Chapter 6.6 — Singular Value Decomposition (SVD — সব matrix-এর ভেতরের গল্প)¶
এই Part-এ এতদিন যা শিখলে তার সবচেয়ে বড় পুরস্কারটা আজ। Diagonalization সুন্দর, কিন্তু খুঁতখুঁতে — eigenvector কম পড়লে (defective!) চলে না, rectangular matrix-এ প্রশ্নই ওঠে না। Spectral theorem রাজকীয়, কিন্তু শুধু symmetric matrix-এর রাজপ্রাসাদে। আজকের theorem-টার কোনো শর্তই নেই: পৃথিবীর প্রতিটা matrix — square হোক বা \(427\times640\)-এর একটা ছবি — ভাঙা যায় তিনটা সরল ধাপে: ঘোরাও → টানো → আবার ঘোরাও। এর নাম Singular Value Decomposition(সিঙ্গুলার ভ্যালু ডিকম্পোজিশন — SVD), আর অনেক গণিতবিদ একে বলেন linear algebra-র চূড়া। Netflix-এর recommendation, ছবির compression, Google-এর শব্দার্থ বোঝা, আর পরের chapter-এর PCA — সবার engine-রুমে এই একটাই যন্ত্র ঘোরে।
🎯 এই chapter-এ যা শিখবে¶
- \(A = U\Sigma V^T\) — যেকোনো \(m \times n\) matrix = rotation × stretch × rotation; কোনো শর্ত নেই, defective-ও না, square-ও লাগে না
- জ্যামিতির মূল ছবি: unit circle → ellipse — ellipse-এর আধা-অক্ষগুলোই \(\sigma_i u_i\)
- Singular Value(সিঙ্গুলার ভ্যালু) \(\sigma_i\) বনাম eigenvalue — কোথায় মিল, কোথায় সাংঘাতিক অমিল (\(\sigma_i = \sqrt{\lambda_i(A^TA)}\), সবসময় real ও \(\geq 0\))
- \(A\)-কে rank-1 স্তরে ভাঙা: \(A = \sigma_1 u_1v_1^T + \sigma_2 u_2v_2^T + \cdots\) — আর Eckart–Young Theorem(একার্ট–ইয়াং): প্রথম \(k\)টা স্তরই সেরা Low-Rank Approximation(লো-র্যাঙ্ক অ্যাপ্রক্সিমেশন)
- Image compression-এর preview + Part IV-এর চার fundamental subspace-এর গল্পের সমাপ্তি — চারটারই orthonormal basis ফ্রি-তে
🖼️ এক ছবিতে মূল idea¶
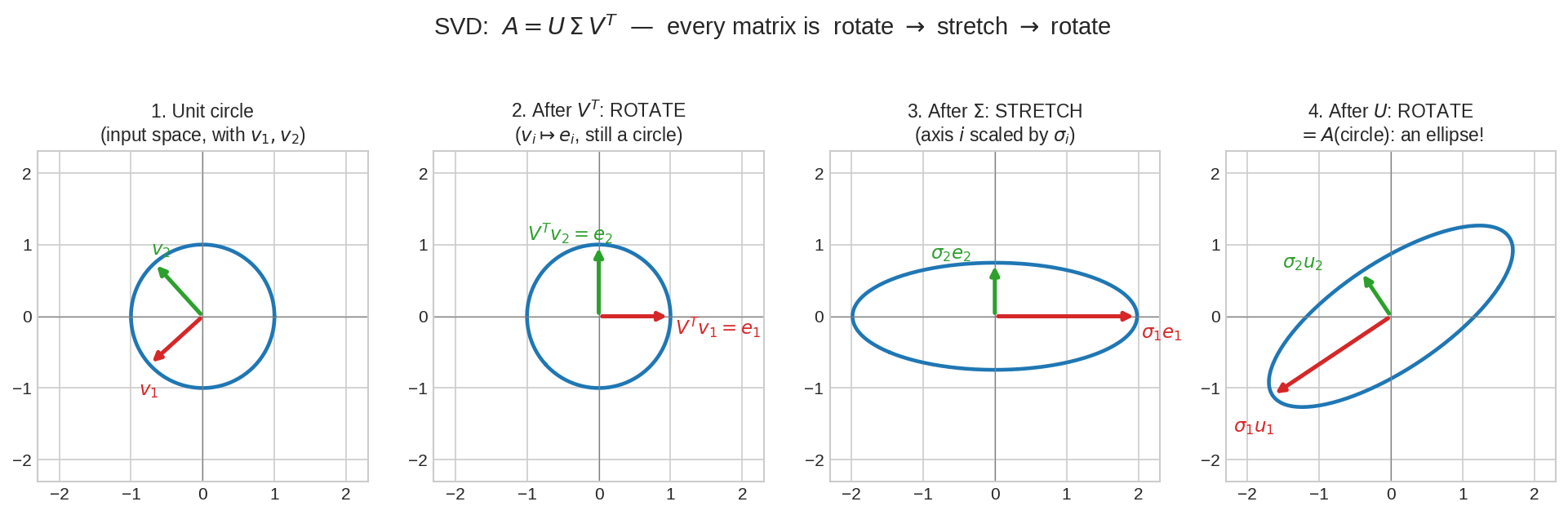
একটা unit circle-কে \(A = U\Sigma V^T\)-এর তিন ধাপে অনুসরণ করো: (১) শুরুতে বৃত্ত, তার ওপর দুটো বিশেষ লম্ব দিক \(v_1 \perp v_2\); (২) \(V^T\) শুধু ঘোরায় — \(v_i\)-রা গিয়ে বসে অক্ষের ওপর, বৃত্ত বৃত্তই; (৩) \(\Sigma\) অক্ষ বরাবর টানে — \(i\)-নং অক্ষ \(\sigma_i\) গুণ, বৃত্ত হয়ে যায় ellipse; (৪) \(U\) আবার শুধু ঘোরায় — ellipse-টা তার শেষ অবস্থানে। ফলাফল হুবহু \(A\)(circle)। যেকোনো matrix-এর যত জটিল আচরণ, সব এই তিন সরল ধাপের সাজানো নাটক।
১. কি? (What)¶
দৈনন্দিন analogy: রুটি বেলার সঠিক কোণ¶
রুটি বেলার কথা ভাবো। বেলনা যেদিকে চালাও রুটি সেদিকে লম্বা হয়, আড়াআড়ি দিকে প্রায় একই থাকে। এখন ধরো একটা অদ্ভুত মেশিন রুটিকে একইসাথে টানে, ঘোরায়, হেলায় — দেখে মনে হয় ভীষণ জটিল। SVD-র আবিষ্কার: ঠিক কোণে দাঁড়িয়ে দেখলে জটিলতাটা উধাও। ময়দার ওপর সঠিক দুটো লম্ব দাগ (\(v_1, v_2\)) এঁকে দাও — মেশিন যাই করুক, ওই দাগ দুটো শুধু টানা হবে (\(\sigma_1, \sigma_2\) গুণ) আর ঘুরে গিয়ে নতুন দুটো লম্ব দাগে (\(u_1, u_2\)) বসবে। বাঁকাচোরা কিছুই আসলে ঘটে না — শুধু ইনপুটের সঠিক অক্ষ আর আউটপুটের সঠিক অক্ষ চিনতে হয়।
সংজ্ঞা¶
যেকোনো \(m \times n\) matrix \(A\) (rank \(r\))-কে লেখা যায়:
- \(V\): \(n \times n\) orthogonal matrix — column-গুলো \(v_1, \dots, v_n\) হলো right singular vector (ইনপুট জগতের সঠিক অক্ষ),
- \(U\): \(m \times m\) orthogonal matrix — column-গুলো \(u_1, \dots, u_m\) হলো left singular vector (আউটপুট জগতের সঠিক অক্ষ),
- \(\Sigma\): \(m \times n\) diagonal — diagonal-এ singular value \(\sigma_1 \geq \sigma_2 \geq \cdots \geq \sigma_r > 0\), বাকি সব শূন্য। সবসময় real, সবসময় \(\geq 0\), সবসময় বড় থেকে ছোট সাজানো।
পুরোটার হৃদয় একটা সমীকরণে — column ধরে ধরে পড়লে \(AV = U\Sigma\) মানে:
পড়ো ছবির ভাষায়: "\(A\)-কে \(v_i\) খাওয়ালে বেরোয় \(u_i\)-এর দিকে \(\sigma_i\) লম্বা একটা vector।" Eigenvector-এর \(Av = \lambda v\)-র সাথে মেলাও — সেখানে ইনপুট-আউটপুট একই দিক ছিল; এখানে দিক দুটো আলাদা হতে দেওয়া হয়েছে (\(v_i\) ঢোকে, \(u_i\) বেরোয়) — আর এই ছাড়টুকু দেওয়ার বিনিময়েই theorem-টা সব matrix-এ খাটে।
Orthogonal মানে মনে আছে তো?¶
Part V থেকে: \(U^TU = I\), \(V^TV = I\) — মানে \(U, V\) শুধু rotation/reflection, দৈর্ঘ্য-কোণ কিছুই বদলায় না (আর Chapter 6.1 থেকে: \(|\det| = 1\), আয়তনও না)। তাই \(A\)-র সব "টানাটানি"-র খবর একা \(\Sigma\)-র কাছে — matrix-এর আসল শক্তি মাপতে চাইলে singular value দেখো।
২. দেখতে কেমন?¶
দৃশ্য ১: shear-ও গোপনে rotate–stretch–rotate¶
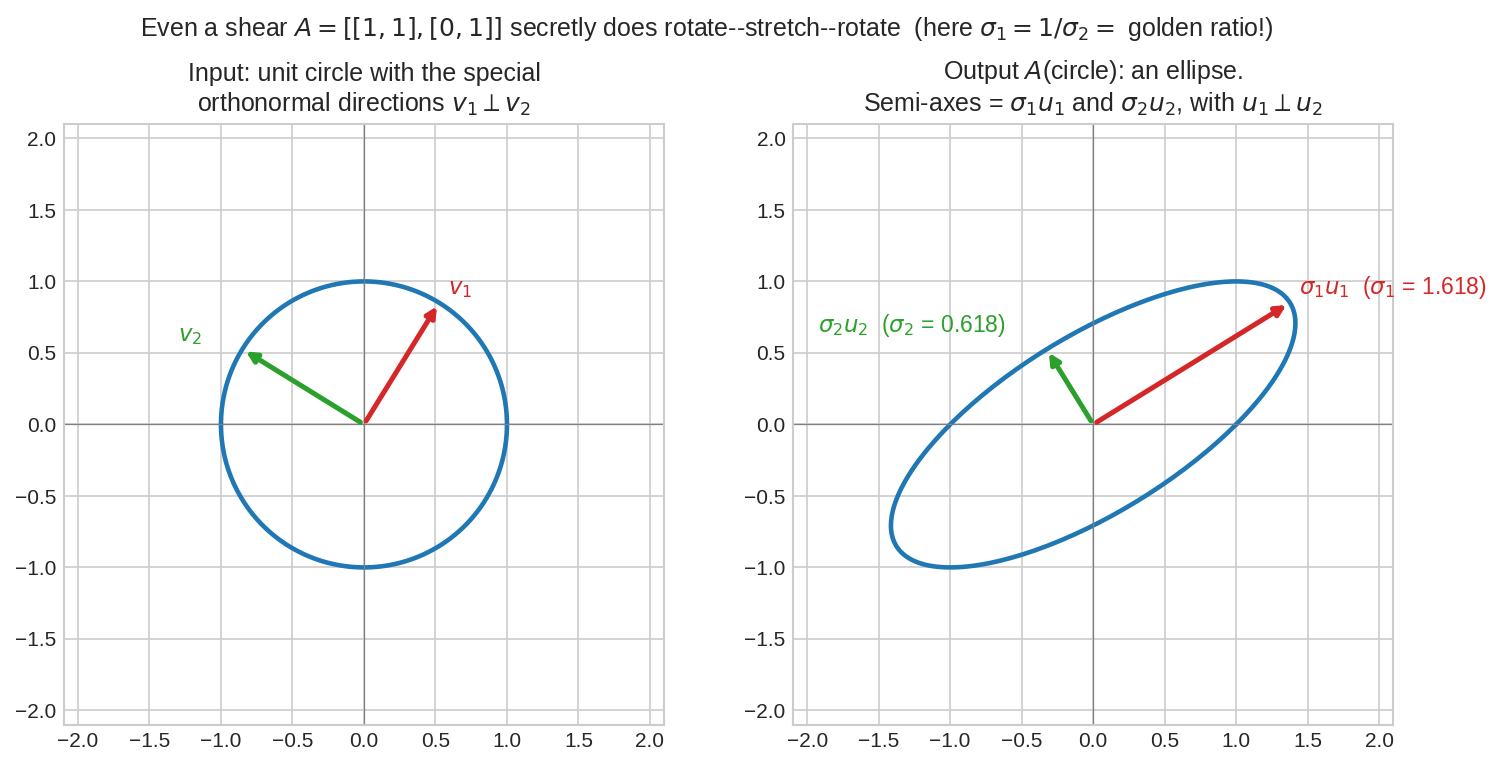
Shear \(A = \begin{bmatrix}1&1\\0&1\end{bmatrix}\) — Chapter 6.2-এর সেই defective বদমাশ, যার eigenvector-দিক মোটে একটা। কিন্তু SVD-র চোখে সে-ও ভদ্র: ইনপুট বৃত্তের ওপর ঠিক দুটো লম্ব দিক \(v_1 \perp v_2\) আছে যারা আউটপুটে গিয়ে ellipse-এর দুই লম্ব আধা-অক্ষ \(\sigma_1u_1 \perp \sigma_2u_2\) হয়। (মজা: এখানে \(\sigma_1 = 1.618\ldots\) — golden ratio, আর \(\sigma_2 = 1/\sigma_1\)!) Eigen-জগতে যে matrix সমস্যাজনক, singular-জগতে সে-ও নিখুঁত।
এটাই SVD-র জ্যামিতিক সারকথা: যেকোনো matrix unit circle(/sphere)-কে ellipse(/ellipsoid)-এ পাঠায় — আর ellipse-এর আধা-অক্ষের দৈর্ঘ্যগুলোই \(\sigma_1, \sigma_2, \ldots\), দিকগুলোই \(u_1, u_2, \ldots\)।
দৃশ্য ২: চার fundamental subspace — গল্পের শেষ অঙ্ক¶
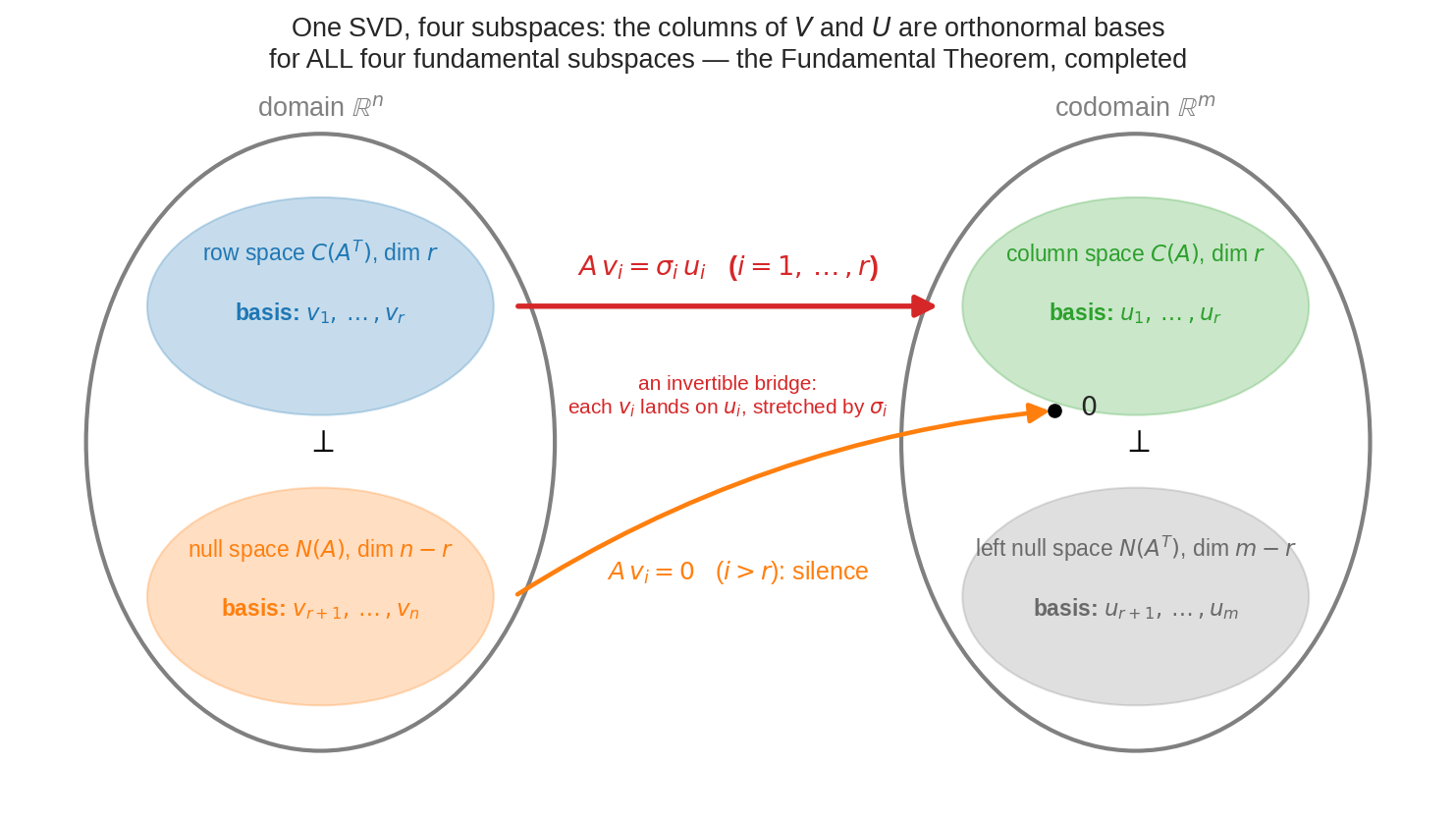
Part IV-এ চারটা subspace চিনেছিলে; Part V-এ শিখেছিলে row space \(\perp\) null space, column space \(\perp\) left null space। SVD এসে সেই ছবিটা সম্পূর্ণ করলো: \(v_1,\dots,v_r\) হলো row space-এর orthonormal basis, \(v_{r+1},\dots,v_n\) null space-এর; \(u_1,\dots,u_r\) column space-এর, \(u_{r+1},\dots,u_m\) left null space-এর। আর মাঝখানে লাল সেতুটা: row space-এর প্রতিটা basis vector \(v_i\) ঠিক \(\sigma_i\) গুণ হয়ে column space-এর basis vector \(u_i\)-তে নামে — null space-এর বাসিন্দারা যায় শূন্যে। এক decomposition-এ চার subspace-এর নিখুঁত মানচিত্র।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- ছবি/ভিডিও compression: ছবি মানেই সংখ্যার matrix — SVD-তে ভেঙে ছোট \(\sigma\)-র স্তর ফেলে দিলে ছবি প্রায় অবিকল, জায়গা লাগে ভগ্নাংশ (আজকের Notebook Project-এ হাতে-কলমে)।
- Noise কমানো: সত্যিকারের signal থাকে কয়েকটা বড় \(\sigma\)-র স্তরে, এলোমেলো noise ছড়িয়ে থাকে ছোট \(\sigma\)-দের মধ্যে — লেজ ছেঁটে দিলে noise-ই আগে যায়। MRI, জিনোমিক্স, অডিও — সবখানে এই কৌশল।
- যন্ত্রের স্বাস্থ্যপরীক্ষা: engineering-এ system-এর matrix-টার \(\sigma_{\min}\) শূন্যের কাছে চলে যাওয়া মানে কাঠামো ভাঙনের পথে — determinant-এর চেয়ে অনেক নির্ভরযোগ্য signal (Chapter 6.1-এর সাবধানবাণী মনে আছে?)।
Data Science / ML-এ:
- Recommender system: Netflix-এর (user × movie) rating matrix-টা প্রায় low-rank — মানুষের রুচি আসলে অল্প ক'টা "স্বাদ-দিক" (action-প্রেমী? রোমকম?) দিয়ে চলে। SVD সেই লুকানো দিকগুলো বের করে ফাঁকা ঘরগুলো আন্দাজ করে — বিখ্যাত Netflix Prize-এর বিজয়ী কৌশলের মেরুদণ্ড।
- Latent Semantic Analysis: (document × word) matrix-এ SVD চালালে \(u, v\)-রা হয়ে যায় "topic" — "গাড়ি" আর "অটোমোবাইল" আলাদা শব্দ হয়েও এক topic-স্তরে পড়ে; search engine সমার্থক শব্দ বোঝে এভাবেই।
- PCA-র engine: পরের chapter-এর পুরো কারিগরি ভেতরে ভেতরে ডেটা matrix-এর SVD — \(v_i\)-রাই principal component।
- Pseudoinverse ও least squares: singular/rectangular matrix-এর "যতটা সম্ভব inverse" \(A^+ = V\Sigma^+U^T\) — শূন্য নয় এমন \(\sigma\)-গুলো উল্টে দাও, বাকি বাদ।
np.linalg.lstsqভেতরে এটাই করে। - Condition number: Chapter 6.5-এ দেখা \(\kappa = \sigma_{\max}/\sigma_{\min}\) — ellipse কতটা সরু, হিসাব কতটা বিপজ্জনক।
৪. Properties¶
Property 1 — অস্তিত্বের গ্যারান্টি: সবার জন্য, সবসময়¶
প্রতিটা \(m \times n\) real matrix-এর SVD আছেই — symmetric লাগে না, square লাগে না, defective হলেও চলে। (কেন — Intuition-এ, আর প্রমাণের পুরো কৃতিত্ব Chapter 6.4-এর spectral theorem-এর।) Diagonalization-এর সব ব্যর্থ কেস — shear, rectangular — সবাই SVD-তে ধরা দেয়।
Property 2 — \(\sigma\), \(v\), \(u\) কোথা থেকে আসে: \(A^TA\) আর \(AA^T\)¶
\(A = U\Sigma V^T\) হলে:
ডান পাশটা চিনতে পারছো? এটা \(A^TA\)-র spectral decomposition (Chapter 6.4)! অর্থাৎ:
- \(v_i\) = \(A^TA\)-র eigenvector, আর \(\sigma_i^2\) = তার eigenvalue: \(\boxed{\sigma_i = \sqrt{\lambda_i(A^TA)}}\)
- একইভাবে \(AA^T = U(\Sigma\Sigma^T)U^T\) — \(u_i\) = \(AA^T\)-র eigenvector, eigenvalue সেই \(\sigma_i^2\)-ই।
\(A^TA\) symmetric ও positive semidefinite (Chapter 6.5: \(x^TA^TAx = \|Ax\|^2 \geq 0\)) — তাই eigenvalue-রা real ও \(\geq 0\), বর্গমূল নেওয়া সবসময় বৈধ। হাতে SVD বের করার recipe-ও এটাই (Worked Example 1)।
Property 3 — Singular value বনাম eigenvalue: মুখোমুখি¶
| প্রশ্ন | Eigenvalue \(\lambda\) | Singular value \(\sigma\) |
|---|---|---|
| কোন matrix-এর জন্য? | শুধু square | যেকোনো \(m\times n\) |
| Real হওয়ার গ্যারান্টি? | না (rotation → complex) | সবসময় real, \(\geq 0\) |
| ইনপুট-আউটপুট দিক | একই (\(Av = \lambda v\)) | আলাদা হতে পারে (\(Av_i = \sigma_iu_i\)) |
| Vector-রা লম্ব? | সাধারণত না (symmetric হলে হ্যাঁ) | সবসময় (\(v\)-রা লম্ব, \(u\)-রাও) |
| মানে কী মাপে? | invariant দিকের scale | সর্বোচ্চ/অক্ষভিত্তিক stretch: \(\sigma_1 = \max\|Ax\|/\|x\|\) |
| কখন দুটো এক? | — | \(A\) symmetric positive semidefinite হলে \(\sigma_i = \lambda_i\) |
Square matrix-এও দুটো সাধারণত আলাদা: shear-এর eigenvalue দুটোই \(1\), কিন্তু \(\sigma_1 \approx 1.618 > 1\) — eigenvalue বলছে "কিছু বদলায় না", singular value ধরে ফেলছে "মোটেই না, তির্যকে দিব্যি টানে!" আর symmetric হলে সম্পর্কটা \(\sigma_i = |\lambda_i|\)।
Property 4 — Rank, norm, determinant: সব খবর \(\Sigma\)-তে¶
- Rank \(r\) = nonzero singular value-র সংখ্যা (orthogonal matrix rank বদলায় না — সব ভাঙাভাঙির পরে গোনা যায় শুধু \(\Sigma\)-তে)।
- \(\|A\|_2 = \sigma_1\) (সবচেয়ে বড় stretch), \(\|A\|_F = \sqrt{\sigma_1^2 + \cdots + \sigma_r^2}\) (Frobenius norm — সব entry-র বর্গের যোগফলের বর্গমূল)।
- Square হলে \(|\det A| = \sigma_1\sigma_2\cdots\sigma_n\) — Chapter 6.1-এর ভাষায়: unit circle → ellipse, আর ellipse-এর area \(= \pi\sigma_1\sigma_2\), বৃত্তের \(\pi\) গুণে ঠিক \(\sigma_1\sigma_2\) ✓
Property 5 — Rank-1 স্তরে ভাঙা¶
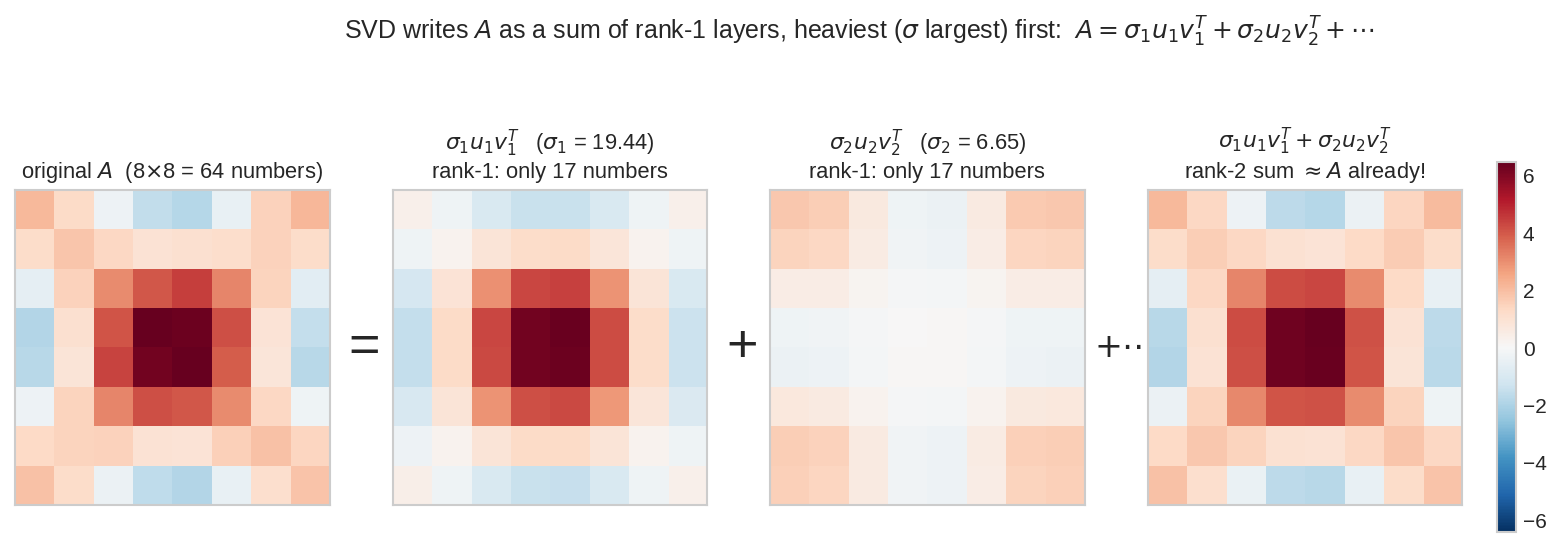
\(8\times8\) একটা matrix-কে (heatmap) SVD ভেঙেছে rank-1 স্তরে। প্রতিটা স্তর \(\sigma_iu_iv_i^T\) — মোটে \(17\)টা সংখ্যা (\(8+8+1\)), অথচ প্রথম দুটো স্তর যোগ করতেই আসল \(64\)-সংখ্যার matrix-এর প্রায় সবটা ফিরে এসেছে। ভারী স্তর (\(\sigma\) বড়) আগে, হালকা স্তর পরে — এই সাজানোটাই compression-এর চাবি।
Matrix গুণের column-row রূপে (Part III) \(U\Sigma V^T\) খুললে:
প্রতিটা \(u_iv_i^T\) একটা rank-1 matrix (একটা column × একটা row) — \(A\)-র একেকটা "স্তর", আর \(\sigma_i\) স্তরটার ওজন। SVD মানে: যেকোনো matrix = ওজন অনুসারে সাজানো rank-1 স্তরের যোগফল, ভারীটা আগে।
Property 6 — Eckart–Young: লেজ ছাঁটাই-ই সেরা¶
প্রথম \(k\)টা স্তর রেখে বাকি ছেঁটে দাও: \(A_k = \sum_{i=1}^{k}\sigma_iu_iv_i^T\)। Eckart–Young theorem বলে: rank-\(k\) matrix-দের গোটা রাজ্যে \(A\)-র সবচেয়ে কাছের matrix-টা ঠিক এই \(A_k\)-ই —
(Frobenius norm-এও একই বিজয়ী, error \(= \sqrt{\sigma_{k+1}^2 + \cdots + \sigma_r^2}\)।) ভুলটাও আগে থেকে জানা: প্রথম যে স্তরটা ফেললে, তার ওজনটাই তোমার error। এই একটা theorem-ই image compression, PCA, recommender — সবার বৈধতার সনদ।
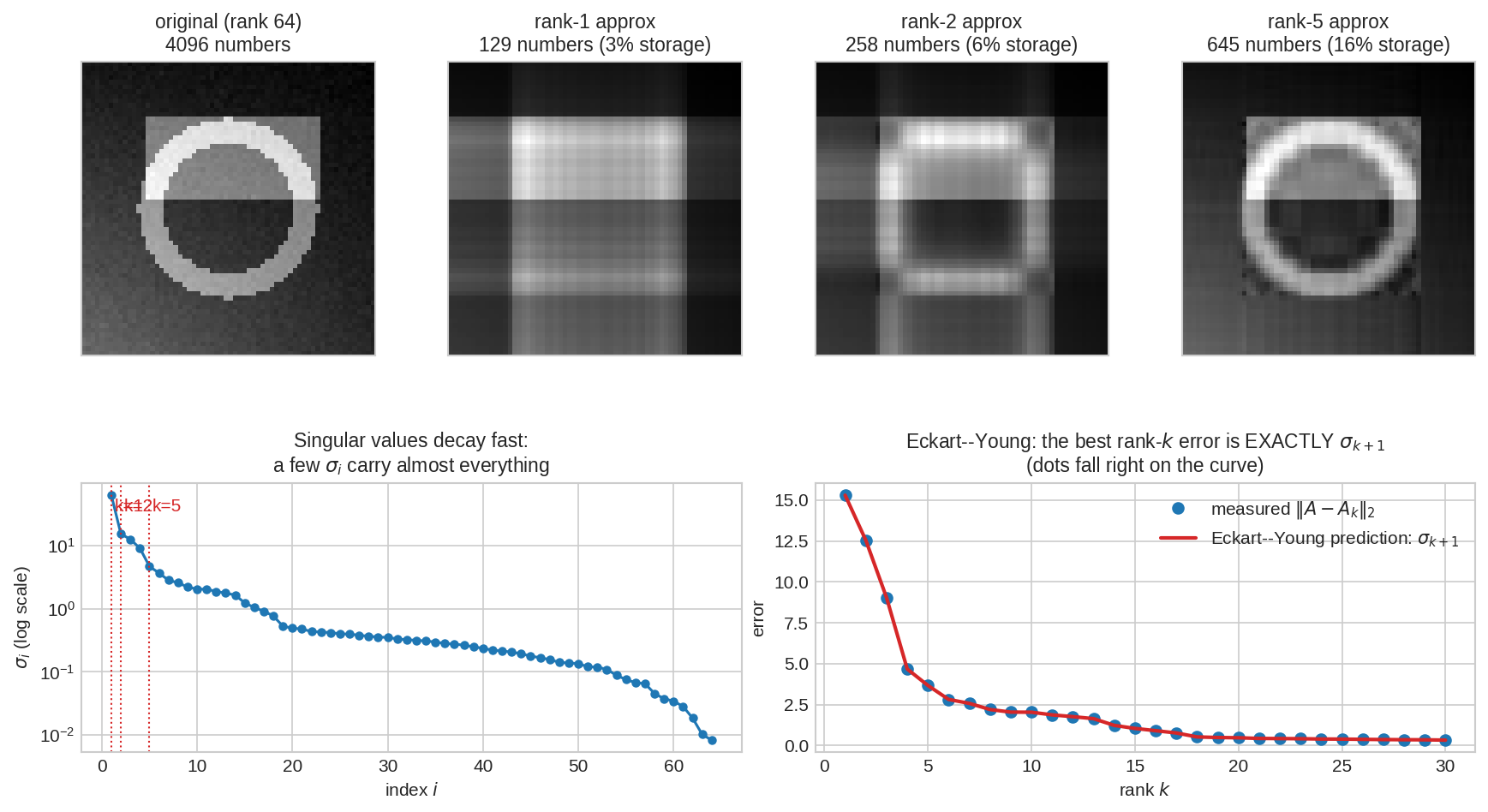
ওপরে: একটা \(64\times64\) synthetic "ছবি" আর তার rank-\(1\), \(2\), \(5\) approximation — rank \(5\)-এই মূল কাঠামো চেনা যায়, storage মাত্র কয়েক শতাংশ। নিচে বাঁয়ে: singular value-রা log scale-এ হুড়মুড়িয়ে পড়ে — অল্প ক'টা \(\sigma\)-ই প্রায় সব বহন করে। নিচে ডানে: প্রতিটা \(k\)-তে মাপা error (নীল বিন্দু) পড়েছে হুবহু Eckart–Young-এর ভবিষ্যদ্বাণী \(\sigma_{k+1}\) (লাল রেখা)-র ওপর।
৫. Intuition — কেন সত্য?¶
কেন প্রতিটা matrix-এ এমন লম্ব-জোড়া থাকবেই?¶
পুরো theorem-টা দাঁড়িয়ে আছে একটা সরল পর্যবেক্ষণে: \(A\) যেমনই হোক, \(A^TA\) সবসময় symmetric (\(({A^TA})^T = A^TA^{TT} = A^TA\))। আর symmetric matrix-এর জন্য Chapter 6.4-এর spectral theorem পূর্ণ ক্ষমতায় খাটে: real eigenvalue, আর গোটা space জুড়ে orthonormal eigenvector \(v_1, \dots, v_n\) — কোনো defect নেই, কোনো complex নেই।
এখন জাদুটা দেখো — এই \(v_i\)-দের \(A\)-র ভেতর দিয়ে পাঠাই। \(i \neq j\) হলে:
ইনপুটে লম্ব ছিল, আউটপুটেও লম্ব রইলো! সাধারণ matrix লম্ব জিনিসকে লম্ব রাখে না — কিন্তু এই বিশেষ লম্ব-জোড়াগুলোকে রাখে, কারণ এরা \(A^TA\)-র eigenvector। আর প্রতিটার দৈর্ঘ্য?
তাহলে নামকরণ সারা: \(u_i = Av_i/\sigma_i\) (unit করে নেওয়া), আর পাওয়া গেলো \(Av_i = \sigma_iu_i\), যেখানে \(v\)-রা লম্ব, \(u\)-রাও লম্ব। এটাই SVD-র জন্ম — spectral theorem-কে একবার \(A^TA\)-তে খাটিয়ে যেকোনো matrix বশ। (Chapter 6.4 পড়ার আসল পুরস্কার এই পাঁচ লাইন।)
কেন unit circle থেকে ellipse?¶
বৃত্তের প্রতিটা বিন্দু \(x = (\cos t)v_1 + (\sin t)v_2\) (কারণ \(v_1, v_2\) একটা orthonormal basis)। তাহলে
— \(u_1, u_2\) লম্ব অক্ষে \(\cos\)-\(\sin\)-এর প্যারামিটার — এটা তো ellipse-এর সংজ্ঞাই, আধা-অক্ষ \(\sigma_1u_1\) আর \(\sigma_2u_2\)! বৃত্ত কখনো তারার মতো, কখনো আলুর মতো বিকৃত হয় না — সবসময় ellipse — কারণ প্রতিটা matrix-ই আসলে rotate–stretch–rotate।
\(\sigma_1\) = "সবচেয়ে জোরে টানার দিক"¶
\(\|Ax\|\)-কে সবচেয়ে বড় করতে চাও (\(\|x\| = 1\) রেখে)? \(x\)-কে \(v\)-basis-এ ভাঙো: \(x = c_1v_1 + \cdots + c_nv_n\), \(\sum c_i^2 = 1\)। তখন \(\|Ax\|^2 = \sum c_i^2\sigma_i^2\) — এটা \(\sigma_i^2\)-দের weighted average, সবচেয়ে বড় হয় সব ওজন \(\sigma_1\)-এ ঢাললে: \(x = v_1\)। তাই \(\sigma_1 = \max\|Ax\|/\|x\|\) — matrix-এর "সর্বোচ্চ গতি"। (চিনতে পারছো? Chapter 6.7-এ এই একই maximization-ই হবে "ডেটার সবচেয়ে ছড়ানো দিক" খোঁজা — Rayleigh quotient-এর গল্প।)
Eckart–Young কেন বিশ্বাসযোগ্য?¶
পুরো প্রমাণ না করি, কিন্তু অনুভবটা নাও। Rank-\(k\) approximation মানে \(A\)-র "কঙ্কাল"-টা \(k\)টা দিক দিয়ে ধরা। SVD স্তরগুলো ওজন অনুযায়ী সাজানো — ভারী স্তর আগে ফেললে ক্ষতি সবচেয়ে বেশি, তাই বুদ্ধিমান ছাঁটাই হালকা লেজ থেকে। আর লম্বভাবে সাজানো বলে স্তরগুলোর মধ্যে কোনো "overlap" নেই — এক স্তরের কাজ আরেক স্তর আংশিক করে দিতে পারে না (Frobenius norm-এ Pythagoras: \(\|A\|_F^2 = \sum\sigma_i^2\), স্তরে স্তরে ভাগ হয়ে আছে)। ফেলে দেওয়া অংশের ওজন \(\sigma_{k+1}, \ldots\) — এর চেয়ে কমে কোনো rank-\(k\) প্রতিযোগী নামতে পারে না। Notebook-এ ২০০টা random প্রতিযোগী বানিয়ে হারিয়ে দেখবে!
৬. Code-এ কেমনে লিখে¶
import numpy as np
np.random.seed(42)
A = np.array([[1.5, 0.8],
[0.4, 1.2]])
# --- এক লাইনে SVD ---
U, s, Vt = np.linalg.svd(A)
print("singular values:", s) # [1.9..., 0.7...] — বড় থেকে ছোট
print("U:\n", U)
print("Vt (V-এর TRANSPOSE!):\n", Vt) # NumPy V নয়, V^T ফেরত দেয় — সাবধান!
# --- জোড়া লাগিয়ে যাচাই ---
print("U @ diag(s) @ Vt == A ?", np.allclose(U @ np.diag(s) @ Vt, A))
# --- মূল সমীকরণ: A v_i = sigma_i u_i ---
V = Vt.T
for i in range(2):
print(np.allclose(A @ V[:, i], s[i] * U[:, i])) # True, True
# --- sigma_i^2 == A^T A-র eigenvalue? ---
lam = np.linalg.eigvalsh(A.T @ A) # symmetric-এর জন্য eigvalsh (Ch 6.4)
print("sqrt(eig(A^T A)) =", np.sqrt(lam[::-1]), " vs s =", s)
# --- Property যাচাই: norm আর det ---
print("||A||_2 = sigma_1 ?", np.isclose(np.linalg.norm(A, 2), s[0]))
print("|det A| = sigma_1*sigma_2 ?", np.isclose(abs(np.linalg.det(A)), s.prod()))
# --- rank-1 approximation: Eckart–Young হাতে-নাতে ---
A1 = s[0] * np.outer(U[:, 0], Vt[0]) # প্রথম স্তরটাই
print("rank-1 approx:\n", A1.round(3))
print("error ||A - A1||_2 =", np.linalg.norm(A - A1, 2), " == sigma_2 =", s[1])
# --- rectangular-এও দিব্যি চলে (eig পারতো না!) ---
B = np.random.randn(5, 3)
Ub, sb, Vtb = np.linalg.svd(B, full_matrices=False) # economy size
print("B (5x3)-এর sigma:", sb.round(3), " shapes:", Ub.shape, Vtb.shape)
Output ব্যাখ্যা:
- এক নম্বর কোডিং-ফাঁদ:
np.linalg.svdফেরত দেয়Vt\(= V^T\), \(V\) নয় — right singular vector-রাVt-র row (বাVt.T-র column)। ভুলে গেলে সব হিসাব নিঃশব্দে ভুল আসবে। - \(\sqrt{\lambda(A^TA)}\) হুবহু singular value-দের মিললো — Property 2 জীবন্ত (eigvalsh ছোট→বড় দেয়, তাই
[::-1])। - Rank-1 approximation-এর error ঠিক \(\sigma_2\) — Eckart–Young এক লাইনে verify।
- \(5\times3\) matrix-এ
eigচালালে NumPy error দিত;svdহাসিমুখে চললো —full_matrices=False(economy SVD) বড় ডেটায় memory বাঁচায়, ছবির notebook-এও এটাই ব্যবহার করবে।
৭. Worked Examples¶
Example 1 — হাতে পুরো SVD: \(A^TA\)-র পথ ধরে¶
\(A = \begin{bmatrix}4 & 4\\ -3 & 3\end{bmatrix}\) (Strang-এর প্রিয় ধাঁচের উদাহরণ, নিজের মতো সাজানো)।
ধাপ ১ — \(A^TA\):
ধাপ ২ — এর eigenvalue (Chapter 6.2-এর কায়দা): \(\det(A^TA - \lambda I) = (25-\lambda)^2 - 49 = 0 \Rightarrow 25 - \lambda = \pm7 \Rightarrow \lambda = 32, 18\)।
চেক: \(32 + 18 = 50 = \operatorname{tr}\) ✓। তাহলে \(\sigma_1 = \sqrt{32} = 4\sqrt2\), \(\sigma_2 = \sqrt{18} = 3\sqrt2\)।
ধাপ ৩ — \(v\)-রা (\(A^TA\)-র eigenvector): \(\lambda = 32\): \(x = y \Rightarrow v_1 = \frac{1}{\sqrt2}(1,1)\); \(\lambda = 18\): \(x = -y \Rightarrow v_2 = \frac{1}{\sqrt2}(1,-1)\)। (Symmetric matrix — লম্ব হবেই, Chapter 6.4 ✓)
ধাপ ৪ — \(u_i = Av_i/\sigma_i\):
ফলাফল:
শেষ চেক: \(|\det A| = |12+12| = 24 = 4\sqrt2 \cdot 3\sqrt2\) ✓
Example 2 — Rectangular, rank-1: SVD খালি চোখে¶
\(B = \begin{bmatrix}1 & 2\\ 2 & 4\\ 3 & 6\end{bmatrix}\) — দ্বিতীয় column প্রথমটার দ্বিগুণ, rank \(1\)।
Rank-1 মানে \(B\) = একটাই স্তর: \(B = \begin{bmatrix}1\\2\\3\end{bmatrix}\begin{bmatrix}1 & 2\end{bmatrix}\) — column × row! এখন শুধু unit বানিয়ে ওজনটা বের করি:
তাহলে \(B = \sigma_1u_1v_1^T\), ব্যস — \(\sigma_2 = 0\) (rank \(1\)!)। বাকি \(v_2 = (2,-1)/\sqrt5\) গেলো null space-এ (\(Bv_2 = 0\) — মিলিয়ে দেখো), আর \(u_2, u_3\) column space-এর লম্বে — fig03-এর চার-subspace ছবিটা ক্ষুদ্র আকারে সম্পূর্ণ। শিক্ষা: nonzero \(\sigma\) গুনলেই rank, আর শূন্য-\(\sigma\)-র \(v\)-রাই null space-এর basis।
Example 3 — Eckart–Young সংখ্যায়: কোন \(k\) যথেষ্ট?¶
ধরো একটা ছবির singular value-রা: \(\sigma = (100, 40, 8, 3, 1, 0.5, \ldots)\) (দ্রুত-পড়া লেজ)। \(k = 2\) রাখলে:
- Spectral error: \(\|A - A_2\|_2 = \sigma_3 = 8\) — সবচেয়ে খারাপ দিকে ভুল \(8\)।
- Relative Frobenius error: \(\sqrt{\frac{8^2 + 3^2 + 1^2 + 0.5^2}{100^2 + 40^2 + 8^2 + \cdots}} \approx \sqrt{\frac{74.25}{11674.25}} \approx 8\%\)।
মানে মাত্র ২টা স্তরে ছবির \(92\%\) "শক্তি" ধরা পড়ে গেছে। ছবিটা যদি \(500\times400\) হয়: আসল storage \(200{,}000\) সংখ্যা, rank-2 storage \(2(500+400+1) = 1802\) — ১%-এরও কম! Compression মানেই এই হিসাব: \(\sigma\)-র লেজ যত দ্রুত পড়ে, তত কম \(k\)-তে তত ভালো ছবি।
৮. Problems ও Solutions¶
Problem 1. \(D = \begin{bmatrix}2 & 0\\ 0 & -3\end{bmatrix}\)-এর eigenvalue আর singular value আলাদা করে বের করো। দুটো এক হলো না কেন — অথচ matrix-টা diagonal-ই তো ছিল!
Solution
Eigenvalue: diagonal থেকে সরাসরি \(\lambda = 2, -3\)।
Singular value: \(D^TD = \begin{bmatrix}4 & 0\\ 0 & 9\end{bmatrix} \Rightarrow \sigma = \sqrt9, \sqrt4 = 3, 2\) (বড়টা আগে!)।
দুটো তফাত: (১) singular value ঋণাত্মক হয় না — \(-3\)-এর জায়গায় \(3\); sign-টা ("flip") চলে যায় \(U\)-র ভেতরে: \(D = \begin{bmatrix}0&1\\-1&0\end{bmatrix}\begin{bmatrix}3&0\\0&2\end{bmatrix}\begin{bmatrix}0&1\\1&0\end{bmatrix}\)-জাতীয় সাজানোয়। (২) সাজানোর নিয়ম আলাদা — \(\sigma\) সবসময় বড়→ছোট। সম্পর্কটা এখানে \(\sigma_i = |\lambda_i|\) (symmetric matrix বলে); general matrix-এ সেটুকুও থাকে না।
Problem 2. \(Q\) orthogonal (\(Q^TQ = I\)) হলে তার সব singular value বের করো। জ্যামিতিক মানে কী?
Solution
\(Q^TQ = I\)-এর eigenvalue সব \(1\), তাই সব \(\sigma_i = \sqrt1 = 1\)।
জ্যামিতি: unit circle গিয়ে পড়ে এমন ellipse-এ যার সব আধা-অক্ষ \(1\) — মানে আবার unit circle-ই! Rotation/reflection কিছুই টানে না — SVD-র ভাষায় "সব \(\sigma = 1\)" আর Part V-এর "দৈর্ঘ্য বাঁচায়" একই কথা। (আর Chapter 6.1-এর সাথে: \(|\det Q| = \sigma_1\sigma_2\cdots = 1\) ✓)
Problem 3. প্রমাণ করো: (a) \(A^TA\)-র প্রতিটা eigenvalue \(\geq 0\)। (b) \(A\)-র rank আর \(A^TA\)-র rank সমান — তাই nonzero singular value-র সংখ্যা = rank।
Solution
(a) \(A^TAv = \lambda v\), \(\|v\| = 1\) হলে: \(\lambda = v^TA^TAv = (Av)^T(Av) = \|Av\|^2 \geq 0\) ∎ (Chapter 6.5-এর positive semidefinite-এর সংজ্ঞাই।)
(b) দেখাই \(N(A) = N(A^TA)\): \(Av = 0 \Rightarrow A^TAv = 0\) (সোজা দিক); উল্টো দিকে \(A^TAv = 0 \Rightarrow v^TA^TAv = 0 \Rightarrow \|Av\|^2 = 0 \Rightarrow Av = 0\)। Null space এক, তাই (rank–nullity, Part IV) rank-ও এক ∎। আর \(A^TA\)-র rank = তার nonzero eigenvalue-র সংখ্যা (symmetric, diagonalizable) = nonzero \(\sigma^2\)-এর সংখ্যা।
Problem 4. হাতে পুরো SVD বের করো: \(A = \begin{bmatrix}3 & 0\\ 4 & 5\end{bmatrix}\)। (পথ: \(A^TA \to \lambda \to \sigma, v \to u_i = Av_i/\sigma_i\); শেষে \(|\det|\) দিয়ে চেক।)
Solution
\(A^TA = \begin{bmatrix}25 & 20\\ 20 & 25\end{bmatrix}\); \(\det(A^TA - \lambda I) = (25-\lambda)^2 - 400 \Rightarrow \lambda = 45, 5\)।
\(\sigma_1 = \sqrt{45} = 3\sqrt5\), \(\sigma_2 = \sqrt5\)।
\(\lambda = 45\): \(x = y \Rightarrow v_1 = \frac{1}{\sqrt2}(1,1)\); \(\lambda = 5\): \(v_2 = \frac{1}{\sqrt2}(1,-1)\)।
(\(u_1 \cdot u_2 = (3 - 3)/10 = 0\) — লম্ব ✓)। চেক: \(|\det A| = 15 = 3\sqrt5\cdot\sqrt5\) ✓
Problem 5. \(C = \begin{bmatrix}2 & 4\\ 1 & 2\end{bmatrix}\)। (a) না-হিসাব-করে বলো একটা singular value শূন্য — কীভাবে জানলে? (b) \(\sigma_1\) বের করো rank-1 কৌশলে (Example 2)। (c) \(v_2\) (শূন্য-\(\sigma\)-র দিক) কোন subspace-এর basis?
Solution
(a) Column 2 = 2 × column 1 — rank \(1\), আর nonzero \(\sigma\)-র সংখ্যা = rank, তাই \(\sigma_2 = 0\)।
(b) \(C = \begin{bmatrix}2\\1\end{bmatrix}\begin{bmatrix}1 & 2\end{bmatrix}\), তাই \(\sigma_1 = \|(2,1)\|\cdot\|(1,2)\| = \sqrt5\cdot\sqrt5 = 5\), সাথে \(u_1 = (2,1)/\sqrt5\), \(v_1 = (1,2)/\sqrt5\)।
চেক: \(\|C\|_F = \sqrt{4+16+1+4} = 5 = \sqrt{\sigma_1^2 + 0^2}\) ✓
(c) \(v_2 = (2,-1)/\sqrt5\) — \(Cv_2 = 0\), এটা \(N(C)\)-র basis। Rank-1 matrix-এর SVD মানেই fig03: এক লাইনের row space → এক লাইনের column space, বাকি সব শূন্যে।
Problem 6. Square \(A\)-র জন্য প্রমাণ করো \(|\det A| = \sigma_1\sigma_2\cdots\sigma_n\)। তারপর Chapter 6.1-এর ভাষায় এক বাক্যে মানে বলো।
Solution
\(A = U\Sigma V^T\)-এ product rule (Chapter 6.1, Property 7):
\(U, V\) orthogonal — \(\det = \pm1\) (Chapter 6.1, Problem 5-এ প্রমাণ করেছিলে!)। Absolute value নিলে:
মানে: determinant = আয়তনের scale factor, আর rotate–stretch–rotate-এর মধ্যে আয়তন বদলায় শুধু stretch ধাপে — প্রতিটা অক্ষে \(\sigma_i\) গুণ, মোট \(\prod\sigma_i\) গুণ। দুই chapter-এর গল্প এক সূত্রে গাঁথা।
Problem 7. একটা \(600 \times 400\) grayscale ছবি rank-\(k\)-তে রাখতে লাগে \(k(600 + 400 + 1)\) সংখ্যা। (a) \(k = 30\)-এ storage মূল ছবির কত শতাংশ? (b) কোন \(k\) পেরোলে "compression" আর লাভজনক থাকে না? (c) ছবির \(\sigma\)-রা যদি হয় \(\sigma_i \approx 1000/i^2\), তবে \(k=30\)-এর relative spectral error আন্দাজ করো।
Solution
(a) \(\frac{30 \times 1001}{600\times400} = \frac{30030}{240000} \approx 12.5\%\) — এক-অষ্টমাংশ জায়গায় পুরো ছবি (প্রায়)।
(b) লাভ থাকে যতক্ষণ \(k(m+n+1) < mn\): \(k < \frac{240000}{1001} \approx 239.8\) — মানে \(k \leq 239\)। এর ওপরে গেলে "compressed" সংস্করণই আসলের চেয়ে ভারী!
(c) Eckart–Young: \(\|A - A_{30}\|_2 = \sigma_{31} \approx \frac{1000}{31^2} \approx 1.04\), আর \(\sigma_1 = 1000\) — relative error \(\approx 0.1\%\)। \(1/i^2\)-গতিতে পড়া লেজ মানে অসাধারণ compressible ছবি; বাস্তবের মসৃণ ছবিরা প্রায় এমনই, random noise-ভরা ছবি হলে লেজ চ্যাপ্টা — compression জমে না (Notebook-এর প্রশ্ন ২-এ পরখ করবে)।
Problem 8. ঠিক না ভুল — কারণসহ: (a) "\(A\)-র singular value আর \(A^T\)-র singular value একই।" (b) "\(\sigma_1 \geq |\lambda|\) — যেকোনো eigenvalue-র চেয়ে বড়-সমান।" (c) "দুটো matrix-এর singular value সব মিলে গেলে matrix দুটো সমান।"
Solution
(a) ঠিক। \(A^T = V\Sigma^TU^T\) — এটাই \(A^T\)-র SVD (\(U\), \(V\)-র ভূমিকা অদল-বদল), \(\Sigma\)-র diagonal একই। (\(AA^T\) আর \(A^TA\)-র nonzero eigenvalue একই — সেটারই প্রতিধ্বনি।)
(b) ঠিক। \(Av = \lambda v\), \(\|v\|=1\) হলে \(|\lambda| = \|Av\| \leq \max_{\|x\|=1}\|Ax\| = \sigma_1\) — কোনো দিকের stretch-ই "সর্বোচ্চ stretch"-কে ছাড়াতে পারে না। (Shear মনে করো: \(\lambda = 1\) কিন্তু \(\sigma_1 = 1.618\) — অসমতাটা strict-ও হতে পারে।)
(c) ভুল! \(\begin{bmatrix}1&0\\0&1\end{bmatrix}\) আর \(\begin{bmatrix}0&1\\1&0\end{bmatrix}\) — দুটোরই \(\sigma = (1,1)\), কিন্তু matrix ভিন্ন। \(\Sigma\) শুধু "কতটা টানে" বলে; "কোন দিক থেকে কোন দিকে" — সে খবর \(U, V\)-র — সেটা ফেললে matrix ফেরত পাওয়া যায় না।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "Singular value তো eigenvalue-রই আরেক নাম" | না! \(\sigma_i = \sqrt{\lambda_i(A^TA)}\) — \(A\)-র নিজের eigenvalue না। Square matrix-এও আলাদা (shear: \(\lambda = 1,1\) কিন্তু \(\sigma \approx 1.618, 0.618\))। এক হয় শুধু symmetric positive semidefinite-এ। |
| "Eigenvalue-র মতো \(\sigma\)-ও negative/complex হতে পারে" | কখনো না — \(\sigma_i = \sqrt{\|Av_i\|^2\)-জাতীয় রাশি\(}\), সবসময় real ও \(\geq 0\), আর সবসময় বড়→ছোট সাজানো। Flip/rotation-এর সব খবর \(U, V\) শুষে নেয়। |
"NumPy-র svd থেকে V পেলাম" |
পাওনি — পেয়েছো \(V^T\) (Vt)! Right singular vector-রা Vt-র row। Vt.T-র column নিতে ভুলো না — নিঃশব্দ ভুলের এক নম্বর উৎস। |
| "\(A = U\Sigma V^T\) মানে \(U\) আর \(V\) একই জিনিসের দুই কপি" | দুটো আলাদা জগতের basis: \(v\)-রা ইনপুট space-এ (\(\mathbb{R}^n\)), \(u\)-রা আউটপুট space-এ (\(\mathbb{R}^m\)) — rectangular হলে মাপই আলাদা। Diagonalization-এর \(PDP^{-1}\)-এ এক basis-ই দুবার আসে; SVD-র স্বাধীনতা-ই তার শক্তি। |
| "Low-rank approximation একটা approximation-কৌশল মাত্র, যেকোনোভাবে \(k\)টা দিক নিলেই হয়" | Eckart–Young বলে SVD-র truncation-ই প্রমাণিতভাবে সেরা — যেকোনো অন্য rank-\(k\) পছন্দ কড়ায়-গণ্ডায় বেশি ভুল করবে। "কোনটা ফেলবো" প্রশ্নের উত্তর দেয় \(\sigma\)-দের সাজানো তালিকা। |
| "SVD-ও নিশ্চয়ই কোনো কোনো matrix-এ fail করে" | করে না — এটাই পুরো পয়েন্ট। Defective, rectangular, singular, rank-0 — সবার SVD আছে। যা fail করতে পারে তা হলো তোমার ধৈর্য: বড় matrix-এ পুরো SVD দামি (\(O(mn\min(m,n))\)) — তখন truncated/randomized SVD (আরো পরের গল্প)। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| SVD | \(A = U\Sigma V^T\) — সব \(m\times n\) matrix-এর জন্য | rotate → stretch → rotate (fig01) |
| মূল সমীকরণ | \(Av_i = \sigma_iu_i\) | ইনপুট লম্ব-জোড়া → আউটপুট লম্ব-জোড়া |
| জ্যামিতি | unit circle → ellipse; আধা-অক্ষ \(= \sigma_iu_i\) | shear-ও ellipse-ই বানায় (fig02) |
| কোথা থেকে | \(v, \sigma^2\) = \(A^TA\)-র eigen; \(u\) = \(AA^T\)-র | spectral theorem (Ch 6.4) × ১বার = SVD |
| \(\sigma\) বনাম \(\lambda\) | \(\sigma_i = \sqrt{\lambda_i(A^TA)} \geq 0\), সবসময় real | shear: \(\lambda = 1\), \(\sigma =\) golden ratio |
| \(\Sigma\)-তে সব খবর | rank = nonzero \(\sigma\); \(\|A\|_2 = \sigma_1\); \(\vert \det\vert = \prod\sigma_i\) | orthogonal মোড়ক খুলে ভেতরটা পড়ো |
| Rank-1 স্তর | \(A = \sum\sigma_iu_iv_i^T\), ভারী আগে | heatmap-এর স্তর (fig04) |
| Eckart–Young | সেরা rank-\(k\): প্রথম \(k\) স্তর; error \(= \sigma_{k+1}\) | লেজ ছাঁটো, কঙ্কাল রাখো (fig05) |
| চার subspace | \(v\)-রা: row/null; \(u\)-রা: column/left-null — orthonormal basis | Part IV-V-এর গল্পের finale (fig03) |
| DS/ML | compression, denoising, recommender, LSA, pseudoinverse, PCA | linear algebra-র সুইস আর্মি নাইফ |
পরের chapter-এর সেতু: এখন হাতে এমন এক যন্ত্র যা যেকোনো matrix-এর "সবচেয়ে গুরুত্বপূর্ণ দিক"-গুলো ওজনসহ সাজিয়ে দেয়। তাহলে matrix-টা যদি হয় তোমার ডেটা — হাজারটা feature-এর লাখো sample? সবচেয়ে ভারী \(v_1\) তখন "ডেটা যেদিকে সবচেয়ে ছড়িয়ে" সেই দিক, \(v_2\) তার লম্বে দ্বিতীয় সেরা — আর ছোট \(\sigma\)-র দিকগুলো ছেঁটে হাজার dimension নামিয়ে আনা যায় দুটোয়, প্রায় কিছু না হারিয়ে। এই কৌশলের নাম Chapter 6.7: PCA (Principal Component Analysis) — Part VI-এর সমাপনী, আর data science-এর নিত্যদিনের হাতিয়ার।
📓 Notebook Project¶
notebooks/part-06/ch06-project.ipynb — Part VI-এর প্রথম flagship project: sklearn-এ bundled আসল ছবি (china.jpg) grayscale matrix বানিয়ে np.linalg.svd-তে ভাঙা; \(k = 1, 5, 20, 50, 100\)-এর rank-\(k\) গ্যালারি পাশাপাশি এঁকে দেখা কত কম স্তরে চোখ ধোঁকা খায়; singular value-র decay, storage-saving % আর error-vs-\(k\) curve (tail formula \(\sqrt{\sum_{i>k}\sigma_i^2/\sum\sigma_i^2}\) সরাসরি হিসাবের সাথে মিলিয়ে); শেষে Eckart–Young-এর মল্লযুদ্ধ — ২০০টা random rank-\(k\) প্রতিযোগী বানিয়ে histogram-এ দেখা যে একজনও SVD-র truncation-কে হারাতে পারে না।