Chapter 1.4 — Norm & Distance (নর্ম ও দূরত্ব)¶
🎯 এই chapter-এ যা শিখবে¶
- Norm(নর্ম) \(\|x\|\) — vector-এর দৈর্ঘ্য মাপার আনুষ্ঠানিক ফিতা, আর তার ৪টি মৌলিক ধর্ম
- Distance(দূরত্ব) \(\|a - b\|\) — দুই vector/point-এর ফারাক; nearest neighbor-এর ভিত্তি
- Cauchy–Schwarz inequality ও Triangle inequality — কেন "শর্টকাটই সবচেয়ে ছোট"
- Norm দিয়ে কোণের পূর্ণ সূত্র: \(\cos\theta = \frac{a^Tb}{\|a\|\|b\|}\) — আগের chapter-এর ধার শোধ
- চমক: পরিসংখ্যানের Standard deviation(স্ট্যান্ডার্ড ডেভিয়েশন) আসলে একটা norm (VMLS-এর সবচেয়ে সুন্দর সংযোগ)
🖼️ এক ছবিতে মূল idea¶
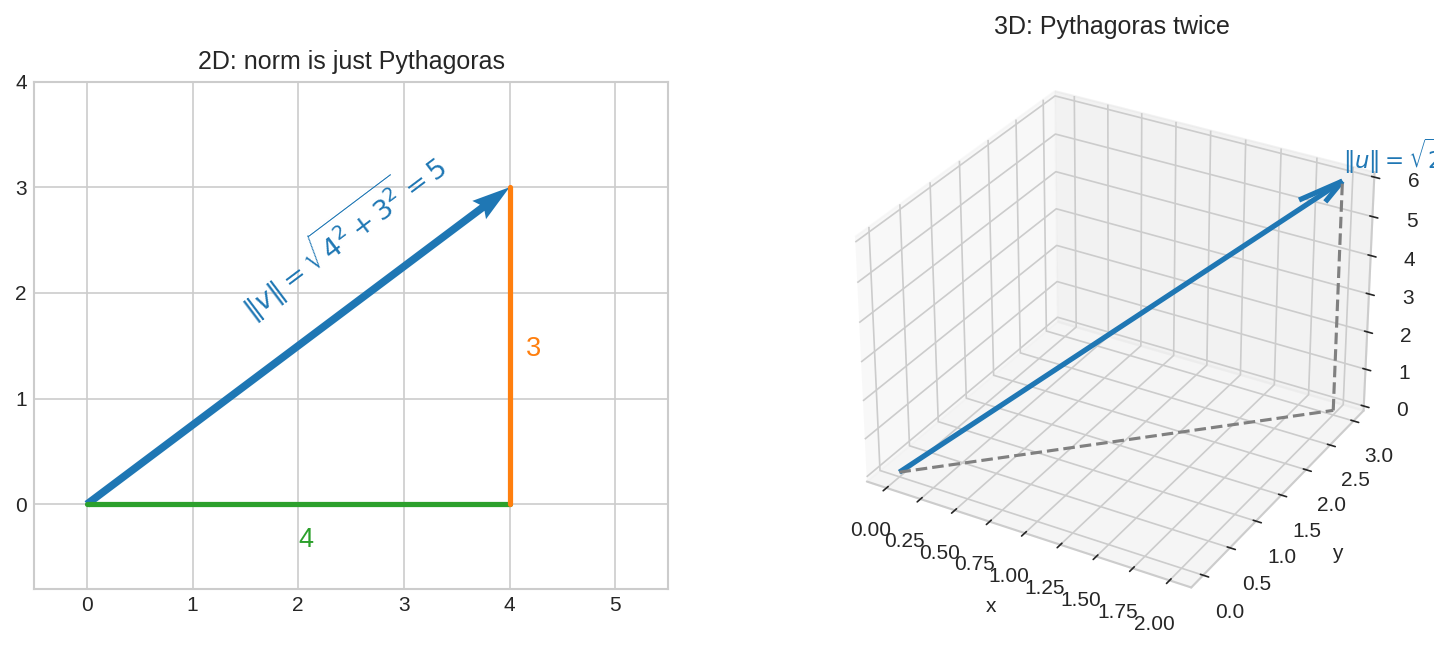
Norm মানে স্রেফ পিথাগোরাস। 2D-তে \(\|(4,3)\| = \sqrt{4^2 + 3^2} = 5\); 3D-তে একই খেলা দুইবার — \(\|(2,3,6)\| = \sqrt{4+9+36} = 7\)। আর \(\mathbb{R}^{100}\)-এ? সূত্র একটুও বদলায় না।
১. কি? (What)¶
দর্জি কাপড় মাপে ফিতায়, আমরা vector মাপবো norm-এ।
আগের chapter-এর শেষ লাইনে ইঙ্গিত দিয়েছিলাম: vector-এর নিজের সাথে dot product \(= a^Ta = a_1^2 + \cdots + a_n^2\) — সবসময় অঋণাত্মক। এর বর্গমূলটাই Euclidean Norm(ইউক্লিডীয় নর্ম):
কেন এটা "দৈর্ঘ্য"? 2D-তে দেখো: \((4, 3)\)-এ পৌঁছাতে ডানে \(4\), উপরে \(3\) — সরাসরি দূরত্ব? পিথাগোরাসের উপপাদ্য: \(\sqrt{4^2 + 3^2} = 5\)। সংজ্ঞাটা ঠিক এটাই বলে। 3D-তে দুইবার পিথাগোরাস (মেঝেতে একবার, উপরে একবার) — ফল \(\sqrt{x_1^2 + x_2^2 + x_3^2}\)। আর \(n\)-dimension-এ আমরা সূত্রটাকেই সংজ্ঞা বানিয়ে নিই।
ছোট উদাহরণ:
\(x\) scalar (1-vector) হলে \(\|x\| = \sqrt{x^2} = |x|\) — norm আসলে absolute value-র বড় ভাই; দুই দাগের \(\|\cdot\|\) চিহ্নটাও তাই এক দাগের \(|\cdot|\)-এর সম্প্রসারণ।
Unit vector(একক ভেক্টর): যার norm ঠিক \(1\)। যেকোনো nonzero \(x\)-কে নিজের norm দিয়ে ভাগ দিলে unit vector পাওয়া যায়: \(\hat{x} = \frac{x}{\|x\|}\) — একে বলে normalize(নর্মালাইজ) করা। \(\hat x\) রাখে শুধু \(x\)-এর দিক, দৈর্ঘ্যের খবর ফেলে দেয়।
আর দুই বিন্দুর ফারাক? আগের chapter-এ শিখেছি \(b - a\) হলো "\(a\) থেকে \(b\)-র arrow" — তার দৈর্ঘ্যই Distance(দূরত্ব):
২. দেখতে কেমন?¶
Norm-এর সবচেয়ে সুন্দর ছবি: norm-\(1\) vector-দের মিছিল — সব দিকে দৈর্ঘ্য-১ arrow ছাড়লে মাথাগুলো মিলে তৈরি হয় unit circle (3D-তে unit sphere):
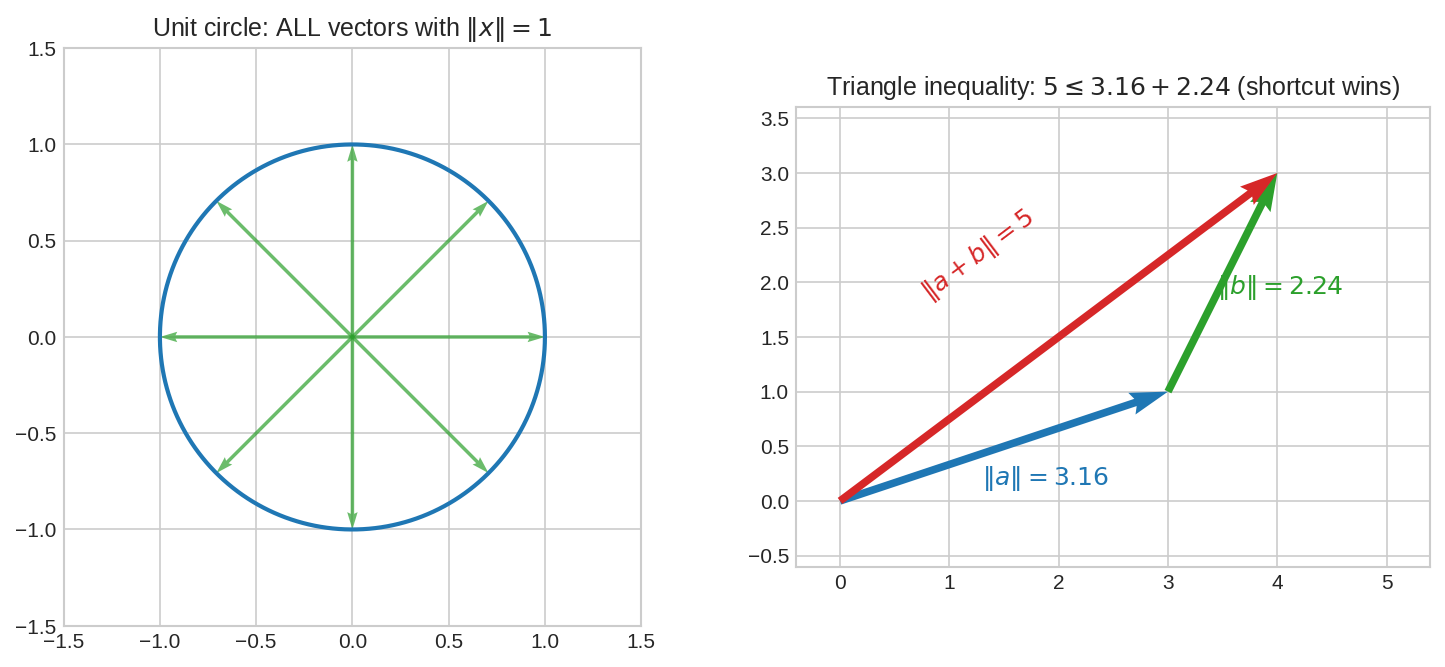
বাঁয়ে: \(\|x\| = 1\) শর্ত মানা সব vector — একটা নিখুঁত বৃত্ত। ডানে: Triangle inequality — origin থেকে সরাসরি \((4,3)\)-এ গেলে \(5\); ঘুরপথে (\(a\) হয়ে \(b\)) \(3.16 + 2.24 = 5.40\)। সরাসরি পথ কখনো বড় হয় না: \(\|a+b\| \le \|a\| + \|b\|\)।
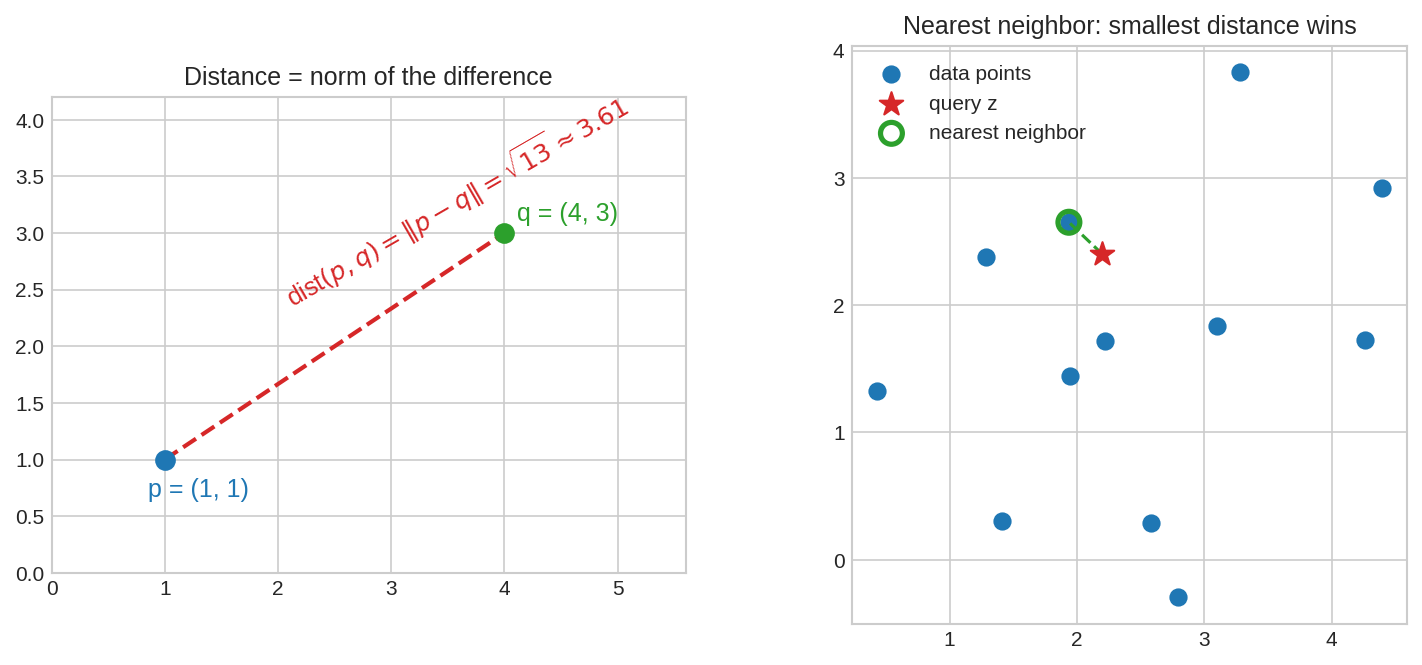
বাঁয়ে: \(p\) থেকে \(q\)-এর দূরত্ব — দাগটানা রেখার দৈর্ঘ্য \(\|p - q\| = \sqrt{13}\)। ডানে: একটা query point \(z\) (তারা) আর একগুচ্ছ data point — যার দূরত্ব সবচেয়ে কম, সেই-ই Nearest Neighbor(নিকটতম প্রতিবেশী), লাল বৃত্তে চিহ্নিত।
৩. কোথায় ইউজ হয়?¶
- RMS value: সিগন্যালের "সাধারণ মাত্রা" \(= \text{rms}(x) = \frac{\|x\|}{\sqrt n}\) — electrical engineering-এর নিত্যসঙ্গী।
- Error মাপা: Model-এর prediction \(\hat y\) আর সত্যি \(y\) — মোট ভুলের মাপ \(\|\hat y - y\|\)। Machine learning-এর "loss function"-দের গোড়ার কথা; Part V-এর least squares এর ওপরেই দাঁড়াবে।
- Nearest neighbor / recommendation: "তোমার মতো ব্যবহারকারীরা আরো কিনেছেন..." — feature space-এ distance মেপে কাছের user খোঁজা। k-nearest-neighbors classifier, k-means clustering (Part VII) — সবার হৃদয়ে \(\|a - b\|\)।
- Standard deviation: ডেটা কতটা ছড়ানো — এই chapter-এর §৫-এ দেখবে এটা de-meaned vector-এর norm। ফলে পরিসংখ্যানের অর্ধেক সূত্র আসলে জ্যামিতি!
- Feature scaling/normalization: ML pipeline-এ vector-দের unit norm-এ আনা হয় যেন দৈর্ঘ্য নয়, দিকটাই কথা বলে (আগের chapter-এর cosine similarity মনে করো)।
- GPS accuracy: "আপনার অবস্থান \(\pm 5\) মিটার" মানে সত্যি অবস্থান আর দেখানো অবস্থানের distance \(\le 5\)।
৪. Properties¶
Euclidean norm-এর চারটি মৌলিক ধর্ম (\(x, y \in \mathbb{R}^n\), scalar \(\beta\)):
| # | Property | সূত্র | ছবি/মানে |
|---|---|---|---|
| ১ | Nonnegative homogeneity | \(\|\beta x\| = \vert \beta\vert \,\|x\|\) | \(2\) গুণ লম্বা করলে দৈর্ঘ্য \(2\) গুণ; \(-2\) গুণেও তাই (\(\vert -2\vert = 2\)) |
| ২ | Triangle inequality | \(\|x + y\| \le \|x\| + \|y\|\) | ঘুরপথ \(\ge\) সরাসরি পথ |
| ৩ | Nonnegativity | \(\|x\| \ge 0\) | দৈর্ঘ্য ঋণাত্মক হয় না |
| ৪ | Definiteness | \(\|x\| = 0 \iff x = \mathbf{0}\) | দৈর্ঘ্যহীন একমাত্র zero vector |
১, ৩, ৪ সংজ্ঞা থেকেই সোজা। যেমন ৪-এর মিনি-derivation: \(\|x\| = 0 \Rightarrow x_1^2 + \cdots + x_n^2 = 0\); অঋণাত্মক সংখ্যাদের যোগফল শূন্য হলে প্রত্যেকে শূন্য, তাই \(x = \mathbf 0\)। \(\blacksquare\)
২ নম্বরটা (triangle inequality) গভীর — তার চাবি হলো Linear Algebra-র অন্যতম বিখ্যাত অসমতা, Cauchy–Schwarz inequality:
("ছায়া কখনো আসলের চেয়ে লম্বা না" — dot product কখনো দৈর্ঘ্যদ্বয়ের গুণফল ছাড়াতে পারে না।) এটা মানলে triangle inequality দু-লাইনে নেমে আসে:
দুই পাশে বর্গমূল নিলেই শেষ। (মাঝের ধাপে distributivity ব্যবহার করেছি — আগের chapter-এর property টেবিল ফল দিতে শুরু করেছে!)
আর distance-এর ধর্মগুলো norm থেকেই নামে: \(\text{dist}(a,b) \ge 0\); \(\text{dist}(a,b) = 0 \iff a = b\); \(\text{dist}(a,b) = \text{dist}(b,a)\); এবং \(\text{dist}(a,c) \le \text{dist}(a,b) + \text{dist}(b,c)\) — ঢাকার থেকে চট্টগ্রাম, কুমিল্লা হয়ে গেলে ছোট হয় না।
কোণের সূত্রের ধার শোধ: আগের chapter-এ কথা দিয়েছিলাম। Cosine rule (ত্রিকোণমিতি) বলে: \(\|a - b\|^2 = \|a\|^2 + \|b\|^2 - 2\|a\|\|b\|\cos\theta\)। আবার বীজগণিতে: \(\|a-b\|^2 = \|a\|^2 + \|b\|^2 - 2\,a^Tb\)। দুটো মিলালেই:
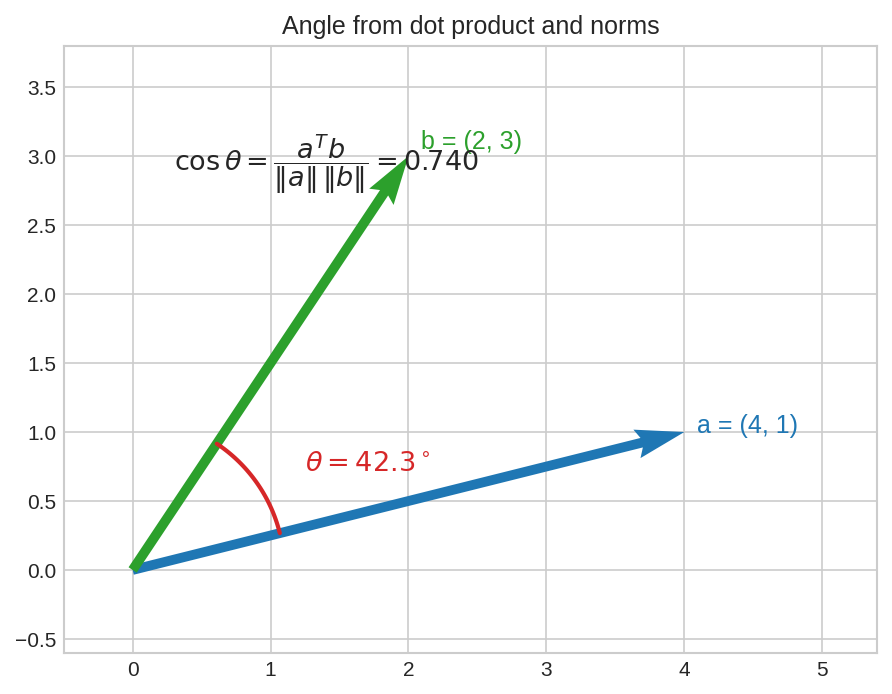
\((4,1)\) আর \((2,3)\)-এর মাঝের কোণ: \(\cos\theta = \frac{11}{\sqrt{17}\sqrt{13}} \approx 0.740\), তাই \(\theta \approx 42.3°\)। Dot product + দুটো norm = যেকোনো dimension-এ কোণ।
৫. Intuition — কেন সত্য?¶
Standard deviation-এর গোপন পরিচয় — এই chapter-এর সবচেয়ে বড় "আহা!" মুহূর্ত।
ধরো ১৬ দিনের তাপমাত্রা-vector \(x \in \mathbb{R}^{16}\)। গড় \(\mu = \frac{\mathbf 1^T x}{n}\) (dot product দিয়ে — চেনা লাগছে?)। এবার প্রতিদিনের মান থেকে গড় বাদ দাও — পাও de-meaned vector:
\(\tilde x\)-এর entry-গুলো হলো "গড়ের চেয়ে কত ওপরে/নিচে"। এখন পরিসংখ্যানের সংজ্ঞা মনে করো — standard deviation \(= \sqrt{\frac{1}{n}\sum_i (x_i - \mu)^2}\)। কিন্তু \(\sum_i (x_i - \mu)^2\) তো ঠিক \(\|\tilde x\|^2\)! তাই:
Standard deviation = de-meaned vector-এর (স্কেল করা) দৈর্ঘ্য। ডেটা যত ছড়ানো, \(\tilde x\) arrow-টা তত লম্বা — ব্যস, এটুকুই। "ছড়িয়ে থাকা" নামের ঝাপসা ধারণাটা এক লহমায় জ্যামিতিক দৈর্ঘ্য হয়ে গেল।
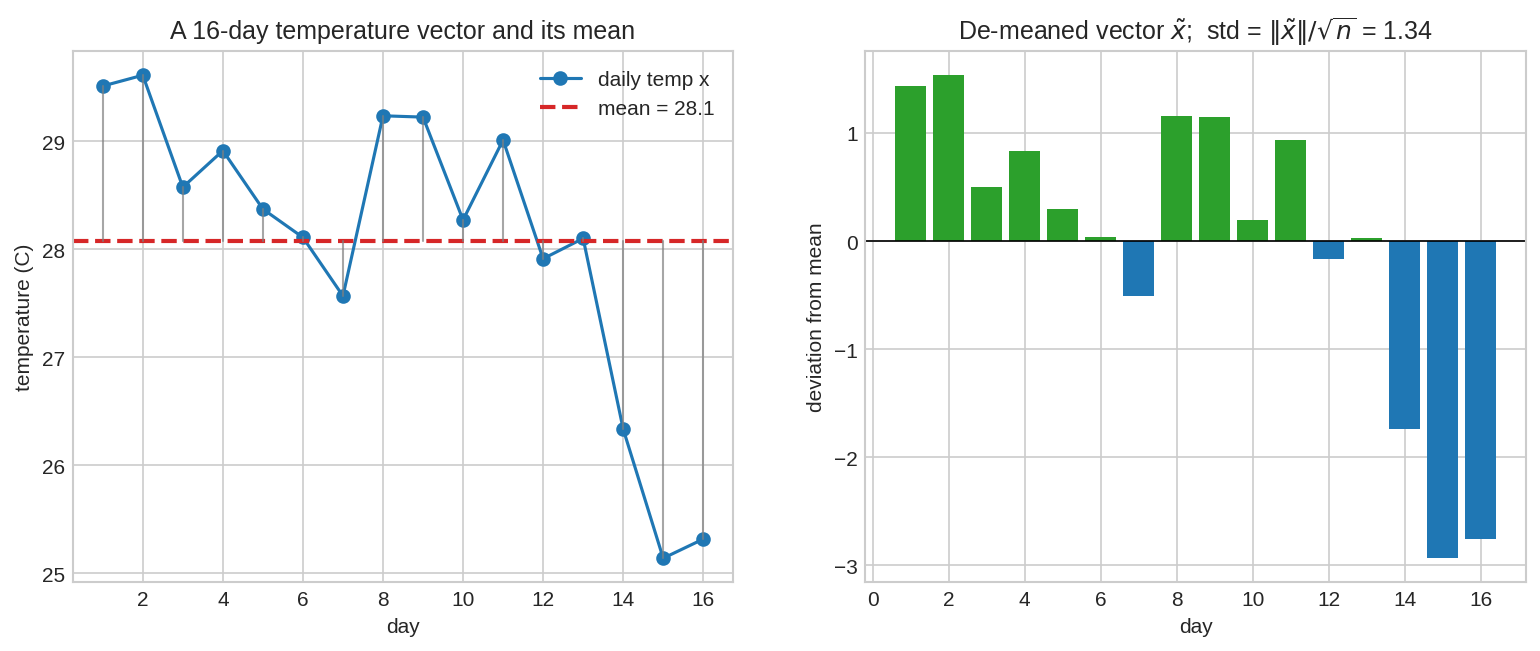
বাঁয়ে: ১৬ দিনের তাপমাত্রা আর তার গড়-রেখা; ধূসর খাড়া দাগগুলো deviation। ডানে: deviation-গুলোকে আলাদা করে সাজালে যে vector হয় (\(\tilde x\)), তার norm-কে \(\sqrt{n}\) দিয়ে ভাগ দিলেই std। পরিসংখ্যান = জ্যামিতি, এক ছবিতে।
(আরো মজা: Chapter 1.3-এর cosine-কে দুটি de-meaned vector-এর ওপর খাটালে যেটা পাও, পরিসংখ্যানে তার নাম correlation coefficient — VMLS ch 3-এর হিরে। Notebook-এ এটা নিজে আবিষ্কার করবে।)
Cauchy–Schwarz কেন বিশ্বাসযোগ্য? \(a^Tb = \|a\|\|b\|\cos\theta\) আর \(|\cos\theta| \le 1\) — geometric চশমায় অসমতাটা প্রায় স্বতঃসিদ্ধ। ছায়া (projection) মূল vector-এর চেয়ে লম্বা হবে কী করে? সমান হয় কেবল তখনই, যখন ছায়াটাই পুরো vector — মানে \(a\) আর \(b\) একই লাইনে (\(\theta = 0°\) বা \(180°\))। এই "সমতা কখন" প্রশ্নটা Chapter 1.5-এ linear dependence-এর সাথে জুড়ে যাবে।
৬. Code-এ কেমনে লিখে¶
import numpy as np
x = np.array([2., -1., 2.])
# norm — তিনভাবে
print(np.linalg.norm(x)) # 3.0 <- standard উপায়
print(np.sqrt(x @ x)) # 3.0 <- সংজ্ঞা: sqrt(x^T x)
print(np.sqrt(np.sum(x**2))) # 3.0 <- একদম হাতে খোলা
# normalize: দিক রেখে দৈর্ঘ্য ১
x_hat = x / np.linalg.norm(x)
print(x_hat) # [ 0.667 -0.333 0.667]
print(np.linalg.norm(x_hat)) # 1.0 (unit vector!)
# distance
p = np.array([1., 1.]); q = np.array([4., 3.])
print(np.linalg.norm(p - q)) # 3.606 = sqrt(13)
# কোণ (radians ও degrees)
a = np.array([4., 1.]); b = np.array([2., 3.])
cos_t = (a @ b) / (np.linalg.norm(a) * np.linalg.norm(b))
theta = np.arccos(cos_t)
print(np.degrees(theta)) # 42.27...
# standard deviation = norm of de-meaned / sqrt(n)
np.random.seed(42)
temps = 30 + np.cumsum(np.random.randn(16)) * 0.9
mu = temps.mean()
dev = temps - mu # de-meaned vector
std_via_norm = np.linalg.norm(dev) / np.sqrt(len(temps))
print(std_via_norm) # 1.0159...
print(temps.std()) # 1.0159... একই!
শেষ দুই লাইন দেখো — আমাদের জ্যামিতিক সূত্র আর NumPy-র built-in std() অক্ষরে অক্ষরে মিললো। কোনো কাকতালীয় নয়; আমরা এইমাত্র প্রমাণটা কোডে যাচাই করলাম।
Nearest neighbor তিন লাইনে:
data = np.random.randn(12, 2) * 1.2 + np.array([2.5, 2.0]) # ১২টি point
z = np.array([2.2, 2.4]) # query
dists = np.linalg.norm(data - z, axis=1) # সবগুলোর সাথে distance একসাথে!
print(np.argmin(dists)) # সবচেয়ে কাছের point-এর index
axis=1 মানে "প্রতিটি সারির norm আলাদা করে" — NumPy-র broadcasting এক লাইনে ১২টা বিয়োগ ও ১২টা norm করে দিলো।
৭. Worked Examples¶
Example 1 — norm ও normalize। \(v = (3, -4)\)-এর norm বের করে unit vector বানাও।
ধাপ ১: \(\|v\| = \sqrt{9 + 16} = \sqrt{25} = 5\)। ধাপ ২: \(\hat v = \frac{1}{5}(3, -4) = (0.6, -0.8)\)। যাচাই: \(\|\hat v\| = \sqrt{0.36 + 0.64} = 1\) ✓। দিক অটুট: \(\hat v\)-ও ডানে-নিচে।
Example 2 — কোন দোকান কাছে? তুমি আছো \(z = (2, 3)\)-এ; দোকান A আছে \((5, 7)\)-এ, দোকান B \((6, 1)\)-এ। (দূরত্ব সোজা লাইনে।)
ধাপ ১: \(\text{dist}(z, A) = \|(5-2, 7-3)\| = \|(3,4)\| = 5\)। ধাপ ২: \(\text{dist}(z, B) = \|(4, -2)\| = \sqrt{20} \approx 4.47\)। উত্তর: দোকান B সামান্য কাছে। — এটাই nearest neighbor-এর পুরো algorithm, দুটো প্রার্থীর বেলায়।
Example 3 — std হাতে-কলমে। ৫ দিনের বিক্রি \(x = (10, 12, 8, 14, 6)\) (হাজার টাকায়)। Norm-এর সূত্র দিয়ে standard deviation।
ধাপ ১: গড় \(\mu = \frac{10+12+8+14+6}{5} = 10\)। ধাপ ২: de-meaned: \(\tilde x = (0, 2, -2, 4, -4)\)। ধাপ ৩: \(\|\tilde x\| = \sqrt{0 + 4 + 4 + 16 + 16} = \sqrt{40}\)। ধাপ ৪: \(\text{std} = \frac{\sqrt{40}}{\sqrt 5} = \sqrt 8 \approx 2.83\) হাজার টাকা। বিক্রি সাধারণত গড়ের \(\pm 2.83\) হাজারের মধ্যে দোলে — আর পুরোটা বের হলো একটা norm থেকে।
৮. Problems ও Solutions¶
Problem 1. Norm বের করো: (ক) \((6, 8)\); (খ) \((1, 1, 1, 1)\); (গ) \((2, -3, 6)\); (ঘ) \(0.5 \times (6, 8)\) — (ঘ)-তে property ১ ব্যবহার করে শর্টকাটে।
Solution
(ক) \(\sqrt{36+64} = 10\)। (খ) \(\sqrt{4} = 2\)। (মজা: \(\mathbb{R}^n\)-এর ones vector-এর norm \(\sqrt n\) — dimension বাড়লে কর্ণ লম্বা হয়!) (গ) \(\sqrt{4+9+36} = \sqrt{49} = 7\)। (ঘ) Property ১: \(\|0.5\,x\| = 0.5\|x\| = 0.5 \times 10 = 5\) — নতুন করে বর্গ-যোগ লাগলোই না।
Problem 2. \(a = (1, 2, -2)\): (ক) \(\hat a\) বের করো; (খ) \(-3a\)-এর norm property দিয়ে; (গ) \(a\)-এর দিকে দৈর্ঘ্য-\(6\) vector কোনটা?
Solution
(ক) \(\|a\| = \sqrt{1+4+4} = 3\); \(\hat a = \left(\frac13, \frac23, -\frac23\right)\)। (খ) \(\|-3a\| = |-3| \cdot 3 = 9\)। (গ) \(6\hat a = (2, 4, -4)\) — unit vector-কে কাঙ্ক্ষিত দৈর্ঘ্য দিয়ে গুণ; যাচাই: \(\|(2,4,-4)\| = \sqrt{4+16+16} = 6\) ✓।
Problem 3. তিন বন্ধুর ফোনের location: রনি \((0, 0)\), শুভ \((6, 8)\), আলো \((3, 3)\)। (ক) কে কার কাছে? সব জোড়ার দূরত্ব বের করো। (খ) triangle inequality এখানে কী বলে — রনি→শুভ সরাসরি বনাম আলো হয়ে?
Solution
(ক) রনি–শুভ: \(\|(6,8)\| = 10\)। রনি–আলো: \(\|(3,3)\| = \sqrt{18} \approx 4.24\)। শুভ–আলো: \(\|(3,5)\| = \sqrt{34} \approx 5.83\)। সবচেয়ে কাছের জোড়া: রনি–আলো। (খ) সরাসরি \(10\); ঘুরপথে \(4.24 + 5.83 = 10.07 \ge 10\) ✓ — triangle inequality টিকে গেল (প্রায় সমান, কারণ আলো প্রায় রনি-শুভর লাইনের ওপরেই)।
Problem 4. Cauchy–Schwarz যাচাই করো \(a = (3, 4)\), \(b = (5, 12)\) দিয়ে: \(|a^Tb|\) আর \(\|a\|\|b\|\) আলাদা করে বের করে তুলনা করো। সমতা হয়নি কেন?
Solution
\(a^Tb = 15 + 48 = 63\)। \(\|a\| = 5\), \(\|b\| = 13\), গুণফল \(65\)। \(63 \le 65\) ✓। সমতা হয়নি কারণ \(a\) ও \(b\) ঠিক এক লাইনে নেই — \((5,12)\) কি \((3,4)\)-এর গুণিতক? \(5/3 \neq 12/4\) — না। কোণটা ছোট কিন্তু শূন্য নয় (\(\cos\theta = 63/65 \approx 0.969\), \(\theta \approx 14.25°\))।
Problem 5. \(x = (4, 8, 6, 2)\) — চার সপ্তাহের অনলাইন কোর্স-ভিউ (হাজারে)। Norm-সূত্র দিয়ে (ক) গড়; (খ) de-meaned vector; (গ) standard deviation বের করো।
Solution
(ক) \(\mu = \frac{\mathbf 1^Tx}{4} = \frac{20}{4} = 5\)। (খ) \(\tilde x = x - 5\cdot\mathbf 1 = (-1, 3, 1, -3)\)। (যাচাই: entry-গুলোর যোগ \(0\) — de-meaned vector-এর যোগফল সবসময় শূন্য!) (গ) \(\|\tilde x\| = \sqrt{1+9+1+9} = \sqrt{20}\); \(\text{std} = \frac{\sqrt{20}}{\sqrt 4} = \frac{\sqrt{20}}{2} = \sqrt 5 \approx 2.24\) হাজার ভিউ।
Problem 6. \(u = (1, 2)\) ও \(v = (3, k)\)। \(k\)-এর কোন মানে (ক) \(u \perp v\); (খ) \(\theta = 0°\) (একই দিক); (গ) \(\text{dist}(u, v) = \sqrt 5\)?
Solution
(ক) \(u^Tv = 3 + 2k = 0 \Rightarrow k = -1.5\)। (খ) একই দিক মানে \(v = \beta u\), \(\beta > 0\): \(3 = \beta \cdot 1 \Rightarrow \beta = 3\), তাই \(k = 6\)। (গ) \(\|u - v\|^2 = (1-3)^2 + (2-k)^2 = 4 + (2-k)^2 = 5 \Rightarrow (2-k)^2 = 1 \Rightarrow k = 1\) বা \(k = 3\) — দুটোই বৈধ! (দূরত্বের শর্ত বৃত্ত আঁকে, আর বৃত্ত সরলরেখাকে দুই জায়গায় কাটতে পারে।)
Problem 7. সত্য/মিথ্যা — কারণসহ: (ক) \(\|a + b\| = \|a\| + \|b\|\) হতে পারে; (খ) \(\|a - b\| \ge \big|\|a\| - \|b\|\big|\); (গ) \(\|a\| = \|b\|\) হলে \(a = \pm b\); (ঘ) normalize করলে যেকোনো দুটি vector-এর দূরত্ব \(\le 2\) হয়ে যায়।
Solution
(ক) সত্য — যখন \(a, b\) একই দিকে (যেমন \(b = 2a\), \(a \ne \mathbf 0\)): \(\|3a\| = 3\|a\| = \|a\| + \|2a\|\)। ত্রিভুজটা তখন চ্যাপ্টা হয়ে সরলরেখা। (খ) সত্য। Triangle inequality-র উল্টো পিঠ (reverse triangle inequality): \(\|a\| = \|(a-b) + b\| \le \|a-b\| + \|b\|\), তাই \(\|a\| - \|b\| \le \|a - b\|\); \(a,b\) অদল-বদল করে অন্য দিকটাও। (গ) মিথ্যা। \((1, 0)\) আর \((0, 1)\) — norm দুটোই \(1\), কিন্তু \(\pm\) সম্পর্ক নেই। সমান দৈর্ঘ্যের arrow অগুনতি দিকে থাকতে পারে (unit circle মনে করো!)। (ঘ) সত্য। Unit vector-রা থাকে unit circle/sphere-এর ওপর; দুই unit vector-এর সর্বোচ্চ দূরত্ব ব্যাসের সমান \(= 2\) (ঠিক বিপরীত মেরুতে হলে): \(\|\hat a - \hat b\| \le \|\hat a\| + \|\hat b\| = 2\)।
Problem 8 (চ্যালেঞ্জ)। RMS deviation দিয়ে prediction তুলনা: সত্যি মান \(y = (10, 20, 30, 40)\); Model A দিলো \(\hat y_A = (12, 18, 33, 39)\), Model B দিলো \(\hat y_B = (10, 25, 30, 35)\)। (ক) দুই model-এর error-vector ও error-norm বের করো। (খ) RMS error (\(= \|e\|/\sqrt n\)) কার কম? (গ) B-এর সবচেয়ে বড় একক ভুল A-এর চেয়ে বড়, তবু জিতলো কে — এ থেকে কী শিখলে?
Solution
(ক) \(e_A = \hat y_A - y = (2, -2, 3, -1)\), \(\|e_A\| = \sqrt{4+4+9+1} = \sqrt{18} \approx 4.24\)। \(e_B = (0, 5, 0, -5)\), \(\|e_B\| = \sqrt{50} \approx 7.07\)। (খ) RMS: A-এর \(\sqrt{18}/2 \approx 2.12\); B-এর \(\sqrt{50}/2 \approx 3.54\)। Model A জয়ী। (গ) B দুটো জায়গায় নিখুঁত ছিল, কিন্তু বাকি দুটোয় বড় ভুল (\(\pm 5\)) করেছে; norm ভুলগুলোকে বর্গ করে বলে বড় ভুলকে বেশি শাস্তি দেয়। শিক্ষা: Euclidean norm "মাঝেমধ্যে বিশাল ভুল"-এর চেয়ে "সবসময় ছোট ভুল" পছন্দ করে — least squares-এর (Part V) দর্শনের প্রথম ঝলক।
৯. Common ভুল¶
- \(\|x\|\)-কে entry-র যোগফল ভাবা — \(\|(3, 4)\| = 7\) নয়, \(5\)। আগে বর্গ, তারপর যোগ, শেষে বর্গমূল। (যোগফল-ভিত্তিক মাপও আছে — \(\ell_1\) norm — কিন্তু সে অন্য ফিতা, অন্য গল্প।)
- \(\|a - b\|\) আর \(\|a\| - \|b\|\) গুলিয়ে ফেলা — প্রথমটা দূরত্ব, দ্বিতীয়টা দৈর্ঘ্যের ফারাক। \((1,0)\) আর \((0,1)\): দূরত্ব \(\sqrt 2\), কিন্তু norm-এর ফারাক \(0\)!
- Zero vector normalize করতে যাওয়া — \(\frac{\mathbf 0}{\|\mathbf 0\|} = \frac{\mathbf 0}{0}\) — অসংজ্ঞায়িত! কোডে
nan-এর বন্যা। Normalize-এর আগে সবসময় \(\|x\| > 0\) যাচাই। - \(\|x\|^2\) আর \(\|x\|\) অদল-বদল — হিসাবের মাঝে বর্গমূল "পরে নেবো" বলে ভুলে যাওয়া ক্লাসিক। মনে রাখো: \(x^Tx = \|x\|^2\) — dot product দেয় norm-এর বর্গ।
- Std-তে \(n\) না \(\sqrt n\) — \(\text{std} = \|\tilde x\| / \sqrt{n}\), ভাগটা \(\sqrt n\) দিয়ে (\(n\) দিয়ে নয়!)। কারণ বর্গের গড়ের ভেতরে \(n\), বাইরে এসে সে \(\sqrt n\)। (আর পরিসংখ্যান বইয়ের \(n-1\) সংস্করণটা sample std — সে গল্প Statistics কোর্সের।)
১০. এক নজরে¶
| ধারণা | সূত্র | মানে |
|---|---|---|
| Norm | \(\|x\| = \sqrt{x^Tx}\) | vector-এর দৈর্ঘ্য |
| Unit vector | \(\hat x = x/\|x\|\) | দিক এক, দৈর্ঘ্য ১ |
| Distance | \(\text{dist}(a,b) = \|a-b\|\) | দুই point-এর ফারাক |
| Cauchy–Schwarz | \(\vert a^Tb\vert \le \|a\|\|b\|\) | ছায়া \(\le\) আসল |
| Triangle inequality | \(\|a+b\| \le \|a\| + \|b\|\) | শর্টকাট সবচেয়ে ছোট |
| কোণ | \(\theta = \arccos\frac{a^Tb}{\|a\|\|b\|}\) | যেকোনো dimension-এ |
| RMS | \(\|x\|/\sqrt n\) | "সাধারণ" entry-মাপ |
| Standard deviation | \(\|x - \mu\mathbf 1\|/\sqrt n\) | ছড়ানো = দৈর্ঘ্য |
পরের chapter-এর সেতু: এখন তুমি vector মাপতে পারো, মেশাতে পারো, তুলনা করতে পারো। শেষ প্রশ্নটা সবচেয়ে দার্শনিক: কয়েকটা vector হাতে থাকলে তাদের মিশিয়ে কোথায় কোথায় পৌঁছানো যায়? উত্তরের নাম Span — আর সেখানেই Part I-এর climax।
📓 Notebook Project¶
notebooks/part-01/ch04-project.ipynb — scratch-এ norm/distance লিখে NumPy-র সাথে মিলাও, synthetic ২D data-তে nearest-neighbor classifier বানাও, আর তাপমাত্রা-data দিয়ে "std = norm" পরিচয়টা নিজের চোখে যাচাই করো।