Chapter 7.3 — Constrained Least Squares & Lagrange Multipliers (কনস্ট্রেইনড লিস্ট স্কোয়ার্স ও ল্যাগ্রাঞ্জ মাল্টিপ্লায়ার)¶
Chapter 7.2-এ "\(x\) ছোট হওয়া উচিত" — এই ইচ্ছেটা আমরা নরমভাবে জানিয়েছিলাম: penalty দিয়ে। চাইলে model অমান্য করতে পারতো, শুধু একটু দাম দিয়ে। আজ আমরা এমন সমস্যা দেখবো যেখানে শর্তটা কঠোর, অলঙ্ঘনীয়: "\(x\) অবশ্যই এই সমীকরণগুলো মানবে — কোনো আপস নেই।" Spline-এর দুই টুকরো seam-এ ঠিক মিলতেই হবে; রকেটকে ঠিক লক্ষ্যে থামতেই হবে; portfolio-র ওজনগুলো যোগ করে ঠিক ১ হতেই হবে। এই hard-constraint-ওয়ালা least squares সমাধানের সবচেয়ে সুন্দর গণিত-যন্ত্রটার নাম Lagrange multiplier(ল্যাগ্রাঞ্জ মাল্টিপ্লায়ার) — আর মজার কথা, শেষে যা পাবো সেটা আবার একটা linear সমীকরণ-ব্যবস্থা।
🎯 এই chapter-এ যা শিখবে¶
- Constrained Least Squares(কনস্ট্রেইনড লিস্ট স্কোয়ার্স): \(\underset{x}{\min}\;\|Ax-b\|^2\) শর্তসাপেক্ষে \(Cx = d\)
- Lagrange multiplier পদ্ধতি: constraint-কে multiplier \(z\) দিয়ে objective-এ মিশিয়ে "মুক্ত" সমস্যায় রূপান্তর
- KKT system(কে-কে-টি সিস্টেম): constrained সমস্যার সমাধান একটা বড় linear ব্যবস্থার সমাধানে নেমে আসে
- Least Norm Problem(লিস্ট নর্ম প্রবলেম): \(\underset{x}{\min}\;\|x\|^2\) শর্তসাপেক্ষে \(Cx = d\) — under-determined সমস্যার সবচেয়ে "মিতব্যয়ী" সমাধান
- বাস্তব প্রয়োগ: smooth spline fitting, ও ন্যূনতম-শক্তির নিয়ন্ত্রণ (minimum-energy control)
🖼️ এক ছবিতে মূল idea¶
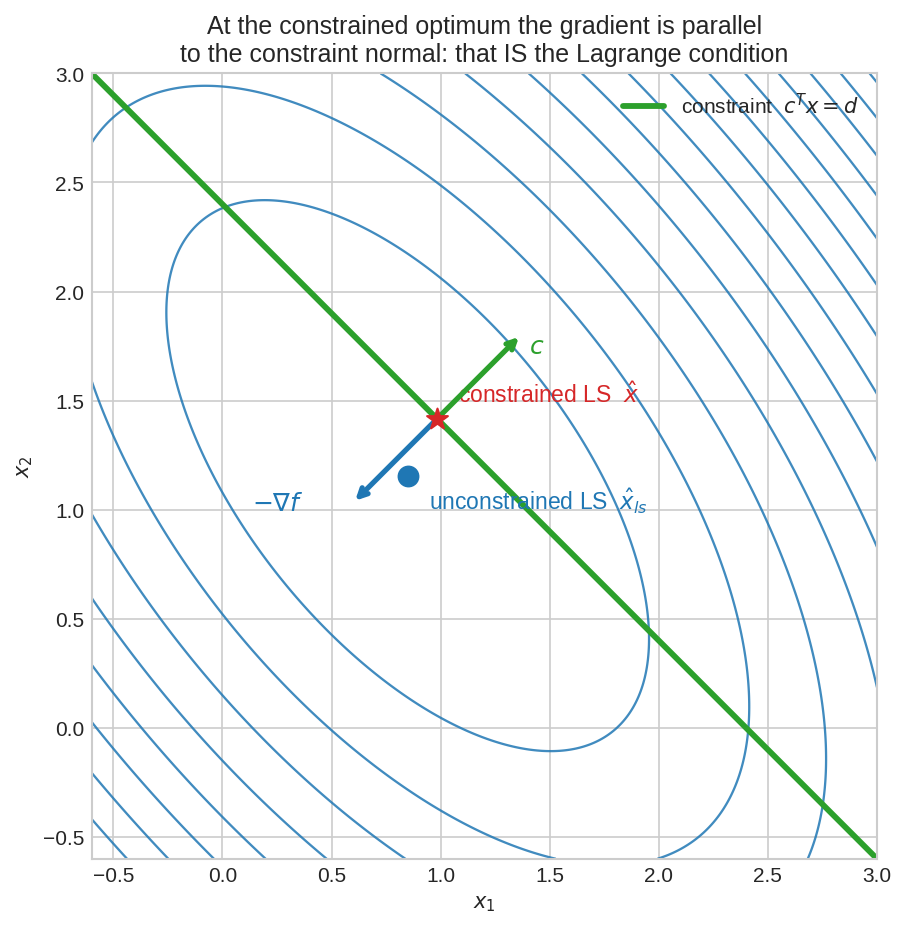
নীল উপবৃত্তগুলো objective \(\|Ax-b\|^2\)-এর contour; কেন্দ্রে unconstrained সমাধান \(\hat{x}_{ls}\)। সবুজ সরলরেখাটা constraint \(c^Tx = d\) — সমাধানকে এই রেখার ওপর থাকতেই হবে। রেখার সব বিন্দুর মধ্যে সেরা (তারা-চিহ্ন) হলো যেখানে একটা নীল contour রেখাটিকে ঠিক স্পর্শ (tangent) করে। সেই বিন্দুতে objective-এর gradient (\(-\nabla f\), নীল তীর) আর constraint-এর normal (\(c\), সবুজ তীর) সমান্তরাল — এটাই Lagrange-এর মূল শর্ত।
১. কি? (What)¶
দৈনন্দিন analogy: পাহাড়ে বেড়া দেওয়া পথ¶
ভাবো তুমি একটা গামলা-আকৃতির উপত্যকায় (objective) নামতে চাও — যত নিচে তত ভালো। কিন্তু একটা বেড়া দেওয়া সরু পথ আছে (constraint), তোমাকে সেই পথেই হাঁটতে হবে, বেড়া টপকানো নিষেধ। সবচেয়ে নিচু বিন্দু হয়তো বেড়ার বাইরে — তুমি সেখানে যেতে পারবে না। তাহলে পথের ওপর সবচেয়ে নিচু জায়গাটা কোথায়? ঠিক সেখানে, যেখানে পথটা উপত্যকার উচ্চতা-রেখার (contour) সাথে সমান্তরাল হয়ে যায় — সেখানে পথ ধরে সামনে-পিছে গেলে আর নিচে নামা যায় না। এই "সমান্তরাল হওয়ার শর্ত"-ই Lagrange-এর হৃদয়।
সংজ্ঞা¶
Part V-এর plain least squares চেয়েছিল মুক্তভাবে \(\|Ax - b\|^2\) ছোট করা — \(x\) যা খুশি হতে পারতো। Constrained least squares-এ \(x\)-এর ওপর কিছু সমতা-শর্ত (equality constraint) চাপানো:
এখানে \(C\) একটা \(p \times n\) matrix (\(p\)টা constraint, \(n\)টা variable), \(d\) একটা \(p\)-vector। ধরে নিচ্ছি \(p < n\) (variable-এর চেয়ে কম শর্ত, নাহলে \(x\) পুরোপুরি বাঁধা পড়ে যায়) আর \(C\)-র rank পূর্ণ (শর্তগুলো পরস্পর-বিরোধী বা অতিরিক্ত নয়)।
- \(\|Ax-b\|^2\) = objective(অবজেক্টিভ) — যা minimize করছি।
- \(Cx = d\) = constraint(কনস্ট্রেইন্ট) — যা মানতেই হবে, আপস নেই।
- শর্ত মানে এমন \(x\)-এর সেট (একটা affine subspace) — তার ভেতর থেকেই সেরাটা বাছবো।
Ridge-এর সাথে পার্থক্য¶
| Ridge (Ch 7.2) | Constrained LS (এই ch) | |
|---|---|---|
| ইচ্ছেটা | নরম (soft): \(\|x\|^2\)-কে penalty | কঠোর (hard): \(Cx = d\) মানতেই হবে |
| অমান্য করা | যায়, দাম দিয়ে | যায় না, একদমই না |
| knob | \(\lambda\) (কতটা চাই) | নেই — শর্ত হয় মানে, নয় ভাঙে |
২. দেখতে কেমন?¶
দৃশ্য ১: মসৃণ spline — দুই বহুপদী seam-এ জোড়া¶
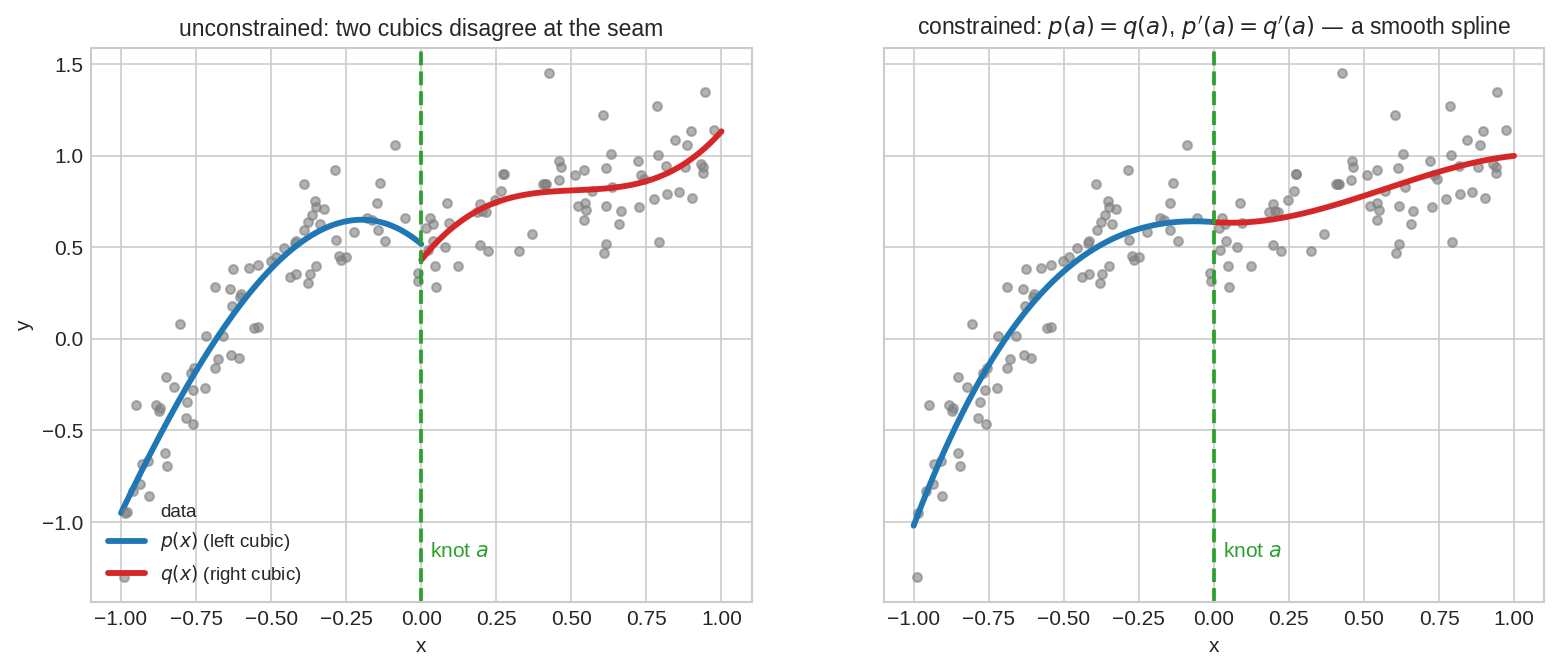
ধরো data-র একটা knot(নট) বিন্দুতে বাঁ পাশে একটা cubic \(p(x)\), ডান পাশে আরেকটা cubic \(q(x)\) fit করছো। বাঁ ছবি (unconstrained): দুই cubic seam-এ লাফ দিয়ে আলাদা — কুৎসিত, বিচ্ছিন্ন। ডান ছবি (constrained): শর্ত বসিয়েছি \(p(a) = q(a)\) (মান মেলে) আর \(p'(a) = q'(a)\) (ঢালও মেলে) — ফলে জোড়াটা মসৃণ, চোখে ধরাই যায় না কোথায় seam। এটাই spline fitting — constrained LS-এর ক্লাসিক প্রয়োগ।
দৃশ্য ২: least norm — সব সমাধানের মধ্যে সবচেয়ে ছোট¶
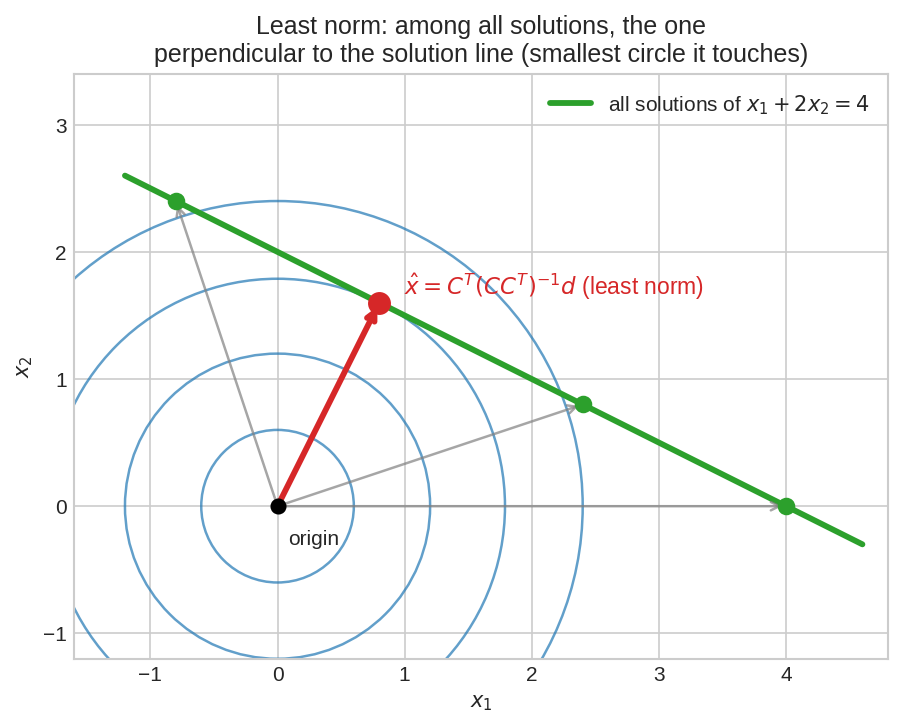
সবুজ রেখাটা \(x_1 + 2x_2 = 4\)-এর সব সমাধান (অসংখ্য!)। নীল বৃত্তগুলো origin-কেন্দ্রিক \(\|x\|\)-এর সমমান-রেখা। যে বৃত্তটা রেখাকে প্রথম স্পর্শ করে, তার স্পর্শবিন্দুই least-norm সমাধান (লাল তীর) — মানে রেখা থেকে origin-এর লম্ব দূরত্বের পাদবিন্দু। খেয়াল করো \(\hat{x}\) constraint রেখার সাথে লম্ব — সবচেয়ে ছোট norm সবসময় লম্বভাবে আসে।
দৃশ্য ৩: ন্যূনতম-শক্তির নিয়ন্ত্রণ¶
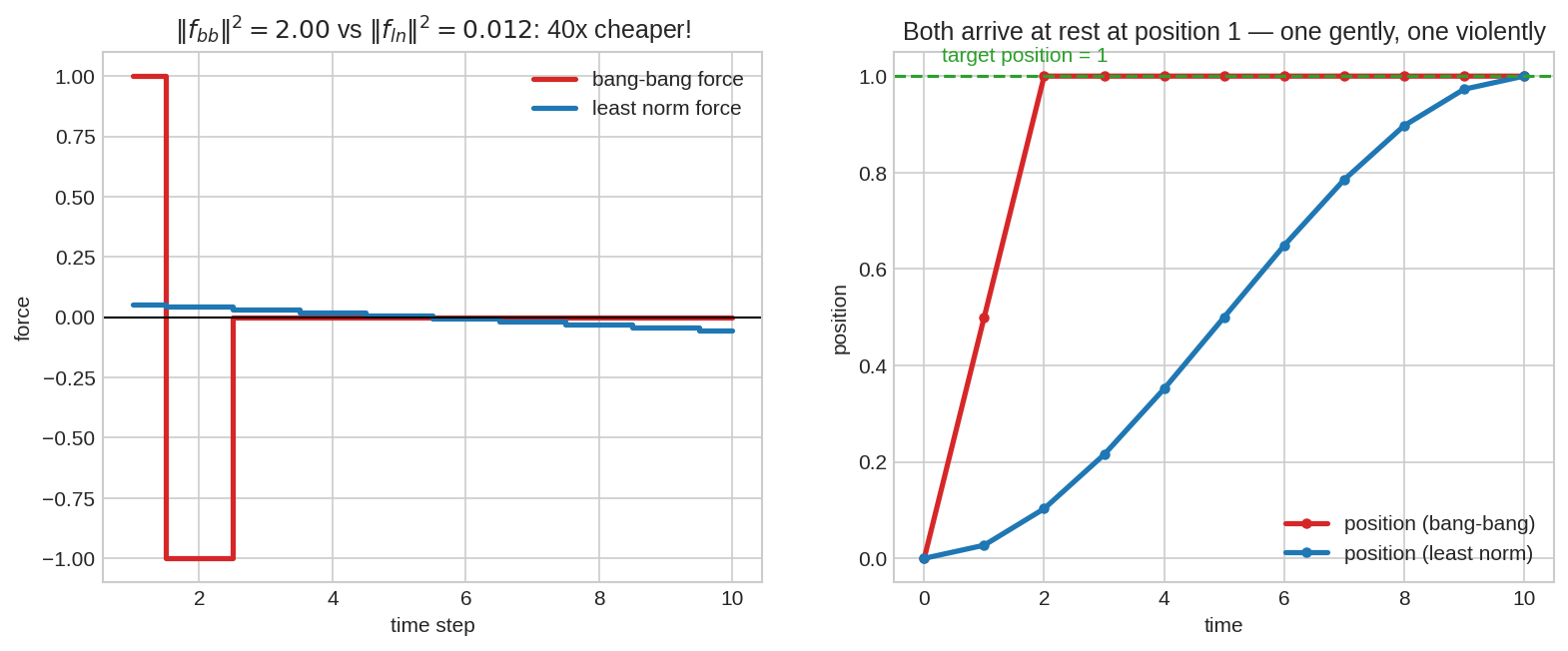
একটা বস্তুকে ১০ ধাপে ঠেলে ঠিক position 1-এ, ঠিক থেমে (velocity 0) পৌঁছাতে হবে — এই দুটোই hard constraint। বাঁ ছবি: দুটো force-প্রোফাইল যারা দুটোই কাজ করে। লাল (bang-bang): শুরুতে ধাক্কা, পরে ব্রেক — শক্তি \(\|f\|^2 = 2.0\)। নীল (least norm): মৃদু, ছড়ানো ধাক্কা — শক্তি প্রায় \(40\) গুণ কম! ডান ছবি: দুটোই লক্ষ্যে পৌঁছায়, একটা নম্রভাবে, একটা হিংস্রভাবে। রকেট/রোবট নিয়ন্ত্রণে least-norm মানেই কম জ্বালানি।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- নিয়ন্ত্রণ (control): রকেট/ড্রোন/রোবট-বাহুকে ন্যূনতম জ্বালানি বা ধাক্কায় লক্ষ্যে নেওয়া। "ঠিক এখানে, ঠিক এই বেগে পৌঁছাও" = hard constraint; "শক্তি কম খরচ কর" = objective। fig04 ঠিক এটাই।
- Spline/curve fitting: টুকরো-টুকরো বহুপদী দিয়ে মসৃণ বক্ররেখা — গাড়ির নকশা, animation-এর গতিপথ, font-এর অক্ষর, সব CAD software-এর ভিত্তি।
- Portfolio optimization: বিনিয়োগের ওজন \(x_i\) যোগ করে ঠিক \(1\) হতে হবে (\(\mathbf{1}^Tx = 1\)) — একটা equality constraint; ঝুঁকি (variance) = objective।
Data Science / ML-এ:
- Least norm সমাধান: feature ≫ sample (under-determined) সমস্যায় \(Ax = b\)-র অসংখ্য সমাধান; ML সবসময় ন্যূনতম-norm-টা বাছে — এটাই deep network-এর "implicit regularization"-এর একটা তত্ত্ব।
- Equality-constrained optimization: অনেক ML সমস্যা (SVM-এর dual, probability normalization) equality constraint সহ; Lagrangian তাদের সমাধানের সাধারণ ভাষা।
- Lagrangian duality: এই chapter-এর multiplier \(z\)-ই optimization-এর গভীর duality তত্ত্বের প্রথম ধাপ — গোটা convex optimization ক্ষেত্রের প্রবেশদ্বার।
৪. Properties¶
Property 1 — Lagrangian ও KKT সমীকরণ¶
Constraint-কে সরাসরি না মেনে, একটা নতুন ভেরিয়েবল Lagrange multiplier \(z \in \mathbb{R}^p\) (প্রতি constraint-এ একটা) এনে একটা যৌথ ফাংশন Lagrangian বানাই:
সমাধানে \(L\)-এর gradient শূন্য হয় \(x\) ও \(z\) দুইয়ের সাপেক্ষে। \(\partial L/\partial z = 0\) ফিরিয়ে দেয় মূল constraint \(Cx = d\); আর \(\partial L/\partial x = 0\) দেয় \(2A^TAx + C^Tz = 2A^Tb\)। দুটো একসাথে একটা বড় linear ব্যবস্থা — KKT (Karush-Kuhn-Tucker) system:
মূল বার্তা: constrained optimization নেমে এসেছে একটা (একটু বড়) linear সমীকরণ solve করায়। কোনো iteration নয়, বন্ধ-রূপ উত্তর।
Property 2 — Lagrange condition: gradient সমান্তরাল¶
\(\partial L/\partial x = 0\) থেকে: \(2A^T(A\hat{x} - b) = -C^Tz\)। বাঁ পাশ হলো objective-এর gradient \(\nabla f(\hat{x})\); ডান পাশ constraint normal-দের একটা linear combination। মানে —
একটা constraint হলে: objective-এর gradient আর constraint-এর normal সমান্তরাল (fig01-এর দুই তীর)। জ্যামিতিক অর্থ: constraint রেখা বরাবর হাঁটলে objective আর কমছে না — সেটাই optimum-এর সংজ্ঞা।
Property 3 — Least norm-এর সুন্দর সূত্র¶
বিশেষ কেস \(A = I\), \(b = 0\) (অর্থাৎ objective \(\|x\|^2\)): \(\underset{x}{\min}\;\|x\|^2\) s.t. \(Cx = d\)। KKT সমাধান করলে একটা পরিষ্কার সূত্র বেরোয়:
(\(C\) full row rank হলে \(CC^T\) invertible।) এই \(\hat{x}\)-ই least norm সমাধান — fig03-এর লাল তীর।
Property 4 — Least norm সমাধান constraint-এর সাথে লম্ব¶
Least norm \(\hat{x} = C^T(CC^T)^{-1}d\) হলো \(C^T\)-র column space-এ, অর্থাৎ constraint normal-দের span-এ। অন্য যেকোনো সমাধান \(x = \hat{x} + v\) যেখানে \(Cv = 0\) (null space)। যেহেতু \(\hat{x} \perp v\) (একটা row space-এ, অন্যটা null space-এ — Part IV-এর orthogonal subspace!):
তাই \(\hat{x}\)-ই সবচেয়ে ছোট। fig03-এ এজন্যই লাল তীর সবুজ রেখার সাথে লম্ব।
Property 5 — Constraint objective-কে কখনো ভালো করে না¶
Unconstrained সমাধান \(\hat{x}_{ls}\) যদি already \(C\hat{x}_{ls} = d\) মানে, তবে constrained উত্তর হুবহু সেটাই (constraint নিষ্ক্রিয়)। নাহলে constraint objective-কে সবসময় খারাপ বা সমান করে:
কারণ আমরা সমাধানের স্বাধীনতা কমিয়েছি — কম জায়গায় খুঁজছি, তাই best-টা তত ভালো হবে না। §৬-এর কোডে residual \(0.283 \to 0.315\)-এ বাড়তে দেখবে: এটাই constraint-এর "দাম"।
৫. Intuition — কেন সত্য?¶
কেন gradient সমান্তরাল হতে হয়?¶
Optimum-এ দাঁড়িয়ে constraint রেখা বরাবর একটু নড়ো — যেকোনো দিকে \(v\) যেখানে \(Cv = 0\) (constraint ভাঙে না)। যদি objective আরও কমার সুযোগ থাকতো, মানে \(\nabla f \cdot v < 0\) কোনো অনুমোদিত \(v\)-র জন্য, তবে সেদিকে সরে আরও ভালো করা যেত — তাহলে এটা optimum ছিল না। তাই optimum-এ \(\nabla f\) প্রতিটা অনুমোদিত দিক \(v\)-র সাথে লম্ব হতে হবে (\(\nabla f \cdot v = 0\))। কিন্তু "সব \(Cv=0\)-র সাথে লম্ব" মানে \(\nabla f\) থাকতে হবে \(C\)-র row-দের span-এ (Part IV: null space-এর orthogonal complement হলো row space)। সেটাই \(\nabla f = -C^Tz\) — Lagrange condition। Multiplier \(z\) শুধু ওই span-এর coefficient।
Multiplier \(z\)-এর মানে: constraint-এর "দাম"¶
\(z\) শুধু গাণিতিক কৌশল নয় — তার একটা অর্থনৈতিক অর্থ আছে। \(z_i\) বলে দেয়: \(i\)-তম constraint-এর \(d_i\)-কে সামান্য শিথিল করলে objective কতটা ভালো হবে। বড় \(|z_i|\) = ওই constraint খুব "চাপ" দিচ্ছে, শিথিল করলে অনেক লাভ; ছোট \(z_i\) = constraint প্রায় নিষ্ক্রিয়। একে বলে shadow price(শ্যাডো প্রাইস) — অর্থনীতিতে সম্পদের প্রকৃত মূল্য মাপার হাতিয়ার।
Least norm-এর intuition: কেন লম্বই সবচেয়ে ছোট¶
Origin থেকে একটা রেখায় (বা plane-এ) সবচেয়ে কাছে যেতে চাইলে — কোন পথে যাবে? অবশ্যই লম্বভাবে (Chapter 5.1-এর projection!)। রেখা বরাবর হাঁটলে দূরত্ব শুধু বাড়ে। fig03-এ নীল বৃত্তগুলো (সমান দূরত্বের রেখা) যখন সবুজ রেখাকে ঠিক স্পর্শ করে, তখনই সবচেয়ে ছোট বৃত্ত — আর স্পর্শবিন্দুতে বৃত্তের ব্যাসার্ধ রেখার লম্ব। "সব সমাধানের ভিড়ে, origin-এর সবচেয়ে কাছেরটাই সবচেয়ে মিতব্যয়ী।"
কেন control-এ least norm মানে কম শক্তি (fig04)¶
Force-প্রোফাইল \(f = (f_1, \dots, f_{10})\)-কে একটা vector ভাবো; খরচ করা মোট শক্তি \(\propto \|f\|^2\)। "position 1-এ থেমে পৌঁছাও" দুটো equality constraint দেয়। এই constraint মানা অসংখ্য force-প্রোফাইলের মধ্যে least-norm-টা মানে সবচেয়ে ছড়ানো, মৃদু ধাক্কা — কোনো এক ধাপে বিশাল force দিয়ে পরে ব্রেক কষার (bang-bang) চেয়ে অনেক কম শক্তি। গণিত এখানে সরাসরি প্রকৌশল-জ্ঞানে রূপ নেয়: মসৃণ নিয়ন্ত্রণ = মিতব্যয়ী নিয়ন্ত্রণ।
৬. Code-এ কেমনে লিখে¶
import numpy as np
def solve_cls(A, b, C, d):
"""Constrained least squares KKT system দিয়ে সমাধান।"""
n = A.shape[1]
p = C.shape[0]
K = np.block([[2 * A.T @ A, C.T],
[C, np.zeros((p, p))]])
rhs = np.hstack([2 * A.T @ b, d])
sol = np.linalg.solve(K, rhs)
return sol[:n], sol[n:] # x_hat, z (multipliers)
# --- সমস্যা: y = a + b*x fit করো, শর্ত: রেখাটা ঠিক (2, 3) দিয়ে যাক ---
x = np.array([0., 1., 2., 3., 4.])
y = np.array([1.0, 1.8, 3.5, 3.9, 5.2])
A = np.column_stack([np.ones(5), x]) # [1, x] -> params (a, b)
C = np.array([[1.0, 2.0]]) # a + 2b = 3 (x=2 -> y=3)
d = np.array([3.0])
x_un, *_ = np.linalg.lstsq(A, y, rcond=None) # unconstrained
x_c, z = solve_cls(A, y, C, d) # constrained
print("unconstrained (a,b):", x_un.round(3))
print("constrained (a,b):", x_c.round(3), " check a+2b =", float((C @ x_c)[0]))
print("Lagrange multiplier z:", z.round(3))
print("prediction at x=2 :", round(float(x_c[0] + x_c[1] * 2), 3), "(target 3)")
print("residual unc:", round(np.sum((A @ x_un - y) ** 2), 4),
" con:", round(np.sum((A @ x_c - y) ** 2), 4))
# --- least norm: min ||x|| s.t. x1 + 2x2 = 4 (Property 3 সূত্র) ---
C2 = np.array([[1., 2.]]); d2 = np.array([4.])
x_ln = C2.T @ np.linalg.solve(C2 @ C2.T, d2)
print("\nleast norm x:", x_ln.ravel().round(3), " norm:", round(float(np.linalg.norm(x_ln)), 3))
print("alt solution (4,0) norm:", round(float(np.linalg.norm([4, 0])), 3))
Output ব্যাখ্যা:
- Unconstrained সেরা রেখা
(a,b) ≈ (0.98, 1.05)— এটা \((2,3)\) দিয়ে যায় না (\(0.98 + 1.05\cdot 2 = 3.08 \neq 3\))। - Constrained উত্তর
(a,b) ≈ (0.90, 1.05)— intercept সামান্য নেমে শর্ত মানলো:a + 2b = 3.0হুবহু, আরprediction at x=2ঠিক3.0। KKT system কাজ করলো। - Multiplier
z ≈ 0.8— constraint-এর "চাপ"; শূন্য নয়, মানে constraint সক্রিয় (unconstrained উত্তর শর্ত মানছিল না)। - residual
0.283 → 0.315-এ বাড়লো: Property 5-এর "constraint-এর দাম" চোখে ধরা পড়লো — স্বাধীনতা কমালে fit একটু খারাপ হয়। - Least norm
x = [0.8, 1.6], norm1.789— বিকল্প সমাধান \((4, 0)\)-ও \(x_1 + 2x_2 = 4\) মানে কিন্তু তার norm4.0, অনেক বড়। least norm সত্যিই সবচেয়ে ছোট।
৭. Worked Examples¶
Example 1 — Least norm হাতে-কলমে¶
\(\underset{x}{\min}\;\|x\|^2 = x_1^2 + x_2^2\) শর্তসাপেক্ষে \(x_1 + 2x_2 = 4\)।
ধাপ ১ — Lagrangian: \(L = x_1^2 + x_2^2 + z(x_1 + 2x_2 - 4)\)।
ধাপ ২ — gradient শূন্য: \(\partial L/\partial x_1 = 2x_1 + z = 0 \Rightarrow x_1 = -z/2\); \(\partial L/\partial x_2 = 2x_2 + 2z = 0 \Rightarrow x_2 = -z\)।
ধাপ ৩ — constraint বসাও: \(x_1 + 2x_2 = -z/2 - 2z = -5z/2 = 4 \Rightarrow z = -8/5\)।
ধাপ ৪ — সমাধান: \(x_1 = -z/2 = 4/5 = 0.8\); \(x_2 = -z = 8/5 = 1.6\)। মিলে \(\hat{x} = (0.8, 1.6)\), norm \(\sqrt{0.64 + 2.56} = \sqrt{3.2} \approx 1.789\)।
সূত্র দিয়ে যাচাই: \(C = [1, 2]\), \(CC^T = 5\), \(\hat{x} = C^T(CC^T)^{-1}d = \frac{1}{5}\begin{bmatrix} 1 \\ 2\end{bmatrix}\cdot 4 = \begin{bmatrix} 0.8 \\ 1.6\end{bmatrix}\) ✓ — Property 3 মিললো।
Example 2 — Lagrange condition যাচাই (দুই তীর সমান্তরাল)¶
\(\underset{x}{\min}\; (x_1 - 3)^2 + (x_2 - 1)^2\) শর্তসাপেক্ষে \(x_1 + x_2 = 2\)।
ধাপ ১ — objective gradient: \(\nabla f = (2(x_1 - 3),\; 2(x_2 - 1))\)। Constraint normal \(c = (1, 1)\)।
ধাপ ২ — সমান্তরালতা (Property 2): \(\nabla f = -zc\), অর্থাৎ \(2(x_1-3) = -z\) ও \(2(x_2-1) = -z\)। দুটো সমান করে: \(2(x_1-3) = 2(x_2-1) \Rightarrow x_1 - 3 = x_2 - 1 \Rightarrow x_1 - x_2 = 2\)।
ধাপ ৩ — constraint সহ solve: \(x_1 + x_2 = 2\) আর \(x_1 - x_2 = 2\) যোগ করে \(2x_1 = 4 \Rightarrow x_1 = 2, x_2 = 0\)।
উত্তর \((2, 0)\)। খেয়াল করো unconstrained সেরা ছিল \((3, 1)\) — constraint সেটাকে \((2,0)\)-এ ঠেলেছে, ঠিক \(\nabla f = (-2, -2)\) যা constraint normal \((1,1)\)-এর সমান্তরাল। তীর দুটো এক লাইনে — fig01-এর ছবি সংখ্যায়।
Example 3 — Multiplier \(z\)-এর অর্থ¶
Example 2-এ \(z = -2(x_1 - 3) = -2(2 - 3) = 2\)। এখন constraint বদলাও \(x_1 + x_2 = 2 + \epsilon\); নতুন optimum objective \(f^*(\epsilon)\)।
Shadow-price তত্ত্ব বলে \(\dfrac{df^*}{d\epsilon} = -z = -2\) (multiplier-এর চিহ্ন-সাপেক্ষ)। মানে constraint-এর ডান পাশ ১ একক বাড়ালে objective প্রায় \(2\) কমবে। মিলিয়ে দেখো: \(\epsilon = 1\)-এ constraint \(x_1 + x_2 = 3\); একই পদ্ধতিতে optimum \((2.5, 0.5)\), \(f^* = (2.5-3)^2 + (0.5-1)^2 = 0.5\); আগে ছিল \(f^* = (2-3)^2 + 0^2 = 1\)। কমেছে \(0.5\)... প্রায় linear approximation-এ \(-2\cdot 1 = -2\)-এর দিকে (বড় \(\epsilon\)-তে ঠিক মেলে না কারণ objective quadratic, কিন্তু ছোট \(\epsilon\)-তে ঢাল \(-z\))। \(z\) constraint-এর প্রান্তিক মূল্য।
৮. Problems ও Solutions¶
Problem 1. \(\underset{x}{\min}\;\|x\|^2\) শর্তসাপেক্ষে \(2x_1 + x_2 = 5\)। Lagrangian পদ্ধতিতে সমাধান করো, তারপর Property 3-এর সূত্র দিয়ে যাচাই করো।
Solution
Lagrangian: \(L = x_1^2 + x_2^2 + z(2x_1 + x_2 - 5)\)। Gradient: \(2x_1 + 2z = 0 \Rightarrow x_1 = -z\); \(2x_2 + z = 0 \Rightarrow x_2 = -z/2\)। Constraint: \(2(-z) + (-z/2) = -5z/2 = 5 \Rightarrow z = -2\)। সমাধান: \(x_1 = 2\), \(x_2 = 1\)। Norm \(\sqrt{5}\)।
সূত্রে যাচাই: \(C = [2, 1]\), \(CC^T = 5\), \(\hat{x} = \frac{1}{5}\begin{bmatrix} 2 \\ 1\end{bmatrix}\cdot 5 = \begin{bmatrix} 2 \\ 1\end{bmatrix}\) ✓। লক্ষ করো \(\hat{x} = (2,1)\) constraint normal \((2,1)\)-এর দিকেই — Property 4 (least norm ⟂ constraint) মিললো।
Problem 2. \(\underset{x}{\min}\; (x_1 - 4)^2 + (x_2 - 2)^2\) শর্তসাপেক্ষে \(x_1 - x_2 = 0\) (মানে \(x_1 = x_2\))। Lagrange condition দিয়ে সমাধান করো এবং gradient-normal সমান্তরালতা দেখাও।
Solution
\(\nabla f = (2(x_1 - 4),\; 2(x_2 - 2))\); constraint normal \(c = (1, -1)\)। সমান্তরালতা \(\nabla f = -zc\): \(2(x_1 - 4) = -z\) আর \(2(x_2 - 2) = z\)। যোগ করি: \(2(x_1 - 4) + 2(x_2 - 2) = 0 \Rightarrow x_1 + x_2 = 6\)। constraint \(x_1 = x_2\) সহ: \(x_1 = x_2 = 3\)।
সমাধান \((3, 3)\)। যাচাই: \(\nabla f = (2(3-4), 2(3-2)) = (-2, 2) = -2\cdot(1,-1) = -2c\) — সত্যিই \(c\)-এর সমান্তরাল (\(z = 2\))। Unconstrained ছিল \((4, 2)\); constraint line \(x_1=x_2\)-এ তার লম্ব-প্রক্ষেপই \((3,3)\)।
Problem 3. KKT system প্রমাণ করো: \(\underset{x}{\min}\;\|Ax-b\|^2\) s.t. \(Cx = d\)-এর Lagrangian থেকে \(\begin{bmatrix} 2A^TA & C^T \\ C & 0\end{bmatrix}\begin{bmatrix} x \\ z\end{bmatrix} = \begin{bmatrix} 2A^Tb \\ d\end{bmatrix}\)।
Solution
Lagrangian: \(L(x, z) = \|Ax - b\|^2 + z^T(Cx - d) = x^TA^TAx - 2b^TAx + b^Tb + z^TCx - z^Td\)।
\(\partial L/\partial x = 0\): \(2A^TAx - 2A^Tb + C^Tz = 0 \Rightarrow 2A^TAx + C^Tz = 2A^Tb\)। এটাই উপরের block row।
\(\partial L/\partial z = 0\): \(Cx - d = 0 \Rightarrow Cx = d\)। এটাই নিচের block row।
দুটো একসাথে matrix আকারে সাজালে ঠিক KKT system ∎। খেয়াল করো matrix-টা symmetric (block-transpose করলে একই) — এটা coincidence নয়, Lagrangian-এর গঠনগত সৌন্দর্য।
Problem 4. (Spline) দুটো সরলরেখা \(p(x) = a_0 + a_1 x\) (\(x \leq 0\)) আর \(q(x) = b_0 + b_1 x\) (\(x \geq 0\))। Knot \(x = 0\)-এ মসৃণ জোড়ার জন্য কী কী constraint লাগবে? Matrix \(C\) লেখো (\(x = (a_0, a_1, b_0, b_1)\))।
Solution
দুটো শর্ত মসৃণতার জন্য: - মান মেলে \(p(0) = q(0)\): \(a_0 = b_0 \Rightarrow a_0 - b_0 = 0\)। - ঢাল মেলে \(p'(0) = q'(0)\): \(a_1 = b_1 \Rightarrow a_1 - b_1 = 0\)।
এই \(C\)-ই fig02-এর মসৃণ জোড়া বানায় (সেখানে cubic, তাই আরও term, কিন্তু ধারণা এক)। শিক্ষা: "মসৃণ" মানে গণিতে "মান ও ঢাল উভয় ধারাবাহিক" — দুটো linear equality constraint, ব্যস।
Problem 5. Property 5 প্রমাণ করো: constraint কখনো objective ভালো করে না, অর্থাৎ \(\|A\hat{x} - b\|^2 \geq \|A\hat{x}_{ls} - b\|^2\) যেখানে \(\hat{x}_{ls}\) unconstrained সেরা।
Solution
Unconstrained সমস্যাটা constrained-এর চেয়ে বেশি \(x\)-এর ওপর minimize করে: unconstrained-এ \(x\) পুরো \(\mathbb{R}^n\)-এ ঘুরতে পারে, constrained-এ শুধু \(\{x : Cx = d\}\) affine subset-এ।
বড় সেটে minimum সবসময় ছোট-বা-সমান সেটের minimum-এর চেয়ে কম-বা-সমান (বেশি জায়গায় খুঁজলে আরও ভালো পাওয়ার সুযোগ)। তাই:
সমতা তখনই, যখন unconstrained optimum \(\hat{x}_{ls}\) ঘটনাক্রমে \(C\hat{x}_{ls} = d\) মানে (constraint নিষ্ক্রিয়) ∎। অর্থ: constraint = স্বাধীনতা হারানো = fit-এর মূল্য দেওয়া। §৬-এর residual বৃদ্ধি এরই সংখ্যা।
Problem 6. (Control) একটা বস্তুকে ২ ধাপে (\(f_1, f_2\)) ঠেলে চূড়ান্ত বেগ \(v = f_1 + f_2 = 1\) পেতে হবে (একটাই constraint)। ন্যূনতম শক্তি \(\|f\|^2 = f_1^2 + f_2^2\)-এর force খুঁজো। bang-bang \((1, 0)\)-এর সাথে তুলনা করো।
Solution
\(\underset{f}{\min}\; f_1^2 + f_2^2\) s.t. \(f_1 + f_2 = 1\)। এটা least-norm; সূত্রে \(C = [1,1]\), \(CC^T = 2\):
শক্তি \(\|\hat{f}\|^2 = 0.25 + 0.25 = 0.5\)।
তুলনা: \((1, 0)\)-ও \(f_1 + f_2 = 1\) মানে, কিন্তু শক্তি \(1^2 + 0 = 1.0\) — দ্বিগুণ! least-norm force ছড়িয়ে (দুই ধাপে সমান) দিলে শক্তি অর্ধেক। এটাই fig04-এর মূল বার্তার ছোট সংস্করণ: মৃদু, সুষম ধাক্কা = মিতব্যয়ী নিয়ন্ত্রণ। (গাণিতিক কারণ: fixed sum-এ বর্গের যোগফল তখনই সবচেয়ে ছোট যখন সব সমান — AM-QM অসমতা।)
Problem 7. (কোডে) solve_cls ব্যবহার করে fit করো \(y = a + bx + cx^2\) data \((x,y) = (0,1),(1,0),(2,1),(3,4)\)-তে, শর্ত \(c = 1\) (মানে \(x^2\)-এর coefficient ঠিক \(1\))। Constrained ও unconstrained সমাধান তুলনা করো।
Solution
import numpy as np
def solve_cls(A, b, C, d):
n, p = A.shape[1], C.shape[0]
K = np.block([[2*A.T@A, C.T], [C, np.zeros((p, p))]])
rhs = np.hstack([2*A.T@b, d])
s = np.linalg.solve(K, rhs); return s[:n], s[n:]
x = np.array([0., 1, 2, 3]); y = np.array([1., 0, 1, 4])
A = np.column_stack([np.ones(4), x, x**2]) # params (a, b, c)
C = np.array([[0., 0., 1.]]); d = np.array([1.0]) # c = 1
x_un, *_ = np.linalg.lstsq(A, y, rcond=None)
x_c, z = solve_cls(A, y, C, d)
print("unconstrained (a,b,c):", x_un.round(3))
print("constrained (a,b,c):", x_c.round(3), " c =", round(float(x_c[2]), 3))
Problem 8. ধারণাগত: বন্ধু বলছে "constraint আর ridge penalty তো একই জিনিস — দুটোই \(x\)-কে বাঁধে।" তাকে পার্থক্যটা বোঝাও, আর কখন কোনটা ব্যবহার করবে।
Solution
দুটোই \(x\)-কে "বাঁধে" কিন্তু ভিন্নভাবে:
- Ridge penalty (soft): "\(x\) ছোট হলে ভালো, তবে দরকারে বড় হতে পারে — শুধু \(\lambda\|x\|^2\) দাম দিতে হবে।" একটা knob \(\lambda\); সমাধান কখনো ঠিক শর্ত মানে না, একটা আপস।
- Constraint (hard): "\(Cx = d\) মানতেই হবে, ব্যতিক্রম নেই।" knob নেই; সমাধান নিখুঁতভাবে শর্তে বসে।
কখন কোনটা: - শর্তটা ভৌত/যৌক্তিকভাবে অলঙ্ঘনীয় হলে (spline seam মিলতেই হবে, probability যোগে \(1\) হতেই হবে, রকেট ঠিক লক্ষ্যে) → constraint। - শর্তটা শুধু একটা "পছন্দ"/prior হলে (coefficient ছোট থাকলে ভালো, overfitting এড়াতে চাই) → ridge penalty।
গাণিতিক সংযোগ: constraint হলো \(\lambda \to \infty\) সীমায় penalty-র চরম রূপ। কিন্তু ব্যবহারিকভাবে এরা আলাদা যন্ত্র, আলাদা উদ্দেশ্যে।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "Constrained optimization মানে iterative খোঁজাখুঁজি" | সমতা-শর্তের LS-এ নয়! Lagrangian → একটা linear KKT system → বন্ধ-রূপ উত্তর (Property 1)। iteration লাগে না। |
| "Lagrange multiplier \(z\) শুধু কৌশল, অর্থহীন" | \(z\)-এর অর্থ আছে: constraint শিথিল করলে objective কত বদলাবে — shadow price (Example 3)। শূন্য \(z\) = নিষ্ক্রিয় constraint। |
| "Constraint objective ভালো করে দেবে" | উল্টো! constraint স্বাধীনতা কমায়, তাই fit সবসময় খারাপ-বা-সমান হয় (Property 5)। constraint-এর একটা "দাম" আছে। |
| "Least norm মানে shortest, তাই constraint line-এর সমান্তরাল" | না — least norm সমাধান constraint line-এর সাথে লম্ব (Property 4)। origin থেকে লম্ব দূরত্বই সবচেয়ে ছোট (projection!)। |
| "প্রতি constraint-এ variable কমে, তাই \(p = n\) ভালো" | \(p = n\) হলে \(Cx = d\) নিজেই \(x\)-কে পুরো ঠিক করে দেয় (আর optimize-এর কিছু থাকে না)। constrained LS-এর মজা \(p < n\)-এই — কিছু স্বাধীনতা থাকে objective কমানোর। |
| "Ridge আর constraint একই" | Ridge = soft (আপসযোগ্য penalty); constraint = hard (অলঙ্ঘনীয়)। constraint হলো \(\lambda\to\infty\) সীমা, কিন্তু আলাদা যন্ত্র, আলাদা কাজ (Problem 8)। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Constrained LS | \(\underset{x}{\min}\;\|Ax-b\|^2\) s.t. \(Cx = d\) | বেড়া দেওয়া উপত্যকা |
| Lagrangian | \(L = \|Ax-b\|^2 + z^T(Cx-d)\) | constraint-কে objective-এ মেশানো |
| KKT system | \(\begin{bmatrix}2A^TA & C^T\\ C & 0\end{bmatrix}\begin{bmatrix}x\\ z\end{bmatrix} = \begin{bmatrix}2A^Tb\\ d\end{bmatrix}\) | এক বড় linear ব্যবস্থা |
| Lagrange condition | \(\nabla f \parallel\) constraint normal | fig01-এর দুই সমান্তরাল তীর |
| Multiplier \(z\) | constraint-এর shadow price (প্রান্তিক মূল্য) | constraint কতটা চাপে |
| Least norm | \(\hat{x} = C^T(CC^T)^{-1}d\) | origin থেকে লম্ব পাদবিন্দু |
| Constraint-এর দাম | fit খারাপ-বা-সমান হয় (Property 5) | কম জায়গায় খোঁজা |
পরের chapter-এর সেতু: এতদিন (Part V–এই chapter পর্যন্ত) আমরা ধরে নিয়েছি data-র সাথে একটা label বা target \(b\) দেওয়া আছে — supervised জগৎ। কিন্তু বাস্তবের বেশিরভাগ data-য় কোনো label নেই: হাজারো গ্রাহক, কোনো "শ্রেণি" লেখা নেই; লক্ষ্য web-page, কোনো "গুরুত্ব" চিহ্নিত নেই। label ছাড়াই কি structure খুঁজে বের করা যায়? হ্যাঁ — unsupervised learning। Chapter 7.4-এ দুটো সুন্দর উদাহরণ: k-means (label ছাড়া data-কে দলে ভাগ করা) আর PageRank (network-এর গঠন থেকে গুরুত্ব বের করা) — আর দেখবে, দুটোরই ভিত্তি সেই চেনা linear algebra।
📓 Notebook Project¶
notebooks/part-07/ch03-project.ipynb — KKT solver scratch-এ লিখে তিনটা সমস্যা: (১) constrained line fitting (নির্দিষ্ট বিন্দু দিয়ে যাওয়া রেখা), (২) least-norm দিয়ে ন্যূনতম-শক্তির control force খুঁজে গতিপথ আঁকা, (৩) piecewise polynomial-কে constraint দিয়ে মসৃণ spline বানানো — প্রতিটাতে unconstrained বনাম constrained পাশাপাশি এবং constraint-এর "দাম" মেপে দেখা।