Chapter 1.3 — Inner Product / Dot Product (ইনার প্রোডাক্ট / ডট প্রোডাক্ট)¶
🎯 এই chapter-এ যা শিখবে¶
- Inner Product(ইনার প্রোডাক্ট) বা Dot Product-এর সংজ্ঞা: দুটি vector থেকে একটি সংখ্যা
- এর দুই চেহারা — বীজগণিতে "গুণ করে যোগ", জ্যামিতিতে "ছায়া (projection) \(\times\) দৈর্ঘ্য"
- Dot product-এর চিহ্ন (+, 0, −) থেকে দুই vector-এর কোণের ধরন পড়া
- Cosine similarity(কোসাইন সাদৃশ্য) — ML-এ "কতটা মিল" মাপার আদর্শ ফিতা
- Properties: symmetry, distributivity — আর বহু বাস্তব প্রয়োগ (বিল, গড়, ওজনি স্কোর)
🖼️ এক ছবিতে মূল idea¶
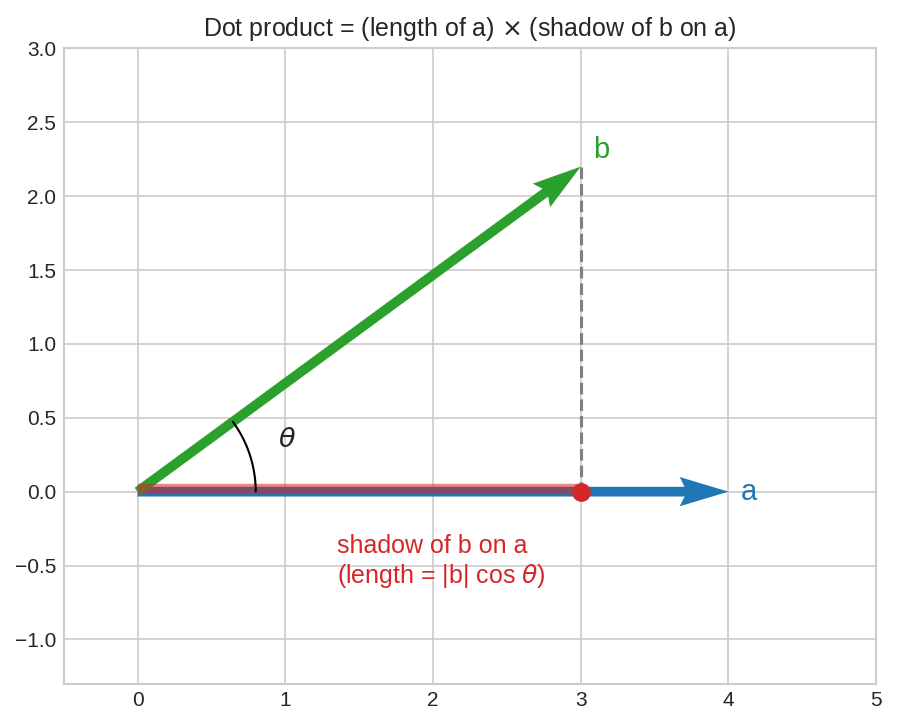
মাথার ওপর সূর্য; \(b\)-এর ছায়া পড়েছে \(a\)-এর ওপর — ছায়ার দৈর্ঘ্য \(\|b\|\cos\theta\)। Dot product হলো \(a\)-এর দৈর্ঘ্য \(\times\) এই ছায়া: \(a \cdot b = \|a\|\,\|b\|\cos\theta\)। দুই vector যত একমুখী, ছায়া তত লম্বা, dot product তত বড়।
১. কি? (What)¶
বাজারে গেলে: চাল ৫ কেজি, ডিম ২ ডজন, দুধ ৩ লিটার, তেল ১ লিটার। দাম যথাক্রমে ৮০, ১৫০, ৯০, ১৮০ টাকা (একক প্রতি)। মোট বিল কত? প্রত্যেকটার "পরিমাণ \(\times\) দাম" গুণ করে সব যোগ:
এই "জোড়ায় জোড়ায় গুণ, তারপর সব যোগ" — হিসাবটারই গালভরা নাম Inner Product (অন্য নাম Dot Product, বা Scalar Product)। পরিমাণ-vector \(q = (5, 2, 3, 1)\) আর দাম-vector \(p = (80, 150, 90, 180)\) হলে:
সাধারণ সংজ্ঞা — দুটি \(n\)-vector \(a, b\)-এর জন্য:
তিনটি notation-ই চালু: \(a^T b\) (VMLS/এই বই), \(a \cdot b\) (physics — "dot" নামের উৎস), \(\langle a, b\rangle\) (pure math)। (\(T\)-superscript-টার মানে transpose — Part III-তে বিস্তারিত; আপাতত \(a^T b\)-কে একটা জোড়-চিহ্ন হিসেবেই পড়ো।)
সবচেয়ে জরুরি কথাটা এখনই গেঁথে নাও: vector যোগের ফল ছিল vector, scalar গুণের ফলও vector — কিন্তু dot product-এর ফল একটি সংখ্যা (scalar)। দুটি vector ঢুকলো, একটা সংখ্যা বেরোলো। এই সংখ্যাটাই বলে দেবে দুই vector-এর "সম্পর্ক কেমন"।
ছোট উদাহরণ: \(a = (-1, 2, 2)\), \(b = (1, 0, -3)\) হলে
২. দেখতে কেমন?¶
সংখ্যার সংজ্ঞাটা যান্ত্রিক; আসল সৌন্দর্য geometry-তে। 2D/3D-তে প্রমাণ করা যায় (এই chapter-এর §৫-এ intuition, পুরো proof Chapter 1.4-এ):
যেখানে \(\|a\|\) মানে \(a\)-এর দৈর্ঘ্য (পরের chapter-এর নায়ক) আর \(\theta\) হলো দুই vector-এর মাঝের কোণ। Opening figure-এ দেখেছো এর মানে: ছায়া-গল্প। আর কোণ বদলালে চিহ্ন কীভাবে বদলায়:
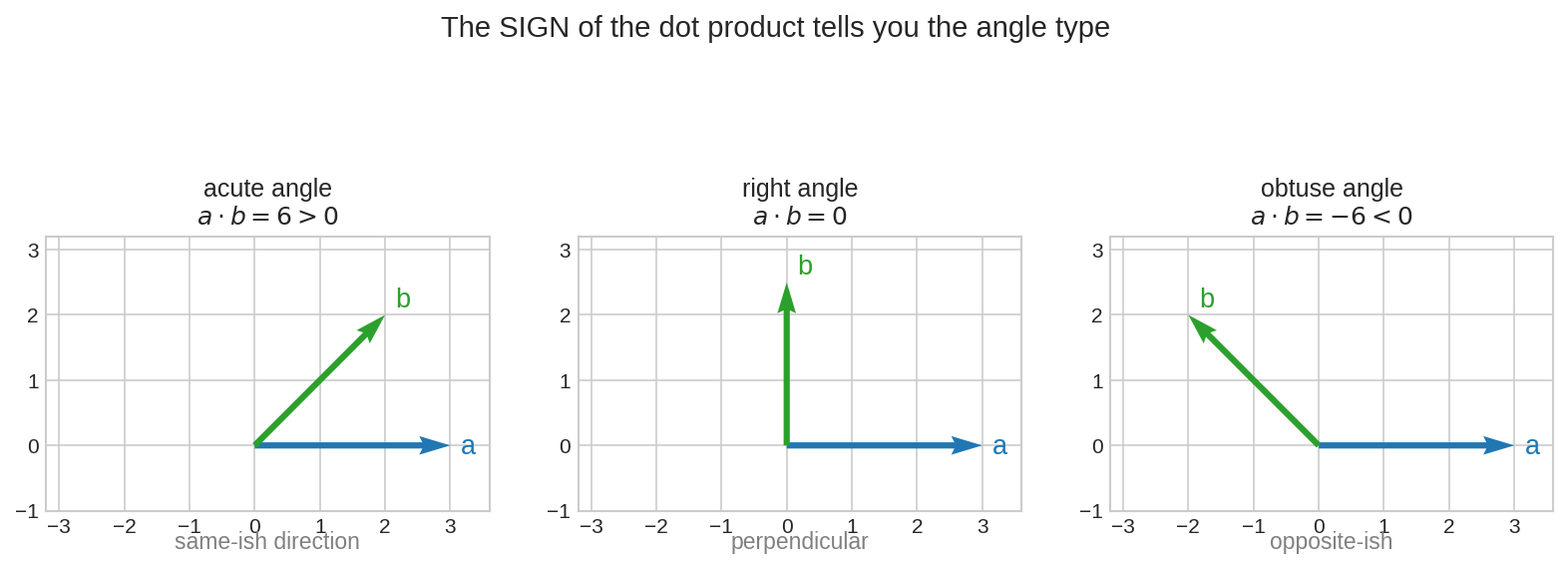
তিনটি জগত: কোণ \(90°\)-এর কম হলে \(a^Tb > 0\) (ছায়া সামনের দিকে), ঠিক \(90°\) হলে \(a^Tb = 0\) (ছায়াই নেই!), \(90°\)-এর বেশি হলে \(a^Tb < 0\) (ছায়া পেছনে)। শুধু চিহ্ন দেখে বলে দেওয়া যায় দুই vector বন্ধু, নিরপেক্ষ, নাকি বিপরীতমুখী।
\(a^T b = 0\)-এর বিশেষ নাম আছে: \(a\) ও \(b\) পরস্পর Orthogonal(অর্থোগোনাল) — মানে লম্ব (perpendicular)। এটা এতই গুরুত্বপূর্ণ যে Part V-এর পুরোটাই এর ওপর।
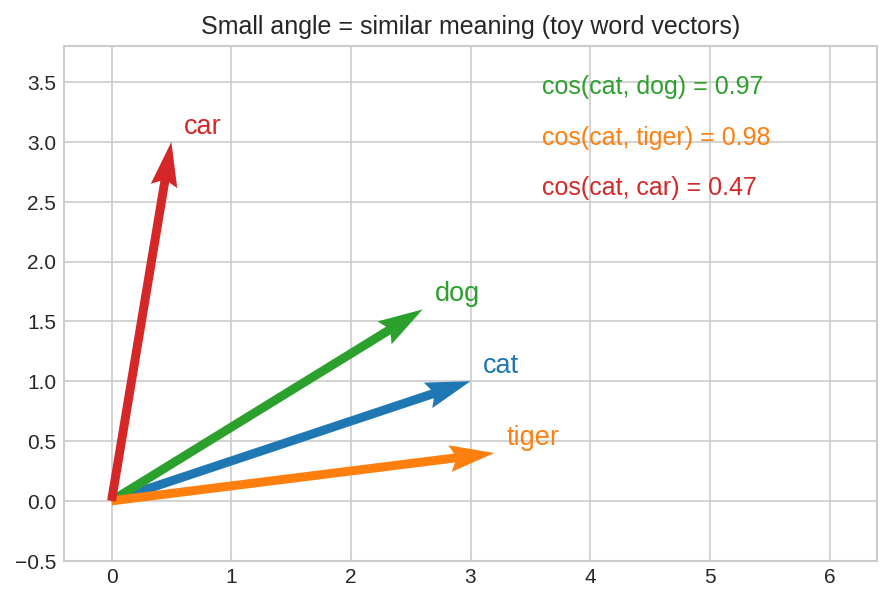
চারটি "শব্দ-vector": cat-এর সাথে dog আর tiger-এর কোণ ছোট (cosine বড়), কিন্তু car প্রায় লম্বদিকে (cosine ছোট)। কোণ-ই অর্থের দূরত্ব — এটাই word embedding-এর মূল দর্শন।
৩. কোথায় ইউজ হয়?¶
Dot product সম্ভবত Data Science-এর সবচেয়ে বেশিবার execute হওয়া operation। যেমন:
- মোট খরচ / revenue: পরিমাণ \(\cdot\) দাম — একটু আগেই করলে।
- Weighted score(ওজনি স্কোর): বিশ্ববিদ্যালয়ের ভর্তি: \(0.5 \times\) পরীক্ষা \(+ 0.3 \times\) GPA \(+ 0.2 \times\) ইন্টারভিউ। ছাত্রের score-vector আর weight-vector-এর dot product। প্রতিটা linear ML model-এর prediction-ও ঠিক এটাই: \(\hat{y} = w^T x\)!
- গড়: \(x\)-এর গড় \(= \frac{1}{n}\mathbf{1}^T x\) — ones vector-এর সাথে dot product ভাগ \(n\)। (আগের chapter-এর \(\mathbf{1}\) মনে আছে?)
- Cosine similarity — search engine: দুটি document/word vector-এর মিল মাপা হয় \(\cos\theta = \frac{a^Tb}{\|a\|\|b\|}\) দিয়ে। Google search, recommendation system, ChatGPT-র retrieval — সবখানে এই সূত্র। আজকের notebook project-এ নিজেই একটা বানাবে।
- Neural network: একটা neuron আসলে কী করে? Input vector \(x\)-এর সাথে নিজের weight vector \(w\)-এর dot product + bias, তারপর একটা bend। কোটি কোটি dot product/সেকেন্ড — এটাই GPU-র কাজ।
- Physics-এ কাজ (work): বল \(F\) আর সরণ \(d\) হলে কাজ \(= F^T d\) — বলের যে অংশটুকু চলার দিকে, শুধু সেটুকুই কাজে লাগে। ওই "যে অংশটুকু ওই দিকে" — আবারও ছায়া!
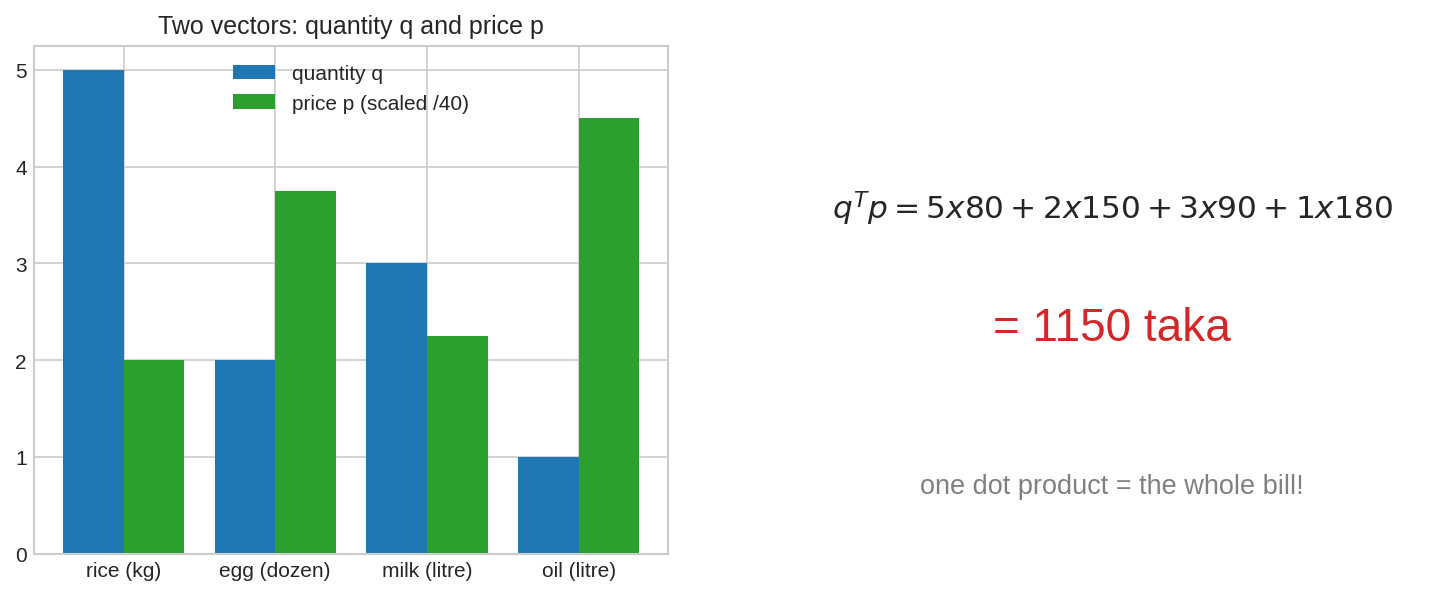
বাজারের হিসাব = dot product। বাঁয়ে দুটি vector (quantity ও price), ডানে তাদের inner product — এক সংখ্যায় পুরো বিল।
৪. Properties¶
\(a, b, c \in \mathbb{R}^n\), scalar \(\gamma\):
| Property | সূত্র | মানে |
|---|---|---|
| Commutativity(বিনিময়) | \(a^T b = b^T a\) | order-এ কিছু আসে যায় না |
| Scalar সাথে সহযোগিতা | \((\gamma a)^T b = \gamma (a^T b)\) | scale আগে বা পরে — সমান |
| Distributivity(বণ্টন) | \((a + b)^T c = a^T c + b^T c\) | যোগের ওপর ভাগ হয়ে যায় |
| নিজের সাথে | \(a^T a = a_1^2 + \cdots + a_n^2 \geq 0\) | সবসময় অঋণাত্মক; \(=0\) শুধু \(a=\mathbf{0}\) হলে |
প্রতিটির মিনি-derivation একই কৌশলে — সংজ্ঞা খুলে সাধারণ বীজগণিত। যেমন commutativity:
(সংখ্যার গুণ commutative, তাই vector-এর dot product-ও।)
আর distributivity:
চতুর্থ property-টা বিশেষভাবে দেখো: \(a^T a\) = নিজের ছায়া নিজের ওপর = দৈর্ঘ্যের বর্গ। পরের chapter-এ এ থেকেই norm-এর জন্ম: \(\|a\| = \sqrt{a^T a}\)।
কয়েকটা কাজের বিশেষ dot product (আগের chapter-দের চরিত্ররা ফিরে এলো):
- \(e_i^T a = a_i\) — unit vector দিয়ে dot মানে \(i\)-তম entry তুলে আনা (Ch 1.1-এর Problem 3!)
- \(\mathbf{1}^T a = a_1 + \cdots + a_n\) — সব entry-র যোগফল
- \(\mathbf{0}^T a = 0\) — zero vector সবার সাথেই orthogonal
সাবধানবাণী (দুটি ফাঁদ): ১. Dot product-এর কোনো "cancellation" নেই: \(a^Tb = a^Tc\) হলেও \(b = c\) নাও হতে পারে। ২. \((a^Tb)c\) আর \(a(b^Tc)\) এক নয় — প্রথমটা \(c\)-এর গুণিতক, দ্বিতীয়টা \(a\)-এর!
৫. Intuition — কেন সত্য?¶
"গুণ-করে-যোগ" আর "দৈর্ঘ্য \(\times\) ছায়া" — দুটো এত ভিন্ন বর্ণনা এক হয় কীভাবে? ধাপে ধাপে অনুভব করা যাক।
ধাপ ১ — সবচেয়ে সহজ ক্ষেত্র: \(a = (3, 0)\) (\(x\)-axis বরাবর)। তাহলে \(a^T b = 3b_1 + 0 = 3 b_1\)। এখন \(b_1\) কী? — \(b\)-এর "\(x\)-বরাবর অংশ", মানে \(x\)-axis-এর ওপর \(b\)-এর ছায়া! তাহলে \(a^Tb = \|a\| \times (\text{ছায়া})\) — সংজ্ঞা থেকেই বেরিয়ে এলো, কোনো জাদু ছাড়া।
ধাপ ২ — ঘুরিয়ে দিলে? যেকোনো \(a\)-কেই তো axis ভাবা যায় — কাগজটা ঘুরিয়ে নাও যেন \(a\) ডান দিকে শোয়। ঘোরালে দৈর্ঘ্য আর কোণ বদলায় না, তাই "ছায়া-গল্প" সব দিকের জন্যই খাটে। (আর "গুণ-করে-যোগ" যে ঘোরানোতে বদলায় না — সেটার সুন্দর প্রমাণ Chapter 1.4-এ cosine rule দিয়ে দেখবো।)
ধাপ ৩ — চিহ্নের অর্থ: ছায়া সামনে পড়লে \(+\), পেছনে পড়লে \(-\)। তাই dot product আসলে একটা "একমত-মিটার": দুই vector কতটা একমত হয়ে একই দিকে টানছে। পুরো একমত (\(\theta=0\)): সর্বোচ্চ \(\|a\|\|b\|\)। পুরো বিরোধ (\(\theta = 180°\)): সর্বনিম্ন \(-\|a\|\|b\|\)। উদাসীন (\(\theta = 90°\)): শূন্য।
ধাপ ৪ — কেন cosine similarity-তে ভাগ করি: \(a^Tb\) বড় হতে পারে দুই কারণে — কোণ ছোট, অথবা vector-রা এমনিই লম্বা। শুধু "দিকের মিল" চাইলে দৈর্ঘ্যের প্রভাব ঝেড়ে ফেলতে হয়:
এখন একটা ৫০০ শব্দের আর ৫০,০০০ শব্দের প্রবন্ধ — বিষয় এক হলে score একই রকম বড় হবে। এই normalization-টাই cosine similarity-র পুরো বুদ্ধি।
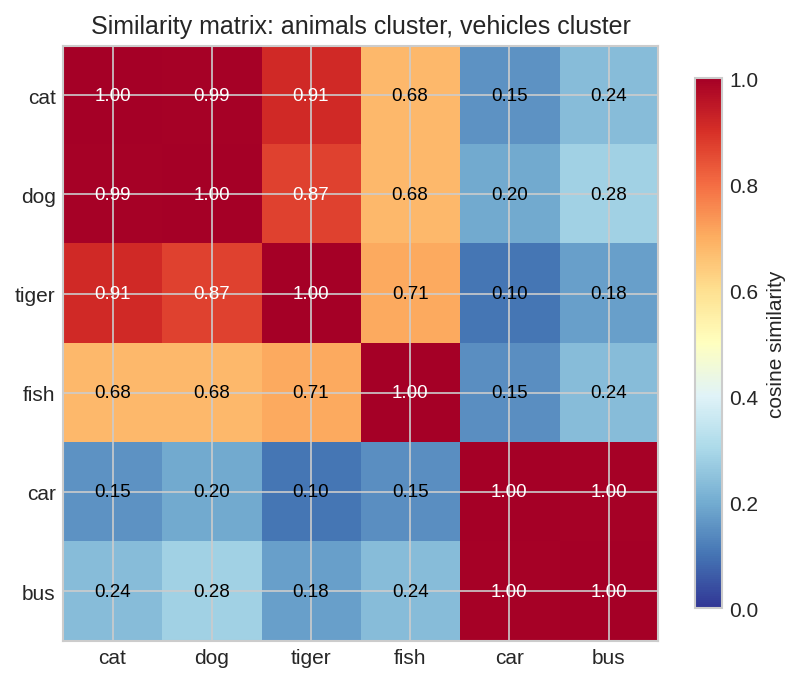
৬টি toy শব্দ-vector-এর সব জোড়ার cosine similarity। কর্ণ বরাবর সব \(1.00\) (নিজের সাথে নিজের কোণ শূন্য!)। প্রাণীরা পরস্পরের সাথে উজ্জ্বল-লাল (মিল বেশি), যানবাহনরা নিজেদের মধ্যে — আর দুই দলের মাঝে নীলচে (মিল কম)। পুরো matrix-টা মাত্র কয়েকটা dot product।
৬. Code-এ কেমনে লিখে¶
import numpy as np
a = np.array([-1., 2., 2.])
b = np.array([1., 0., -3.])
# তিনভাবে dot product — সব সমান
print(np.dot(a, b)) # -7.0
print(a @ b) # -7.0 <- আধুনিক ও প্রিয় লেখা
print(np.sum(a * b)) # -7.0 <- সংজ্ঞা খুলে: গুণ করে যোগ
# properties যাচাই
c = np.array([2., -1., 4.])
print(np.isclose(a @ b, b @ a)) # True (commutative)
print(np.isclose((a + b) @ c, a @ c + b @ c)) # True (distributive)
print(a @ a) # 9.0 = (-1)^2+2^2+2^2 >= 0
# বিশেষ dot products
ones = np.ones(3)
print(ones @ a) # 3.0 (= সব entry-র যোগফল)
print(ones @ a / 3) # 1.0 (= গড়)
# cosine similarity — scratch-এ
def cosine_sim(u, v):
return (u @ v) / (np.linalg.norm(u) * np.linalg.norm(v))
cat = np.array([0.9, 0.8, 0.1, 0.05])
dog = np.array([0.85, 0.9, 0.15, 0.1])
car = np.array([0.05, 0.1, 0.05, 0.95])
print(f"cat~dog: {cosine_sim(cat, dog):.3f}") # cat~dog: 0.997
print(f"cat~car: {cosine_sim(cat, car):.3f}") # cat~car: 0.135
Output ব্যাখ্যা: a @ b দিলো \(-7.0\) — হাতের হিসাবের সাথে হুবহু মিল। cat-dog similarity \(0.997\) (প্রায় একই দিক!) আর cat-car \(0.135\) (প্রায় orthogonal)। np.linalg.norm এখানে দৈর্ঘ্য মাপছে — পরের chapter-এ এর ভেতরটা খুলবো।
একটা performance-কথা: \(n\)-vector-এর dot product-এ লাগে \(n\)টা গুণ আর \(n-1\)টা যোগ — মোট \(\approx 2n\) operation (flops)। কোটি-dimension হলেও আজকের computer-এ এক পলক। VMLS-এর ভাষায় complexity \(O(n)\) — Part VIII-এ এই হিসাবের জগতে ঢুকবো।
৭. Worked Examples¶
Example 1 — হাতে হাতে dot product। \(a = (2, -1, 3)\), \(b = (1, 4, -2)\)।
ধাপ ১: জোড়ায় গুণ: \(2 \cdot 1 = 2\); \((-1)(4) = -4\); \((3)(-2) = -6\)। ধাপ ২: যোগ: \(2 - 4 - 6 = -8\)। ধাপ ৩ (ব্যাখ্যা): \(a^Tb = -8 < 0\) — vector দুটোর কোণ \(90°\)-এর বেশি; মোটের ওপর বিপরীতমুখী।
Example 2 — orthogonal কি না, আর অজানা entry। (ক) \(u = (3, -2)\) ও \(v = (4, 6)\) কি orthogonal? (খ) \(w = (5, k)\)-কে \(u\)-এর orthogonal বানাতে \(k\) কত?
ধাপ ১: \(u^T v = 3\cdot4 + (-2)(6) = 12 - 12 = 0\) — হ্যাঁ, orthogonal! (ছবি আঁকলে দেখবে সত্যিই লম্ব।) ধাপ ২: চাই \(u^T w = 0\): \(\;3 \cdot 5 + (-2)k = 0 \Rightarrow 15 = 2k \Rightarrow k = 7.5\)। যাচাই: \((3, -2)^T(5, 7.5) = 15 - 15 = 0\) ✓।
Example 3 — weighted score দিয়ে ranking। ভর্তি কমিটির weight \(w = (0.5, 0.3, 0.2)\) — (পরীক্ষা, GPA, ইন্টারভিউ), প্রতিটি ১০০-তে। দুই প্রার্থী: রিমা \(x_R = (80, 90, 70)\), সাজিদ \(x_S = (90, 70, 80)\)। কে এগিয়ে?
ধাপ ১: রিমা: \(w^T x_R = 0.5(80) + 0.3(90) + 0.2(70) = 40 + 27 + 14 = 81\)। ধাপ ২: সাজিদ: \(w^T x_S = 45 + 21 + 16 = 82\)। ধাপ ৩: সাজিদ সামান্য এগিয়ে। লক্ষ করো — weight বদলালে ফল উল্টে যেতে পারে; যেমন \(w = (0.2, 0.6, 0.2)\) হলে রিমা \(73\), সাজিদ \(76\)... না, এখনো সাজিদ! (\(w=(0.1,0.8,0.1)\) নিলে রিমা \(87\), সাজিদ \(73\) — এবার রিমা।) Model মানেই weight — weight মানেই dot product।
৮. Problems ও Solutions¶
Problem 1. হিসাব করো: (ক) \((1, 2, 3)^T(3, 2, 1)\); (খ) \((2, -3)^T(-3, -2)\); (গ) \((1, 0, -1, 2)^T(2, 9, 2, 0)\) — এবং প্রতিটির চিহ্ন থেকে কোণের ধরন বলো।
Solution
(ক) \(3 + 4 + 3 = 10 > 0\) — কোণ সূক্ষ্ম (acute); মোটের ওপর একই দিকে। (খ) \(-6 + 6 = 0\) — orthogonal, ঠিক \(90°\)। (গ) \(2 + 0 - 2 + 0 = 0\) — এটাও orthogonal! (\(\mathbb{R}^4\)-এ কোণ চোখে দেখা যায় না, কিন্তু সংজ্ঞা নির্ভীক।)
Problem 2. \(a^Tb\) ব্যবহার করে এক লাইনে লেখো: (ক) \(x \in \mathbb{R}^n\)-এর প্রথম ও শেষ entry-র যোগফল; (খ) \(x\)-এর জোড় index-এর entry-গুলোর যোগফল (\(n=4\) ধরো); (গ) \(x\)-এর গড়।
Solution
(ক) \((e_1 + e_n)^T x = x_1 + x_n\)। (খ) \(s = (0, 1, 0, 1)\) নিলে \(s^T x = x_2 + x_4\)। (গ) \(\left(\frac{1}{n}\mathbf{1}\right)^T x = \frac{x_1 + \cdots + x_n}{n}\)। দেখো — "কোন entry-গুলো নেবো" প্রশ্নটা প্রতিবার একটা selector vector হয়ে গেল। Dot product = প্রশ্ন করার ভাষা।
Problem 3. \(p = (12, 8, 15)\) হলো তিন পণ্যের দাম (টাকা), আর সোম-মঙ্গল-বুধের বিক্রয় পরিমাণ \(q_1 = (10, 5, 2)\), \(q_2 = (8, 6, 4)\), \(q_3 = (12, 4, 3)\)। (ক) প্রতিদিনের revenue বের করো। (খ) তিন দিনের মোট revenue দুইভাবে বের করো — আগে পরিমাণ যোগ করে, আর দিন-প্রতি revenue যোগ করে। কোন property মিলিয়ে দিলো?
Solution
(ক) \(p^Tq_1 = 120 + 40 + 30 = 190\); \(p^Tq_2 = 96 + 48 + 60 = 204\); \(p^Tq_3 = 144 + 32 + 45 = 221\)। (খ) পথ ১: \(q_1 + q_2 + q_3 = (30, 15, 9)\); \(p^T(30,15,9) = 360 + 120 + 135 = 615\)। পথ ২: \(190 + 204 + 221 = 615\) ✓। মিলালো distributivity: \(p^T(q_1 + q_2 + q_3) = p^Tq_1 + p^Tq_2 + p^Tq_3\)।
Problem 4. \(u = (1, 1)\), \(v = (1, 0)\)-এর মধ্যের কোণ বের করো cosine সূত্র দিয়ে। (\(\|u\| = \sqrt{2}\), \(\|v\| = 1\) দেওয়া রইলো।)
Solution
\(u^Tv = 1\)। \(\cos\theta = \dfrac{1}{\sqrt{2} \cdot 1} = \dfrac{1}{\sqrt 2} \approx 0.707\)। \(\theta = \arccos(0.707) = 45°\)। ছবি মেলে: \((1,1)\) কর্ণ বরাবর, \((1,0)\) axis বরাবর — মাঝে ঠিক আধা-সমকোণ।
Problem 5. দুটি ভিন্ন nonzero vector \(b \ne c\) খুঁজে বের করো যেন \(a = (1, 2)\)-এর জন্য \(a^Tb = a^Tc\) হয়। এ থেকে কী শিক্ষা?
Solution
যেমন \(b = (2, 0)\) আর \(c = (0, 1)\): \(a^Tb = 2\), \(a^Tc = 2\) — সমান, অথচ \(b \neq c\)। শিক্ষা: dot product-এ cancellation চলে না — \(a^Tb = a^Tc \nRightarrow b = c\)। কারণ সমান হওয়ার মানে শুধু এই যে \(a^T(b - c) = 0\), অর্থাৎ \(b-c\) vector-টা \(a\)-এর orthogonal — শূন্য হওয়া জরুরি না। (\(b - c = (2,-1)\), আর \((1,2)^T(2,-1) = 0\) ✓!)
Problem 6. Cosine similarity বের করো: \(d_1 = (2, 4, 6)\) আর \(d_2 = (1, 2, 3)\)। ফলটা দেখে কী বুঝলে? (\(\|d_1\| = \sqrt{56}\), \(\|d_2\| = \sqrt{14}\)।)
Solution
\(d_1^Td_2 = 2 + 8 + 18 = 28\)। \(\cos\theta = \dfrac{28}{\sqrt{56}\sqrt{14}} = \dfrac{28}{\sqrt{784}} = \dfrac{28}{28} = 1\)। Similarity ঠিক \(1\) — সর্বোচ্চ! কারণ \(d_1 = 2d_2\) — একই দিকের vector, শুধু দৈর্ঘ্য আলাদা। যেমন একই প্রবন্ধের ছোট আর বড় সংস্করণ: শব্দসংখ্যা দ্বিগুণ, কিন্তু "topic-এর দিক" এক — cosine similarity সেটাই ধরে।
Problem 7. সত্য/মিথ্যা — কারণসহ: (ক) \(a^Ta = 0\) হলে \(a = \mathbf{0}\); (খ) \(a^Tb > 0\) এবং \(b^Tc > 0\) হলে \(a^Tc > 0\); (গ) \((2a)^T(3b) = 6\,a^Tb\); (ঘ) দুটি sparse vector-এর dot product সবসময় \(0\)।
Solution
(ক) সত্য। \(a^Ta = a_1^2 + \cdots + a_n^2\) — অঋণাত্মক সংখ্যার যোগফল \(0\) হলে প্রতিটিই \(0\)। (খ) মিথ্যা। "বন্ধুর বন্ধু বন্ধু" এখানে খাটে না! যেমন \(a = (1,0)\), \(b = (1,1)\), \(c = (-1, 2)\): \(a^Tb = 1 > 0\), \(b^Tc = 1 > 0\), কিন্তু \(a^Tc = -1 < 0\)। (গ) সত্য। Scalar-রা বাইরে বেরিয়ে আসে: \((2a)^T(3b) = 2 \cdot 3 \,(a^Tb) = 6\,a^Tb\)। (ঘ) মিথ্যা। অশূন্য জায়গা মিলে গেলে dot product অশূন্য: \((1, 0, 0)^T(2, 0, 0) = 2\)। (তবে অশূন্য জায়গাগুলো আলাদা হলে অবশ্যই \(0\)।)
Problem 8 (চ্যালেঞ্জ — mini-search)। চারটি "প্রবন্ধ"-vector (topic-স্কোর: [ক্রিকেট, রাজনীতি, প্রযুক্তি]): \(d_1 = (8, 1, 1)\), \(d_2 = (1, 9, 2)\), \(d_3 = (2, 1, 9)\), \(d_4 = (5, 1, 5)\)। Query: "ক্রিকেট + প্রযুক্তি" \(= q = (1, 0, 1)\)। Cosine similarity দিয়ে প্রবন্ধগুলো rank করো। (\(\sqrt{66} \approx 8.12\), \(\sqrt{86} \approx 9.27\), \(\sqrt{2} \approx 1.41\), \(\sqrt{51} \approx 7.14\) কাজে লাগবে।)
Solution
Dot products: \(q^Td_1 = 8+0+1 = 9\); \(q^Td_2 = 3\); \(q^Td_3 = 11\); \(q^Td_4 = 10\)। Norms: \(\|d_1\| = \sqrt{66} \approx 8.12\), \(\|d_2\| = \sqrt{86} \approx 9.27\), \(\|d_3\| = \sqrt{86} \approx 9.27\), \(\|d_4\| = \sqrt{51} \approx 7.14\), \(\|q\| = \sqrt 2 \approx 1.41\)। Similarities: \(d_1: \frac{9}{8.12 \times 1.41} \approx 0.78\); \(\;d_2: \frac{3}{9.27 \times 1.41} \approx 0.23\); \(\;d_3: \frac{11}{9.27 \times 1.41} \approx 0.84\); \(\;d_4: \frac{10}{7.14 \times 1.41} \approx 0.99\)। Ranking: \(d_4 > d_3 > d_1 > d_2\)। \(d_4\) জিতলো কারণ সে ঠিক অর্ধেক ক্রিকেট-অর্ধেক প্রযুক্তি — query-র দিকের সাথে প্রায় নিখুঁত মিল! (খেয়াল করো: raw dot product-এ \(d_3\) এগিয়ে ছিল; normalization ছবিটা পাল্টে দিলো।) — এটাই আজকের notebook-এর ইঞ্জিন।
৯. Common ভুল¶
- Dot product-এর ফলকে vector ভাবা — \((1,2)\cdot(3,4) = (3, 8)\) লেখা। ভুল! ওটা entry-wise গুণ (NumPy-র
a * b)। Dot product হলো তার যোগফলও: \(3 + 8 = 11\) — একটা সংখ্যা। a * bআরa @ bগুলিয়ে ফেলা — NumPy-তে*মানে entry-wise (ফল vector),@মানে inner product (ফল সংখ্যা)। ML কোডের অর্ধেক bug-এর জন্ম এখানে।- বড় dot product = বেশি মিল, সবসময় — না! লম্বা vector এমনিই বড় dot product দেয়। দিকের মিল চাইলে cosine similarity (নর্মালাইজ করা) ব্যবহার করো — Problem 8 দেখো, ranking বদলে গিয়েছিল।
- \(a^Tb = 0\) মানে "কোনো একটা zero" — মোটেই না; দুটো দিব্যি nonzero হয়েও লম্ব হতে পারে: \((3,-2) \perp (4,6)\)। Orthogonality একটা সম্পর্ক, শূন্যতা নয়।
- তিন vector-এর dot product লেখা — \(a^Tb^Tc\) ধরনের লেখা অর্থহীন। \((a^Tb)c\) (সংখ্যা \(\times\) vector \(c\)) আর \(a(b^Tc)\) (সংখ্যা \(\times\) vector \(a\)) — দুটো ভিন্ন vector; বন্ধনী জীবন বাঁচায়।
১০. এক নজরে¶
| ধারণা | সূত্র | ফল | মনে রাখার ছবি |
|---|---|---|---|
| Inner/Dot product | \(a^Tb = \sum_i a_i b_i\) | সংখ্যা | গুণ করে যোগ |
| Geometric রূপ | \(a^Tb = \|a\|\|b\|\cos\theta\) | সংখ্যা | দৈর্ঘ্য \(\times\) ছায়া |
| চিহ্ন | \(>0\) / \(=0\) / \(<0\) | — | acute / লম্ব / obtuse |
| Orthogonal | \(a^Tb = 0\) | — | \(\perp\), ছায়া নেই |
| নিজের সাথে | \(a^Ta = \|a\|^2 \ge 0\) | সংখ্যা | দৈর্ঘ্যের বর্গ |
| Cosine similarity | \(\frac{a^Tb}{\|a\|\|b\|} \in [-1,1]\) | সংখ্যা | শুধু দিকের মিল |
| গড় | \(\frac{1}{n}\mathbf{1}^Tx\) | সংখ্যা | ones-এর সাথে dot |
পরের chapter-এর সেতু: আজ বারবার \(\|a\|\) লিখেছি — "দৈর্ঘ্য" — কিন্তু সংজ্ঞা দিইনি (শুধু ফিসফিস করেছি: \(\sqrt{a^Ta}\))। পরের chapter-এ norm-কে আনুষ্ঠানিকভাবে গড়বো, distance মাপবো, আর অবাক হয়ে দেখবো পরিসংখ্যানের standard deviation-ও আসলে একটা norm!
📓 Notebook Project¶
notebooks/part-01/ch03-project.ipynb — Part I-এর flagship: ছোট্ট word-vector সেটে scratch-এ cosine similarity search engine — dot product নিজে লিখে, query দিয়ে শব্দ খুঁজে, similarity matrix-এর heatmap এঁকে।