Chapter 2.3 — Elementary Matrices ও LU Decomposition (এলিমেন্টারি ম্যাট্রিক্স ও LU বিশ্লেষণ)¶
🎯 এই chapter-এ যা শিখবে¶
- Elementary Matrix(এলিমেন্টারি ম্যাট্রিক্স) — প্রতিটা row operation আসলে একটা matrix দিয়ে বাঁদিক থেকে গুণ
- Elementary matrix-দের inverse(ইনভার্স) — প্রতিটা চালের "undo বোতাম"ও একটা elementary matrix
- LU Decomposition(এল-ইউ বিশ্লেষণ): \(A = LU\) — elimination-এর পুরো খাতা দুটো Triangular Matrix(ত্রিভুজাকার ম্যাট্রিক্স)-এ গুছিয়ে রাখা
- \(L\)-এর ভেতরে multiplier(গুণক)-রা কীভাবে বিনা খরচে জমা হয় — এই chapter-এর সবচেয়ে সুন্দর জাদু
- LU দিয়ে \(A\mathbf{x}=\mathbf{b}\) solve: forward substitution + back substitution, আর কেন বাস্তবের solver-রা এটাই করে
🖼️ এক ছবিতে মূল idea¶
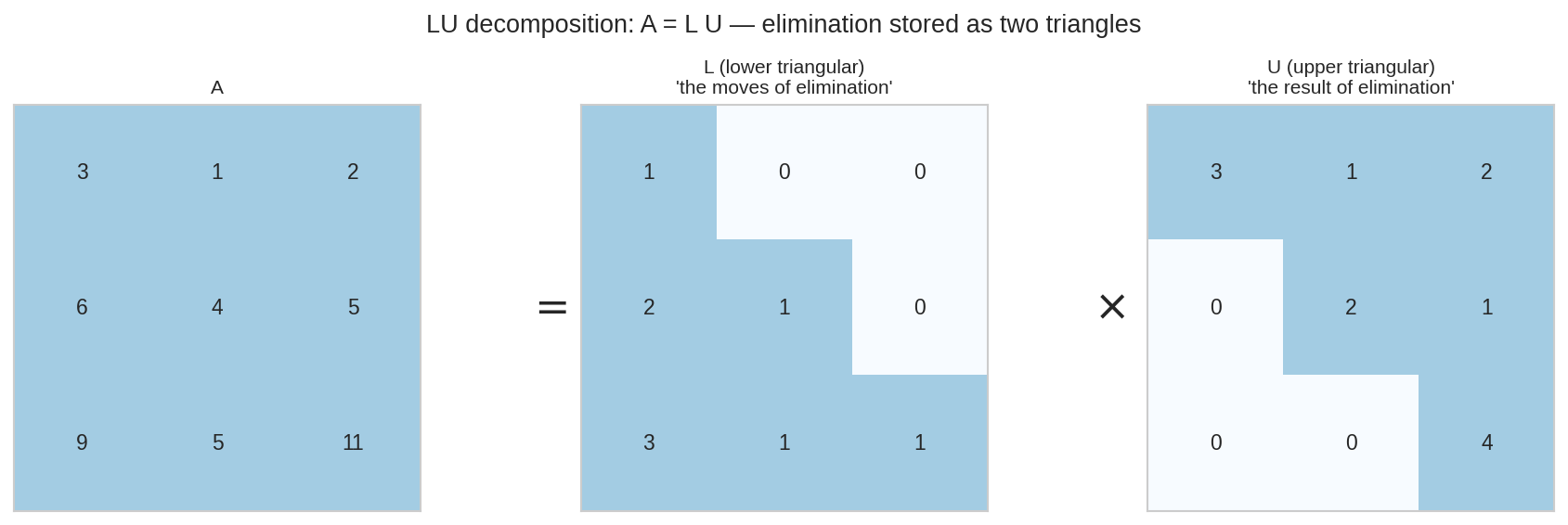
একটা সাধারণ matrix \(A\) ভেঙে যায় দুই ত্রিভুজে: \(L\) (lower triangular — elimination-এ কী কী চাল দিয়েছিলে তার খাতা) আর \(U\) (upper triangular — elimination শেষে যা পেয়েছিলে)। \(A = LU\): চাল + ফলাফল = আসল matrix।
১. কি? (What)¶
চালের খাতা¶
দাবা খেলোয়াড়রা প্রতিটা চাল খাতায় লেখে — পরে যেকোনো অবস্থান থেকে খেলা রিপ্লে করা যায়। আগের chapter-এ আমরা elimination-এর চালগুলো লিখতাম মুখের ভাষায়: "\(R_2 \leftarrow R_2 - 2R_1\)"। এই chapter-এর প্রথম আবিষ্কার: প্রতিটা চাল আসলে একটা matrix, আর চাল দেওয়া মানে সেই matrix দিয়ে বাঁদিক থেকে গুণ করা।
Elementary Matrix বানানোর রেসিপি (একটাই): identity matrix \(I\) নাও, তার উপর সেই row operation-টাই করো — ব্যস।
- \(R_1 \leftrightarrow R_2\) চাই? \(I\)-র প্রথম দুই row অদলবদল করো: \(E_{\text{swap}} = \begin{pmatrix}0&1&0\\1&0&0\\0&0&1\end{pmatrix}\)
- \(R_2 \leftarrow 3R_2\) চাই? \(E_{\text{scale}} = \begin{pmatrix}1&0&0\\0&3&0\\0&0&1\end{pmatrix}\)
- \(R_3 \leftarrow R_3 - 2R_1\) চাই? \(E_{\text{add}} = \begin{pmatrix}1&0&0\\0&1&0\\-2&0&1\end{pmatrix}\)
এখন যেকোনো matrix \(A\)-র জন্য \(E A\) হিসাব করলে দেখবে: ফলাফল ঠিক সেই row operation করা \(A\)। (কেন বাঁদিক থেকে? Matrix গুণে বাঁয়ের matrix ডানেরটার row-দের মিশায় — Part I-এ row-দৃষ্টিতে গুণ মনে করো। ডান থেকে গুণ করলে মিশতো column-রা।)
তাহলে elimination মানে কী দাঁড়ালো?¶
Chapter 2.2-এর পুরো অ্যালগরিদম এখন এক লাইনের গল্প: matrix \(A\)-র উপর একের পর এক elementary matrix:
আর LU decomposition হলো এই সমীকরণটাই উল্টে লেখা:
যেখানে \(L\) Lower Triangular(নিম্ন-ত্রিভুজাকার) — diagonal-এর উপরে সব শূন্য, আর \(U\) Upper Triangular(ঊর্ধ্ব-ত্রিভুজাকার) — diagonal-এর নিচে সব শূন্য। (Row swap না লাগলে এটা সরাসরি কাজ করে; লাগলে কী হয় — Property 5 দেখো।)
২. দেখতে কেমন?¶
তিন জাতের elementary matrix¶
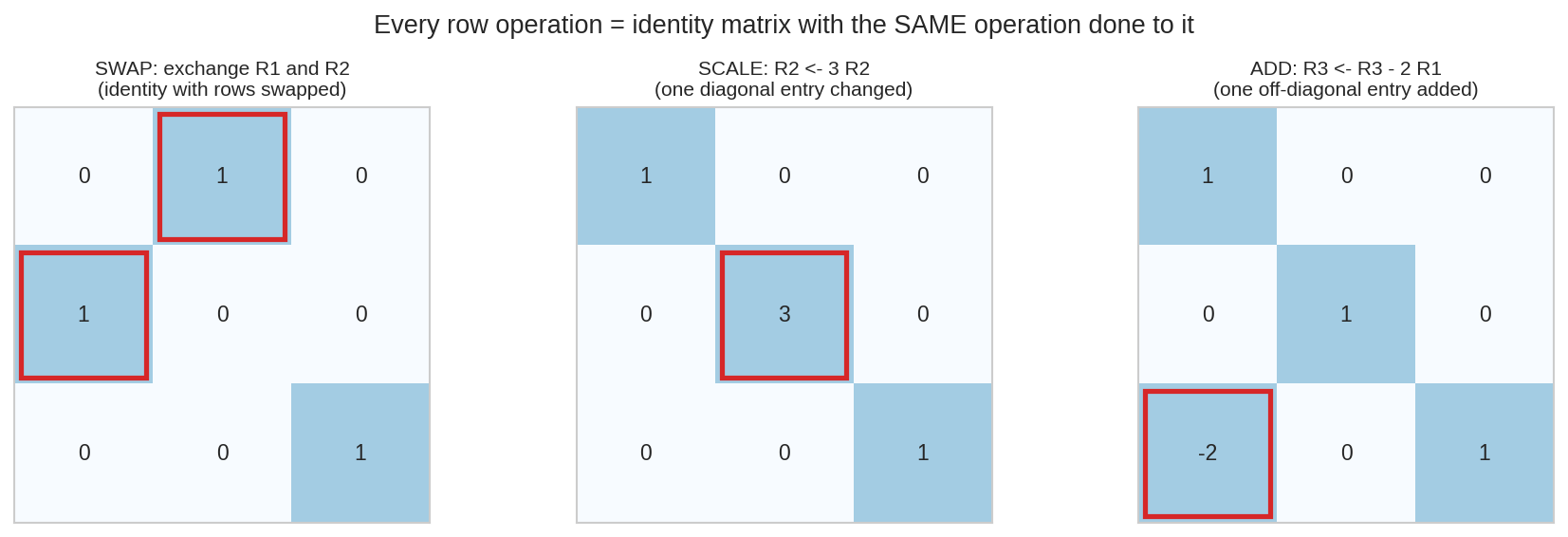
তিনটা চাল, তিনটা চেহারা — সবগুলোই "identity + সামান্য গোলমাল": swap-এ দুটো \(1\) জায়গা বদলায়, scale-এ একটা diagonal entry বদলায়, add-এ একটা off-diagonal ঘরে নতুন সংখ্যা বসে।
গুণ করলেই চাল¶
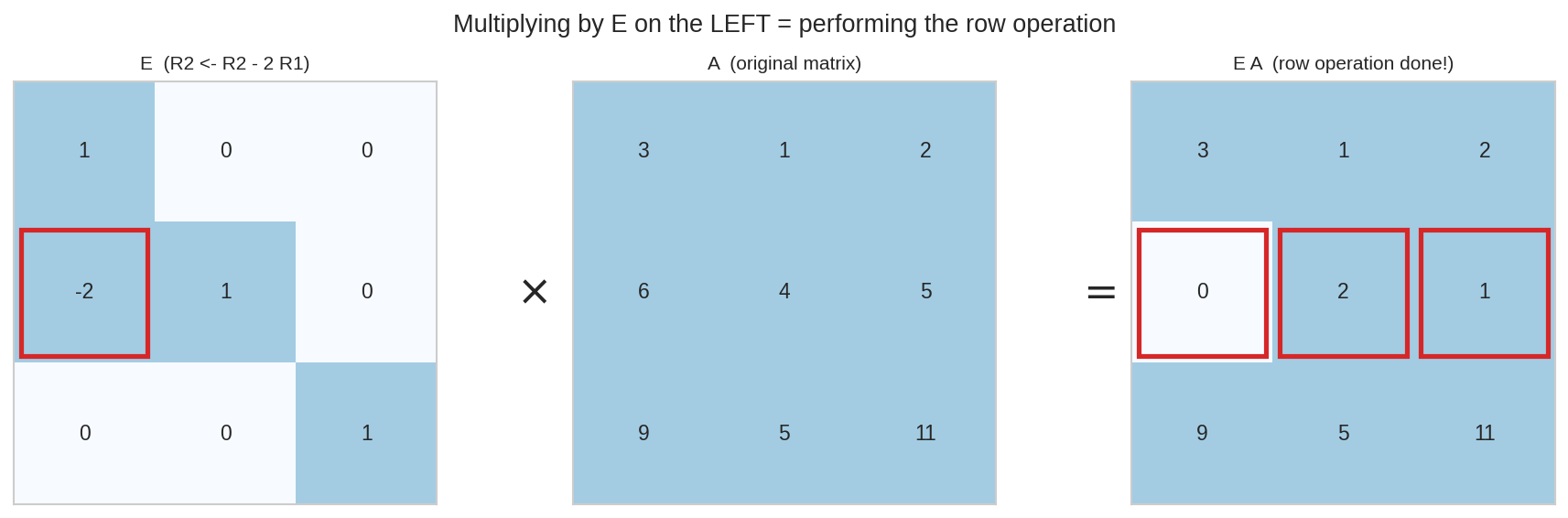
বাঁয়ে \(E\) (\(R_2 \leftarrow R_2 - 2R_1\)-এর matrix), মাঝে \(A\), ডানে গুণফল \(EA\) — দ্বিতীয় row-টা ঠিক বদলে গেছে, বাকি সব অক্ষত। "চাল দেওয়া = বাঁ থেকে গুণ।"
৩. কোথায় ইউজ হয়?¶
- প্রতিটা পেশাদার solver:
scipy.linalg.lu_factor, LAPACK-এরgetrf, MATLAB-এরlu— কম্পিউটার যখনই \(A\mathbf{x}=\mathbf{b}\) solve করে, ভেতরে প্রায় সবসময় LU-ই চলে।np.linalg.solve-ও তাই। - এক \(A\), হাজারটা \(\mathbf{b}\): circuit simulation, structural engineering (Finite Element Method), weather model — একই কাঠামো (\(A\)) বারবার, লোড/ইনপুট (\(\mathbf{b}\)) বদলায়। LU একবার বানিয়ে প্রতিটা নতুন \(\mathbf{b}\) প্রায় বিনা খরচে solve হয় (Property 4)।
- Determinant: \(\det A = \det L \cdot \det U = 1 \cdot (u_{11}u_{22}\cdots u_{nn})\) — triangular-এর determinant শুধু diagonal-এর গুণফল; Part VI-এ এটাই দ্রুততম পথ।
- Matrix inverse: সত্যি বলতে, বাস্তবে \(A^{-1}\) প্রায় কখনো সরাসরি বানানো হয় না — "inverse লাগবে" মানে প্রায় সবসময় "LU দিয়ে solve করো।"
- ML পাইপলাইনে: Gaussian process, Kalman filter, ridge regression-এর normal equations — সবখানে বারবার positive definite system solve; সেখানে LU-এর ভাই Cholesky decomposition (Part VI ও VIII) রাজত্ব করে।
৪. Properties¶
Property 1 — প্রতিটা elementary matrix invertible, inverse-ও elementary¶
চালের undo-চাল তো Chapter 2.2-এই দেখেছি; matrix-এর ভাষায়:
শেষেরটা সবচেয়ে দরকারি: add-চালের inverse মানে শুধু চিহ্ন উল্টানো — "বিয়োগ করেছিলে? যোগ করে দাও।"
Property 2 — \(L\)-এর জাদু: multiplier-রা নিজের ঘরে নিজে বসে¶
Elimination-এ যখন \(R_i \leftarrow R_i - \ell_{ij} R_j\) চাল দাও, সেই সংখ্যা \(\ell_{ij}\)-কে বলে multiplier। জাদুটা হলো:
— অর্থাৎ \(E^{-1}\)-দের গুণফল আলাদা করে হিসাবই করতে হয় না; প্রতিটা multiplier চিহ্ন-সহ (যেটা বিয়োগ করেছ সেটাই, + হয়ে) \(L\)-এর \((i,j)\) ঘরে বসিয়ে দাও, diagonal-এ \(1\)। কেন এই সরল জমা-খরচ কাজ করে — §৫-এ। (\(L\)-এর diagonal-এ সব \(1\) — এমন matrix-কে বলে unit lower triangular।)
⚠️ সতর্কতা: জাদুটা খাটে শুধু সঠিক ক্রমে কাজ করলে (column ধরে বাঁ থেকে ডানে, উপরে থেকে নিচে) — যে ক্রমে Gaussian elimination এমনিতেই চলে।
Property 3 — Triangular system solve করা পানির মতো সহজ¶
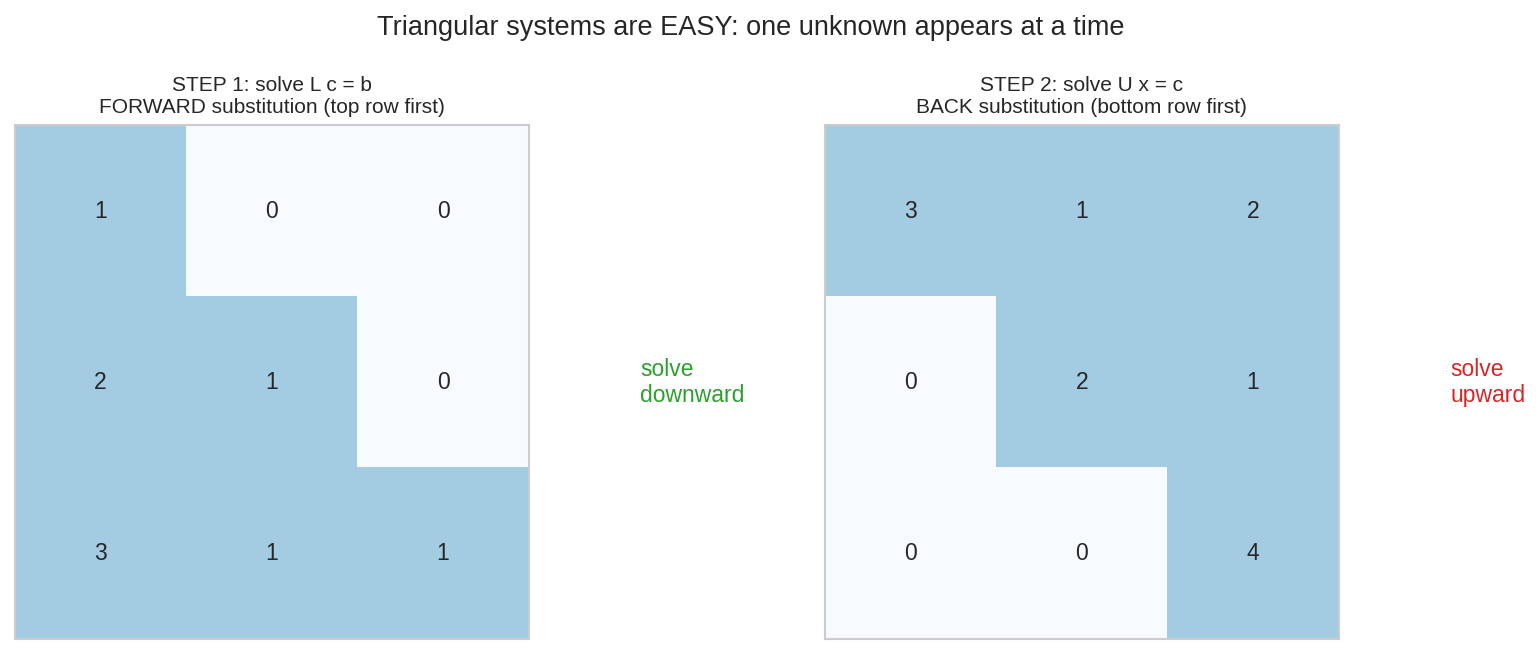
Triangular matrix-এ প্রতি row-তে একটাই নতুন unknown — তাই কোনো elimination ছাড়াই, শুধু বসিয়ে-বসিয়ে সমাধান। \(L\)-এ উপর থেকে নামো, \(U\)-তে নিচ থেকে ওঠো।
Property 4 — খরচের হিসাব: কেন LU, কেন বারবার elimination নয়¶
\(n\times n\) matrix-এ elimination-এর খরচ \(\approx \frac{2}{3}n^3\) operation; কিন্তু triangular solve মাত্র \(\approx 2n^2\)। তাই \(k\)টা ভিন্ন \(\mathbf{b}\)-র জন্য:
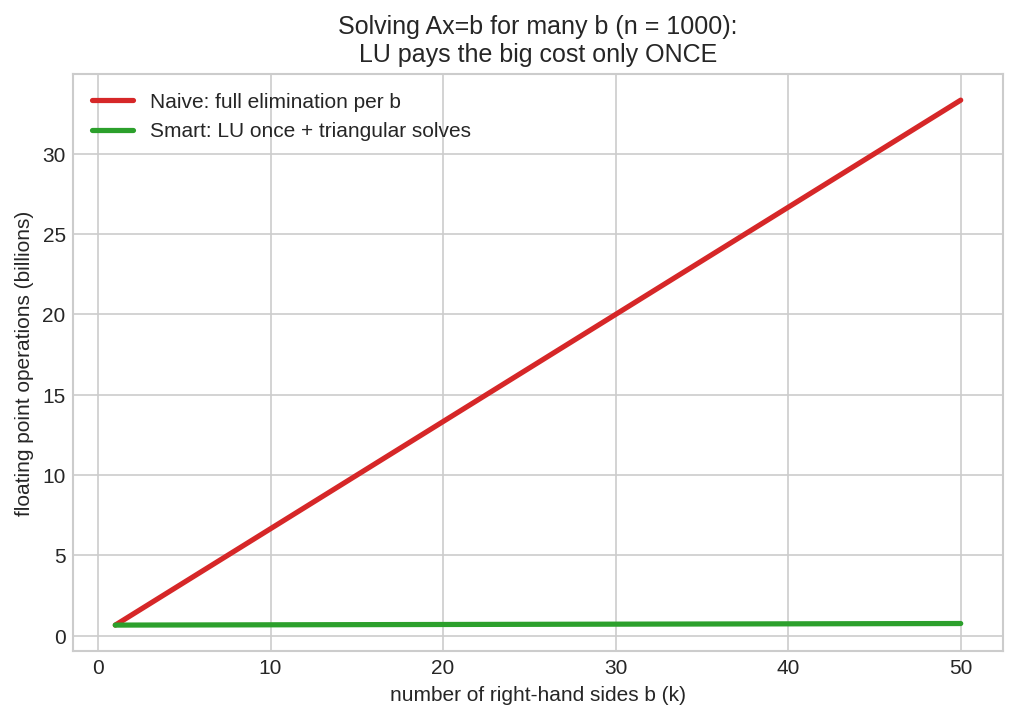
\(n=1000\)-এ ৫০টা \(\mathbf{b}\) solve করতে: বারবার elimination ৩৩ বিলিয়ন operation, LU-পথ মোটে ০.৭৭ বিলিয়ন — প্রায় ৪৩ গুণ সস্তা। \(n\) যত বড়, ফারাক তত নাটকীয়।
Property 5 — Pivot শূন্য পড়লে? \(PA = LU\)¶
Elimination-এ কখনো pivot-এর ঘরে শূন্য পড়ে — তখন row swap লাগে, আর swap-রা \(L\)-এর সরল জমা-খরচে ধরা দেয় না। সমাধান: সব swap-কে একটা Permutation Matrix(পারমুটেশন ম্যাট্রিক্স) \(P\)-তে (identity-র row-রা এলোমেলো করা matrix) জড়ো করে আগে সেরে ফেলা ভাবো:
কম্পিউটার আসলে সবসময় এটাই করে — শূন্য pivot না পড়লেও, নির্ভুলতার জন্য প্রতি ধাপে সবচেয়ে বড় entry-কে swap করে pivot বানায় (partial pivoting, Chapter 2.2-এর Problem 7 মনে করো)। scipy.linalg.lu তাই তিনটা জিনিস ফেরত দেয়: \(P, L, U\)।
৫. Intuition — কেন সত্য?¶
কেন \(L\)-এ multiplier-রা সোজা বসে যায়?¶
একটা চালের কথা ভাবো: \(R_2 \leftarrow R_2 - 2R_1\), মানে \(E_1 = \left[\begin{smallmatrix}1&0&0\\-2&1&0\\0&0&1\end{smallmatrix}\right]\)। এর undo: \(E_1^{-1} = \left[\begin{smallmatrix}1&0&0\\+2&1&0\\0&0&1\end{smallmatrix}\right]\) — "যা কেটেছিলে, ফেরত দাও।"
এবার আসল প্রশ্ন: \(L = E_1^{-1}E_2^{-1}E_3^{-1}\cdots\) গুণফলে ঘরগুলো মিশে যায় না কেন? লক্ষ করো \(E_1^{-1}\)-এর কাজ "row 1-এর \(2\) গুণ row 2-তে যোগ", আর \(E_2^{-1}\) হয়তো "row 1-এর \(3\) গুণ row 3-তে যোগ"। Undo-দের এই বিশেষ ক্রমে (elimination-এর উল্টো ক্রম মানে: আগে column 1-এর undo-রা, ভেতরে উপর থেকে নিচ) প্রতিটা undo যখন কাজ করে, যে row-টা সে ব্যবহার করছে (pivot row) তখনো তার নিজের ঘরে \(1\) আর বাঁয়ে-শূন্য অবস্থায় — তাই যোগ করার সময় অন্য multiplier-দের ঘাঁটায় না; প্রত্যেকে নিজের \((i,j)\) ঘরে নিজের সংখ্যাটা রেখে সরে যায়। ফল: গুণফল = "সবাই নিজ ঘরে বসা" matrix।
সন্দেহ হলে সবচেয়ে ভালো ওষুধ — একবার হাতে গুণে দেখা (Worked Example 1-এ করবো)।
\(A = LU\)-কে গল্প হিসেবে পড়া¶
- \(U\) হলো গন্তব্য: elimination শেষের সিঁড়ি-আকার matrix।
- \(L\) হলো ফেরার পথের নির্দেশনা: \(U\) থেকে শুরু করে \(L\)-এর চালগুলো (multiplier-রা) উল্টো করে প্রয়োগ করলে \(A\) ফিরে আসে।
তাই \(LU\) রাখা মানে \(A\)-র সব তথ্য রাখা — কিন্তু এমন ফরম্যাটে যেখানে solve করা সস্তা। Data compression যেমন ছবি রাখে অন্য ফরম্যাটে, LU রাখে matrix-কে "solve-বান্ধব" ফরম্যাটে।
৬. Code-এ কেমনে লিখে¶
আগে scratch-এ, তারপর লাইব্রেরি দিয়ে যাচাই:
import numpy as np
def lu_scratch(A):
"""LU decomposition (pivoting ছাড়া) — Doolittle পদ্ধতি।"""
n = A.shape[0]
L = np.eye(n)
U = A.astype(float).copy()
for j in range(n - 1): # column ধরে এগোই
if np.isclose(U[j, j], 0):
raise ValueError("zero pivot — এখানে PA=LU লাগবে!")
for i in range(j + 1, n):
m = U[i, j] / U[j, j] # multiplier
L[i, j] = m # খাতায় লিখে রাখো (জাদু!)
U[i] = U[i] - m * U[j] # row operation
return L, U
A = np.array([[3., 1., 2.],
[6., 4., 5.],
[9., 5., 11.]])
L, U = lu_scratch(A)
print("L =\n", L)
print("U =\n", U)
print("L @ U == A ?", np.allclose(L @ U, A))
Output:
L =
[[1. 0. 0.]
[2. 1. 0.]
[3. 1. 1.]]
U =
[[3. 1. 2.]
[0. 2. 1.]
[0. 0. 4.]]
L @ U == A ? True
এবার LU দিয়ে solve — দুটো triangular solve:
def forward_sub(L, b): # L c = b, উপর থেকে নিচে
n = len(b); c = np.zeros(n)
for i in range(n):
c[i] = (b[i] - L[i, :i] @ c[:i]) / L[i, i]
return c
def back_sub(U, c): # U x = c, নিচ থেকে উপরে
n = len(c); x = np.zeros(n)
for i in range(n - 1, -1, -1):
x[i] = (c[i] - U[i, i+1:] @ x[i+1:]) / U[i, i]
return x
b = np.array([13., 31., 43.])
c = forward_sub(L, b)
x = back_sub(U, c)
print("x =", x, "| check:", A @ x) # A @ x == b ✓
লাইব্রেরির সাথে মিলিয়ে দেখা (সে \(P\)-ও দেয়, কারণ সে সবসময় pivoting করে):
from scipy.linalg import lu, lu_factor, lu_solve
P, L2, U2 = lu(A)
print(np.allclose(P @ L2 @ U2, A)) # True (এখানে বিন্যাস A = P L U)
lu_piv = lu_factor(A) # বাস্তবের কাজে এটাই ব্যবহার করো
print(lu_solve(lu_piv, b)) # x — এক লাইনে
৭. Worked Examples¶
Example 1 — চাল থেকে matrix, matrix থেকে চাল¶
\(3\times3\)-এ পরপর দুই চাল: প্রথমে \(R_2 \leftarrow R_2 - 2R_1\), তারপর \(R_3 \leftarrow R_3 + R_2\)।
দুই চাল একসাথে = \(E_2 E_1\) (খেয়াল করো: আগের চাল ডানে, কারণ \(A\)-র গায়ে সে-ই আগে লাগে — \(E_2(E_1 A)\)):
আর undo-দের গুণফল, উল্টো ক্রমে:
দেখো — multiplier দুটো (\(+2\) আর \(-1\)… মানে চাল দুটোর উল্টো-চিহ্ন) যে যার ঘরে পরিষ্কার বসে আছে, কোনো মেশামেশি নেই। এটাই Property 2-এর জাদু, হাতে-নাতে। (আর \(E_2E_1\)-এ কিন্তু \((3,1)\) ঘরে একটা "ভেজাল" \(-2\) ঢুকে গেছে — তাই খাতা রাখা হয় undo-দের দিয়ে, চালদের দিয়ে নয়!)
Example 2 — পুরো LU, ধাপে ধাপে¶
ধাপ ১ (column 1 সাফ): \(\ell_{21} = \frac63 = 2\), \(R_2 \leftarrow R_2 - 2R_1\); \(\ell_{31} = \frac93 = 3\), \(R_3 \leftarrow R_3 - 3R_1\):
ধাপ ২ (column 2 সাফ): \(\ell_{32} = \frac22 = 1\), \(R_3 \leftarrow R_3 - R_2\):
যাচাই (\(LU\)-এর তৃতীয় row): \(3\cdot(3,1,2) + 1\cdot(0,2,1) + 1\cdot(0,0,4) = (9, 5, 11)\) ✓ — এটাই opening figure-এর matrix।
Example 3 — সেই LU দিয়ে \(A\mathbf{x} = \mathbf{b}\), \(\mathbf{b} = (13, 31, 43)\)¶
Forward (\(L\mathbf{c}=\mathbf{b}\), উপর থেকে):
Back (\(U\mathbf{x}=\mathbf{c}\), নিচ থেকে):
যাচাই (প্রথম equation): \(3\cdot\frac{29}{8} + \frac{21}{8} + 2\cdot(-\frac14) = \frac{87+21-4}{8} = \frac{104}{8} = 13\) ✓। কোথাও একটাও "elimination" করতে হয়নি — শুধু বসানো আর ভাগ। কাল যদি নতুন \(\mathbf{b}\) আসে, আবার শুধু এই সস্তা দুই ধাপ।
৮. Problems ও Solutions¶
Problem 1. \(4\times4\) identity থেকে বানাও: (a) \(R_2 \leftrightarrow R_4\)-এর elementary matrix, (b) \(R_3 \leftarrow R_3 + 5R_1\)-এর, (c) \(R_1 \leftarrow -2R_1\)-এর। প্রত্যেকটার inverse-ও লেখো।
Solution
নিয়ম মনে রাখো: swap-এর inverse সে নিজে; add-এর inverse চিহ্ন-উল্টানো; scale-এর inverse reciprocal।
Problem 2. \(B = \begin{pmatrix}1&4\\2&9\end{pmatrix}\)-এর LU decomposition হাতে বের করো, তারপর \(LU\) গুণ করে যাচাই করো।
Solution
Multiplier: \(\ell_{21} = \frac21 = 2\); \(R_2 \leftarrow R_2 - 2R_1\) দিলে \(R_2 = (0, 1)\)।
যাচাই: \(LU = \begin{pmatrix}1\cdot1+0 & 1\cdot4+0\\ 2\cdot1+0 & 2\cdot4+1\end{pmatrix} = \begin{pmatrix}1&4\\2&9\end{pmatrix} = B\) ✓
Problem 3. দেওয়া আছে \(L = \begin{pmatrix}1&0\\3&1\end{pmatrix}\), \(U = \begin{pmatrix}2&1\\0&5\end{pmatrix}\), \(\mathbf{b} = \binom{4}{22}\)। \(A\) না বানিয়ে \(A\mathbf{x}=\mathbf{b}\) solve করো।
Solution
Forward (\(L\mathbf{c}=\mathbf{b}\)): \(c_1 = 4\); \(3(4) + c_2 = 22 \implies c_2 = 10\)।
Back (\(U\mathbf{x}=\mathbf{c}\)): \(5y = 10 \implies y = 2\); \(2x + y = 4 \implies x = 1\)।
\(\mathbf{x} = (1, 2)\)। ইচ্ছা করলে এখন যাচাই: \(A = LU = \begin{pmatrix}2&1\\6&8\end{pmatrix}\), আর \(A\binom{1}{2} = \binom{4}{22}\) ✓ — কিন্তু solve করতে \(A\) লাগেইনি, এটাই পয়েন্ট।
Problem 4. \(C = \begin{pmatrix}0&2\\3&1\end{pmatrix}\)-এর pivoting-ছাড়া LU নেই কেন ব্যাখ্যা করো, তারপর এমন \(P\) খুঁজে বের করো যেন \(PC\)-র LU আছে, এবং সেই \(L, U\) লেখো।
Solution
প্রথম pivot-এর ঘরে (\(1,1\) অবস্থানে) \(0\) — multiplier \(\ell_{21} = \frac30\) অসংজ্ঞায়িত, elimination প্রথম ধাপেই আটকে যায়। অথচ \(C\) দিব্যি ভালো matrix (invertible!) — দোষটা matrix-এর নয়, ক্রমের।
Row অদলবদল করি: \(P = \begin{pmatrix}0&1\\1&0\end{pmatrix}\) নিলে \(PC = \begin{pmatrix}3&1\\0&2\end{pmatrix}\) — এটা এমনিতেই upper triangular! তাই
Problem 5. প্রমাণ করো: দুটো \(n\times n\) lower triangular matrix-এর গুণফলও lower triangular। (\(L\) কেন lower triangular হয় তার হিসাবি কারণ এটাই।)
Solution
\(A, B\) lower triangular মানে \(i < j\) হলে \(a_{ij} = 0, b_{ij} = 0\)। গুণফলের \((i,j)\) entry (\(i<j\) ধরে):
প্রতিটা পদে হয় \(m > i \ge\) … দেখি: \(a_{im} \ne 0\) হতে হলে চাই \(m \le i\); আবার \(b_{mj} \ne 0\) হতে হলে চাই \(m \ge j\)। দুটো একসাথে চাইলে \(j \le m \le i\), অর্থাৎ \(j \le i\) — কিন্তু আমরা ধরেছি \(i < j\)। কাজেই প্রতিটা পদই শূন্য, \((AB)_{ij} = 0\)। \(\blacksquare\)
(একই যুক্তিতে unit diagonal-ও টিকে থাকে: \((AB)_{ii} = a_{ii}b_{ii} = 1\cdot1 = 1\)। তাই \(E^{-1}\)-দের গুণফল \(L\) সবসময় unit lower triangular।)
Problem 6. তোমার ল্যাবের simulation-এ একটা \(2000\times2000\) matrix \(A\) fixed, আর প্রতিদিন ৫০০টা নতুন \(\mathbf{b}\) আসে। (a) \(\frac23 n^3\) আর \(2n^2\) সূত্র দিয়ে দুই কৌশলের মোট operation তুলনা করো। (b) কতগুণ সাশ্রয়? (c) যদি প্রতিদিন matrix \(A\)-ও বদলাতো, LU কি তবু লাভজনক?
Solution
(a) \(n = 2000\): elimination একবার \(= \frac23 (2000)^3 \approx 5.33\times10^9\); triangular solve একজোড়া \(= 2n^2 = 8\times10^6\)।
- বারবার elimination: \(500 \times 5.33\times10^9 \approx 2.67\times10^{12}\)
- LU একবার: \(5.33\times10^9 + 500 \times 8\times10^6 \approx 9.33\times10^9\)
(b) \(\frac{2.67\times10^{12}}{9.33\times10^9} \approx 286\) গুণ সাশ্রয় — ঘণ্টার কাজ সেকেন্ডে।
(c) \(A\) প্রতিদিন বদলালেও দিনে একটাই factorization + ৫০০ জোড়া সস্তা solve — তবুও দিনপ্রতি ৫০০ গুণের জায়গায় ১ গুণ elimination। LU তখনো জেতে; হারতো কেবল যদি প্রতিটা \(\mathbf{b}\)-র সাথে \(A\)-ও বদলাতো (তখন উভয় কৌশলই সমান)।
৯. Common ভুল¶
ভুল ১: \(E\)-কে ডানদিক থেকে গুণ করা (\(AE\))। ✗ \(AE\) করলে row নয়, column operation হয়ে যায় — সম্পূর্ণ অন্য জিনিস। ✓ Row operation = বাঁ থেকে গুণ: \(EA\)। মুখস্থের বদলে মনে রাখো: বাঁয়ের matrix ডানেরটার row মিশায়।
ভুল ২: চালের ক্রম উল্টে ফেলা। ✗ আগে \(E_1\), পরে \(E_2\) করলে ফলাফল \(E_1 E_2 A\) নয়। ✓ যে চাল আগে, সে \(A\)-র গা ঘেঁষে: \(E_2 E_1 A\)। (ফাংশন composition-এর মতো — ভেতরেরটা আগে খাটে।)
ভুল ৩: \(L\)-এ multiplier-এর চিহ্ন উল্টে রাখা। ✗ চাল ছিল \(R_2 \leftarrow R_2 - 2R_1\), তাই \(L\)-এ \(-2\) বসানো — ভুল! ✓ \(L\) হলো undo-দের খাতা: \(\ell_{21} = +2\) (যে সংখ্যা দিয়ে ভাগ-করা-অনুপাতে বিয়োগ করেছ, সেটাই সোজা চিহ্নে)। দ্রুত যাচাই: \(LU\) গুণ করে \(A\) ফেরে কি না।
ভুল ৪: Pivoting ভুলে zero-pivot-এ আটকে যাওয়া (বা প্রায়-শূন্য pivot-এ ভুল উত্তর)।
✗ Scratch LU সরাসরি production-এ চালানো।
✓ শেখার জন্য pivoting-ছাড়া ঠিক আছে; আসল কাজে scipy.linalg.lu_factor (ভেতরে \(PA=LU\) + partial pivoting)।
ভুল ৫: "Inverse বানিয়ে solve করি" — \(A^{-1}\mathbf{b}\)।
✗ \(A^{-1}\) বানানো LU-এর চেয়ে ~৩ গুণ দামি, নির্ভুলতাও কম।
✓ কোডে np.linalg.inv(A) @ b না লিখে np.linalg.solve(A, b) (এক \(\mathbf{b}\)) বা lu_factor/lu_solve (অনেক \(\mathbf{b}\))।
১০. এক নজরে¶
| ধারণা | এক লাইনে |
|---|---|
| Elementary matrix | \(I\)-র উপর একটা ERO করা matrix; \(EA\) = সেই ERO করা \(A\) |
| \(E^{-1}\) | undo-চালের matrix — swap→নিজে, scale→reciprocal, add→চিহ্ন-উল্টো |
| \(A = LU\) | \(U\): elimination-এর ফল (upper); \(L\): multiplier-দের খাতা (unit lower) |
| \(L\)-এর জাদু | \(\ell_{ij}\) = multiplier, সোজা চিহ্নে নিজ ঘরে; কোনো গুণ-হিসাব লাগে না |
| Solve | \(L\mathbf{c}=\mathbf{b}\) (forward) → \(U\mathbf{x}=\mathbf{c}\) (back); খরচ মাত্র \(2n^2\) |
| কেন দরকার | factor একবার (\(\frac23n^3\)), তারপর যত খুশি \(\mathbf{b}\) প্রায় ফ্রি |
| \(PA = LU\) | zero/ছোট pivot সামলাতে row swap-দের permutation matrix \(P\)-তে জমা |
পরের chapter-এর সেতু: এ পর্যন্ত আমরা শিখেছি সমাধান বের করতে — এবার প্রশ্ন, সমাধানগুলো দেখতে কেমন? Chapter 2.4-এ ফিরবো geometry-তে: এক equation কেন একটা hyperplane, free variable-রা কেন সমাধান সেটকে লাইন/প্লেন বানায়, আর কেন প্রতিটা সমাধান সেট = একটা particular সমাধান + homogeneous সমাধানেরা — Linear Algebra-র সবচেয়ে দামি বাক্যগুলোর একটা।
📓 Notebook Project¶
notebooks/part-02/ch03-project.ipynb — Scratch-এ LU factorization + forward/back substitution লিখে scipy-র সাথে নির্ভুলতা ও গতি দুটোই মেপে দেখো: এক \(A\), একশো \(\mathbf{b}\)-র race।