Chapter 6.2 — Eigenvalues ও Eigenvectors (আইগেনভ্যালু — যে দিক বদলায় না)¶
একটা vector space-এ কোনো transformation না থাকলে সব vector সমান — কেউ কারো চেয়ে special না। কিন্তু যেই একটা matrix \(A\) এসে সবাইকে নাড়াচাড়া শুরু করলো, অমনি নাটক জমে গেলো: বেশিরভাগ vector-এর দিক ঘুরে যায়, কিন্তু গুটিকয়েক ভাগ্যবান দিক আছে যারা নিজের লাইনেই থেকে যায় — শুধু লম্বা বা খাটো হয়। এই "না-ঘোরা দিক"-গুলোই eigenvector, আর কতগুণ লম্বা/খাটো হলো সেই সংখ্যাটাই eigenvalue। Google-এর PageRank, PCA-র প্রধান দিক, সেতু কেন কেঁপে ভেঙে পড়ে, গিটারের তার কোন সুরে বাজে — সবার উত্তর লুকিয়ে আছে ছোট্ট একটা সমীকরণে: \(Av = \lambda v\)। অনেকে বলে এটাই linear algebra-র সবচেয়ে গুরুত্বপূর্ণ সমীকরণ — আজ আমরা তাকে চিনবো।
🎯 এই chapter-এ যা শিখবে¶
- \(Av = \lambda v\)-এর মানে: Eigenvector(আইগেনভেক্টর) = দিক-না-বদলানো vector, Eigenvalue(আইগেনভ্যালু) = তার scale factor
- Characteristic Polynomial(ক্যারেক্টারিস্টিক পলিনোমিয়াল) \(\det(A - \lambda I) = 0\) — আগের chapter-এর determinant এখানেই আসল কাজে লাগে
- \(2\times2\) ও \(3\times3\) matrix-এর eigenvalue-eigenvector হাতে বের করা, আর Eigenspace(আইগেনস্পেস) চেনা
- দুটো ফ্রি চেক: Trace(ট্রেস) \(= \lambda\)-দের যোগফল, \(\det = \lambda\)-দের গুণফল; আর Multiplicity(মাল্টিপ্লিসিটি) — algebraic বনাম geometric
- বিশেষ কেসের গ্যালারি (projection, reflection, rotation, shear) + Power Iteration(পাওয়ার ইটারেশন) — PageRank-এর হৃদপিণ্ড
🖼️ এক ছবিতে মূল idea¶
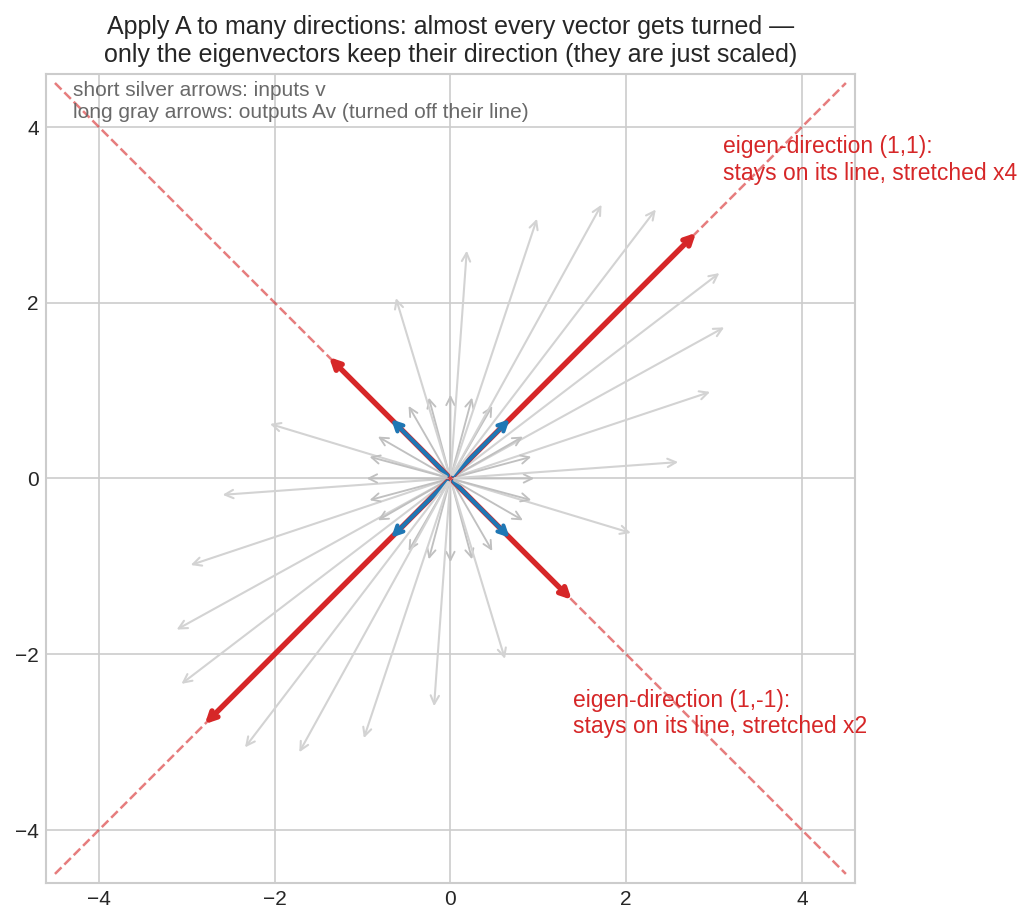
Matrix \(A = \begin{bmatrix}3&1\\1&3\end{bmatrix}\)-কে একগাদা দিকের ওপর ছেড়ে দেওয়া হয়েছে। ধূসর vector-রা সবাই নিজের লাইন থেকে ঘুরে গেছে — কিন্তু লাল দুটো দিক \((1,1)\) আর \((1,-1)\) নিজের লাইনেই আছে, শুধু যথাক্রমে ৪ গুণ আর ২ গুণ লম্বা হয়েছে। এরাই \(A\)-এর eigenvector, আর ৪ ও ২ হলো eigenvalue।
১. কি? (What)¶
দৈনন্দিন analogy: ঘুরন্ত গ্লোবের অক্ষ¶
একটা পৃথিবীর গ্লোব ঘোরাও। ঢাকার বিন্দুটা সরে যায়, নিউইয়র্ক সরে যায়, ভূমধ্যরেখার সবাই দৌড়ায় — কিন্তু উত্তর মেরু থেকে দক্ষিণ মেরু পর্যন্ত অক্ষটা এক চুলও নড়ে না। পুরো 3D ঘূর্ণনের ভেতরে ওই একটা দিক transformation-এর কাছে "অদৃশ্য"। ওই অক্ষই ঘূর্ণন-matrix-এর eigenvector (eigenvalue \(1\) — লম্বাও হয়নি, খাটোও না)।
আরেকটা: একটা রাবারের চাদর দুই কোণা ধরে টানো। চাদরের বেশিরভাগ আঁকিবুঁকি বেঁকে যায়, কিন্তু টানের দিক বরাবর দাগটা সোজাই থাকে — শুধু stretch হয়। যে দিকে টানছো সেটা eigenvector, কতগুণ টানলে সেটা eigenvalue।
সংজ্ঞা¶
\(A\) একটা \(n \times n\) (square!) matrix। যদি কোনো nonzero vector \(v\) আর scalar \(\lambda\) পাওয়া যায় যাতে
তাহলে \(v\)-কে বলে \(A\)-এর Eigenvector, আর \(\lambda\)-কে তার Eigenvalue। (জার্মান eigen = "নিজস্ব" — matrix-এর নিজস্ব দিক।)
সমীকরণটা পড়ো ছবির ভাষায়: বাঁ পাশে \(Av\) — matrix পুরো শক্তি দিয়ে \(v\)-কে transform করলো; ডান পাশে \(\lambda v\) — ফলাফল স্রেফ পুরনো \(v\)-এরই একটা স্কেল-করা সংস্করণ। অর্থাৎ এই বিশেষ \(v\)-এর ওপর গোটা matrix-টা একটা মামুলি সংখ্যার মতো আচরণ করে। \(n^2\)টা entry-র জটিল যন্ত্র নেমে এলো একটা সংখ্যায় — এইজন্যই eigenvector-রা এত দামি।
তিনটা সূক্ষ্ম কথা এখনই পরিষ্কার করি:
- \(v \neq 0\) বাধ্যতামূলক — কারণ \(A\,0 = \lambda\, 0\) সব \(\lambda\)-র জন্যই সত্য; শূন্য vector-কে ঢুকতে দিলে সংজ্ঞাটাই অর্থহীন।
- কিন্তু \(\lambda = 0\) দিব্যি হতে পারে! \(Av = 0v = 0\) মানে \(v\) null space-এ থাকে — Part IV মনে করো। "eigenvalue শূন্য" আর "eigenvector শূন্য" এক জিনিস না।
- \(v\) eigenvector হলে \(cv\)-ও eigenvector (\(c \neq 0\)): \(A(cv) = cAv = c\lambda v = \lambda(cv)\)। তাই eigenvector আসলে একটা দিক — গোটা একটা লাইন (বা আরো বড় subspace)।
Eigenspace¶
একই \(\lambda\)-র সব eigenvector, সাথে শূন্য vector — এই সেটটাকে বলে \(\lambda\)-র Eigenspace:
দ্বিতীয় সমতাটা দেখো: \(Av = \lambda v \iff Av - \lambda v = 0 \iff (A - \lambda I)v = 0\)। অর্থাৎ eigenspace মানে \(A - \lambda I\)-এর null space — আর null space যে একটা subspace, সেটা Part IV-এ প্রমাণ করাই আছে। দুই eigenvector-এর যোগফল (একই \(\lambda\) হলে) আবার eigenvector, scalar গুণেও তাই — আলাদা করে কিছু প্রমাণ করতে হলো না।
২. দেখতে কেমন?¶
দৃশ্য ১: transformation-এর আগে-পরে¶
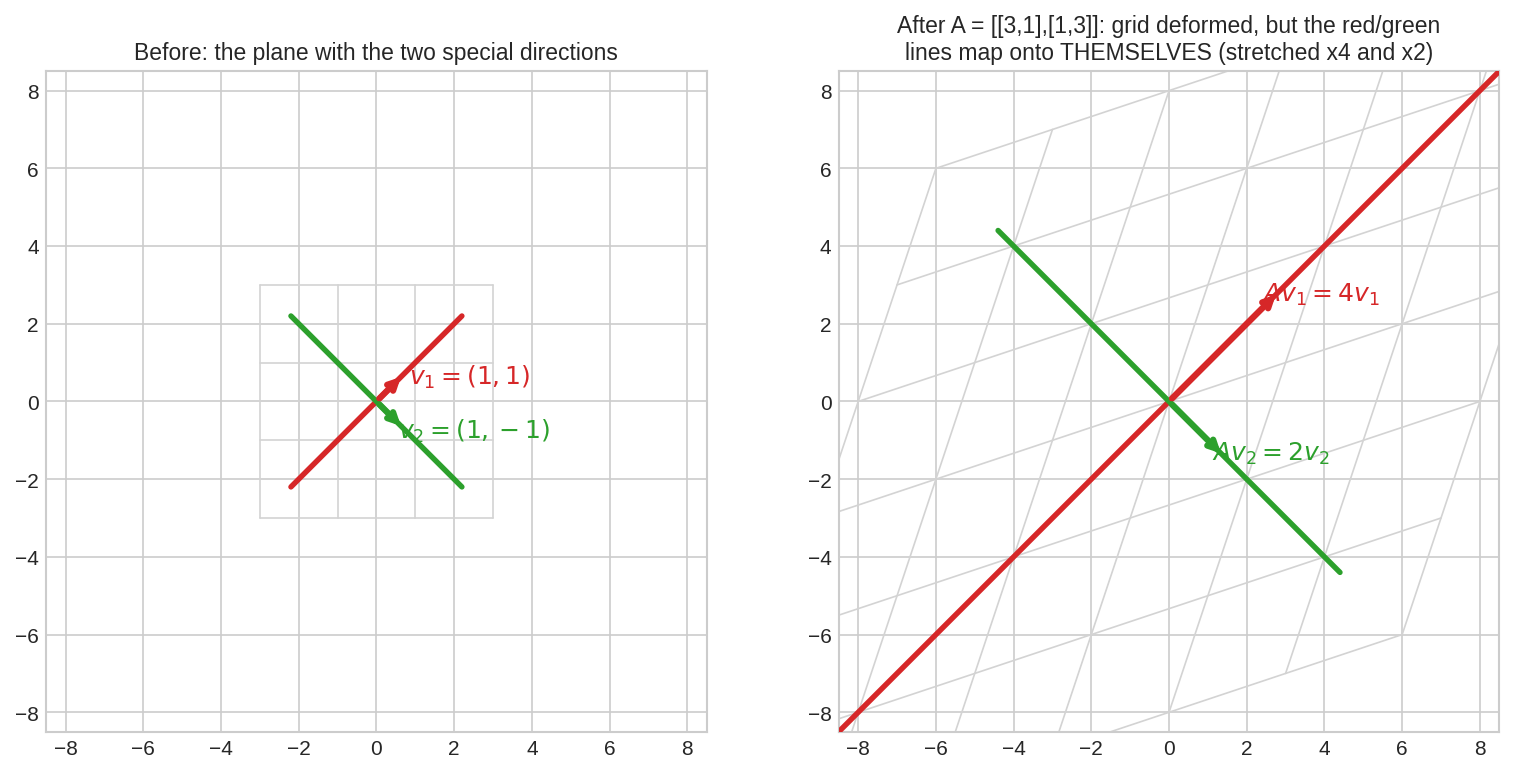
বাঁয়ে সাধারণ grid, তার ওপর দুটো বিশেষ দিক: \(v_1 = (1,1)\) (লাল) আর \(v_2 = (1,-1)\) (সবুজ)। ডানে \(A = \begin{bmatrix}3&1\\1&3\end{bmatrix}\) apply করার পর: গোটা grid বেঁকেচুরে parallelogram হয়ে গেছে, কিন্তু লাল লাইন পড়েছে লাল লাইনের ওপরেই (৪ গুণ টানা), সবুজ লাইন সবুজের ওপরেই (২ গুণ)। Part III-এর "matrix মানে জায়গার রূপান্তর" ছবিটার সাথে মেলাও — eigenvector হলো সেই রূপান্তরের কঙ্কাল।
দৃশ্য ২: eigenvalue-রা লুকিয়ে আছে একটা polynomial-এর root-এ¶
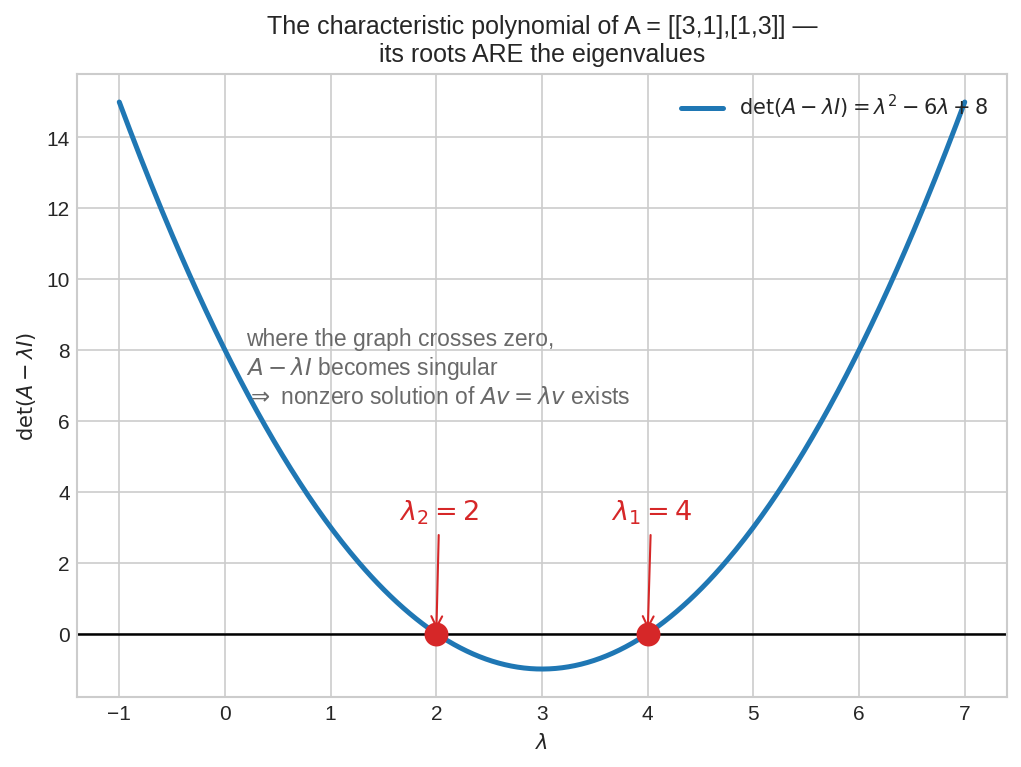
\(\lambda\)-কে চলক ধরে \(\det(A - \lambda I)\) আঁকলে পাওয়া যায় একটা polynomial-এর graph — এই matrix-এর জন্য \(\lambda^2 - 6\lambda + 8\)। Graph যেখানে শূন্য রেখা কাটে (\(\lambda = 2\) আর \(\lambda = 4\)), ঠিক সেখানে \(A - \lambda I\) singular হয়ে যায় — আর তখনই nonzero \(v\) পাওয়া সম্ভব। Root = eigenvalue।**
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- সেতু আর অনুরণন: প্রতিটা কাঠামোর কিছু "প্রিয় কম্পন-দিক" (eigenvector) আর প্রিয় কম্পাঙ্ক (eigenvalue থেকে) আছে। বাইরের ধাক্কা সেই কম্পাঙ্কে মিললে দুলুনি ফুলেফেঁপে ওঠে — ১৯৪০-এ Tacoma Narrows সেতু এভাবেই দুলে দুলে ভেঙে পড়েছিল। সৈন্যদের সেতুতে মার্চ ভেঙে হাঁটতে বলা হয় একই কারণে।
- সংগীত: টানটান তারের wave equation-কে \(Lv = \lambda v\) আকারে লেখা যায় (Guest-এর বইও এখান থেকেই শুরু করে) — তার কোন কোন আকৃতিতে কাঁপতে "পছন্দ" করে, সেগুলোই eigenvector; কোন সুরে, সেটা eigenvalue।
- কোয়ান্টাম মেকানিক্স: পরমাণুর electron-এর অনুমোদিত শক্তিস্তরগুলো আক্ষরিক অর্থে একটা operator-এর eigenvalue — "eigen" শব্দটা পদার্থবিদদের হাত ধরেই বিখ্যাত।
Data Science / ML-এ:
- Google PageRank(পেজর্যাঙ্ক): পুরো ওয়েবকে একটা দৈত্যাকার matrix বানিয়ে তার সবচেয়ে বড় eigenvalue-র eigenvector বের করা হয় — সেই vector-এর \(i\)-তম entry-ই পেজ \(i\)-এর গুরুত্ব। বিশ্বের সবচেয়ে দামি eigenvector!
- Markov Chain(মার্কভ চেইন)-এর steady state: আবহাওয়া, গ্রাহক-আচরণ, শেয়ারবাজার — "কাল কী হবে" যদি matrix গুণ হয়, তবে "অনন্তকাল পরে কী হবে" হলো \(\lambda = 1\)-এর eigenvector (Worked Example 3)।
- PCA-র teaser: ডেটার covariance matrix-এর eigenvector-গুলো হলো ডেটা যেসব দিকে সবচেয়ে ছড়িয়ে আছে সেই প্রধান দিক, আর eigenvalue = সেই দিকে variance। হাজার-মাত্রার ডেটাকে ২-৩ মাত্রায় নামানোর পুরো কারিগরি এটাই — Part VII-এ পূর্ণ গল্প।
- Graph spectra(গ্রাফ স্পেকট্রা): সোশ্যাল নেটওয়ার্কের adjacency/Laplacian matrix-এর eigenvalue-রা বলে দেয় নেটওয়ার্কে কয়টা দল (community) আছে — spectral clustering এই idea-তেই চলে।
- Differential equation-এর স্বাদ: \(\frac{du}{dt} = Au\) system-এর সমাধান \(e^{\lambda t}v\) আকারে আসে — \(\lambda > 0\) মানে বিস্ফোরণ, \(\lambda < 0\) মানে মিলিয়ে যাওয়া। Neural network-এর gradient vanish/explode করার বিশ্লেষণও এই ভাষায় হয়।
৪. Properties¶
Property 1 — Eigenvalue খোঁজার সমীকরণ: \(\det(A - \lambda I) = 0\)¶
\(\lambda\) eigenvalue হবে তখনই যখন \((A - \lambda I)v = 0\)-এর nonzero সমাধান আছে, অর্থাৎ \(A - \lambda I\) singular, অর্থাৎ (Chapter 6.1-এর প্রধান উপপাদ্য!)
\(\lambda\)-কে অজানা রেখে এই determinant খুললে পাওয়া যায় \(n\) ডিগ্রির polynomial — Characteristic Polynomial \(p(\lambda)\)। Fundamental Theorem of Algebra বলে: complex সংখ্যা পর্যন্ত গুনলে এর ঠিক \(n\)টা root (repeat-সহ) — তাই \(n\times n\) matrix-এর \(n\)টা eigenvalue (কিছু repeat হতে পারে, কিছু complex হতে পারে)।
Property 2 — দুটো ফ্রি চেক: trace ও determinant¶
\(2\times2\)-এর জন্য নিজে খুলে দেখো:
Root-দের যোগফল \(= a+d\), গুণফল \(= ad - bc\) (Vieta-র সূত্র)। এটা সব \(n\)-এর জন্যই সত্য:
প্রতিবার eigenvalue বের করে এই দুটো মিলিয়ে নাও — হাতের হিসাবের সবচেয়ে সস্তা ভুল-ধরা যন্ত্র। আর দ্বিতীয়টা থেকে একটা রত্ন: \(\det A = 0 \iff\) কোনো \(\lambda_i = 0 \iff A\) singular। Chapter 6.1-এর "det \(= 0\) মানে জায়গা চ্যাপ্টা" আর এই chapter-এর "\(\lambda = 0\) মানে কোনো দিক শূন্যে চুপসে যায়" — একই সত্যের দুই চেহারা।
Property 3 — Multiplicity: algebraic বনাম geometric¶
- Algebraic Multiplicity(অ্যালজেব্রেয়িক মাল্টিপ্লিসিটি): characteristic polynomial-এ root \(\lambda\) কতবার আসে। যেমন \(p(\lambda) = (\lambda-1)^2(\lambda-4)\) হলে \(\lambda = 1\)-এর algebraic multiplicity \(2\)।
- Geometric Multiplicity(জিওমেট্রিক মাল্টিপ্লিসিটি): \(\dim E_\lambda = \dim N(A - \lambda I)\) — ওই \(\lambda\)-র কয়টা independent eigenvector আছে।
সবসময়: \(1 \le \text{geometric} \le \text{algebraic}\)। দুটো সমান না হলে matrix-টাকে বলে Defective(ডিফেক্টিভ) — eigenvector-এর "ঘাটতি" আছে (shear-এর কেসটা Intuition-এ দেখবে)। এই পার্থক্যটাই ঠিক করে দেবে পরের chapter-এ কোন matrix diagonalize করা যাবে আর কোনটা যাবে না।
Property 4 — Eigenvalue-র পাটিগণিত: \(A^2\), \(A^k\), \(A^{-1}\)¶
\(Av = \lambda v\) হলে:
একই যুক্তি চালিয়ে: \(A^k v = \lambda^k v\) — eigenvector একই থাকে, eigenvalue-র power হয়। আর \(A\) invertible হলে \(Av = \lambda v\)-এর দুই পাশে \(A^{-1}\): \(v = \lambda A^{-1}v \Rightarrow A^{-1}v = \frac{1}{\lambda}v\)। Matrix-এর ১০০তম power জানতে চাও? Eigenvalue-দের ১০০তম power-ই যথেষ্ট — পরের chapter-এর diagonalization এই পর্যবেক্ষণটারই শিল্পরূপ।
Property 5 — Triangular matrix পড়া যায় খালি চোখে¶
\(A\) triangular (উপরের বা নিচের) হলে \(A - \lambda I\)-ও triangular, আর Chapter 6.1 থেকে জানো triangular-এর det = diagonal-এর গুণফল:
Eigenvalue-রা diagonal-এ বসে আছে! কিন্তু সাবধান — eigenvector-গুলো standard basis নাও হতে পারে (Problem 2)।
Property 6 — আলাদা eigenvalue ⟹ independent eigenvector¶
\(\lambda_1, \dots, \lambda_k\) সব আলাদা হলে তাদের eigenvector \(v_1, \dots, v_k\) অবশ্যই linearly independent। (প্রমাণ Intuition-এ — ছোট্ট আর সুন্দর।) ফল: \(n\times n\) matrix-এর \(n\)টা আলাদা eigenvalue থাকলে \(n\)টা independent eigenvector গ্যারান্টিড — গোটা space-এর একটা "eigen-basis" পাওয়া যায়। Repeat হলে গ্যারান্টি নেই — তখনই defective হওয়ার ঝুঁকি।
৫. Intuition — কেন সত্য?¶
কেন determinant-ই চাবি?¶
লক্ষ করো সমস্যাটা প্রথম দেখায় অসম্ভব লাগে: \(Av = \lambda v\)-তে দুটো জিনিসই অজানা — \(\lambda\) আর \(v\), আর তারা গুণ হয়ে জড়িয়ে আছে (nonlinear!)। কৌশল: জোড়া ভেঙে ফেলা।
\((A - \lambda I)v = 0\) লেখো। এবার ভাবো — একটা matrix কখন কোনো nonzero vector-কে শূন্যে পাঠায়? যখন সে জায়গাকে চ্যাপ্টা করে — কোনো একটা দিক পুরো গিলে ফেলে। আর Chapter 6.1-এ আমরা শিখেছি "চ্যাপ্টা করা"-র নিখুঁত detector: determinant শূন্য। তাই আগে \(v\)-কে ভুলে গিয়ে শুধু জিজ্ঞেস করো: কোন কোন \(\lambda\)-র জন্য \(A - \lambda I\) চ্যাপ্টা হয়? — এটা \(\lambda\)-র এক-চলকের polynomial সমীকরণ, high school-এর চেনা মাঠ। \(\lambda\) পেয়ে গেলে \(v\) বের করা তো স্রেফ null space-এর হিসাব (Part IV)। Nonlinear ধাঁধা ভেঙে গেলো দুটো linear ধাপে — মাঝের সেতুটা determinant। আগের chapter-এ det শিখে থাকা এই মুহূর্তটার জন্যই।
বিশেষ কেসের গ্যালারি — চেনা transformation-দের eigen-পরিচয়¶
জ্যামিতি জানলে অনেক সময় polynomial না খুলেই উত্তর বলা যায়:
| Transformation | Eigenvector (দিক) | Eigenvalue | কেন |
|---|---|---|---|
| Projection (লাইনের ওপর ছায়া) | লাইনের দিক | \(1\) | ছায়ার ছায়া সে নিজেই |
| লাইনের লম্ব দিক | \(0\) | লম্ব জিনিসের ছায়া শূন্য — \(\lambda=0\) বাস্তবেই ঘটে! | |
| Reflection (আয়না) | আয়নার দিক | \(1\) | আয়নার গায়ের জিনিস নড়ে না |
| আয়নার লম্ব দিক | \(-1\) | উল্টে যায় — ঋণাত্মক eigenvalue মানে দিক reverse | |
| Rotation (\(0 < \theta < \pi\)) | কোনো real দিক নেই | complex | সবাই ঘোরে — নিচে দেখো |
| Shear \(\begin{bmatrix}1&1\\0&1\end{bmatrix}\) | শুধু \(x\)-অক্ষ | \(1\) (double) | দ্বিতীয় eigenvector নেই — defective! |
Shear-টা ভালো করে দেখো: \(p(\lambda) = (1-\lambda)^2\), তাই \(\lambda = 1\) algebraic multiplicity \(2\)। কিন্তু \(A - I = \begin{bmatrix}0&1\\0&0\end{bmatrix}\)-এর null space শুধু \(x\)-অক্ষ — geometric multiplicity \(1\)। তাসের ডেক ভাবো: টেবিলে শোয়া ডেকের ওপরের কার্ডগুলো পাশে ঠেলে দাও — একদম নিচের কার্ডের (মেঝের) দিকটাই কেবল অবিচল থাকে। ২টা eigenvalue-এর জায়গায় eigenvector-দিক মোটে ১টা — এই ঘাটতিই "defective"।
Rotation: যখন eigenvalue পালিয়ে যায় complex জগতে¶
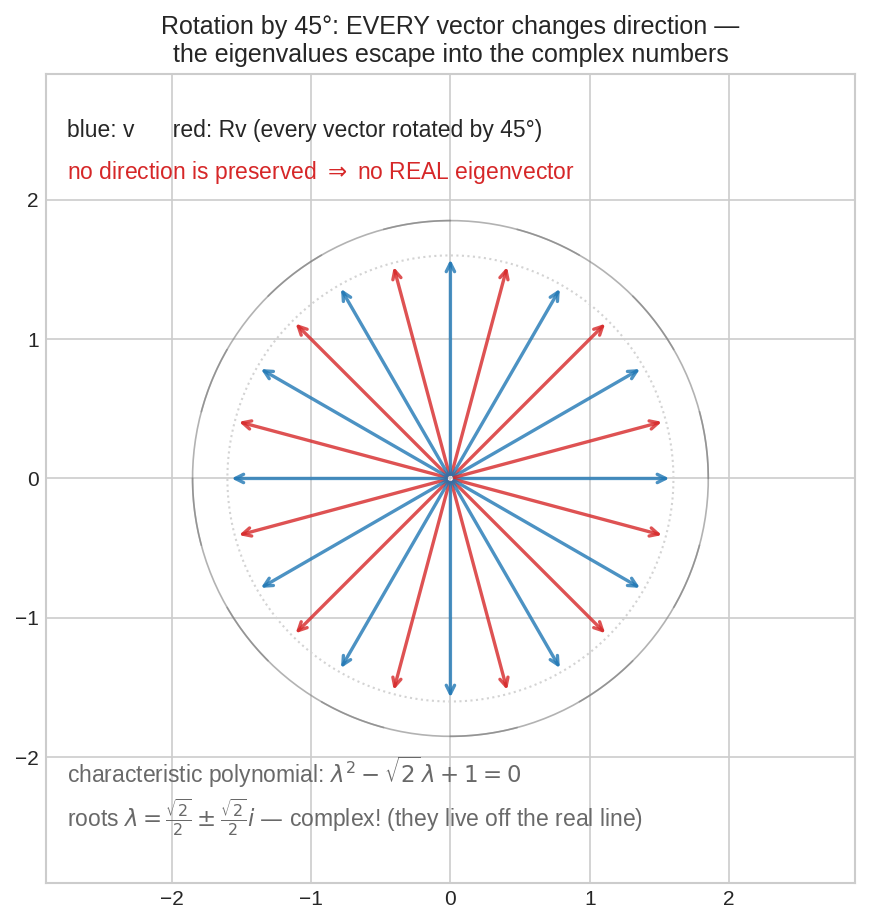
\(45°\) ঘূর্ণনে প্রতিটা নীল vector লাল অবস্থানে ঘুরে গেছে — একটা দিকও নিজের লাইনে নেই, তাই real eigenvector শূন্যটা। কিন্তু polynomial তো root চাইবেই — সে root খুঁজে নেয় complex সংখ্যায়।
\(R = \begin{bmatrix}\cos\theta & -\sin\theta\\ \sin\theta & \cos\theta\end{bmatrix}\)-এর characteristic polynomial: \(\lambda^2 - 2\cos\theta\,\lambda + 1 = 0\), root
ভয় পেয়ো না — শুধু দুটো জিনিস নিয়ে যাও: (১) real matrix-এর complex eigenvalue সবসময় conjugate জোড়ায় আসে (\(a+bi\) থাকলে \(a-bi\)-ও থাকবে); (২) \(|\lambda| = 1\) — মানে কিছু লম্বা-খাটো হয় না, শুধুই ঘোরে। সাধারণভাবে complex eigenvalue = transformation-এর ভেতরে কোথাও একটা ঘূর্ণন লুকিয়ে আছে; \(|\lambda| > 1\) হলে ঘুরতে ঘুরতে বাইরে ছিটকে যাওয়া spiral, \(|\lambda| < 1\) হলে ভেতরে গুটিয়ে আসা spiral। আপাতত এটুকুই — গভীর ডুব পরে।
আলাদা eigenvalue ⟹ independent — দুই লাইনের প্রমাণ¶
ধরো \(\lambda_1 \neq \lambda_2\), eigenvector \(v_1, v_2\), আর কেউ দাবি করলো \(c_1 v_1 + c_2 v_2 = 0\)। দুই পাশে \(A\) চালাও: \(c_1\lambda_1 v_1 + c_2\lambda_2 v_2 = 0\)। এবার প্রথম সমীকরণকে \(\lambda_2\) দিয়ে গুণ করে বিয়োগ দাও:
\(\lambda_1 \neq \lambda_2\) আর \(v_1 \neq 0\), অতএব \(c_1 = 0\); তখন \(c_2 v_2 = 0 \Rightarrow c_2 = 0\) ∎। (বেশি vector-এর জন্য একই যুক্তি ধাপে ধাপে চলে।) অর্থটা জ্যামিতিক: দুই ভিন্ন স্কেল-ফ্যাক্টরের দিক কখনো এক লাইনে শুতে পারে না — এক লাইনে শুলে স্কেলও এক হতো।
Power iteration: সবচেয়ে বড় \(\lambda\) সব দখল করে নেয়¶
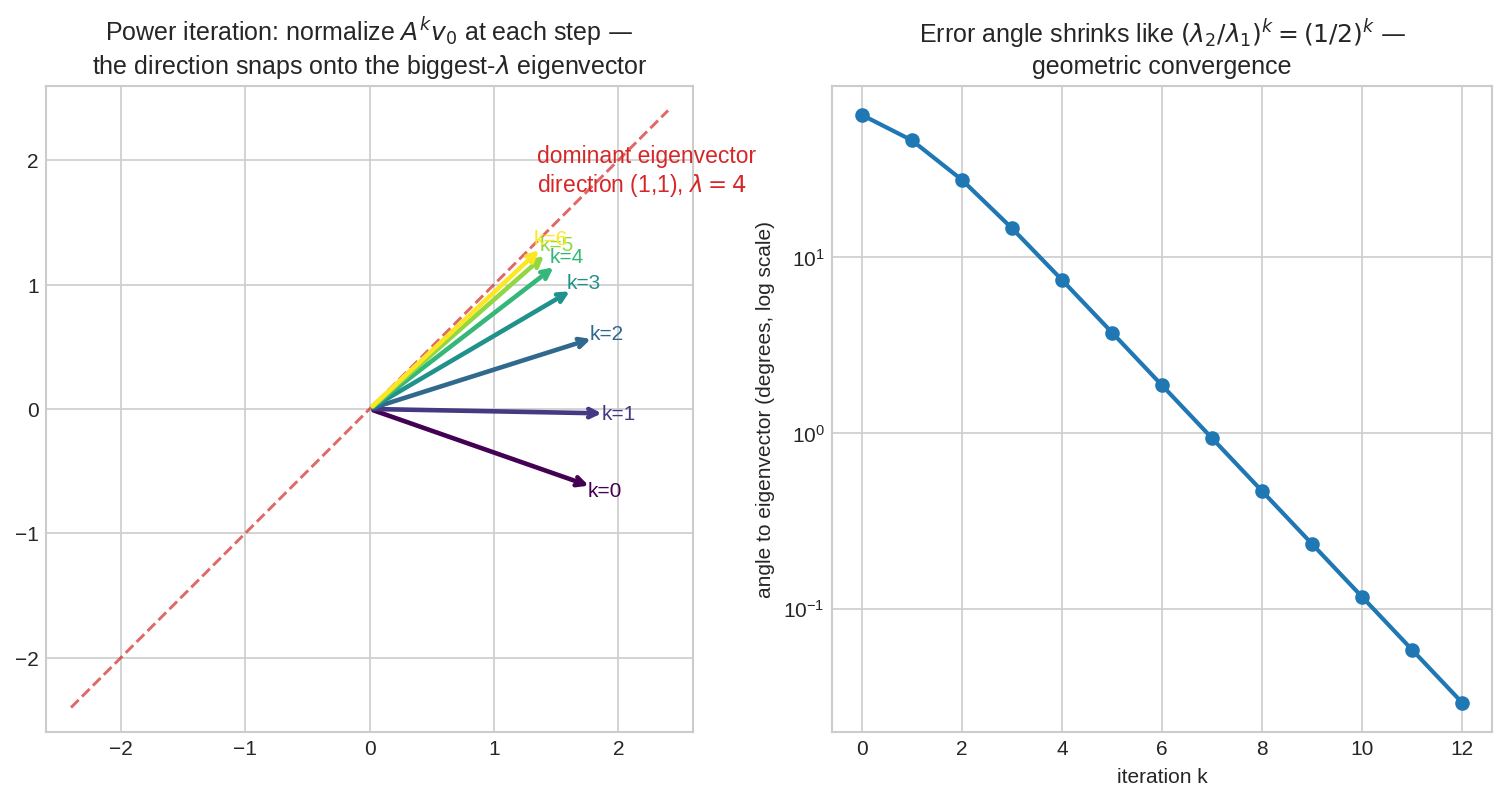
যেকোনো \(v_0\) থেকে শুরু করে বারবার \(A\) গুণ করো (প্রতি ধাপে normalize): দিকটা ধীরে ধীরে ঘুরে গিয়ে সবচেয়ে বড় eigenvalue-র eigenvector-এ আটকে যায়। ডানে: ভুল-কোণ প্রতি ধাপে \(\lambda_2/\lambda_1 = 1/2\) গুণ হারে কমে — সরলরেখা (log scale-এ) মানে geometric গতিতে convergence।
কেন কাজ করে? \(v_0\)-কে eigen-basis-এ ভাঙো: \(v_0 = c_1 v_1 + c_2 v_2\) (ধরো \(|\lambda_1| > |\lambda_2|\))। Property 4 প্রয়োগ করলে:
\(k\) বাড়তেই দ্বিতীয় term মিলিয়ে যায় — টিকে থাকে শুধু \(v_1\)-এর দিক। Google এই সরল লুপটাই চালায় শত-কোটি পাতার matrix-এর ওপর: শুরুতে সব পেজ সমান গুরুত্ব, তারপর "গুরুত্ব প্রবাহিত করো, normalize করো, repeat" — কয়েক ডজন iteration-এই ranking-vector স্থির হয়ে যায়।
৬. Code-এ কেমনে লিখে¶
import numpy as np
np.random.seed(42)
A = np.array([[3., 1.],
[1., 3.]])
# --- এক লাইনে সব: eigenvalues ও eigenvectors ---
lams, V = np.linalg.eig(A)
print("eigenvalues :", lams) # [4. 2.]
print("eigenvectors (columns!):\n", V)
# V-এর প্রতিটা COLUMN একেকটা eigenvector, unit length-এ normalize করা
# --- যাচাই: Av == λv প্রতিটা জোড়ার জন্য ---
for lam, v in zip(lams, V.T): # .T কারণ column চাই
print(np.allclose(A @ v, lam * v)) # True, True
# --- ফ্রি চেক: trace ও det ---
print("trace =", np.trace(A), "= sum λ =", lams.sum()) # 6.0 = 6.0
print("det =", np.linalg.det(A), "= prod λ =", lams.prod()) # 8.0 = 8.0
# --- Power iteration: PageRank-এর খেলনা সংস্করণ ---
v = np.array([1.0, -0.35]) # যেকোনো শুরুর vector
for k in range(15):
v = A @ v
v = v / np.linalg.norm(v) # normalize, নাহলে সংখ্যা বিস্ফোরিত হবে
print("power iteration direction:", v) # ≈ [0.7071, 0.7071] = (1,1)/√2
print("eigenvalue estimate:", v @ A @ v) # Rayleigh quotient ≈ 4.0
# --- Rotation matrix: complex eigenvalue দেখো নিজের চোখে ---
th = np.pi / 4
R = np.array([[np.cos(th), -np.sin(th)],
[np.sin(th), np.cos(th)]])
print("rotation eigenvalues:", np.linalg.eig(R)[0])
# [0.7071+0.7071j 0.7071-0.7071j] ← conjugate জোড়া, |λ| = 1
Output ব্যাখ্যা:
np.linalg.eigএকসাথে সব eigenvalue আর eigenvector দেয় — কিন্তু মনে রেখো eigenvector-রাV-এর column, row নয় (নতুনদের এক নম্বর কোডিং-ভুল)।- Trace (\(6 = 4+2\)) আর det (\(8 = 4\times2\)) দুটো চেক-ই মিললো — হাতের হিসাবেও সবসময় এটা করো।
- Power iteration মাত্র ১৫ ধাপে \((1,1)/\sqrt2\)-তে পৌঁছে গেছে; Rayleigh quotient \(v^TAv\) (unit \(v\)-এর জন্য) দিলো eigenvalue-র চমৎকার estimate।
- Rotation-এর \(\lambda\) complex এলো (
j= Python-এর \(i\)) — NumPy কোনো অভিযোগ ছাড়াই complex-এ চলে যায়, আর \(|\lambda| = \sqrt{0.7071^2 + 0.7071^2} = 1\) ✓।
৭. Worked Examples¶
Example 1 — \(2\times2\) পুরো হিসাব হাতে¶
\(A = \begin{bmatrix}1 & 2\\ 5 & 4\end{bmatrix}\)-এর eigenvalue ও eigenvector বের করি।
ধাপ ১ — Characteristic polynomial:
ধাপ ২ — Root: \(\lambda^2 - 5\lambda - 6 = (\lambda - 6)(\lambda + 1) = 0 \Rightarrow \lambda_1 = 6, \lambda_2 = -1\)।
চেক: যোগফল \(6 + (-1) = 5 = \operatorname{tr}(A)\) ✓, গুণফল \(-6 = \det(A) = 4 - 10\) ✓
ধাপ ৩ — প্রতিটা \(\lambda\)-র জন্য null space:
\(\lambda = 6\): \((A - 6I)v = \begin{bmatrix}-5 & 2\\ 5 & -2\end{bmatrix}v = 0\)। দুই সারিই বলে \(5x = 2y\) — এক সারি অন্যটার গুণিতক হওয়াটা ভালো লক্ষণ (singular বানাতেই তো \(\lambda\) বেছেছি!)। \(v_1 = (2, 5)\)।
\(\lambda = -1\): \((A + I)v = \begin{bmatrix}2 & 2\\ 5 & 5\end{bmatrix}v = 0 \Rightarrow x = -y\), \(v_2 = (1, -1)\)।
শেষ চেক: \(Av_1 = (2 + 10,\; 10 + 20) = (12, 30) = 6(2,5)\) ✓
Example 2 — \(3\times3\), repeated eigenvalue আর eigen-plane¶
\(B = \begin{bmatrix}2 & 1 & 1\\ 1 & 2 & 1\\ 1 & 1 & 2\end{bmatrix}\) (Guest-এর Example 128-এর আদলে, নিজের সংখ্যায়)।
ধাপ ১ — প্রথম সারি ধরে cofactor expansion (Chapter 6.1-এর কায়দা):
\((2-\lambda)^2 - 1 = (\lambda-1)(\lambda-3)\) বসিয়ে গুছালে:
ধাপ ২ — Root: \(\lambda = 1\) (algebraic multiplicity \(2\)), \(\lambda = 4\)। চেক: \(1 + 1 + 4 = 6 = \operatorname{tr}(B)\) ✓, \(1 \cdot 1 \cdot 4 = 4 = \det(B)\) ✓
ধাপ ৩ —
\(\lambda = 4\): \(B - 4I = \begin{bmatrix}-2&1&1\\ 1&-2&1\\ 1&1&-2\end{bmatrix}\) — elimination করলে solution \(x = y = z\), অর্থাৎ \(v = (1,1,1)\)। Eigenspace = একটা লাইন।
\(\lambda = 1\): \(B - I = \begin{bmatrix}1&1&1\\ 1&1&1\\ 1&1&1\end{bmatrix}\) — তিন সারিই এক! শর্ত একটাই: \(x + y + z = 0\) — এটা একটা plane, dimension \(2\)। Basis: \((1,-1,0)\) আর \((1,0,-1)\)। Geometric multiplicity \(2 =\) algebraic multiplicity \(2\) — এই matrix defective না; \(3\)টা independent eigenvector মিলে গোটা \(\mathbb{R}^3\)-এর basis।
ছবিটা দেখো: \(B\) পুরো space-কে এমনভাবে টানে যে \((1,1,1)\) লাইনটা ৪ গুণ stretch হয়, আর তার লম্ব plane-টা যেখানে ছিলো সেখানেই থাকে (\(\lambda = 1\))।
Example 3 — Markov chain-এর steady state: \(\lambda = 1\)-এর জাদু¶
একটা শহরে প্রতি বছর: গ্রামের \(10\%\) মানুষ শহরে যায়, শহরের \(20\%\) গ্রামে ফেরে। Transition matrix (column = এ বছরের অবস্থা):
Eigenvalue: \(\det(P - \lambda I) = \lambda^2 - 1.7\lambda + 0.7 = (\lambda - 1)(\lambda - 0.7)\)। \(\lambda_1 = 1\), \(\lambda_2 = 0.7\)।
(Markov matrix-এর \(\lambda = 1\) সবসময় থাকে — column-যোগফল \(1\) মানে \(\mathbf{1}^T P = \mathbf{1}^T\), তাই \(P^T\)-এর eigenvalue \(1\), আর \(P\) ও \(P^T\)-এর characteristic polynomial একই।)
\(\lambda = 1\)-এর eigenvector: \((P - I)v = \begin{bmatrix}-0.1 & 0.2\\ 0.1 & -0.2\end{bmatrix}v = 0 \Rightarrow x = 2y\)। জনসংখ্যার ভগ্নাংশ হিসেবে normalize: \(v = (2/3,\; 1/3)\)।
অর্থ: যেভাবেই শুরু করো, বছর গড়ালে বিন্যাস \((2/3, 1/3)\)-এ স্থির হবে — কারণ power iteration-এর যুক্তিতে \(0.7^k \to 0\), টিকে থাকে শুধু \(\lambda = 1\)-এর অংশ। PageRank ঠিক এই হিসাবই — শহর-গ্রামের বদলে কোটি ওয়েবপেজ, আর steady state vector-টাই পেজের ranking।
৮. Problems ও Solutions¶
Problem 1. \(A = \begin{bmatrix}4 & 1\\ 2 & 3\end{bmatrix}\)-এর সব eigenvalue ও eigenvector বের করো। Trace আর determinant দিয়ে উত্তর যাচাই করো।
Solution
Characteristic polynomial:
তাই \(\lambda_1 = 5\), \(\lambda_2 = 2\)।
\(\lambda = 5\): \((A - 5I) = \begin{bmatrix}-1 & 1\\ 2 & -2\end{bmatrix} \Rightarrow x = y \Rightarrow v_1 = (1, 1)\)
\(\lambda = 2\): \((A - 2I) = \begin{bmatrix}2 & 1\\ 2 & 1\end{bmatrix} \Rightarrow y = -2x \Rightarrow v_2 = (1, -2)\)
চেক: \(5 + 2 = 7 = \operatorname{tr}(A)\) ✓; \(5 \times 2 = 10 = 12 - 2 = \det(A)\) ✓; আর \(Av_1 = (5,5) = 5v_1\) ✓
Problem 2. \(B = \begin{bmatrix}3 & 1 & 0\\ 0 & 3 & 2\\ 0 & 0 & 5\end{bmatrix}\)-এর eigenvalue বলো কোনো determinant না খুলেই। তারপর প্রতিটা eigenvalue-র geometric multiplicity বের করে বলো matrix-টা defective কি না।
Solution
\(B\) upper triangular — Property 5 বলে eigenvalue-রা diagonal-এই: \(\lambda = 3\) (algebraic multiplicity \(2\)) আর \(\lambda = 5\)।
\(\lambda = 3\): \(B - 3I = \begin{bmatrix}0 & 1 & 0\\ 0 & 0 & 2\\ 0 & 0 & 2\end{bmatrix}\) — সমীকরণ: \(y = 0\), \(z = 0\); \(x\) free। Null space \(= \{(t, 0, 0)\}\), dimension \(1\)। Geometric multiplicity \(1 <\) algebraic multiplicity \(2\)।
\(\lambda = 5\): \(B - 5I = \begin{bmatrix}-2 & 1 & 0\\ 0 & -2 & 2\\ 0 & 0 & 0\end{bmatrix}\): \(-2y + 2z = 0 \Rightarrow y = z\); \(-2x + y = 0 \Rightarrow x = y/2\)। \(v = (1, 2, 2)\), geometric multiplicity \(1 =\) algebraic ✓
মোট independent eigenvector \(1 + 1 = 2 < 3\) — matrix-টা defective। শিক্ষা: triangular হলে eigenvalue ফ্রি-তে পাও, কিন্তু eigenvector-এর জন্য খাটতে হয়ই — আর repeat-করা eigenvalue-তে ঘাটতি পড়তে পারে।
Problem 3. Shear matrix \(S = \begin{bmatrix}1 & 1\\ 0 & 1\end{bmatrix}\)-এর eigenvalue ও eigenvector বের করো। এর কি দুটো linearly independent eigenvector আছে? জ্যামিতিক ভাষায় ব্যাখ্যা করো কেন। (Guest Review Problem 2-এর আদলে)
Solution
\(\det(S - \lambda I) = (1-\lambda)^2 = 0 \Rightarrow \lambda = 1\), algebraic multiplicity \(2\)।
\(S - I = \begin{bmatrix}0 & 1\\ 0 & 0\end{bmatrix}\) — সমীকরণ শুধু \(y = 0\)। Eigenspace \(= x\)-অক্ষ, dimension \(1\)।
না — eigenvector-দিক মাত্র একটাই। Geometric multiplicity \(1 <\) algebraic \(2\) — defective।
জ্যামিতি: shear মানে তাসের ডেক পাশে ঠেলা — মেঝেতে শোয়া কার্ডের দিক (\(x\)-অক্ষ) ছাড়া প্রতিটা দিক সামনের দিকে হেলে পড়ে। ঘোরানো "থামার" দ্বিতীয় কোনো লাইন নেই। পরের chapter-এ দেখবে: ঠিক এই কারণেই shear-কে diagonalize করা যায় না।
Problem 4. \(Av = \lambda v\) হলে প্রমাণ করো: (a) \(v\) হলো \(A^2\)-এরও eigenvector — eigenvalue কত? (b) সব \(n \in \mathbb{N}\)-এর জন্য \(A^n v = \lambda^n v\)। (c) \(A\) invertible হলে \(v\) হলো \(A^{-1}\)-এর eigenvector, eigenvalue \(1/\lambda\)। (Guest Review Problem 5-এর আদলে)
Solution
(a) \(A^2 v = A(Av) = A(\lambda v) = \lambda (Av) = \lambda^2 v\) — eigenvalue \(\lambda^2\), eigenvector সেই \(v\)-ই ✓
(b) Induction: \(n=1\) সত্য। \(A^n v = \lambda^n v\) ধরে নিলে
(c) \(A\) invertible হলে আগে দেখো \(\lambda \neq 0\): \(\lambda = 0\) হলে \(Av = 0\), অথচ \(v \neq 0\) — মানে \(A\) singular, contradiction। এবার \(Av = \lambda v\)-এর দুই পাশে \(A^{-1}\):
মূল্য: matrix-এর power/inverse নেওয়া eigen-জগতে স্রেফ সংখ্যার power/inverse — এই একটা প্রবলেমই power iteration আর পরের chapter-এর \(A^{100}\)-হিসাবের ভিত্তি।
Problem 5. \(P\) একটা projection matrix, অর্থাৎ \(P^2 = P\) (Chapter 5.4 মনে করো)। প্রমাণ করো \(P\)-এর eigenvalue কেবল \(0\) বা \(1\) হতে পারে, এবং প্রতিটা কোন eigenvector-দিকে ঘটে তা জ্যামিতিকভাবে ব্যাখ্যা করো। (Guest Review Problem 6-এর আদলে)
Solution
ধরো \(Pv = \lambda v\), \(v \neq 0\)। দুই পাশে আবার \(P\):
কিন্তু \(P^2 = P\), তাই \(P^2 v = Pv = \lambda v\)। দুটো মিলিয়ে:
জ্যামিতি: \(\lambda = 1\)-এর eigenspace = যে subspace-এর ওপর ছায়া ফেলা হচ্ছে (\(C(P)\)) — সেখানকার বাসিন্দাদের ছায়া তারা নিজেরাই। \(\lambda = 0\)-এর eigenspace = তার লম্ব দিক (\(N(P)\)) — লম্ব জিনিসের ছায়া শূন্য। লক্ষ করো "\(\lambda = 0\)" এখানে কোনো ব্যর্থতা নয় — projection-এর কর্মপদ্ধতিরই অংশ।
Problem 6. Rotation matrix \(R = \begin{bmatrix}\cos\theta & -\sin\theta\\ \sin\theta & \cos\theta\end{bmatrix}\)। (a) দেখাও এর eigenvalue \(\lambda = \cos\theta \pm i\sin\theta\)। (b) \(\theta\)-র কোন কোন মানে eigenvalue real? সেই কেসগুলোর জ্যামিতিক মানে কী? (c) দেখাও \(|\lambda| = 1\) — এর মানে কী? (Guest Review Problem 3-এর আদলে)
Solution
(a) \(\det(R - \lambda I) = (\cos\theta - \lambda)^2 + \sin^2\theta = \lambda^2 - 2\cos\theta\,\lambda + 1\) Quadratic formula:
(b) Real হবে যখন \(\sin\theta = 0\): \(\theta = 0\) (\(\lambda = 1, 1\) — identity, সব দিকই eigenvector!) আর \(\theta = \pi\) (\(\lambda = -1, -1\) — আধপাক ঘোরা মানে প্রতিটা vector উল্টে যায়, তাই প্রতিটা দিকই eigenvector, eigenvalue \(-1\))। মাঝের যেকোনো \(\theta\)-তে সব দিক ঘোরে — কোনো real eigenvector নেই।
(c) \(|\lambda| = \sqrt{\cos^2\theta + \sin^2\theta} = 1\) ✓। মানে: rotation কিছুই stretch করে না — শুধু ঘোরায়। Complex eigenvalue-র modulus বহন করে "কত গুণ বড়/ছোট" খবরটা, আর argument বহন করে "কত কোণ ঘোরা"।
Problem 7. (Discrete dynamical system — Guest Review Problem 9-এর আদলে) \(M = \begin{bmatrix}2 & 1\\ 1 & 2\end{bmatrix}\) আর নিয়ম \(v(t+1) = Mv(t)\)। (a) \(M\)-এর eigenvalue-eigenvector বের করো। (b) কোন কোন \(v(0)\)-র জন্য \(v(0) = v(1) = v(2) = \cdots\) (fixed point)? (c) কোন কোন \(v(0)\)-র জন্য সব \(v(t)\) একই দিকে থাকে? (d) একটা সাধারণ \(v(0) = (1, 0)\) নিলে অনেক দিন পরে \(v(t)\)-এর দিক কোনদিকে যাবে — এবং কেন?
Solution
(a) \(\det(M - \lambda I) = (2-\lambda)^2 - 1 = (\lambda - 3)(\lambda - 1)\)। \(\lambda_1 = 3\), \(v_1 = (1,1)\) (কারণ \(M - 3I\) দেয় \(x = y\)); \(\lambda_2 = 1\), \(v_2 = (1,-1)\) (কারণ \(M - I\) দেয় \(x = -y\))। চেক: \(3+1 = 4 = \operatorname{tr}\) ✓, \(3 \cdot 1 = 3 = \det\) ✓
(b) Fixed point মানে \(Mv = v\) — অর্থাৎ \(\lambda = 1\)-এর eigenvector! উত্তর: \((1,-1)\)-এর লাইনের সব vector (শূন্যসহ)।
(c) "দিক অপরিবর্তিত" মানেই eigenvector: দুটো লাইন — \((1,1)\)-এর লাইন (প্রতি ধাপে ৩ গুণ হয়ে দৌড়ায়) আর \((1,-1)\)-এর লাইন (দাঁড়িয়ে থাকে)।
(d) \(v(0) = (1,0) = \frac12(1,1) + \frac12(1,-1)\)। তাহলে
\(3^t\) বিস্ফোরিত হয়, দ্বিতীয় term বসে থাকে — কয়েক ধাপেই দিকটা কার্যত \((1,1)\)। এটাই power iteration-এর গল্প (fig05): সবচেয়ে বড় \(|\lambda|\)-ই দীর্ঘমেয়াদে সব দখল করে। Markov chain, PageRank, population model — সব একই নাটকের ভিন্ন মঞ্চায়ন।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "\(\lambda = 0\) হতে পারে না / eigenvector \(0\) হতে পারে" | দুটো আলাদা কথা! Eigenvector কখনোই \(0\) না (সংজ্ঞা), কিন্তু eigenvalue দিব্যি \(0\) হয় — তখন eigenvector-রা থাকে \(N(A)\)-তে (projection-এর \(\lambda = 0\) মনে করো)। |
| "প্রতিটা \(n\times n\) matrix-এর \(n\)টা independent eigenvector আছে" | না — shear \(\begin{bmatrix}1&1\\0&1\end{bmatrix}\)-এর \(\lambda = 1\) দুবার, কিন্তু eigenvector-দিক একটাই (defective)। Distinct eigenvalue হলে গ্যারান্টি, repeat হলে চেক করতে হয়। |
| "Real matrix-এর eigenvalue সবসময় real" | Rotation matrix-এর \(\lambda = \cos\theta \pm i\sin\theta\) — দিব্যি complex। Real matrix-এ complex \(\lambda\) conjugate জোড়ায় আসে। (Symmetric matrix-এর \(\lambda\) অবশ্য সবসময় real — সেই সুখবর সামনের chapter-গুলোয়।) |
| "Eigenvector বের করার আগে \(A\)-কে row reduce করে নিই" | সর্বনাশ! Row operation determinant-এর মতো eigenvalue-ও বদলে দেয় — RREF-এর eigenvalue আর \(A\)-এর eigenvalue সম্পূর্ণ ভিন্ন জিনিস। Row reduce করবে \((A - \lambda I)\)-কে, \(\lambda\) বসানোর পরে। |
| "\((A - \lambda I)v = 0\) solve করতে গিয়ে \(v = 0\) পেলাম — উত্তর \(v = 0\)" | \(v = 0\) সবসময়ই solution — ওটা উত্তর না! তুমি খুঁজছো nonzero solution। যদি nonzero solution না-ই থাকে, তার মানে তোমার \(\lambda\)-টা eigenvalue-ই না — polynomial-এর root-এ হিসাব-ভুল হয়েছে। (\(A - \lambda I\)-এর সারিগুলো পরস্পরের গুণিতক হয়ে যাওয়াটাই সুস্থতার লক্ষণ।) |
| "\(A\) আর \(2A\)-এর eigenvector আলাদা" | Eigenvector একই থাকে, eigenvalue দ্বিগুণ হয়: \((2A)v = 2(Av) = 2\lambda v\)। Scale বদলালে দিক বদলায় না — সংজ্ঞাটা ভাবলেই পরিষ্কার। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| মূল সমীকরণ | \(Av = \lambda v\), \(v \neq 0\) | যে দিক ঘোরে না, শুধু scale হয় |
| Eigenvalue খোঁজা | \(\det(A - \lambda I) = 0\) | চ্যাপ্টা-detector (Ch 6.1) দিয়ে \(\lambda\) ধরা |
| Eigenvector খোঁজা | \(N(A - \lambda I)\) solve | \(\lambda\) বসাও → null space (Part IV) |
| Eigenspace | \(E_\lambda = N(A-\lambda I)\), একটা subspace | লাইন বা plane — একার নয়, গোটা পরিবার |
| ফ্রি চেক | \(\sum \lambda_i = \operatorname{tr} A\), \(\prod \lambda_i = \det A\) | প্রতিবার মেলাও! |
| Multiplicity | \(1 \le\) geometric \(\le\) algebraic; কম পড়লে defective | shear: \(\lambda\) দুটো, দিক একটা |
| বিশেষ কেস | projection: \(0,1\); reflection: \(\pm1\); rotation: \(e^{\pm i\theta}\); triangular: diagonal | জ্যামিতি আগে, polynomial পরে |
| Powers | \(A^k v = \lambda^k v\), \(A^{-1}v = \lambda^{-1}v\) | power iteration → বড় \(\lambda\)-র জয় |
| DS/ML | PageRank, Markov steady state (\(\lambda=1\)), PCA-র প্রধান দিক, graph spectra | সবচেয়ে দামি eigenvector-রা |
পরের chapter-এর সেতু: Example 2-তে দেখলে — \(3\)টা independent eigenvector পেলে গোটা space-এর একটা eigen-basis হাতে আসে, আর সেই basis-এ matrix-টা হয়ে যায় নিছক একটা diagonal সংখ্যার তালিকা। জটিল \(A\)-কে ভেঙে \(A = PDP^{-1}\) লেখা, \(A^{100}\) এক নিঃশ্বাসে হিসাব করা, Fibonacci-র closed formula বের করা — আর কোন matrix-এর বেলায় এই জাদু চলে না (shear-রা, সাবধান!) — সব আসছে Chapter 6.3: Diagonalization-এ।
📓 Notebook Project¶
notebooks/part-06/ch02-project.ipynb — characteristic polynomial scratch-এ বানিয়ে \(2\times2\)/\(3\times3\) matrix-এর eigenvalue বের করা (np.roots দিয়ে root, তারপর null space থেকে eigenvector); power iteration নিজ হাতে implement করে NumPy-র eig-এর সাথে মেলানো; আর একটা "কোন vector ঘোরে না" visualizer — যেকোনো \(2\times2\) matrix দিলে সব দিকের ঘূর্ণন এঁকে eigenvector-দিক খুঁজে দেখায়।