Chapter 4.5 — Kernel, Range ও Rank–Nullity Theorem (কার্নেল, রেঞ্জ ও র্যাঙ্ক–নালিটি উপপাদ্য)¶
🎯 এই chapter-এ যা শিখবে¶
- প্রতিটা linear map-এর দুটো গোপন subspace — Kernel(কার্নেল): কারা শূন্যে চাপা পড়ে, আর Range(রেঞ্জ): output কোথায় কোথায় পৌঁছায়
- চার fundamental subspace-এর বিখ্যাত ছবি — একটা matrix-এর domain আর codomain কীভাবে চার টুকরোয় ভাগ হয়ে যায়
- RREF দিয়ে kernel ও range-এর basis বের করার হাতে-কলমে রেসিপি
- Rank–Nullity Theorem: \(\text{rank} + \text{nullity} = n\) — input-এর dimension ভাগ হয়ে যায় "বাঁচা" আর "মরা"-য়, এক মাত্রাও হারায় না
- Kernel দেখে এক নজরে বলা — map-টা কি one-to-one? Invertible?
🖼️ এক ছবিতে মূল idea¶
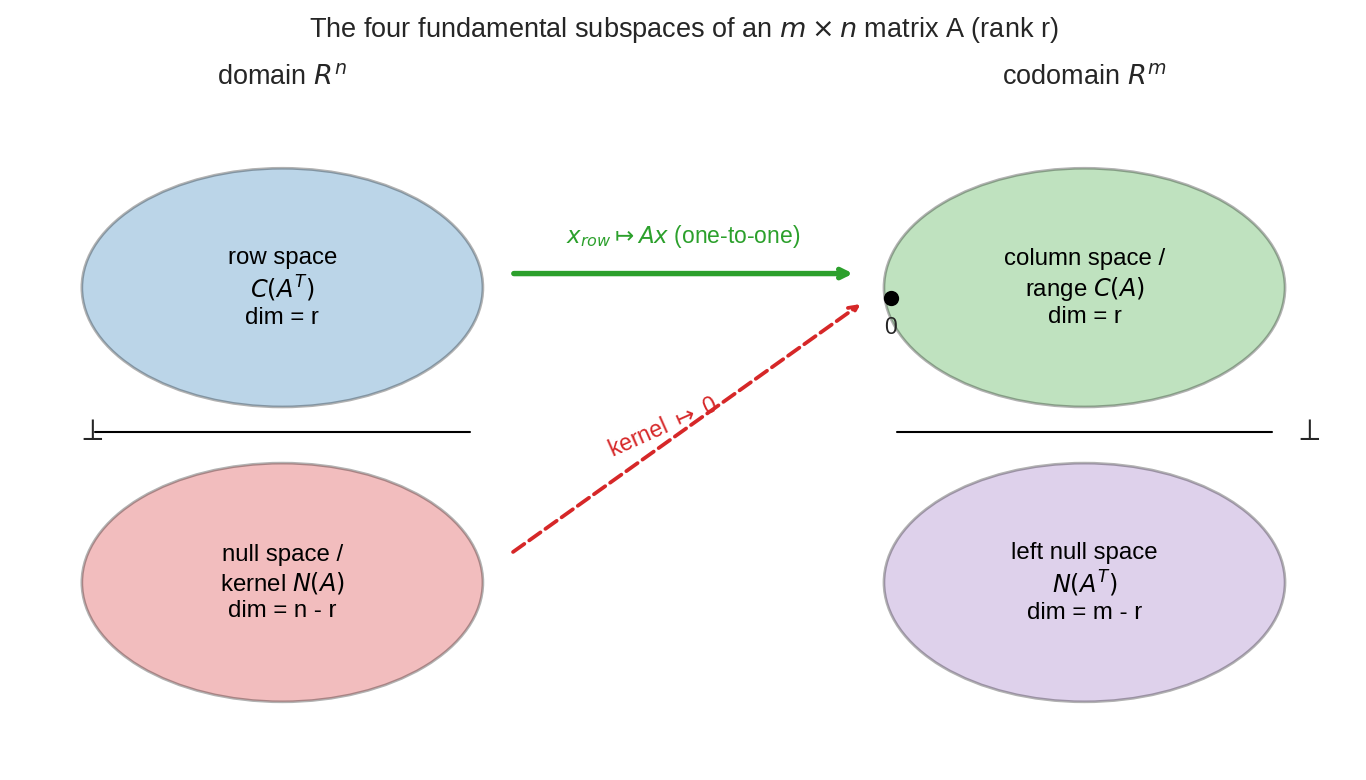
একটা \(m \times n\) matrix \(A\)-র পুরো জীবনী এক ছবিতে: বাঁয়ে domain \(R^n\) ভাগ হয়ে গেছে row space আর kernel-এ; ডানে codomain \(R^m\) ভাগ হয়ে গেছে range (column space) আর left null space-এ। Kernel-এর সবাই চাপা পড়ে \(0\)-তে; বাকিরা এক-এক করে range-এ পৌঁছায়। এই chapter শেষে ছবিটার প্রতিটা শব্দ তোমার চেনা হয়ে যাবে।
১. কি? (What)¶
আগে concrete ছবি: ছায়া ফেলা¶
\(R^3\)-এ সূর্য ঠিক মাথার ওপরে — প্রতিটা vector মেঝেতে (xy-plane-এ) ছায়া ফেলে:
দুটো প্রশ্ন করি:
প্রশ্ন ১: কোন কোন vector-এর ছায়া একেবারে শূন্য — মানে \(L(v) = 0\)? উত্তর: যারা খাড়া দাঁড়িয়ে — \((0, 0, z)\) — পুরো \(z\)-axis। এরা map-এর হাতে "চাপা পড়ে যায়"।
প্রশ্ন ২: ছায়ারা সব মিলে কোথায় কোথায় পড়তে পারে? উত্তর: পুরো মেঝে — xy-plane। মেঝের বাইরে ছায়া পড়ার প্রশ্নই নেই।
এই দুই উত্তরের গালভরা নাম-ই আজকের বিষয়: প্রথমটা \(L\)-এর kernel, দ্বিতীয়টা range। আর একটা হিসাব মিলিয়ে দেখো: চাপা-পড়া দিক \(1\)টা (\(z\)-axis), বেঁচে-যাওয়া দিক \(2\)টা (মেঝে) — যোগফল \(1 + 2 = 3 =\) input-এর dimension। এই হিসাব কখনো ভুল হয় না — সেটাই chapter-এর শেষ উপহার।
দৈনন্দিন analogy: তথ্য হারানোর হিসাবরক্ষা¶
একটা জরিপ ভাবো যেখানে সবার (উচ্চতা, ওজন, বয়স) থেকে শুধু (উচ্চতা, ওজন) রাখা হয় — বয়সের কলামটা মুছে যায়। "বয়স-দিক"-এ যত তথ্য ছিল সব হারাল (kernel), আর output-রা সবাই (উচ্চতা, ওজন)-plane-এ বাস করে (range)। Linear map মানেই এমন একটা "তথ্য-প্রক্রিয়াকরণ যন্ত্র" — kernel মাপে কতটা তথ্য হারায়, range মাপে কতটা টিকে থাকে।
Formal সংজ্ঞা¶
সংজ্ঞা: Kernel
Linear map \(L : V \to W\)-এর Kernel(কার্নেল) (অন্য নাম null space — নাল স্পেস) হলো \(0\)-তে চাপা-পড়া সদস্যদের set:
Matrix-এর ভাষায়: \(\ker A\) = homogeneous system \(Ax = 0\)-এর সব solution — Part II-এর পুরনো বন্ধু!
সংজ্ঞা: Range
\(L\)-এর Range(রেঞ্জ) (অন্য নাম image — ইমেজ, matrix-এর বেলায় column space — কলাম স্পেস) হলো সম্ভাব্য সব output-এর set:
Matrix-এর ভাষায়: \(Ax = x_1 (\text{col}_1) + \cdots + x_n (\text{col}_n)\) — তাই \(\operatorname{ran} A = \operatorname{span}\{\text{columns of } A\}\)। Range = column-দের span — এই এক লাইন মুখস্থ রাখো।
লক্ষ করো দুজনের বাসা আলাদা: \(\ker L\) থাকে input জগতে (\(V\)), \(\operatorname{ran} L\) থাকে output জগতে (\(W\))। ছবিতে গুলিয়ে ফেলো না।
আর দুটো মাপ:
সংজ্ঞা: Rank ও Nullity
Rank(র্যাঙ্ক) = কতগুলো দিক বেঁচে থাকে; Nullity(নালিটি) = কতগুলো দিক চাপা পড়ে।
২. দেখতে কেমন?¶
ছায়া-map-এর পূর্ণ ছবি¶
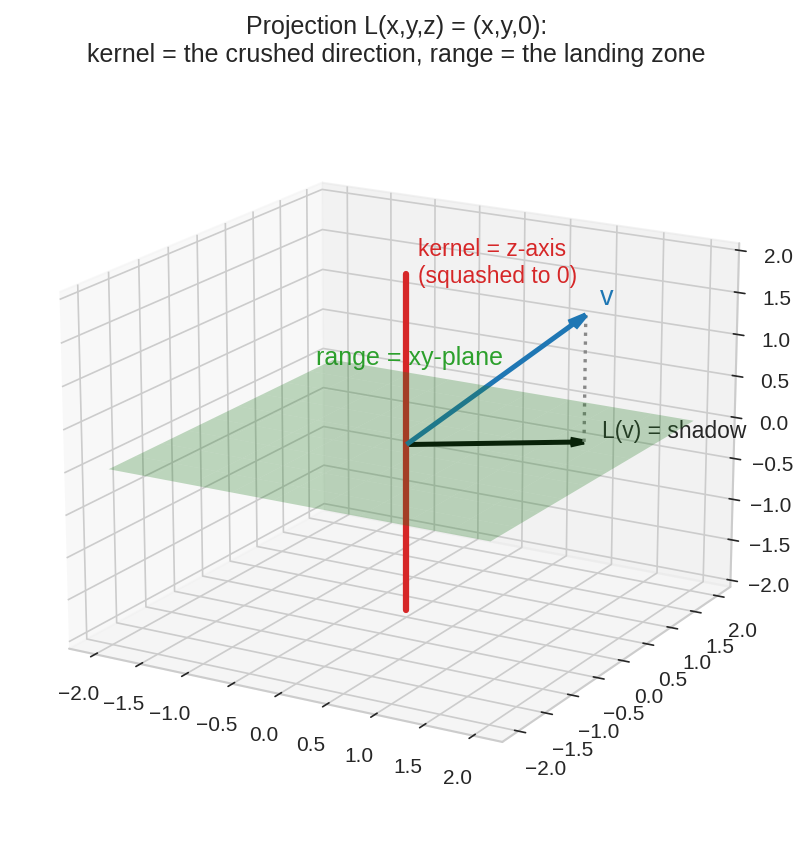
ছায়া-map \(L(x,y,z) = (x,y,0)\): লাল খাড়া line-টা kernel — ওই দিকের সব vector শূন্যে চুপসে যায়; সবুজ plane-টা range — সব ছায়া এখানেই নামে। \(v\) থেকে ছায়া \(L(v)\)-তে নামার পথটাও আঁকা। Nullity \(=1\), rank \(=2\), যোগফল \(=3\) ✓
Matrix-ও তাই করে: plane-কে line বানিয়ে ফেলা¶
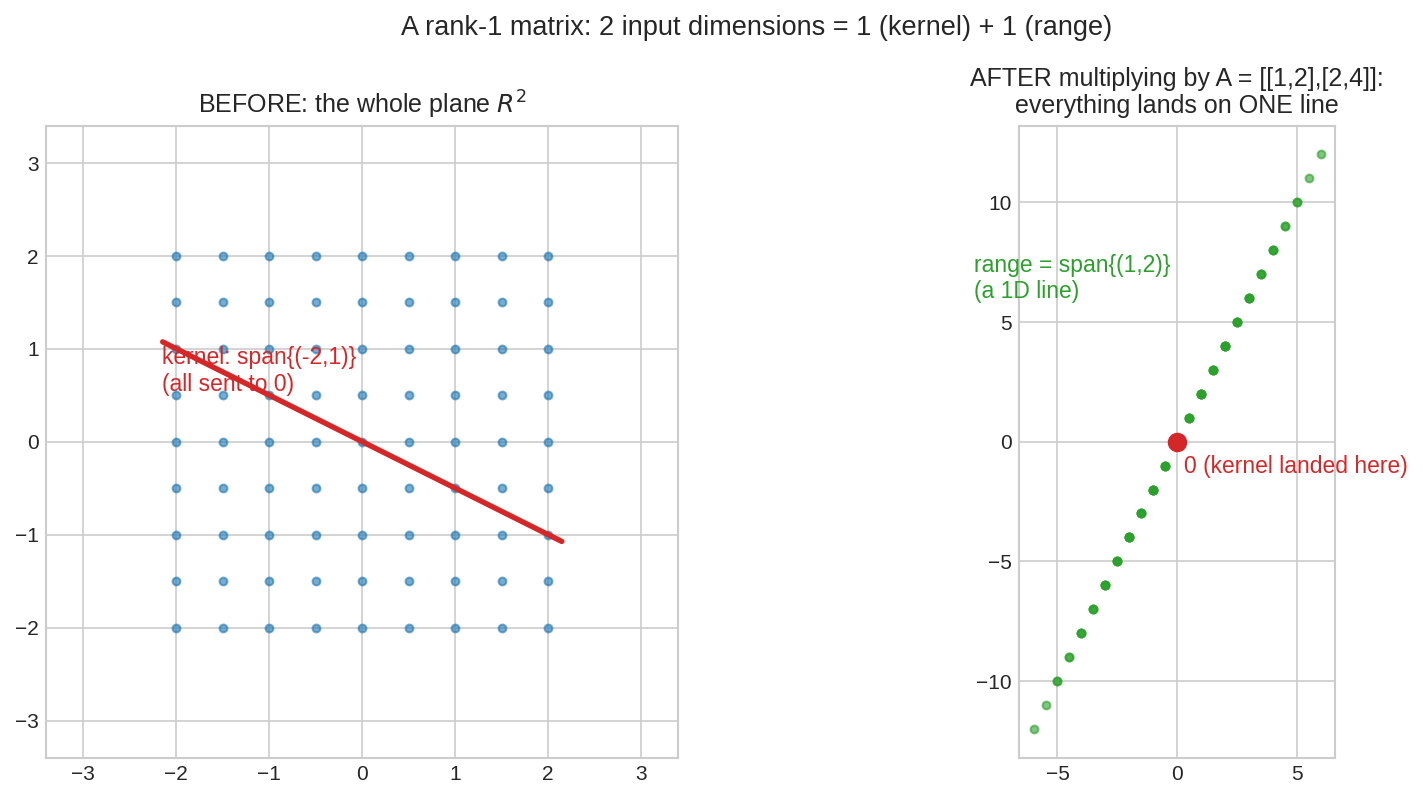
\(A = \begin{pmatrix}1&2\\2&4\end{pmatrix}\) (দ্বিতীয় column প্রথমটার দ্বিগুণ — dependent!)। বাঁয়ে গোটা \(R^2\)-এর গ্রিড-বিন্দুরা; ডানে \(A\) দিয়ে গুণের পরে সবাই এক line-এর ওপর — range \(= \operatorname{span}\{(1,2)\}\), মাত্র ১-মাত্রিক। আর লাল দিকের (\((-2,1)\)-এর গুণিতক) সবাই এক বিন্দুতে: \(0\)। ২ মাত্রার input \(= 1\) (মরা) \(+ 1\) (বাঁচা)।
এই ছবিটাই singular matrix-এর আসল চেহারা: \(\det = 0\) মানে কোথাও না কোথাও space চুপসে গেছে — আর চুপসে যাওয়া দিকগুলোই kernel।
৩. কোথায় ইউজ হয়?¶
- সমীকরণ solve-এর পূর্ণ তত্ত্ব (Part II সম্পূর্ণ হলো): \(Ax = b\) solve করা যাবে কি? — যাবে যদি ও কেবল যদি \(b \in \operatorname{ran} A\)। Solution ক-টা? — kernel যত বড়: এক solution \(x_p\) পেলে বাকি সব \(= x_p + (\text{kernel-এর সদস্য})\)। অর্থাৎ range বলে "সম্ভব কি না", kernel বলে "ক-টা"।
- Machine Learning-এ feature redundancy: data matrix-এর rank কম মানে কিছু feature অন্যদের combination — regression-এ coefficient অনন্যভাবে ঠিক হয় না (multicollinearity)। Rank চেক করা মানেই kernel খোঁজা।
- Image compression (rank আবার!): ছবির matrix-এর rank যত কম, তত কম সংখ্যায় ছবিটা লেখা যায় — Part VI-এর SVD এই idea-র চূড়া: "প্রায় কম rank"-এ approximate করা।
- Neural network-এর bottleneck: \(784 \to 32\) dimension-এর layer মানে rank \(\le 32\) — জোর করে তথ্য চাপা (nullity \(\ge 752\)); autoencoder ঠিক এই চাপাচাপিকেই শেখার কৌশল বানায়।
- Computer vision-এ camera projection: 3D দৃশ্য → 2D ছবি একটা linear-ঘেঁষা projection; kernel-এর দিক (গভীরতা) হারায় বলেই এক ছবি থেকে দূরত্ব বলা কঠিন — stereo vision লাগে।
- Control theory: system-এর controllability matrix-এর rank কম মানে কিছু state-এ কখনোই পৌঁছানো যাবে না (range-এর বাইরে) — রকেট ডিজাইনের আগে এই rank চেক বাধ্যতামূলক।
৪. Properties¶
Property 1: Kernel একটা subspace¶
\(u, v \in \ker L\) আর scalar \(\mu, \nu\) নাও। Linearity থেকে:
কাজেই \(\mu u + \nu v \in \ker L\) — Chapter 4.1-এর Subspace Theorem-এ প্রমাণ শেষ। (\(0 \in \ker L\)-ও বটে: \(L(0) = 0\)।) এই জন্যই homogeneous system-এর solution set সবসময় এত সুন্দর — সে subspace, line বা plane, কখনো বিদঘুটে বাঁকা কিছু নয়।
Property 2: Range-ও subspace¶
\(w = L(u)\), \(w' = L(v)\) দুটো output হলে \(\mu w + \nu w' = L(\mu u + \nu v)\) — সেটাও একটা output। কাজেই range addition ও scaling-এ closed — subspace ✓ (তবে খেয়াল: kernel বাস করে \(V\)-তে, range \(W\)-তে।)
Property 3: Kernel দেখে one-to-one চেনা যায়¶
Injectivity test
\(L\) one-to-one(এক-এক — injective) \(\iff \ker L = \{0\}\)।
প্রমাণ: (\(\Leftarrow\)) ধরো \(L(v_1) = L(v_2)\); তাহলে \(L(v_1 - v_2) = 0\), মানে \(v_1 - v_2 \in \ker L = \{0\}\), মানে \(v_1 = v_2\) ✓। (\(\Rightarrow\)) \(L(0) = 0\); one-to-one হলে \(0\)-তে যাওয়ার আর কেউ নেই, তাই \(\ker L = \{0\}\) ✓
দারুণ ব্যাপারটা লক্ষ করো: সাধারণ function-এ one-to-one চেক করতে সব জোড়া input দেখতে হয়; linear map-এ মাত্র একটা প্রশ্ন — "শূন্যে কে কে যায়?" Linearity-র উপহার।
Property 4: RREF থেকে দুই basis — এক ঢিলে দুই পাখি¶
\(A\)-এর RREF বের করো। তারপর:
- Range-এর basis: RREF-এ যেসব column-এ pivot, মূল \(A\)-এর সেই column-গুলো। (Non-pivot column-রা বাঁয়ের pivot column-দের combination — Chapter 4.2-এর শিক্ষা।)
- Kernel-এর basis: free variable-প্রতি একটা solution vector (Part II-এর special solution-রা)।
উদাহরণ (Guest বইয়ের ধাঁচে): \(A = \begin{pmatrix} 1 & 2 & 0 & 1 \\ 1 & 2 & 1 & 2 \\ 0 & 0 & 1 & 1 \end{pmatrix} \xrightarrow{\text{RREF}} \begin{pmatrix} 1 & 2 & 0 & 1 \\ 0 & 0 & 1 & 1 \\ 0 & 0 & 0 & 0 \end{pmatrix}\)
Pivot column: ১ ও ৩ নম্বর \(\Rightarrow\) range-basis \(= \left\{\begin{pmatrix}1\\1\\0\end{pmatrix}, \begin{pmatrix}0\\1\\1\end{pmatrix}\right\}\), rank \(= 2\)। Free variable: \(x_2, x_4\) \(\Rightarrow\) kernel-basis \(= \left\{\begin{pmatrix}-2\\1\\0\\0\end{pmatrix}, \begin{pmatrix}-1\\0\\-1\\1\end{pmatrix}\right\}\), nullity \(= 2\)। যোগফল \(2 + 2 = 4 = n\) ✓
Property 5: Rank–Nullity Theorem — হিসাব সবসময় মেলে¶
Rank–Nullity Theorem (Dimension Formula)
\(L : V \to W\) linear, \(V\) finite-dimensional হলে:
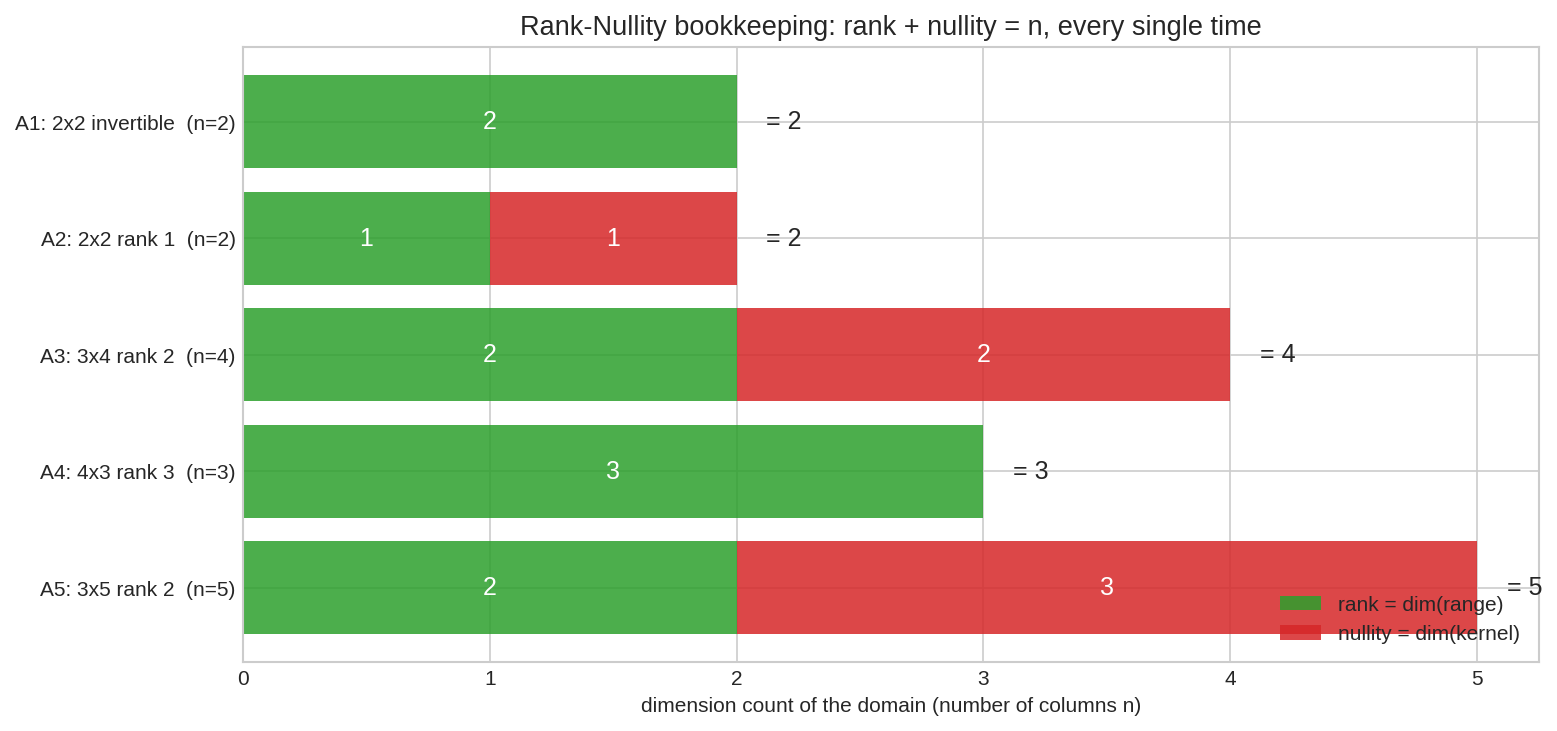
পাঁচটা একদম ভিন্ন সাইজ-চেহারার matrix — প্রত্যেকের সবুজ (rank) আর লাল (nullity) অংশ জোড়া দিলে ঠিক \(n\) (column-সংখ্যা)। ব্যতিক্রম নেই — এটা প্রকৃতির নিয়ম নয়, গণিতের theorem।
প্রমাণের কঙ্কাল (পুরোটা Intuition ও Problems-এ): \(\ker L\)-এর একটা basis নাও (\(p\) জন), তাকে বাড়িয়ে \(V\)-এর basis বানাও (\(p + q\) জন)। দেখানো যায়: বাড়তি \(q\) জনের image-রা \(\operatorname{ran} L\)-এর basis। তাহলে \(\dim V = p + q = \operatorname{null} L + \operatorname{rank} L\)। \(\blacksquare\)
৫. Intuition — কেন সত্য?¶
Rank–nullity আসলে "মাত্রার সংরক্ষণ সূত্র" (conservation law)। পদার্থবিজ্ঞানে শক্তি হারায় না — রূপ বদলায়। Linear map-এ input-এর মাত্রাও হারায় না — প্রতিটা দিকের ভাগ্য দুটোর একটা: হয় সে চাপা পড়ে (kernel-এ যায়), নয় সে বেঁচে গিয়ে output-এ নতুন দিক হয় (range-এ যায়)। আধা-চাপা বলে কিছু নেই — linearity তা হতে দেয় না। তাই:
ছায়ার ছবিতে ফেরো: \(3 = 1 + 2\)। Rank-1 matrix-এর ছবিতে: \(2 = 1 + 1\)। Invertible matrix-এ কেউ মরে না: \(n = 0 + n\) — সব দিক বাঁচে, তাই সে উল্টানো যায়।
কেন "আধা-চাপা" অসম্ভব — প্রমাণের প্রাণভোমরা। Kernel-এর basis \(\{v_1, \ldots, v_p\}\)-কে বাড়িয়ে পুরো \(V\)-এর basis \(\{v_1, \ldots, v_p, u_1, \ldots, u_q\}\) বানাও। যেকোনো output:
— kernel-অংশটা নিঃশব্দে উবে গেল, \(u\)-দের image-রাই range-টা span করে। আর তারা independent-ও: \(\sum d_j L(u_j) = 0\) হলে \(\sum d_j u_j \in \ker L\), মানে সে \(v_i\)-দের combination — কিন্তু basis-এর সদস্যরা একে অন্যের combination হতে পারে না, তাই সব \(d_j = 0\)। ব্যস: range-এর basis-এ ঠিক \(q\) জন — kernel যত জন খেল, range পেল বাকি সবাই।
চার subspace-এর ছবিটার মানে এবার পূর্ণ হলো। Opening figure-এ domain-এর ওপরের অংশ (row space) হলো "বাঁচা দিকদের আসল ঠিকানা" — তার dimension-ও \(r\); সে আর kernel মিলে পুরো \(R^n\)। Output পাশে range (\(r\)) আর তার বাইরে-থাকা left null space (\(m - r\))। Part V-এ শিখবে এই জোড়াগুলো আসলে পরস্পরের লম্ব — আপাতত এটুকু নাও: একটা matrix মানেই চারটা subspace-এর এই নিখুঁত চৌকাঠ।
৬. Code-এ কেমনে লিখে¶
RREF-ভিত্তিক রেসিপিটাই কোডে — kernel ও range-এর basis, তারপর rank–nullity যাচাই:
import numpy as np
from scipy.linalg import null_space
np.random.seed(42)
A = np.array([[1.0, 2, 0, 1],
[1.0, 2, 1, 2],
[0.0, 0, 1, 1]])
m, n = A.shape
# ---- rank: বাঁচা দিকের সংখ্যা ----
r = np.linalg.matrix_rank(A)
print("rank =", r, "| nullity =", n - r, "| যোগফল =", n)
# ---- range-এর basis: pivot column বাছাই (QR দিয়ে দ্রুত উপায়ও আছে;
# এখানে সরল পথ — column একে একে যোগ করে rank বাড়ে কি না দেখা) ----
pivots = []
for j in range(n):
cols = pivots + [j]
if np.linalg.matrix_rank(A[:, cols]) > len(pivots):
pivots.append(j)
print("pivot columns:", pivots)
print("range basis (A-এর column):\n", A[:, pivots])
# ---- kernel-এর basis ----
K = null_space(A) # column-রা kernel-এর orthonormal basis
print("kernel basis (columns):\n", np.round(K, 3))
# ---- যাচাই: kernel-এর সদস্যরা সত্যিই শূন্যে যায়? ----
print("A @ kernel =", np.round(A @ K, 10).max(), "(সব ~0)")
# ---- rank-nullity পাঁচটা random matrix-এ ----
for shape in [(2, 2), (3, 4), (4, 3), (2, 5), (5, 5)]:
M = np.random.randn(*shape) @ np.diag(np.random.randint(0, 2, shape[1]) * 1.0)
rM = np.linalg.matrix_rank(M)
print(f"shape {shape}: rank {rM} + nullity {shape[1]-rM} = {shape[1]}")
Output:
rank = 2 | nullity = 2 | যোগফল = 4
pivot columns: [0, 2]
range basis (A-এর column):
[[1. 0.]
[1. 1.]
[0. 1.]]
kernel basis (columns):
[[-0.894 -0.213]
[ 0.447 -0.426]
[ 0. -0.641]
[ 0. 0.641]]
A @ kernel = 0.0 (সব ~0)
shape (2, 2): rank 1 + nullity 1 = 2
shape (3, 4): rank 2 + nullity 2 = 4
shape (4, 3): rank 2 + nullity 1 = 3
shape (2, 5): rank 2 + nullity 3 = 5
shape (5, 5): rank 3 + nullity 2 = 5
ব্যাখ্যা: null_space(A)-এর column দুটো হাতের হিসাবের \((-2,1,0,0)\), \((-1,0,-1,1)\)-এর মতো দেখতে নয় — কিন্তু তারা একই subspace-এর অন্য (orthonormal) basis; A @ K শূন্য হওয়াই তার সাক্ষী। আর শেষ লুপটা rank–nullity-র stress-test: matrix-এর সাইজ-চেহারা যা-ই হোক, rank + nullity \(= n\) — একবারও ফেল করে না।
৭. Worked Examples¶
Example 1: হাতে-কলমে kernel ও range¶
\(L(x, y) = (x + y,\; x + 2y,\; y)\) — অর্থাৎ matrix \(A = \begin{pmatrix} 1 & 1 \\ 1 & 2 \\ 0 & 1 \end{pmatrix}\)। Kernel, range, আর দুটোর dimension বের করো। \(L\) কি one-to-one?
ধাপ ১ (kernel): Solve \(Ax = 0\):
কাজেই \(\ker L = \{0\}\), nullity \(= 0\) — Property 3 মতে \(L\) one-to-one ✓
ধাপ ২ (range): column-দের span: \(\operatorname{ran} L = \operatorname{span}\{(1,1,0), (1,2,1)\}\); দুজন dependent নয় (কেউ কারো গুণিতক না), তাই এরাই basis — rank \(= 2\)।
ধাপ ৩ (হিসাব): rank + nullity \(= 2 + 0 = 2 = \dim R^2\) ✓। জ্যামিতি: \(R^2\) কোনো চাপ না খেয়ে \(R^3\)-এর ভেতরের একটা plane-এ ঢুকে গেল — কিন্তু onto নয়: \(R^3\)-এর অধিকাংশ জায়গায় সে পৌঁছায় না।
Example 2: RREF-রেসিপির পূর্ণ প্রদর্শন¶
\(A = \begin{pmatrix} 1 & 2 & 1 \\ 2 & 4 & 2 \\ 1 & 2 & 3 \end{pmatrix}\)-এর চারটে সংখ্যা বের করো: rank, nullity, kernel-basis, range-basis।
ধাপ ১ (RREF): \(R_2 \to R_2 - 2R_1\), \(R_3 \to R_3 - R_1\):
ধাপ ২ (পড়ে ফেলা): pivot column ১ ও ৩ \(\Rightarrow\) rank \(= 2\); free variable \(x_2\) \(\Rightarrow\) nullity \(= 1\)। যোগফল \(3\) ✓
ধাপ ৩ (basis-রা): Range-basis: মূল \(A\)-এর ১ ও ৩ নম্বর column \(= \{(1,2,1), (1,2,3)\}\)। Kernel: \(x_1 = -2x_2\), \(x_3 = 0\) — basis \(\{(-2, 1, 0)\}\)।
যাচাই: \(A(-2, 1, 0)^T = (-2 + 2,\; -4 + 4,\; -2 + 2)^T = 0\) ✓
Example 3: Rank–nullity দিয়ে না-দেখেই উত্তর¶
\(L : R^7 \to R^4\) একটা linear map, আর জানা আছে \(L\) onto (range পুরো \(R^4\))। \(\ker L\)-এর dimension কত? \(L\) কি one-to-one হতে পারে?
ধাপ ১: onto মানে \(\operatorname{rank} L = \dim R^4 = 4\)।
ধাপ ২: rank–nullity: \(\operatorname{null} L = 7 - 4 = 3\)।
ধাপ ৩: nullity \(= 3 \ne 0\), তাই one-to-one অসম্ভব — সাতটা মাত্রাকে চারটায় ঢোকাতে গেলে অন্তত তিনটা দিক চাপা পড়বেই। Matrix-টা কেমন, কোথা থেকে এলো — কিছুই না জেনে উত্তর দিয়ে দিলাম। এটাই theorem-এর শক্তি: সে সম্ভব-অসম্ভবের সীমানা টেনে দেয়।
৮. Problems ও Solutions¶
Problem 1. \(A = \begin{pmatrix} 1 & 3 \\ 2 & 6 \end{pmatrix}\)-এর kernel ও range-এর basis বের করো এবং ছবিটা বর্ণনা করো (\(R^2\)-এর কি হাল হয়?)।
Solution
Kernel: \(x + 3y = 0\) (দ্বিতীয় সমীকরণ প্রথমটার দ্বিগুণ — নতুন তথ্য নেই): \(x = -3y\), basis \(\{(-3, 1)\}\), nullity \(= 1\)। Range: column-রা \((1,2)\) ও \((3,6) = 3(1,2)\) — dependent; basis \(\{(1, 2)\}\), rank \(= 1\)। ছবি: পুরো plane চুপসে \((1,2)\)-দিকের এক line হয়ে যায়; \((-3,1)\)-দিকের প্রতিটা line-এর সবাই এক-এক বিন্দুতে গাদাগাদি করে নামে (kernel-এর সমান্তরাল "fiber")। হিসাব: \(1 + 1 = 2\) ✓
Problem 2. প্রমাণ করো: \(\operatorname{ran} L\) সত্যিই subspace (Property 2-এর পূর্ণ প্রমাণ — zero, addition, scaling তিনটাই দেখাও)।
Solution
Zero: \(L(0_V) = L(0 \cdot 0_V) = 0 \cdot L(0_V) = 0_W\) — কাজেই \(0_W \in \operatorname{ran} L\) ✓ Addition: \(w_1 = L(v_1)\), \(w_2 = L(v_2)\) হলে \(w_1 + w_2 = L(v_1 + v_2)\) — এটাও একটা image, তাই range-এ ✓ Scaling: \(c\,w_1 = c\,L(v_1) = L(c\,v_1) \in \operatorname{ran} L\) ✓ তিন ধাপই আসলে এক কথার রূপ: linearity output-দের জগৎকেও বদ্ধ ঘর বানিয়ে দেয়। (Chapter 4.1-এর ভাষায়: range হলো \(L(V)\) — subspace-এর image subspace।)
Problem 3. \(L : P_2 \to P_2\), \(L(p) = p'\) (derivative)। Kernel, range, rank, nullity বের করো এবং rank–nullity মিলিয়ে দেখাও।
Solution
Kernel: \(p' = 0\) মানে \(p\) constant — \(\ker L = \operatorname{span}\{1\}\), nullity \(= 1\)। (Calculus-এর "constant of integration" আসলে একটা kernel-এর গল্প!) Range: \(L(a_0 + a_1 t + a_2 t^2) = a_1 + 2a_2 t\) — সব ডিগ্রি-\(\le 1\) polynomial পাওয়া যায়: \(\operatorname{ran} L = P_1 \subset P_2\), basis \(\{1, t\}\), rank \(= 2\)। হিসাব: \(\dim P_2 = 3 = 1 + 2\) ✓ লক্ষ করো: \(L\) one-to-one নয় (\(1\) আর \(1 + 5\)-এর derivative একই) এবং onto-ও নয় (\(t^2\) কারো derivative হতে হলে \(\frac{t^3}{3} \in P_2\) লাগত)। Arrow ছাড়া জগতেও kernel-range দিব্যি কাজ করে — Part IV-এর প্রতিশ্রুতি।
Problem 4. \(A = \begin{pmatrix} 1 & 0 & 2 & 0 & 1 \\ 0 & 1 & 1 & 0 & 1 \\ 1 & 1 & 3 & 0 & 2 \end{pmatrix}\)-এর rank, nullity, ও kernel-এর basis বের করো।
Solution
RREF: \(R_3 \to R_3 - R_1 - R_2\) দিলে তৃতীয় সারি শূন্য:
Pivot: column ১, ২ \(\Rightarrow\) rank \(= 2\); free: \(x_3, x_4, x_5\) \(\Rightarrow\) nullity \(= 3\) (\(2 + 3 = 5\) ✓)। Kernel-basis (free variable-প্রতি একজন): \(x_1 = -2x_3 - x_5\), \(x_2 = -x_3 - x_5\):
(\(x_4\)-এর column পুরো শূন্য ছিল — সে সম্পূর্ণ "অদৃশ্য" input, তাই \(e_4\) নির্ভেজাল kernel-সদস্য।)
Problem 5. সত্য/মিথ্যা (যুক্তিসহ): (ক) "\(5 \times 3\) matrix-এর rank \(4\) হতে পারে।" (খ) "\(3 \times 5\) matrix কখনো one-to-one হতে পারে না।" (গ) "\(L : V \to V\)-তে (\(\dim V\) সসীম) one-to-one হলেই onto।"
Solution
(ক) মিথ্যা। Rank \(\le \min(m, n) = 3\) — range-এর basis column থেকে আসে, column-ই তো ৩টা। (Row-দিক দিয়েও আটকায়: row rank = column rank।) (খ) সত্য। \(n = 5\), rank \(\le 3\), তাই nullity \(= 5 - \text{rank} \ge 2 > 0\) — kernel-এ শূন্য ছাড়াও কেউ আছেই; Property 3 মতে one-to-one অসম্ভব। চওড়া matrix (columns > rows) সবসময় তথ্য হারায়। (গ) সত্য। one-to-one \(\Rightarrow\) nullity \(= 0\) \(\Rightarrow\) rank \(= \dim V\) \(\Rightarrow\) range হলো \(V\)-এরই সম-dimension subspace \(\Rightarrow\) range \(= V\) (Chapter 4.4, Problem 3(গ)) — onto ✓। একই যুক্তি উল্টো দিকেও চলে: onto \(\Rightarrow\) one-to-one। Square-এর জগতে এক-এক আর সর্বগামী একসাথে আসে-যায় — Part III-এর "invertible matrix theorem"-এর গভীর কারণটা এই।
Problem 6. \(L : R^n \to R^m\) আর \(M : R^m \to R^k\) দুটো linear map। প্রমাণ করো: \(\operatorname{rank}(M \circ L) \le \min(\operatorname{rank} M, \operatorname{rank} L)\)।
Solution
\(\le \operatorname{rank} L\): \(M \circ L\)-এর range \(= M(\operatorname{ran} L)\) — মানে \(M\)-কে শুধু \(\operatorname{ran} L\) subspace-এর ওপর চালানো। Linear map dimension বাড়াতে পারে না (rank–nullity সেই subspace-এ খাটাও: image-এর dim \(\le\) input-এর dim), তাই \(\dim M(\operatorname{ran} L) \le \operatorname{rank} L\) ✓ \(\le \operatorname{rank} M\): \(M(\operatorname{ran} L) \subseteq M(R^m) = \operatorname{ran} M\), আর subspace-এর dimension বড়টার চেয়ে বেশি নয় (Chapter 4.4, Property 3) ✓ মানে: ধাপে ধাপে map চালালে rank শুধু কমতে পারে, বাড়ে না — হারানো তথ্য পরের ধাপে ফেরত আসে না। Deep network-এ bottleneck layer-এর পরে যত বড় layer-ই দাও, rank আর \(32\) ছাড়াবে না — ডিজাইনের বাস্তব শিক্ষা।
Problem 7 (challenge). Rank–nullity দিয়ে প্রমাণ করো: \(n\)টা অজানা, \(m\)টা সমীকরণের homogeneous system \(Ax = 0\)-তে যদি \(m < n\) হয় (সমীকরণ কম, অজানা বেশি), তবে অশূন্য solution থাকবেই।
Solution
\(A\) হলো \(m \times n\) — একটা map \(R^n \to R^m\)। Range বাস করে \(R^m\)-এ, তাই \(\operatorname{rank} A \le m < n\)। Rank–nullity:
Kernel-এর dimension অন্তত \(1\) — মানে শূন্য ছাড়াও সদস্য আছে, আর তারা প্রত্যেকে \(Ax = 0\)-এর অশূন্য solution। \(\blacksquare\) Part II-তে এটা RREF-এর ছবি দেখে মেনে নিয়েছিলে ("free variable থাকবেই") — আজ সেটা theorem থেকে অনিবার্য প্রমাণ হলো। দুই chapter-এর জ্ঞান এক সুতোয়: RREF হলো হিসাবের যন্ত্র, rank–nullity হলো তার পেছনের আইন।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ ঠিক ধারণা |
|---|---|
| "Kernel আর range একই জায়গায় বাস করে" | Kernel \(\subseteq V\) (input জগৎ), range \(\subseteq W\) (output জগৎ) — \(m \ne n\) হলে গুলানোর সুযোগই নেই, ছবিতে দুই পাশে আঁকো |
| "Range-এর basis হলো RREF-এর pivot column-গুলো" | Pivot column-এর নম্বর RREF থেকে, কিন্তু vector নিতে হবে মূল \(A\) থেকে — row operation column space বদলে দেয়! |
| "rank + nullity \(= m\) (row-সংখ্যা)" | \(= n\) (column-সংখ্যা = input dimension) — ভাগ হচ্ছে input-এর মাত্রা, output-এর নয় |
| "Kernel-এ শুধু \(0\) থাকা এক বিরল কাণ্ড" | এটাই one-to-one হওয়ার সংজ্ঞা-সমান শর্ত — invertible square matrix মানেই \(\ker = \{0\}\); বরং বড় kernel-ই "তথ্য হারানোর" চিহ্ন |
| "Onto না হলে map-টা খারাপ/ভুল" | Onto না হওয়া মানে শুধু codomain-এর সবখানে পৌঁছায় না — projection, embedding সবই দরকারি ও নিখুঁত map; ভালো-খারাপ নয়, কি হারায় কি রাখে সেটাই প্রশ্ন |
১০. এক নজরে¶
| ধারণা | এক লাইনে |
|---|---|
| Kernel (\(\ker L\)) | \(L(v) = 0\) মানা সবাই — "চাপা-পড়া" দিক; \(Ax=0\)-এর solution set; subspace |
| Range (\(\operatorname{ran} L\)) | সম্ভাব্য সব output — column-দের span; subspace |
| Rank / Nullity | \(\dim(\text{range})\) / \(\dim(\text{kernel})\) — বাঁচা আর মরা দিকের সংখ্যা |
| Rank–Nullity | \(\operatorname{rank} + \operatorname{nullity} = n\) — input-মাত্রার নিখুঁত ভাগবাটোয়ারা |
| RREF-রেসিপি | Pivot column (মূল \(A\)-এর) → range-basis; free variable → kernel-basis |
| One-to-one test | \(\ker L = \{0\}\) — একটাই প্রশ্ন: শূন্যে কে কে যায়? |
| চার subspace | Row space \(\oplus\) kernel \(= R^n\); range \(\oplus\) left null space \(= R^m\) |
পরের chapter-এর সেতু: এই chapter-এ map আর matrix শব্দদুটো প্রায় সমার্থক ব্যবহার করেছি — কিন্তু ঠিক কোন নিয়মে একটা abstract linear map একটা সংখ্যার টেবিল (matrix) হয়ে যায়? আর Chapter 4.4-এর চশমা বদলালে সেই টেবিলের কি হয়? Abstract আর concrete-এর সেই শেষ সেতুটা — linear map-এর matrix — Chapter 4.6-এ, Part IV-এর সমাপ্তিতে।
📓 Notebook Project¶
notebooks/part-04/ch05-project.ipynb — scratch-এ RREF দিয়ে kernel ও range-এর basis-বের-করা function বানাবে, random matrix-এ rank–nullity-র stress-test চালাবে, আর rank-1 matrix-এর "plane চুপসে line" হওয়ার ছবি নিজে আঁকবে।