Chapter 6.7 — PCA (পিসিএ — data-র প্রধান দিক খোঁজা)¶
Part VI-এর পুরো যাত্রাটা মনে করো: determinant থেকে eigenvalue, eigenvalue থেকে diagonalization, তারপর symmetric matrix-এর spectral theorem, positive semidefinite matrix, আর গত chapter-এ SVD। এতগুলো যন্ত্র বানালাম কেন? উত্তরটা এই chapter — Principal Component Analysis(প্রিন্সিপাল কম্পোনেন্ট অ্যানালাইসিস), সংক্ষেপে PCA। বাস্তব ডেটার হাজারটা column-এর ভেতরে লুকানো আসল গল্পটা ক'টা দিকে লেখা — সেটা খুঁজে বের করার যন্ত্র। এটা সম্ভবত পুরো linear algebra-র সবচেয়ে বেশি-ব্যবহৃত data science algorithm — আর মজার ব্যাপার, এর ভেতরে নতুন গণিত একটুও নেই। শুধু আগের ছয় chapter-এর ফসল তোলা।
🎯 এই chapter-এ যা শিখবে¶
- Data matrix \(X\) থেকে Centering(সেন্টারিং) হয়ে Covariance Matrix(কোভ্যারিয়ান্স ম্যাট্রিক্স) \(C = \frac{X^TX}{n-1}\) — এবং কেন সে symmetric ও positive semidefinite
- PCA-র মূল উপপাদ্য: \(C\)-এর eigenvector = principal direction, eigenvalue = সেই দিকের variance — variance maximization থেকে নিজ হাতে derive করা (Rayleigh quotient-এর প্রথম স্বাদ)
- SVD দিয়ে PCA: \(X = U\Sigma V^T\) হলে \(V\)-ই principal direction, \(\lambda_i = \sigma_i^2/(n-1)\) — এবং কেন বাস্তবে এই পথটাই নিরাপদ
- Explained Variance Ratio(এক্সপ্লেইন্ড ভ্যারিয়ান্স রেশিও), Scree Plot(স্ক্রি প্লট), আর ক'টা component রাখবে (\(k\) বাছাই)
- PCA বনাম least squares (লম্ব-দূরত্ব বনাম উল্লম্ব-দূরত্ব), standardization কখন লাগে, আর PCA-র সীমাবদ্ধতাগুলো
🖼️ এক ছবিতে মূল idea¶
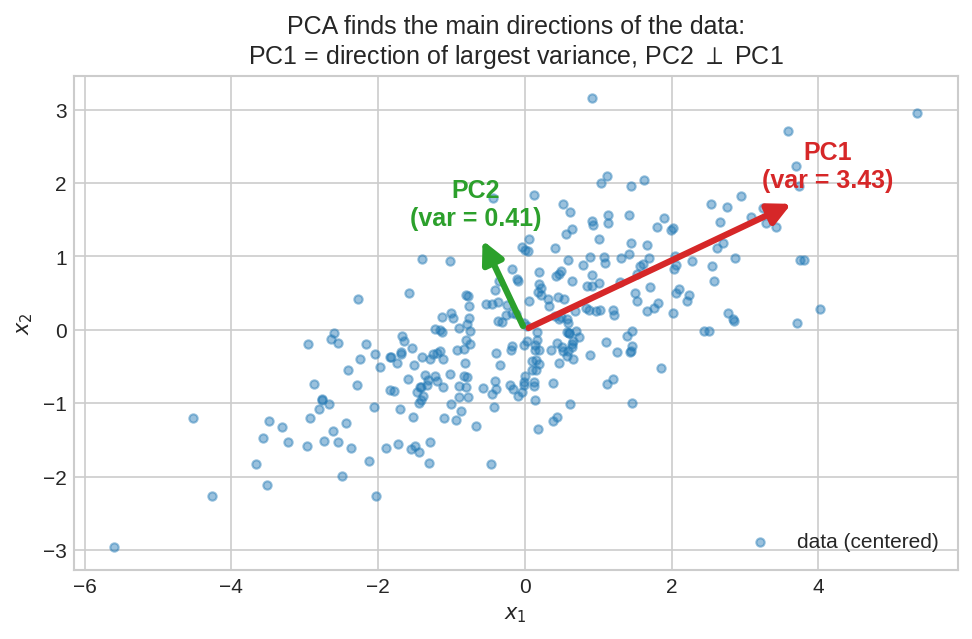
এটাই PCA-র সম্পূর্ণ গল্প: ডেটার মেঘটা কোনো একটা দিকে বেশি ছড়ানো। সেই সবচেয়ে-ছড়ানো দিকটাই PC1 (লাল তীর, variance \(\lambda_1 \approx 3.43\)), আর তার লম্ব দিকে যেটুকু বাকি ছড়ানো সেটা PC2 (সবুজ খাটো তীর, \(\lambda_2 \approx 0.41\))। তীর দুটো আসলে covariance matrix-এর eigenvector — লম্বা তীরের দৈর্ঘ্য বলে দেয় সেই দিকে গল্প কতটা।
১. কি? (What)¶
দৈনন্দিন analogy: পরীক্ষার হাজার নম্বরের পেছনে দুটো গুণ¶
ধরো এক স্কুলে ৩০০ জন ছাত্রের ৫০টা পরীক্ষার নম্বর আছে — প্রতিটা ছাত্র মানে \(50\)-dimensional একটা vector। ৫০টা সংখ্যা, অথচ শিক্ষকরা জানেন আসল গল্পটা মোটে দুটো: কেউ "গণিত-ধাঁচের" ভালো, কেউ "ভাষা-ধাঁচের"। algebra-তে ভালো করলে calculus-এও ভালো — column-গুলো একসাথে ওঠানামা করে, অর্থাৎ তারা correlated। তাহলে ৫০টা নম্বরের জায়গায় মাত্র ২টা সংখ্যা — "গণিত-স্কোর" আর "ভাষা-স্কোর" — রাখলেই প্রায় পুরো তথ্য থেকে যায়।
PCA ঠিক এই কাজটাই করে, কিন্তু নিজে থেকে: তুমি বলে দাও না কোন combination গুরুত্বপূর্ণ — ডেটার ছড়ানো (variance) দেখে সে নিজেই সবচেয়ে তথ্যবহুল দিকগুলো খুঁজে নেয়।
আরেকটা ছবি: একটা 3D মূর্তির ছবি তুলবে, কিন্তু ছবি তো 2D। কোন angle থেকে তুললে মূর্তির সবচেয়ে বেশি বৈশিষ্ট্য ধরা পড়ে? PCA হলো সেই "সেরা angle" খোঁজার গণিত — \(d\)-dimension থেকে \(k\)-dimension-এ নামার সময় যত কম সম্ভব তথ্য হারানোর angle।
সংজ্ঞা — তিন ধাপে¶
ধাপ ১ — Data Matrix(ডেটা ম্যাট্রিক্স): \(n\)টা sample, প্রতিটার \(d\)টা feature — সাজাও \(n \times d\) matrix \(X\)-এ; প্রতি row একটা sample, প্রতি column একটা feature। (সাবধান: Part V-এর least squares-এ \(A\)-ও এভাবেই সাজানো ছিল — পরিচিত বন্ধু।)
ধাপ ২ — Centering: প্রতিটা column থেকে তার গড় বিয়োগ করো:
এখন থেকে \(X\) বলতে ধরবো centered matrix — মেঘটাকে টেনে origin-এ বসানো হয়েছে। এটা optional সাজগোজ নয়, বাধ্যতামূলক — কেন, একটু পরেই ছবিতে দেখবে।
ধাপ ৩ — Covariance Matrix:
\(C_{jj}\) = feature \(j\)-এর variance (সে নিজে কতটা ছড়ানো), \(C_{jk}\) = feature \(j\) ও \(k\)-এর covariance (তারা কতটা একসাথে ওঠানামা করে)। এই matrix-টাই ডেটার "ছড়ানোর মানচিত্র"।
PCA-র সংজ্ঞা: \(C\)-এর eigendecomposition করো —
- \(V\)-এর column \(v_1, \dots, v_d\) = Principal Component(প্রিন্সিপাল কম্পোনেন্ট) বা principal direction — ডেটার প্রধান দিকগুলো, পরস্পর orthonormal।
- \(\lambda_i\) = \(v_i\) দিকে ডেটার variance — সেই দিকে গল্প কতটুকু।
- Sample \(x\)-এর score: \(z = V_k^T x\) (প্রথম \(k\)টা দিকে ছায়া) — এটাই \(d\) সংখ্যার জায়গায় নতুন \(k\)টা সংখ্যা।
লক্ষ করো এই সংজ্ঞা লেখারও অধিকার আমরা আগের chapter-গুলো থেকে অর্জন করেছি: \(C = X^TX/(n-1)\) আকারের matrix সবসময় symmetric (\(C^T = C\) — চেক করো!) — তাই Chapter 6.4-এর spectral theorem বলছে orthonormal eigenvector-এর পূর্ণ সেট আছেই; আর সে positive semidefinite — তাই Chapter 6.5 বলছে সব \(\lambda_i \geq 0\), মানে "ঋণাত্মক variance"-এর মতো অর্থহীন জিনিস কখনো আসবে না। দুই chapter-এর theory এখানে নগদ ফল দিলো।
২. দেখতে কেমন?¶
দৃশ্য ১: Centering না করলে কী সর্বনাশ হয়¶
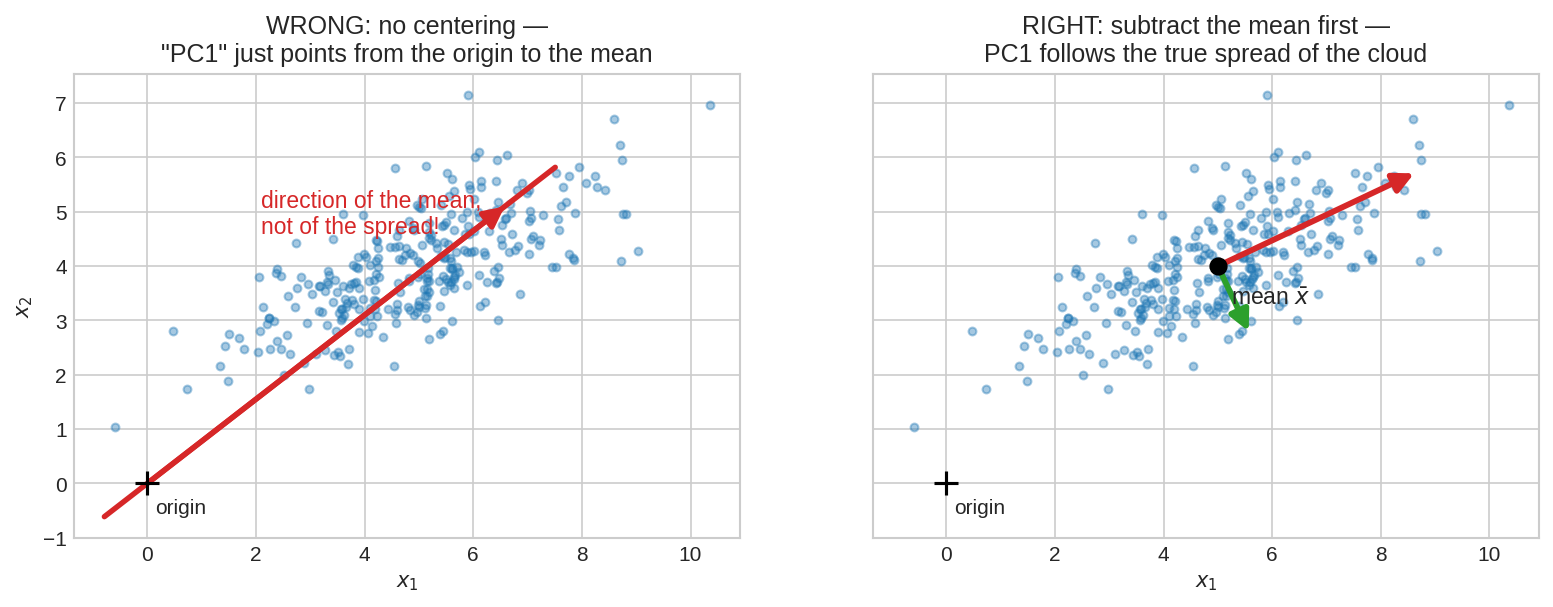
একই মেঘ, mean \((5, 4)\)-এ বসানো। বাঁয়ে: center না করে \(X^TX/(n-1)\)-এর top eigenvector নিলে "PC1" যায় origin থেকে mean-এর দিকে — কারণ uncentered second moment-এ mean-এর টানই সবচেয়ে জোরালো; ডেটা কোন দিকে ছড়ানো তার খবরই নেই। ডানে: mean বিয়োগ করার পর PC1 সত্যিকারের ছড়ানোর দিক ধরে। Centering মানে ক্যামেরাটাকে মেঘের কেন্দ্রে নিয়ে যাওয়া।
দৃশ্য ২: 2D → 1D — projection, আর least squares-এর সাথে পার্থক্য¶
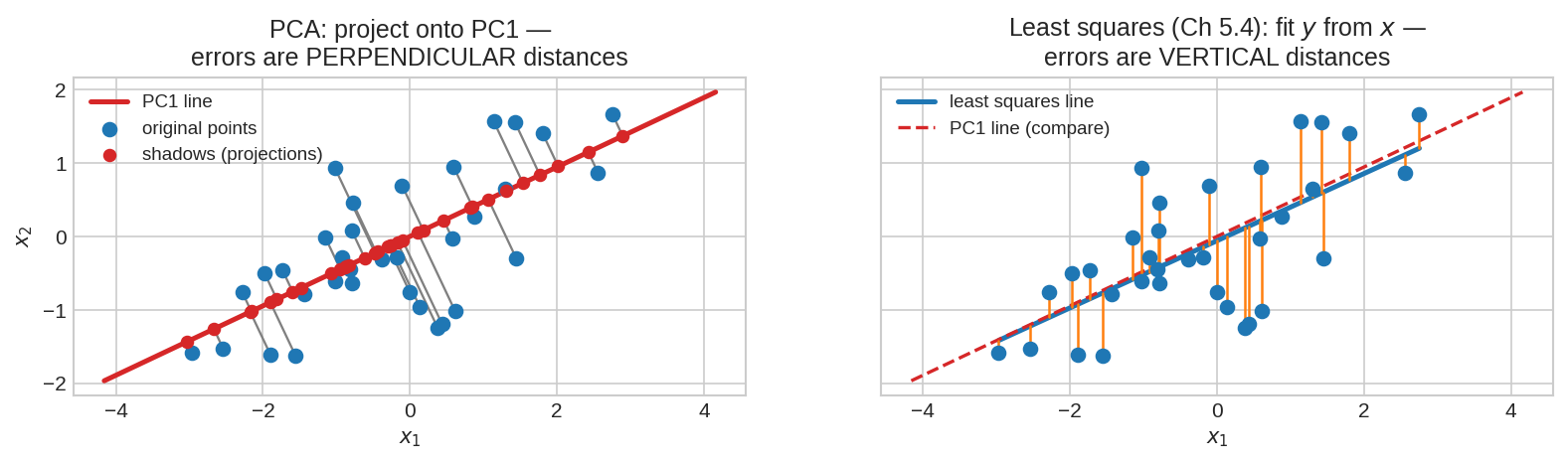
বাঁয়ে PCA: প্রতিটা নীল বিন্দুকে PC1 লাইনে নামানো হয়েছে (লাল ছায়া-বিন্দু), ভুলটুকু ধূসর লম্ব দাগ। ডানে Chapter 5.4-এর least squares: সে \(x\) থেকে \(y\) predict করে, তাই তার ভুল উল্লম্ব (খাড়া) দাগ। ছবি দুটো দেখতে ভাই-ভাই, কিন্তু দর্শন আলাদা — least squares-এ একটা variable "উত্তর" আরেকটা "প্রশ্ন"; PCA-তে কেউ বিশেষ নয়, সব দিক সমান চোখে দেখা হয়। তাই লাইন দুটোও সাধারণত এক নয়!
দৃশ্য ৩: উঁচু dimension-এ — scree plot আর 2D মানচিত্র¶
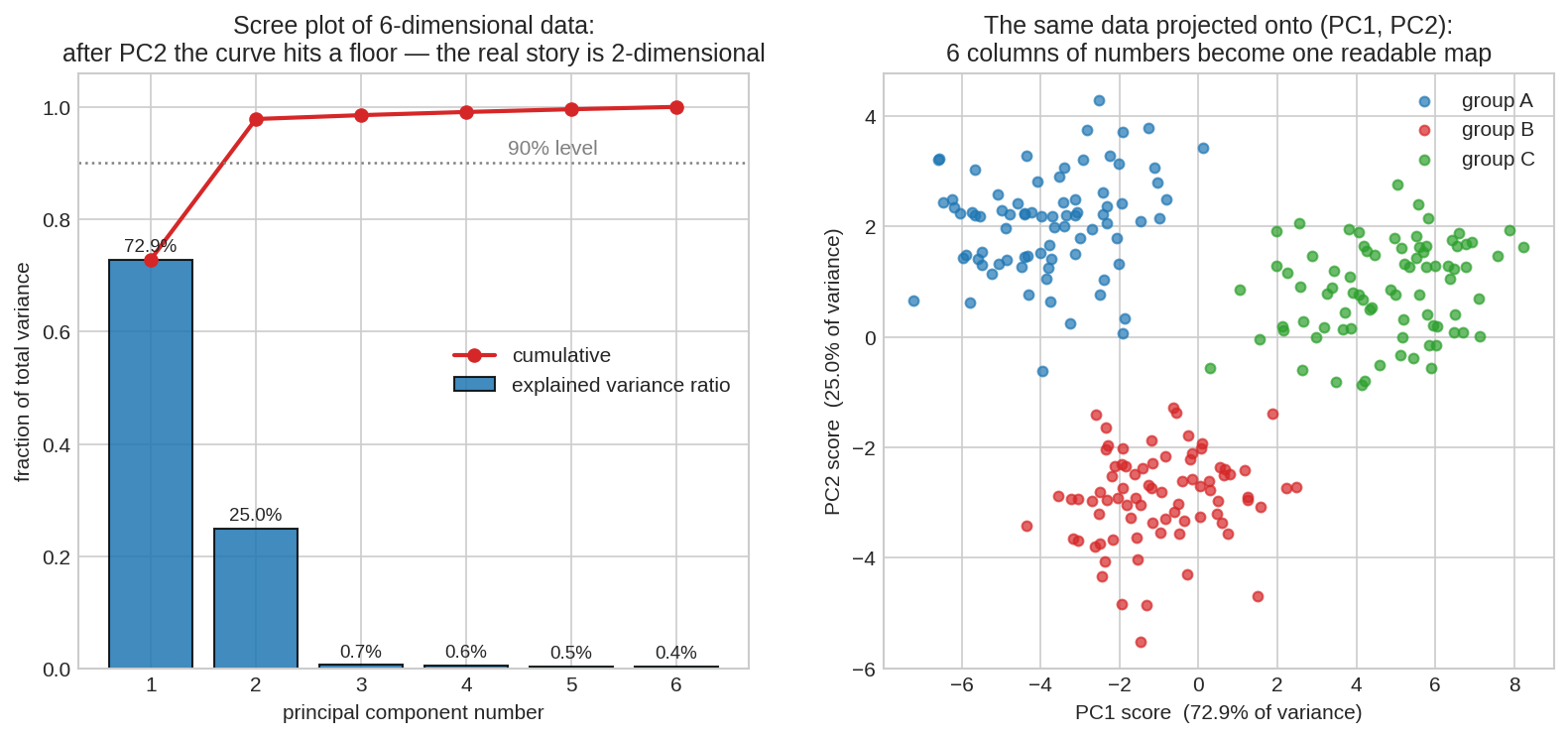
৬-dimensional synthetic ডেটা — চোখে দেখা অসম্ভব। বাঁয়ে scree plot: প্রতিটা PC কত ভাগ variance ব্যাখ্যা করে। PC1 + PC2 মিলে \(\sim 97\%\), তারপর curve মেঝেতে শুয়ে পড়ে — অর্থাৎ ৬টা column-এর আসল গল্প ২-dimensional। ডানে সেই দুই PC-তে project করা ডেটা: তিনটা দল খালি চোখে আলাদা — যে দলগুলোর কথা ৬ column-এর সংখ্যার টেবিলে তাকিয়ে কোনোদিন বুঝতে না।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- Eigenfaces — মুখ চেনার আদি যুগ: ১৯৯১ সালে Turk ও Pentland হাজারখানেক মুখের ছবি (প্রতিটা ছবি = হাজার-dimensional pixel vector) PCA-তে ফেললেন। প্রথম কয়েকটা principal direction দেখতে হলো ভুতুড়ে "গড় মুখের ছাঁচ" — কোনোটা ধরে আলোর দিক, কোনোটা চশমা, কোনোটা মুখের গড়ন। মাত্র ৫০-১০০টা "eigenface"-এর সংখ্যা দিয়েই যেকোনো মুখ প্রায় নিখুঁত বানানো যায় — face recognition-এর প্রথম কার্যকর পদ্ধতি ছিল এটাই।
- Genetics: লক্ষ লক্ষ DNA marker-এর PCA করলে PC1-PC2-এর ছবিতে মানুষের ভৌগোলিক বংশধারা ফুটে ওঠে — বিখ্যাত ফল: ইউরোপীয়দের genetic PCA-র মানচিত্র প্রায় ইউরোপের ভূগোলের মানচিত্র!
- Finance: শত শত stock-এর return-এর PCA — PC1 প্রায় সবসময় "গোটা বাজারের ওঠানামা" (market factor), PC2-PC3 sector-এর গল্প।
- Image compression ও noise কমানো: ছোট \(\lambda\)-র দিকগুলো প্রায়ই noise — সেগুলো ফেলে দিলে ছবি/সিগনাল পরিষ্কার হয় (গত chapter-এর low-rank approximation-এরই ভাই)।
Data Science / ML-এ:
- Dimensionality Reduction(ডাইমেনশনালিটি রিডাকশন): হাজার feature → গুটিকয় score; পরের model দ্রুত চলে, overfitting কমে।
- Visualization: যেকোনো উঁচু-dimensional ডেটাকে PC1-PC2 plane-এ ফেলে চোখে দেখা — cluster আছে কি না, outlier কোথায় (fig05-এর ডান ছবি)।
- Feature Decorrelation ও Whitening(হোয়াইটেনিং): PC score-রা পরস্পর uncorrelated (Property 3); প্রতিটাকে \(\sqrt{\lambda_i}\) দিয়ে ভাগ করলে সব দিকের variance \(1\) — একে বলে whitening; অনেক algorithm (যেমন কিছু neural network preprocessing, ICA) এটা আগে চায়।
- Preprocessing pipeline-এর রুটিন সদস্য:
sklearn-এPCA(n_components=k)— সম্ভবতfit_transformলেখা হয় এমন সবচেয়ে সাধারণ transformer-দের একটা।
তবে সাবধান — PCA সর্বরোগের ওষুধ নয়। তিনটা সীমাবদ্ধতা মনে রেখো: (১) PCA শুধু সরল (linear) দিক খোঁজে — ডেটা যদি বাঁকানো সুইস-রোলের মতো প্যাঁচানো হয়, সোজা তীর দিয়ে সে গল্প ধরা যায় না (তখন kernel PCA, t-SNE, UMAP)। (২) Variance ≠ গুরুত্ব — classification-এ দুই দলের পার্থক্য হয়তো এমন এক দিকে যার variance ছোট; PCA সেই দিক নির্মমভাবে ফেলে দিতে পারে। (৩) Variance বর্গ-ভিত্তিক জিনিস, তাই outlier-এর কাছে PCA অসহায় — একটা পাগলা বিন্দু PC1-কে নিজের দিকে ঘুরিয়ে নিতে পারে (least squares-এর সেই পুরনো রোগ)।
৪. Properties¶
Property 1 — \(C\) symmetric ও positive semidefinite (পুরনো theorem-এর নগদ ফল)¶
\(C^T = \left(\frac{X^TX}{n-1}\right)^T = \frac{X^TX}{n-1} = C\) — symmetric। আর যেকোনো \(v\)-এর জন্য
— positive semidefinite (Chapter 6.5-এর সেই \(A^TA\) কৌশল)। ফল: spectral theorem (Ch 6.4) দিচ্ছে orthonormal eigenvector-এর basis, PSD-তত্ত্ব (Ch 6.5) দিচ্ছে \(\lambda_i \geq 0\)। PCA-র পুরো ভিত এই এক লাইনে দাঁড়িয়ে।
Property 2 — যেকোনো দিকের variance এক গুণফলে: \(\text{var}(v) = v^TCv\)¶
Centered ডেটাকে unit vector \(v\)-তে project করো: score \(z_i = v^Tx_i\)। score-দের গড় \(0\) (centering-এর উপহার), তাই variance
অর্থ: covariance matrix জানা থাকলে আর ডেটায় হাত দিতে হয় না — যেকোনো দিকের ছড়ানো এক quadratic form-এই পাওয়া যায়। বিশেষ করে \(v = v_i\) (eigenvector) হলে \(v_i^TCv_i = v_i^T(\lambda_i v_i) = \lambda_i\) — eigenvalue মানেই সেই principal দিকের variance।
Property 3 — PC score-রা uncorrelated, আর মোট variance-এর হিসাব মেলে¶
নতুন coordinate \(Z = XV\) নিলে
অর্থাৎ PC score-দের covariance matrix diagonal — পরস্পর সম্পূর্ণ uncorrelated (feature decorrelation)। আর trace-এর পুরনো কৌশলে (Ch 6.2):
— variance কোথাও হারায় না, শুধু নতুন লম্ব দিকগুলোতে ভাগ হয়ে যায়। এ থেকেই explained variance ratio:
প্রথম \(k\)টার cumulative যোগফল \(90\%\)-\(95\%\) ছুঁলে সাধারণত সেখানে থামা হয়; আর scree plot-এ যেখানে curve "কনুই" ভেঙে মেঝেতে নামে, সেটাও \(k\) বাছার জনপ্রিয় ইশারা (fig05)।
Property 4 — SVD-ই PCA-র আসল engine¶
Centered \(X\)-এর SVD নাও (গত chapter!): \(X = U\Sigma V^T\)। তাহলে
— এটা তো হুবহু \(C\)-এর eigendecomposition-এর চেহারা! অতএব:
কেন বাস্তবে SVD-পথই নেওয়া হয়: \(X^TX\) বানালেই condition number বর্গ হয়ে যায় — Chapter 5.4-এ normal equations-এর বিরুদ্ধে ঠিক এই অভিযোগই ছিল। কাছাকাছি-সমান ছোট singular value-গুলো \(X^TX\)-এ গিয়ে rounding error-এর নিচে চাপা পড়ে; সরাসরি \(X\)-এর SVD নিলে পড়ে না। তাই sklearn-এর PCA ভেতরে ভেতরে covariance matrix বানায়ই না — SVD চালায়। আমরা শেখার সময় দুই পথই দেখবো, কাজের সময় SVD।
Property 5 — Projection, reconstruction, আর হারানো তথ্যের সঠিক হিসাব¶
প্রথম \(k\)টা direction \(V_k = [v_1|\cdots|v_k]\) নিয়ে: compression \(z = V_k^Tx\) (\(k\)টা সংখ্যা), reconstruction \(\hat{x} = V_kz = V_kV_k^Tx\) — এটা ঠিক Part V-এর orthonormal projection \(P = QQ^T\) (\(Q\)-এর জায়গায় \(V_k\))! গড় reconstruction error-টাও সুন্দর:
— যে দিকগুলো ফেলে দিলে, ঠিক তাদের variance-টুকুই হারালে, তার বেশি এক ফোঁটাও নয়। আর গত chapter-এর Eckart–Young theorem বলছে: এই choice-টাই সব \(k\)-dimensional subspace-এর মধ্যে সর্বোত্তম — এর চেয়ে কম ক্ষতিতে \(k\) মাত্রায় নামা অসম্ভব।
Standardization — কখন \(C\) নয়, correlation matrix?¶
Feature-দের একক (unit) আলাদা হলে আগে প্রতিটা column-কে তার standard deviation দিয়ে ভাগ করো (centering-এর পর) — একে বলে Standardization(স্ট্যান্ডার্ডাইজেশন); তখন \(C\) আসলে correlation matrix। কেন দরকার: উচ্চতা মিটারে লিখলে variance \(\sim 0.01\), সেন্টিমিটারে লিখলে \(\sim 100\) — শুধু একক বদলেই PC1 ঘুরে যায়! Variance-খেলায় "জোরে চিৎকার করা" feature-ই জেতে, তাই সবাইকে আগে একই ভলিউমে আনতে হয়। আর সব feature একই এককে ও তুলনীয় স্কেলে থাকলে (যেমন সব pixel intensity) raw covariance-ই ঠিক আছে।
৫. Intuition — কেন eigenvector-ই সেরা দিক?¶
সমস্যাটা সাজাই: variance maximization¶
PCA-র প্রতিশ্রুতি: PC1 হলো সবচেয়ে বেশি variance-এর দিক। Property 2 বলেছে \(v\) দিকের variance \(= v^TCv\)। তাহলে সমস্যা:
(\(\|v\|=1\) শর্তটা জরুরি — নইলে \(v\)-কে বড় করলেই "variance" যত খুশি ফোলানো যেত; আমরা দিক চাই, দৈর্ঘ্য নয়।) এই ভগ্নাংশ-চেহারার বস্তু \(\frac{v^TCv}{v^Tv}\)-কে বলে Rayleigh Quotient(রেলে কোশেন্ট) — Part VIII-এ এর সাথে আবার গভীরভাবে দেখা হবে; আজ প্রথম পরিচয়।
প্রমাণ — spectral theorem-এর কাঁধে চড়ে (মুখস্থ নয়, তিন লাইনের যুক্তি)¶
\(C\) symmetric, তাই orthonormal eigenbasis \(v_1, \dots, v_d\) আছে (\(\lambda_1 \geq \cdots \geq \lambda_d\))। যেকোনো unit vector-কে সেই basis-এ ভাঙো: \(v = c_1v_1 + \cdots + c_dv_d\), যেখানে \(c_1^2 + \cdots + c_d^2 = 1\)। তাহলে
(orthonormality-তে cross term সব মরে গেছে)। এখন \(\sum_i \lambda_ic_i^2\) হলো \(\lambda\)-দের weighted গড়, ওজন \(c_i^2\) যাদের যোগফল \(1\) — গড় কখনো সর্বোচ্চ সদস্যকে ছাড়াতে পারে না:
আর সমান হয় ঠিক তখনই যখন পুরো ওজন \(\lambda_1\)-এর ঘরে — \(v = \pm v_1\) ∎
একই যুক্তি চালিয়ে যাও: PC1-এর লম্ব জগতে (\(c_1 = 0\) রেখে) আবার maximize করো — জিতবে \(v_2\), variance \(\lambda_2\)। এভাবে একে একে সব PC। Greedy-ভাবে "সেরা, তারপর লম্বে সেরা, তারপর..." — আর প্রতিবার উত্তর রেডিমেড: eigenvector-রা লাইনে দাঁড়িয়েই ছিল।
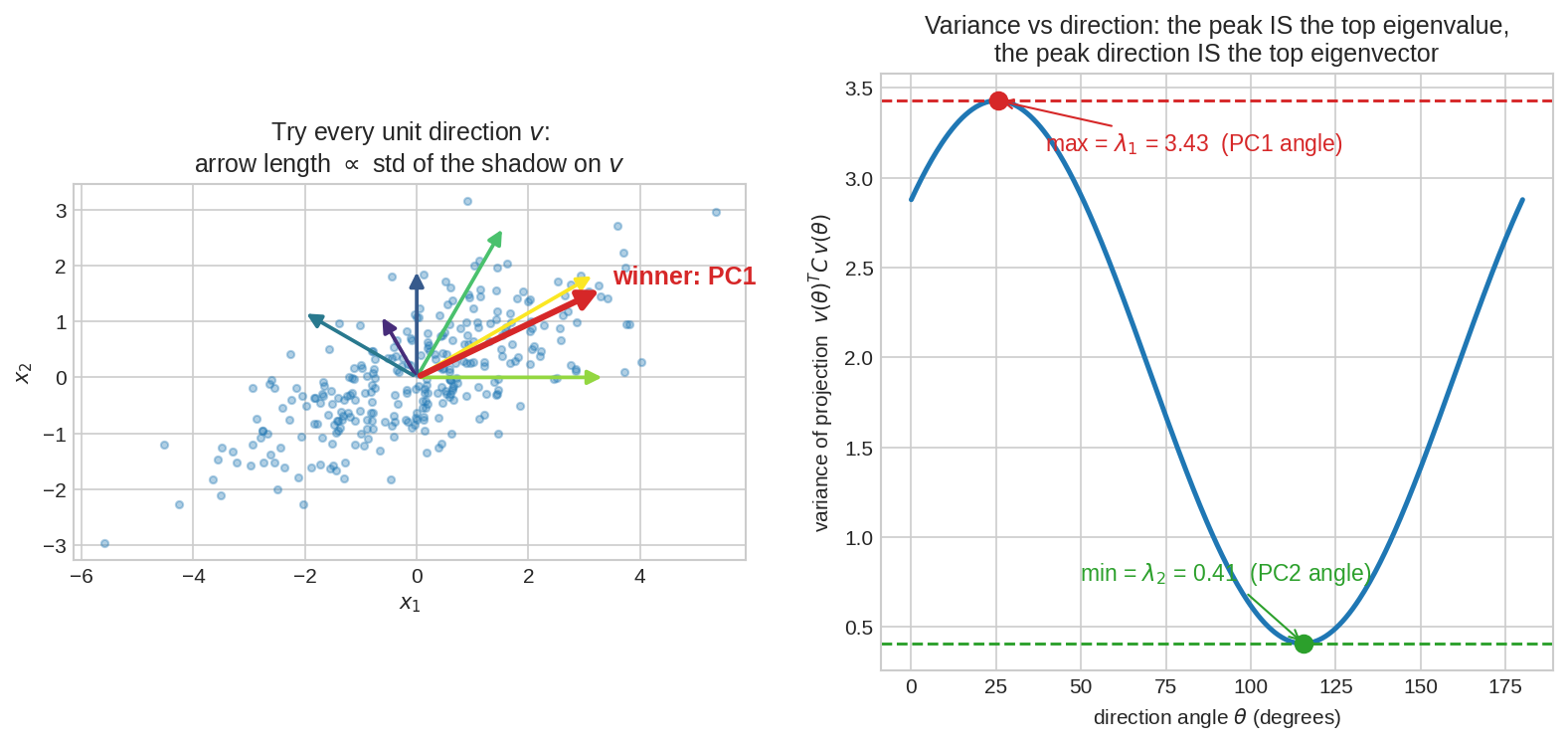
প্রমাণটা চোখে দেখো: বাঁয়ে প্রতিটা প্রার্থী দিক \(v(\theta)\)-র তীরের দৈর্ঘ্য সেই দিকের ছায়ার std; ডানে \(\theta\) ঘোরালে variance \(v(\theta)^TCv(\theta)\)-র curve — মসৃণ ঢেউ, চূড়া ঠিক \(\lambda_1 = 3.43\)-এ (PC1-এর কোণ), খাদ ঠিক \(\lambda_2 = 0.41\)-এ (PC2-এর কোণ)। Eigenvalue দুটো curve-টার ছাদ আর মেঝে।
আরেক চোখে: PCA = লম্ব-দূরত্বের least squares¶
Pythagoras বলে (centered) প্রতিটা বিন্দুর জন্য \(\|x_i\|^2 = \underbrace{(v^Tx_i)^2}_{\text{ছায়ার দৈর্ঘ্য}^2} + \underbrace{d_i^2}_{\text{লম্ব-দূরত্ব}^2}\)। বাঁ পাশ ধ্রুবক — ডেটা তো বদলাচ্ছে না। অতএব
— একই মুদ্রার দুই পিঠ! তাই PCA-কে বলা যায় "total least squares": Chapter 5.4-এর least squares খাড়া (উল্লম্ব) ভুল কমায় কারণ সেখানে \(y\) বিশেষ (সে-ই prediction-এর লক্ষ্য); PCA লম্ব ভুল কমায় কারণ তার কাছে সব অক্ষ সমান (fig03 আবার দেখো)। প্রশ্ন আলাদা, তাই লাইনও আলাদা — কোনোটা "ভুল" নয়।
৬. Code-এ কেমনে লিখে¶
import numpy as np
np.random.seed(42)
# --- synthetic correlated data: n=300 samples, d=2 features ---
L = np.linalg.cholesky(np.array([[3.0, 1.2], [1.2, 1.0]]))
X = np.random.randn(300, 2) @ L.T + np.array([5.0, 4.0]) # mean (5,4)
n = len(X)
# ধাপ ১: centering (বাধ্যতামূলক!)
mu = X.mean(axis=0)
Xc = X - mu
# --- পথ ১: covariance + eigendecomposition (শেখার পথ) ---
C = Xc.T @ Xc / (n - 1)
lam, V = np.linalg.eigh(C) # eigh: symmetric-এর জন্য, ascending order
lam, V = lam[::-1], V[:, ::-1] # বড় থেকে ছোট সাজাই
print("C =\n", C.round(3)) # [[2.877 1.167],[1.167 0.959]]
print("eigenvalues:", lam.round(4)) # [3.4284 0.4077]
# --- পথ ২: SVD (বাস্তবের পথ) ---
U, s, Vt = np.linalg.svd(Xc, full_matrices=False)
print("sigma^2/(n-1):", (s**2 / (n - 1)).round(4)) # [3.4284 0.4077] ← হুবহু মিল!
print("directions match:",
np.allclose(np.abs(Vt.T), np.abs(V))) # True (sign আলাদা হতে পারে)
# --- explained variance ratio ---
print("EVR:", (lam / lam.sum()).round(4)) # [0.8937 0.1063] → PC1-ই 89%
# --- 2D → 1D: project, then reconstruct ---
v1 = V[:, 0]
z = Xc @ v1 # scores: প্রতি sample-এ ১টা সংখ্যা
X_hat = np.outer(z, v1) + mu # reconstruction
err = np.sum((X - X_hat)**2) / (n - 1)
print("score variance:", z.var(ddof=1).round(4)) # 3.4284 = lambda_1 ✓
print("avg sq reconstruction error:", err.round(4)) # 0.4077 = lambda_2 ✓
# --- decorrelation যাচাই ---
Z = Xc @ V
print("cov of scores:\n", (Z.T @ Z / (n - 1)).round(4)) # diag(3.4284, 0.4077)
Output ব্যাখ্যা:
- দুই পথ একই উত্তর দিলো: eigenvalue \(= \sigma^2/(n-1)\), direction একই (sign পর্যন্ত — eigenvector-এর \(\pm\) দুটোই সমান বৈধ)।
- Score-এর variance ঠিক \(\lambda_1 = 3.4284\), আর PC2 ফেলে দেওয়ার মূল্য ঠিক \(\lambda_2 = 0.4077\) — Property 5-এর হিসাব কোডে অক্ষরে অক্ষরে মিললো।
- Score-দের covariance matrix diagonal — decorrelation হাতেনাতে।
np.linalg.eighলিখেছি,eigনয় — symmetric matrix-এর জন্যeighদ্রুত, নির্ভুল, আর eigenvalue real ও sorted দেয়। আর সিরিয়াস কাজে:sklearn.decomposition.PCA— ভেতরে এই SVD-পথই চলে।
৭. Worked Examples¶
Example 1 — নিখুঁত সরলরেখার ডেটা: PCA নিজেই বলে দেয় "গল্পটা 1D"¶
পাঁচটা বিন্দু: \((1,2), (3,3), (5,4), (7,5), (9,6)\)।
ধাপ ১ — Center: গড় \(\bar{x} = 5, \bar{y} = 4\)। Centered ডেটা: \(x\): \(-4,-2,0,2,4\); \(y\): \(-2,-1,0,1,2\)।
ধাপ ২ — Covariance (\(n-1 = 4\)):
ধাপ ৩ — Eigen: \(\det C = 25 - 25 = 0\) — singular! \(\lambda_1 + \lambda_2 = \text{tr} = 12.5\), \(\lambda_1\lambda_2 = 0\), তাই \(\lambda_1 = 12.5, \lambda_2 = 0\)। Eigenvector (\(\lambda_1\)): \((10 - 12.5)v_1 + 5v_2 = 0 \Rightarrow v_2 = \tfrac12 v_1\), unit করে \(v_1 = \frac{1}{\sqrt5}(2, 1)\)।
পাঠ: EVR \(= 12.5/12.5 = 100\%\) — PCA ঘোষণা করলো ডেটা হুবহু এক-মাত্রিক; দিকটা \((2,1)\) — খেয়াল করো ডেটাও ঠিক \(y = 1.5 + 0.5x\) লাইনে ছিল, ঢাল \(\tfrac12\), দিক \((2,1)\) ✓। \(\lambda = 0\) মানে সেই দিকে variance শূন্য — Ch 6.5-এর PSD-ভাষায়: \(C\) singular \(\iff\) ডেটা কোনো subspace-এ শুয়ে আছে।
Example 2 — দুই দিকেই গল্প আছে এমন ডেটা, পুরো হিসাব হাতে¶
ছয়টা centered বিন্দু: \((2,1), (-2,-1), (1,-1), (-1,1), (1,2), (-1,-2)\) (যোগফল শূন্য — আগেই centered)।
ধাপ ১ — Covariance (\(n - 1 = 5\)):
ধাপ ২ — Eigen: চেনা ছাঁচ \(\begin{bmatrix} a & b \\ b & a \end{bmatrix}\) (Ch 6.2-এর প্রিয় উদাহরণ): eigenvalue \(a \pm b = 3.6, 1.2\); eigenvector \(\frac{1}{\sqrt2}(1,1)\) ও \(\frac{1}{\sqrt2}(1,-1)\)।
ধাপ ৩ — ব্যাখ্যা: PC1 \(= \frac{1}{\sqrt2}(1,1)\), variance \(3.6\); EVR \(= 3.6/(3.6+1.2) = 75\%\)।
ধাপ ৪ — একটা বিন্দু project করি: \(x = (2,1)\)-এর score \(z = v_1^Tx = \frac{2+1}{\sqrt2} = \frac{3}{\sqrt2} \approx 2.12\); reconstruction \(\hat{x} = zv_1 = (1.5, 1.5)\); residual \(x - \hat{x} = (0.5, -0.5)\) — ঠিক \(v_2\)-এর দিকে, PC1-এর লম্বে ✓।
Example 3 — একই ডেটা, SVD-পথে (দুই রাস্তা এক ঠিকানা)¶
Example 2-এর \(X\) (৬×২)-এর SVD-তে singular value কী হবে? \(X^TX\)-এর eigenvalue: \(12 \pm 6 = 18, 6\) (উপরের হিসাবেরই \(5\)-গুণ)। তাই
আর PCA-র eigenvalue ফিরে পাই: \(\lambda_1 = \sigma_1^2/(n-1) = 18/5 = 3.6\) ✓, \(\lambda_2 = 6/5 = 1.2\) ✓। Right singular vector-ও সেই \(\frac{1}{\sqrt2}(1, \pm 1)\) — Property 4 হাতে-কলমে। খেয়াল করো SVD-পথে কোথাও \(C\) বানাতে হয়নি — বড়, প্রায়-singular ডেটায় এটাই জীবন বাঁচায়।
৮. Problems ও Solutions¶
Problem 1. কোনো centered ডেটার covariance matrix \(C = \begin{bmatrix} 5 & 2 \\ 2 & 2 \end{bmatrix}\)। হাতে eigen করে দুটো principal direction, তাদের variance, আর PC1-এর explained variance ratio বের করো।
Solution
Characteristic equation: \(\lambda^2 - (\text{tr})\lambda + \det = \lambda^2 - 7\lambda + (10 - 4) = 0\), অর্থাৎ \(\lambda^2 - 7\lambda + 6 = (\lambda - 6)(\lambda - 1) = 0\)।
\(\lambda_1 = 6\): \((5-6)v_1 + 2v_2 = 0 \Rightarrow v_1 = 2v_2 \Rightarrow v^{(1)} = \tfrac{1}{\sqrt5}(2, 1)\)। \(\lambda_2 = 1\): \((5-1)v_1 + 2v_2 = 0 \Rightarrow v_2 = -2v_1 \Rightarrow v^{(2)} = \tfrac{1}{\sqrt5}(1, -2)\)।
চেক: \(v^{(1)}\cdot v^{(2)} = \tfrac{2 - 2}{5} = 0\) ✓ (orthogonal, যেমনটা symmetric matrix-এ হতেই হবে)।
— ডেটাকে \((2,1)\) দিকের এক সংখ্যায় নামালে \(85.7\%\) ছড়ানো টিকে থাকে।
Problem 2. চারটা বিন্দু: \((9,10), (11,10), (10,9), (10,11)\)। (a) Center না করে \(M = \frac{X^TX}{n-1}\)-এর top eigenvector বের করো। (b) Center করে সত্যিকারের covariance \(C\) বের করো। দুটো উত্তর তুলনা করে বুঝিয়ে বলো centering কেন জীবন-মরণ।
Solution
(a) Centering ছাড়া: \(\sum x_i^2 = 81 + 121 + 100 + 100 = 402\); একইভাবে \(\sum y_i^2 = 402\); \(\sum x_iy_i = 90 + 110 + 90 + 110 = 400\)।
চেনা ছাঁচ: eigenvalue \(\frac{402 \pm 400}{3} = \frac{802}{3} \approx 267\) এবং \(\frac{2}{3}\); top eigenvector \(\frac{1}{\sqrt2}(1,1)\) — বিশাল eigenvalue নিয়ে "PC1" ঘোষণা করবে \((1,1)\) দিক।
(b) Centering-সহ: গড় \((10, 10)\); centered বিন্দু: \((-1,0), (1,0), (0,-1), (0,1)\)।
— দুই eigenvalue সমান (\(\tfrac23\)), মানে ডেটার আদৌ কোনো প্রিয় দিক নেই! (বিন্দু চারটা mean-এর চারপাশে নিখুঁত প্রতিসমভাবে বসানো।)
পাঠ: Uncentered \(M\)-এর \((1,1)\)-দিকটা ডেটার ছড়ানোর খবর নয় — সেটা শুধু origin থেকে mean \((10,10)\)-এর দিক; mean-এর "DC signal"-টাই সব eigenvalue খেয়ে ফেলেছে (\(267\) বনাম \(0.67\)!)। Centering সেই ভুয়া দিকটা মুছে আসল (এক্ষেত্রে: দিকহীন) গল্প বের করে। fig02-র ছবিটা এই হিসাবেরই নাটক।
Problem 3. প্রমাণ করো: centered \(X\)-এর SVD \(X = U\Sigma V^T\) হলে (a) \(V\)-এর column-রাই \(C = \frac{X^TX}{n-1}\)-এর eigenvector, eigenvalue \(\lambda_i = \frac{\sigma_i^2}{n-1}\); (b) \(U\)-এর column-রা \(XX^T\)-এর eigenvector। (অর্থাৎ এক SVD-তে দুটো eigen-সমস্যার উত্তর।)
Solution
(a) \(U\)-এর column orthonormal (\(U^TU = I\)) ব্যবহার করে:
\(\Sigma^T\Sigma\) diagonal, entry \(\sigma_i^2\)। তাহলে \(C = V\,\frac{\Sigma^T\Sigma}{n-1}\,V^T\), আর \(V\) orthogonal — এটাই spectral decomposition-এর সংজ্ঞামাফিক চেহারা: column-ধরে লিখলে
(b) একইভাবে \(XX^T = U\Sigma V^TV\Sigma^TU^T = U(\Sigma\Sigma^T)U^T\), তাই \(XX^Tu_i = \sigma_i^2u_i\) ∎
মন্তব্য: Guest বইয়ের singular value নির্মাণটা ঠিক এই পথে উল্টোদিকে হাঁটে — \(X^TX\)-এর eigenvector \(v_i\) থেকে শুরু করে \(Xv_i\)-রা \(XX^T\)-এর eigenvector আর তাদের দৈর্ঘ্য \(\sqrt{\lambda_i}\) দেখিয়ে SVD বানায়। দুই matrix-এর nonzero eigenvalue একদম এক — Part VI-এর সবচেয়ে সুন্দর প্রতিসাম্যগুলোর একটা।
Problem 4. এক ডেটাসেটের covariance-এর eigenvalue: \(\lambda = 4, 2, 1, 0.5, 0.5\)। (a) প্রতিটা PC-র explained variance ratio ও cumulative ratio বের করো। (b) অন্তত \(85\%\) variance রাখতে ক'টা component লাগবে? (c) Scree plot-টা মনে মনে এঁকে বলো "কনুই"টা কোথায়।
Solution
(a) মোট variance \(= 4 + 2 + 1 + 0.5 + 0.5 = 8\)।
| PC | \(\lambda_i\) | EVR | cumulative |
|---|---|---|---|
| 1 | 4 | \(50\%\) | \(50\%\) |
| 2 | 2 | \(25\%\) | \(75\%\) |
| 3 | 1 | \(12.5\%\) | \(87.5\%\) |
| 4 | 0.5 | \(6.25\%\) | \(93.75\%\) |
| 5 | 0.5 | \(6.25\%\) | \(100\%\) |
(b) \(k = 2\)-তে \(75\% < 85\%\); \(k = 3\)-এ \(87.5\% \geq 85\%\) — লাগবে ৩টা।
(c) \(4 \to 2 \to 1\) দ্রুত নামছে, তারপর \(0.5, 0.5\)-এ সমতল মেঝে — কনুই PC3-এর পরে; শেষ দুটো সম্ভবত noise-এর তলা (আর তারা সমান বলে তাদের ভেতরে দিক বাছাইও অনন্য নয় — যেকোনো ঘোরানো জোড়া চলে)।
Problem 5. প্রমাণ করো: \(C\)-এর দুটো ভিন্ন eigenvalue \(\lambda \neq \mu\)-এর eigenvector \(u, v\) অবশ্যই orthogonal — অর্থাৎ principal direction-রা এমনি এমনি লম্ব নয়, symmetric হওয়াটাই কারণ।
Solution
\(Cu = \lambda u\), \(Cv = \mu v\)। এখন সংখ্যা \(u^TCv\)-কে দুইভাবে পড়ি।
সরাসরি: \(u^TCv = u^T(\mu v) = \mu\,u^Tv\)।
Symmetry দিয়ে ঘুরিয়ে: \(u^TCv = (C^Tu)^Tv = (Cu)^Tv = \lambda\,u^Tv\)।
দুটো সমান, তাই \((\lambda - \mu)\,u^Tv = 0\); \(\lambda \neq \mu\) বলে \(u^Tv = 0\) ∎
কোথায় symmetry লাগলো: মাঝের ধাপে \(C^T = C\) — এইটুকুই। Symmetric না হলে (\(C^T \neq C\)) যুক্তি ভেঙে পড়ে, আর সত্যিই সাধারণ matrix-এর eigenvector লম্ব হয় না (Ch 6.3-এর উদাহরণ মনে করো)। PCA-র "orthogonal দিকে ভাগ করা যায়" প্রতিশ্রুতিটা covariance-এর symmetry-র উপহার — spectral theorem-এর ছোট্ট সংস্করণ নিজের হাতে প্রমাণ করলে।
Problem 6. Centered ডেটা \(x_1, \dots, x_n\) আর unit vector \(v\)। (a) দেখাও score \(z_i = v^Tx_i\)-দের sample variance \(= v^TCv\)। (b) \(v = c_1v_1 + \cdots + c_dv_d\) (orthonormal eigenbasis) লিখে প্রমাণ করো \(v^TCv \leq \lambda_1\), সমান কেবল \(v = \pm v_1\)-এ (যখন \(\lambda_1 > \lambda_2\))। — অর্থাৎ section ৫-এর derivation-টা নিজে পুরোটা লেখো।
Solution
(a) ডেটা centered, তাই \(\bar{z} = v^T\bar{x} = 0\)। অতএব
(মাঝে ব্যবহার করলাম \(\sum_i x_ix_i^T = X^TX\) — outer product-এ matrix গুণের সেই পুরনো ভাঙন, Part II।)
(b) \(\|v\| = 1 \Rightarrow \sum_i c_i^2 = 1\) (orthonormal basis-এ Pythagoras)। আর
তাহলে \(v^TCv - \lambda_1 = \sum_i (\lambda_i - \lambda_1)c_i^2 \leq 0\), কারণ প্রতিটা \(\lambda_i - \lambda_1 \leq 0\)। সমান হতে হলে প্রতিটা term শূন্য হতে হবে; \(\lambda_1 > \lambda_2\) হলে \(i \geq 2\)-এর সব \(c_i = 0\), অর্থাৎ \(v = c_1v_1\), \(|c_1| = 1\) ∎
ML যোগ: এই বস্তুটাই Rayleigh quotient-এর maximization — spectral clustering, Fisher-এর LDA, এমনকি PageRank-এর power method — সবার নিচে এই একই lemma ঘুমিয়ে আছে। Part VIII-এ আবার দেখা হবে।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "Centering না করলেও মোটামুটি চলে" | চলে না — uncentered "PC1" origin-থেকে-mean-এর দিক দেখায়, ডেটার ছড়ানো নয় (fig02, Problem 2-এ \(267\) বনাম \(0.67\)-এর নাটক)। আগে center, তারপর সব। |
| "Feature-এর একক যা-ই হোক, raw covariance-এ PCA চালাও" | একক ভিন্ন হলে জোরে-চিৎকার-করা (বড়-সংখ্যার) feature-ই PC1 দখল করে। আগে standardize করো — মিটার-কে সেন্টিমিটারে বদলালেই উত্তর পাল্টে যাওয়া কোনো "insight" নয়। |
| "PC1 লাইনটাই তো regression line" | না — least squares উল্লম্ব ভুল কমায় (\(y\) বিশেষ), PCA লম্ব ভুল কমায় (কেউ বিশেষ নয়); লাইন দুটো সাধারণত ভিন্ন (fig03)। প্রশ্ন আলাদা, উত্তরও আলাদা। |
| "বেশি variance মানেই বেশি দরকারি information" | Variance অন্ধ পরিমাপ — label-এর খবর সে জানে না। দুই class-এর পার্থক্য ছোট-variance দিকে থাকলে PCA সেটা ফেলে দিতে পারে; supervised কাজে ভাবনাচিন্তা করে ব্যবহার করো (বিকল্প: LDA)। |
| "PCA-র উত্তর (eigenvector-গুলো) unique" | \(\pm v_i\) দুটোই সমান বৈধ (sign flip); আর দুটো eigenvalue সমান হলে তাদের plane-এ যেকোনো ঘোরানো orthonormal জোড়া চলে — তোমার আর লাইব্রেরির sign না মিললে আতঙ্কের কিছু নেই। |
"বড় ডেটায়ও \(C = X^TX/(n-1)\) বানিয়ে eig করাই ঠিক পথ" |
\(X^TX\) বানালে condition number বর্গ হয়ে ছোট singular value-রা rounding-এ ডুবে যায় — বাস্তবের পথ centered \(X\)-এর সরাসরি SVD (Property 4); sklearn-ও তাই করে। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Data prep | center: \(X \leftarrow X - \bar{x}\) (দরকারে std দিয়ে ভাগ) | ক্যামেরা মেঘের কেন্দ্রে |
| Covariance | \(C = \frac{X^TX}{n-1}\) — symmetric PSD | ছড়ানোর মানচিত্র |
| PCA | \(C = V\Lambda V^T\): \(v_i\) = দিক, \(\lambda_i\) = সেই দিকের variance | লম্বা তীর, খাটো তীর |
| কেন eigenvector | \(\max_{\|v\|=1} v^TCv = \lambda_1\), winner \(v_1\) (Rayleigh) | কোণ-vs-variance curve-এর চূড়া |
| SVD পথ | \(X = U\Sigma V^T\): \(V\) = দিক, \(\lambda_i = \frac{\sigma_i^2}{n-1}\) | \(C\) না বানিয়েই PCA |
| \(k\) বাছাই | EVR \(= \lambda_i/\sum\lambda\), cumulative \(90\%\)+ বা scree-র কনুই | পাহাড় থেকে মেঝেতে নামা |
| Compress/rebuild | \(z = V_k^Tx\), \(\hat{x} = V_kz\); গড় ক্ষতি \(= \sum_{i>k}\lambda_i\) | ফেলে-দেওয়া দিকের variance-ই দাম |
| বনাম least squares | PCA: লম্ব দূরত্ব; LS: উল্লম্ব দূরত্ব | fig03-এর দুই ভাই |
Part VI-এর মালা গাঁথা — চোখ বন্ধ করে মনে করো: শুরু করেছিলাম determinant দিয়ে — matrix কতটা জায়গা ফোলায়-চুপসে দেয়; সে-ই দিলো characteristic polynomial। তারপর eigenvalue-eigenvector — matrix-এর নিজস্ব দিক, যেখানে সে শুধু টানে-ঠেলে, ঘোরায় না। Diagonalization সেই দিকগুলোতে matrix-কে খুলে সাজালো। Spectral theorem কথা দিলো: symmetric হলে দিকগুলো orthonormal — নিখুঁত লম্ব কঙ্কাল। PSD চেনালো সেই symmetric matrix-দের যাদের সব eigenvalue \(\geq 0\) — যারা energy, দূরত্ব, variance ধরে। SVD সব matrix-এর জন্য (এমনকি আয়তাকার!) সেই লম্ব-কঙ্কাল আবিষ্কার করলো। আর আজ PCA দেখালো এই পুরো সিঁড়িটা কোথায় ওঠে: বাস্তব ডেটার covariance ঠিক সেই symmetric PSD matrix, তার spectral decomposition-ই ডেটার প্রধান দিক, আর হিসাবটা চালানোর সেরা যন্ত্র SVD। Theory-র প্রতিটা ধাপ শেষ chapter-এ এসে একটা কাজের algorithm হয়ে গেলো — এর চেয়ে সুন্দর সমাপ্তি linear algebra-য় কমই আছে।
পরের Part-এর সেতু: যন্ত্রপাতি সব হাতে — এবার পুরোদস্তুর মাঠে নামা। Part VII-এ linear algebra দিয়ে আসল machine learning: least squares দিয়ে classification (হ্যাঁ, MNIST-এর হাতের লেখা চেনা!), \(k\)-means clustering, আর ডেটার জগতে এই সব যন্ত্রের একসাথে বাজানো — Applied Linear Algebra, VMLS-এর হাত ধরে।
📓 Notebook Project¶
notebooks/part-06/ch07-project.ipynb — Part VI-এর flagship প্রজেক্ট: সত্যিকারের dataset-এ (Iris/Wine) PCA সম্পূর্ণ scratch-এ — covariance-পথ (center → \(C\) → eigh) আর SVD-পথ দুটোই বানিয়ে sklearn.decomposition.PCA-র সাথে অঙ্কে-অঙ্কে মিলিয়ে দেখা; scree plot এঁকে \(k\) বাছাই, আর PC1-PC2 plane-এ project করে ফুলের/মদের জাত খালি চোখে চেনা — হাজার সংখ্যার টেবিল থেকে এক নজরের মানচিত্র।