Chapter 6.5 — Positive Definite Matrices ও Quadratic Forms (পজিটিভ ডেফিনিট — bowl নাকি saddle?)¶
আগের chapter-এ spectral theorem আমাদের দিয়েছে symmetric matrix-এর সম্পূর্ণ এক্স-রে: \(A = Q\Lambda Q^T\)। এবার সেই এক্স-রে দিয়ে linear algebra-র সবচেয়ে দামি প্রশ্নটার উত্তর দেবো: \(x^TAx\) নামের surface-টা কি একটা পেয়ালা (bowl), নাকি ঘোড়ার জিন (saddle)? পেয়ালা হলে তলা আছে — minimum আছে — আর machine learning-এর প্রতিটা optimization ঠিক এই তলাটাই খোঁজে। Strang বলেন, একটা matrix-এর সম্পর্কে তুমি সবচেয়ে ভালো যে খবরটা পেতে পারো তা হলো: "it is positive definite।" এই chapter-এ দেখবে কেন — আর এক matrix-কে পাঁচ ভিন্ন আয়নায় চিনে নেওয়ার পাঁচটা test শিখবে, যাদের প্রত্যেকটা আসলে একই সত্যের ভিন্ন পোশাক।
🎯 এই chapter-এ যা শিখবে¶
- Quadratic Form(কোয়াড্রাটিক ফর্ম) \(Q(x) = x^TAx\) — matrix থেকে জন্ম নেওয়া "energy function", হাতে গুণ করে
- Positive Definite(পজিটিভ ডেফিনিট), Semidefinite(সেমিডেফিনিট), Negative Definite, Indefinite — চার চেহারার সংজ্ঞা ও ছবি
- পাঁচটা সমতুল্য test: eigenvalue, determinant (leading principal minor), pivot, Cholesky \(A = R^TR\), আর energy — প্রতিটা \(2\times 2\)-তে হাতে
- Principal Axes Theorem(প্রিন্সিপাল অ্যাক্সেস থিওরেম): spectral theorem দিয়ে \(Q(x) = \sum \lambda_i y_i^2\) — bowl/saddle-এর সম্পূর্ণ ব্যাখ্যা, ellipse-এর axes
- Calculus-এর second derivative test-এর matrix রূপ (Hessian), আর ML-এ কেন এসব প্রাণভোমরা: convexity, covariance, Gaussian, kernel, condition number
🖼️ এক ছবিতে মূল idea¶
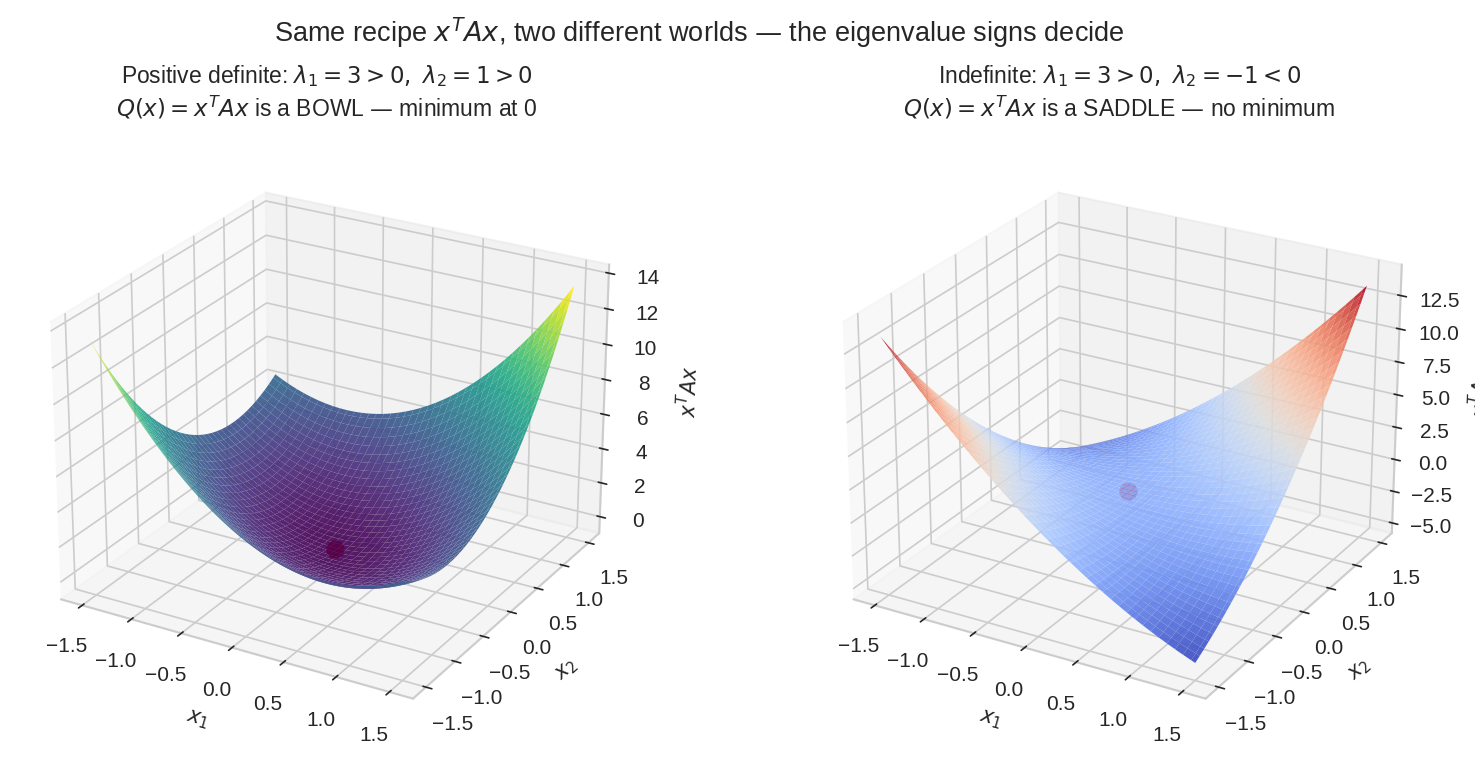
একই রেসিপি \(x^TAx\), দুই ভিন্ন পৃথিবী। বাঁয়ে \(A = \begin{bmatrix}2&1\\1&2\end{bmatrix}\) — দুটো eigenvalue-ই positive (\(3, 1\)), surface-টা নিখুঁত bowl, তলায় (লাল বিন্দু) minimum। ডানে \(A = \begin{bmatrix}1&2\\2&1\end{bmatrix}\) — eigenvalue \(3\) আর \(-1\), mixed sign — surface-টা saddle: এক দিকে উঠেছে, আরেক দিকে নেমে গেছে, minimum বলে কিছু নেই। পুরো chapter-টা এই দুই ছবির পার্থক্য ধরার গল্প।
১. কি? (What)¶
দৈনন্দিন analogy: বল ছেড়ে দাও, দেখো কোথায় থামে¶
একটা পাহাড়ি জায়গায় তুমি মার্বেল ছেড়ে দিলে। জায়গাটা যদি পেয়ালার মতো হয়, মার্বেল গড়িয়ে তলায় গিয়ে থামবে — একটা স্থিতিশীল বিশ্রামের বিন্দু আছে। জায়গাটা যদি ঘোড়ার জিনের মতো হয় — সামনে-পেছনে উঁচু, দুই পাশে ঢালু — মার্বেল এক মুহূর্ত মাঝখানে দাঁড়িয়ে থেকে পাশ দিয়ে গড়িয়ে পালিয়ে যাবে; থামার জায়গা নেই। প্রশ্ন: surface-এর সমীকরণ দেখে আগে থেকে বলা যায় কোনটা হবে? Symmetric matrix-এর জন্য উত্তর: হ্যাঁ, নিখুঁতভাবে — আর সেটাই positive definiteness।
Quadratic form: matrix থেকে জন্ম নেওয়া function¶
এতদিন \(A\) আমাদের কাছে ছিলো একটা যন্ত্র: vector ঢোকে (\(x\)), vector বেরোয় (\(Ax\))। আজ নতুন খেলা — বেরোনো vector-টাকে আবার \(x\)-এর সাথেই dot করে দাও:
এটাকে বলে Quadratic Form(কোয়াড্রাটিক ফর্ম — দ্বিঘাত রূপ) — physics/engineering-এ এরই নাম প্রায়ই energy। কেন "quadratic"? হাতে গুণ করে দেখি। \(x = (x_1, x_2)\) আর \(A = \begin{bmatrix}a & b\\ b & c\end{bmatrix}\) নাও:
ধাপ ১ — ভেতরের গুণ:
ধাপ ২ — বাইরের dot:
প্রতিটা term-এ \(x\) ঠিক দুইবার — তাই quadratic। খেয়াল করো cross term-এর কেরামতি: off-diagonal \(b\) দুই জায়গা থেকে এসে জোড়া লেগে \(2b\,x_1x_2\) হয়েছে। আমাদের চেনা উদাহরণে:
উল্টো দিকেও চলে: যেকোনো \(ax_1^2 + 2bx_1x_2 + cx_2^2\) দেখলেই matrix-টা পড়ে ফেলতে পারো — diagonal-এ বর্গের coefficient, off-diagonal-এ cross term-এর অর্ধেক।
কেন symmetric ধরে নেওয়াই যথেষ্ট?¶
\(x^TAx\) একটা \(1\times 1\) "matrix" — নিজের transpose-এর সমান: \(x^TAx = (x^TAx)^T = x^TA^Tx\)। দুটো গড় করো:
অর্থাৎ quadratic form শুধু \(A\)-এর symmetric অংশটাই দেখে — antisymmetric অংশের energy সবসময় শূন্য। যেমন \(\begin{bmatrix}1&4\\0&1\end{bmatrix}\) আর তার symmetric ভাই \(\begin{bmatrix}1&2\\2&1\end{bmatrix}\) — দুজনেরই \(Q = x_1^2 + 4x_1x_2 + x_2^2\)। তাই এই chapter-এ \(A\) সবসময় symmetric — কিছুই হারাচ্ছি না, আর বিনিময়ে Chapter 6.4-এর পুরো spectral theorem হাতে পেয়ে যাচ্ছি।
সংজ্ঞা: energy test দিয়ে চার (আসলে পাঁচ) জাত¶
Symmetric \(A\)-কে শ্রেণীবদ্ধ করি — সব \(x \neq 0\)-এর জন্য energy-র চিহ্ন দেখে:
| জাত | শর্ত (সব \(x \neq 0\)-তে) | surface | eigenvalue-এ |
|---|---|---|---|
| Positive Definite(পজিটিভ ডেফিনিট) (PD) | \(x^TAx > 0\) | bowl — তলায় strict minimum | সব \(\lambda > 0\) |
| Positive Semidefinite(পজিটিভ সেমিডেফিনিট) (PSD) | \(x^TAx \geq 0\) | trough/নালা — তলা চ্যাপ্টা হতে পারে | সব \(\lambda \geq 0\) |
| Negative Definite(নেগেটিভ ডেফিনিট) (ND) | \(x^TAx < 0\) | উল্টানো bowl — চূড়ায় maximum | সব \(\lambda < 0\) |
| Indefinite(ইনডেফিনিট) | কোথাও \(>0\), কোথাও \(<0\) | saddle — minimum-ও নয়, maximum-ও নয় | mixed sign |
(Negative semidefinite-ও আছে — \(\leq 0\) — PSD-র আয়না-ছবি।) এই "সব \(x\neq 0\)-তে energy positive?" প্রশ্নটাই energy test — সংজ্ঞা নিজেই একটা test। বাকি চারটা test আসবে Properties-এ; তারা সবাই এই একটাই প্রশ্নের চতুর শর্টকাট।
২. দেখতে কেমন?¶
দৃশ্য ১: চার জাতের গ্যালারি¶
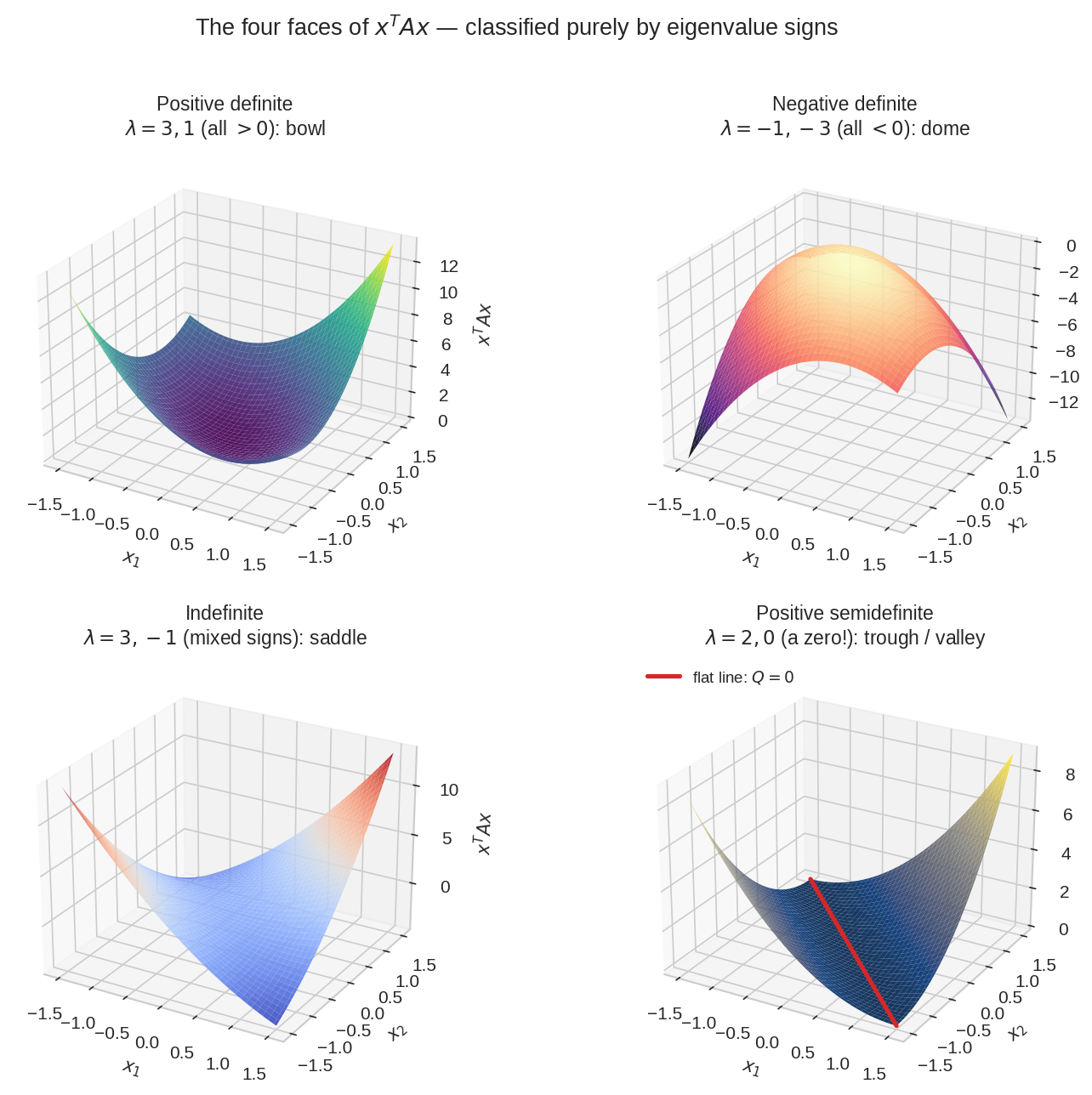
চার জাত, চার surface — শ্রেণীবিভাগটা পুরোপুরি eigenvalue-এর চিহ্ন দিয়ে। ওপরে-বাঁয়ে PD bowl (\(\lambda = 3, 1\)); ওপরে-ডানে ND-র উল্টানো bowl (\(\lambda = -1, -3\)); নিচে-বাঁয়ে indefinite saddle (\(\lambda = 3, -1\)); নিচে-ডানে PSD-র নালা (\(\lambda = 2, 0\)) — লাল লাইনটা \(x_1 = -x_2\) বরাবর, সেখানে \(Q\) ঠিক শূন্য: তলা আছে, কিন্তু এক বিন্দুতে নয়, গোটা একটা লাইন জুড়ে। ওই zero eigenvalue-এর দিকেই surface চ্যাপ্টা।
দৃশ্য ২: ওপর থেকে দেখলে — level curves¶
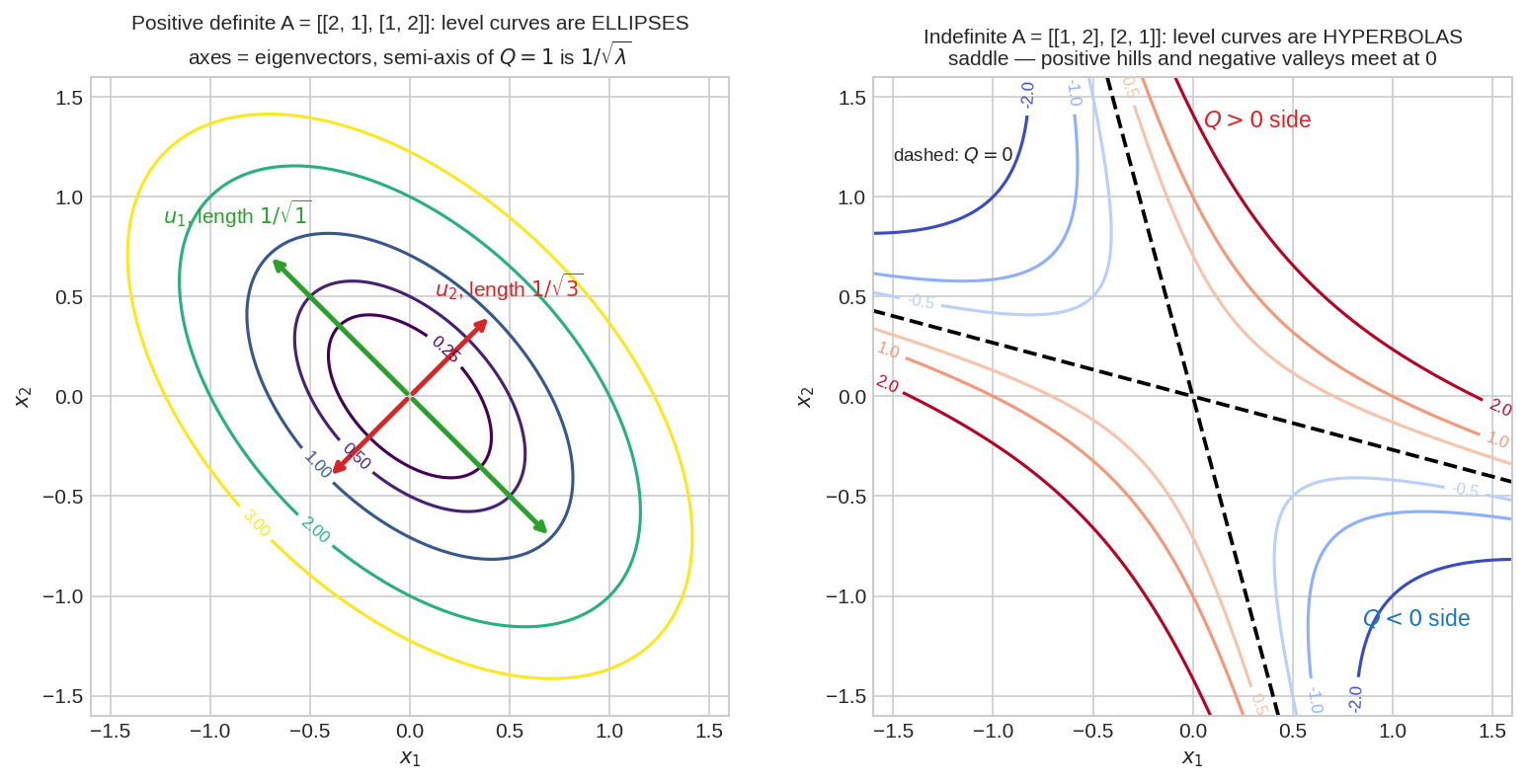
Surface-টাকে সমতল করে কাটলে (contour) জাত ধরা পড়ে আরো সুন্দরভাবে। বাঁয়ে PD: level curve-গুলো ellipse — আর তাদের axes ঠিক eigenvector বরাবর! \(Q = 1\) ellipse-এর semi-axis-এর দৈর্ঘ্য \(1/\sqrt{\lambda}\): বড় \(\lambda\) (লাল, \(\lambda = 3\)) মানে energy দ্রুত বাড়ে, তাই সেই দিকে ellipse খাটো; ছোট \(\lambda\) (সবুজ, \(\lambda = 1\)) দিকে লম্বা। ডানে indefinite: level curve hyperbola, আর কালো dashed লাইনে \(Q = 0\) — positive পাহাড় আর negative উপত্যকার সীমান্ত।
দৃশ্য ৩: energy test-এর ছবি — সব দিকে ঘুরে দেখা¶
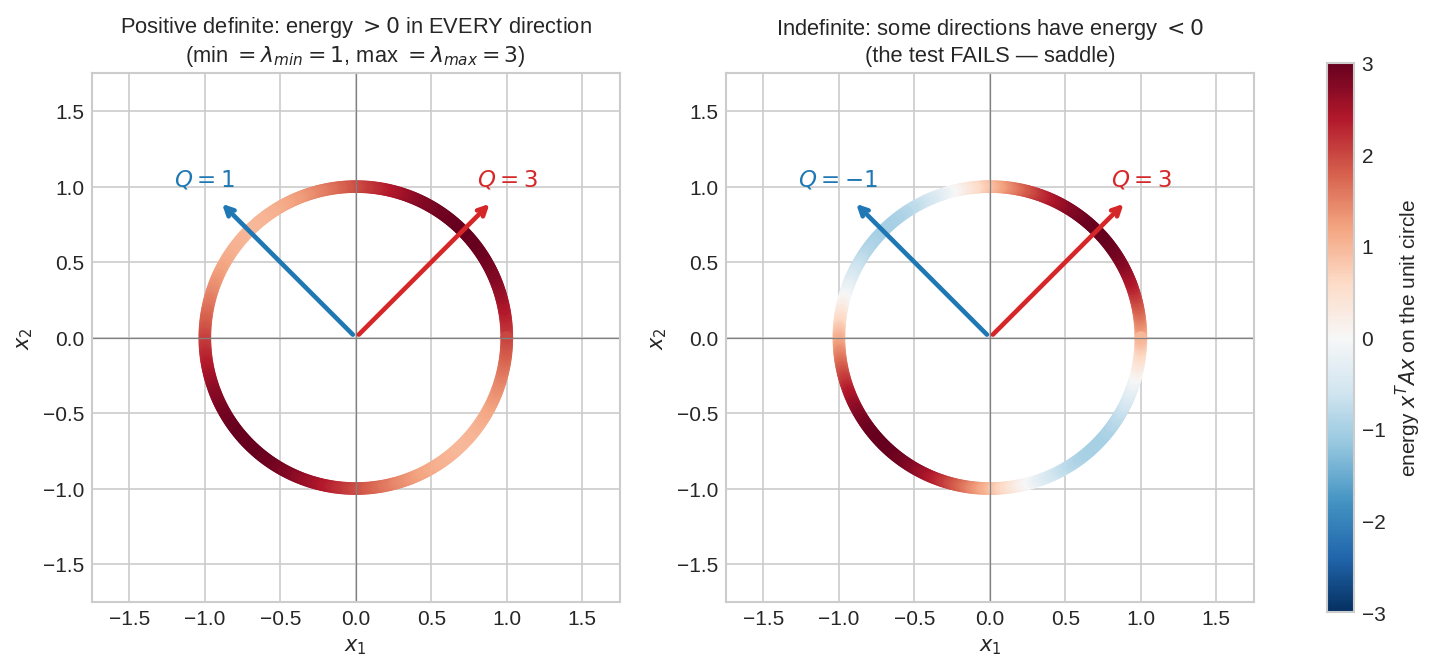
Energy test মানে: unit circle-এর প্রতিটা দিকে দাঁড়িয়ে \(x^TAx\) মাপো। বাঁয়ে PD matrix — circle-এর প্রতিটা বিন্দু লাল-ঘেঁষা (positive); সর্বনিম্ন energy \(\lambda_{min} = 1\) (নীল তীর, eigenvector দিক), সর্বোচ্চ \(\lambda_{max} = 3\) (লাল তীর)। ডানে indefinite — circle-এর কিছু অংশ নীল: সেই দিকগুলোতে energy negative, test fail। unit vector-এ energy-র চূড়া-খাদ সবসময় eigenvalue — এটা Chapter 6.4-এর Rayleigh quotient-এর কথা।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- কাঠামো প্রকৌশল (জন্মভূমি): সেতু বা বিল্ডিং-এর stiffness matrix-এ \(\frac12 x^TKx\) হলো বিকৃতির energy। \(K\) positive definite মানে যেকোনো ধাক্কায় energy জমা হয়, কাঠামো ফিরে আসে — স্থিতিশীল। Zero eigenvalue মানে এমন এক নড়াচড়া যাতে কোনো বাধা নেই — নড়বড়ে জোড়া!
- কম্পন ও stability: পদার্থবিজ্ঞানে ভারসাম্য বিন্দু স্থিতিশীল কি না — potential-এর Hessian PD কি না, সেই প্রশ্ন।
- পরিসংখ্যান: যেকোনো dataset-এর covariance matrix স্বভাবগতভাবে PSD (নিচে proof) — এ কারণেই variance কখনো negative হয় না, যেদিকেই ডেটা project করো।
Data Science / ML-এ:
- Loss surface-এর জ্যামিতি: Part V-এর least squares objective \(\|Ax - b\|^2\)-এর Hessian হলো \(2A^TA\) — PSD, তাই surface-টা পেয়ালা, তাই minimum-এ পৌঁছানো সম্ভব। Convexity(কনভেক্সিটি — উত্তল হওয়া) ব্যাপারটাই এটা: Hessian সব জায়গায় PSD \(\iff\) function convex \(\iff\) local minimum-ই global minimum।
- Gaussian distribution: multivariate normal-এর density-তে বসে \(e^{-\frac12 (x-\mu)^T\Sigma^{-1}(x-\mu)}\) — এটা অর্থবহ হতে \(\Sigma\) positive definite হতেই হবে; নাহলে "bell" কোনো দিকে চ্যাপ্টা বা উল্টে যায়, integral-ই converge করে না। Gaussian-এর ellipse-আকৃতির contour-গুলো ঠিক আমাদের fig03-এর ellipse — axes বরাবর eigenvector, ছড়ানো \(\propto \sqrt{\lambda}\)।
- Kernel matrix: SVM/Gaussian process-এর kernel matrix \(K_{ij} = k(x_i, x_j)\) বৈধ হওয়ার শর্তই PSD হওয়া (Mercer-এর শর্ত) — নাহলে "similarity"-র জ্যামিতিটাই ভেঙে পড়ে।
- Cholesky দিয়ে sampling: \(\Sigma = R^TR\) ভাঙতে পারলে \(z \sim \mathcal{N}(0, I)\) থেকে \(R^Tz\) বানালেই covariance \(\Sigma\)-ওয়ালা sample — প্রতিটা probabilistic ML library-র ভেতরে প্রতিদিন এই লাইন চলে।
- Condition number ও gradient descent-এর গতি: নিচের ছবিটা দেখো —
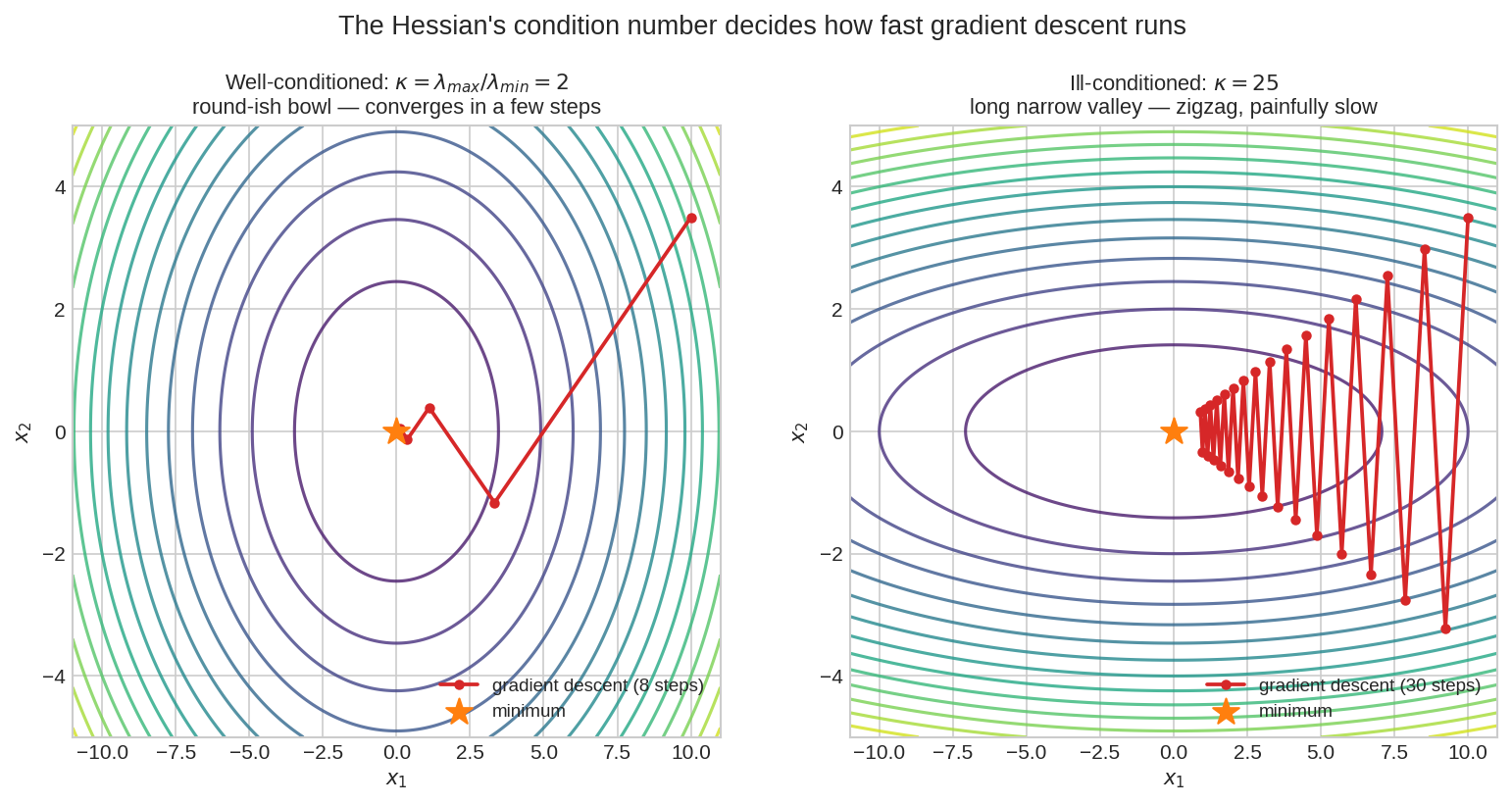
দুটোই positive definite bowl, কিন্তু আচরণ আকাশ-পাতাল। Condition Number(কন্ডিশন নাম্বার) \(\kappa = \lambda_{max}/\lambda_{min}\) মাপে bowl কতটা লম্বাটে। বাঁয়ে \(\kappa = 2\) — প্রায় গোল পেয়ালা, gradient descent সোজা তলায় (৮ ধাপ)। ডানে \(\kappa = 25\) — সরু উপত্যকা: gradient খাড়া দেয়ালের দিকে টানে, তলার দিকে নয় — path zigzag করে করে অনন্তকাল লাগায়। Feature normalization, preconditioning, Adam optimizer — সবার আসল কাজ এই \(\kappa\) ছোট করা।
৪. Properties — পাঁচটা সমতুল্য test¶
Symmetric \(A\)-এর জন্য নিচের পাঁচটা কথা হুবহু সমান — একটা সত্য হলে সবগুলো সত্য। প্রতিটা এখনই আমাদের \(A = \begin{bmatrix}2&1\\1&2\end{bmatrix}\)-তে হাতে যাচাই করবো।
Test 1 — Eigenvalue test: সব \(\lambda > 0\)¶
সবচেয়ে "সত্যের কাছের" test — কিন্তু বড় matrix-এ eigenvalue বের করা দামি। তাই বাকি চারটা।
Test 2 — Determinant test: সব leading principal minor \(> 0\)¶
Leading Principal Minor(লিডিং প্রিন্সিপাল মাইনর) \(D_k\) = ওপরের-বাঁ কোণার \(k\times k\) ব্লকের determinant। \(n\times n\)-এ \(n\)টা:
\(2\times 2\)-তে সূত্রটা মুখস্থ রাখার মতো ছোট: \(\begin{bmatrix}a&b\\b&c\end{bmatrix}\) PD \(\iff\) \(a > 0\) এবং \(ac - b^2 > 0\)। শুধু \(\det > 0\) যথেষ্ট নয় — \(-I\)-এর determinant \(+1\) কিন্তু সে negative definite! দুই negative eigenvalue গুণে positive হয়ে determinant-কে ধোঁকা দেয়; \(D_1\) সেই ধোঁকা ধরে ফেলে।
Test 3 — Pivot test: elimination-এর সব pivot \(> 0\)¶
Chapter 2-এর পুরনো বন্ধু elimination! Row 2 থেকে \(\tfrac12\times\) Row 1 বাদ দাও:
লুকোনো সৌন্দর্য: pivot = পরপর দুই minor-এর ভাগফল, \(d_k = D_k / D_{k-1}\) (এখানে \(2 = 2/1\), \(\tfrac32 = 3/2\))। তাই সব minor positive \(\iff\) সব pivot positive — Test 2 আর Test 3 একই মুদ্রার দুই পিঠ, আর pivot বের করা (\(O(n^3)\), determinant-এর চেয়ে সস্তা) বাস্তবের পথ।
Test 4 — Cholesky test: \(A = R^TR\) লেখা যায় (independent-column \(R\))¶
Cholesky Decomposition(কোলেস্কি ডিকম্পোজিশন): PD matrix মানেই কোনো upper-triangular \(R\) (positive diagonal) দিয়ে \(A = R^TR\) — যেন matrix-এর "বর্গমূল"। হাতে বের করি: \(R = \begin{bmatrix}r_{11}&r_{12}\\0&r_{22}\end{bmatrix}\) ধরে \(R^TR\)-এর entry মেলাও —
লক্ষ করো: \(r_{11}^2 = 2\) আর \(r_{22}^2 = \tfrac32\) — diagonal-এর বর্গগুলো ঠিক pivot! Cholesky আসলে elimination-এরই symmetric সংস্করণ (\(A = LDL^T\) লিখে \(R = \sqrt{D}\,L^T\))। আর কেন \(A = R^TR\) হলেই PD? — Test 5 দেখো।
Test 5 — Energy test: সব \(x \neq 0\)-তে \(x^TAx > 0\)¶
সংজ্ঞা নিজে। হাতে যাচাইয়ের কৌশল: বর্গ পূর্ণ করা (completing the square) —
দুটো বর্গের যোগফল, coefficient দুটো positive — কাজেই \(x \neq 0\) হলে অন্তত একটা বর্গ \(> 0\), energy \(> 0\) ✓। আর coefficient দুটো কারা? \(2\) আর \(\tfrac32\) — আবার pivots! বর্গ পূর্ণ করা আর elimination আসলে একই হিসাব — এটাই Strang-এর প্রিয় চমক, আর এটাই Test 3 \(\Rightarrow\) Test 5-এর প্রমাণ।
Property — \(A^TA\) সবসময় PSD (এক লাইনের proof)¶
যেকোনো \(m\times n\) matrix \(A\)-এর জন্য:
Energy মানে "লম্বা করার পর দৈর্ঘ্যের বর্গ" — negative হওয়ার প্রশ্নই নেই। আর \(= 0\) কেবল \(Ax = 0\) হলে — তাই \(A\)-এর column independent হলে (\(N(A) = \{0\}\)) \(A^TA\) পুরোপুরি PD। Part V-এ normal equations-এ \(A^TA\) invertible হওয়ার পেছনে এই সত্যটাই কাজ করছিলো; covariance matrix (\(X\) কেন্দ্রীভূত করে \(\tfrac{1}{n}X^TX\)) আর kernel matrix PSD হওয়ারও একই কারণ।
Property — Minimum test: calculus-এর second derivative test-এর বড় ভাই¶
এক চলকে শিখেছিলে: \(f'(a) = 0\) আর \(f''(a) > 0\) হলে \(a\)-তে minimum। বহু চলকে \(f''\)-এর জায়গা নেয় Hessian(হেসিয়ান) — second partial derivative-দের symmetric matrix \(H_{ij} = \tfrac{\partial^2 f}{\partial x_i \partial x_j}\):
\(H\) indefinite হলে saddle point; PD-র বদলে শুধু PSD হলে রায় ঝুলে থাকে (উচ্চতর term দেখতে হয়)। \(f(x,y) = ax^2 + 2bxy + cy^2\)-এর Hessian \(\begin{bmatrix}2a&2b\\2b&2c\end{bmatrix}\) — তাই calculus বইয়ের "\(f_{xx} > 0,\; f_{xx}f_{yy} - f_{xy}^2 > 0\)" শর্তটা আসলে ছদ্মবেশে আমাদের determinant test! রহস্যভেদ: তুমি Calculus-এ এতদিন positive definiteness-ই পরীক্ষা করে এসেছো, নাম না জেনে।
PSD-র জন্য test-গুলো কেমন বদলায়?¶
সাবধানতার জায়গা: PD-র "\(>\)"-গুলো সরল "\(\geq\)" হয়ে যায় না সবখানে। সব \(\lambda \geq 0\) ✓; \(A = R^TR\) (যেকোনো \(R\), dependent column চলবে) ✓; কিন্তু determinant test-এ শুধু leading নয়, সব principal minor (যেকোনো সারি-column জোড়া মুছে পাওয়া) \(\geq 0\) লাগে — Common ভুল-এ counterexample পাবে।
৫. Intuition — কেন সত্য? (Spectral theorem-এর পুরস্কার)¶
Principal Axes Theorem: ঘুরে দাঁড়ালেই সব সরল¶
Chapter 6.4-এর spectral theorem: \(A = Q\Lambda Q^T\), যেখানে \(Q\)-এর column-রা orthonormal eigenvector। নতুন স্থানাঙ্ক নাও \(y = Q^Tx\) — মানে eigenvector-দের চোখে \(x\)-কে দেখা (শুধুই একটা ঘোরানো, দৈর্ঘ্য অটুট)। তখন:
Cross term সব উধাও! একে বলে Principal Axes Theorem(প্রিন্সিপাল অ্যাক্সেস থিওরেম)। এবার সব রহস্য এক নিঃশ্বাসে পরিষ্কার:
- সব \(\lambda_i > 0\): প্রতিটা দিকে ওঠা — \(Q(x)\) positive বর্গের যোগফল — bowl। এটাই "eigenvalue test \(\iff\) energy test"-এর প্রমাণ: এক দিকে (\(x =\) eigenvector \(q_i\) বসাও) \(q_i^TAq_i = \lambda_i\), তাই energy positive হতে প্রতিটা \(\lambda_i > 0\) লাগবেই; উল্টোদিকে সব \(\lambda > 0\) হলে যোগফলটা positive না হয়ে পারে না।
- কোনো \(\lambda_i < 0\): সেই \(y_i\) অক্ষ বরাবর surface নামে, অন্য positive অক্ষে ওঠে — saddle।
- কোনো \(\lambda_i = 0\): সেই দিকে surface সমতল — PSD-র নালা (fig02-এর লাল লাইন)।
- Ellipse-এর axes: \(Q(x) = 1\) মানে \(\sum\lambda_i y_i^2 = 1\) — eigenvector-স্থানাঙ্কে খাঁটি ellipse; \(y_i\) অক্ষ বরাবর অর্ধ-দৈর্ঘ্য \(1/\sqrt{\lambda_i}\)। মূল স্থানাঙ্কে ফিরলে অক্ষগুলো বসে eigenvector বরাবর — fig03-এর বাঁ ছবিটা এই theorem-এর ফটোগ্রাফ।
পাঁচ test-এর ঐক্য — এক নজরে যুক্তির শিকল¶
আর Cholesky দুই দিকে যাতায়াত করে: pivots থেকে \(R = \sqrt{D}L^T\) বানানো যায়, আবার \(A = R^TR\) থাকলে \(x^TAx = \|Rx\|^2 > 0\) (energy)। শিকলটা বন্ধ — পাঁচটা কথা একটাই কথা। প্রতিটা test এক-এক পেশার চোখে একই সত্য: eigenvalue জ্যামিতির, pivot গণনার, determinant বীজগণিতের, Cholesky সফটওয়্যারের, আর energy পদার্থবিজ্ঞানের।
৬. Code-এ কেমনে লিখে¶
import numpy as np
np.random.seed(42)
A = np.array([[2., 1.], [1., 2.]]) # আমাদের bowl
B = np.array([[1., 2.], [2., 1.]]) # আমাদের saddle
def pivots(S):
"""Row exchange ছাড়া elimination — pivot-দের তালিকা।"""
U = S.astype(float).copy()
n = len(U)
for i in range(n):
for j in range(i + 1, n):
U[j] -= (U[j, i] / U[i, i]) * U[i]
return np.diag(U)
def report(S, name):
lam = np.linalg.eigvalsh(S) # test 1
minors = [np.linalg.det(S[:k, :k]) for k in range(1, len(S) + 1)] # test 2
piv = pivots(S) # test 3
try: # test 4
L = np.linalg.cholesky(S) # L @ L.T = S, অর্থাৎ R = L.T
chol = "works"
except np.linalg.LinAlgError:
chol = "FAILS"
theta = np.linspace(0, 2 * np.pi, 361) # test 5
C = np.vstack([np.cos(theta), np.sin(theta)])
emin = np.einsum('ij,ij->j', C, S @ C).min()
print(f"{name}: eigenvalues={np.round(lam, 3)}, minors={np.round(minors, 3)},")
print(f" pivots={np.round(piv, 3)}, cholesky {chol}, min energy on circle={emin:.3f}")
report(A, "A")
report(B, "B")
# Cholesky দিয়ে Gaussian sampling — ML-এর প্রতিদিনের কাজ
Sigma = np.array([[2., 1.], [1., 2.]])
R = np.linalg.cholesky(Sigma).T # Sigma = R^T R
z = np.random.randn(100000, 2) # সাদা noise
samples = z @ R # covariance এখন Sigma!
print("sample covariance ≈\n", np.round(np.cov(samples.T), 2))
Output ব্যাখ্যা:
A: eigenvalues=[1. 3.], minors=[2. 3.],
pivots=[2. 1.5], cholesky works, min energy on circle=1.000
B: eigenvalues=[-1. 3.], minors=[ 1. -3.],
pivots=[ 1. -3.], cholesky FAILS, min energy on circle=-1.000
sample covariance ≈
[[2. 1. ]
[1. 2. ]]
- \(A\)-তে পাঁচ test-ই সবুজ বাতি; \(B\)-তে পাঁচটাই লাল — negative eigenvalue, negative minor, negative pivot, Cholesky-র
LinAlgError, circle-এ negative energy। এক test fail মানে সব fail — সমতুল্যতার জীবন্ত প্রদর্শনী। - Circle-এর minimum energy ঠিক \(\lambda_{min}\) — fig04-এর গল্প সংখ্যায়।
- বাস্তবে PD চেক করার দ্রুততম উপায়:
np.linalg.choleskyচালিয়ে দেখো exception ওঠে কি না — eigenvalue বের করার অর্ধেক খরচে। - শেষ ব্লক: \(R^Tz\) কৌশলে সাদা noise থেকে ঠিক \(\Sigma\) covariance-এর 100,000 sample — Cholesky sampling।
৭. Worked Examples¶
Example 1 — এক matrix, পাঁচ test (সবগুলো হাতে)¶
\(S = \begin{bmatrix}4&2\\2&3\end{bmatrix}\) — PD কি না, পাঁচ আয়নায়:
Test 2 (সবচেয়ে দ্রুত): \(D_1 = 4 > 0\), \(D_2 = 12 - 4 = 8 > 0\) ✓ — এখানেই রায় হয়ে গেছে; বাকিগুলো মিলিয়ে দেখি।
Test 3: Row 2 \(-\tfrac12\) Row 1: \(\begin{bmatrix}4&2\\0&2\end{bmatrix}\) — pivots \(4, 2 > 0\) ✓ (যাচাই: \(4\cdot2 = 8 = \det\), আর \(2 = D_2/D_1 = 8/4\) ✓)
Test 1: \(\det(S - \lambda I) = \lambda^2 - 7\lambda + 8 = 0 \Rightarrow \lambda = \tfrac{7 \pm \sqrt{17}}{2} \approx 5.56,\; 1.44\) — দুটোই positive ✓ (দ্রুত যাচাই: যোগফল \(7 =\) trace, গুণফল \(8 = \det\))
Test 4: \(r_{11} = \sqrt4 = 2\); \(r_{12} = 2/2 = 1\); \(r_{22} = \sqrt{3 - 1} = \sqrt2\):
Test 5: \(4x_1^2 + 4x_1x_2 + 3x_2^2 = 4\big(x_1 + \tfrac12x_2\big)^2 + 2x_2^2 > 0\) ✓ — coefficients আবার pivots \(4, 2\)।
Example 2 — ধোঁকাবাজ matrix: সব entry positive, তবু saddle¶
\(T = \begin{bmatrix}1&3\\3&1\end{bmatrix}\) — সব entry positive, দেখে মনে হয় "positive" কিছু একটা হবে। Test করো:
Eigenvalue-ও তাই বলে: \(\lambda = 1 \pm 3 = 4, -2\)। Negative energy-র দিক খুঁজতে ছোট eigenvalue-এর eigenvector নাও — \((1, -1)\):
দুই স্থানাঙ্ক বিপরীত চিহ্নে টানলে বিশাল cross term \(6x_1x_2\) negative হয়ে বর্গদের হারিয়ে দেয়। শিক্ষা: positive definite মানে entry positive নয় — energy positive। চোখ নয়, test-এ বিশ্বাস রাখো।
Example 3 — Ellipse আঁকা: principal axes theorem হাতে-কলমে¶
\(5x_1^2 + 8x_1x_2 + 5x_2^2 = 9\) — এটা কেমন দেখতে?
ধাপ ১ — matrix পড়ো: \(A = \begin{bmatrix}5&4\\4&5\end{bmatrix}\) (cross term \(8\)-এর অর্ধেক off-diagonal-এ)।
ধাপ ২ — spectral ভাঙন: \(\det(A - \lambda I) = (5-\lambda)^2 - 16 = 0 \Rightarrow \lambda = 9, 1\)। Eigenvector: \(\lambda = 9\)-এ \((1,1)/\sqrt2\); \(\lambda = 1\)-এ \((1,-1)/\sqrt2\)। দুটোই positive — ellipse নিশ্চিত।
ধাপ ৩ — নতুন স্থানাঙ্কে লেখো: \(y = Q^Tx\) নিলে সমীকরণ হয় \(9y_1^2 + y_2^2 = 9\), অর্থাৎ \(\tfrac{y_1^2}{1} + \tfrac{y_2^2}{9} = 1\)।
ধাপ ৪ — পড়ে ফেলো: semi-axis \(\sqrt{9/\lambda}\): বড় \(\lambda = 9\) দিকে (\(45°\), \((1,1)\) বরাবর) ছোট অর্ধ-অক্ষ \(1\); ছোট \(\lambda = 1\) দিকে (\((1,-1)\) বরাবর) বড় অর্ধ-অক্ষ \(3\)। একটা \(3:1\) লম্বাটে ellipse, \(45°\) হেলানো — না এঁকেই সব জেনে গেলে। (Gaussian-এর confidence ellipse ঠিক এভাবেই আঁকা হয়, \(A = \Sigma^{-1}\) নিয়ে।)
৮. Problems ও Solutions¶
Problem 1. Determinant test দিয়ে দেখাও Strang-এর প্রিয় second difference matrix PD:
তারপর minor-দের ভাগফল থেকে হিসাব না করেই pivot তিনটা লিখে ফেলো।
Solution
Leading principal minor তিনটা:
সব positive (\(2, 3, 4\)) — \(K\) positive definite ∎
Pivot = পরপর minor-এর ভাগফল \(d_k = D_k/D_{k-1}\):
Elimination করে মিলিয়ে দেখতে পারো — ঠিক \(2, \tfrac32, \tfrac43\) আসবে। (এই \(K\) হলো discretized "টানটান তারের" stiffness matrix — PD মানেই তারটা স্থিতিশীল; \(n\times n\) সংস্করণে pivot-ধারা \(\tfrac{k+1}{k}\) চলতেই থাকে।)
Problem 2. \(b\)-এর কোন মানের জন্য \(\begin{bmatrix}1&b\\b&9\end{bmatrix}\) (a) positive definite, (b) positive semidefinite? সীমান্ত-মানে matrix-টাকে \(R^TR\) আকারে লিখে semidefinite-ত্ব সরাসরি দেখাও।
Solution
(a) Determinant test: \(D_1 = 1 > 0\) সবসময়; \(D_2 = 9 - b^2 > 0 \iff -3 < b < 3\)।
(b) \(b = \pm 3\)-তে \(D_2 = 0\): eigenvalue \(0\) ঢুকে পড়ে — positive semidefinite (আর \(|b| > 3\) হলে indefinite)।
সীমান্তে \(b = 3\): \(\begin{bmatrix}1&3\\3&9\end{bmatrix} = \begin{bmatrix}1\\3\end{bmatrix}\begin{bmatrix}1&3\end{bmatrix} = R^TR\), যেখানে \(R = [\,1\;\;3\,]\)। তাই
— কখনো negative নয়, কিন্তু \(x = (3, -1) \neq 0\)-তে ঠিক শূন্য। এটাই PSD-র trough: \((3,-1)\) লাইন বরাবর energy-র নালা। (\(R\)-এর column dependent — তাই PD নয়, শুধু PSD।)
Problem 3. Eigenvalue test দিয়ে শ্রেণীবদ্ধ করো: \(M = \begin{bmatrix}2&3\\3&2\end{bmatrix}\)। Saddle হলে এমন একটা দিক বের করো যেদিকে energy negative, আর এক দিক যেদিকে positive — দুটোই হাতে যাচাই করো।
Solution
Mixed sign — indefinite, saddle। (দ্রুত চেক: \(D_2 = 4 - 9 = -5 < 0\) — \(2\times2\)-তে negative determinant মানেই দুই eigenvalue বিপরীত চিহ্নের, সোজা saddle।)
Negative দিক: \(\lambda = -1\)-এর eigenvector \((1, -1)\):
Positive দিক: \(\lambda = 5\)-এর eigenvector \((1, 1)\):
(\(10 = 5\cdot\|(1,1)\|^2\) আর \(-2 = -1\cdot\|(1,-1)\|^2\) — eigenvector-এ energy \(= \lambda\|x\|^2\), principal axes theorem-এর ছোট্ট যাচাই।)
Problem 4. হাতে Cholesky: \(A = \begin{bmatrix}9&3\\3&5\end{bmatrix}\)-কে \(R^TR\) আকারে ভাঙো (\(R\) upper triangular, positive diagonal)। Diagonal entry-র বর্গ দুটো \(A\)-এর pivot-এর সাথে মিলিয়ে দেখাও।
Solution
\(R = \begin{bmatrix}r_{11}&r_{12}\\0&r_{22}\end{bmatrix}\) ধরে \(R^TR\)-এর তিনটা entry মেলাও:
- \((1,1)\): \(r_{11}^2 = 9 \Rightarrow r_{11} = 3\)
- \((1,2)\): \(r_{11}r_{12} = 3 \Rightarrow r_{12} = 1\)
- \((2,2)\): \(r_{12}^2 + r_{22}^2 = 5 \Rightarrow r_{22}^2 = 4 \Rightarrow r_{22} = 2\)
Pivot মেলানো: elimination-এ Row 2 \(-\tfrac13\) Row 1 দিলে pivots \(9\) আর \(5 - 1 = 4\) — ঠিক \(r_{11}^2 = 9\), \(r_{22}^2 = 4\) ✓। Cholesky মানে "pivot-দের বর্গমূল বিলিয়ে দেওয়া" — \(A = LDL^T\)-এর \(\sqrt{D}\)-কে দুই পাশে ভাগ করা।
Problem 5. (a) এক লাইনে প্রমাণ করো: যেকোনো \(m \times n\) matrix \(A\)-এর জন্য \(A^TA\) positive semidefinite। (b) ঠিক কখন সে positive definite? (c) এ থেকে ব্যাখ্যা করো কেন covariance matrix কখনো negative eigenvalue পায় না।
Solution
(a) \(x^T(A^TA)x = (Ax)^T(Ax) = \|Ax\|^2 \geq 0\) ∎
(b) Equality \(\iff Ax = 0\)। তাই \(x \neq 0\)-তে energy শূন্য হতে পারে কেবল \(N(A) \neq \{0\}\) হলে। অতএব:
(Part V-এ normal equations \(A^TA\hat{x} = A^Tb\) solve করার সময় ঠিক এই শর্তটাই লাগতো — এখন জানো তার আসল নাম।)
(c) Data matrix \(X\)-এর প্রতিটা column থেকে গড় বাদ দিয়ে (centered) covariance \(\Sigma = \tfrac{1}{n}X_c^TX_c\) — অবিকল \(A^TA\)-এর চেহারা, তাই PSD। আর যেকোনো দিক \(w\)-তে \(w^T\Sigma w = \tfrac1n\|X_cw\|^2\) হলো সেই দিকে project-করা ডেটার variance — variance negative হতে পারে না, এটা তারই matrix-ভাষ্য। (কোনো \(w\)-তে শূন্য মানে সেই দিকে ডেটা একদম চ্যাপ্টা — feature-রা linearly dependent।)
Problem 6. \(f(x, y) = x^2 + 2xy + 3y^2 - 4x\)-এর critical point বের করো এবং Hessian test দিয়ে নির্ধারণ করো সেটা minimum, maximum না saddle। মানটাও বের করো।
Solution
ধাপ ১ — gradient শূন্য করো:
প্রথমটা: \(x + y = 2\); দ্বিতীয়টা: \(x + 3y = 0\)। বিয়োগ: \(2y = -2 \Rightarrow y = -1,\; x = 3\)।
ধাপ ২ — Hessian:
Determinant test: \(D_1 = 2 > 0\), \(D_2 = 12 - 4 = 8 > 0\) — positive definite — কাজেই \((3, -1)\)-এ strict minimum ∎
ধাপ ৩ — মান: \(f(3, -1) = 9 - 6 + 3 - 12 = -6\)।
Quadratic function-এর Hessian ধ্রুবক, তাই এটা শুধু local নয় — global minimum (function-টা convex)। খেয়াল করো: linear term \(-4x\) শুধু bowl-টাকে সরিয়েছে, তার bowl-ত্ব ঠিক করে দিয়েছে খাঁটি quadratic অংশের matrix — সেটাই Hessian test-এর মর্ম।
Problem 7. \(A\) ও \(B\) দুটোই positive definite (\(n\times n\))। প্রমাণ করো: (a) \(A + B\) positive definite; (b) \(A\)-এর প্রতিটা diagonal entry \(> 0\); (c) দেখাও (b)-এর উল্টোটা মিথ্যা — diagonal positive হলেই PD নয়।
Solution
(a) Energy test-এর কাছে এ প্রশ্ন এক লাইনের: যেকোনো \(x \neq 0\)-তে
(Eigenvalue দিয়ে চেষ্টা করলে আটকে যেতে — \(A+B\)-এর eigenvalue মোটেই \(\lambda_A + \lambda_B\) নয়! সঠিক test বেছে নেওয়াটাই আসল দক্ষতা।)
(b) Energy test-এ চতুর \(x\) বসাও: standard basis vector \(e_i\) (শুধু \(i\)-তম জায়গায় \(1\)):
(c) Counterexample আগেই দেখেছি — Example 2-এর \(\begin{bmatrix}1&3\\3&1\end{bmatrix}\): diagonal \(1, 1 > 0\), কিন্তু \(\det = -8 < 0\) — saddle। Diagonal positive হওয়া প্রয়োজনীয় (necessary) শর্ত, যথেষ্ট (sufficient) নয় — cross term বিদ্রোহ করতে পারে।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "সব entry positive মানেই positive definite" | না! \(\begin{bmatrix}1&3\\3&1\end{bmatrix}\)-এর সব entry positive, তবু saddle (\(\lambda = 4, -2\))। "Positive" বসে energy/eigenvalue-এর ওপর, entry-র ওপর নয়। উল্টোটাও সত্য: \(\begin{bmatrix}2&-1\\-1&2\end{bmatrix}\)-এ negative entry আছে, তবু দিব্যি PD। |
| "\(\det A > 0\) হলেই PD" | \(-I\)-এর \(\det = +1\), কিন্তু সে negative definite! জোড় সংখ্যক negative eigenvalue determinant-কে positive করে ফেলে। লাগবে সব leading minor \(D_1, D_2, \dots, D_n > 0\) — শুধু শেষেরটা নয়। |
| "\(A\) symmetric না হলেও \(x^TAx > 0\) দেখলেই PD বলা যায়" | সাবধান — quadratic form শুধু \(\tfrac{A + A^T}{2}\) দেখে। Non-symmetric matrix-এ "positive definite" শব্দটা ব্যবহারের আগে symmetric part নাও; নাহলে eigenvalue test-এর সাথে সংঘর্ষ বাধবে (non-symmetric matrix-এর \(\lambda\) complex-ও হতে পারে)। |
| "PSD check-ও leading minor \(\geq 0\) দিয়েই হয়" | ফাঁদ! \(\begin{bmatrix}0&0\\0&-1\end{bmatrix}\)-এর leading minor \(0, 0\) — সব \(\geq 0\) — অথচ \(x = (0,1)\)-এ energy \(= -1\)। PSD-র জন্য লাগে সব principal minor \(\geq 0\) (যেকোনো row-column জোড়া বাদ দিয়ে), শুধু leading নয়। নিরাপদ পথ: eigenvalue দেখো। |
| "Gradient শূন্য মানেই minimum পেয়ে গেছি" | Gradient শূন্য শুধু "সমতল জায়গা" বলে — সেটা তলা, চূড়া, না ঘোড়ার জিন, বলে Hessian। ML-এ high-dimension-এ saddle point-ই সংখ্যাগরিষ্ঠ — \(n\)টা eigenvalue-এর সবগুলো একই চিহ্নের হওয়া কাকতালীয়ভাবে বিরল। |
| "PD হলেই optimization সহজ" | তলা আছে জানা আর দ্রুত পৌঁছানো এক নয় — \(\kappa = \lambda_{max}/\lambda_{min}\) বিশাল হলে gradient descent zigzag-এ ডুবে যায় (fig05)। PD বলে "পৌঁছানো সম্ভব", condition number বলে "কত দিনে"। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Quadratic form | \(Q(x) = x^TAx = \sum a_{ij}x_ix_j\) | matrix থেকে জন্মানো energy-surface |
| Positive definite | \(x^TAx > 0 \;\forall x \neq 0\) | bowl — মার্বেল তলায় থামে |
| পাঁচ সমতুল্য test | \(\lambda > 0\) ⇔ minors \(> 0\) ⇔ pivots \(> 0\) ⇔ \(A = R^TR\) ⇔ energy \(> 0\) | পাঁচ আয়নায় এক মুখ |
| \(2\times2\) শর্টকাট | \(a > 0\) এবং \(ac - b^2 > 0\) | calculus-এর second derivative test |
| Principal axes | \(A = Q\Lambda Q^T \Rightarrow Q(x) = \sum\lambda_iy_i^2\) | ellipse-এর axes = eigenvectors, অর্ধ-অক্ষ \(1/\sqrt{\lambda}\) |
| \(A^TA\) | সবসময় PSD; column independent হলে PD | \(\|Ax\|^2\) কখনো negative নয় |
| Hessian test | \(\nabla f = 0\) + \(H\) PD \(\Rightarrow\) minimum | \(f'' > 0\)-এর matrix সংস্করণ |
| Condition number | \(\kappa = \lambda_{max}/\lambda_{min}\) | গোল bowl দ্রুত, সরু উপত্যকা zigzag |
পরের chapter-এর সেতু: Spectral theorem-এর স্বপ্নটা মধুর — orthonormal অক্ষ, খাঁটি stretching — কিন্তু শর্ত কড়া: matrix-কে symmetric (এমনকি square!) হতে হবে। অথচ ডেটার জগতে matrix প্রায় সবসময় rectangular — \(m\)টা sample, \(n\)টা feature। তাহলে কি স্বপ্ন শেষ? না — এই chapter-এর \(A^TA\) (সবসময় symmetric PSD!) হবে গোপন সিঁড়ি: যেকোনো matrix-এর জন্য দুই দিকে দুটো orthonormal অক্ষ-সেট, মাঝে অ-negative stretching — Chapter 6.6: Singular Value Decomposition — linear algebra-র মুকুট।
📓 Notebook Project¶
notebooks/part-06/ch05-project.ipynb — পাঁচটা positive-definiteness test (eigenvalue, minor, pivot, Cholesky, energy) scratch-এ implement করে random symmetric matrix-দের ওপর মিলিয়ে দেখা যে পাঁচজনের রায় সবসময় এক; bowl/saddle/trough/dome-এর 3D গ্যালারি নিজে আঁকা; আর condition number \(\kappa\) বাড়িয়ে বাড়িয়ে gradient descent-এর ধাপসংখ্যা মেপে "zigzag-এর দাম" পরীক্ষা।