix-এর দুই index পেরিয়ে আমরা যাই তিন, চার, বহু-মাত্রায় (Chapter 9.6)। সংখ্যা থেকে গঠনে, গঠন থেকে বিমূর্ততায় — এবার সেই যাত্রা।
📓 Notebook Project¶
notebooks/part-08/ch04-project.ipynb — Part VIII-এর flagship project: scratch-এ randomized SVD (চার ধাপ + power iteration) লিখে numpy-র full SVD-এর সাথে গতি ও নির্ভুলতা বেঞ্চমার্ক করা; একটা ছবি matrix low-rank compress করে চোখে দেখা; Johnson–Lindenstrauss projection দিয়ে high-dim বিন্দুদের দূরত্ব রক্ষা যাচাই; আর singular value-র পতন-হার কীভাবে randomized-এর সাফল্য ঠিক করে তা পরীক্ষা করা।