Chapter 7.5 — Markov Matrices & Matrix Exponential (মার্কভ ম্যাট্রিক্স ও ম্যাট্রিক্স এক্সপোনেনশিয়াল)¶
Chapter 7.4-এ PageRank-এ চোখে পড়েছিল একটা বিশেষ matrix — Google matrix \(G\)-র প্রতিটা column-এর যোগফল ঠিক \(1\), আর power iteration \(r \leftarrow Gr\) একটা steady-state-এ থামে। সেই "column sum \(1\)" matrix-এর নাম Markov Matrix(মার্কভ ম্যাট্রিক্স), আর তার steady-state এক গভীর ও সুন্দর গল্প। আজ Part VII শেষ করবো দুই ধারণায়: (১) Markov chain — সম্ভাবনার বিবর্তন কীভাবে সবসময় একটা স্থির ভারসাম্যে পৌঁছায় (কালকের আবহাওয়া কেন আজকেরটা "ভুলে যায়"), আর (২) Matrix Exponential(ম্যাট্রিক্স এক্সপোনেনশিয়াল) \(e^{At}\) — সময়কে অবিচ্ছিন্ন (continuous) করলে discrete step কীভাবে মসৃণ প্রবাহে পরিণত হয়। eigenvalue এখানে চূড়ান্ত নায়ক।
🎯 এই chapter-এ যা শিখবে¶
- Markov Matrix: column sum \(1\), entry \(\geq 0\); probability vector(প্রবাবিলিটি ভেক্টর) ও তার বিবর্তন \(p_{k+1} = Pp_k\)
- Steady State(স্টেডি স্টেট) \(\pi\): \(P\pi = \pi\) — eigenvalue-\(1\) eigenvector; কেন সবসময় থাকে ও কেন সবাই সেখানে পৌঁছায়
- Convergence speed(কনভার্জেন্স স্পিড) = দ্বিতীয় eigenvalue \(|\lambda_2|\): memory কত দ্রুত মরে
- Matrix Exponential \(e^{At} = I + At + \frac{(At)^2}{2!} + \cdots\): continuous-time dynamics \(\dot{x} = Ax\)-এর সমাধান \(x(t) = e^{At}x_0\)
- Continuous vs discrete: eigenvalue-র বাস্তব/কাল্পনিক অংশ কীভাবে decay ও rotation (spiral) ঠিক করে
🖼️ এক ছবিতে মূল idea¶
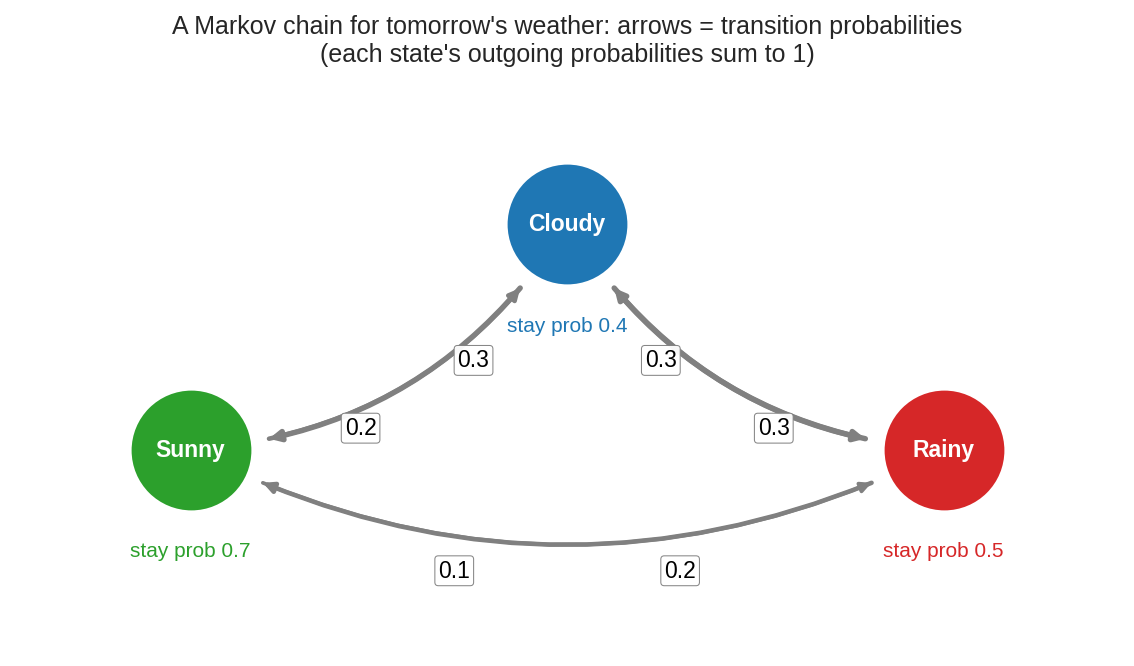
আবহাওয়ার একটা Markov chain — তিন অবস্থা (Sunny, Cloudy, Rainy), তীর = রূপান্তর সম্ভাবনা। প্রতিটা অবস্থা থেকে বেরোনো সব তীরের সম্ভাবনা যোগ করে ঠিক \(1\) (কালকের আবহাওয়া কিছু-না-কিছু হবেই)। "আজ রোদ থাকলে কাল রোদ থাকার সম্ভাবনা \(0.7\)" — এই স্থানীয় নিয়মগুলো থেকেই বেরিয়ে আসে দীর্ঘকালীন জলবায়ু।
১. কি? (What)¶
দৈনন্দিন analogy: আবহাওয়ার অভ্যাস¶
আবহাওয়ার একটা "অভ্যাস" আছে — আজ রোদ থাকলে কাল সাধারণত রোদই থাকে, মাঝে মাঝে মেঘ। এই অভ্যাসটা একটা সম্ভাবনার নিয়ম: "আজকের অবস্থা → কালকের অবস্থার সম্ভাবনা।" মজার ব্যাপার: তুমি আজ যা-ই দেখো না কেন (রোদ বা বৃষ্টি), যথেষ্ট দিন পরে আবহাওয়া তোমার আজকের অবস্থা ভুলে যায় — দীর্ঘকালীন গড় (কত শতাংশ দিন রোদ, কত মেঘ) সবসময় একই দাঁড়ায়। এই "ভুলে যাওয়া" আর "স্থির ভারসাম্য"-ই Markov chain-এর হৃদয়।
সংজ্ঞা: Markov matrix ও probability vector¶
একটা Markov matrix (বা stochastic matrix) \(P\) হলো এমন এক বর্গ matrix যার: 1. প্রতিটা entry \(P_{ij} \geq 0\) (সম্ভাবনা ঋণাত্মক হয় না), 2. প্রতিটা column-এর যোগফল \(1\) (একটা অবস্থা থেকে বেরিয়ে কোথাও-না-কোথাও যেতেই হবে)।
\(P_{ij}\) = "অবস্থা \(j\) থেকে অবস্থা \(i\)-তে যাওয়ার সম্ভাবনা।" একটা probability vector \(p\) হলো এমন vector যার entry \(\geq 0\) এবং যোগফল \(1\) — বর্তমান অবস্থার সম্ভাবনা-বণ্টন। এক ধাপ পরের বণ্টন:
(Markov matrix \(\times\) probability vector = আবার probability vector — যোগফল \(1\) থাকে।)
সংজ্ঞা: steady state¶
যদি বিবর্তন এমন এক বণ্টন \(\pi\)-এ পৌঁছায় যা আর বদলায় না — \(P\pi = \pi\) — তাকে বলে steady state বা stationary distribution। এটাই সেই "দীর্ঘকালীন জলবায়ু।" গণিতে \(\pi\) হলো \(P\)-র eigenvalue-\(1\) eigenvector (যোগফল \(1\)-এ normalized)।
সংজ্ঞা: matrix exponential¶
Discrete step (\(k = 0, 1, 2, \dots\))-এর বদলে যদি সময় অবিচ্ছিন্ন হয় (\(t \in \mathbb{R}\)), dynamics লেখা হয় differential equation-এ: \(\dot{x}(t) = Ax(t)\)। এর সমাধান জড়িত matrix exponential:
সাধারণ \(e^x\)-এর Taylor series-এর মতোই, শুধু \(x\)-এর জায়গায় matrix \(At\)। এটা discrete power \(P^k\)-এর অবিচ্ছিন্ন যমজ।
২. দেখতে কেমন?¶
দৃশ্য ১: যা-ই শুরু, শেষে একই ভারসাম্য¶
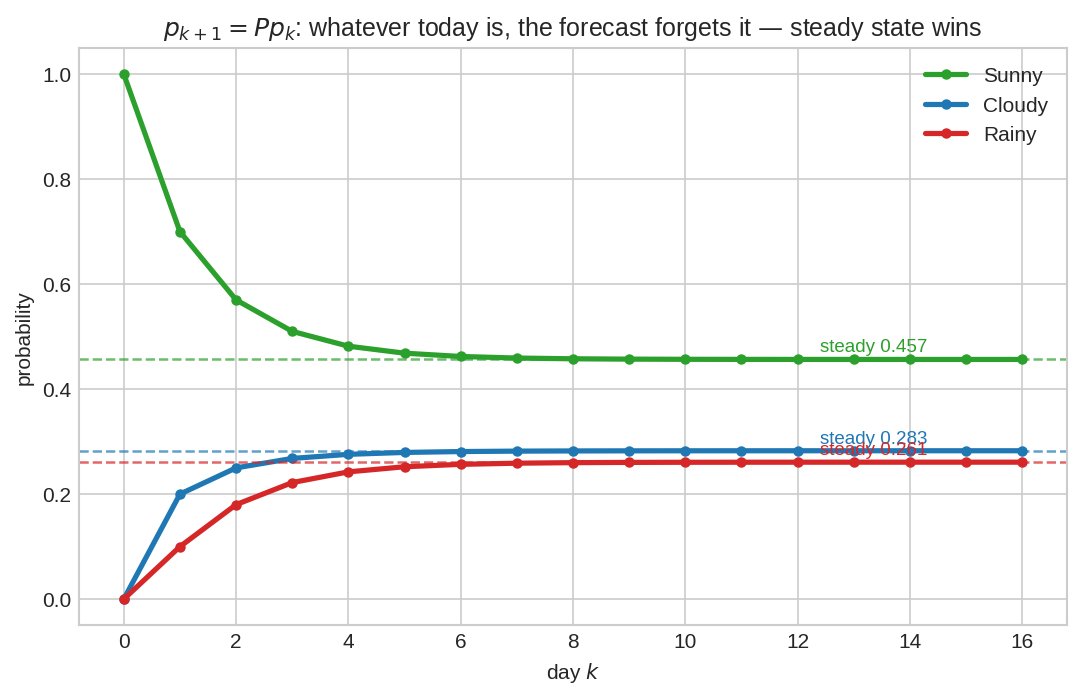
শুরু: "আজ নিশ্চিত রোদ" (\(p_0 = (1,0,0)\))। প্রতিদিন \(p_{k+1} = Pp_k\) চালালে তিন অবস্থার সম্ভাবনা তিনটা রেখা ধরে এগোয় — কয়েক দিনেই ড্যাশ-লাইনে (steady state) স্থির। যেখানেই শুরু করো (নিশ্চিত বৃষ্টি হলেও একই জায়গায় পৌঁছাতো), forecast আজকের অবস্থা ভুলে গিয়ে একই জলবায়ুতে বসে। এই "প্রাথমিক অবস্থা ভুলে যাওয়া"-ই Markov chain-এর সিগনেচার।
দৃশ্য ২: memory কত দ্রুত মরে — দ্বিতীয় eigenvalue¶
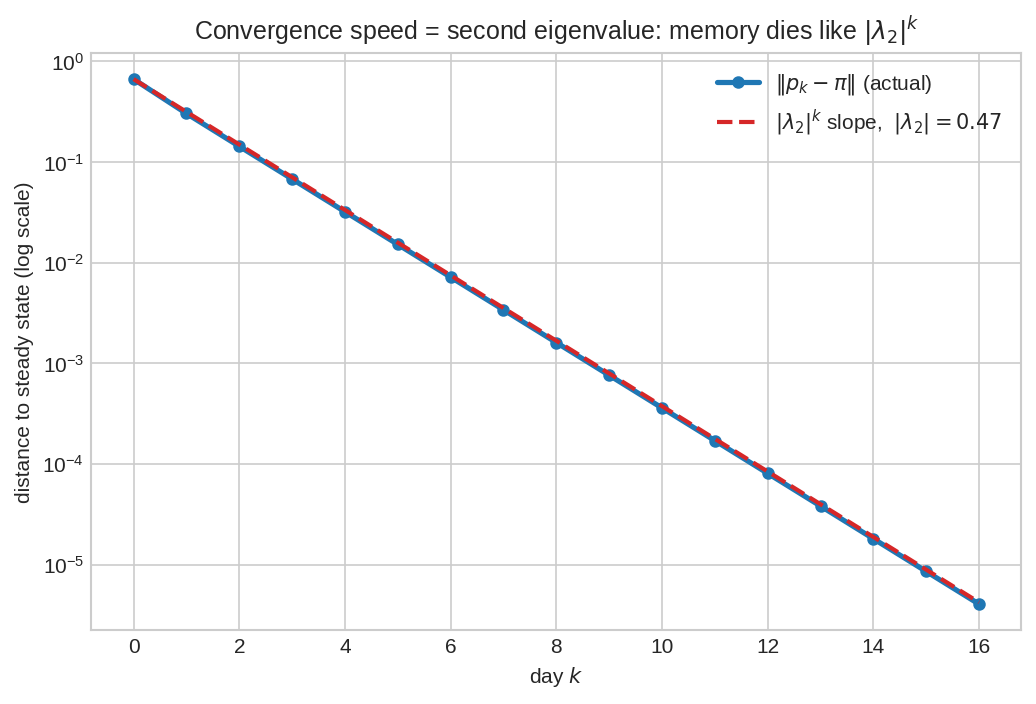
Steady state থেকে দূরত্ব \(\|p_k - \pi\|\) (log-scale)। নীল = আসল দূরত্ব, লাল ড্যাশ = \(|\lambda_2|^k\)-এর ঢাল। দুটো প্রায় সমান্তরাল — মানে প্রাথমিক অবস্থার স্মৃতি ঠিক দ্বিতীয় বৃহত্তম eigenvalue \(|\lambda_2|\)-এর হারে মরে। \(|\lambda_2|\) ছোট হলে দ্রুত ভুলে যায় (দ্রুত mixing), \(1\)-এর কাছে হলে ধীরে। convergence-এর গতি এক সংখ্যায় বন্দি।
দৃশ্য ৩: Markov matrix-এর power সবাই একই দিকে ছোটে¶
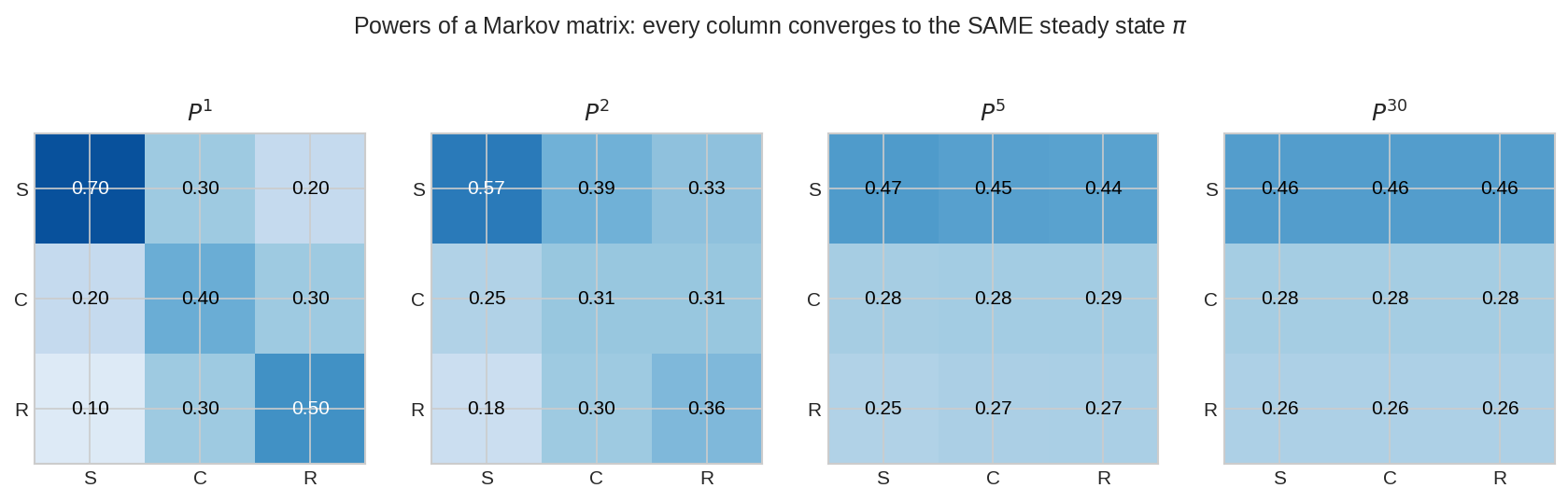
\(P, P^2, P^5, P^{30}\)-এর heatmap। খেয়াল করো — power বাড়ালে প্রতিটা column একই হয়ে যায় (সব column = steady state \(\pi\))। মানে ৩০ দিন পর "কোথা থেকে শুরু করেছিলে" আর কোনো তথ্য দেয় না — প্রতিটা শুরু-অবস্থা একই দীর্ঘকালীন বণ্টনে মেশে। \(P^\infty\) = সব-column-\(\pi\) matrix।
দৃশ্য ৪: matrix exponential — decay + rotation = spiral¶
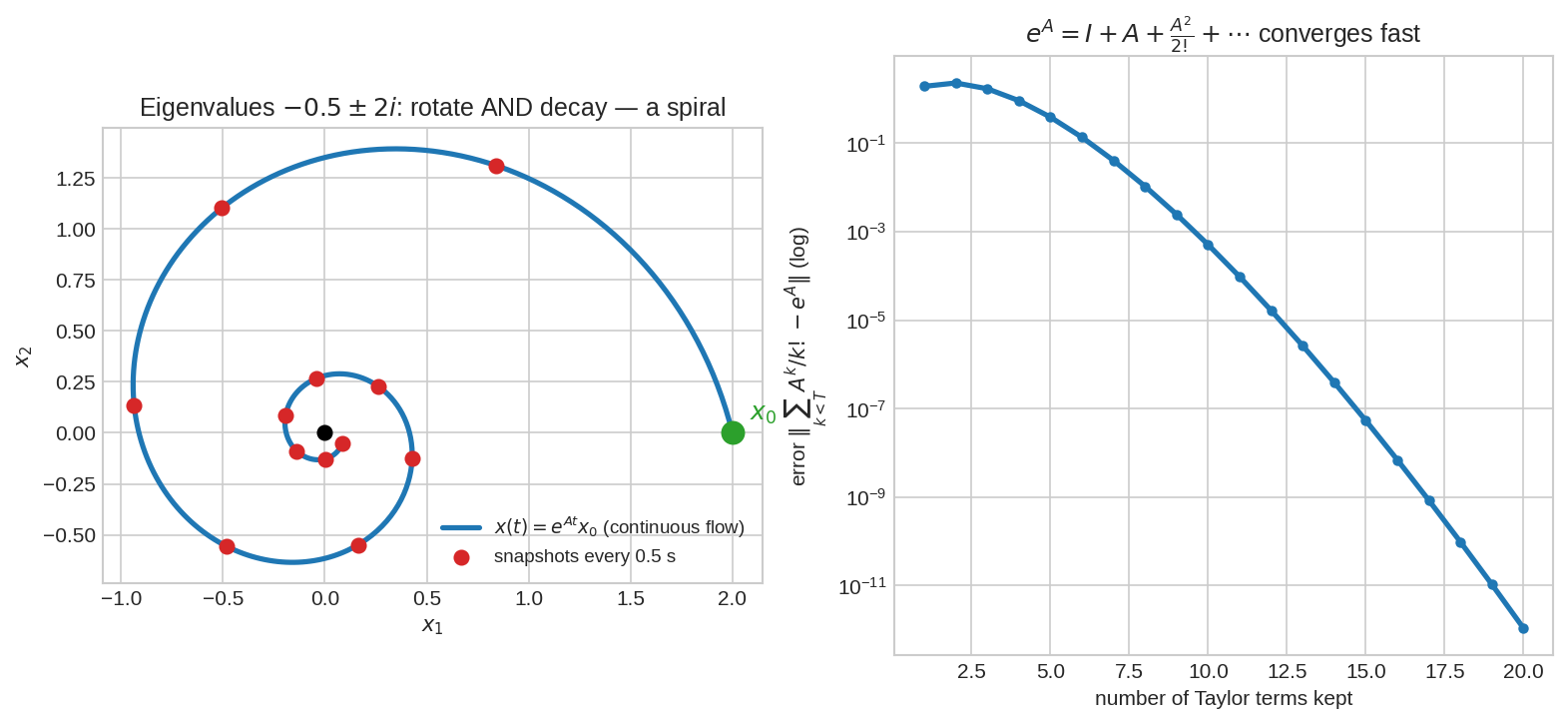
বাঁয়ে: continuous-time dynamics \(\dot{x} = Ax\)-এর গতিপথ \(x(t) = e^{At}x_0\), যেখানে \(A\)-র eigenvalue \(-0.5 \pm 2i\)। কাল্পনিক অংশ (\(\pm 2i\)) ঘোরায় (rotation), বাস্তব অংশ (\(-0.5\)) সংকুচিত করে (decay) — মিলে একটা spiral origin-এর দিকে। লাল বিন্দু = প্রতি \(0.5\) সেকেন্ডে snapshot। ডানে: Taylor series কত দ্রুত converge করে — মাত্র ১৫-২০ term-এই নিখুঁত।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- আবহাওয়া/জলবায়ু মডেল: আজকের অবস্থা থেকে কালকের পূর্বাভাস, আর দীর্ঘকালীন জলবায়ু-গড় (fig01–02)।
- সারি ও নির্ভরযোগ্যতা (queuing/reliability): call center-এ কত লোক অপেক্ষায়, মেশিন কখন সচল/বিকল — অবস্থার মধ্যে random রূপান্তর।
- জনসংখ্যা/অর্থনীতি: শহর-গ্রামে মানুষের স্থানান্তর, আয়-শ্রেণির মধ্যে চলাচল — সবই Markov।
- পদার্থবিজ্ঞান/রসায়ন: radioactive decay, রাসায়নিক বিক্রিয়ার হার — continuous-time \(\dot{x} = Ax\), সমাধান \(e^{At}\)।
Data Science / ML-এ:
- PageRank (Ch 7.4): Google matrix একটা Markov matrix, ranking তার steady state।
- Hidden Markov Models (HMM): বাক-শনাক্তকরণ, জিন-অনুক্রম, সময়-সিরিজ — লুকানো Markov chain।
- Reinforcement Learning: Markov Decision Process (MDP) হলো RL-এর গাণিতিক ভিত্তি; state transition ঠিক এই Markov matrix।
- MCMC (Markov Chain Monte Carlo): আধুনিক Bayesian statistics-এর ইঞ্জিন — এমন Markov chain বানানো যার steady state ঠিক কাঙ্ক্ষিত distribution।
- Neural ODEs & continuous models: matrix exponential ও তার সাধারণীকরণ আধুনিক deep learning-এর continuous-depth model-এ।
৪. Properties¶
Property 1 — Markov matrix-এর সবসময় eigenvalue \(1\)¶
Column sum \(1\) মানে \(\mathbf{1}^TP = \mathbf{1}^T\) (প্রতি column যোগ করলে \(1\))। মানে \(\mathbf{1}\) হলো \(P^T\)-র eigenvector eigenvalue \(1\) নিয়ে। কিন্তু \(P\) আর \(P^T\)-র eigenvalue একই (transpose eigenvalue বদলায় না)। তাই \(P\)-রও eigenvalue \(1\) আছে — এবং তার (ডান) eigenvector \(P\pi = \pi\)-ই steady state। steady state সবসময় থাকে, প্রতিটা Markov matrix-এই।
Property 2 — সব eigenvalue \(|\lambda| \leq 1\)¶
Markov matrix কোনো probability vector-এর যোগফল বাড়ায় না (column sum \(1\))। এর ফল: কোনো eigenvalue-ই \(1\)-এর চেয়ে বড় modulus রাখতে পারে না — \(|\lambda_i| \leq 1\) সবার জন্য। তাই বারবার \(P\) দিয়ে গুণলে কিছুই বিস্ফোরিত হয় না; eigenvalue-\(1\) দিক টিকে থাকে, বাকি সব (\(|\lambda| < 1\)) ম্লান হয় — এজন্যই steady state-এ পৌঁছায় (Property 3)।
Property 3 — power iteration steady state-এ পৌঁছায়¶
\(p_k = P^k p_0\)। \(p_0\)-কে eigenvector-দের যোগফলে লিখলে, প্রতিবার \(P\) গুণে প্রতিটা component তার \(\lambda\) দিয়ে গুণিত হয়। eigenvalue-\(1\) component অপরিবর্তিত থাকে (steady state), আর সব \(|\lambda| < 1\) component \(\lambda^k \to 0\)-তে মরে যায়। তাই:
শুরু-অবস্থা নির্বিশেষে (যদি \(P\) "regular" — কিছু power-এ সব entry ধনাত্মক)। fig02-এর সব রেখা এক জায়গায় মেলা এরই ছবি।
Property 4 — convergence-গতি = দ্বিতীয় eigenvalue¶
সবচেয়ে ধীরে-মরা component-এর হার ঠিক করে দ্বিতীয় বৃহত্তম \(|\lambda_2|\)। তাই steady state থেকে দূরত্ব প্রায় \(|\lambda_2|^k\) হারে কমে:
\(|\lambda_2|\) যত ছোট, তত দ্রুত mixing (স্মৃতি-ক্ষয়)। \(|\lambda_2| \to 1\) হলে ভয়ংকর ধীর। fig03-এর সমান্তরাল দুই রেখা এটাই দেখায়। §৬-এর কোডে \(|\lambda_2| = 0.47\) — প্রতি দিনে দূরত্ব প্রায় অর্ধেক।
Property 5 — matrix exponential-এর মূল ধর্ম¶
- \(e^{A\cdot 0} = I\) (শুরু বিন্দু)।
- \(\frac{d}{dt}e^{At} = Ae^{At}\) — তাই \(x(t) = e^{At}x_0\) সত্যিই \(\dot{x} = Ax\)-এর সমাধান।
- eigenvalue-র রূপান্তর: \(A\)-র eigenvalue \(\lambda\) হলে \(e^{At}\)-র eigenvalue \(e^{\lambda t}\) (eigenvector একই)। সব গল্প eigenvalue-তে।
Property 6 — eigenvalue continuous vs discrete-এ দুই ভাষা¶
| Discrete (\(x_{k+1} = Ax_k\)) | Continuous (\(\dot{x} = Ax\)) | |
|---|---|---|
| স্থিতিশীল (decay) | \(\vert \lambda\vert < 1\) | \(\text{Re}(\lambda) < 0\) |
| ভারসাম্য (স্থির) | \(\vert \lambda\vert = 1\) | \(\text{Re}(\lambda) = 0\) |
| বিস্ফোরণ | \(\vert \lambda\vert > 1\) | \(\text{Re}(\lambda) > 0\) |
| ঘূর্ণন (rotation) | complex \(\lambda\) | কাল্পনিক অংশ \(\text{Im}(\lambda)\) |
fig05-এ \(\lambda = -0.5 \pm 2i\): বাস্তব অংশ \(-0.5 < 0\) → decay; কাল্পনিক অংশ \(\pm 2\) → rotation; মিলে spiral।
৫. Intuition — কেন সত্য?¶
কেন steady state সবসময় থাকে¶
একটা "মেশানো" নিয়ম (Markov matrix) probability ছড়িয়ে দেয় — কোনো অবস্থায় বেশি জমলে সেখান থেকে বেরোয়, কম থাকলে ঢোকে। এই push-pull একটা ভারসাম্যে থামতে বাধ্য: যেখানে "যত ঢুকছে তত বেরোচ্ছে" প্রতিটা অবস্থায়। সেই ভারসাম্যই \(P\pi = \pi\) — steady state। গণিতে column sum \(1\) (Property 1) নিশ্চিত করে এমন একটা \(\pi\) সবসময় আছে। প্রকৃতির "গড়ে ফিরে আসা" প্রবণতারই এটা রৈখিক-বীজগণিতীয় রূপ।
কেন প্রাথমিক অবস্থা "ভুলে যায়"¶
যেকোনো শুরু \(p_0\)-কে ভাবো: \(p_0 = \pi + (\text{বাকিটা})\)। বাকি অংশটা eigenvalue-\(1\) ছাড়া অন্য eigenvector-দের নিয়ে গড়া (\(|\lambda| < 1\))। প্রতিবার \(P\) গুণে এই বাকি অংশ \(\lambda^k\) দিয়ে সংকুচিত হয়ে \(0\)-তে মেলায়, শুধু \(\pi\) টিকে থাকে। তাই "কোথা থেকে এলে" (বাকি অংশ) মুছে যায়, "কোথায় যাবে" (\(\pi\)) থাকে। fig04-এর সব column একই হওয়া এরই দৃশ্য — \(P^{30}\) শুরুর তথ্য পুরো হারিয়েছে।
কেন \(|\lambda_2|\) গতি ঠিক করে¶
steady state-এ পৌঁছানোর গতি নির্ভর করে "সবচেয়ে একগুঁয়ে" অ-ভারসাম্য উপাদানের ওপর — যেটা সবচেয়ে ধীরে মরে, অর্থাৎ যার \(|\lambda|\) সবচেয়ে বড় (কিন্তু \(<1\))। সেটাই \(|\lambda_2|\)। বাকি ছোট eigenvalue-গুলোর component আগেই উবে যায়, তাই দীর্ঘমেয়াদে দূরত্ব \(|\lambda_2|^k\)-এর মতো আচরণ করে। "শৃঙ্খলের গতি তার সবচেয়ে ধীর কড়ি দিয়ে মাপা" — এখানে সেই ধীর কড়ি \(\lambda_2\)।
কেন \(e^{At}\) discrete-এর অবিচ্ছিন্ন যমজ¶
Discrete-এ এক ধাপ = \(\times A\), তাই \(k\) ধাপ = \(\times A^k\)। Continuous-এ "এক muhূর্ত" মানে অসীম-ছোট ধাপ — সেগুলো একত্রিত (integrate) করলে discrete power-এর সীমা: \(e^{At} = \lim_{n\to\infty}(I + \frac{At}{n})^n\) (ঠিক \(e^x = \lim(1+x/n)^n\)-এর matrix রূপ)। তাই \(e^{At}\) হলো "অসীম-ছোট Markov step"-দের গুণফল। eigenvalue-র ভাষায়: discrete-এ \(\lambda^k\), continuous-এ \(e^{\lambda t}\) — একই decay/rotation, শুধু মসৃণ। Property 6-এর দুই কলাম আসলে এক গল্পের দুই উপভাষা।
spiral-এর জ্যামিতি (fig05)¶
Complex eigenvalue \(a \pm bi\)-কে ভাঙো: \(e^{(a+bi)t} = e^{at}\cdot e^{ibt} = e^{at}(\cos bt + i\sin bt)\)। \(e^{at}\) অংশ ব্যাসার্ধ বদলায় (ব্যাসার্ধ \(a<0\)-তে সংকুচিত), \(e^{ibt}\) অংশ কোণ ঘোরায় (কম্পাঙ্ক \(b\))। ব্যাসার্ধ কমছে + কোণ ঘুরছে = spiral। বাস্তব অংশ = "কত দ্রুত ভেতরে/বাইরে", কাল্পনিক অংশ = "কত দ্রুত ঘোরে"। এক complex সংখ্যায় গোটা গতির চরিত্র।
৬. Code-এ কেমনে লিখে¶
import numpy as np
# ============ Part A: Markov chain (weather) ============
# states: Sunny, Cloudy, Rainy; columns sum to 1
P = np.array([[0.7, 0.3, 0.2],
[0.2, 0.4, 0.3],
[0.1, 0.3, 0.5]])
print("column sums:", P.sum(axis=0)) # সব 1
# steady state = eigenvalue-1 eigenvector
w, V = np.linalg.eig(P)
print("eigenvalues:", np.round(w, 3))
i1 = np.argmin(np.abs(w - 1.0))
pi = np.real(V[:, i1]); pi = pi / pi.sum()
print("steady state pi:", pi.round(4))
print("check P@pi == pi:", np.allclose(P @ pi, pi))
# evolve from 'certainly sunny' — memory fades
p = np.array([1.0, 0, 0])
for k in [1, 2, 5, 10, 30]:
pk = np.linalg.matrix_power(P, k) @ np.array([1.0, 0, 0])
print(f"day {k:2d}: {pk.round(4)}")
lam2 = np.sort(np.abs(w))[-2]
print("|lambda_2| (mixing rate):", round(lam2, 4))
# ============ Part B: matrix exponential ============
def expm_taylor(M, terms=60):
E = np.eye(M.shape[0]); term = np.eye(M.shape[0])
for k in range(1, terms):
term = term @ M / k # term = M^k / k!
E = E + term
return E
A = np.array([[-0.5, -2.0], # eigenvalues -0.5 ± 2i
[ 2.0, -0.5]])
print("\nA eigenvalues:", np.round(np.linalg.eigvals(A), 3))
x0 = np.array([2.0, 0.0])
for t in [0, 1, 2, 3]:
xt = expm_taylor(A * t) @ x0
print(f"t={t}: x(t)={xt.round(3)} ||x||={np.linalg.norm(xt):.3f}")
Output ব্যাখ্যা:
- Column sums সব
1.0— বৈধ Markov matrix। - Eigenvalues
[1.0, 0.473, 0.127]— ঠিক একটা \(1\) (Property 1, steady state আছে), বাকি দুটো \(<1\) (Property 2)। - steady state
pi ≈ [0.4565, 0.2826, 0.2609]— দীর্ঘকালীনে ~\(46\%\) দিন রোদ, ~\(28\%\) মেঘ, ~\(26\%\) বৃষ্টি।P@pi == piসত্য, তাই এটা সত্যিই stationary। - Memory fades: day 1-এ \((0.7, 0.2, 0.1)\) (আজকের রোদের ছাপ প্রবল), কিন্তু day 30-এ \((0.4565, 0.2826, 0.2609)\) — হুবহু \(\pi\)। শুরুর "নিশ্চিত রোদ" পুরো ভুলে গেছে (Property 3)।
- \(|\lambda_2| = 0.4732\) — প্রতি দিনে steady state থেকে দূরত্ব প্রায় \(0.47\) গুণ হয়, তাই ~১০ দিনেই কার্যত মিলে যায় (Property 4)।
- Matrix exponential: \(A\)-র eigenvalue
-0.5 ± 2j(Property 6: বাস্তব অংশ ঋণাত্মক → decay; কাল্পনিক → rotation)। \(t\) বাড়লে \(\|x\|\) কমছে (\(2.0 \to 1.21 \to 0.74 \to 0.45\)) কিন্তু দিক ঘুরছে — spiral (fig05)।
৭. Worked Examples¶
Example 1 — \(2\times 2\) Markov chain-এর steady state¶
\(P = \begin{bmatrix} 0.8 & 0.3 \\ 0.2 & 0.7\end{bmatrix}\) (column sum \(1\) ✓)। steady state \(\pi\) বের করো।
ধাপ ১ — \(P\pi = \pi\) লেখো (\(\pi = (\pi_1, \pi_2)\)): \(0.8\pi_1 + 0.3\pi_2 = \pi_1\) ও \(0.2\pi_1 + 0.7\pi_2 = \pi_2\)।
ধাপ ২ — সরল করো: প্রথমটা: \(0.3\pi_2 = 0.2\pi_1 \Rightarrow \pi_1 = 1.5\pi_2\)।
ধাপ ৩ — normalize: \(\pi_1 + \pi_2 = 1 \Rightarrow 1.5\pi_2 + \pi_2 = 1 \Rightarrow \pi_2 = 0.4\), \(\pi_1 = 0.6\)।
\(\pi = (0.6, 0.4)\)। যাচাই: \(P\pi = (0.8\cdot 0.6 + 0.3\cdot 0.4,\; 0.2\cdot 0.6 + 0.7\cdot 0.4) = (0.6, 0.4) = \pi\) ✓। দীর্ঘকালীনে \(60\%\) সময় অবস্থা ১-এ।
Example 2 — power দিয়ে steady state যাচাই¶
Example 1-এর \(P\)-তে শুরু \(p_0 = (1, 0)\) (নিশ্চিত অবস্থা ১)।
- \(p_1 = Pp_0 = (0.8, 0.2)\)।
- \(p_2 = Pp_1 = (0.8\cdot 0.8 + 0.3\cdot 0.2,\; 0.2\cdot 0.8 + 0.7\cdot 0.2) = (0.70, 0.30)\)।
- \(p_3 = Pp_2 = (0.65, 0.35)\)।
- ... একঘেয়েভাবে \((0.6, 0.4)\)-এর দিকে।
দ্বিতীয় eigenvalue: \(\lambda_1 = 1\), আর \(\text{trace} = 0.8 + 0.7 = 1.5 = \lambda_1 + \lambda_2 \Rightarrow \lambda_2 = 0.5\)। তাই প্রতি ধাপে \(\pi\) থেকে দূরত্ব প্রায় অর্ধেক — day 1-এ দূরত্ব \(|0.8 - 0.6| = 0.2\), day 2-এ \(0.1\), day 3-এ \(0.05\) — ঠিক \(0.5^k\) (Property 4 সংখ্যায়)।
Example 3 — matrix exponential eigenvalue দিয়ে¶
\(A = \begin{bmatrix} -1 & 0 \\ 0 & -3\end{bmatrix}\) (diagonal, তাই সহজ)। \(x_0 = (2, 1)\)-এ \(x(t) = e^{At}x_0\) বের করো।
Diagonal matrix-এর exponential = প্রতি entry-র exponential (Property 5): \(e^{At} = \begin{bmatrix} e^{-t} & 0 \\ 0 & e^{-3t}\end{bmatrix}\)।
দুই eigenvalue \(-1, -3\) দুই বাস্তব ঋণাত্মক (Property 6: decay, ঘূর্ণন নেই)। \(x_2\) (eigenvalue \(-3\)) দ্রুত মরে, \(x_1\) (eigenvalue \(-1\)) ধীরে — দুটোই \(\to 0\), origin স্থিতিশীল। কোনো spiral নেই কারণ eigenvalue বাস্তব; সোজা origin-এর দিকে ধাবমান।
৮. Problems ও Solutions¶
Problem 1. \(P = \begin{bmatrix} 0.9 & 0.5 \\ 0.1 & 0.5\end{bmatrix}\)। (a) বৈধ Markov matrix কিনা যাচাই করো। (b) steady state \(\pi\) বের করো। (c) \(\lambda_2\) কত, আর convergence কত দ্রুত?
Solution
(a) entry সব \(\geq 0\); column sum: \(0.9 + 0.1 = 1\), \(0.5 + 0.5 = 1\) ✓ — বৈধ।
(b) \(P\pi = \pi\): \(0.9\pi_1 + 0.5\pi_2 = \pi_1 \Rightarrow 0.5\pi_2 = 0.1\pi_1 \Rightarrow \pi_1 = 5\pi_2\)। normalize: \(5\pi_2 + \pi_2 = 1 \Rightarrow \pi_2 = 1/6, \pi_1 = 5/6\)।
(c) trace \(= 0.9 + 0.5 = 1.4 = 1 + \lambda_2 \Rightarrow \lambda_2 = 0.4\)। প্রতি ধাপে দূরত্ব \(\times 0.4\) — বেশ দ্রুত (আরও কম \(|\lambda_2|\) মানে আরও দ্রুত mixing)।
Problem 2. Markov matrix-এর সবসময় eigenvalue \(1\) থাকে প্রমাণ করো (Property 1)।
Solution
Column sum \(1\) মানে প্রতিটা column-এর entry যোগ করলে \(1\), অর্থাৎ all-ones row-vector দিয়ে বাঁ থেকে গুণলে:
(কারণ \((\mathbf{1}^TP)_j = \sum_i P_{ij} =\) column \(j\)-র যোগফল \(= 1 = (\mathbf{1}^T)_j\)।)
এটা বলছে \(\mathbf{1}\) হলো \(P^T\)-র eigenvector, eigenvalue \(1\): \(P^T\mathbf{1} = \mathbf{1}\)। এখন মূল সত্য: \(P\) ও \(P^T\)-র eigenvalue হুবহু একই (কারণ \(\det(P - \lambda I) = \det((P-\lambda I)^T) = \det(P^T - \lambda I)\) — transpose determinant বদলায় না)। তাই \(P\)-রও eigenvalue \(1\) আছে, আর তার ডান-eigenvector \(\pi\) (\(P\pi = \pi\))-ই steady state ∎।
(লক্ষ্য: বাঁ-eigenvector \(\mathbf{1}\) সহজ, কিন্তু steady state হলো ডান-eigenvector \(\pi\) — দুটো আলাদা, শুধু eigenvalue এক।)
Problem 3. \(P = \begin{bmatrix} 0.5 & 0.5 & 0 \\ 0.5 & 0 & 1 \\ 0 & 0.5 & 0\end{bmatrix}\)। column sum যাচাই করে steady state বের করো (linear system solve)।
Solution
Column sums: \(0.5+0.5+0=1\), \(0.5+0+0.5=1\), \(0+1+0=1\) ✓।
\(P\pi = \pi\) দেয় তিনটা সমীকরণ (একটা redundant): - \(0.5\pi_1 + 0.5\pi_2 = \pi_1 \Rightarrow 0.5\pi_2 = 0.5\pi_1 \Rightarrow \pi_1 = \pi_2\)। - \(0.5\pi_1 + \pi_3 = \pi_2 \Rightarrow \pi_3 = \pi_2 - 0.5\pi_1 = 0.5\pi_1\) (যেহেতু \(\pi_2 = \pi_1\))।
তাই \(\pi = (\pi_1, \pi_1, 0.5\pi_1)\)। normalize: \(\pi_1 + \pi_1 + 0.5\pi_1 = 2.5\pi_1 = 1 \Rightarrow \pi_1 = 0.4\)।
যাচাই: \(P\pi = (0.5\cdot 0.4 + 0.5\cdot 0.4,\; 0.5\cdot 0.4 + 0.2,\; 0.5\cdot 0.4) = (0.4, 0.4, 0.2) = \pi\) ✓।
Problem 4. \(x_0\)-এ শুরু করা Markov chain কেন সবসময় একই \(\pi\)-তে পৌঁছায়, শুরু যা-ই হোক (Property 3)? eigenvector-এর ভাষায় ব্যাখ্যা করো।
Solution
ধরো \(P\)-র eigenvector \(v_1 = \pi\) (eigenvalue \(1\)), \(v_2, v_3, \dots\) (eigenvalue \(\lambda_2, \lambda_3, \dots\), সব \(|\lambda| < 1\))। যেকোনো শুরু \(p_0\)-কে এদের যোগফলে লেখো:
\(k\) ধাপ পরে (প্রতিবার \(P\) গুণে প্রতিটা eigenvector তার \(\lambda\) পায়):
যেহেতু \(|\lambda_j| < 1\) (\(j \geq 2\)), \(\lambda_j^k \to 0\); সব "বাকি" পদ মরে যায়:
আর probability normalization নিশ্চিত করে \(c_1 = 1\), তাই \(p_k \to \pi\) — শুরু \(p_0\) (মানে \(c_2, c_3, \dots\)) নির্বিশেষে ∎। শুধু eigenvalue-\(1\) দিকই বাঁচে; বাকি সব শুরুর তথ্য মুছে যায়।
Problem 5. matrix exponential-এর series ব্যবহার করে দেখাও \(e^{At}\)-র derivative \(Ae^{At}\), তাই \(x(t) = e^{At}x_0\) সত্যিই \(\dot{x} = Ax\) মানে।
Solution
\(e^{At} = I + At + \frac{A^2t^2}{2!} + \frac{A^3t^3}{3!} + \cdots\)। term-by-term \(t\)-এর সাপেক্ষে derivative:
প্রতিটা পদ থেকে একটা \(A\) বাইরে বের করো:
তাই \(\dot{x}(t) = \frac{d}{dt}(e^{At}x_0) = Ae^{At}x_0 = Ax(t)\) ✓, আর \(x(0) = e^{0}x_0 = x_0\) (প্রাথমিক শর্তও মেলে) ∎। সাধারণ \(\frac{d}{dt}e^{at} = ae^{at}\)-এর হুবহু matrix সংস্করণ।
Problem 6. (কোডে) \(3\times 3\) Markov matrix \(P = \begin{bmatrix} 0.6 & 0.1 & 0.3 \\ 0.3 & 0.7 & 0.2 \\ 0.1 & 0.2 & 0.5\end{bmatrix}\)-এর steady state ও \(|\lambda_2|\) বের করো, আর \(p_0 = (0,0,1)\) থেকে কত দিনে steady state-এর \(1\%\)-এর মধ্যে আসে দেখো।
Solution
import numpy as np
P = np.array([[0.6, 0.1, 0.3],
[0.3, 0.7, 0.2],
[0.1, 0.2, 0.5]])
print("col sums:", P.sum(0)) # সব 1
w, V = np.linalg.eig(P)
i1 = np.argmin(np.abs(w - 1))
pi = np.real(V[:, i1]); pi = pi / pi.sum()
print("steady state:", pi.round(4))
print("|lambda_2| :", round(np.sort(np.abs(w))[-2], 4))
p = np.array([0., 0, 1])
for k in range(1, 30):
p = P @ p
if np.linalg.norm(p - pi) < 0.01:
print(f"within 1% at day {k}, p = {p.round(4)}"); break
Problem 7. continuous-time: \(A = \begin{bmatrix} 0 & -1 \\ 1 & 0\end{bmatrix}\)-এর eigenvalue বের করো। \(x(t) = e^{At}x_0\)-এর গতিপথ কেমন হবে (decay/grow/rotate)?
Solution
Characteristic: \(\det(A - \lambda I) = \lambda^2 + 1 = 0 \Rightarrow \lambda = \pm i\) (বিশুদ্ধ কাল্পনিক)।
Property 6 অনুসারে: বাস্তব অংশ \(0\) → decay-ও নয় grow-ও নয় (ব্যাসার্ধ স্থির); কাল্পনিক অংশ \(\pm 1\) → rotation। তাই গতিপথ একটা নিখুঁত বৃত্ত — spiral নয়, কারণ ব্যাসার্ধ কমে/বাড়ে না। আসলে \(e^{At} = \begin{bmatrix} \cos t & -\sin t \\ \sin t & \cos t\end{bmatrix}\) — ঠিক rotation matrix! \(x(t)\) ধ্রুব-গতিতে origin-এর চারপাশে ঘোরে, কোনোদিন থামে না, দূরেও যায় না।
(তুলনায় fig05-এ বাস্তব অংশ \(-0.5 < 0\) ছিল, তাই বৃত্ত সংকুচিত হয়ে spiral। এখানে বাস্তব অংশ ঠিক \(0\), তাই বৃত্তই থাকে।)
Problem 8. ধারণাগত: বন্ধু বলছে "steady state মানে chain থেমে যায়, আর কিছু হয় না।" তার ভুলটা ধরিয়ে দাও।
Solution
ভুল বোঝাবুঝি: steady state মানে chain থামে না — প্রতিটা পদক্ষেপ চলতেই থাকে, individual অবস্থা বদলাতেই থাকে (আজ রোদ, কাল মেঘ, পরশু বৃষ্টি)। যা স্থির হয় তা হলো সম্ভাবনা-বণ্টন \(\pi\) — "যেকোনো দিন রোদ থাকার সম্ভাবনা \(0.46\)" এটা আর বদলায় না, যদিও কোন্ দিন রোদ তা random-ই থাকে।
সঠিক ছবি: একটা ব্যস্ত রেস্তোরাঁয় মোট \(100\) জন খদ্দের ধ্রুব থাকে (steady), কিন্তু ক্রমাগত কেউ ঢুকছে কেউ বেরোচ্ছে — প্রতিটা চেয়ারের দখলে-থাকার সম্ভাবনা স্থির, চেয়ারের মানুষ নয়। \(P\pi = \pi\) মানে "প্রতি অবস্থায় যত ঢুকছে তত বেরোচ্ছে" (detailed flow balance), গতি বন্ধ নয়। এটাই "dynamic equilibrium" — সচল ভারসাম্য।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "steady state মানে chain থেমে যায়" | না — অবস্থা বদলাতেই থাকে; শুধু সম্ভাবনা-বণ্টন \(\pi\) স্থির হয় (Problem 8)। dynamic equilibrium, স্থবিরতা নয়। |
| "steady state শুরুর অবস্থার ওপর নির্ভর করে" | (regular chain-এ) না — যেখানেই শুরু করো, একই \(\pi\)-তে পৌঁছাও (Property 3, fig02)। শুরুর তথ্য mixing-এ মুছে যায়। |
| "steady state হলো \(P\)-র বাঁ বা যেকোনো eigenvector" | না — নির্দিষ্টভাবে eigenvalue-\(1\) ডান-eigenvector, যোগফল \(1\)-এ normalized। \(\mathbf{1}\) হলো বাঁ-eigenvector (সহজ), কিন্তু সেটা steady state নয় (Problem 2)। |
| "\(e^{At}\) মানে প্রতি entry-র \(e^{a_{ij}t}\)" | না! সেটা শুধু diagonal matrix-এ খাটে। সাধারণভাবে \(e^{At}\) Taylor series (বা eigen-decomposition) দিয়ে, entry-wise নয় (Property 5)। |
| "complex eigenvalue = ভুল/অবাস্তব উত্তর" | না — complex eigenvalue মানে rotation; বাস্তব সিস্টেমে দোলন/spiral (fig05)। কাল্পনিক অংশ = ঘূর্ণন-কম্পাঙ্ক, খুবই বাস্তব। |
| "discrete (\(\lambda^k\)) আর continuous (\(e^{\lambda t}\)) আলাদা তত্ত্ব" | একই গল্পের দুই ভাষা (Property 6)। discrete-এ \(\vert \lambda\vert <1\) = continuous-এ \(\text{Re}(\lambda)<0\) = স্থিতিশীল। eigenvalue সব ঠিক করে। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Markov matrix | column sum \(1\), entry \(\geq 0\) | আবহাওয়ার অভ্যাস |
| বিবর্তন | \(p_{k+1} = Pp_k\) | সম্ভাবনার প্রবাহ |
| steady state | \(P\pi = \pi\); eigenvalue-\(1\) eigenvector | দীর্ঘকালীন জলবায়ু |
| সবসময় থাকে | column sum \(1 \Rightarrow\) eigenvalue \(1\) | Property 1 |
| convergence-গতি | \(\|p_k - \pi\| \approx \vert \lambda_2\vert ^k\) | মেমরি \(\lambda_2\)-হারে মরে |
| power-এর সীমা | \(P^\infty\) = সব column \(\pi\) | শুরু ভুলে যায় (fig04) |
| matrix exponential | \(e^{At} = \sum \frac{(At)^k}{k!}\); \(x(t)=e^{At}x_0\) | discrete-এর অবিচ্ছিন্ন যমজ |
| eigenvalue-র ভাষা | Re → decay/grow; Im → rotation | \(-0.5\pm 2i\) = spiral |
Part VII-এর সমাপ্তি: এই chapter দিয়ে আমরা applied linear algebra-র একটা সমৃদ্ধ ভ্রমণ শেষ করলাম — classification (7.1), regularization (7.2), constraints (7.3), unsupervised learning ও network (7.4), আর dynamics (7.5)। প্রতিটাতেই ভিত্তি ছিল সেই একই কয়েকটা ধারণা: projection, eigenvector, least squares, matrix গুণ। তুমি এখন দেখতে পাচ্ছো — Google-এর ranking থেকে আবহাওয়ার পূর্বাভাস, ridge regression থেকে k-means, সব একই গণিতের ভাষায় লেখা।
পরের Part-এর সেতু: এতদিন আমরা ধরে নিয়েছি matrix invert করা, eigenvalue বের করা, least squares solve করা — কম্পিউটারে "নিখুঁতভাবে" হয়। কিন্তু বাস্তব কম্পিউটার সংখ্যা রাখে সীমিত নির্ভুলতায় (floating point), আর কিছু matrix এত "সংবেদনশীল" যে ছোট ভুল বিশাল হয়ে ওঠে। কীভাবে math কম্পিউটারে ভুল হয়, কোন algorithm স্থিতিশীল, বড় sparse matrix কীভাবে দ্রুত solve করা যায় — এই ব্যবহারিক-গণনার জগৎই Part VIII: Computational / Numerical Linear Algebra।
📓 Notebook Project¶
notebooks/part-07/ch05-project.ipynb — Part VII flagship-এর সমাপ্তি কিস্তি: (১) একটা আবহাওয়া Markov chain simulate করে steady state দুইভাবে (eigenvector ও power iteration) বের করা ও মেলানো, (২) \(|\lambda_2|\) থেকে convergence-গতির পূর্বানুমান যাচাই, (৩) matrix exponential scratch-এ (Taylor) লিখে \(\dot{x} = Ax\)-এর spiral গতিপথ আঁকা ও eigenvalue-র বাস্তব/কাল্পনিক অংশের প্রভাব চোখে দেখা।