Chapter 5.2 — Gram–Schmidt and QR Decomposition (গ্রাম–শ্মিট ও QR ডিকম্পোজিশন)¶
আগের chapter-এ ছায়া ফেলা শিখেছো। এবার সেই ছায়াকে হাতিয়ার বানাবো: এলোমেলো, তির্যক vector-দের একটার পর একটার ছায়া বিয়োগ করে করে বানাবো একদম নিখুঁত, পরস্পর-লম্ব, দৈর্ঘ্য-১ vector-এর দল। পুরো প্রক্রিয়াটাকে matrix-এর ভাষায় লিখলেই পেয়ে যাবে \(A = QR\) — সংখ্যা-জগতের অন্যতম দরকারি decomposition।
🎯 এই chapter-এ যা শিখবে¶
- Orthonormal(অর্থোনরমাল) set ও basis কি, আর কেন এরা "গণিতের গ্রাফ পেপার"
- Orthonormal basis-এ coordinate বের করা কেন শুধুই dot product — কোনো সমীকরণ সমাধান লাগে না
- Gram–Schmidt Procedure(গ্রাম–শ্মিট প্রসিডিউর): ধাপে ধাপে, ছবিতে ছবিতে — "ছায়া বিয়োগ" algorithm
- QR Decomposition(QR ডিকম্পোজিশন): \(A = QR\) — Gram–Schmidt-এর হিসাবের খাতা
- NumPy-র
np.linalg.qrআর নিজের লেখা Gram–Schmidt মিলিয়ে দেখা
🖼️ এক ছবিতে মূল idea¶
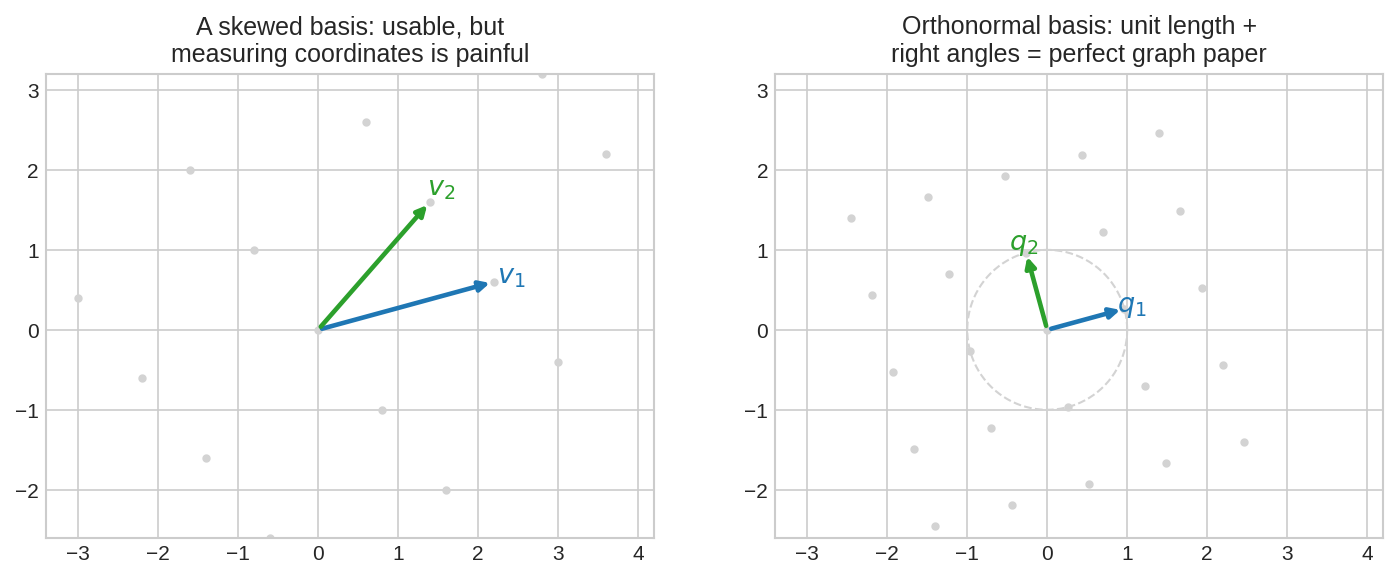
বাঁয়ে: তির্যক (skewed) basis — এর গ্রিডে কাজ চলে, কিন্তু কোনো বিন্দুর coordinate মাপতে সমীকরণ সমাধান করতে হয়। ডানে: orthonormal basis — ইউনিট দৈর্ঘ্য, সমকোণ — নিখুঁত গ্রাফ পেপার, coordinate মাপা মানে স্রেফ ছায়া মাপা। Gram–Schmidt হলো বাঁ থেকে ডানে যাওয়ার মেশিন।
১. কি? (What)¶
দৈনন্দিন analogy: বাঁকা দেয়ালের বাড়ি সোজা করা¶
ধরো তুমি একটা পুরনো বাড়ি কিনেছো যার দেয়ালগুলো একটার সাথে আরেকটা ঠিক \(90°\)-তে নেই — সব একটু একটু তির্যক। আসবাব বসাতে, টাইলস মাপতে প্রতিবার ঝামেলা। একজন রাজমিস্ত্রি ডাকলে সে কী করবে? প্রথম দেয়ালটা রেখে দেবে (শুধু মাপ ঠিক করবে), দ্বিতীয় দেয়ালের যে অংশ প্রথমটার গায়ে হেলে আছে সেটা কেটে ফেলবে, তৃতীয়টার থেকে কেটে ফেলবে আগের দুটোর দিকে হেলে-থাকা অংশ... শেষে সব দেয়াল পরস্পর লম্ব।
Gram–Schmidt ঠিক এই রাজমিস্ত্রি — "হেলে থাকা অংশ" মানে আগের vector-দের ওপর ছায়া (projection), আর "কেটে ফেলা" মানে বিয়োগ।
সংজ্ঞাগুলো¶
Orthogonal set(অর্থোগোনাল সেট): একগুচ্ছ nonzero vector \(\{u_1, \dots, u_k\}\), যেখানে প্রতিটি জোড়া পরস্পর লম্ব: \(u_i^T u_j = 0\) যখন \(i \neq j\)।
Orthonormal set(অর্থোনরমাল সেট): orthogonal set, যার প্রতিটি vector-এর দৈর্ঘ্যও ১:
("ortho" = লম্ব, "normal" = normalized অর্থাৎ দৈর্ঘ্য ১ করা।) এই শর্তটা একসাথে লেখা যায় \(Q^TQ = I\) আকারে, যেখানে \(Q\)-এর column গুলো হলো \(q_i\)।
Orthonormal basis(অর্থোনরমাল বেসিস): যে orthonormal set একই সাথে space-টার Basis(বেসিস — Chapter 4.3)। যেমন \(\mathbb{R}^2\)-এর standard basis \(e_1, e_2\); কিংবা সেটাকে যেকোনো কোণে ঘুরিয়ে পাওয়া \(q_1, q_2\)।
Gram–Schmidt: যেকোনো linearly independent list \(v_1, \dots, v_k\) থেকে orthonormal list \(q_1, \dots, q_k\) বানানোর algorithm — এমনভাবে যে প্রতি ধাপে span অক্ষুণ্ণ থাকে:
QR Decomposition: \(A\)-এর column-গুলোতে Gram–Schmidt চালানোর ফলাফলটাই সাজিয়ে লেখা:
যেখানে \(Q\)-এর column গুলো orthonormal (\(Q^TQ = I\)), আর \(R\) হলো Upper Triangular(আপার ট্রায়াঙ্গুলার — কর্ণের নিচে সব শূন্য) matrix যেটা মনে রাখে "কোন ধাপে কতটুকু ছায়া কেটেছিলাম।"
২. দেখতে কেমন?¶
দৃশ্য ১: এক ধাপের ছবি — ছায়া খোঁজো, ছায়া বাদ দাও¶
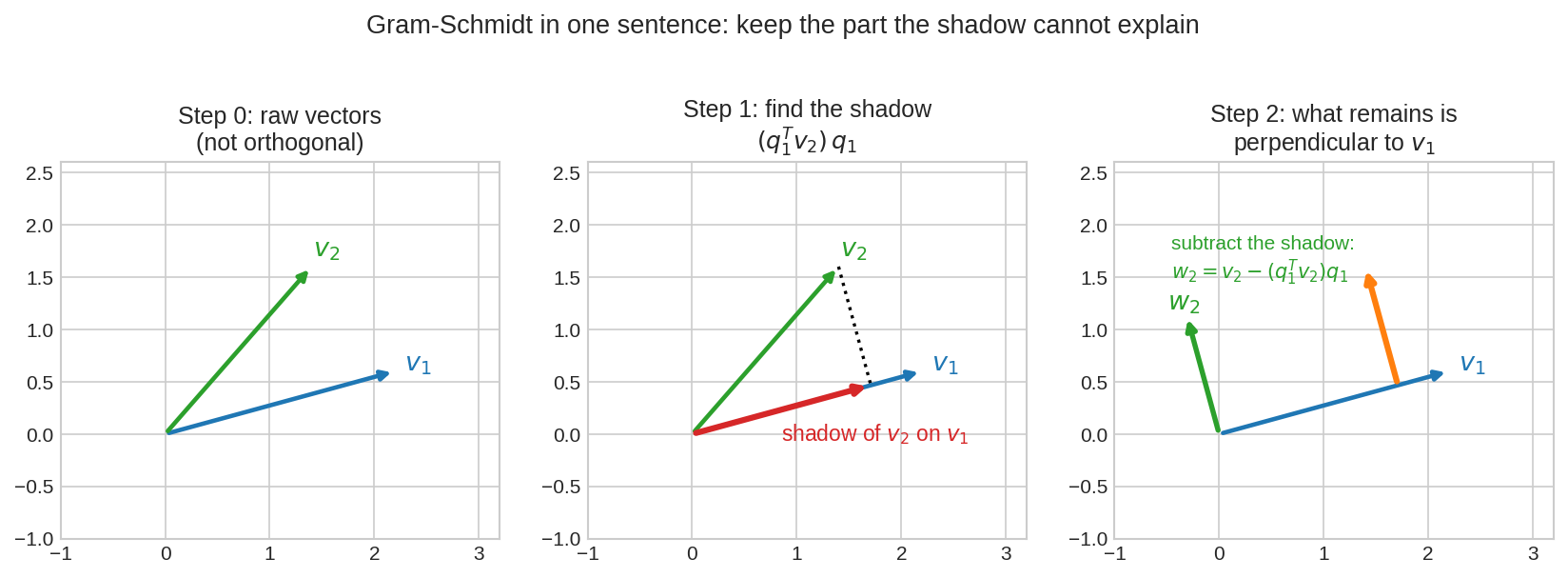
বাঁয়ে raw vector \(v_1, v_2\) — লম্ব নয়। মাঝে: \(v_1\)-এর ওপর \(v_2\)-এর ছায়া (লাল)। ডানে: \(v_2\) থেকে ছায়া বিয়োগ করলে থাকে \(w_2\) — যেটা \(v_1\)-এর ওপর নিখুঁত লম্ব। এই এক ধাপই Gram–Schmidt-এর হৃদয়; বাকিটা পুনরাবৃত্তি।
দৃশ্য ২: 3D-তে তিন ধাপ¶
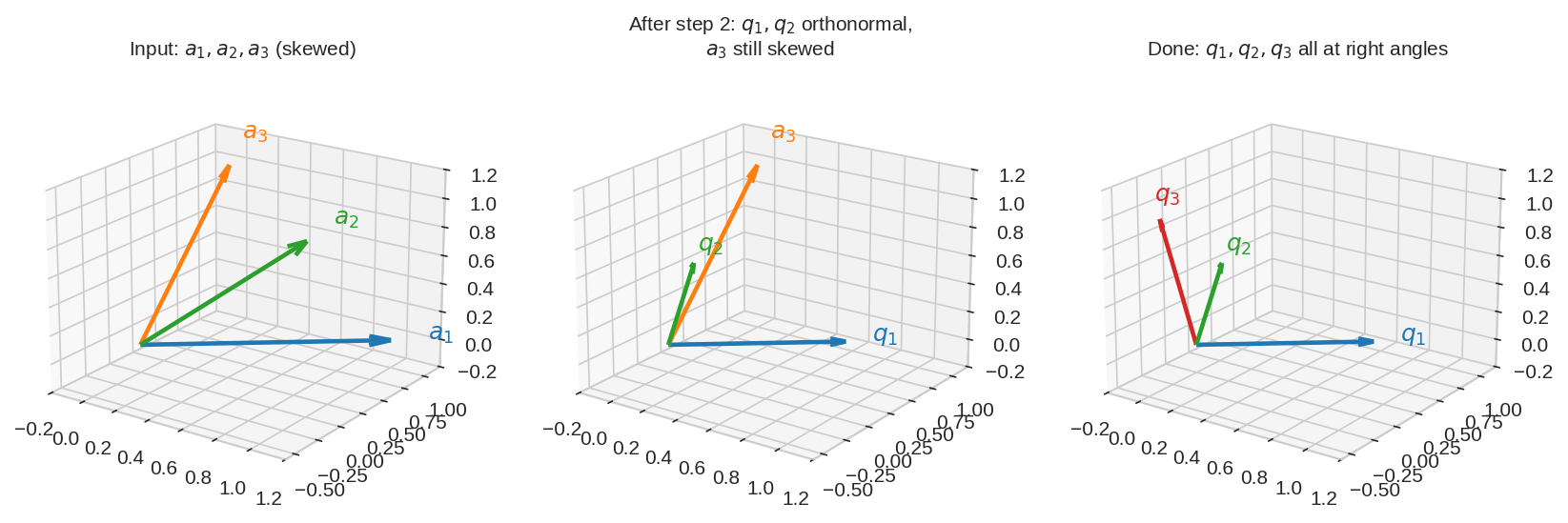
তিনটা তির্যক vector \(a_1, a_2, a_3\) ঢুকছে; একে একে ছায়া কেটে বেরিয়ে আসছে তিনটা orthonormal \(q_1, q_2, q_3\)। খেয়াল করো — \(q_3\) বানাতে আগের দুটোর ছায়াই কাটতে হয়েছে।
দৃশ্য ৩: হিসাবের খাতা — \(A = QR\)¶
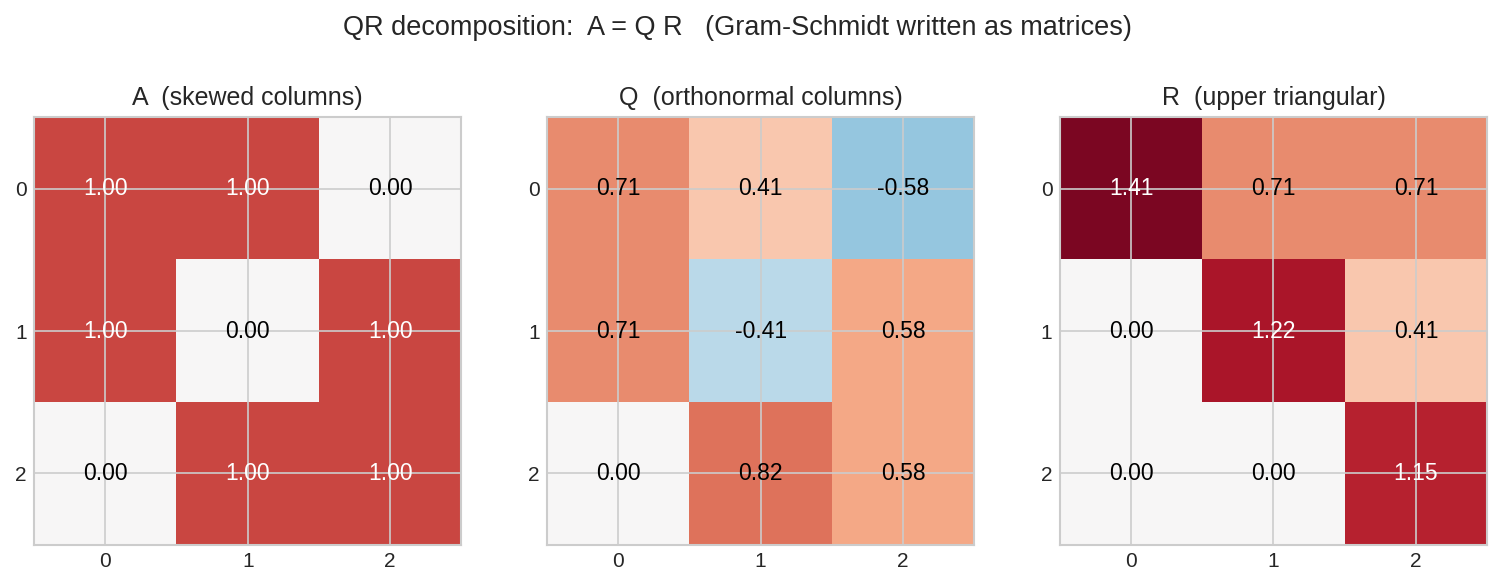
matrix হিসেবে দেখলে: skewed column-ওয়ালা \(A\) ভেঙে যায় orthonormal \(Q\) আর upper triangular \(R\)-এ। \(R\)-এর কর্ণের নিচে শূন্য কেন? কারণ \(j\)-তম column বানাতে শুধু প্রথম \(j\)টা \(q\)-ই লেগেছিল — পরেরগুলো নয়।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- ক্যামেরা ও রোবোটিক্স: রোবটের হাত বা ক্যামেরার orientation বোঝাতে ঘোরানো coordinate frame লাগে — orthonormal basis। সেন্সরের noise-এ frame একটু বেঁকে গেলে Gram–Schmidt দিয়ে "re-orthogonalize" করা হয়।
- সিগনাল প্রসেসিং: Fourier-এর sine/cosine wave-রা function জগতের orthonormal basis — একটা গানের ভেতর কোন সুর কতটুকু, বের করা হয় dot product (ছায়া!) দিয়ে।
- সার্ভেয়িং/নির্মাণ: ঠিক আমাদের analogy-র মতো — reference লাইন থেকে লম্ব লাইন তোলা।
Data Science / ML-এ:
- Least squares-এর নির্ভরযোগ্য সমাধান (Chapter 5.4): practical সব library (\(R\)-এর
lm, Python-এরlstsq) ভেতরে QR-ই ব্যবহার করে, কারণ normal equations-এর চেয়ে QR অনেক বেশি numerically stable। - Feature decorrelation: পরস্পর জড়ানো (correlated) feature-দের Gram–Schmidt করলে পাওয়া যায় "নতুন তথ্য শুধু"-ওয়ালা feature — regression-এ এর নামই partialling out।
- Eigenvalue algorithm (Part VIII): বিখ্যাত QR algorithm — বারবার \(A = QR\), তারপর \(RQ\) — eigenvalue বের করার industrial পদ্ধতি।
- Random projection / deep learning init: নিউরাল নেটের weight orthogonal রাখলে gradient বিস্ফোরিত/বিলীন হয় কম — orthogonal initialization।
৪. Properties¶
Property 1 — Orthonormal basis-এ coordinate = ছায়া (dot product)¶
\(q_1, \dots, q_n\) orthonormal basis হলে, যেকোনো \(x\)-এর জন্য:
মিনি-derivation: \(x = c_1q_1 + \cdots + c_nq_n\) লিখে দুই পাশে \(q_i^T\) বসাও:
সমীকরণ সমাধান ছাড়াই coefficient বেরিয়ে গেলো! Skewed basis-এ এই কাজে পুরো linear system solve করতে হতো (Chapter 4.4)। এই ছবিটা দেখো:
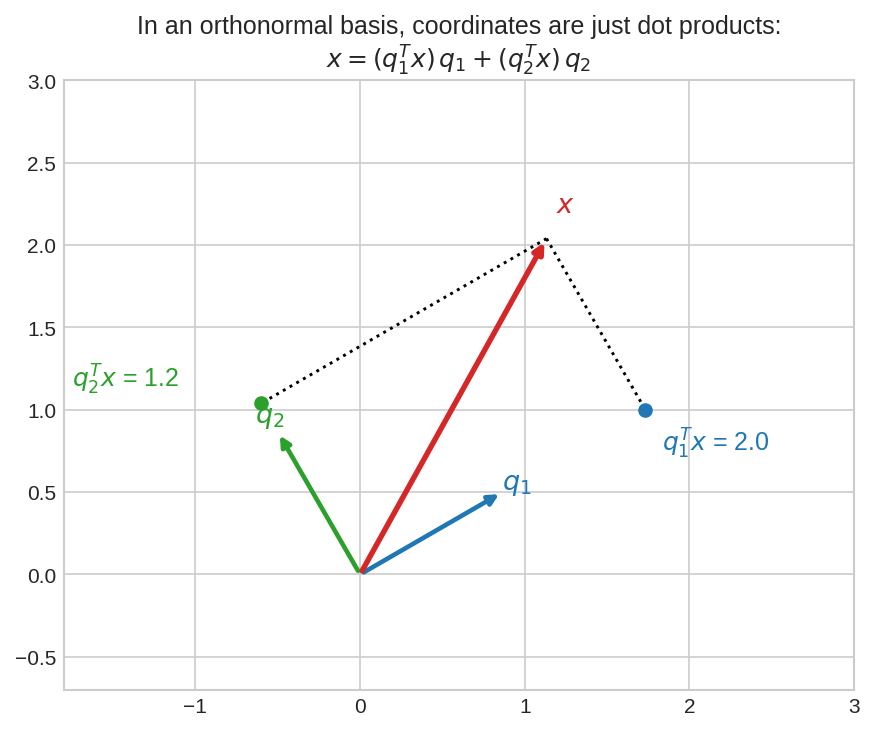
Orthonormal basis \(q_1, q_2\)-তে \(x\)-এর coordinate মানে দুই অক্ষের ওপর তার দুটো ছায়া — \(q_1^Tx\) আর \(q_2^Tx\)। মাপো, লেখো, শেষ।
Property 2 — Orthogonal set আপনাআপনি linearly independent¶
Nonzero orthogonal vector-রা কখনো একে অপরের combination হতে পারে না।
মিনি-proof: ধরো \(c_1u_1 + \cdots + c_ku_k = 0\)। দুই পাশে \(u_i^T\) বসালে সব cross term মরে যায়:
সব \(c_i = 0\), অতএব independent। ∎ — অর্থাৎ লম্ব দিকেরা কেউ কারো "অপ্রয়োজনীয় কপি" নয় (Chapter 4.2-এর ভাষায়)।
Property 3 — \(Q\) দৈর্ঘ্য আর কোণ বাঁচিয়ে রাখে¶
\(Q^TQ = I\) হলে:
মিনি-proof: \(\|Qx\|^2 = (Qx)^T(Qx) = x^T Q^TQ\, x = x^Tx = \|x\|^2\)। ∎ Geometric অর্থ: \(Q\) দিয়ে গুণ মানে জগৎটাকে শুধু ঘোরানো (বা আয়নায় উল্টানো) — কোনো টানাটানি-চ্যাপ্টানো নেই। এ কারণে QR-ভিত্তিক হিসাব এত stable: ঘোরালে ভুল বড় হয় না।
Property 4 — Square orthogonal matrix-এর inverse = transpose¶
\(Q\) square ও orthonormal-column হলে (\(n \times n\)):
কারণ \(Q^TQ = I\) আর square বলে \(QQ^T = I\)-ও সত্য। Inverse বের করা — সাধারণত \(O(n^3)\)-এর ব্যথা — এখানে ফ্রি! এই matrix-দের বলে Orthogonal Matrix(অর্থোগোনাল ম্যাট্রিক্স)। (হ্যাঁ, নামটা বিভ্রান্তিকর — "orthonormal matrix" বলা উচিত ছিল, কিন্তু ঐতিহ্য।)
Property 5 — \(R\)-এর diagonal(কর্ণ) nonzero ⇔ column গুলো independent¶
Gram–Schmidt চলার সময় কোনো ধাপে \(w_j = 0\) হয়ে গেলে বুঝবে \(v_j\) আগেরগুলোর combination ছিল (নতুন কোনো দিক দেয়নি)। \(A\)-এর column linearly independent হলে প্রতি ধাপে \(w_j \neq 0\), তাই \(R_{jj} = \|w_j\| > 0\) — decomposition নির্বিঘ্নে শেষ হয়।
৫. Intuition — কেন সত্য? (Algorithm-টা নিজে বানাই)¶
লক্ষ্য: \(v_1, v_2, v_3, \dots\) থেকে orthonormal \(q_1, q_2, q_3, \dots\) — যেন প্রতি ধাপে span একই থাকে।
ধাপ ১ — প্রথমজনকে শুধু মাপে আনো। লম্ব করার মতো "আগের কেউ" নেই, তাই শুধু normalize:
ধাপ ২ — দ্বিতীয়জনের থেকে প্রথমজনের ছায়া কাটো। Chapter 5.1-এর decomposition মনে করো: \(v_2\)-এর যে অংশ \(q_1\)-বরাবর সেটা ছায়া \((q_1^Tv_2)\,q_1\); যেটা লম্ব সেটাই আমাদের চাই:
Property 3 (আগের chapter) গ্যারান্টি দেয় \(w_2 \perp q_1\)। আর \(w_2\) হলো \(v_1, v_2\)-এরই combination, তাই span বদলায়নি।
ধাপ ৩ — তৃতীয়জনের থেকে দুজনের ছায়া কাটো:
এখানে সূক্ষ্ম একটা প্রশ্ন: দুটো ছায়া আলাদা আলাদা কেটে দিলে সত্যিই দুজনের সাথেই লম্ব হবে তো? হবে — কারণ \(q_1 \perp q_2\)। \(q_1\)-এর ছায়া কাটার সময় \(q_2\)-দিকের কিছু নষ্ট হয় না (তারা একে অপরের "এলাকায়" ঢোকে না)। চেক করো:
সাধারণ ধাপ:
QR কোথা থেকে এলো? ওপরের সমীকরণটা উল্টে \(v_j\)-কে \(q\)-দের ভাষায় লেখো:
প্রতিটা \(v_j\) শুধু প্রথম \(j\)টা \(q\) দিয়েই লেখা যাচ্ছে — column আকারে সাজালে এটাই \(A = QR\), আর "শুধু প্রথম \(j\)টা" কথাটাই \(R\)-কে upper triangular বানায়। মজার সূত্র: \(R_{ij} = q_i^Tv_j\) — \(R\) হলো ছায়াদের হিসাবের খাতা।
৬. Code-এ কেমনে লিখে¶
import numpy as np
np.random.seed(42)
def gram_schmidt(A):
"""A-র column-গুলো থেকে orthonormal Q আর upper triangular R।
(শেখার জন্য সহজ সংস্করণ — classical Gram-Schmidt)"""
A = A.astype(float)
m, n = A.shape
Q = np.zeros((m, n))
R = np.zeros((n, n))
for j in range(n):
w = A[:, j].copy()
for i in range(j): # আগের সব q-এর ছায়া কাটো
R[i, j] = Q[:, i] @ A[:, j] # ছায়ার পরিমাণ, খাতায় লেখো
w -= R[i, j] * Q[:, i]
R[j, j] = np.linalg.norm(w)
if R[j, j] < 1e-12:
raise ValueError(f"column {j} আগেরগুলোর combination!")
Q[:, j] = w / R[j, j] # normalize
return Q, R
A = np.array([[1., 1., 0.],
[1., 0., 1.],
[0., 1., 1.]])
Q, R = gram_schmidt(A)
print("Q =\n", Q.round(4))
print("R =\n", R.round(4))
print("Q^T Q = I?", np.allclose(Q.T @ Q, np.eye(3))) # True
print("QR = A? ", np.allclose(Q @ R, A)) # True
# NumPy-র built-in-এর সাথে মিলাও
Q2, R2 = np.linalg.qr(A)
print("NumPy-র সাথে মেলে?",
np.allclose(np.abs(Q), np.abs(Q2)), np.allclose(np.abs(R), np.abs(R2)))
Output ব্যাখ্যা:
Q^T Q = I? True— আমাদের \(q\)-রা সত্যিই orthonormal।QR = A? True— ভাঙা টুকরো জোড়া দিলে আসল matrix ফিরে আসে।- NumPy-র সাথে তুলনায়
np.absকেন? QR-এ প্রতিটা \(q_j\)-এর চিহ্ন (+/−) ambiguous — NumPy অনেক সময় উল্টো চিহ্ন বেছে নেয় (সাথে \(R\)-এর সংশ্লিষ্ট সারিও উল্টে যায়)। দুটোই সমান বৈধ। - সতর্কতা: বড়/প্রায়-dependent matrix-এ এই "classical" সংস্করণ floating point-এ ভেঙে পড়ে; বাস্তবে ব্যবহার হয় Modified Gram–Schmidt বা Householder পদ্ধতি (Part VIII-এ)। শেখার জন্য classical-ই ঠিক আছে।
৭. Worked Examples¶
Example 1 — হাতে হাতে Gram–Schmidt (\(\mathbb{R}^3\), দুটো vector)¶
\(v_1 = (1, 1, 0)\), \(v_2 = (2, 0, 1)\)।
ধাপ ১: \(\|v_1\| = \sqrt{2}\), তাই \(q_1 = \frac{1}{\sqrt2}(1,1,0)\)।
ধাপ ২: ছায়ার পরিমাণ \(q_1^Tv_2 = \frac{2+0+0}{\sqrt2} = \sqrt2\)।
ধাপ ৩: \(\|w_2\| = \sqrt3\), তাই \(q_2 = \frac{1}{\sqrt3}(1,-1,1)\)।
যাচাই: \(q_1^Tq_2 = \frac{1\cdot1 + 1\cdot(-1) + 0}{\sqrt2\sqrt3} = 0\) ✓। খাতায় (\(R\)-এ) লেখা থাকলো: \(R_{11}=\sqrt2\), \(R_{12}=\sqrt2\), \(R_{22}=\sqrt3\)।
Example 2 — পুরো QR (\(3\times3\))¶
Column 1: \(\|a_1\| = \sqrt2 \Rightarrow q_1 = \frac{1}{\sqrt2}(1,1,0)\), \(R_{11} = \sqrt2\)।
Column 2: \(R_{12} = q_1^Ta_2 = \frac{1}{\sqrt2}\)।
\(\|w_2\| = \sqrt{\tfrac32} \Rightarrow R_{22} = \sqrt{3/2}\), \(q_2 = \frac{1}{\sqrt6}(1,-1,2)\)।
Column 3: \(R_{13} = q_1^Ta_3 = \frac{1}{\sqrt2}\), \(R_{23} = q_2^Ta_3 = \frac{-1+2}{\sqrt6} = \frac{1}{\sqrt6}\)।
(হিসাবটা নিজে মিলিয়ে দেখো!) \(\|w_3\| = \frac{2}{\sqrt3} \Rightarrow q_3 = \frac{1}{\sqrt3}(-1,1,1)\), \(R_{33} = \frac{2}{\sqrt3}\)।
ফলাফল:
উপরের Code section-এর script চালালে ঠিক এই সংখ্যাগুলোই পাবে (দশমিকে)।
Example 3 — orthonormal basis-এ কষ্ট-ছাড়া coordinate¶
Example 1-এর \(q_1 = \frac{1}{\sqrt2}(1,1,0)\), \(q_2 = \frac{1}{\sqrt3}(1,-1,1)\)-এর plane-এ \(x = (3, 1, 2)\)-এর ছায়া (projection) বের করো।
Property 1 বলে — শুধু dot product:
কোনো সমীকরণ সমাধান লাগেনি! Skewed basis হলে এখানে \(2\times2\) system solve করতে হতো। এটাই orthonormal-এর আসল লাভ — আর ঠিক এই সুবিধার জন্যই Chapter 5.4-এ least squares-এ QR এত প্রিয়।
৮. Problems ও Solutions¶
Problem 1. \(\left\{\frac{1}{\sqrt2}(1,1,0),\; \frac{1}{\sqrt2}(1,-1,0),\; (0,0,1)\right\}\) — এই set-টা কি orthonormal? \(\mathbb{R}^3\)-এর basis?
Solution
Orthonormal চেক: তিনটি দৈর্ঘ্য: \(\frac{\sqrt{1+1}}{\sqrt2}=1\), \(1\), \(1\) ✓। জোড়ায় জোড়ায় dot product:
সবগুলো শর্ত মিলেছে — orthonormal।
Basis চেক: Property 2 অনুযায়ী orthogonal set আপনাআপনি linearly independent, আর \(\mathbb{R}^3\)-এ তিনটা independent vector মানেই basis (Chapter 4.3)। ✓
এই বিশেষ basis-টা আসলে standard basis-কে \(z\)-অক্ষের চারদিকে \(45°\) ঘোরানো রূপ।
Problem 2. Gram–Schmidt চালাও: \(v_1 = (3, 4)\), \(v_2 = (1, 2)\), এবং \(R\) matrix-টাও লেখো।
Solution
ধাপ ১: \(\|v_1\| = 5 \Rightarrow q_1 = (0.6, 0.8)\), \(R_{11} = 5\)।
ধাপ ২: \(R_{12} = q_1^Tv_2 = 0.6 + 1.6 = 2.2\)।
\(\|w_2\| = \sqrt{0.1024 + 0.0576} = 0.4 \Rightarrow q_2 = (-0.8, 0.6)\), \(R_{22} = 0.4\)।
যাচাই: \(QR\)-এর দ্বিতীয় column \(= 2.2\,(0.6,0.8) + 0.4\,(-0.8,0.6) = (1.32-0.32,\; 1.76+0.24) = (1,2)\) ✓
Problem 3. Gram–Schmidt-এ input-এর ক্রম বদলালে output বদলায় — \(v_1=(1,0)\), \(v_2=(1,1)\) এই ক্রমে এবং উল্টো ক্রমে চালিয়ে দেখাও।
Solution
ক্রম ১: \((1,0)\) আগে। \(q_1 = (1,0)\)। \(w_2 = (1,1) - 1\cdot(1,0) = (0,1) \Rightarrow q_2 = (0,1)\)। ফল: standard basis \(\{(1,0), (0,1)\}\)।
ক্রম ২: \((1,1)\) আগে। \(q_1 = \frac{1}{\sqrt2}(1,1)\)। ছায়া: \(q_1^Tv = \frac{1}{\sqrt2}\), তাই
ফল: \(45°\)-ঘোরানো basis \(\left\{\frac{(1,1)}{\sqrt2}, \frac{(1,-1)}{\sqrt2}\right\}\)।
দুটো উত্তরই সঠিক orthonormal basis, কিন্তু আলাদা — কারণ প্রথম vector-টা algorithm সবচেয়ে "সম্মান" করে (তাকে শুধু normalize করে, দিক বদলায় না)। Guest বইয়ের পরামর্শ: হাতে হিসাবের সময় যে vector-এ শূন্য বেশি তাকে আগে রাখো — গুণ-ভাগ কম লাগবে।
Problem 4. \(Q\) একটি \(m\times n\) matrix যার column orthonormal (\(m > n\))। দেখাও \(Q^TQ = I_n\) কিন্তু \(QQ^T \neq I_m\) (সাধারণত)। \(QQ^T\) আসলে কী করে?
Solution
\(Q^TQ\): এর \((i,j)\) entry হলো \(q_i^Tq_j\) — orthonormality-র সংজ্ঞা অনুযায়ীই এটা \(1\) (যখন \(i=j\)) বা \(0\) — অর্থাৎ \(I_n\)। ✓
\(QQ^T\): এটা \(m\times m\), কিন্তু এর Rank(র্যাঙ্ক) বড়জোর \(n < m\); আর \(I_m\)-এর rank \(m\)। তাই সমান হওয়া অসম্ভব।
\(QQ^T\) কী করে: যেকোনো \(b\)-এর জন্য
— এটা ঠিক Property 1-এর ছায়া-যোগ, কিন্তু মাত্র \(n\)টা দিকে। অর্থাৎ \(QQ^T\) হলো \(Q\)-এর column space-এর ওপর projection matrix — \(b\)-এর ছায়া ফেলে \(q\)-দের টানা subspace-এ। Chapter 5.4-এ এই matrix-টাই হবে মূল চরিত্র। (উদাহরণ: \(Q = \begin{bmatrix}1\\0\end{bmatrix}\) নিলে \(QQ^T = \begin{bmatrix}1&0\\0&0\end{bmatrix}\) — x-অক্ষে ছায়া ফেলার মেশিন, identity নয়।)
Problem 5. Gram–Schmidt চালাতে গিয়ে তৃতীয় ধাপে \(w_3 = 0\) পেলে। এর মানে কী? Algorithm-টার তখন কী করা উচিত?
Solution
\(w_3 = v_3 - (q_1^Tv_3)q_1 - (q_2^Tv_3)q_2 = 0\) মানে:
অর্থাৎ \(v_3\) পুরোপুরি \(q_1, q_2\)-এর span-এ শুয়ে আছে — যেটা \(v_1, v_2\)-এরই span। কাজেই \(v_3\) আগের দুটোর linear combination — set-টা linearly dependent ছিল (Chapter 4.2-এর ভাষায় \(v_3\) "অপ্রয়োজনীয়")।
করণীয় দুটো পথ: (১) error দাও — যদি ধরে নেওয়া থাকে input independent (আমাদের code এটাই করে); (২) \(v_3\)-কে চুপচাপ বাদ দিয়ে পরের vector-এ চলে যাও — তাহলে শেষে যে \(q\)-গুলো পাবে তারা হবে span-এর একটা orthonormal basis, আর কতগুলো \(q\) পেলে সেই সংখ্যাই হলো Rank। অর্থাৎ Gram–Schmidt একটা rank-detector-ও বটে!
Problem 6. (Legendre-এর প্রথম ধাপ) Function-দের জগতেও Gram–Schmidt চলে! \([-1,1]\) ব্যবধিতে inner product \(\langle f,g\rangle = \int_{-1}^1 f(x)g(x)\,dx\) ধরে \(\{1, x, x^2\}\)-এর প্রথম দুটোকে orthogonal করো।
Solution
ধাপ ১: \(u_1 = 1\) (প্রথমজন যেমন আছে তেমন)।
ধাপ ২: \(x\)-এর ওপর \(1\)-এর ছায়া:
ছায়াই শূন্য! তাই \(u_2 = x - 0\cdot1 = x\) — \(1\) আর \(x\) এমনিতেই orthogonal (জোড়-বিজোড় function-এর গুণফলের integral শূন্য)।
বোনাস, \(x^2\): \(\langle 1, x^2\rangle = \int_{-1}^1x^2dx = \frac23\), তাই
\(\{1,\; x,\; x^2 - \frac13\}\) — এরা (scaling বাদে) বিখ্যাত Legendre polynomial — পদার্থবিজ্ঞান আর numerical integration-এর সর্বত্র। শিক্ষা: "ছায়া বিয়োগ" ধারণাটা vector ছাড়িয়ে function পর্যন্ত পৌঁছে যায়, কারণ দরকার শুধু একটা inner product।
Problem 7. \(A = QR\) জানা থাকলে \(Ax = b\) (square, invertible \(A\)) সমাধান করা যায় \(x = R^{-1}Q^Tb\) সূত্রে। ব্যাখ্যা করো কেন এটা কাজ করে এবং কেন এটা হিসাবে সুবিধাজনক।
Solution
কেন কাজ করে:
(মাঝের ধাপে \(Q^TQ = I\)।) তারপর \(x = R^{-1}Q^Tb\)।
কেন সুবিধাজনক:
- \(Q^{-1}\) লাগে না — transpose-ই inverse (Property 4)। \(Q^Tb\) হিসাব মানে শুধু কিছু dot product।
- \(R\) upper triangular, তাই \(Rx = Q^Tb\) solve করতে Gaussian elimination লাগে না — নিচ থেকে ওপরে Back Substitution(ব্যাক সাবস্টিটিউশন — Chapter 2.2) — সস্তা, \(O(n^2)\)।
- \(Q\) দিয়ে গুণে ভুল (rounding error) বাড়ে না (Property 3: দৈর্ঘ্য অটুট) — তাই পদ্ধতিটা numerically নিরাপদ।
Chapter 5.4-এ দেখবে: least squares-ও ঠিক এই পথে solve হয়, শুধু \(A\) লম্বা (tall) হয়।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "Normalize আগে করি, পরে orthogonal করবো — ক্রম যাই হোক" | ছায়া কাটার আগে না পরে normalize করছো তাতে সূত্রের চেহারা বদলায়। নিরাপদ অভ্যাস: প্রতি ধাপে আগে ছায়া বিয়োগ, তারপর normalize। ছায়া কাটতে unnormalized \(u_i\) ব্যবহার করলে \(\frac{u_i^Tv}{u_i^Tu_i}\) — ভাগটা ভুলো না! |
| "\(q_2\) বানাতে \(v_1\)-এর ছায়া কাটলেই হবে" | ছায়া কাটতে হবে \(q_1\)-এর (বা \(u_1\)-এর), আসল \(v_1\)-এর নয় — তৃতীয় ধাপ থেকে এই পার্থক্য মারাত্মক: \(v\)-রা তো পরস্পর লম্ব নয়! |
| "Orthogonal matrix মানে entries-এ শূন্য বেশি" | নামের ফাঁদ! Orthogonal matrix মানে \(Q^TQ = I\) — column-রা orthonormal। দেখতে সে ঘনবসতিপূর্ণও হতে পারে (যেমন rotation matrix)। |
| "QR শুধু square matrix-এর জন্য" | Tall matrix (\(m > n\))-এরও QR হয় — \(Q\) হয় \(m\times n\) (column orthonormal), \(R\) হয় \(n\times n\)। least squares-এ এটাই ব্যবহার হয়। |
| "Gram–Schmidt-এ vector-দের ক্রমে কিছু যায় আসে না" | আসে! ক্রম বদলালে ভিন্ন (তবুও বৈধ) orthonormal basis পাবে — Problem 3 দেখো। প্রথম vector-এর দিক পুরোপুরি টিকে থাকে। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Orthonormal | \(q_i^Tq_j = \delta_{ij}\), অর্থাৎ \(Q^TQ = I\) | নিখুঁত গ্রাফ পেপার |
| Coordinate বের করা | \(x = \sum_i (q_i^Tx)\,q_i\) | প্রতিটা অক্ষে ছায়া মাপো |
| Gram–Schmidt ধাপ | \(w_j = v_j - \sum_{i<j}(q_i^Tv_j)q_i\), \(q_j = w_j/\|w_j\|\) | রাজমিস্ত্রি: হেলে-থাকা অংশ কাটো |
| QR | \(A = QR\), \(R_{ij} = q_i^Tv_j\) | \(R\) = ছায়াদের হিসাবের খাতা |
| Orthogonal matrix | \(Q^{-1} = Q^T\), \(\|Qx\| = \|x\|\) | শুধু ঘোরায়, টানে না |
| Projection matrix (আসছে) | \(QQ^T\) = column space-এ ছায়া | Problem 4 |
পরের chapter-এর সেতু: Gram–Schmidt-এ আমরা এক-একটা vector-এর লম্ব অংশ বের করেছি। এবার জিজ্ঞেস করবো আরো সাহসী প্রশ্ন: একটা গোটা subspace-এর সাথে লম্ব সব vector-এর দল — সেটা দেখতে কেমন? এই "লম্ব জগৎ"-এর নাম Orthogonal Complement, আর সেটা দিয়েই লেখা হয় Linear Algebra-র সবচেয়ে সুন্দর উপপাদ্য — Fundamental Theorem of Linear Algebra — চারটা subspace-এর এক মহাজাগতিক ছবি। Chapter 5.3-এ চলো।
📓 Notebook Project¶
notebooks/part-05/ch02-project.ipynb — Gram–Schmidt scratch-এ লিখে np.linalg.qr-এর সাথে মিলাবে, ধাপে ধাপে 3D visualization আঁকবে, আর correlated feature-দের decorrelate করে দেখবে \(R\) matrix কীভাবে "কে কার কপি" ফাঁস করে দে