Chapter 8.2 — Solving Ax = b in Practice (বাস্তবে \(Ax = b\) সমাধান — LU / QR / Cholesky, complexity, sparse matrix)¶
Part I থেকে এতদিন আমরা \(Ax = b\) সমাধান করেছি একটাই মন্ত্রে: "\(x = A^{-1}b\)"। কাগজে সুন্দর, কিন্তু কম্পিউটারে এটা প্রায় সবসময় ভুল অভ্যাস — ধীর, অপচয়ী, আর কখনো বিপজ্জনকভাবে ভুল। আজ শিখবে পেশাদাররা আসলে কী করে: matrix-টাকে একবার সহজ টুকরোয় ভেঙে (factor করে) রাখা, তারপর যতবার দরকার সেই টুকরো দিয়ে দ্রুত সমাধান টেনে নেওয়া। কোন সমস্যায় কোন factorization — LU(এলইউ), QR(কিউআর), নাকি Cholesky(কোলেস্কি) — সেটা বাছাই করাই একজন numerical linear algebra জানা মানুষের আসল দক্ষতা। আর যখন matrix বিশাল কিন্তু বেশিরভাগ ঘর শূন্য (sparse), তখন এই বাছাই ভুল হলে ল্যাপটপ জমে যায়, ঠিক হলে সেকেন্ডে উত্তর আসে। Chapter 8.1-এ শিখেছো conditioning কীভাবে ভুল বড় করে; এবার শিখবে কীভাবে সেই ভুল কমিয়ে দ্রুত সমাধান করা যায়।
🎯 এই chapter-এ যা শিখবে¶
- কেন
inv(A)কখনো নয় — বরং factor + substitute: matrix ভেঙে ত্রিভুজাকার টুকরোয়, তারপর দ্রুত সমাধান - LU Decomposition(এলইউ ডিকম্পোজিশন) \(PA = LU\) — Gaussian elimination-এর স্মৃতি ধরে রাখা, খরচ \(\sim \frac{2}{3}n^3\)
- Cholesky Decomposition(কোলেস্কি ডিকম্পোজিশন) \(A = LL^T\) — symmetric positive definite matrix-এর জন্য অর্ধেক খরচে (\(\sim \frac{1}{3}n^3\)) সমাধান
- QR Decomposition(কিউআর ডিকম্পোজিশন) \(A = QR\) — লম্বা (tall) system আর least squares-এর নিরাপদ পথ, খরচ \(\sim 2mn^2\)
- Complexity(কমপ্লেক্সিটি) পড়া (\(n^3\)-এর অর্থ), আর Sparse Matrix(স্পার্স ম্যাট্রিক্স)-এ fill-in এড়িয়ে বিশাল system সমাধান
🖼️ এক ছবিতে মূল idea¶
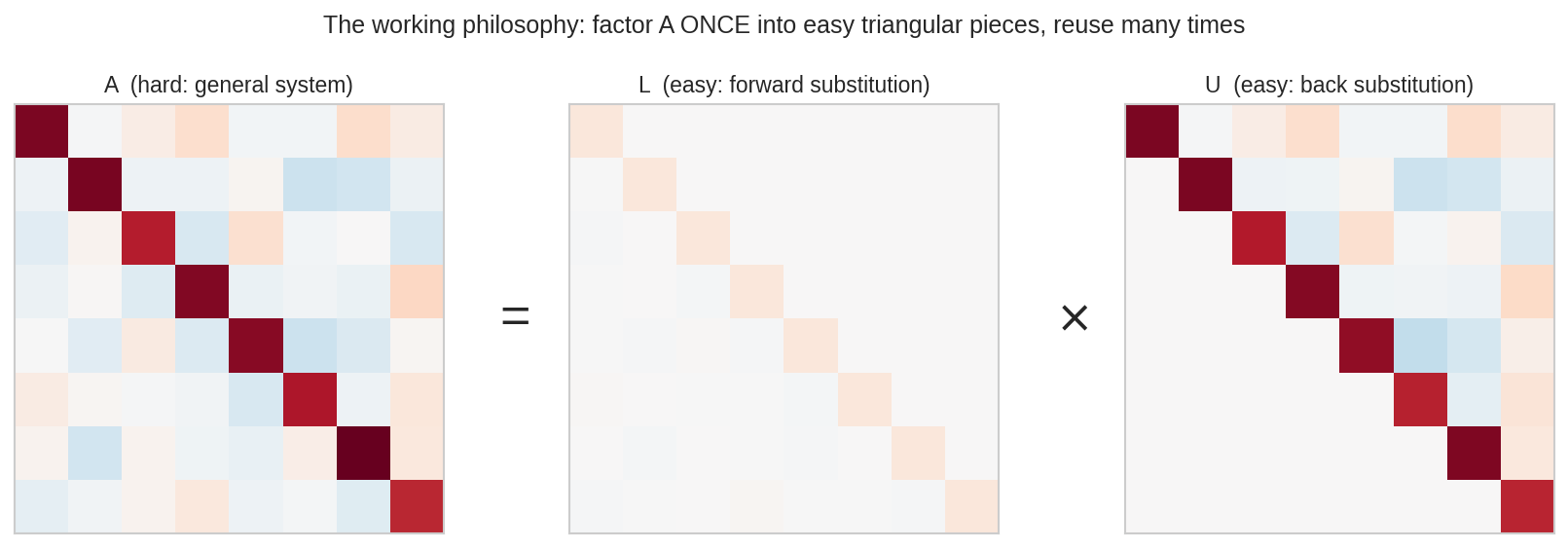
বাঁয়ে একটা "কঠিন" general matrix \(A\) (রঙিন এলোমেলো ঘর) — এর সাথে সরাসরি \(Ax = b\) সমাধান করা কষ্টকর। মাঝে ও ডানে সেই \(A\)-কেই দুটো ত্রিভুজাকার matrix-এ ভাঙা হয়েছে: \(L\) (নিচের ত্রিভুজ) আর \(U\) (উপরের ত্রিভুজ)। ত্রিভুজ system সমাধান করা খুব সহজ — এক এক করে substitution। মূল দর্শন: matrix-টা একবারই কষ্ট করে ভাঙো, তারপর যত \(b\) আসুক, সস্তায় সমাধান কর।
১. কি? (What)¶
দৈনন্দিন analogy: একবার চাবি বানাও, বারবার খোলো¶
ভাবো তোমার একটা কঠিন তালা আছে। প্রতিবার খুলতে হলে যদি নতুন করে তালা-ভাঙার কসরত কর, প্রতিবারই ঘণ্টাখানেক যাবে। কিন্তু যদি একবার কষ্ট করে একটা চাবি বানিয়ে ফেলো — তারপর প্রতিবার খোলা লাগে মাত্র এক সেকেন্ড। Matrix factorization ঠিক তাই: \(A\)-কে সহজ টুকরোয় ভাঙা মানে "চাবি বানানো", আর সেই টুকরো দিয়ে যেকোনো \(b\)-র জন্য সমাধান টানা মানে "চাবি ঘোরানো"।
কেন এটা গুরুত্বপূর্ণ? বাস্তবে একই \(A\) নিয়ে অনেকবার \(Ax = b\) সমাধান করতে হয় — শুধু \(b\) বদলায়। যেমন একটা circuit-এ input voltage বদলাচ্ছে, বা একটা structure-এ ভিন্ন ভিন্ন load। প্রতিবার নতুন করে elimination চালানো মানে বোকামি।
কেন inv(A) নয়? — তিনটা কারণ¶
তুমি হয়তো ভাবছো: "\(A^{-1}\) একবার বের করে রেখে দিলেই তো হয়, তারপর প্রতিবার \(A^{-1}b\)?" এটাই সবচেয়ে সাধারণ ভুল। তিনটা কারণে পেশাদাররা inverse এড়ায়:
- ধীর: \(A^{-1}\) বের করা আর তারপর গুণ করা — factorization + substitution-এর চেয়ে প্রায় তিনগুণ বেশি কাজ।
- কম নির্ভুল: inverse বের করার পথে বেশি floating point operation, তাই বেশি ধুলো জমে (Chapter 8.1-এর error accumulation) — সরাসরি solve প্রায় সবসময় বেশি সঠিক।
- Sparse ধ্বংস করে: \(A\) sparse (বেশিরভাগ ঘর শূন্য) হলেও \(A^{-1}\) প্রায় সবসময় পুরো ভরা (dense) — memory-তে আঁটবে না (§২-এর ছবি)।
মন্ত্রটা মুখস্থ করো: কখনো matrix invert করো না; factor করো, তারপর substitute করো।
সংজ্ঞা: তিন factorization¶
LU Decomposition: যেকোনো (square, invertible) matrix \(A\)-কে লেখা যায়
যেখানে \(L\) একটা lower triangular(নিচের ত্রিভুজ) matrix (diagonal-এ ১), \(U\) একটা upper triangular(উপরের ত্রিভুজ) matrix, আর \(P\) একটা permutation matrix(পারমিউটেশন — শুধু row অদল-বদল করে)। \(P\) লাগে pivoting-এর জন্য: elimination-এ সবচেয়ে বড় সংখ্যাটাকে pivot বানালে (partial pivoting) সংখ্যা বেশি stable থাকে (Chapter 8.1-এর stability)।
Cholesky Decomposition: \(A\) যদি symmetric positive definite(SPD — Part VI-এর সেই বিশেষ শ্রেণি, সব eigenvalue ধনাত্মক) হয়, তাহলে
একটাই lower triangular \(L\) দিয়ে — LU-এর "অর্ধেক", কারণ symmetry-র সুবাদে \(U = L^T\)। খরচ ঠিক অর্ধেক।
QR Decomposition: যেকোনো matrix \(A\) (\(m \times n\), \(m \ge n\)) লেখা যায়
যেখানে \(Q\)-এর column-গুলো orthonormal (Part V-এর Gram–Schmidt/Householder), আর \(R\) upper triangular। এটাই least squares-এর নিরাপদ পথ (Chapter 5.4-এ normal equations দেখেছো — QR তার stable সংস্করণ)।
Triangular system কেন সহজ?¶
Factorization-এর পুরো লাভ এখানে: ত্রিভুজ system সমাধান করা তুচ্ছ। ধরো \(Lc = b\), যেখানে \(L\) lower triangular:
প্রথম সারি বলে \(l_{11}c_1 = b_1 \Rightarrow c_1 = b_1/l_{11}\) — সরাসরি! এবার \(c_1\) জানা, দ্বিতীয় সারি থেকে \(c_2\), তারপর \(c_3\)। একে বলে Forward Substitution(ফরওয়ার্ড সাবস্টিটিউশন)। Upper triangular-এ নিচ থেকে ওপরে গেলে Back Substitution(ব্যাক সাবস্টিটিউশন)। প্রতিটার খরচ মাত্র \(\sim n^2\) — factorization-এর \(n^3\)-এর তুলনায় নগণ্য।
তাই পুরো recipe:
২. দেখতে কেমন?¶
দৃশ্য ১: খরচের বাস্তব মাপ — কে দ্রুত, কে ধীর¶
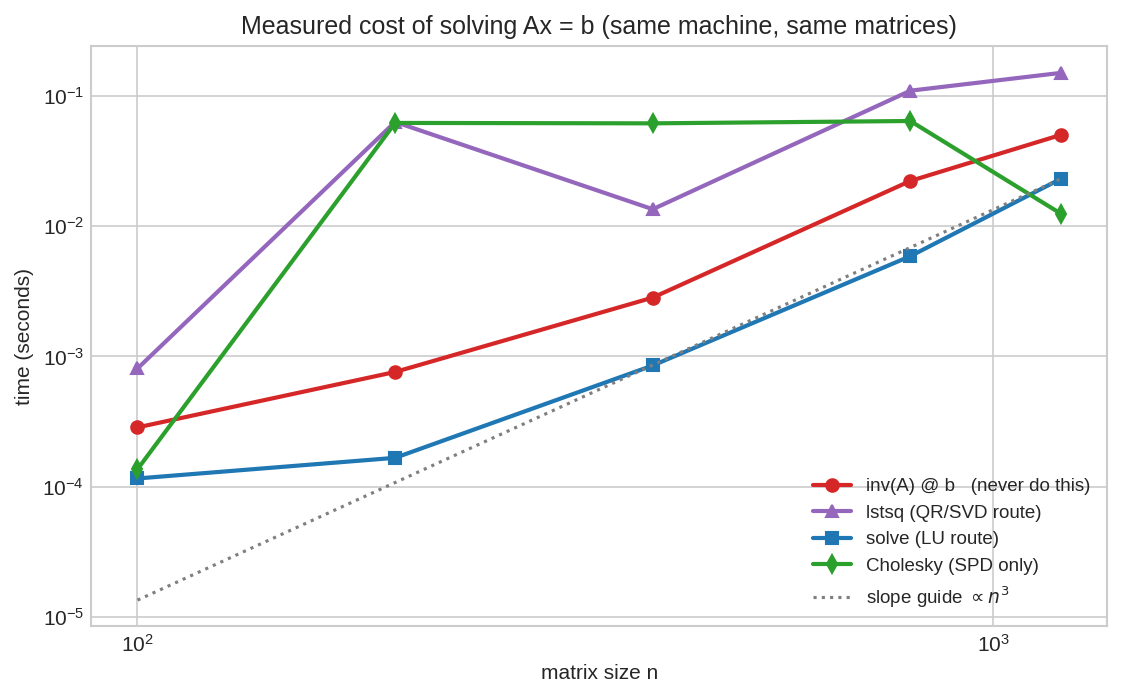
একই মেশিনে, একই matrix-এ চার পদ্ধতির মাপা সময় (log-log scale)। সব লাইনই ধূসর গাইড-লাইনের (\(\propto n^3\)) সমান্তরাল — অর্থাৎ সবার খরচ \(n^3\)-এর মতো বাড়ে, শুধু ধ্রুবক গুণকটা আলাদা। লাল (inv(A) @ b) সবার ওপরে — সবচেয়ে ধীর। সবুজ (Cholesky, SPD matrix-এ) সবচেয়ে নিচে — অর্ধেক খরচ। নীল (solve, LU পথ) মাঝে। শিক্ষা: matrix-এর গঠন যত বেশি কাজে লাগাবে, তত সস্তা।
দৃশ্য ২: রোগ ও উপসর্গ — inverse বেশি digit হারায়¶
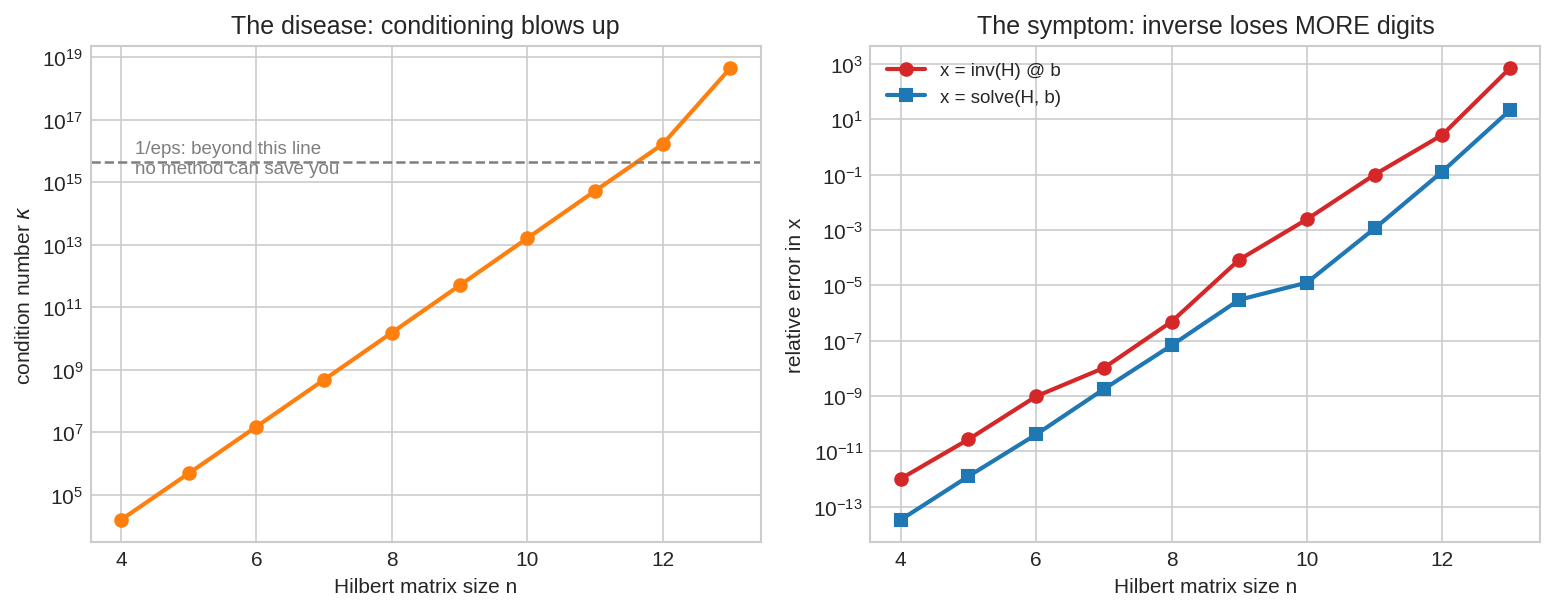
বাঁয়ে "রোগ": Hilbert matrix-এর condition number \(\kappa\) আকারের সাথে বিস্ফোরকভাবে বাড়ে (\(n = 13\)-এই \(\kappa > 10^{16}\) — মেশিন-নির্ভুলতার সীমা পার)। ডানে "উপসর্গ": একই সমস্যায় inv(H) @ b (লাল) সমাধানে বেশি digit হারায়, solve(H, b) (নীল) কম। conditioning সমস্যার দোষ (এড়ানো যায় না), কিন্তু inverse ব্যবহার সেই দোষ আরো বাড়িয়ে দেয় — algorithm-এর দোষ (এড়ানো যায়)।
দৃশ্য ৩: Sparse matrix আর fill-in-এর অভিশাপ¶
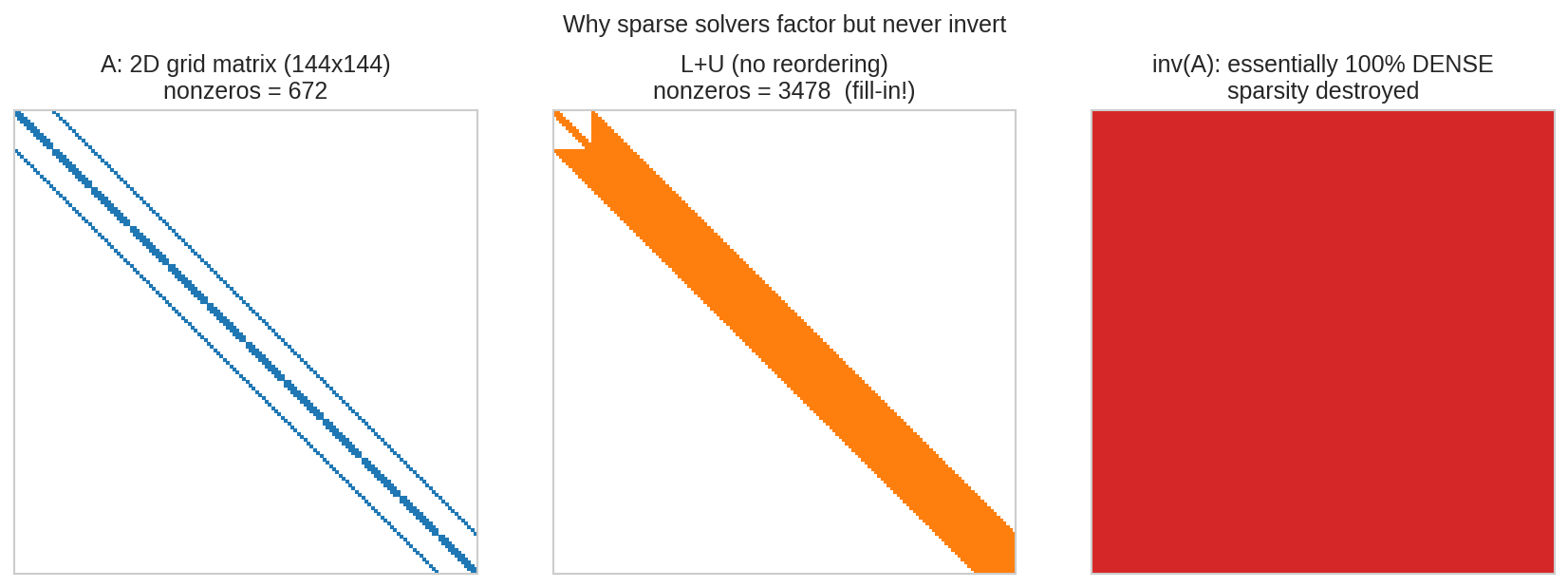
বাঁয়ে একটা 2D grid থেকে আসা matrix (\(144 \times 144\)) — শুধু কয়েকটা diagonal-এ nonzero, বাকি সব শূন্য (নীল বিন্দুগুলোই nonzero)। মাঝে সেই matrix-এর LU factor: শূন্য জায়গাগুলো ভরে উঠেছে (কমলা — একে বলে fill-in), তবু বেশিরভাগ শূন্যই টিকে আছে। ডানে সেই একই matrix-এর inverse: প্রায় ১০০% ভরা (লাল)! এই ছবিটাই বলে দেয় কেন sparse solver কখনো invert করে না — factor করে, কারণ factor-এ sparsity অনেকটা বাঁচে, inverse-এ পুরো মরে।
দৃশ্য ৪: কোন যন্ত্র কখন — field guide¶
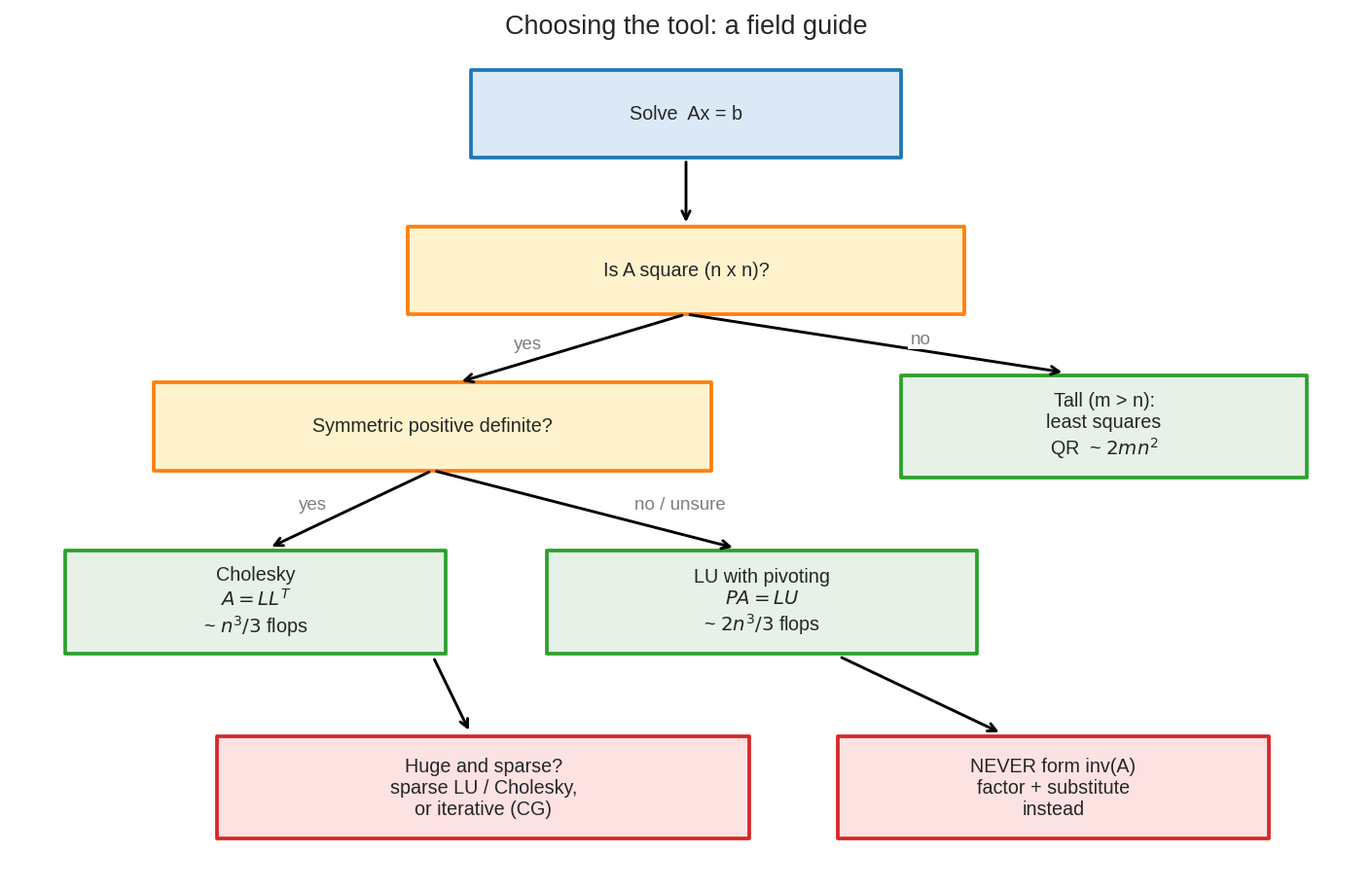
একটা সিদ্ধান্ত-বৃক্ষ (decision tree)। "square নাকি tall?" — tall হলে QR (least squares)। square হলে "SPD নাকি?" — হ্যাঁ হলে Cholesky (সস্তা), না হলে pivoting-সহ LU। "বিশাল ও sparse?" — sparse LU/Cholesky বা iterative (CG)। আর সবার নিচে লাল সতর্কবাণী: কখনো inv(A) বানিও না। এই ছবিটাই পুরো chapter-এর সারমর্ম।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- Circuit simulation: SPICE-এর মতো software একটা circuit-কে বিশাল sparse \(Ax = b\)-তে রূপ দেয় (\(A\) = conductance matrix), প্রতিটা time-step-এ সমাধান করে। sparse LU ছাড়া তোমার ল্যাপটপে একটা chip simulate করা অসম্ভব হতো।
- Structural engineering: সেতু বা ভবনের finite element model — লক্ষ লক্ষ variable, কিন্তু প্রতিটা node শুধু প্রতিবেশীর সাথে যুক্ত, তাই matrix cripplingly sparse। Cholesky (stiffness matrix SPD) এখানে workhorse।
- আবহাওয়া ও তরলবিদ্যা: Navier–Stokes সমীকরণ discretize করলে প্রতিটা step-এ বিশাল sparse system — এখানে সরাসরি factorization-ও ব্যয়বহুল, তাই iterative method (§নিচে) লাগে।
Data Science / ML-এ:
- Linear ও Ridge regression: normal equation \((X^TX)\hat\beta = X^Ty\) — \(X^TX\) SPD, তাই Cholesky আদর্শ। কিন্তু বড় বা ill-conditioned হলে QR সরাসরি \(X\)-এ (normal equation না বানিয়েই) বেশি নিরাপদ — Chapter 5.4-এর normal equation-এর "লুকানো condition number দ্বিগুণ" সমস্যাটা QR এড়ায়।
- Gaussian Process ও Kernel method: kernel matrix \(K\) SPD, তার Cholesky (\(K = LL^T\)) দিয়েই GP-র posterior, likelihood, sampling — সব হয়। বড় dataset-এ এই \(n^3\)-ই মূল bottleneck।
- Newton's method / optimization: প্রতিটা iteration-এ Hessian system \(H\Delta = -g\) সমাধান — \(H\) SPD হলে (convex সমস্যায়) Cholesky, নইলে LU।
- Recommendation / graph: বিশাল sparse system (user-item, PageRank-ধাঁচ) — এখানে সরাসরি factorization-ও মাঝেমধ্যে অসম্ভব, তখন iterative solver (§নিচে) একমাত্র উপায়।
৪. Properties¶
Property 1 — Triangular solve সস্তা, factorization দামি¶
একটা \(n \times n\) system-এর মোট খরচ দুই ভাগে ভাগ:
এই ভাগটাই factorization-এর মূল সুবিধা। \(A\) একই রেখে \(k\)টা ভিন্ন \(b\) সমাধান করতে খরচ \(\sim n^3 + kn^2\), inverse-বহু-গুণ পথে হতো \(\sim 3n^3 + kn^2\) — বড় \(n\)-এ বিরাট ফারাক। Factor একবার, ব্যবহার বহুবার।
Property 2 — Cholesky ঠিক অর্ধেক খরচ (এবং এক স্বয়ংক্রিয় SPD-পরীক্ষা)¶
SPD matrix-এ \(U = L^T\) হওয়ায় \(L\)-এর অর্ধেক entry-ই যথেষ্ট: খরচ \(\sim \frac{1}{3}n^3\), LU-এর \(\frac{2}{3}n^3\)-এর ঠিক অর্ধেক। উপরি লাভ: Cholesky চালাতে গিয়ে যদি কোনো ধাপে diagonal-এ ঋণাত্মক সংখ্যার বর্গমূল নিতে হয়, তার মানে matrix-টা SPD নয় — এটাই বাস্তবে SPD পরীক্ষার দ্রুততম উপায় (eigenvalue বের করার দরকার নেই)।
Property 3 — Complexity ধ্রুবক নয়, বৃদ্ধির হার¶
"\(\sim n^3\)" মানে matrix দ্বিগুণ বড় হলে খরচ আট গুণ (\(2^3 = 8\))। এই একটা তথ্যই বাস্তব সিদ্ধান্তের ভিত্তি:
| operation | খরচ | মানে |
|---|---|---|
| Triangular solve | \(\sim n^2\) | সস্তা — factorization-এর পর "ফ্রি" |
| LU factorization | \(\sim \frac{2}{3}n^3\) | general square |
| Cholesky | \(\sim \frac{1}{3}n^3\) | SPD — অর্ধেক |
| QR (\(m \times n\)) | \(\sim 2mn^2\) | tall/least squares |
| Matrix inverse | \(\sim 2n^3\) | সবচেয়ে দামি — এড়াও |
\(n = 10{,}000\)-এর একটা dense LU \(\sim 6.7 \times 10^{11}\) flop — কয়েক সেকেন্ড। কিন্তু \(n = 10^6\)? \(\sim 10^{17}\) flop — অসম্ভব। এখানেই sparsity বাঁচায়।
Property 4 — Sparse-এ কাঠামোই সব, আকার নয়¶
Sparse matrix-এর খরচ \(n^3\) নয়, বরং nonzero-র সংখ্যা আর কাঠামোর ওপর নির্ভর। ভালো ordering (reordering rows/columns যাতে fill-in কম হয় — যেমন AMD, nested dissection) ব্যবহার করলে 2D grid-এর \(n\)-variable system \(\sim n^{1.5}\)-এ, 1D-তে প্রায় \(\sim n\)-এ সমাধান হয়। তাই sparse solver-এ factorization-এর আগে ordering ঠিক করাই আসল শিল্প।
Property 5 — Factorization সমস্যা সহজ করে, কিন্তু conditioning বদলায় না¶
মনে রাখো (Chapter 8.1): factorization সমাধান দ্রুত ও stable করে, কিন্তু matrix-এর অন্তর্নিহিত \(\kappa(A)\) কমায় না। \(A\) ill-conditioned হলে কোনো solver-ই নিখুঁত উত্তর দেবে না — factorization শুধু algorithm-এর অতিরিক্ত ভুল কমায়, সমস্যার ভুল নয়। Hilbert matrix-এর ছবিটা (§২) ঠিক এটাই দেখায়: solve inverse-এর চেয়ে ভালো, কিন্তু \(\kappa\) বিশাল হলে দুটোই ফেল।
৫. Intuition — কেন সত্য?¶
কেন LU = Gaussian elimination-এর ডায়েরি¶
Part I-এ Gaussian elimination করেছো: row-এর গুণিতক বিয়োগ করে করে matrix-টাকে upper triangular (\(U\)) বানানো। প্রশ্ন: elimination-এ যেসব গুণক (\(m_{ij}\) = কত গুণ বিয়োগ করলাম) ব্যবহার করলাম, সেগুলো কোথায় যায়? উত্তর: ঠিক ওই গুণকগুলো জমা হয় \(L\)-এর নিচের ঘরে!
তাই \(A = LU\) আসলে বলছে: "\(A\)-কে \(U\) বানাতে আমি যা যা করেছি (\(L\)-এ লেখা), সেটা উল্টে চালালে \(U\) থেকে \(A\) ফিরে পাই।" LU হলো elimination-এর স্মৃতি — একবার elimination করে সেই কাজটা ধরে রাখা, যেন প্রতিবার নতুন \(b\)-তে আবার করতে না হয়। এটাই "একবার চাবি বানানো"।
কেন pivoting লাগে — শূন্য দিয়ে ভাগের ভয়¶
Elimination-এ pivot (যে সংখ্যা দিয়ে ভাগ করি) যদি শূন্য বা খুব ছোট হয়, তাহলে বিপর্যয় — শূন্য দিয়ে ভাগ, বা ছোট সংখ্যা দিয়ে ভাগ করে বিশাল সংখ্যা তৈরি (Chapter 8.1-এর catastrophic amplification)। সমাধান: প্রতি ধাপে column-এর সবচেয়ে বড় সংখ্যাটাকে ওপরে এনে (row swap = \(P\)) pivot বানাও। এতে গুণকগুলো সবসময় \(\le 1\), সংখ্যা নিয়ন্ত্রণে থাকে। এই "বড়টাকে সামনে আনা"-ই partial pivoting, আর \(P\) তার হিসাব রাখে।
কেন Cholesky অর্ধেক — symmetry-র উপহার¶
\(A\) symmetric মানে উপরের ত্রিভুজ আর নিচের ত্রিভুজ একে অপরের প্রতিফলন — অর্ধেক তথ্যই যথেষ্ট। SPD আরো বেশি দেয়: সব "pivot" ধনাত্মক থাকার গ্যারান্টি (কারণ leading minor সব ধনাত্মক), তাই pivoting-ই লাগে না — row swap ছাড়াই সবসময় stable। এক ঢিলে দুই পাখি: অর্ধেক কাজ, আর \(P\)-এর ঝামেলা নেই। জ্যামিতিকভাবে \(A = LL^T\) মানে "\(A\) = কোনো ত্রিভুজাকার রূপান্তর \(L\)-এর নিজের সাথে গুণফল" — যেকোনো SPD matrix আসলে একটা vector-set-এর Gram matrix (Part V), আর \(L\) তার "বর্গমূল"।
কেন QR least squares-এর নিরাপদ পথ¶
Normal equation \((A^TA)x = A^Tb\)-এ \(A^TA\) বানানো condition number বর্গ করে দেয় (\(\kappa(A^TA) = \kappa(A)^2\)) — Chapter 8.1-এর বিপদ দ্বিগুণ। QR এই বিপদ এড়ায়: \(A = QR\) বসিয়ে
(\(Q^TQ = I\) কারণ orthonormal, আর \(R^T\) কাটাকাটি)। শেষ ধাপ একটা সাধারণ triangular solve — আর \(A^TA\) কখনো বানানোই হলো না, তাই condition number বর্গ হলো না। orthogonal matrix দৈর্ঘ্য সংরক্ষণ করে (Part V), তাই ভুলও বাড়ায় না — এই দুই কারণে QR সংখ্যাগতভাবে least squares-এর সোনার মান।
Iterative method — যখন factorization-ও অসম্ভব¶
\(n = 10^7\)-এর sparse system-এ factorization-ও (fill-in-এর কারণে) অসম্ভব হতে পারে। তখন iterative method: শুরু করো একটা আন্দাজ \(x_0\) থেকে, প্রতি ধাপে শুধু \(A\)-এর সাথে একটা vector গুণ করে (\(A\) sparse বলে সস্তা) উত্তরের দিকে এগোও। SPD-তে সবচেয়ে বিখ্যাত Conjugate Gradient(কনজুগেট গ্রেডিয়েন্ট — CG): তত্ত্বে \(n\) ধাপে, বাস্তবে অনেক কম ধাপে (condition number ভালো হলে) কাছাকাছি উত্তর — কখনো \(A\) factor না করেই। বিশাল জগতে factorization বিলাসিতা, iteration বাস্তবতা।
৬. Code-এ কেমনে লিখে¶
import numpy as np
import scipy.linalg as sla
import scipy.sparse as sp
import scipy.sparse.linalg as spla
import time
rng = np.random.default_rng(42)
# ---------- ১. LU: factor একবার, বহু b-তে reuse ----------
n = 500
A = rng.standard_normal((n, n)) + n * np.eye(n) # invertible
lu, piv = sla.lu_factor(A) # factor একবার (P, L, U)
for _ in range(3): # অনেক b, সস্তা solve
b = rng.standard_normal(n)
x = sla.lu_solve((lu, piv), b)
print("LU residual:", np.linalg.norm(A @ x - b)) # ~1e-12, প্রায় শূন্য
# ---------- ২. Cholesky: SPD-তে অর্ধেক খরচ ----------
B = rng.standard_normal((n, n))
S = B @ B.T + n * np.eye(n) # symmetric positive definite
c, low = sla.cho_factor(S) # A = L L^T
b = rng.standard_normal(n)
x_chol = sla.cho_solve((c, low), b)
print("Cholesky residual:", np.linalg.norm(S @ x_chol - b))
# Cholesky = SPD পরীক্ষা: non-SPD-তে ভেঙে পড়ে
try:
sla.cho_factor(np.array([[1.0, 2.0], [2.0, 1.0]])) # eigenvalue -1, 3: not SPD
except np.linalg.LinAlgError:
print("Cholesky failed -> matrix is NOT positive definite (এটাই SPD-পরীক্ষা)")
# ---------- ৩. QR: least squares-এর নিরাপদ পথ ----------
m = 800
A_tall = rng.standard_normal((m, n)) # tall: m > n
y = rng.standard_normal(m)
Q, R = np.linalg.qr(A_tall) # A = QR
x_ls = sla.solve_triangular(R, Q.T @ y) # R x = Q^T y
resid_qr = np.linalg.norm(A_tall @ x_ls - y)
x_np = np.linalg.lstsq(A_tall, y, rcond=None)[0] # library-র সাথে মিলিয়ে দেখা
print("QR vs lstsq match:", np.allclose(x_ls, x_np))
# ---------- ৪. inv() কেন খারাপ: সময় মেপে দেখা ----------
t0 = time.perf_counter(); sla.lu_solve(sla.lu_factor(A), b); t_solve = time.perf_counter() - t0
t0 = time.perf_counter(); np.linalg.inv(A) @ b; t_inv = time.perf_counter() - t0
print(f"solve time={t_solve*1e3:.1f}ms, inv time={t_inv*1e3:.1f}ms -> inv slower")
# ---------- ৫. Sparse: বিশাল system, sparsity বাঁচায় ----------
N = 4000
diag = 4 * np.ones(N)
off = -1 * np.ones(N - 1)
As = sp.diags([off, diag, off], [-1, 0, 1], format="csc") # tridiagonal, sparse
bs = rng.standard_normal(N)
xs = spla.spsolve(As, bs) # sparse solver: factor keeps sparsity
print("sparse residual:", np.linalg.norm(As @ xs - bs))
print("A nonzeros:", As.nnz, "vs dense would be:", N * N)
Output ব্যাখ্যা:
- সব residual \(\sim 10^{-12}\) বা কম — অর্থাৎ সমাধানগুলো নিখুঁত (Chapter 8.1-এর machine epsilon-এর ঘরে)।
- LU অংশে একটাই factor (
lu_factor) তিনটা ভিন্ন \(b\)-তে reuse হলো — factorization-এর মূল সুবিধা কোডে দেখা। - Cholesky সফল হলো SPD
S-এ, কিন্তু \(\begin{bmatrix}1&2\\2&1\end{bmatrix}\)-এ (eigenvalue \(-1, 3\) — SPD নয়) ভেঙে পড়লো — Property 2-এর স্বয়ংক্রিয় SPD-পরীক্ষা হাতেনাতে। - QR-এর সমাধান
np.linalg.lstsq-এর সাথে হুবহু মিললো (True) — normal equation না বানিয়েই least squares। invসময়েsolve-এর চেয়ে ধীর — কোডে Property 3-এর প্রমাণ।- Sparse tridiagonal-এ nonzero মাত্র \(\sim 12{,}000\), dense হলে হতো \(1.6 \times 10^7\) — sparsity-র বিশাল সাশ্রয়, আর
spsolveঠিক এই sparsity কাজে লাগায়।
৭. Worked Examples¶
Example 1 — হাতে-কলমে LU factorization, তারপর দুই \(b\)-তে reuse¶
ধাপ ১ — Elimination (গুণকগুলো মনে রাখো): Row2 \(\leftarrow\) Row2 \(- 2\cdot\)Row1 (গুণক \(m_{21} = 2\)); Row3 \(\leftarrow\) Row3 \(- 4\cdot\)Row1 (গুণক \(m_{31} = 4\)):
Row3 \(\leftarrow\) Row3 \(- 3\cdot\)Row2 (গুণক \(m_{32} = 3\)):
ধাপ ২ — \(L\) = গুণকগুলো (diagonal-এ ১):
যাচাই: \(LU = A\) ✓ (গুণ করে দেখো)।
ধাপ ৩ — \(b = (1, 4, 15)^T\)-তে সমাধান। Forward (\(Lc = b\)): \(c_1 = 1\); \(2(1) + c_2 = 4 \Rightarrow c_2 = 2\); \(4(1) + 3(2) + c_3 = 15 \Rightarrow c_3 = 5\)। Back (\(Ux = c\)): \(2x_3 = 5 \Rightarrow x_3 = 2.5\); \(x_2 + 2.5 = 2 \Rightarrow x_2 = -0.5\); \(2x_1 - 0.5 + 2.5 = 1 \Rightarrow x_1 = -0.5\)। সমাধান \(x = (-0.5, -0.5, 2.5)^T\)।
ধাপ ৪ — নতুন \(b = (0, 2, 8)^T\): factorization পুনর্ব্যবহার! কোনো নতুন elimination নয় — শুধু substitution। Forward: \(c = (0, 2, 2)^T\); Back: \(x_3 = 1, x_2 = 1, x_1 = -1\)। এটাই factorization-এর জাদু: elimination একবার, সমাধান যতবার খুশি।
Example 2 — Cholesky হাতে-কলমে (\(2\times 2\))¶
ধাপ ১ — SPD কিনা? symmetric ✓; leading minor \(4 > 0\), \(\det = 20 - 4 = 16 > 0\) ✓ — SPD।
ধাপ ২ — \(A = LL^T\) ধরো \(L = \begin{bmatrix} l_{11} & 0 \\ l_{21} & l_{22}\end{bmatrix}\)। গুণ করে মেলাও:
\(l_{11}^2 = 4 \Rightarrow l_{11} = 2\); \(l_{11}l_{21} = 2 \Rightarrow l_{21} = 1\); \(l_{21}^2 + l_{22}^2 = 5 \Rightarrow 1 + l_{22}^2 = 5 \Rightarrow l_{22} = 2\)।
লক্ষ করো: কোথাও ঋণাত্মক সংখ্যার বর্গমূল নিতে হলো না — SPD-র গ্যারান্টি। \(A\) SPD না হলে (\(l_{22}^2 < 0\)) এখানেই ভেঙে পড়তো — Property 2-এর SPD পরীক্ষা।
Example 3 — Complexity দিয়ে সিদ্ধান্ত: কোন পথ?¶
পরিস্থিতি: তোমার কাছে একটা \(n = 5000\) SPD matrix, আর ৫০টা ভিন্ন \(b\)। তিনটা পরিকল্পনা তুলনা করো (flop-এর আনুমানিক হিসাব):
- পরিকল্পনা A (inverse): \(A^{-1}\) একবার (\(\sim 2n^3\)), তারপর ৫০টা গুণ (\(50 \times 2n^2\))। মোট \(\approx 2n^3 = 2.5 \times 10^{11}\)।
- পরিকল্পনা B (LU একবার): LU (\(\sim \frac{2}{3}n^3\)) + ৫০ substitution (\(50 \times 2n^2\))। মোট \(\approx 0.83 \times 10^{11}\)।
- পরিকল্পনা C (Cholesky একবার): Cholesky (\(\sim \frac{1}{3}n^3\)) + ৫০ substitution। মোট \(\approx 0.42 \times 10^{11}\)।
সিদ্ধান্ত: SPD বলে Cholesky (C) — inverse-এর তুলনায় প্রায় ৬ গুণ কম কাজ, আর বেশি নির্ভুল। substitution অংশ (\(50 \times 2n^2 = 2.5 \times 10^9\)) তিনটাতেই নগণ্য — factorization-ই খরচের রাজা, তাই সবচেয়ে সস্তা factorization বাছাই = সবচেয়ে ভালো পরিকল্পনা।
৮. Problems ও Solutions¶
Problem 1. \(A = \begin{bmatrix} 1 & 2 & 4 \\ 3 & 8 & 14 \\ 2 & 6 & 13 \end{bmatrix}\)-এর LU factorization বের করো (pivoting ছাড়া), তারপর \(b = (7, 25, 21)^T\)-তে \(Ax = b\) সমাধান করো।
Solution
Elimination: Row2 \(-3\cdot\)Row1 (\(m_{21}=3\)), Row3 \(-2\cdot\)Row1 (\(m_{31}=2\)):
Row3 \(-1\cdot\)Row2 (\(m_{32}=1\)):
যাচাই: \(LU = A\) ✓।
Forward (\(Lc = b\)): \(c_1 = 7\); \(3(7) + c_2 = 25 \Rightarrow c_2 = 4\); \(2(7) + 1(4) + c_3 = 21 \Rightarrow c_3 = 3\)।
Back (\(Ux = c\)): \(3x_3 = 3 \Rightarrow x_3 = 1\); \(2x_2 + 2(1) = 4 \Rightarrow x_2 = 1\); \(x_1 + 2(1) + 4(1) = 7 \Rightarrow x_1 = 1\)।
সমাধান \(x = (1, 1, 1)^T\) ✓ (মিলিয়ে দেখো: \(A(1,1,1)^T = (7, 25, 21)^T\))।
Problem 2. \(A = \begin{bmatrix} 9 & 3 \\ 3 & 5 \end{bmatrix}\) SPD কিনা যাচাই করো, তারপর Cholesky \(A = LL^T\) বের করো।
Solution
SPD পরীক্ষা: symmetric ✓; leading minor \(9 > 0\); \(\det = 45 - 9 = 36 > 0\) — দুই leading minor-ই ধনাত্মক, তাই SPD ✓।
Cholesky: \(l_{11}^2 = 9 \Rightarrow l_{11} = 3\); \(l_{11}l_{21} = 3 \Rightarrow l_{21} = 1\); \(l_{21}^2 + l_{22}^2 = 5 \Rightarrow l_{22}^2 = 4 \Rightarrow l_{22} = 2\)।
কোনো ধাপে ঋণাত্মক-বর্গমূল আসেনি — SPD-র গ্যারান্টি নিজেই confirm করলো।
Problem 3. একটা \(n = 2000\) dense general matrix, আর তোমাকে \(100\)টা ভিন্ন \(b\)-তে \(Ax = b\) সমাধান করতে হবে। দুটো পরিকল্পনার flop তুলনা করো: (A) প্রতিবার নতুন করে solve(A, b); (B) একবার LU factor করে \(100\)বার substitute। কোনটা কত গুণ দ্রুত?
Solution
LU factorization খরচ \(\sim \frac{2}{3}n^3\), প্রতি substitution \(\sim 2n^2\)।
- (A) প্রতিবার নতুন factor: \(100 \times \frac{2}{3}n^3 = \frac{200}{3}n^3 \approx 5.3 \times 10^{11}\) flop।
- (B) একবার factor + \(100\) substitute: \(\frac{2}{3}n^3 + 100 \times 2n^2 = 0.53 \times 10^{10} + 8 \times 10^8 \approx 6.1 \times 10^9\) flop।
অনুপাত \(\approx 5.3\times10^{11} / 6.1\times10^9 \approx 87\) গুণ! শিক্ষা: একই \(A\), বহু \(b\) — factorization একবার করে reuse করাই একমাত্র বুদ্ধিমানের কাজ। (scipy.linalg.lu_factor একবার, lu_solve বহুবার।)
Problem 4. কেন least squares-এ QR সরাসরি \(A\)-তে চালানো, normal equation \(A^TA\) বানানোর চেয়ে ভালো? Condition number-এর ভাষায় ব্যাখ্যা করো।
Solution
Normal equation \((A^TA)x = A^Tb\) সমাধান করতে হলে \(A^TA\) matrix-এর সাথে কাজ করতে হয়, আর
— condition number বর্গ হয়ে যায় (Chapter 8.1-এর \(\kappa = \sigma_1/\sigma_n\) থেকে, কারণ \(A^TA\)-এর singular value হলো \(A\)-এর singular value-র বর্গ)। ফলে যদি \(\kappa(A) = 10^6\) হয় (মোটামুটি খারাপ), \(\kappa(A^TA) = 10^{12}\) — double precision-এ প্রায় সব digit হারানো।
QR পথে \(Rx = Q^Tb\) সমাধান করা হয় সরাসরি, \(A^TA\) বানানো ছাড়া — condition number থাকে \(\kappa(A)\) (বর্গ হয় না), আর orthogonal \(Q\) ভুল বাড়ায় না। তাই একই সমস্যায় QR অনেক বেশি digit বাঁচায়। নিয়ম: ill-conditioned least squares-এ কখনো normal equation বানিও না; QR (বা SVD) ব্যবহার করো।
Problem 5. একটা \(A\) (\(2 \times 2\)) দেওয়া যেখানে pivoting ছাড়া LU ব্যর্থ হয়: \(A = \begin{bmatrix} 0 & 1 \\ 1 & 1 \end{bmatrix}\)। (a) কেন pivoting ছাড়া ব্যর্থ? (b) row swap করে \(PA = LU\) বের করো।
Solution
(a) প্রথম pivot হলো \(a_{11} = 0\)। Elimination-এ Row2 থেকে \(\frac{a_{21}}{a_{11}} = \frac{1}{0}\) গুণ Row1 বিয়োগ করতে হবে — শূন্য দিয়ে ভাগ, অসম্ভব। তাই pivoting ছাড়া থমকে যায়।
(b) Row swap (\(P\) = দুই row বদলানো):
এখন pivot \(1 \ne 0\)। এটা ইতিমধ্যে upper triangular, কোনো elimination লাগে না:
যাচাই: \(PA = LU\) ✓। শিক্ষা: partial pivoting শুধু stability-র জন্য না — কখনো কখনো LU অস্তিত্বের জন্যই লাগে (শূন্য pivot এড়াতে)। বাস্তব solver-এ তাই সবসময় pivoting চালু থাকে।
Problem 6. একটা \(1000 \times 1000\) sparse tridiagonal matrix (শুধু তিনটা diagonal-এ nonzero) বনাম একই আকারের dense matrix। (a) প্রতিটার nonzero সংখ্যা আন্দাজ করো। (b) কেন dense LU-এর \(O(n^3)\)-এর বদলে sparse tridiagonal solve \(O(n)\)-এ হয়?
Solution
(a) Tridiagonal: main diagonal \(n = 1000\) + দুটো off-diagonal \(2(n-1) = 1998\), মোট \(\approx 2998 \approx 3000\) nonzero। Dense: \(n^2 = 10^6\) — প্রায় ৩৩০ গুণ বেশি।
(b) Tridiagonal-এ elimination-এ প্রতিটা row-এ মাত্র একটা off-diagonal entry নির্মূল করতে হয়, আর সেটা শুধু পরের row-কে প্রভাবিত করে — কোনো fill-in নেই (নতুন nonzero তৈরি হয় না)। তাই মোট \(n\)টা এমন সস্তা ধাপ, খরচ \(O(n)\)। Dense-এ প্রতি ধাপ নিচের সব row বদলায় (\(n\)টা), \(n\) ধাপে \(O(n^3)\)। মূল কথা: sparse solver-এর গতি nonzero-র সংখ্যা আর fill-in-এর ওপর নির্ভর, আকার \(n\)-এর ওপর নয় — এই একটা কারণেই লক্ষ-variable system বাস্তবে সমাধানযোগ্য।
Problem 7. (কোডে) একটা \(300 \times 300\) SPD matrix বানাও, তারপর তিন পথে \(Ax = b\) সমাধান করে residual \(\|Ax - b\|\) তুলনা করো: (i) inv(A) @ b, (ii) np.linalg.solve, (iii) Cholesky। কোনটা সবচেয়ে নির্ভুল?
Solution
import numpy as np
import scipy.linalg as sla
rng = np.random.default_rng(0)
n = 300
B = rng.standard_normal((n, n))
A = B @ B.T + n * np.eye(n) # SPD
b = rng.standard_normal(n)
x_inv = np.linalg.inv(A) @ b
x_solve = np.linalg.solve(A, b)
c, low = sla.cho_factor(A); x_chol = sla.cho_solve((c, low), b)
for name, x in [("inv", x_inv), ("solve", x_solve), ("cholesky", x_chol)]:
print(name, "residual:", np.linalg.norm(A @ x - b))
inv সাধারণত সামান্য বেশি residual দেয় (বেশি operation, বেশি জমা ভুল), আর Cholesky দ্রুততম। শিক্ষা: well-conditioned matrix-এ পার্থক্য ছোট, কিন্তু ill-conditioned-এ (Problem-এর A-কে Hilbert দিয়ে বদলে দেখো) inv-এর দুর্বলতা স্পষ্ট হয় — তাই অভ্যাসটাই বদলে ফেলো: solve/factor, inv নয়।
Problem 8. Chapter 8.1-এর সাথে সেতু: factorization কি matrix-এর condition number \(\kappa(A)\) কমায়? একটা ill-conditioned matrix-এ LU আর inverse দুটোই ব্যর্থ হবে — এটা কি factorization-এর দোষ, নাকি matrix-এর? ব্যাখ্যা করো।
Solution
না, factorization \(\kappa(A)\) কমায় না। Condition number হলো সমস্যার অন্তর্নিহিত ধর্ম (Chapter 8.1) — matrix কতটা "নড়বড়ে", input-এর ছোট বদল output-এ কত বড় বদল আনে। কোনো algorithm এটা বদলাতে পারে না; factorization শুধু algorithm-এর নিজের অতিরিক্ত ভুল (stability) কমায়।
তাই ill-conditioned matrix-এ (\(\kappa \sim 10^{16}\)) LU-ও ব্যর্থ, inverse-ও — কারণ দোষটা matrix-এর (§২-এর Hilbert ছবি)। তবে দুইয়ের মধ্যে LU/solve কম খারাপ, কারণ কম operation-এ কম stability-ভুল। দুটো আলাদা ধারণা মনে রাখো: conditioning = সমস্যার দোষ (এড়ানো যায় না, শুধু regularization দিয়ে আলাদা সমস্যায় রূপ দেওয়া যায়); stability = algorithm-এর দোষ (ভালো factorization বাছাই করে এড়ানো যায়)। Factorization দ্বিতীয়টা সারায়, প্রথমটা নয়।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "\(Ax = b\) সমাধান মানে \(x = A^{-1}b\) — inverse বের করে গুণ" | কখনো inverse বানিও না। Factor করো (\(LU\)/Cholesky/QR), তারপর substitute — দ্রুততর, বেশি নির্ভুল, আর sparsity বাঁচায়। inv শুধু তত্ত্বের প্রতীক, বাস্তব কোডে প্রায় সবসময় ভুল অভ্যাস। |
| "Factorization মানে matrix-টা সহজ হয়ে গেলো, conditioning সমস্যা মিটলো" | Factorization stability ঠিক করে (algorithm-এর ভুল), কিন্তু \(\kappa(A)\) (সমস্যার ভুল) একটুও কমায় না। ill-conditioned matrix সব solver-কেই হারায় (Problem 8)। |
| "যেকোনো square matrix-এ Cholesky চালানো যায়" | না — Cholesky শুধু SPD-তে। symmetric না হলে বা negative eigenvalue থাকলে বর্গমূলে ভেঙে পড়ে। বরং এই ভেঙে পড়াটাই দ্রুততম SPD-পরীক্ষা (Property 2)। |
| "Least squares মানেই normal equation \(A^TA x = A^Tb\)" | ছোট, well-conditioned সমস্যায় ঠিক আছে, কিন্তু \(A^TA\) condition number বর্গ করে — ill-conditioned-এ বিপর্যয়। QR (বা SVD) সরাসরি \(A\)-তে চালাও, \(A^TA\) বানিও না (Problem 4)। |
| "Sparse matrix-এর inverse বের করলেই তো দ্রুত সমাধান" | Sparse matrix-এর inverse প্রায় সবসময় পুরো dense (§২ ছবি) — memory-তে আঁটবে না। Sparse solver তাই factor করে (sparsity অনেকটা বাঁচে), invert কখনো নয়। |
| "\(n\) দ্বিগুণ হলে খরচ দ্বিগুণ" | \(O(n^3)\) মানে \(n\) দ্বিগুণ হলে খরচ আট গুণ (\(2^3\))। এই তথ্যেই বোঝা যায় কেন dense \(n = 10^6\) অসম্ভব আর sparsity অপরিহার্য (Property 3)। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| মূল দর্শন | invert নয় — factor + substitute | একবার চাবি বানাও, বারবার খোলো |
| LU | \(PA = LU\), খরচ \(\sim \frac{2}{3}n^3\); general square | Gaussian elimination-এর ডায়েরি |
| Cholesky | \(A = LL^T\), খরচ \(\sim \frac{1}{3}n^3\); শুধু SPD | symmetry-র অর্ধেক-দামে উপহার |
| QR | \(A = QR\), খরচ \(\sim 2mn^2\); tall/least squares | orthogonal পথ, condition বর্গ হয় না |
| Triangular solve | \(\sim n^2\); forward/back substitution | factorization-এর পর "প্রায় ফ্রি" |
| Complexity | \(O(n^3)\): \(n\) দ্বিগুণ = খরচ ৮ গুণ | বড় \(n\)-এ sparsity ছাড়া গতি নেই |
| Sparse | factor করে (fill-in এড়িয়ে), invert কখনো নয় | inverse dense বানায়, factor sparse রাখে |
| Iterative (CG) | \(A\) কে factor না করে বারবার গুণ | বিশাল জগতে একমাত্র উপায় |
পরের chapter-এর সেতু: এই chapter-এ আমরা \(Ax = b\) — linear system — দ্রুত ও নিরাপদে সমাধান করা শিখলাম, matrix-কে ত্রিভুজে ভেঙে। কিন্তু linear algebra-র আরেকটা মহাপ্রশ্ন এখনো বাকি: eigenvalue বের করা। Part VI-এ eigenvalue-র তত্ত্ব শিখেছি (\(\det(A - \lambda I) = 0\)), কিন্তু কম্পিউটারে সেই characteristic polynomial-এর মূল বের করা এক দুঃস্বপ্ন (§৮.৩-এ Wilkinson-এর ধাক্কা দেখবে!)। তাহলে Google-এর PageRank বা তোমার PCA আসলে কীভাবে eigenvalue বের করে? উত্তর — power method আর QR algorithm — এই chapter-এর QR factorization-কেই বারবার ঘুরিয়ে। Chapter 8.3-এ।
📓 Notebook Project¶
notebooks/part-08/ch02-project.ipynb — scratch-এ forward/back substitution আর LU factorization লিখে scipy-র সাথে মিলিয়ে দেখা; একই \(A\)-তে বহু \(b\) reuse করে সময় মাপা; Cholesky দিয়ে SPD-পরীক্ষা; আর একটা sparse 2D grid system dense বনাম sparse solver-এ সমাধান করে fill-in ও গতির পার্থক্য চোখে দেখা।