Chapter 4.6 — Linear Map-এর Matrix (লিনিয়ার ম্যাপের ম্যাট্রিক্স): Abstract থেকে Concrete-এর শেষ সেতু¶
🎯 এই chapter-এ যা শিখবে¶
- এক প্রশ্নের জাদু: "প্রতিটা basis vector কোথায় যায়?" — শুধু এইটুকু জানলেই পুরো linear map জানা হয়ে যায়
- Matrix বানানোর সর্বজনীন রেসিপি: column \(j\) = \(j\)-তম basis vector-এর image-এর coordinates — \([L]^{B'}_{B}\) notation-সহ
- \([L(v)]_{B'} = M\,[v]_B\) — abstract map উপরতলায়, matrix-এর গুণ নিচতলায়: দুই পথে একই উত্তর
- একই map, ভিন্ন basis-এ ভিন্ন matrix — আর \(M' = P^{-1}MP\) সূত্রে সেই matrix-দের আত্মীয়তা
- Derivative-এর মতো "calculus-এর জিনিস"-ও কেমন করে একটা matrix হয়ে যায়
🖼️ এক ছবিতে মূল idea¶
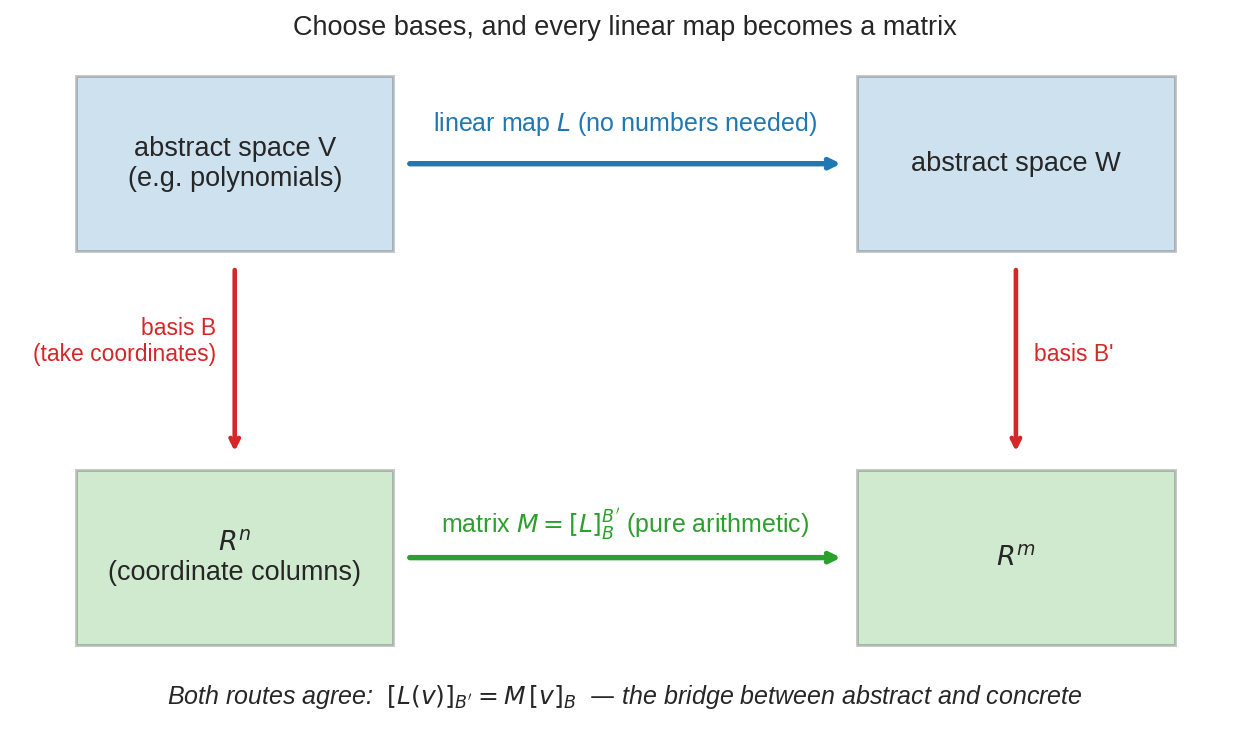
দোতলা বাড়ি: উপরতলায় abstract জগৎ — \(V\) থেকে \(W\)-তে linear map \(L\), কোনো সংখ্যা নেই। নিচতলায় concrete জগৎ — \(R^n\) থেকে \(R^m\)-এ matrix-এর গুণ, শুধুই সংখ্যা। Basis হলো দুই তলার সিঁড়ি — আর ছবির প্রতিশ্রুতি: যে পথেই যাও, উত্তর এক।**
১. কি? (What)¶
আগে concrete ছবি: দুটো প্রশ্নেই পুরো map ফাঁস¶
\(R^2\)-এর একটা linear map \(L\) ভাবো — ধরো কোনো ঘোরানো-টানানো মেশানো transformation, ভেতরের কারিগরি জানি না। আমি শুধু দুটো প্রশ্ন করব:
\(L(e_1)\) কত? — ধরো \((1, 0.5)\)। \(L(e_2)\) কত? — ধরো \((-1, 1.5)\)।
ব্যস, খেলা শেষ! এখন যেকোনো vector-এর ভাগ্য আমি বলে দিতে পারি। কেন? যেকোনো \(v = (x, y) = x\,e_1 + y\,e_2\), আর \(L\) linear:
দুই উত্তরকে পাশাপাশি বসালেই matrix! Linearity মানে map-টার স্বাধীনতা প্রায় নেই — basis vector-দের ওপর তার আচরণই তার সবটুকু। ছবিতে:
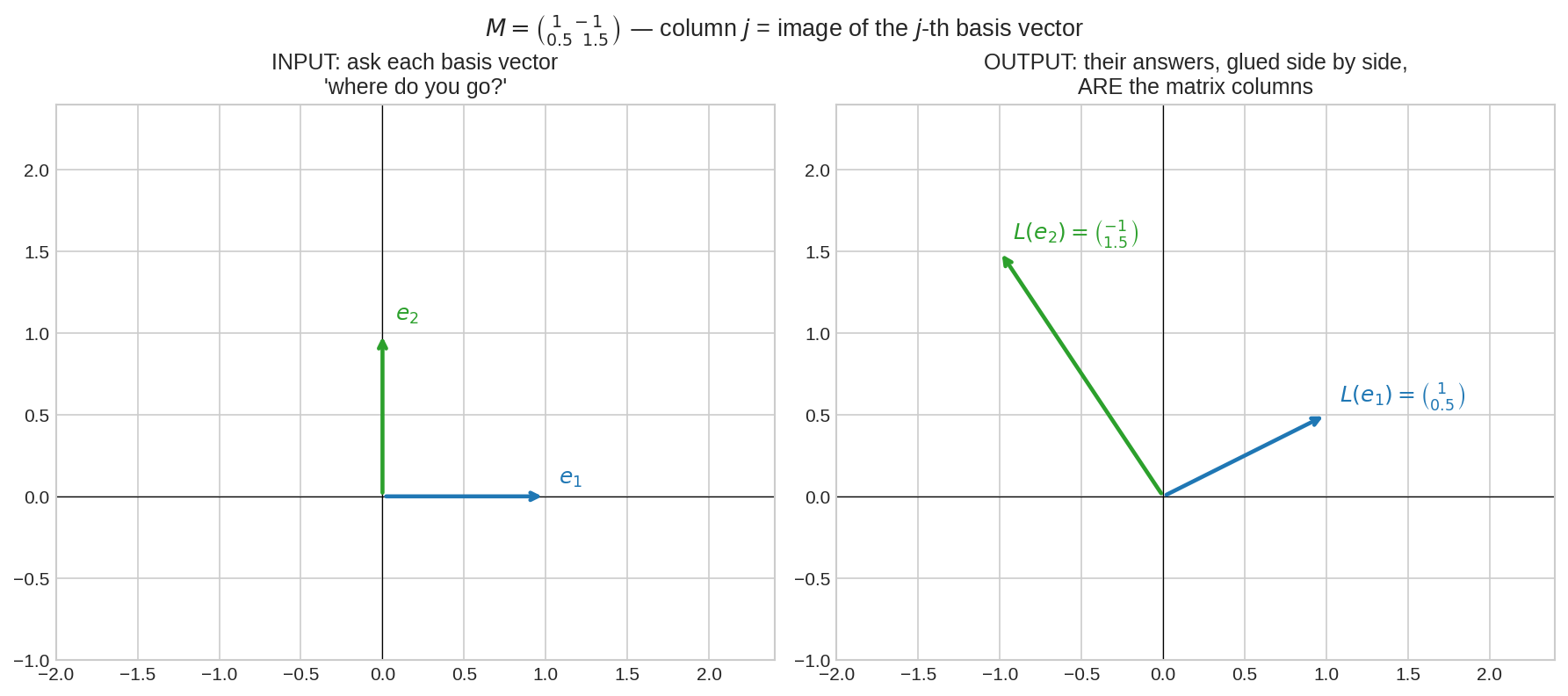
বাঁয়ে দুই basis vector প্রশ্ন শুনছে: "কোথায় যাও?" ডানে তাদের উত্তর — আর উত্তর দুটো পাশাপাশি সাজালেই matrix-এর দুই column। Matrix মানে: basis vector-দের গন্তব্যের তালিকা।**
দৈনন্দিন analogy: রেসিপির বই¶
একজন রাঁধুনির সব রান্না জানতে তার প্রতিটা রান্না চেখে দেখতে হয় না — মূল উপকরণগুলো সে কীভাবে সামলায় জানলেই আন্দাজ মেলে। Linear map-এর বেলায় আন্দাজ নয়, একদম নিখুঁত হিসাব: basis vector-রাই মূল উপকরণ, আর বাকি সব vector তাদের combination — তাই map-এর পুরো "রেসিপির বই" হলো ওই ছোট্ট টেবিলটা: কোন basis vector কোথায় যায়। সেই টেবিলের নামই matrix।
Formal সংজ্ঞা — এবার যেকোনো vector space-এ¶
উপরের গল্পটা \(R^2\)-তে standard basis দিয়ে; আসল শক্তি দেখা যায় abstract জগতে। \(L : V \to W\) linear, input basis \(B = (b_1, \ldots, b_n)\), output basis \(B' = (b'_1, \ldots, b'_m)\)।
সংজ্ঞা: Linear Map-এর Matrix
প্রতিটি \(L(b_j)\) তো \(W\)-এর সদস্য — তাই তাকে \(B'\)-তে অনন্যভাবে লেখা যায় (Chapter 4.3-এর uniqueness):
এই সংখ্যাগুলো সাজিয়ে পাওয়া \(m \times n\) matrix \(M = (m_{ij})\)-কে বলে \(B, B'\) basis-এ \(L\)-এর matrix, লেখা হয় \([L]^{B'}_{B}\)। Column-এর নিয়ম: \(j\)-তম column \(= [L(b_j)]_{B'}\) — \(j\)-তম input-basis-vector-এর image-এর output-ভাষার coordinates।
আর কেন্দ্রীয় সূত্র — দোতলার প্রতিশ্রুতি:
The Bridge Equation
সব \(v \in V\)-এর জন্য:
বাংলায়: উপরতলায় \(L\) চালানো \(=\) নিচতলায় matrix গুণ। Abstract প্রশ্ন ঢোকাও coordinates-এ, matrix গুণ করো, উত্তরকে আবার abstract-এ পড়ো।
মিনি-derivation: \(v = c_1 b_1 + \cdots + c_n b_n\) হলে linearity-তে \(L(v) = \sum_j c_j L(b_j)\); প্রতিটা \(L(b_j)\)-এর জায়গায় তার \(B'\)-বিস্তার বসাও আর \(b'_i\)-প্রতি coefficient গোছাও — \(i\)-তম coefficient দাঁড়ায় \(\sum_j m_{ij} c_j\), যেটা ঠিক \(M[v]_B\)-এর \(i\)-তম entry। \(\blacksquare\)
২. দেখতে কেমন?¶
Derivative — একটা "calculus-যন্ত্র"-এর matrix-রূপ¶
সবচেয়ে চমকপ্রদ উদাহরণ arrow-জগতের বাইরে। \(L = \frac{d}{dt} : P_2 \to P_2\), basis \(B = B' = (1, t, t^2)\)। Column-এর নিয়ম প্রয়োগ করো — প্রতি basis vector-কে জিজ্ঞেস করো "derivative কত?":
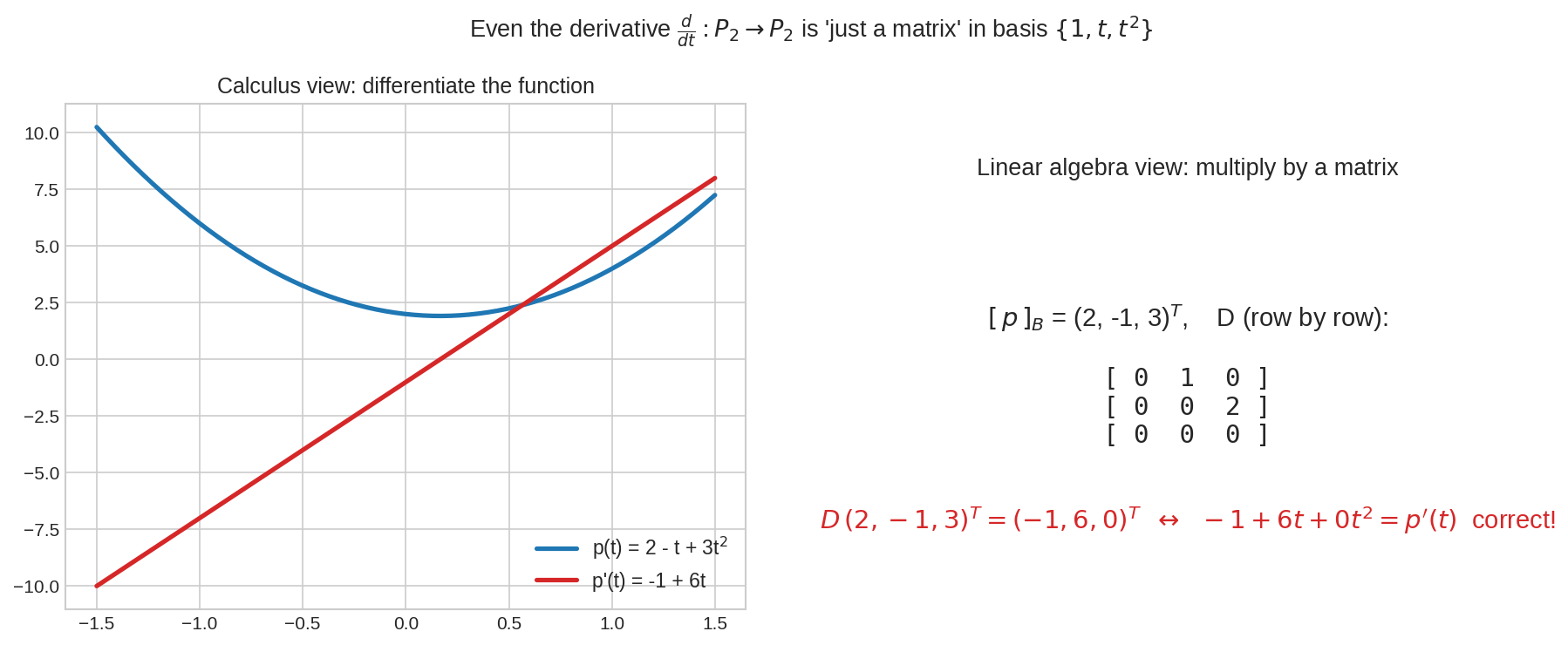
বাঁয়ে calculus-এর চোখ: \(p(t) = 2 - t + 3t^2\) থেকে \(p'(t) = -1 + 6t\) — curve-এর ঢাল। ডানে linear algebra-র চোখ: \([p]_B = (2, -1, 3)\)-কে \(D\) দিয়ে গুণ, ফল \((-1, 6, 0)\) — মানে \(-1 + 6t\)। একই কাজ, দুই ভাষা। Differentiation যন্ত্রটাও basis পরলে নেহাত একটা সংখ্যার টেবিল।
যাচাই করে দেখো: \(D\begin{pmatrix}2\\-1\\3\end{pmatrix} = \begin{pmatrix}-1\\6\\0\end{pmatrix}\) ✓ — Chapter 4.5-এর Problem 3-এ এই map-এরই kernel-range বের করেছিলে; আজ পেলে তার পুরো শরীর।
Composition = matrix গুণ — পুরনো রহস্যের সমাধান¶
Part I-এ মেনে নিয়েছিলে matrix multiplication-এর অদ্ভুত নিয়মটা। আজ কারণটা এক লাইনে: \(L_2 \circ L_1\)-এর matrix \(= M_2 M_1\) — পরপর দুই map চালানোর টেবিল হিসাব করলে ঠিক matrix গুণের সূত্রটাই বেরিয়ে আসে। Matrix multiplication ওরকম "প্যাঁচানো" কারণ সে function composition-এর ছায়া — এটা design, দুর্ঘটনা নয়।
৩. কোথায় ইউজ হয়?¶
- Computer graphics-এর প্রাণ: ঘোরানো, scale, ছায়া ফেলা — game engine-এ প্রতিটা transformation জমা থাকে matrix হিসেবে; কেন? কারণ শুধু basis vector-দের গন্তব্য রাখলেই চলে, আর composition মানে আগে থেকে গুণ করে রাখা এক matrix — লক্ষ frame-এ দ্রুত।
- Deep learning-এর layer:
nn.Linear(784, 128)মানে আক্ষরিকভাবে \([L]^{B'}_{B}\) — একটা শেখা-যায় এমন linear map-এর matrix (\(+\) bias); train করা মানে সেই matrix-এর entries বদলানো। - Fourier transform: "signal থেকে frequency" — এটাও এক linear map, আর FFT হলো চালাক basis-এ তার matrix-গুণ দ্রুত করার কৌশল; পুরো signal processing এই এক matrix-এর সাম্রাজ্য।
- Derivative/Integral solver: কম্পিউটারে differential equation solve করার spectral method: function-কে polynomial/sine basis-এ লিখে derivative-কে উপরের \(D\)-এর মতো matrix বানিয়ে ফেলা — calculus-এর সমস্যা linear system হয়ে যায়।
- Robotics-এর Jacobian: জয়েন্টের কোণ থেকে হাতের ডগার অবস্থান — nonlinear, কিন্তু প্রতিটা মুহূর্তে তার সেরা linear approximation একটা matrix (Jacobian); রোবট নড়ে সেই matrix-এর হিসাবে।
- Quantum mechanics: observable মানেই একটা linear operator, আর measurement-এর হিসাব চলে বেছে-নেওয়া basis-এ তার matrix দিয়ে — "matrix mechanics" নামটা ওখান থেকেই।
৪. Properties¶
Property 1: রেসিপিটা দুই দিকেই চলে (map ↔ matrix)¶
Basis ঠিক করা থাকলে প্রতিটা linear map \(L : V \to W\) একটা অনন্য \(m \times n\) matrix পায় — আর প্রতিটা \(m \times n\) matrix-ও একটা অনন্য linear map সংজ্ঞা করে। এক-এক মিল (bijection): linear map-দের জগৎ আর matrix-দের জগৎ, basis-চুক্তির নিচে, একই জিনিস। এই জন্যই Part I–III-তে "matrix = transformation" বলে পার পেয়ে গেছি — চুক্তিটা ছিল standard basis।
Property 2: Map-এর যোগ-scale = matrix-এর যোগ-scale¶
\([L_1 + L_2] = [L_1] + [L_2]\), \([cL] = c[L]\) — অনুবাদটা linear structure-ও রক্ষা করে। (ফলে linear map-রা নিজেরাই একটা vector space বানায় — \(\dim = mn\); চাইলে Problems-এর পরে ভেবে দেখো!)
Property 3: Composition \(\mapsto\) গুণ, identity \(\mapsto\) \(I\), inverse \(\mapsto\) inverse¶
শেষটার মানে গভীর: \(L\) invertible (bijective) \(\iff\) তার matrix invertible — Chapter 4.5-এর "kernel \(=\{0\}\) + onto" শর্ত matrix-ভাষায় \(\det \ne 0\) হয়ে যায়। সব সুতো এক গিঁটে।
Property 4: Basis বদলালে matrix বদলায় — নিয়ম মেনে¶
একই \(L : V \to V\), দুই basis \(S\) (পুরনো) আর \(S'\) (নতুন), change of basis matrix \(P\) (Chapter 4.4):
Derivation তিন লাইনে: নতুন-ভাষার input \([v]_{S'}\) নাও। (১) পুরনো ভাষায় অনুবাদ: \(P[v]_{S'}\)। (২) পুরনো টেবিলে কাজ: \(MP[v]_{S'}\)। (৩) উত্তর নতুন ভাষায় ফেরত: \(P^{-1}MP[v]_{S'}\)। এই তিন-ধাপ যন্ত্রটা পুরোটাই "নতুন ভাষায় \(L\)" — তাই \(M' = P^{-1}MP\)। \(\blacksquare\)
এমন \(M' = P^{-1}MP\) সম্পর্কের matrix-দের বলে similar(সদৃশ) — তারা আসলে একই map-এর দুই পোশাক। (Input–output ভিন্ন basis হলে সাধারণ রূপ: \(M' = Q^{-1}MP\)।)
Property 5: চালাক basis-এ matrix সরল — সামনে যা আসছে তার trailer¶
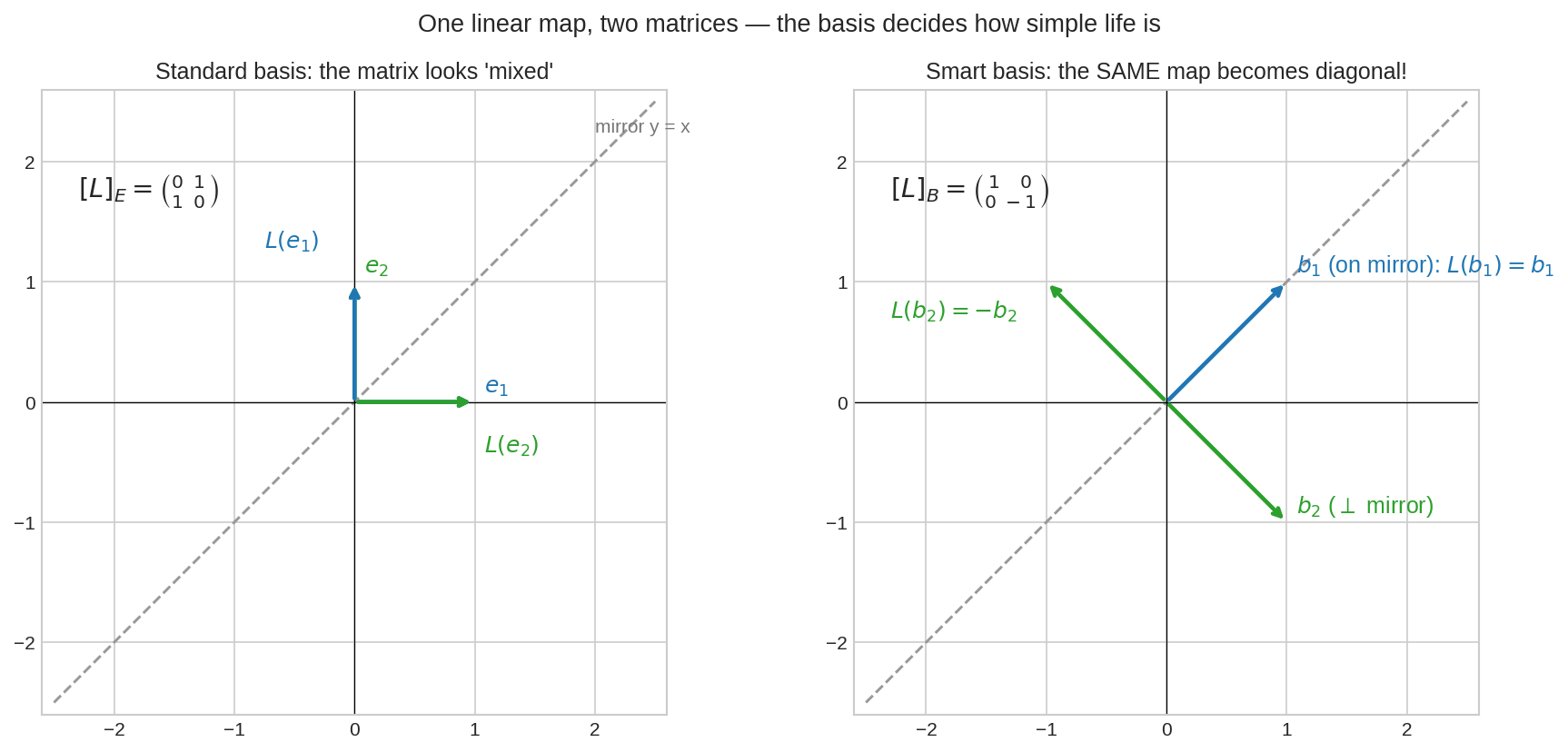
আয়নার map (reflection, আয়না \(y = x\)): standard basis-এ matrix \(\begin{pmatrix}0&1\\1&0\end{pmatrix}\) — ঘোলাটে, কি করে বোঝা যায় না। কিন্তু আয়নার নিজের basis-এ — \(b_1\) আয়নার ওপর (\(L(b_1) = b_1\)), \(b_2\) আয়নার লম্বে (\(L(b_2) = -b_2\)) — matrix হয়ে যায় \(\begin{pmatrix}1&0\\0&-1\end{pmatrix}\): diagonal! পড়েই বোঝা যায়: এক দিক অটুট, এক দিক উল্টে যায়।
Rank, determinant, trace — এসব similar matrix-দের মধ্যে বদলায় না (এরা map-এর ধর্ম, পোশাকের নয়)। আর "কোন basis-এ matrix diagonal হয়?" — এই এক প্রশ্নের নামই eigenvector theory, Part VI-এর পুরোটা।
৫. Intuition — কেন সত্য?¶
কেন basis vector-রাই যথেষ্ট — শেষবারের মতো, গভীরভাবে। Linear map-এর দুটো মাত্র প্রতিজ্ঞা: \(L(u + v) = L(u) + L(v)\) আর \(L(cv) = cL(v)\)। এই দুই প্রতিজ্ঞা তাকে grid-রক্ষক বানিয়ে দেয়: origin ঠিক থাকে, সমান্তরাল রেখা সমান্তরাল থাকে, সমান ভাগ সমান থাকে। তাহলে গোটা গ্রিডের ভাগ্য ঝুলে থাকে শুধু গ্রিডের কঙ্কালের — basis vector-দের — ওপর। তারা কোথায় গেল বলো, বাকি গ্রিড নিজে নিজেই টানটান হয়ে বসে যাবে। 3Blue1Brown-এর ভাষায়: linear transformation দেখতে চাও? শুধু দেখো \(\hat{i}\) আর \(\hat{j}\) কোথায় নামল — ওই দুই arrow-ই পুরো সিনেমা।
দোতলা বাড়ির ছবিটা কেন এত দামি। উপরতলায় থাকে অর্থ — polynomial, signal, ছবি, probability distribution: যেসব জিনিস নিয়ে সত্যিই মাথা ঘামাই। নিচতলায় থাকে হিসাব — float-এর array, GPU-র গুণ। Bridge equation \([L(v)]_{B'} = M[v]_B\) প্রতিশ্রুতি দেয়: নিচতলায় হিসাব করে উপরতলার সত্য পাওয়া যায় — একটুও তথ্য না হারিয়ে। Computer কোনোদিন polynomial "বোঝে না" — সে \((2, -1, 3)\) আর \(D\)-এর গুণ জানে; তবু তার উত্তর calculus-এর উত্তরের সাথে হুবহু মেলে। পুরো computational science এই এক বিশ্বাসের ওপর দাঁড়িয়ে।
আর \(P^{-1}MP\)-এর sandwich-টা? ভাবো তুমি ইংরেজি জানো, দলিলটা বাংলায় (\(M\) কাজ করে পুরনো ভাষায়)। কি করবে? বাংলায় অনুবাদ করো (\(P\)), দলিলের কাজ সারো (\(M\)), ফলাফল ইংরেজিতে ফিরিয়ে নাও (\(P^{-1}\))। Sandwich-এর তিন স্তর তিনটে সৎ ধাপ — মুখস্থের কিছুই নেই। আর এই sandwich-ই বলে দেয় কেন "ভালো basis খোঁজা" এত বড় শিল্প: \(M\) যত কুৎসিতই হোক, চালাক \(P\) বেছে \(P^{-1}MP\)-কে diagonal বানাতে পারলে সব হিসাব পানি হয়ে যায়।
৬. Code-এ কেমনে লিখে¶
Column-এর রেসিপি সরাসরি কোডে — derivative-matrix বানানো, bridge equation যাচাই, আর basis বদলের sandwich:
import numpy as np
np.random.seed(42)
# ---- ধাপ ১: basis-এর image থেকে matrix (column-এর নিয়ম) ----
# L = d/dt : P2 -> P2, basis (1, t, t^2)
# L(1) = 0, L(t) = 1, L(t^2) = 2t — image-দের coordinates column-এ বসাও
D = np.column_stack([
[0, 0, 0], # [L(1)]_B = 0
[1, 0, 0], # [L(t)]_B = 1
[0, 2, 0], # [L(t^2)]_B = 2t
]).astype(float)
print("D =\n", D)
# ---- ধাপ ২: bridge equation — p(t) = 2 - t + 3t^2 ----
p = np.array([2.0, -1.0, 3.0]) # [p]_B
dp = D @ p
print("[p']_B =", dp, " অর্থাৎ p'(t) = -1 + 6t")
# calculus-এর সাথে মিলিয়ে দেখা (সংখ্যায়):
t = 0.7
manual = -1 + 6 * t # matrix-পথের উত্তর বসিয়ে
exact = np.polyval(np.polyder([3, -1, 2]), t) # খাঁটি calculus
print("t=0.7-এ:", manual, "vs", exact)
# ---- ধাপ ৩: sandwich M' = P^{-1} M P — আয়নার map ----
M = np.array([[0.0, 1.0], [1.0, 0.0]]) # reflection, standard basis
P = np.column_stack([[1.0, 1.0], [1.0, -1.0]]) # smart basis: আয়নার নিজের দিক
M_new = np.linalg.solve(P, M @ P) # P^{-1} (M P)
print("smart basis-এ matrix:\n", M_new)
# invariant-রা বদলায়নি তো?
for name, f in [("det", np.linalg.det), ("trace", np.trace),
("rank", np.linalg.matrix_rank)]:
print(f"{name}: {f(M):.1f} == {f(M_new):.1f}")
Output:
D =
[[0. 1. 0.]
[0. 0. 2.]
[0. 0. 0.]]
[p']_B = [-1. 6. 0.] অর্থাৎ p'(t) = -1 + 6t
t=0.7-এ: 3.2 vs 3.2
smart basis-এ matrix:
[[ 1. 0.]
[ 0. -1.]]
det: -1.0 == -1.0
trace: 0.0 == 0.0
rank: 2.0 == 2.0
ব্যাখ্যা: (১) np.column_stack-এ image-দের বসানো — এটাই column-এর নিয়মের আক্ষরিক অনুবাদ; (২) matrix-পথ আর polyder-এর calculus-পথ \(t = 0.7\)-এ হুবহু মিলল — দোতলার প্রতিশ্রুতি রাখা হলো; (৩) sandwich-এর পর আয়নার matrix diagonal — আর det, trace, rank অটুট: matrix বদলাল, map বদলায়নি।
৭. Worked Examples¶
Example 1: বর্ণনা থেকে matrix¶
\(L : R^3 \to R^2\), \(L(x, y, z) = (x + 2y - z,\; 3z - y)\)। Standard basis-এ matrix লেখো।
ধাপ ১ (তিন প্রশ্ন):
ধাপ ২ (column-এ সাজাও):
যাচাই: \(M(x, y, z)^T = (x + 2y - z,\; -y + 3z)^T\) ✓ — সমীকরণের coefficient-রাই সারি সারি বসে গেছে। Shortcut: বর্ণনা linear হলে matrix পড়ে ফেলা যায়; কিন্তু রেসিপিটা জানা জরুরি — কারণ পরের উদাহরণে shortcut অচল।
Example 2: Abstract জগতে, non-standard basis-এ¶
\(L : P_1 \to P_1\), \(L(p)(t) = p(t) + t\,p'(t)\); basis \(B = (1 + t,\; 1 - t)\) (input ও output দুটোই)। \([L]_B\) বের করো।
ধাপ ১ (প্রথম basis vector): \(p = 1 + t\): \(p' = 1\), তাই \(L(p) = (1 + t) + t = 1 + 2t\)। এবার \(1 + 2t\)-কে \(B\)-তে লেখো: \(c_1(1+t) + c_2(1-t) = (c_1 + c_2) + (c_1 - c_2)t\)। চাই \(c_1 + c_2 = 1\), \(c_1 - c_2 = 2\) — solve: \(c_1 = \frac32\), \(c_2 = -\frac12\)। কাজেই প্রথম column \(= (\frac32, -\frac12)\)।
ধাপ ২ (দ্বিতীয়): \(p = 1 - t\): \(p' = -1\), \(L(p) = (1 - t) - t = 1 - 2t\)। একইভাবে: \(c_1 + c_2 = 1\), \(c_1 - c_2 = -2\) — \(c_1 = -\frac12\), \(c_2 = \frac32\)। দ্বিতীয় column \(= (-\frac12, \frac32)\)।
উত্তর: \([L]_B = \begin{pmatrix} 3/2 & -1/2 \\ -1/2 & 3/2 \end{pmatrix}\)।
যাচাই (bridge দিয়ে): \(p(t) = 2t = 1\cdot(1+t) + (-1)\cdot(1-t)\), মানে \([p]_B = (1, -1)\)। Matrix-পথ: \([L(p)]_B = (3/2 + 1/2,\; -1/2 - 3/2) = (2, -2)\), অর্থাৎ \(2(1+t) - 2(1-t) = 4t\)। সরাসরি-পথ: \(L(2t) = 2t + t \cdot 2 = 4t\) ✓ — দোতলার দুই পথ মিলল।
Example 3: Sandwich হাতে-কলমে¶
\(M = \begin{pmatrix} 3 & 1 \\ 0 & 2 \end{pmatrix}\) (standard basis-এ)। নতুন basis \(S' = ((1, 0), (1, -1))\)-তে একই map-এর matrix \(M'\) বের করো।
ধাপ ১: \(P = \begin{pmatrix} 1 & 1 \\ 0 & -1 \end{pmatrix}\); \(\det P = -1\), \(P^{-1} = \begin{pmatrix} 1 & 1 \\ 0 & -1 \end{pmatrix}\) (নিজেই নিজের inverse — চেক করো!)।
ধাপ ২: \(MP = \begin{pmatrix} 3 & 1 \\ 0 & 2 \end{pmatrix}\begin{pmatrix} 1 & 1 \\ 0 & -1 \end{pmatrix} = \begin{pmatrix} 3 & 2 \\ 0 & -2 \end{pmatrix}\)।
ধাপ ৩: \(M' = P^{-1}(MP) = \begin{pmatrix} 1 & 1 \\ 0 & -1 \end{pmatrix}\begin{pmatrix} 3 & 2 \\ 0 & -2 \end{pmatrix} = \begin{pmatrix} 3 & 0 \\ 0 & 2 \end{pmatrix}\) — diagonal!
মানে: \(S'\)-এর দুই vector আসলে এই map-এর "নিজস্ব দিক" — প্রথমটা \(3\) গুণ, দ্বিতীয়টা \(2\) গুণ হয়, দিক বদলায় না। যাচাই: \(M(1,0)^T = (3,0)^T = 3(1,0)^T\) ✓, \(M(1,-1)^T = (2,-2)^T = 2(1,-1)^T\) ✓। এই "নিজস্ব দিক"-দেরই নাম eigenvector — Part VI দরজায় কড়া নাড়ছে।
৮. Problems ও Solutions¶
Problem 1. \(L : R^2 \to R^3\), \(L(x, y) = (2x - y,\; x,\; x + y)\)। (ক) Standard basis-এ matrix লেখো। (খ) সেই matrix দিয়ে \(L(3, 1)\) বের করে সরাসরি হিসাবের সাথে মেলাও।
Solution
(ক) \(L(e_1) = (2, 1, 1)\), \(L(e_2) = (-1, 0, 1)\) — column-এ:
(খ) \(M(3, 1)^T = (6 - 1,\; 3,\; 3 + 1)^T = (5, 3, 4)^T\)। সরাসরি: \(L(3,1) = (6 - 1, 3, 3 + 1) = (5, 3, 4)\) ✓ — দুই পথ, এক উত্তর।
Problem 2. \(T : P_2 \to P_2\), \(T(p)(t) = p(t + 1)\) ("এক ঘর বাঁয়ে সরানো")। Basis \((1, t, t^2)\)-তে \(T\)-এর matrix বের করো। Matrix-টা invertible কি? মানে কি?
Solution
তিন প্রশ্ন: \(T(1) = 1 \mapsto (1, 0, 0)\); \(T(t) = t + 1 \mapsto (1, 1, 0)\); \(T(t^2) = (t+1)^2 = 1 + 2t + t^2 \mapsto (1, 2, 1)\)।
Upper-triangular, diagonal-এ সব \(1\) — \(\det = 1 \ne 0\): invertible। মানে পরিষ্কার: সরানো জিনিস ফেরত সরানো যায় — \(T^{-1}(p)(t) = p(t - 1)\); তার matrix হবে \([T]^{-1}\) (entries-এ \(-1, 1\)-এর নকশা — বের করে মিলিয়ে দেখো!)। লক্ষ করো Chapter 4.4-এর Problem 7-এর Taylor-shift এখানে map হয়ে ফিরে এলো।
Problem 3. \(L : R^2 \to R^2\)-এর জানা আছে: \(L(1, 1) = (2, 4)\) এবং \(L(1, -1) = (0, 2)\)। Standard basis-এ \(L\)-এর matrix বের করো। (Hint: আগে \(L(e_1), L(e_2)\) বের করো — linearity দিয়ে।)
Solution
\(e_1 = \frac{(1,1) + (1,-1)}{2}\), তাই linearity:
\(e_2 = \frac{(1,1) - (1,-1)}{2}\):
যাচাই: \([L](1,1)^T = (2, 4)^T\) ✓, \([L](1,-1)^T = (0, 2)^T\) ✓। শিক্ষা: যেকোনো এক basis-এর ওপর আচরণ জানলেই map পুরো নির্ধারিত — standard হওয়া জরুরি না; শুধু অনুবাদটুকু নিজে করতে হয়।
Problem 4. আয়নার map: \(R^2\)-এ \(x\)-axis-এ reflection (\(L(x, y) = (x, -y)\))। (ক) Standard basis-এ matrix। (খ) Basis \(S' = ((1, 1), (1, -1))\)-তে \(M' = P^{-1}MP\) বের করো। (গ) \(M'\) দেখে কি বোঝা গেল যেটা \(M\) দেখে বোঝা যাচ্ছিল?
Solution
(ক) \(L(e_1) = (1, 0)\), \(L(e_2) = (0, -1)\): \(M = \begin{pmatrix} 1 & 0 \\ 0 & -1 \end{pmatrix}\) — এবার standard-এই diagonal, কারণ আয়নাটা (\(x\)-axis) standard দিকেই শুয়ে আছে! (খ) \(P = \begin{pmatrix} 1 & 1 \\ 1 & -1 \end{pmatrix}\), \(P^{-1} = \begin{pmatrix} 1/2 & 1/2 \\ 1/2 & -1/2 \end{pmatrix}\)।
(গ) উল্টো শিক্ষা! এবার নতুন basis-এ matrix ঘোলাটে হলো — কারণ \(S'\)-এর vector-রা আয়নার সাথে \(45°\) কোণে। fig03-এর সাথে মেলাও: সেখানে আয়না ছিল \(y = x\), তাই \((1,1), (1,-1)\)-ই ছিল smart basis। কোন basis "ভালো" তা map-এর ওপর নির্ভর করে — সব map-এর এক সার্বজনীন ভালো basis নেই; প্রত্যেকের নিজেরটা খুঁজে দিতে হয় (Part VI-এর কাজ)।
Problem 5. প্রমাণ করো: similar matrix-দের (\(M' = P^{-1}MP\)) determinant সমান, trace-ও সমান। (Trace-এর জন্য ব্যবহার করতে পারো: \(\operatorname{tr}(AB) = \operatorname{tr}(BA)\)।)
Solution
Determinant: Part III-এর গুণ-নিয়ম \(\det(AB) = \det A \det B\):
Trace: \(\operatorname{tr}(M') = \operatorname{tr}\big(P^{-1}(MP)\big) = \operatorname{tr}\big((MP)P^{-1}\big) = \operatorname{tr}(M)\)। \(\blacksquare\) মানে: det আর trace আসলে map-এর ধর্ম — কোন চশমায় দেখছ তাতে কিছু আসে-যায় না। এই জন্যই det-এর জ্যামিতিক মানে (আয়তনের গুণক) basis-নিরপেক্ষভাবে সত্য; আর এই জন্যই Part VI-এ eigenvalue-রা (যাদের যোগফল trace, গুণফল det) basis-নিরপেক্ষ হবে।
Problem 6. \(L : P_2 \to R^2\), \(L(p) = \big(p(0),\; p(1)\big)\) ("দুই জায়গায় মান পড়া")। Basis: input-এ \((1, t, t^2)\), output-এ standard। (ক) Matrix লেখো। (খ) Kernel বের করো। (গ) Rank–nullity মিলাও (Chapter 4.5-এর সাথে হাত মেলানো)।
Solution
(ক) \(L(1) = (1, 1)\), \(L(t) = (0, 1)\), \(L(t^2) = (0, 1)\):
(খ) \(Mx = 0\): প্রথম সারি \(a_0 = 0\); দ্বিতীয় সারি \(a_0 + a_1 + a_2 = 0 \Rightarrow a_2 = -a_1\)। Kernel \(= \operatorname{span}\{t - t^2\}\) — অর্থাৎ যেসব polynomial \(0\) আর \(1\) দুই জায়গাতেই শূন্য (যাচাই: \(p(t) = t - t^2 = t(1 - t)\)-এর মূল ঠিক \(0\) ও \(1\)! ✓)। (গ) rank \(= 2\) (দুটো pivot), nullity \(= 1\); \(2 + 1 = 3 = \dim P_2\) ✓। দেখো তিন chapter এক টেবিলে: matrix বানালাম (4.6), kernel পড়লাম (4.5), dimension গুনলাম (4.4)।
Problem 7 (challenge). \(L : V \to V\) linear, আর ধরো এমন basis \(B = (b_1, \ldots, b_n)\) আছে যেখানে প্রতিটা \(b_i\)-এর জন্য \(L(b_i) = \lambda_i b_i\) (নিজের দিকেই থাকে, \(\lambda_i\) গুণ হয়)। প্রমাণ করো \([L]_B\) diagonal, আর দেখাও \(L^k\) (\(k\) বার \(L\))-এর matrix হিসাব করা তখন কত সোজা।
Solution
Diagonal: column-এর নিয়ম: \(j\)-তম column \(= [L(b_j)]_B = [\lambda_j b_j]_B = (0, \ldots, \lambda_j, \ldots, 0)\) — \(j\)-তম ঘরে \(\lambda_j\), বাকি শূন্য। সব column মিলে:
Power: Property 3 মতে \([L^k]_B = ([L]_B)^k = \operatorname{diag}(\lambda_1^k, \ldots, \lambda_n^k)\) — matrix-এর power নেমে এলো সংখ্যার power-এ! \(100\) ধাপের Markov chain, Fibonacci-র \(1000\)তম পদ — সব এই কৌশলে সোজা হয়ে যায়। এমন জাদুকরী basis (\(L(b_i) = \lambda_i b_i\)) কোথায় পাব, সবসময় পাওয়া যায় কি না — এই দুই প্রশ্নই Part VI-এর সূচিপত্র। Part IV তোমাকে দরজা পর্যন্ত পৌঁছে দিল।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ ঠিক ধারণা |
|---|---|
| "Matrix-ই হলো linear map" | Matrix হলো নির্দিষ্ট basis-চুক্তিতে map-এর বর্ণনা; basis বদলালে matrix বদলায়, map বদলায় না — বাসা আর ঠিকানার গল্পটাই আবার |
| "Matrix-এর row \(j\) = \(L(b_j)\)-এর coordinates" | Column \(j\) — column, column, column! \(L(b_j)\)-এর coordinates খাড়াভাবে বসে; row ভাবলে সব হিসাব transpose হয়ে ভুল হবে |
| "\(M' = PMP^{-1}\) নাকি \(P^{-1}MP\) — যেকোনো একটা লিখলেই হয়" | দিক আছে: \(P\) অনুবাদ করে নতুন→পুরনো, তাই নতুন-ভাষার যন্ত্র \(= P^{-1}MP\); উল্টো লিখলে আসলে উল্টো দিকের বদল হয়ে যায় — sandwich-এর তিন ধাপ মনে করো |
| "Non-standard basis-এ matrix বানানো একটা আলাদা, কঠিন theory" | রেসিপি একটাই: basis vector-দের image নাও, output basis-এর ভাষায় লেখো, column-এ বসাও — standard হোক বা polynomial, এক নিয়ম |
| "\(L(e_1)\) আর \(L(e_2)\) জানা মানে মোটে দুটো point জানা — এত অল্পে পুরো map?" | Linearity-ই বাকি সব টেনে দেয়: প্রতিটা input basis-দের combination, তাই প্রতিটা output-ও image-দের সেই একই combination — এটাই linear হওয়ার পুরো মানে |
১০. এক নজরে¶
| ধারণা | এক লাইনে |
|---|---|
| মূল রেসিপি | Column \(j = [L(b_j)]_{B'}\) — basis vector-দের গন্তব্যের তালিকাই matrix |
| Bridge equation | \([L(v)]_{B'} = [L]^{B'}_{B}[v]_B\) — উপরতলার map \(=\) নিচতলার গুণ |
| Composition | \([L_2 \circ L_1] = [L_2][L_1]\) — matrix গুণের নিয়মের জন্মরহস্য |
| Basis বদল | \(M' = P^{-1}MP\) — sandwich: অনুবাদ, কাজ, ফেরত-অনুবাদ |
| Similar matrices | \(P^{-1}MP\)-সম্পর্কিত matrix-রা একই map-এর ভিন্ন পোশাক; det, trace, rank অটুট |
| চালাক basis | Map-এর নিজস্ব দিক ধরলে matrix diagonal — হিসাব সংখ্যার power-এ নামে |
| বড় ছবি | Abstract-এ ভাবো, basis বেছে concrete-এ গুণ করো, উত্তর abstract-এ পড়ো |
পরের Part-এর সেতু: Part IV সম্পূর্ণ — তুমি এখন জানো vector space কি (4.1), কারা independent (4.2), basis ও coordinates (4.3), dimension আর চশমা বদল (4.4), map-এর kernel-range-rank (4.5), আর map ↔ matrix সেতু (4.6)। কিন্তু একটা জিনিস এখনো নেই: দৈর্ঘ্য আর কোণ। কোন vector "বড়", কারা "লম্ব" — vector space-এর কঙ্কালে এবার মাংস চড়বে: inner product, orthogonality, projection — Part V শুরু হচ্ছে।
📓 Notebook Project¶
notebooks/part-04/ch06-project.ipynb — "Matrix Factory" বানাবে: যেকোনো linear map + basis দিলে column-রেসিপিতে matrix বানানো function, derivative-matrix দিয়ে polynomial-এর calculus, sandwich \(P^{-1}MP\)-এর যাচাই, আর diagonal-হয়ে-যাওয়া map-এর ছবি।