Chapter 7.2 — Multi-objective & Regularized Least Squares (মাল্টি-অবজেক্টিভ ও রেগুলারাইজড লিস্ট স্কোয়ার্স — Ridge Regression)¶
Chapter 7.1-এর শেষে একটা কাঁটা রেখে গিয়েছিলাম: feature বাড়ালে training-এ classifier নিখুঁত, বাস্তবে ধোঁকা — overfitting(ওভারফিটিং)। আজ তার ওষুধ। এতদিন least squares-এর কাছে চাওয়া ছিল একটাই: "data-র সাথে যত ভালো মেলানো যায়"। আজ আমরা একসাথে দুটো চাওয়া রাখবো — "data-র সাথে মেলাও, কিন্তু \(x\)-কেও ছোট রাখো"। দুই নৌকায় পা দেওয়ার এই গণিতই multi-objective least squares, আর তার সবচেয়ে বিখ্যাত সন্তান Ridge Regression(রিজ রিগ্রেশন)। মজার কথা: নতুন কোনো solver লাগবে না — Part V-এর সেই stacked-matrix চালাকিটাই যথেষ্ট।
🎯 এই chapter-এ যা শিখবে¶
- Multi-objective (bi-criterion) least squares: \(J_1 + \lambda J_2\) — দুটো লক্ষ্যকে একটা weight \(\lambda\) দিয়ে মেশানো
- Optimal trade-off curve(অপটিমাল ট্রেড-অফ কার্ভ) ও Pareto optimal(পারেটো অপটিমাল) বিন্দুর মানে — "একটা ভালো করতে গেলে অন্যটা খারাপ"
- Ridge Regression / Tikhonov Regularization(টিখোনভ রেগুলারাইজেশন): \(\|Ax-b\|^2 + \lambda\|x\|^2\) কেন overfitting থামায়
- Ridge-এর বন্ধ-রূপ সমাধান \(\hat{x} = (A^TA + \lambda I)^{-1}A^Tb\) — আর কেন এটা সবসময় invertible
- Bias-variance trade-off(বায়াস-ভ্যারিয়েন্স ট্রেড-অফ): \(\lambda\) ছোট = over-fit, বড় = under-fit, মাঝে = সোনার হরিণ; validation দিয়ে খুঁজে বের করা
🖼️ এক ছবিতে মূল idea¶
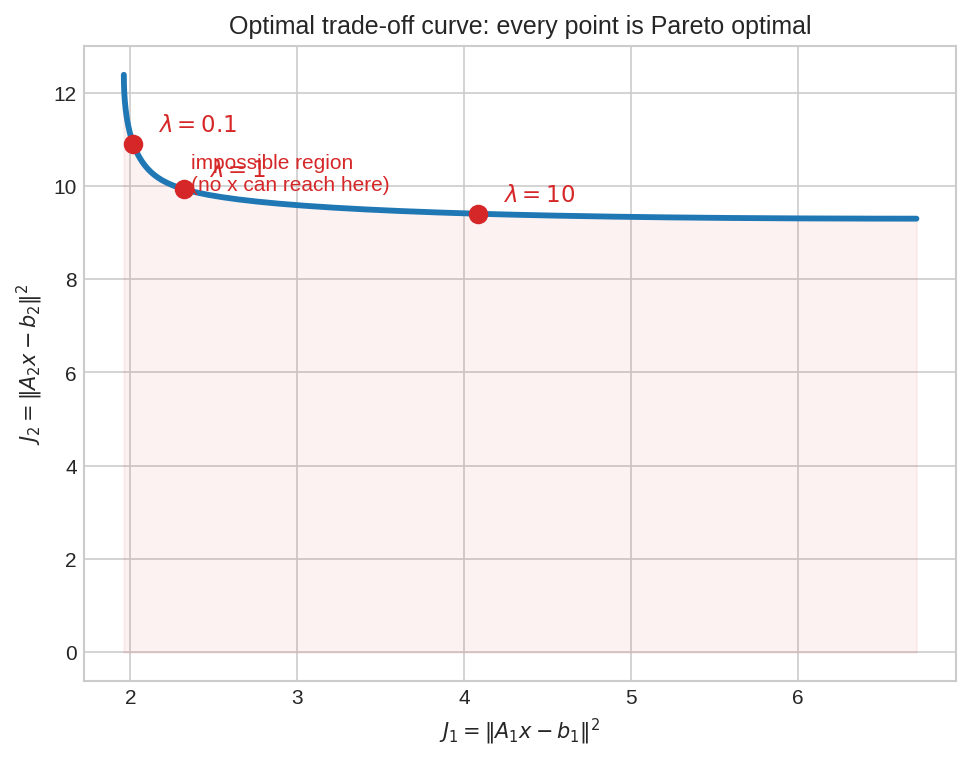
দুটো লক্ষ্য \(J_1\) (আনুভূমিক) আর \(J_2\) (উল্লম্ব)। প্রতিটা \(\lambda\)-র জন্য এক-একটা \(\hat{x}\), আর তার দুটো error মিলে বক্ররেখার একটা বিন্দু। বাঁ-নিচের লাল অঞ্চলটা অসম্ভব — কোনো \(x\)-ই একসাথে দুটো error এত ছোট করতে পারে না। বক্ররেখার ওপরের প্রতিটা বিন্দু Pareto optimal: \(J_1\) কমাতে চাইলে \(J_2\) বাড়াতেই হবে, আর উল্টোটাও। \(\lambda\) ঘোরানো মানে এই বক্ররেখা ধরে হাঁটা।
১. কি? (What)¶
দৈনন্দিন analogy: রান্নায় নুন¶
ভাবো তুমি রান্না করছো। একটা লক্ষ্য — স্বাদ ভালো হোক (নুন দাও, মশলা দাও)। আরেকটা লক্ষ্য — স্বাস্থ্যকর হোক (নুন কমাও)। এই দুটো লক্ষ্য পরস্পরবিরোধী: বেশি নুন = বেশি স্বাদ কিন্তু কম স্বাস্থ্য। তুমি মনে মনে একটা "গুরুত্বের ওজন" ঠিক করো — অতিথি এলে স্বাদকে বেশি ওজন দাও, রোগী হলে স্বাস্থ্যকে। এই ওজনটাই \(\lambda\)।
Part V-এর plain least squares-এ আমাদের লক্ষ্য ছিল একটাই: residual \(\|Ax-b\|^2\) ছোট করা, অর্থাৎ prediction যেন data-র কাছাকাছি থাকে। কিন্তু বাস্তবে আরেকটা জিনিসও চাই — parameter vector \(x\) যেন খুব বড় বা বুনো না হয়। কেন? বড় parameter মানে model অতি-সংবেদনশীল: input-এ সামান্য নড়াচড়ায় output লাফায়, আর সেটাই overfitting-এর লক্ষণ।
সংজ্ঞা: Bi-criterion least squares¶
দুটো objective:
দুটোকেই একসাথে ছোট করতে চাই। কিন্তু "দুটো জিনিস একসাথে minimize" গণিতের ভাষায় অস্পষ্ট — একটা কমাতে গেলে অন্যটা বাড়তে পারে। সমাধান: একটা weighted sum(ওয়েটেড সাম) বানাও, একটা positive weight \(\lambda > 0\) দিয়ে:
\(\lambda\) ছোট হলে \(J_1\)-কে বেশি পাত্তা দিচ্ছি, বড় হলে \(J_2\)-কে। \(\lambda\) একটা knob — ঘোরাও, দেখো কী পাও।
Ridge Regression: সবচেয়ে বিখ্যাত বিশেষ কেস¶
দ্বিতীয় objective-কে যদি বসাই "\(x\)-কে শূন্যের কাছে রাখো" — অর্থাৎ \(A_2 = I\), \(b_2 = 0\), তখন \(J_2 = \|x\|^2\):
এটাই Ridge Regression (বা Tikhonov regularization, বা \(\ell_2\)-regularized least squares)। প্রথম পদ বলে "data-র সাথে মেলাও", দ্বিতীয় পদ বলে "parameter ছোট রাখো"। দ্বিতীয় পদটাকে বলে Regularization Term(রেগুলারাইজেশন টার্ম) বা penalty — এটা model-এর জটিলতার ওপর জরিমানা বসায়। \(\lambda\)-কে বলে Regularization Parameter।
২. দেখতে কেমন?¶
দৃশ্য ১: coefficient-দের সংকোচন-পথ¶
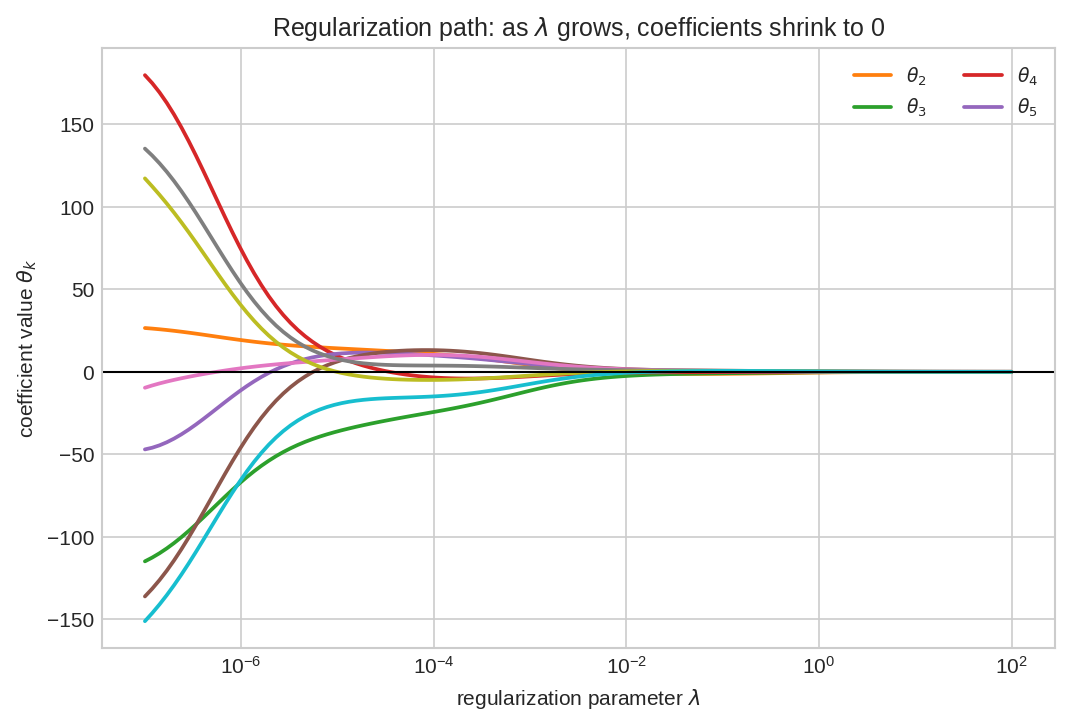
আনুভূমিক অক্ষ \(\lambda\) (log scale), উল্লম্ব অক্ষ প্রতিটা coefficient \(\theta_k\)-র মান। বাঁ দিকে (\(\lambda\) ছোট) coefficient-গুলো বড় ও এলোমেলো — model বুনো। ডানে যেতে যেতে (\(\lambda\) বাড়ে) সব coefficient টান খেয়ে শূন্যের দিকে সংকুচিত হয়। এই বক্ররেখাগুলোকে বলে regularization path — একবার হিসাব করলে সব \(\lambda\)-র উত্তর একসাথে পাওয়া যায়।
দৃশ্য ২: train আর test error-এর ভিন্ন গল্প¶
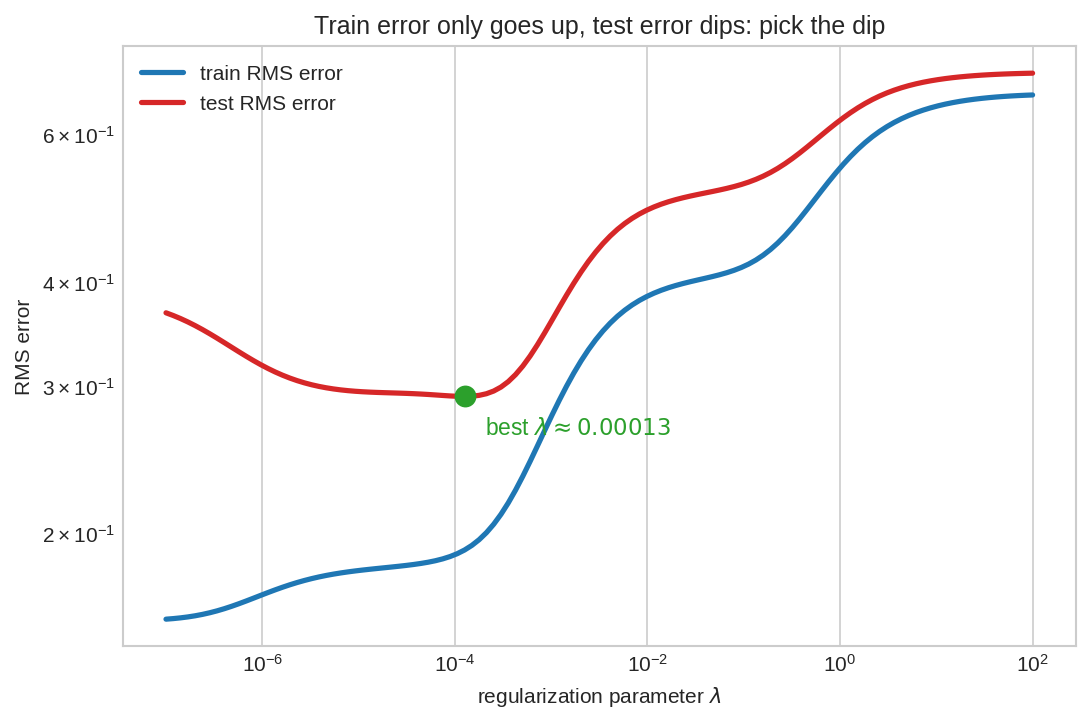
নীল রেখা = training error, লাল = test error (দুটোই log-log)। খেয়াল করো — training error একঘেয়েভাবে শুধু বাড়ে যত \(\lambda\) বাড়াও (স্বাভাবিক, কারণ আমরা fit-এর স্বাধীনতা কমাচ্ছি)। কিন্তু test error আগে কমে, তলানিতে পৌঁছে, তারপর বাড়ে — সবুজ বিন্দুটাই সেই সোনার \(\lambda\)। বাঁয়ে overfitting, ডানে underfitting, মাঝে ভারসাম্য।
দৃশ্য ৩: এক data, তিন \(\lambda\) — bias-variance এক ছবিতে¶
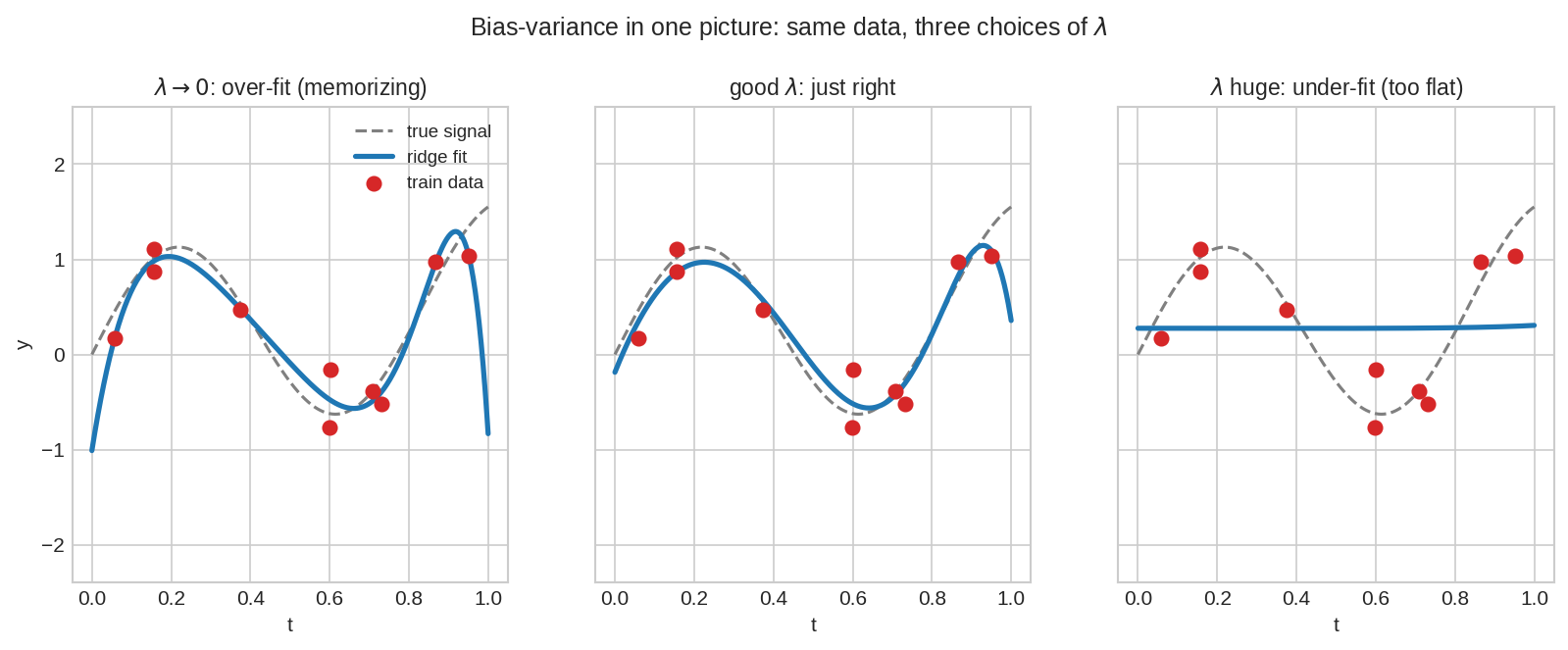
একই ১০টা training বিন্দু, একই degree-9 polynomial, শুধু \(\lambda\) আলাদা। বাঁয়ে (\(\lambda \to 0\)): বক্ররেখা প্রতিটা বিন্দুর ওপর দিয়ে বুনোভাবে ঢেউ খেলে যাচ্ছে — memorize করছে, noise-ও ধরছে। ডানে (\(\lambda\) বিশাল): এত সোজা যে আসল signal-ই মিস করছে — under-fit। মাঝেরটা true signal (ধূসর ড্যাশ)-এর সবচেয়ে কাছে — just right।
দৃশ্য ৪: shrinkage-এর জ্যামিতি¶
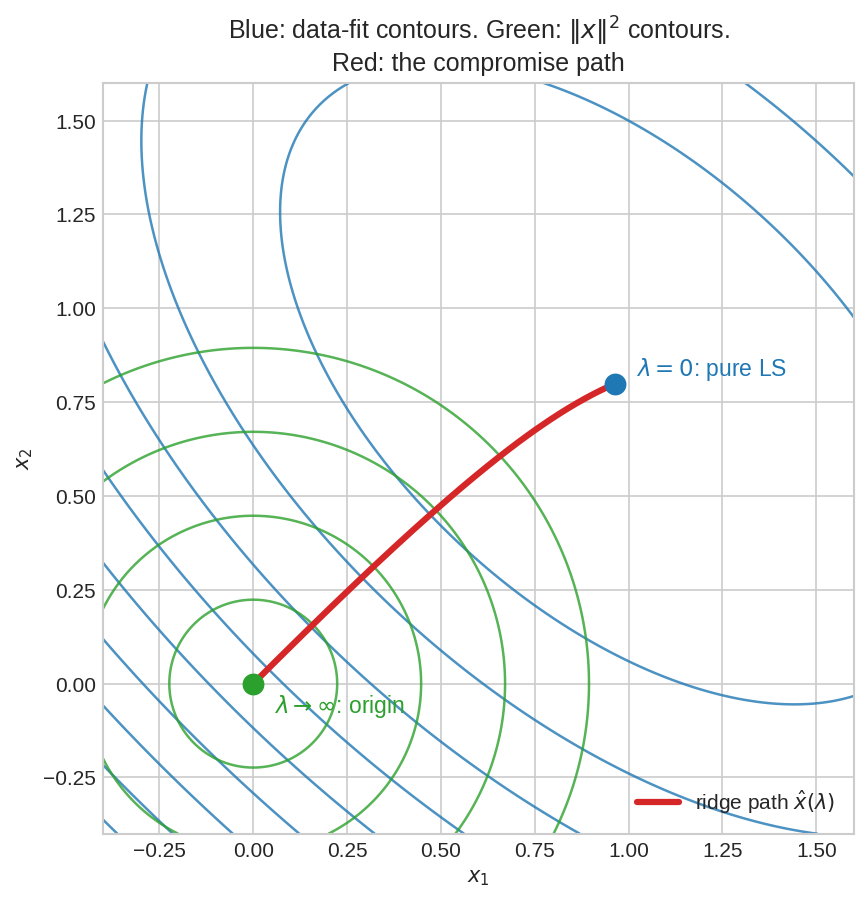
নীল উপবৃত্তগুলো data-fit error \(\|Ax-b\|^2\)-এর contour (কেন্দ্রে plain LS সমাধান)। সবুজ বৃত্তগুলো \(\|x\|^2\)-এর contour (কেন্দ্রে origin)। লাল পথটা ridge সমাধান \(\hat{x}(\lambda)\)-র যাত্রা: \(\lambda=0\)-তে নীল কেন্দ্রে (pure LS), \(\lambda\to\infty\)-তে সবুজ কেন্দ্রে (origin)। ridge মানে দুই কেন্দ্রের মাঝে একটা আপস-বিন্দু — \(\lambda\) যত বড়, origin-এর দিকে তত টান।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- অর্থনৈতিক পূর্বাভাস: অনেকগুলো পরস্পর-সম্পর্কিত (correlated) সূচক দিয়ে GDP predict করা। plain LS এখানে বুনো coefficient দেয়; ridge স্থিতিশীল, ব্যাখ্যাযোগ্য উত্তর দেয়।
- চিকিৎসা/genomics: হাজার হাজার gene (feature), কিন্তু মাত্র কয়েকশো রোগী (sample)। feature ≫ sample — plain LS-এর সমাধানই অসংখ্য (unique নয়)। Ridge একটা নির্দিষ্ট, স্থিতিশীল উত্তর বেছে দেয়।
- সংকেত পুনরুদ্ধার (signal deblurring): ঝাপসা ছবি থেকে আসল ছবি ফেরানো — একটা ill-posed inverse problem। Tikhonov regularization এখানে অপরিহার্য।
Data Science / ML-এ:
- Ridge Regression scikit-learn-এর
Ridge—প্রায় প্রতিটা tabular ML pipeline-এ baseline। - Weight decay(ওয়েট ডিকে): neural network training-এ loss-এর সাথে \(\lambda\|W\|^2\) যোগ করা — সেটা ঠিক এই ridge penalty। আধুনিক deep learning-এর regularization-এর মেরুদণ্ড।
- Multicollinearity(মাল্টিকলিনিয়ারিটি)-র ওষুধ: যখন দুটো feature প্রায় একই তথ্য বহন করে, \(A^TA\) প্রায় singular হয়ে যায়, plain LS বিস্ফোরিত হয় — ridge ঠিক এই রোগ সারায় (§৬-এর কোডে দেখবে)।
- Hyperparameter tuning-এর প্রথম পাঠ: \(\lambda\) হলো তোমার প্রথম hyperparameter — model শেখে না, তুমি validation দিয়ে বেছে দাও। এই কৌশল সারা ML জুড়ে ঘুরে-ফিরে আসবে।
৪. Properties¶
Property 1 — Ridge মানেই একটা stacked least squares¶
\(\|Ax-b\|^2 + \lambda\|x\|^2\)-কে এক-লক্ষ্যের LS বানানো যায়, দুটো matrix স্তূপ করে (Chapter 5-এর সেই কৌশল):
মিলিয়ে দেখো: উপরের ব্লক দেয় \(\|Ax-b\|^2\), নিচের ব্লক দেয় \(\|\sqrt{\lambda} I x - 0\|^2 = \lambda\|x\|^2\)। তাই ridge solve করতে নতুন কিছু লাগে না — শুধু matrix-টা লম্বা করো, তারপর np.linalg.lstsq। এটাই §৬-এর কোডের হৃদয়।
Property 2 — বন্ধ-রূপ সমাধান (closed form)¶
Stacked matrix-এর normal equations লিখলে (Chapter 5.4):
Plain LS-এর (\(A^TA)^{-1}A^Tb\)-র সাথে তুলনা করো: শুধু diagonal-এ \(\lambda\) যোগ হলো। এই \(\lambda\)-ই "ridge" (পাহাড়ের চূড়া) নামের উৎস — \(A^TA\)-র diagonal বরাবর একটা ছোট পাহাড় তুলে দিচ্ছি।
Property 3 — \(A^TA + \lambda I\) সবসময় invertible¶
Plain LS-এর সবচেয়ে বড় দুর্বলতা: \(A\)-র column গুলো linearly dependent (বা প্রায়) হলে \(A^TA\) singular, \((A^TA)^{-1}\) নেই — সমাধান হয় নেই, নয় অসংখ্য। Ridge এই সমস্যাই মুছে দেয়। কারণ:
অর্থাৎ যেকোনো \(\lambda > 0\)-র জন্য \(A^TA + \lambda I\) positive definite, তাই সবসময় invertible। ridge-এর সমাধান সবসময় থাকে এবং একটাই — data যতই বাজে হোক। এটাই feature ≫ sample-এর ক্ষেত্রে ridge-এর জাদু।
Property 4 — চরম সীমা দুটো¶
- \(\lambda \to 0^+\): penalty উবে যায়, \(\hat{x}(\lambda) \to\) (minimum-norm) plain LS সমাধান।
- \(\lambda \to \infty\): penalty সব খেয়ে ফেলে, \(\hat{x}(\lambda) \to 0\) — model বলে "কিচ্ছু predict করবো না, সবকিছুকে \(b\)-র গড় ধরে নেবো"।
মাঝের সব \(\lambda\)-তে \(\hat{x}\) এই দুই চরমের মাঝে কোথাও — fig05-এর লাল পথ ঠিক এটাই আঁকে।
Property 5 — Shrinkage কিন্তু সমান নয় সব দিকে¶
Ridge coefficient-দের শূন্যের দিকে টানে (shrinks), কিন্তু ঠিক শূন্য করে না — সব coefficient একটু একটু বাঁচে। (তুলনায় LASSO/\(\ell_1\) penalty অনেককে একদম শূন্য করে দেয়, feature বেছে নেয় — সেটা আরেক গল্প, এই বইয়ের বাইরে।) SVD-র ভাষায় (Part VI): ছোট singular value-র দিকগুলো বেশি সংকুচিত হয়, বড় singular value-র দিকগুলো কম — noise-ভরা দুর্বল দিকগুলোকেই ridge বেশি দমন করে। চতুর ব্যবস্থা।
৫. Intuition — কেন সত্য?¶
কেন penalty overfitting থামায়?¶
Overfitting-এর চেহারাটা মনে করো (fig04 বাঁ): বক্ররেখা বুনোভাবে ওঠা-নামা করছে। গণিতে এই "বুনোমি" মানে বড় coefficient — degree-9 polynomial-এ noise-কে ধরতে হলে coefficient-দের বিশাল আর পরস্পর-বিরোধী হতে হয় (একটা \(+8000\), পরেরটা \(-15000\), এভাবে টানাটানি করে প্রতিটা বিন্দু ছুঁতে)। Penalty \(\lambda\|x\|^2\) ঠিক এই বিশাল coefficient-কেই দামি করে তোলে। তাই optimizer বাধ্য হয় মসৃণ, শান্ত সমাধান বেছে নিতে — যা signal ধরে কিন্তু noise-এর পেছনে ছোটে না।
জ্যামিতিক ছবি: দুই কেন্দ্রের টানাপোড়েন¶
fig05-এ দুই পরিবারের contour: নীল (data-fit) চায় নিজের কেন্দ্রে যেতে (\(\hat{x}_{ls}\)), সবুজ (\(\|x\|^2\)) চায় origin-এ যেতে। Ridge সমাধান দুই টানের ভারসাম্য-বিন্দুতে বসে — যেখানে নীল contour আর সবুজ contour পরস্পরকে স্পর্শ করে (tangent)। \(\lambda\) বাড়ানো মানে সবুজ টান জোরালো করা, তাই সমাধান origin-এর দিকে সরে। এটা ঠিক Chapter 7.3-এর Lagrange ছবিরই ভাই — সেখানে constraint, এখানে penalty।
বিন্দু-অনুপাত: কেন ছোট coefficient = ভালো সাধারণীকরণ¶
একটা model যদি training-এ input সামান্য বদলালে output লাফায় (বড় coefficient), তবে test data-র সামান্য ভিন্ন input-এও সে বুনো prediction দেবে। ছোট coefficient = মৃদু, স্থিতিশীল function = নতুন data-তেও ভরসাযোগ্য। "সরল ব্যাখ্যাই সেরা ব্যাখ্যা" — Occam's razor-এর গাণিতিক রূপই regularization।
Bias-variance-এর দর কষাকষি¶
- \(\lambda\) ছোট: model খুব নমনীয় → training data-র প্রতিটা খুঁটিনাটি (noise সমেত) ধরে → low bias, high variance। data একটু বদলালেই model অনেক বদলায়।
- \(\lambda\) বড়: model অনড় → signal-ও মিস করে → high bias, low variance।
- মাঝের \(\lambda\): দুইয়ের যোগফল (total test error) সবচেয়ে কম। এই আপসটাই fig03-এর U-আকৃতির test-error curve — ML-এর সবচেয়ে মৌলিক ছবিগুলোর একটা।
৬. Code-এ কেমনে লিখে¶
নিচের কোডে ইচ্ছে করে collinear (প্রায় একরকম) দুটো feature নিয়েছি — এখানেই plain LS ভেঙে পড়ে আর ridge-এর জাদু চোখে পড়ে।
import numpy as np
np.random.seed(0)
# --- data: দুটো feature প্রায় একরকম (collinear) => plain LS বিপদে ---
N = 12
x1 = np.linspace(1, 4, N)
x2 = x1 + 0.05 * np.random.randn(N) # x2 প্রায় x1-এর যমজ
y = 2 + 1.0 * x1 + 0.3 * np.random.randn(N) # আসল: y = 2 + 1*x1 (x2 অপ্রাসঙ্গিক)
A = np.column_stack([np.ones(N), x1, x2]) # [1, x1, x2]
# --- plain least squares (Chapter 5.4) ---
theta_ls, *_ = np.linalg.lstsq(A, y, rcond=None)
print("plain LS :", theta_ls.round(2), " ||theta|| =", round(np.linalg.norm(theta_ls), 2))
# --- ridge: stacked matrix চালাকি (Property 1); intercept-এ penalty নয় ---
def ridge(lam):
D = np.eye(3); D[0, 0] = 0.0 # constant column penalty-মুক্ত
Atil = np.vstack([A, np.sqrt(lam) * D])
btil = np.hstack([y, np.zeros(3)])
th, *_ = np.linalg.lstsq(Atil, btil, rcond=None)
return th
for lam in [0.1, 1, 10, 100]:
th = ridge(lam)
rms = np.sqrt(np.mean((A @ th - y) ** 2))
print(f"lam={lam:6.1f}: theta={th.round(2)} ||theta||={np.linalg.norm(th):4.2f} rms={rms:.3f}")
# --- বন্ধ-রূপ সমাধান stacked-এর সমান কিনা (Property 2) ---
lam = 10; D = np.eye(3); D[0, 0] = 0
th_ne = np.linalg.solve(A.T @ A + lam * (D.T @ D), A.T @ y)
print("closed form == stacked :", np.allclose(th_ne, ridge(10)))
Output ব্যাখ্যা:
- Plain LS দেয়
theta ≈ [2.1, -1.57, 2.5], norm ≈3.63। খেয়াল করো — আসল সম্পর্ক ছিল সহজ (\(y \approx 2 + x_1\)), অথচ LS দিয়েছে উদ্ভট coefficient: \(x_1\)-এ \(-1.57\) (ঋণাত্মক!), \(x_2\)-তে \(+2.5\)। দুই যমজ feature পরস্পরকে বাতিল করতে গিয়ে বিশাল, বিপরীত মান নিয়েছে — এটাই multicollinearity-র রোগ। - \(\lambda\) বাড়াতেই coefficient শান্ত হয়: \(\lambda=10\)-এ
theta ≈ [2.99, 0.3, 0.3]— এবার \(x_1, x_2\) দুজনে সমানভাবে ভার ভাগ করে নিয়েছে (যুক্তিসঙ্গত, কারণ ওরা প্রায় একই), norm নেমে স্থিতিশীল। rms সামান্য বাড়লেও (0.26 → 0.39) coefficient হয়েছে ব্যাখ্যাযোগ্য ও ভরসাযোগ্য। - শেষ লাইন
True— Property 2-র বন্ধ-রূপ \((A^TA+\lambda I)^{-1}A^Tb\) আর stacked-matrix পদ্ধতি হুবহু একই উত্তর দেয়। দুই পথ, এক গন্তব্য।
৭. Worked Examples¶
Example 1 — এক ভেরিয়েবলে ridge হাতে-কলমে¶
Data একটাই: \(A = \begin{bmatrix} 2 \end{bmatrix}\) (একটা row, একটা column), \(b = \begin{bmatrix} 6 \end{bmatrix}\)। Ridge: \(\underset{x}{\min}\; (2x - 6)^2 + \lambda x^2\)।
ধাপ ১ — derivative শূন্য করো: \(\frac{d}{dx}\big[(2x-6)^2 + \lambda x^2\big] = 2(2x-6)(2) + 2\lambda x = 8x - 24 + 2\lambda x = 0\)।
ধাপ ২ — solve: \((8 + 2\lambda)x = 24 \Rightarrow x = \dfrac{24}{8 + 2\lambda} = \dfrac{12}{4 + \lambda}\)।
ধাপ ৩ — পড়ো: \(\lambda = 0\): \(x = 3\) (plain LS, \(2\cdot 3 = 6\) নিখুঁত)। \(\lambda = 4\): \(x = 1.5\) (অর্ধেক সংকুচিত)। \(\lambda \to \infty\): \(x \to 0\)। একঘেয়েভাবে \(\lambda\)-র সাথে \(x\) শূন্যের দিকে নামে — এক সংখ্যায় Property 4-এর পুরো গল্প।
Example 2 — কেন ridge singular case বাঁচায়¶
\(A = \begin{bmatrix} 1 & 1 \\ 1 & 1 \end{bmatrix}\) (দুই column হুবহু সমান!), \(b = \begin{bmatrix} 2 \\ 4 \end{bmatrix}\)।
Plain LS-এর দুরবস্থা: \(A^TA = \begin{bmatrix} 2 & 2 \\ 2 & 2 \end{bmatrix}\) — determinant \(0\), singular, invert করা যায় না। সমাধান অসংখ্য (যেকোনো \(x_1 + x_2 = 3\) সমান error দেয়)।
Ridge-এর উদ্ধার (\(\lambda = 1\)): \(A^TA + I = \begin{bmatrix} 3 & 2 \\ 2 & 3 \end{bmatrix}\), determinant \(9 - 4 = 5 \neq 0\) — invertible! \(A^Tb = \begin{bmatrix} 6 \\ 6 \end{bmatrix}\)।
অসংখ্য সমাধানের মধ্যে থেকে ridge বেছে নিলো সবচেয়ে ছোট norm-এরটা, আর দুই সমান feature-কে সমানভাবে ভার দিলো (\(1.2\) ও \(1.2\))। Property 3 কাজে ধরা পড়লো।
Example 3 — trade-off curve পড়া¶
ধরো তিনটা \(\lambda\)-তে পেলে: \(\lambda = 0.1 \to (J_1, J_2) = (2.0, 9.0)\); \(\lambda = 1 \to (3.5, 4.0)\); \(\lambda = 10 \to (8.0, 1.5)\)।
- \(\lambda\) বাড়ালে \(J_2\) (penalty) কমছে (\(9 \to 4 \to 1.5\)) কিন্তু \(J_1\) (fit-error) বাড়ছে (\(2 \to 3.5 \to 8\)) — trade-off curve-এর সংজ্ঞা মেনে, একটা কমাতে অন্যটা বাড়ছে।
- কোনটা "সেরা"? গণিত বলতে পারে না — নির্ভর করে তোমার application-এ fit বনাম simplicity-র আপেক্ষিক মূল্যের ওপর। তবে যদি validation error দেখো, মাঝেরটা (\(\lambda=1\)) প্রায়ই জেতে — চরম নয়, ভারসাম্য।
৮. Problems ও Solutions¶
Problem 1. এক ভেরিয়েবলে ridge: \(\underset{x}{\min}\; (3x - 12)^2 + \lambda x^2\)। (a) সাধারণ সমাধান \(\hat{x}(\lambda)\) বের করো। (b) \(\lambda = 0, 3, 15\)-এ মান দাও। (c) কোন \(\lambda\)-তে \(\hat{x}\) ঠিক অর্ধেক হবে \(\lambda = 0\)-র মানের?
Solution
(a) Derivative: \(2(3x-12)(3) + 2\lambda x = 18x - 72 + 2\lambda x = 0 \Rightarrow (18 + 2\lambda)x = 72\)।
(b) \(\lambda=0: \hat{x} = 4\) (plain LS, \(3\cdot 4 = 12\) ✓)। \(\lambda=3: \hat{x} = 36/12 = 3\)। \(\lambda=15: \hat{x} = 36/24 = 1.5\)।
(c) অর্ধেক মানে \(\hat{x} = 2\): \(\dfrac{36}{9+\lambda} = 2 \Rightarrow 9 + \lambda = 18 \Rightarrow \lambda = 9\)। এই "coefficient অর্ধেক হওয়ার \(\lambda\)" ধারণাটাই ridge-এর কার্যকর শক্তির মাপকাঠি।
Problem 2. দেখাও যেকোনো \(\lambda > 0\)-র জন্য \(A^TA + \lambda I\) positive definite, তাই invertible — \(A\) যতই বাজে (column dependent) হোক।
Solution
যেকোনো \(x \neq 0\) নাও, quadratic form হিসাব করো:
প্রথম পদ \(\|Ax\|^2 \geq 0\) (norm-এর বর্গ, কখনো ঋণাত্মক নয়)। দ্বিতীয় পদ \(\lambda\|x\|^2 > 0\) (যেহেতু \(\lambda > 0\) আর \(x \neq 0\))। যোগফল কঠোরভাবে ধনাত্মক:
সব nonzero \(x\)-এ quadratic form ধনাত্মক = positive definite = সব eigenvalue ধনাত্মক = determinant ধনাত্মক = invertible ∎
অন্তর্দৃষ্টি: \(A^TA\)-র সবচেয়ে ছোট eigenvalue হয়তো \(0\) (singular), কিন্তু \(\lambda I\) যোগ করলে সব eigenvalue \(\lambda\) পরিমাণ ওপরে ঠেলে ওঠে — কেউ আর \(0\)-তে বসে থাকতে পারে না।
Problem 3. Ridge-এর stacked-matrix রূপ প্রমাণ করো: \(\|Ax-b\|^2 + \lambda\|x\|^2 = \left\|\begin{bmatrix} A \\ \sqrt{\lambda}I\end{bmatrix}x - \begin{bmatrix} b \\ 0\end{bmatrix}\right\|^2\)। এর থেকে normal equation \((A^TA + \lambda I)\hat{x} = A^Tb\) বের করো।
Solution
ডান পাশের stacked vector-এর norm-বর্গ = ব্লকগুলোর norm-বর্গের যোগফল (কারণ \(\|(u; v)\|^2 = \|u\|^2 + \|v\|^2\)):
বাঁ পাশের সমান ✓
এবার stacked matrix-কে \(\tilde{A} = \begin{bmatrix} A \\ \sqrt{\lambda}I\end{bmatrix}\), \(\tilde{b} = \begin{bmatrix} b \\ 0\end{bmatrix}\) ধরে সাধারণ normal equation \(\tilde{A}^T\tilde{A}\hat{x} = \tilde{A}^T\tilde{b}\) লিখি:
তাই \((A^TA + \lambda I)\hat{x} = A^Tb\) ∎ — Property 2 প্রমাণিত, নতুন কোনো ক্যালকুলাস ছাড়াই।
Problem 4. \(2\times 2\) ridge হাতে: \(A = \begin{bmatrix} 1 & 0 \\ 0 & 1 \\ 1 & 1\end{bmatrix}\), \(b = \begin{bmatrix} 2 \\ 4 \\ 3\end{bmatrix}\), \(\lambda = 1\)। \(\hat{x}\) বের করো।
Solution
(হিসাব: \(A^TA\)-র প্রথম column = \(A\)-র প্রথম column-এর সাথে সব column-এর dot; row 1: \(1^2+0+1^2=2\), off-diag \(0+0+1=1\)।)
Inverse: \(\det = 9 - 1 = 8\), \(\begin{bmatrix} 3 & 1 \\ 1 & 3\end{bmatrix}^{-1} = \frac{1}{8}\begin{bmatrix} 3 & -1 \\ -1 & 3\end{bmatrix}\)।
যাচাই: plain LS হতো \(\begin{bmatrix} 2 & 1 \\ 1 & 2\end{bmatrix}^{-1}\begin{bmatrix} 5 \\ 7\end{bmatrix} = \frac{1}{3}\begin{bmatrix} 3 \\ 9\end{bmatrix} = \begin{bmatrix} 1 \\ 3\end{bmatrix}\) — ridge \(\begin{bmatrix} 1 \\ 3\end{bmatrix}\)-কে origin-এর দিকে টেনে \(\begin{bmatrix} 1 \\ 2\end{bmatrix}\) বানালো (norm \(\sqrt{10} \to \sqrt{5}\))। Shrinkage চোখে ধরা পড়লো।
Problem 5. Overfitting-underfitting যুক্তি: degree-9 polynomial ১০টা noisy বিন্দুতে fit করছো। (a) \(\lambda \to 0\)-তে training error কেমন হবে আর কেন সেটা প্রতারণামূলক? (b) \(\lambda \to \infty\)-তে fit দেখতে কেমন? (c) সঠিক \(\lambda\) কীভাবে বাছবে — training error দিয়ে কি সম্ভব?
Solution
(a) ১০ বিন্দু, ১০ coefficient (degree 9) — polynomial প্রতিটা বিন্দুর ঠিক ওপর দিয়ে যেতে পারে, তাই training error প্রায় শূন্য। প্রতারণা: সে data-র noise-ও মুখস্থ করেছে; test বিন্দুতে বুনো ঢেউয়ের কারণে ভয়ংকর ভুল করবে (fig04 বাঁ)। Training error শূন্য = memorization, শেখা নয়।
(b) \(\lambda\) বিশাল হলে penalty coefficient-দের প্রায় শূন্যে টেনে নেয় — বক্ররেখা প্রায় সমতল (শুধু constant term বাঁচে), signal-ও ধরতে পারে না (fig04 ডান)। Under-fit।
(c) Training error দিয়ে অসম্ভব — সে সবসময় \(\lambda\) বাড়ালে বাড়ে (fig03 নীল), তাই সে সবসময় \(\lambda=0\) বেছে নিতে বলবে (ভুল!)। বদলে data-কে ভাগ করো train/validation-এ; একগুচ্ছ \(\lambda\)-তে train করে validation error মাপো; U-curve-এর তলানির \(\lambda\) বাছো (fig03 লাল, সবুজ বিন্দু)। এটাই cross-validation-এর মূল ধারণা।
Problem 6. (কোডে) np.random.seed(1)-এ এমন data বানাও যেখানে দুটো feature collinear: x1 = linspace(0,5,20), x2 = 2*x1 + 0.1*randn(20), y = 1 + 3*x1 + randn(20)। plain LS আর \(\lambda=5\) ridge fit করে coefficient ও norm তুলনা করো।
Solution
import numpy as np
np.random.seed(1)
x1 = np.linspace(0, 5, 20)
x2 = 2 * x1 + 0.1 * np.random.randn(20) # collinear
y = 1 + 3 * x1 + np.random.randn(20)
A = np.column_stack([np.ones(20), x1, x2])
th_ls, *_ = np.linalg.lstsq(A, y, rcond=None)
lam = 5; D = np.eye(3); D[0, 0] = 0
th_r = np.linalg.solve(A.T @ A + lam * (D.T @ D), A.T @ y)
print("plain LS:", th_ls.round(2), " norm", round(np.linalg.norm(th_ls), 2))
print("ridge :", th_r.round(2), " norm", round(np.linalg.norm(th_r), 2))
Problem 7. Multi-objective দৃষ্টিকোণ: \(\underset{x}{\min}\; \|A_1x - b_1\|^2 + \lambda\|A_2x - b_2\|^2\)-এর সাধারণ বন্ধ-রূপ সমাধান বের করো। ridge কীভাবে এর বিশেষ কেস দেখাও।
Solution
Problem 3-এর মতোই stacked করো: \(\tilde{A} = \begin{bmatrix} A_1 \\ \sqrt{\lambda}A_2\end{bmatrix}\), \(\tilde{b} = \begin{bmatrix} b_1 \\ \sqrt{\lambda}b_2\end{bmatrix}\)। Normal equation:
Ridge কেস: \(A_2 = I\), \(b_2 = 0\) বসাও: \(A_2^TA_2 = I\), \(A_2^Tb_2 = 0\), ফলে \(\hat{x} = (A_1^TA_1 + \lambda I)^{-1}A_1^Tb_1\) — ঠিক Property 2। Ridge হলো multi-objective LS-এর "দ্বিতীয় লক্ষ্য = ছোট থাকো" সংস্করণ।
Problem 8. ধারণাগত: বন্ধু বলছে "\(\lambda\) যত বড় করবো, model তত ভালো হবে, কারণ coefficient ছোট রাখা তো সবসময় ভালো।" তার ভুলটা ধরিয়ে দাও।
Solution
বন্ধু অর্ধেক ঠিক — ছোট coefficient overfitting রোধ করে, কিন্তু অতি-ছোট coefficient মানে model আসল signal-ও ধরতে পারে না (under-fit)। \(\lambda\)-র সাথে test error একঘেয়ে কমে না; সে U-আকৃতির (fig03): শুরুতে কমে (overfitting সারছে), তলানিতে সেরা, তারপর বাড়ে (under-fitting শুরু)। "সবসময় বেশি regularization ভালো" ভাবলে তুমি U-curve-এর ডান দেয়ালে উঠে যাবে — model প্রায় constant, কিছুই predict করে না।
সঠিক নীতি: \(\lambda\) একটা knob, চরম নয় — validation দিয়ে U-curve-এর তলানি খোঁজো। "Regularization ওষুধের মতো: কম হলে রোগ সারে না, বেশি হলে বিষ।"
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "Ridge solve করতে নতুন algorithm লাগে" | না! stacked matrix \(\begin{bmatrix} A \\ \sqrt{\lambda}I\end{bmatrix}\) বানিয়ে সেই পুরনো lstsq-ই চালাও (Property 1)। ridge = plain LS on augmented data। |
| "\(\lambda\) বড় করলে সবসময় ভালো model" | Test error U-আকৃতির: বেশি \(\lambda\) = under-fit। validation দিয়ে তলানি খোঁজো, চরমে যেও না (Problem 8)। |
| "Training error দেখে \(\lambda\) বাছবো" | Training error \(\lambda\)-র সাথে শুধু বাড়ে — সে সবসময় \(\lambda=0\) বলবে (overfit!)। validation/test error-ই একমাত্র সৎ বিচারক (fig03)। |
| "Intercept-এও penalty দেবো" | সাধারণত না — constant term (bias) shrink করলে prediction পুরোটা নিচে সরে যায়, অর্থহীন। কোডে তাই D[0,0]=0 রেখে intercept-কে penalty-মুক্ত রাখি। |
| "Ridge feature বেছে দেয় (কিছু coefficient শূন্য করে)" | না — ridge সব coefficient একটু একটু সংকুচিত করে, কাউকে ঠিক শূন্য করে না (Property 5)। শূন্য করতে চাইলে LASSO/\(\ell_1\) লাগবে, ridge নয়। |
| "Regularization মানে data কম ব্যবহার" | Regularization data ফেলে দেয় না — সে prior belief যোগ করে ("সমাধান ছোট হওয়া উচিত")। কম data-তে এই বাড়তি তথ্যই model-কে বাঁচায়। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Bi-criterion LS | \(\underset{x}{\min}\; J_1(x) + \lambda J_2(x)\) | রান্নায় স্বাদ বনাম স্বাস্থ্য |
| Trade-off curve | Pareto optimal বিন্দুর রেখা; একটা কমাতে অন্যটা বাড়ে | fig01-এর বক্ররেখা |
| Ridge regression | \(\underset{x}{\min}\;\|Ax-b\|^2 + \lambda\|x\|^2\) | fit + "ছোট থাকো" penalty |
| Stacked রূপ | \(\left\|\begin{bmatrix}A\\ \sqrt{\lambda}I\end{bmatrix}x - \begin{bmatrix}b\\ 0\end{bmatrix}\right\|^2\) | matrix লম্বা করো |
| বন্ধ-রূপ | \(\hat{x} = (A^TA + \lambda I)^{-1}A^Tb\) | diagonal-এ পাহাড় (ridge) |
| সর্বদা invertible | \(A^TA + \lambda I\) positive definite (\(\lambda>0\)) | singular রোগের ওষুধ |
| \(\lambda\) tuning | validation error U-curve-এর তলানি | over-fit ↔ under-fit |
| \(\lambda\) চরম | \(0 \to\) plain LS; \(\infty \to\) origin | দুই কেন্দ্রের মাঝে টান |
পরের chapter-এর সেতু: Ridge-এ আমরা "\(x\) ছোট হওয়া উচিত" এই ইচ্ছেটা নরমভাবে (penalty দিয়ে) জানিয়েছি — চাইলে অমান্য করা যায়, শুধু দাম দিতে হয়। কিন্তু অনেক সমস্যায় শর্তটা কঠোর: "\(x\) অবশ্যই এই সমীকরণ মানবে, কোনো আপস নেই" — যেমন spline-এর দুই টুকরো ঠিক seam-এ মিলতেই হবে, বা রকেটকে ঠিক লক্ষ্যে থামতেই হবে। নরম penalty নয়, কঠোর constraint। এই hard-constraint-ওয়ালা least squares আর তাকে সমাধানের সুন্দর যন্ত্র Lagrange multiplier — Chapter 7.3-এ। (fig05-এর tangent ছবিটা মনে রেখো, ওটাই সেখানে ফিরবে।)
📓 Notebook Project¶
notebooks/part-07/ch02-project.ipynb — নিজের হাতে ridge scratch-এ: collinear feature বানিয়ে plain LS-এর বিস্ফোরণ দেখা, stacked-matrix ridge implement করা, train/validation ভাগ করে \(\lambda\)-র U-curve আঁকা ও সেরা \(\lambda\) বেছে নেওয়া, আর degree-9 polynomial-এ over/under/just-right তিন fit চোখে দেখা — Part VII flagship project-এর regularization কিস্তি।