Chapter 3.1 — What is a Matrix? (Matrix কি? — টেবিল নয়, transformation)¶
🎯 এই chapter-এ যা শিখবে¶
- Matrix(ম্যাট্রিক্স) জিনিসটা আসলে কি — এবং কেন "সংখ্যার টেবিল" উত্তরটা অর্ধেক সত্যি
- একটা matrix-কে function/machine হিসেবে দেখা: vector ঢোকে, vector বেরোয়
- Matrix-এর column গুলো পড়েই বলে দেওয়া — basis vector গুলো কোথায় গিয়ে পড়বে
- \(A\mathbf{x}\) গুণ করার দুইটা দৃষ্টিভঙ্গি: row picture (dot product) ও column picture (linear combination)
- Data Science-এ matrix কোথায় কোথায় লুকিয়ে আছে — ছবি, নেটওয়ার্ক, dataset
🖼️ এক ছবিতে মূল idea¶
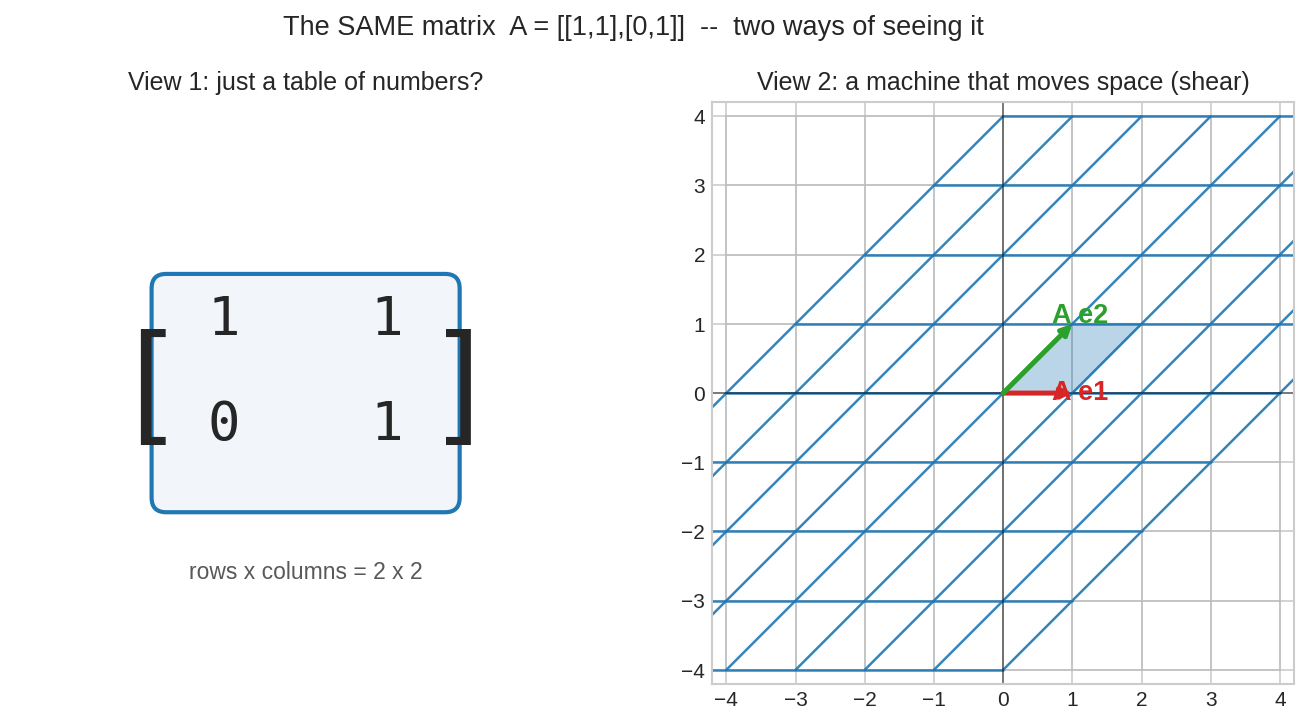
একই matrix \(A = \begin{bmatrix}1 & 1\\ 0 & 1\end{bmatrix}\) — বাঁয়ে "শুধু চারটা সংখ্যা", ডানে সেই সংখ্যাগুলোই পুরো plane-টাকে হেলিয়ে (shear করে) দিচ্ছে। এই Part-এর পুরো গল্পটাই এই দ্বিতীয় দৃষ্টিভঙ্গি শেখার গল্প।
১. কি? (What)¶
স্কুলে আমাদের শেখানো হয়: "Matrix হলো সংখ্যা সাজানো একটা আয়তাকার টেবিল।" কথাটা মিথ্যা নয় — কিন্তু এটা অনেকটা এরকম বলার মতো যে "গান হলো কাগজে আঁকা কিছু কালো ফোঁটা।" স্বরলিপির কাগজটা গান নয়; কাগজটা বাজালে যা শোনা যায়, সেটাই গান। ঠিক তেমনি —
Matrix হলো একটা transformation(রূপান্তর)-এর স্বরলিপি। সংখ্যার টেবিলটা হলো লেখার ফরম্যাট; আসল জিনিসটা হলো space-এর ওপর সেই action(ক্রিয়া)।
আনুষ্ঠানিক সংজ্ঞাটা আগে সেরে ফেলি, তারপর সারা chapter ধরে এর ভেতরের প্রাণটা দেখব।
সংজ্ঞা (রূপ হিসেবে): \(m \times n\) Matrix(ম্যাট্রিক্স) হলো \(m\)টা row(সারি) ও \(n\)টা column(কলাম)-এ সাজানো সংখ্যার আয়তাকার বিন্যাস। আমরা লিখি:
এখানে \(a_{ij}\) মানে \(i\)-তম row আর \(j\)-তম column-এর সংখ্যাটা। আগে row, পরে column — এই ক্রমটা সারাজীবনের জন্য মুখস্থ করে ফেলো: "Row তারপর Column — RC, যেমন RC কোলা।"
সংজ্ঞা (কাজ হিসেবে): একটা \(m \times n\) matrix \(A\) হলো একটা function — সে \(\mathbb{R}^n\)-এর একটা vector খেয়ে \(\mathbb{R}^m\)-এর একটা vector উগরে দেয়:
Part I-তে তুমি vector চিনেছ, Part II-তে সমীকরণের system \(A\mathbf{x} = \mathbf{b}\) সমাধান করেছ — তখন matrix ছিল শুধু coefficient(সহগ) রাখার খাতা। এই chapter থেকে সেই খাতাটা জীবন্ত হয়ে উঠবে।
দৈনন্দিন analogy: ফটো এডিটিং app-এর একটা filter-এর কথা ভাবো। "Rotate 30°" বোতামটা আসলে একটা নিয়ম: ছবির প্রতিটা pixel কোথা থেকে কোথায় যাবে। সেই নিয়মটা লিখে রাখতে লাগে মাত্র চারটা সংখ্যা — একটা \(2\times 2\) matrix। বোতাম = matrix, বোতাম চাপা = matrix দিয়ে গুণ করা।
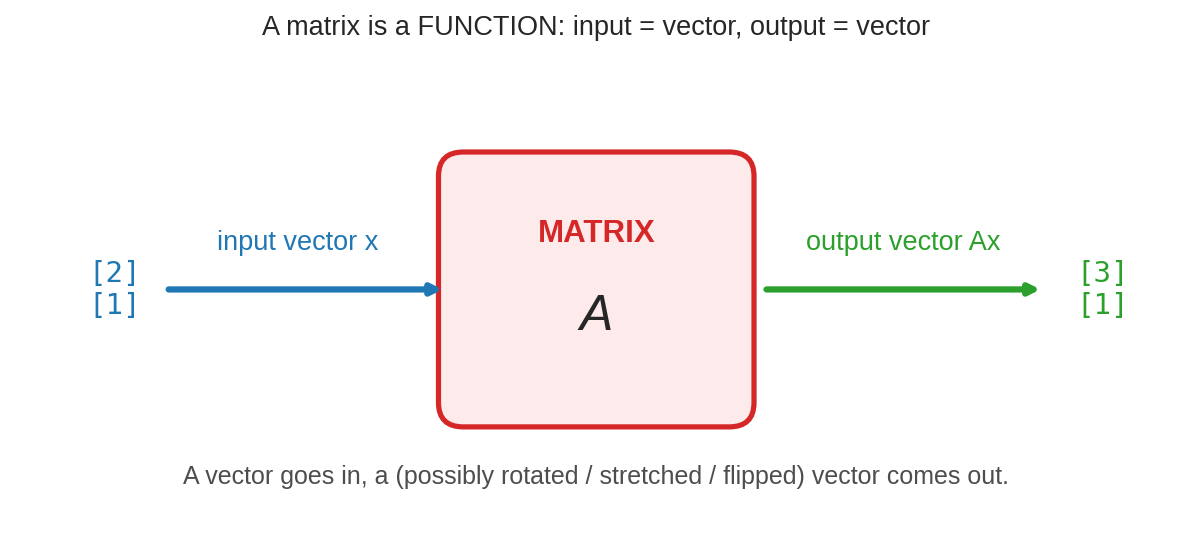
Matrix-কে ভাবো একটা machine হিসেবে: বাঁ দিক দিয়ে input vector \(\mathbf{x}\) ঢোকে, ডান দিক দিয়ে output vector \(A\mathbf{x}\) বেরোয়। Function-এর \(f(x)\) লেখার বদলে আমরা লিখি \(A\mathbf{x}\) — এই যা পার্থক্য।
২. দেখতে কেমন?¶
Matrix-কে "দেখার" সবচেয়ে শক্তিশালী কৌশলটা এখন শিখব। এটাই 3Blue1Brown-এর বিখ্যাত মন্ত্র, আর এটাই পুরো Part III-এর চাবি:
Matrix-এর প্রতিটা column বলে দেয়, একেকটা basis vector transformation-এর পরে কোথায় গিয়ে নামবে।
\(\mathbb{R}^2\)-এ আমাদের দুই বিশ্বস্ত basis vector(ভিত্তি ভেক্টর): \(\mathbf{e}_1 = \begin{bmatrix}1\\0\end{bmatrix}\) (ডান দিকে এক ধাপ) আর \(\mathbf{e}_2 = \begin{bmatrix}0\\1\end{bmatrix}\) (উপরে এক ধাপ)। এখন ধরো \(A = \begin{bmatrix}2 & 1\\ 0.5 & 1.5\end{bmatrix}\)। হিসাব করে দেখো:
কোনো কষ্ট ছাড়াই বেরিয়ে এলো: প্রথম column = \(\mathbf{e}_1\)-এর নতুন ঠিকানা, দ্বিতীয় column = \(\mathbf{e}_2\)-এর নতুন ঠিকানা।
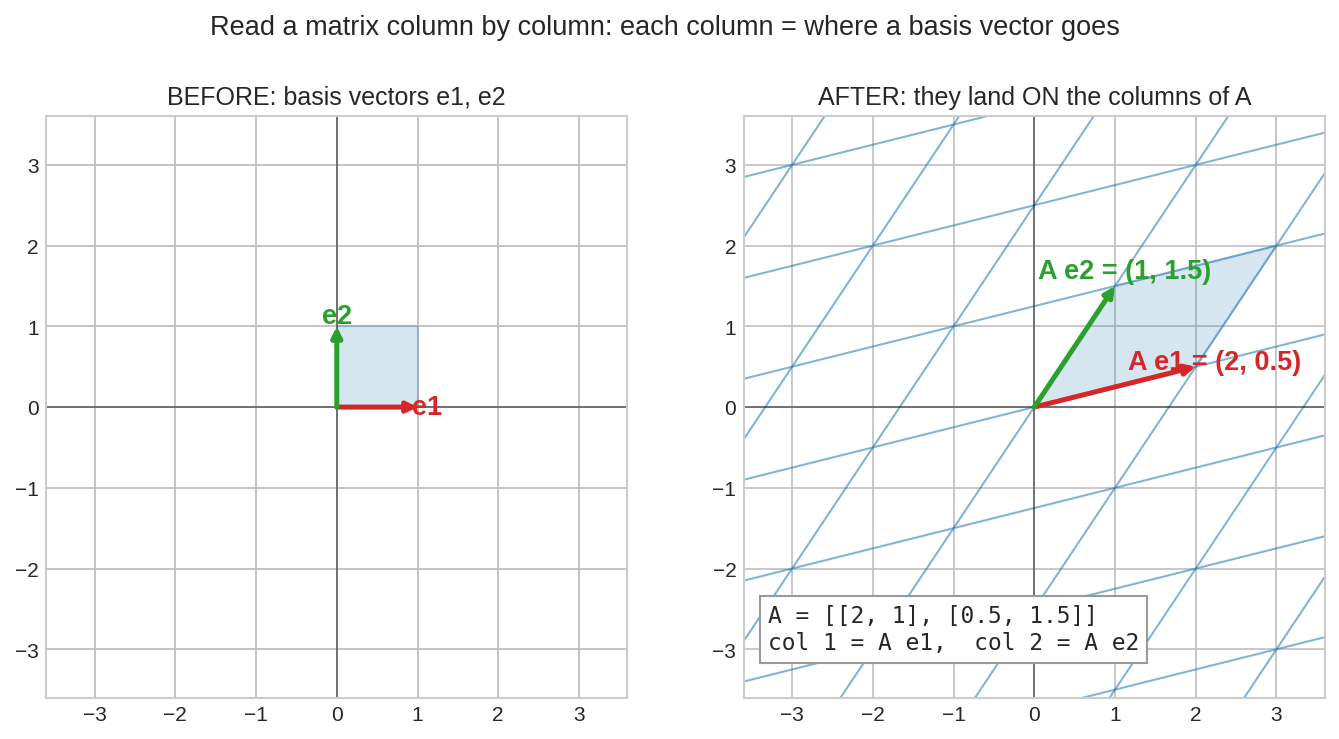
বাঁয়ে: বিশ্রামরত plane, \(\mathbf{e}_1\) (লাল) ও \(\mathbf{e}_2\) (সবুজ)। ডানে: \(A\) প্রয়োগের পর — লাল তীরটা গিয়ে নেমেছে \((2, 0.5)\)-এ (প্রথম column), সবুজটা \((1, 1.5)\)-এ (দ্বিতীয় column)। গোটা নীল গ্রিডটা সেই সাথে তাল মিলিয়ে বেঁকে গেছে।
তাহলে এখন থেকে কোনো matrix দেখলেই তুমি মনে মনে ছবি আঁকতে পারবে। যেমন \(\begin{bmatrix}0 & -1\\ 1 & 0\end{bmatrix}\) দেখামাত্র ভাবো: "\(\mathbf{e}_1\) যাচ্ছে \((0,1)\)-এ (সোজা উপরে), \(\mathbf{e}_2\) যাচ্ছে \((-1,0)\)-এ (বাঁয়ে) — আরে, এ তো ৯০° ঘোরানো!" পরের chapter-এ এমন ছবির পুরো গ্যালারি দেখব।
৩. কোথায় ইউজ হয়?¶
Matrix দুইটা ভিন্ন টুপি পরে কাজ করে — দুটোই Data Science-এ সর্বত্র:
টুপি ১: data-র পাত্র (container)।
- ছবি: একটা grayscale ছবি মানেই একটা matrix — \(a_{ij}\) = \((i,j)\) pixel-এর উজ্জ্বলতা। তোমার ফোনের ১২ megapixel ছবি ≈ \(3000 \times 4000\) matrix।
- Dataset: pandas-এর DataFrame আসলে একটা matrix — প্রতি row একজন মানুষ/observation, প্রতি column একটা feature (বয়স, উচ্চতা, আয়...)। Machine Learning-এর সেই বিখ্যাত \(X\) (design matrix) এটাই।
- নেটওয়ার্ক: Facebook-এর বন্ধুত্ব, শহরের রাস্তা, ওয়েবপেজের লিংক — সব ধরা যায় adjacency matrix(সংলগ্নতা ম্যাট্রিক্স) দিয়ে: \(a_{ij} = 1\) যদি \(i\) আর \(j\) যুক্ত থাকে, নাহলে \(0\)।
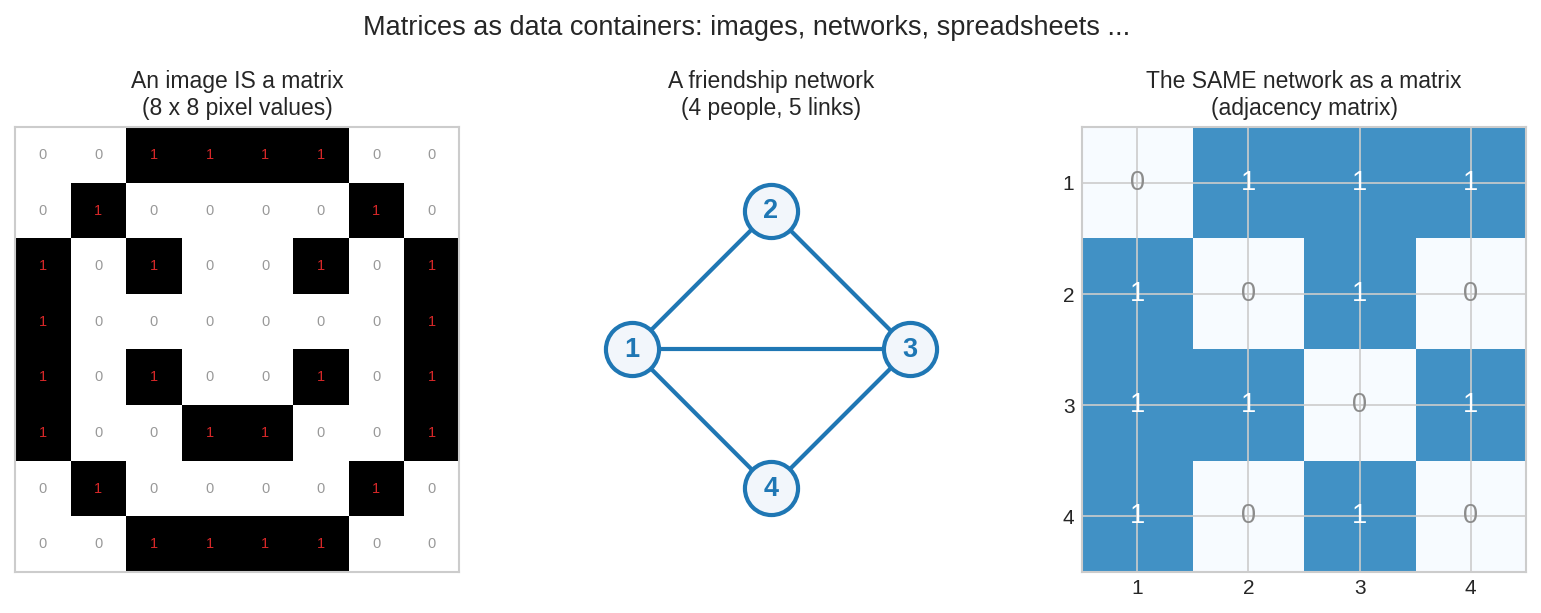
বাঁয়ে: \(8\times 8\) pixel-এর ছোট্ট ছবি — প্রতিটা ঘরই matrix-এর একটা entry। মাঝে: ৪ জনের বন্ধুত্ব-নেটওয়ার্ক। ডানে: সেই নেটওয়ার্কটাই matrix রূপে — ১ মানে বন্ধুত্ব আছে, ০ মানে নেই।
টুপি ২: action/transformation।
- Computer graphics: ভিডিও গেমে ক্যামেরা ঘোরা, চরিত্রের লাফ, 3D থেকে 2D স্ক্রিনে ফেলা — ফ্রেমে ফ্রেমে লক্ষ লক্ষ matrix-vector গুণ।
- Neural network: প্রতিটা layer-এর মূল কাজটাই হলো \(W\mathbf{x} + \mathbf{b}\) — ইনপুট vector-কে একটা weight matrix দিয়ে transform করা। GPT-জাতীয় মডেল মানে কোটি কোটি matrix multiplication।
- PCA, ঘূর্ণন, compression: data-র দিক বদলানো, মাত্রা কমানো — সবই matrix-এর action।
মজার ব্যাপার: দুই টুপি প্রায়ই একসাথে পরা হয়। Google-এর PageRank-এ ওয়েবের লিংক-matrix (পাত্র) নিজেই একটা transformation হয়ে rank ছড়িয়ে দেয় (action)। Part VII-তে এটা করব।
৪. Properties¶
৪.১ আকার (shape) ও নামকরণ¶
- \(m \times n\) matrix: \(m\) row, \(n\) column। \(m = n\) হলে square matrix(বর্গ ম্যাট্রিক্স)।
- \(n \times 1\) matrix মানেই আমাদের চেনা column vector; \(1 \times n\) হলো row vector। অর্থাৎ vector-ও এক ধরনের matrix — পরিবারটা একই।
- দুটো matrix সমান তখনই, যখন আকার এক এবং প্রতিটা জায়গার entry এক।
৪.২ Matrix-vector গুণের নিয়ম (দুই চোখে)¶
\(A\mathbf{x}\) বের করার নিয়মটা দুইভাবে পড়া যায়। ধরো \(A = \begin{bmatrix}2 & 1\\ 0.5 & 1.5\end{bmatrix}\), \(\mathbf{x} = \begin{bmatrix}3\\2\end{bmatrix}\)।
Row picture — প্রতি row-এর সাথে dot product:

Row picture: output-এর \(i\)-তম entry = (\(A\)-র \(i\)-তম row) \(\cdot\) \(\mathbf{x}\)। হাতে হিসাবের সময় এই নিয়মেই দ্রুত হয়।
Column picture — column-দের linear combination:
একই উত্তর! Column picture বলছে: \(A\mathbf{x}\) মানে "\(\mathbf{x}\)-এর recipe অনুযায়ী \(A\)-র column-গুলো মেশাও।" Part I-এর linear combination(রৈখিক সমাবেশ) এখানে ফিরে এলো। হিসাবের জন্য row picture, বোঝার জন্য column picture — দুটোই লাগবে।
৪.৩ Linearity — matrix-এর সবচেয়ে দামি স্বভাব¶
Matrix-vector গুণ দুটো সোনালি নিয়ম মানে (প্রমাণ §৫-এ, পুরো গভীরতা Chapter 3.6-এ):
অর্থাৎ: আগে যোগ করে পরে transform করো, বা আগে transform করে পরে যোগ করো — ফল একই। এই নিরীহ-দর্শন নিয়ম দুটোই matrix-কে এত শক্তিশালী করেছে।
৪.৪ আকারের হিসাব¶
\(m \times n\) matrix কেবল \(n\)-লম্বা vector খেতে পারে, আর উগরে দেয় \(m\)-লম্বা vector:
ভেতরের দুটো \(n\) মিলতেই হবে — না মিললে গুণটা সংজ্ঞায়িতই নয়। যেমন \(3\times 2\) matrix দিয়ে \(\mathbb{R}^2\)-এর vector-কে \(\mathbb{R}^3\)-এ পাঠানো যায় — plane থেকে space-এ!
৫. Intuition — কেন সত্য?¶
কেন column-ই সব বলে দেয়? কারণটা linearity থেকে দুই লাইনে বেরিয়ে আসে। যেকোনো vector-কে basis দিয়ে ভাঙা যায়: \(\mathbf{x} = x\,\mathbf{e}_1 + y\,\mathbf{e}_2\)। এবার linearity-র দুই নিয়ম পরপর লাগাও:
ব্যস! \(A\mathbf{e}_1\) আর \(A\mathbf{e}_2\) — এই দুটো জানলেই যেকোনো \(\mathbf{x}\)-এর গন্তব্য জানা। আর এই দুটোই হলো \(A\)-র দুই column। তাই একটা \(2\times 2\) matrix-এ চারটা সংখ্যা কেন — এখন পরিষ্কার: দুটো গন্তব্য-বিন্দু \(\times\) দুটো করে coordinate = ৪টা সংখ্যা। matrix-এর প্রতিটা সংখ্যার একটা জ্যামিতিক চাকরি আছে; কেউই শুধু টেবিল সাজিয়ে বসে নেই।
Row picture আর column picture একই উত্তর দেয় কেন? দুটোই আসলে \(x\,(A\mathbf{e}_1) + y\,(A\mathbf{e}_2)\)-এরই দুই রকম হিসাব-ক্রম। Row picture এক entry করে জোগাড় করে; column picture পুরো vector একসাথে জোড়ে। যোগের ক্রম বদলালে ফল বদলায় না — এই তো।
একটা সতর্কতা: সব transformation কিন্তু matrix দিয়ে লেখা যায় না। যেমন "সবকিছু ১ ঘর ডানে সরাও" (\(\mathbf{v} \mapsto \mathbf{v} + \mathbf{e}_1\)) — এতে origin নিজেই সরে যায়, কিন্তু \(A\mathbf{0} = \mathbf{0}\) সবসময়। Matrix শুধু সেই transformation-গুলোর স্বরলিপি, যারা linear — যারা origin-কে জায়গায় রাখে আর গ্রিডলাইনকে সোজা, সমান্তরাল ও সমান দূরত্বে রাখে। Chapter 3.6-এ এই শর্তগুলো আতশকাচের নিচে ফেলব।
৬. Code-এ কেমনে লিখে¶
import numpy as np
# Matrix বানানো: row-এর list হিসেবে লেখো
A = np.array([[2.0, 1.0],
[0.5, 1.5]])
print(A.shape) # (2, 2) -> (row, column)
print(A[0, 1]) # 1.0 -> 1ম row, 2য় column (0-indexed!)
# Matrix-vector গুণ: @ operator
x = np.array([3.0, 2.0])
print(A @ x) # [8. 4.5]
# column picture নিজ হাতে যাচাই:
col1, col2 = A[:, 0], A[:, 1] # column বের করা
print(3.0 * col1 + 2.0 * col2) # [8. 4.5] -- একই!
# basis vector-রা কোথায় নামে? column-এই!
e1, e2 = np.array([1.0, 0.0]), np.array([0.0, 1.0])
print(A @ e1) # [2. 0.5] = A-র 1ম column
print(A @ e2) # [1. 1.5] = A-র 2য় column
Output ব্যাখ্যা: A.shape দেয় (2, 2) — অর্থাৎ ২ row, ২ column। A @ x দিলো [8. 4.5], আর column গুলোর হাতে-মেশানো combination-ও দিলো হুবহু তাই — row picture ও column picture-এর মিল কোডেই প্রমাণ। শেষ দুই লাইনে দেখো: A @ e1 হুবহু A[:, 0] — আমাদের মূলমন্ত্রের জীবন্ত প্রমাণ।
⚠️ সাবধান: A * x লিখো না — ওটা element-wise গুণ, matrix গুণ নয়। Matrix গুণের জন্য সবসময় @ (অথবা np.dot)।
import matplotlib.pyplot as plt
# transformation-টা চোখে দেখা: গ্রিডের ছবি আগে-পরে
pts = np.array([[i, j] for i in range(-3, 4) for j in range(-3, 4)], float).T
tp = A @ pts # সব বিন্দু একসাথে transform!
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].scatter(pts[0], pts[1], c='#1f77b4'); axes[0].set_title('before')
axes[1].scatter(tp[0], tp[1], c='#d62728'); axes[1].set_title('after A')
for ax in axes: ax.set_aspect('equal'); ax.set_xlim(-8, 8); ax.set_ylim(-8, 8)
plt.show()
লক্ষ করো: A @ pts-এ pts একটা \(2 \times 49\) matrix — ৪৯টা বিন্দু একসাথে transform হয়ে গেল এক লাইনে। Matrix-এর column-picture-ই এই জাদুর কারণ: প্রতিটা column (একেকটা বিন্দু) আলাদা আলাদা গুণ হয়।
৭. Worked Examples¶
Example 1 — column পড়ে transformation চেনা। \(B = \begin{bmatrix}0 & 1\\ 1 & 0\end{bmatrix}\) কি করে?
ধাপ ১: প্রথম column \((0, 1)\) — অর্থাৎ \(\mathbf{e}_1\) (ডানমুখো তীর) গিয়ে নামবে সোজা উপরে। ধাপ ২: দ্বিতীয় column \((1, 0)\) — অর্থাৎ \(\mathbf{e}_2\) (উপরমুখো তীর) নামবে ডান দিকে। ধাপ ৩: দুই অক্ষ জায়গা বদল করছে — এটা \(y = x\) রেখার সাপেক্ষে reflection(প্রতিফলন), আয়নার মতো। যাচাই: \(B\begin{bmatrix}3\\2\end{bmatrix} = \begin{bmatrix}2\\3\end{bmatrix}\) — coordinates উল্টে গেল। ✓
Example 2 — দুই চোখে \(A\mathbf{x}\)। \(A = \begin{bmatrix}1 & 2\\ 3 & 4\\ 5 & 6\end{bmatrix}\), \(\mathbf{x} = \begin{bmatrix}2\\-1\end{bmatrix}\) হলে \(A\mathbf{x}\) কত?
আকার আগে: \((3\times 2)(2 \times 1) \to 3\times 1\) — উত্তর হবে \(\mathbb{R}^3\)-এর vector। plane থেকে space-এ লাফ! Row picture: \(\begin{bmatrix}(1)(2)+(2)(-1)\\ (3)(2)+(4)(-1)\\ (5)(2)+(6)(-1)\end{bmatrix} = \begin{bmatrix}0\\2\\4\end{bmatrix}\)। Column picture: \(2\begin{bmatrix}1\\3\\5\end{bmatrix} - 1\begin{bmatrix}2\\4\\6\end{bmatrix} = \begin{bmatrix}2-2\\6-4\\10-6\end{bmatrix} = \begin{bmatrix}0\\2\\4\end{bmatrix}\)। ✓ মিলে গেল।
Example 3 — গন্তব্য থেকে matrix বানানো। এমন matrix \(C\) চাই যে \(\mathbf{e}_1\)-কে পাঠায় \((3, 1)\)-এ আর \(\mathbf{e}_2\)-কে পাঠায় \((-1, 2)\)-এ।
ধাপ ১: মূলমন্ত্র উল্টো করে খাটাও — গন্তব্যগুলোকেই column বানিয়ে বসাও:
ধাপ ২: যাচাই: \(C\mathbf{e}_1 = \begin{bmatrix}3\\1\end{bmatrix}\) ✓, \(C\mathbf{e}_2 = \begin{bmatrix}-1\\2\end{bmatrix}\) ✓। Transformation ডিজাইন করা এতই সহজ — চাহিদামতো গন্তব্য ঠিক করো, column-এ বসাও, শেষ।
৮. Problems ও Solutions¶
Problem 1. \(M = \begin{bmatrix}4 & -2 & 7\\ 0 & 3 & 1\end{bmatrix}\)-এর আকার কত? \(m_{12}\), \(m_{23}\), \(m_{21}\) কত? \(M\) কোন space থেকে কোন space-এ vector পাঠায়?
Solution
আকার: ২টা row, ৩টা column — অর্থাৎ \(2 \times 3\)।
Entry-র নিয়ম \(m_{ij}\) = \(i\)-তম row, \(j\)-তম column:
- \(m_{12} = -2\) (১ম row, ২য় column)
- \(m_{23} = 1\) (২য় row, ৩য় column)
- \(m_{21} = 0\) (২য় row, ১ম column)
\(2\times 3\) matrix গুণ করা যায় \(3\times 1\) vector-এর সাথে, ফল \(2 \times 1\)। তাই \(M : \mathbb{R}^3 \to \mathbb{R}^2\) — 3D থেকে 2D-তে নামায় (যেমন ক্যামেরা 3D দৃশ্যকে 2D ছবিতে ফেলে)।
Problem 2. \(A = \begin{bmatrix}1 & -1\\ 2 & 0\end{bmatrix}\), \(\mathbf{x} = \begin{bmatrix}3\\1\end{bmatrix}\)। (a) Row picture দিয়ে \(A\mathbf{x}\) বের করো। (b) Column picture দিয়ে আবার করো। (c) দুই উত্তর মিলল কি?
Solution
(a) Row picture (প্রতি row-এর সাথে dot product):
(b) Column picture (column-দের combination, weight হলো \(\mathbf{x}\)-এর entries):
(c) হ্যাঁ, দুটোই \(\begin{bmatrix}2\\6\end{bmatrix}\) — সবসময় মিলবে, কারণ দুটো একই যোগফলের দুই রকম সাজানো।
Problem 3. শুধু column দেখে বলো নিচের matrix-গুলো জ্যামিতিকভাবে কি করে (হিসাব প্রায় লাগবেই না): (a) \(\begin{bmatrix}3 & 0\\ 0 & 3\end{bmatrix}\) (b) \(\begin{bmatrix}-1 & 0\\ 0 & 1\end{bmatrix}\) (c) \(\begin{bmatrix}0 & 0\\ 0 & 0\end{bmatrix}\)
Solution
(a) \(\mathbf{e}_1 \to (3,0)\), \(\mathbf{e}_2 \to (0,3)\) — দুই অক্ষই নিজ দিকে ৩ গুণ লম্বা। এটা সব দিকে সমান scaling (uniform scaling): প্রতিটা vector ৩ গুণ হয়, দিক অটুট।
(b) \(\mathbf{e}_1 \to (-1,0)\) — ডানমুখো তীর বাঁমুখো হয়ে গেল; \(\mathbf{e}_2 \to (0,1)\) — অনড়। এটা \(y\)-axis-এর সাপেক্ষে reflection: বাঁ-ডান উল্টে যায়, উপর-নিচ ঠিক থাকে।
(c) সব basis vector \(\to (0,0)\)। পুরো plane চুপসে গিয়ে origin-এ জমা হয় — zero matrix, সবচেয়ে ধ্বংসাত্মক transformation। (লক্ষ করো: এর কোনো "undo" সম্ভব না — Chapter 3.4-এ এই হারানোর গল্প।)
Problem 4. এমন \(2\times 2\) matrix \(R\) লেখো যেটা প্রতিটা vector-কে ঘড়ির কাঁটার বিপরীতে \(180°\) ঘোরায়। তারপর দেখাও \(R\mathbf{v} = -\mathbf{v}\) সব \(\mathbf{v}\)-এর জন্য।
Solution
\(180°\) ঘুরলে \(\mathbf{e}_1 = (1,0) \to (-1, 0)\) আর \(\mathbf{e}_2 = (0,1) \to (0,-1)\)। গন্তব্যগুলো column-এ বসাই:
যেকোনো \(\mathbf{v} = \begin{bmatrix}x\\y\end{bmatrix}\)-এর জন্য:
অর্থাৎ \(180°\) ঘোরানো আর \(-1\) দিয়ে scale করা — একই কাজ! (এই \(R = -I\); identity matrix \(I\)-এর সাথে Chapter 3.5-এ ভালো করে আলাপ হবে।)
Problem 5. একটা কারখানা \(2\) ধরনের পণ্য বানায়। পণ্য-১-এ লাগে \(3\) কেজি কাঁচামাল ও \(2\) ঘণ্টা শ্রম; পণ্য-২-এ লাগে \(1\) কেজি ও \(4\) ঘণ্টা। (a) এই তথ্য একটা matrix \(F\)-এ সাজাও যাতে \(F\begin{bmatrix}q_1\\q_2\end{bmatrix}\) = মোট (কাঁচামাল, শ্রম)। (b) \(q_1 = 10, q_2 = 5\) হলে মোট কত লাগবে? (c) \(F\)-এর column গুলোর বাস্তব মানে কি?
Solution
(a) Output-এর ১ম entry = মোট কাঁচামাল, ২য় = মোট শ্রম চাই। তাহলে:
(১ম column = পণ্য-১-এর চাহিদা, ২য় column = পণ্য-২-এর চাহিদা।)
(b)
মোট \(35\) কেজি কাঁচামাল, \(40\) ঘণ্টা শ্রম।
(c) \(F\mathbf{e}_1 = \begin{bmatrix}3\\2\end{bmatrix}\) = "শুধু ১ ইউনিট পণ্য-১ বানালে যা লাগে।" Column picture এখানে ব্যবসার ভাষায় কথা বলছে: মোট খরচ = (পণ্য-১-এর recipe)\(\times q_1\) + (পণ্য-২-এর recipe)\(\times q_2\)। Guest বইয়ের chapter 1-এর "organizing information" ধারণাটা ঠিক এটাই।
Problem 6. \(T\) একটা transformation যেটা প্রথমে প্রতিটা vector-এর \(x\)-অংশ দ্বিগুণ করে, তারপর ফলটাকে \(y=x\) রেখায় reflect করে। \(T\)-এর matrix বের করো (\(\mathbf{e}_1, \mathbf{e}_2\)-কে অনুসরণ করে)।
Solution
\(\mathbf{e}_1 = (1,0)\)-কে অনুসরণ করি: \(x\) দ্বিগুণ \(\Rightarrow (2,0)\); তারপর reflect (coordinates অদলবদল) \(\Rightarrow (0,2)\)।
\(\mathbf{e}_2 = (0,1)\): \(x\) দ্বিগুণ \(\Rightarrow (0,1)\) (এর \(x\) তো \(0\)-ই); reflect \(\Rightarrow (1,0)\)।
গন্তব্য দুটো column-এ:
যাচাই: \(T\begin{bmatrix}1\\1\end{bmatrix} = \begin{bmatrix}1\\2\end{bmatrix}\)। হাতে হাতে: \((1,1)\xrightarrow{x\times 2}(2,1)\xrightarrow{\text{reflect}}(1,2)\) ✓। (দুটো ধাপ পরপর — এটা আসলে দুটো matrix-এর composition; Chapter 3.3-এ এর পুরো নিয়ম আসছে।)
Problem 7. সত্য না মিথ্যা — কারণসহ: (a) \(2\times 2\) matrix-এর ৪টা সংখ্যা মানে ৪টা স্বাধীন তথ্য, জ্যামিতির সাথে সম্পর্কহীন। (b) \(A\mathbf{x}\) সবসময় \(A\)-এর column গুলোর একটা linear combination। (c) এমন matrix আছে যেটা origin-কে \((1,1)\)-এ সরায়।
Solution
(a) মিথ্যা। ৪টা সংখ্যা = দুই basis vector-এর গন্তব্যের ৪টা coordinate। প্রতিটা সংখ্যার জ্যামিতিক অর্থ আছে: যেমন \(a_{21}\) = "transformation-এর পর \(\mathbf{e}_1\)-এর মাথা কতটা উপরে।"
(b) সত্য। Column picture-ই এটা: \(A\mathbf{x} = x_1(\text{col}_1) + x_2(\text{col}_2) + \cdots\) — weight গুলো \(\mathbf{x}\)-এর entries। এ থেকেই পরে (Part IV) বলব: সব সম্ভব output-এর সেট = column-দের span।
(c) মিথ্যা। যেকোনো matrix-এর জন্য \(A\mathbf{0} = 0\cdot(\text{col}_1) + 0\cdot(\text{col}_2) = \mathbf{0}\)। Origin কখনো নড়ে না। "সরানো" (translation) মোটেই linear transformation নয় — Chapter 3.6-এ বিস্তারিত।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ ঠিক ধারণা |
|---|---|
| "Matrix মানে শুধু সংখ্যার টেবিল, মুখস্থের জিনিস" | Matrix হলো একটা transformation-এর সংক্ষিপ্ত ঠিকানা-তালিকা: column \(j\) = "\(\mathbf{e}_j\) কোথায় যাবে" |
| \(a_{ij}\)-তে \(i\) মানে column, \(j\) মানে row | উল্টো! আগে row (\(i\)), পরে column (\(j\)) — \(a_{12}\) = ১ম row, ২য় column |
NumPy-তে A * x দিলেই matrix গুণ হয় |
* হলো element-wise; matrix গুণ A @ x। দুটো সম্পূর্ণ ভিন্ন উত্তর দেয় |
| "\(A\mathbf{x}\)-এ output-এর আকার input-এর সমানই হবে" | \(m\times n\) matrix \(n\)-vector-কে \(m\)-vector বানায়; \(m \ne n\) হলে মাত্রাই বদলে যায় |
| "Matrix দিয়ে যেকোনো নড়াচড়া লেখা যায়" | শুধু linear transformation-ই লেখা যায় — origin অনড়, গ্রিডলাইন সোজা ও সমান্তরাল। Translation লেখা যায় না |
১০. এক নজরে¶
| ধারণা | সারকথা |
|---|---|
| Matrix (রূপ) | \(m \times n\) সংখ্যার আয়তাকার বিন্যাস; \(a_{ij}\) = row \(i\), column \(j\) |
| Matrix (কাজ) | Function \(\mathbb{R}^n \to \mathbb{R}^m\): \(\mathbf{x} \mapsto A\mathbf{x}\) |
| মূলমন্ত্র | Column \(j\) = \(A\mathbf{e}_j\) = basis vector-এর গন্তব্য |
| Row picture | output entry \(i\) = (row \(i\)) \(\cdot\) \(\mathbf{x}\) — হিসাবের হাতিয়ার |
| Column picture | \(A\mathbf{x}\) = column-দের linear combination — বোঝার হাতিয়ার |
| Linearity | \(A(\mathbf{u}+\mathbf{v}) = A\mathbf{u}+A\mathbf{v}\), \(A(c\mathbf{v}) = cA\mathbf{v}\) |
| সীমাবদ্ধতা | Origin নড়ে না (\(A\mathbf{0}=\mathbf{0}\)); শুধু linear map-ই matrix হয় |
পরের chapter-এর সেতু: এখন যেহেতু জানো matrix মানে space-এর transformation, পরের chapter-এ আমরা বিখ্যাত transformation-দের পুরো চিড়িয়াখানা ঘুরব — rotation, shear, scaling, projection — প্রতিটার আগে-পরে গ্রিডের ছবিসহ। চোখ বন্ধ করলেই যেন matrix দেখে ছবি ভেসে ওঠে — সেটাই লক্ষ্য।
📓 Notebook Project¶
notebooks/part-03/ch01-project.ipynb — Matrix-machine playground: scratch-এ নিজের matvec ফাংশন লিখে NumPy-র সাথে মিলিয়ে দেখা, আর random matrix-এর column-গল্প গ্রিড এঁকে যাচাই করা।