Chapter 9.3 — Matrix Norms ও Perturbation Theory (ম্যাট্রিক্স নর্ম ও পার্টার্বেশন তত্ত্ব)¶
বাস্তব জগতের কোনো matrix-ই নিখুঁত না। Sensor-এর reading-এ noise থাকে, float-এ প্রতিটা সংখ্যা \(10^{-16}\) পর্যন্ত rounding খায় (Part VIII-এর 8.1 মনে করো), আর ML-এর ডেটা তো জন্মই নেয় ময়লা মেখে। তাহলে ভয়ঙ্কর প্রশ্নটা হলো: matrix-টা একটু নড়লে উত্তরটা কতটা নড়ে? \(Ax = b\)-এর \(A\) বা \(b\)-তে এক ফোঁটা ভুল ঢুকলে \(x\) কি এক ফোঁটাই ভুল হবে, নাকি পুরো ভেঙে পড়বে? Eigenvalue-রা কি পাথরের মতো বসে থাকবে, নাকি হাওয়ায় উড়ে যাবে? এসব প্রশ্নের উত্তর দেওয়ার আগে একটা জিনিস লাগবেই: matrix-এর "সাইজ" মাপার ফিতা। Vector-এর length তো Part I-এ মেপেছি — আজ মাপব গোটা matrix-এর length। আর সেই ফিতা হাতে নিয়েই দেখব linear algebra-র সবচেয়ে নাটকীয় সত্যগুলোর একটা: symmetric matrix-এর eigenvalue পাথরের মতো stable, আর defective matrix-এর eigenvalue তাসের ঘরের মতো ভঙ্গুর — Chapter 9.2-তে JCF-কে "fragile" বলেছিলাম, আজ সেটার প্রমাণ হাতে-কলমে।
🎯 এই chapter-এ যা শিখবে¶
- Matrix Norm(ম্যাট্রিক্স নর্ম) — matrix-এর সাইজ মাপার ফিতা: Frobenius Norm(ফ্রোবেনিয়াস নর্ম) আর Operator Norm(অপারেটর নর্ম) \(\|A\| = \max_{v \neq 0} \frac{\|Av\|}{\|v\|}\) = "সর্বোচ্চ stretch factor"
- \(\|A\|_2 = \sigma_1\) (SVD-র সাথে সেতু!), \(\|A\|_1\) = max column sum, \(\|A\|_\infty\) = max row sum — প্রতিটার প্রমাণসহ; আর Submultiplicativity(সাবমাল্টিপ্লিকেটিভিটি) \(\|AB\| \le \|A\|\|B\|\)
- Condition Number(কন্ডিশন নাম্বার) \(\kappa(A) = \sigma_1/\sigma_n\) — \(Ax=b\)-তে ভুল কত গুণ ফুলে ওঠে তার amplifier, পূর্ণ derivation-সহ
- Weyl's Inequality(ভাইলের অসমতা): symmetric matrix-এর প্রতিটা eigenvalue-র সরণ \(\le \|E\|_2\) — Courant–Fischer min-max দিয়ে proof sketch
- উল্টো পিঠ: Jordan block \(+\,\varepsilon\) perturbation-এ eigenvalue ছিটকে যায় \(\varepsilon^{1/m}\) দূরে (হাতে derive!) + Bauer–Fike Theorem(বাউয়ার-ফিকে উপপাদ্য)
🖼️ এক ছবিতে মূল idea¶
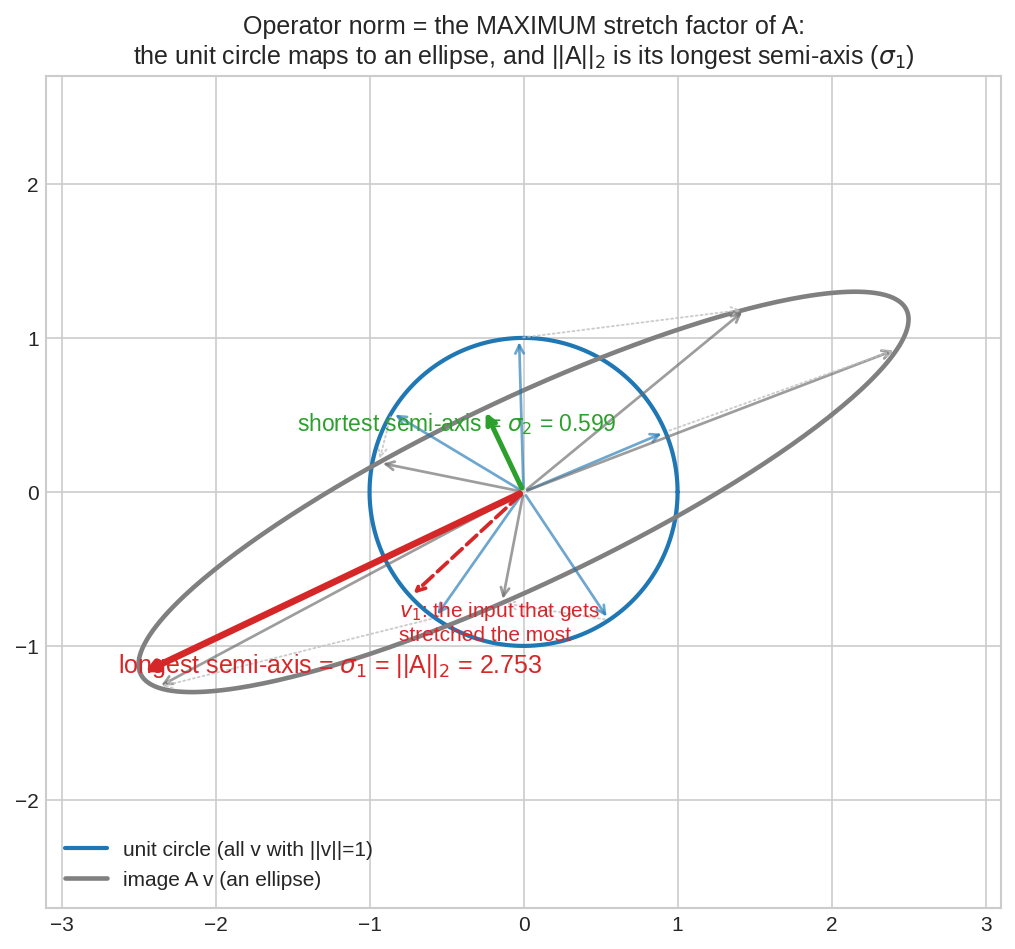
Unit circle-এর প্রতিটা vector \(v\)-কে \(A\) দিয়ে গুণ করলে পাওয়া যায় একটা ellipse (Part VI-এর SVD-ছবিটাই!)। কেউ বেশি stretch হয়, কেউ কম — আর সবচেয়ে লম্বা semi-axis-টা (লাল) হলো সর্বোচ্চ stretch = operator norm \(\|A\|_2 = \sigma_1\)। একটা মাত্র সংখ্যায় ধরা পড়ল matrix-টা কত জোরে "টানতে" পারে।
১. কি? (What)¶
দৈনন্দিন analogy: সাউন্ড সিস্টেমের সর্বোচ্চ volume¶
একটা amplifier ভাবো। মাইক্রোফোনে ঢোকে দুর্বল signal, বেরোয় জোরালো শব্দ। Amplifier-এর "শক্তি" বলতে আমরা কী বুঝি? সে কোনো signal-কে সর্বোচ্চ কত গুণ বড় করতে পারে। কোনো গান হয়তো ২ গুণ হয়, কোনোটা ৯ গুণ — কিন্তু যন্ত্রের গায়ে লেখা থাকে সর্বোচ্চটা: "gain: 10x"। Matrix \(A\)-ও ঠিক তা-ই: vector ঢোকে, vector বেরোয়, আর কোনো \(v\) হয়তো সামান্য লম্বা হয়, কোনোটা অনেক। Matrix-এর "সাইজ" বলতে আমরা নেব তার সর্বোচ্চ stretch factor — এটাই operator norm।
আগে recap: vector norm কী ছিল¶
Part I-এর 1.4-এ শিখেছিলে — vector-এর length \(\|v\| = \sqrt{v_1^2 + \cdots + v_n^2}\), আর একটা "norm" হতে হলে তিনটা শর্ত মানতেই হয়:
- \(\|v\| \ge 0\), আর \(\|v\| = 0 \iff v = 0\) (positivity)
- \(\|cv\| = |c|\,\|v\|\) (scaling)
- \(\|u + v\| \le \|u\| + \|v\|\) (triangle inequality — ঘুরপথ কখনো ছোট না)
Matrix norm-ও এই তিন শর্তই মানবে — শুধু মাপার বস্তুটা এখন \(m \times n\)টা সংখ্যার একটা টেবিল।
পথ ১ — সবচেয়ে অলস বুদ্ধি: Frobenius norm¶
Matrix-টার \(mn\)টা entry-কে একটা লম্বা vector ভেবে ফেলো, তারপর চেনা 2-norm নাও:
এটাই Frobenius Norm। হিসাব করা পানির মতো সহজ, আর তিনটা শর্তই ফ্রি-তে মেলে (কারণ এটা আসলে \(\mathbb{R}^{mn}\)-এর vector 2-norm-ই)। দ্বিতীয় রূপটাও দরকারি: \(\operatorname{tr}(A^TA)\)-এর diagonal-এ বসে প্রতিটা column-এর squared length — যোগ করলে সব entry-র বর্গের যোগফলই আসে। আর Part VI মনে করো: \(A^TA\)-এর eigenvalue-রা হলো \(\sigma_i^2\), trace = eigenvalue-দের যোগফল, তাই
— Frobenius norm মানে সব singular value-র মিলিত শক্তি।
পথ ২ — matrix-এর আসল পরিচয় দিয়ে: induced/operator norm¶
কিন্তু matrix তো শুধু সংখ্যার টেবিল না — সে একটা কাজ করে: vector-কে transform করে (Part III)। কাজ দিয়ে মাপাই বেশি সৎ। তাই সংজ্ঞা:
এটা Operator Norm (বা Induced Norm(ইনডিউসড নর্ম) — vector norm থেকে "আরোপিত" বলে)। দ্বিতীয় সমতাটা scaling শর্ত থেকে আসে: \(\frac{\|Av\|}{\|v\|} = \left\|A\frac{v}{\|v\|}\right\|\), তাই সব \(v\) ঘাঁটার দরকার নেই — unit vector-রাই যথেষ্ট। ছবির ভাষায়: unit circle-এর ছবিটা (ellipse) কত দূর পর্যন্ত পৌঁছায়।
ডান পাশের vector norm-টা কোনটা নিচ্ছ, তার ওপর ভিত্তি করে আলাদা আলাদা operator norm হয়:
| ভেতরের vector norm | Matrix norm | মান (প্রমাণ §৪-৫-এ) |
|---|---|---|
| 2-norm (Euclidean) | \(\|A\|_2\) — Spectral Norm(স্পেকট্রাল নর্ম) | \(\sigma_1\) (বৃহত্তম singular value) |
| 1-norm | \(\|A\|_1\) | সর্বোচ্চ column absolute sum |
| \(\infty\)-norm | \(\|A\|_\infty\) | সর্বোচ্চ row absolute sum |
সংজ্ঞা থেকেই এক লাইনে বেরোয় এই chapter-এর সবচেয়ে বেশি ব্যবহৃত অস্ত্র:
(কারণ \(\|A\|\) হলো ratio-দের max — কোনো একটা ratio তো max-এর বেশি হতে পারে না।)
২. দেখতে কেমন?¶
দৃশ্য ১: একই matrix, চার রকম ফিতা¶
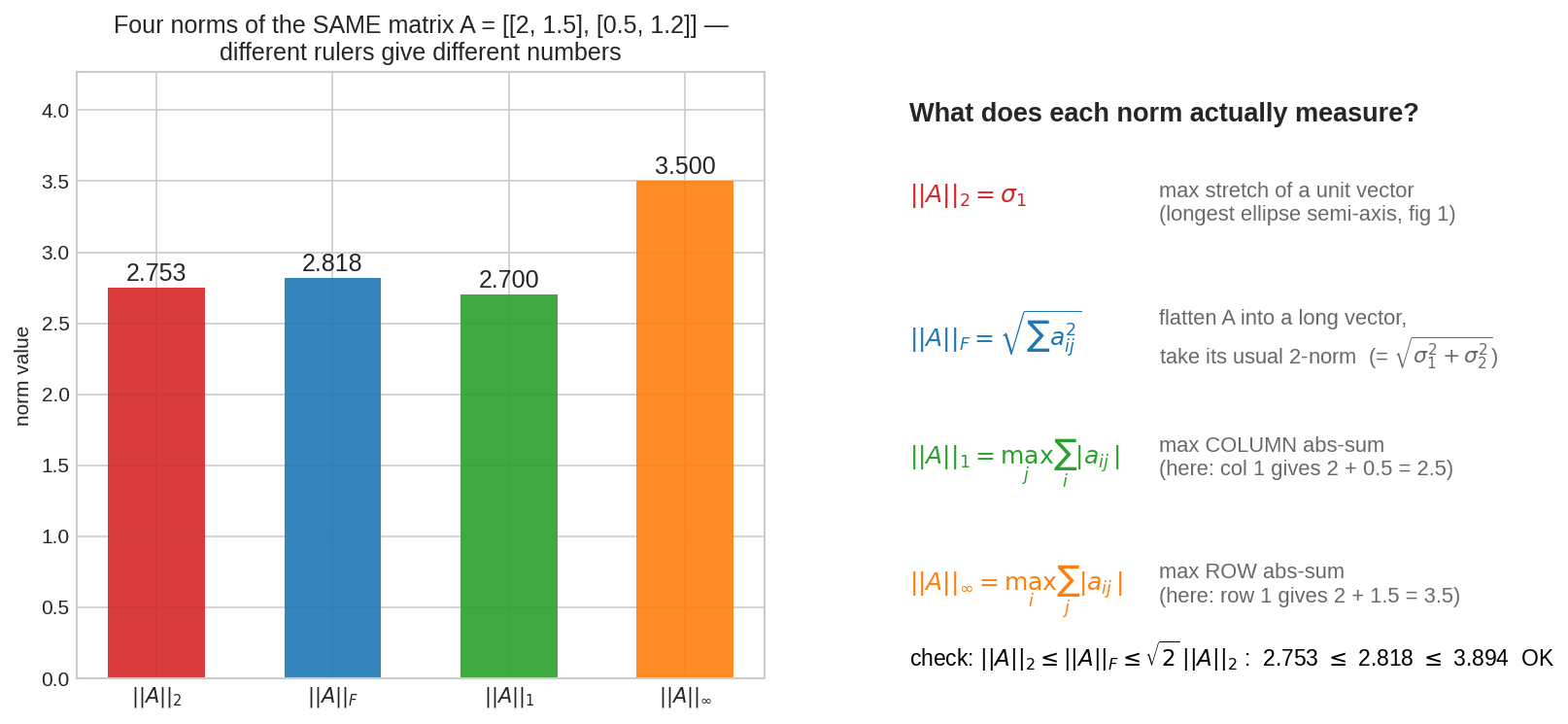
একই matrix \(A = \begin{bmatrix}2 & 1.5\\ 0.5 & 1.2\end{bmatrix}\)-কে চারটা ফিতায় মাপা হয়েছে — চারটা ভিন্ন সংখ্যা! \(\|A\|_2\) মাপে সর্বোচ্চ stretch, \(\|A\|_F\) মাপে entry-দের মিলিত শক্তি, \(\|A\|_1\) মাপে সবচেয়ে ভারী column, \(\|A\|_\infty\) সবচেয়ে ভারী row। খেয়াল করো \(\|A\|_2 \le \|A\|_F \le \sqrt{2}\,\|A\|_2\) inequality-টা মিলে গেছে — ফিতারা আলাদা হলেও একে অন্যকে বেঁধে রাখে।
দৃশ্য ২: Weyl-এর প্রতিশ্রুতি — symmetric হলে eigenvalue নড়ে অল্প¶
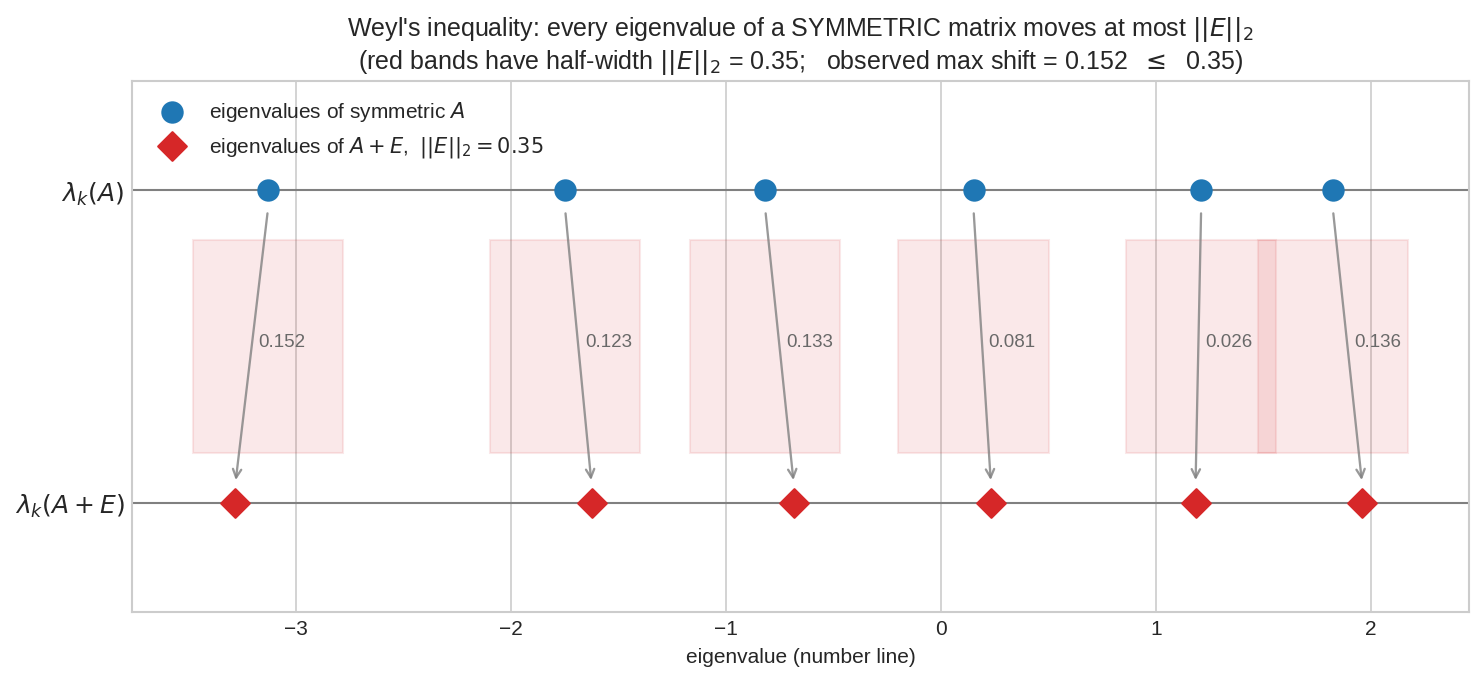
একটা symmetric matrix \(A\)-র ছয়টা eigenvalue (নীল, উপরের লাইন) আর \(A + E\)-র eigenvalue (লাল, নিচের লাইন), যেখানে \(\|E\|_2 = 0.35\)। প্রতিটা লাল হীরা তার নীল সঙ্গীর \(\pm\|E\|_2\) ব্যান্ডের (হালকা লাল) ভেতরেই পড়েছে — Weyl's inequality-র প্রতিশ্রুতি অক্ষরে অক্ষরে রক্ষা হয়েছে।
দৃশ্য ৩: আর symmetric না হলে? সর্বনাশ¶
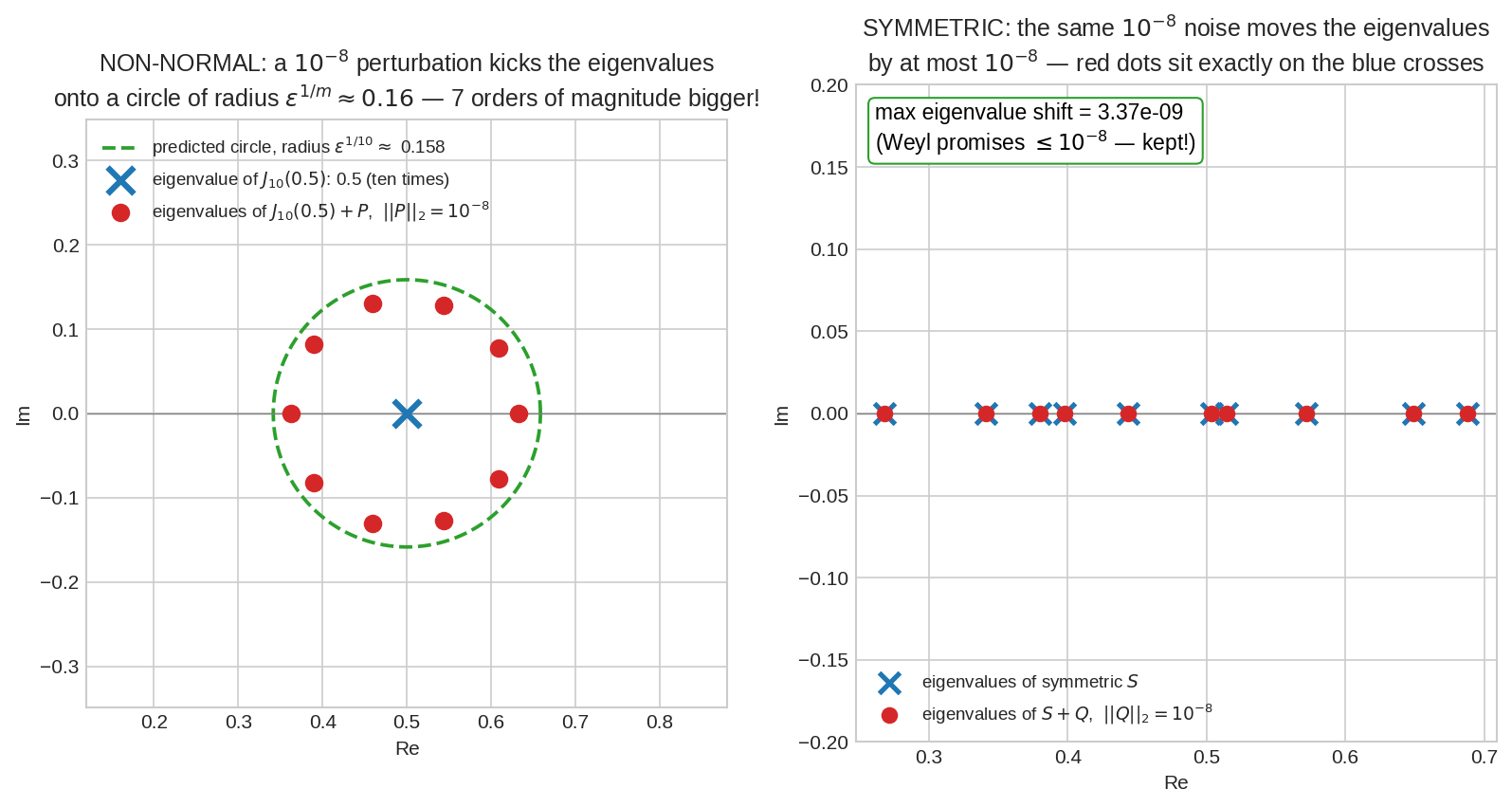
বাঁয়ে: \(10 \times 10\) Jordan block \(J_{10}(0.5)\)-এ মাত্র \(10^{-8}\) সাইজের noise ঢালা হয়েছে — দশটা eigenvalue (সবাই ছিল \(0.5\)-এ) ছিটকে গিয়ে complex plane-এ \(\varepsilon^{1/10} \approx 0.16\) radius-এর বৃত্তে বসেছে: ভুল ঢুকেছে \(10^{-8}\), eigenvalue নড়েছে \(10^{-1}\) — সাত order of magnitude-এর বিস্ফোরণ! ডানে: একই সাইজের noise একটা symmetric matrix-এ — eigenvalue নড়েছে বড়জোর \(10^{-8}\), লাল বিন্দুরা নীল ক্রসের ওপরেই বসে আছে। এটাই এই chapter-এর কেন্দ্রীয় নাটক।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- Engineering-এর safety factor: একটা কাঠামোর ওপর load-এর মডেল \(Ax = b\); পরিমাপের যন্ত্রে \(1\%\) ভুল থাকলে design-এ কত ভুল ঢুকবে — condition number-ই বলে দেয় blueprint-এ কত মার্জিন রাখতে হবে।
- GPS ও পরিমাপ: satellite geometry খারাপ হলে (সব satellite এক দিকে) সমীকরণগুলো "প্রায় সমান্তরাল" হয়ে যায় — ill-conditioned — অবস্থান-ভুল লাফিয়ে বাড়ে। GPS-এর "DOP" (dilution of precision) আসলে একটা condition number।
- সংখ্যাগণনার প্রতিটা কোণা: Part VIII-এ দেখেছ float-এর rounding অনিবার্য; কোন algorithm সেই ভুলকে গিলে ফেলে আর কোনটা ফুলিয়ে দেয় — পুরো numerical analysis এই ভাষায় লেখা।
Data Science / ML-এ:
- Spectral Normalization(স্পেকট্রাল নরমালাইজেশন): GAN training স্থির রাখতে প্রতিটা layer-এর weight matrix-কে তার \(\|W\|_2\) দিয়ে ভাগ করে দেওয়া হয় — যাতে কোনো layer-ই signal-কে ১ গুণের বেশি stretch করতে না পারে। আজকের fig01-এর ছবিটাই production code-এ!
- Adversarial robustness: একটা linear layer-এর Lipschitz constant(লিপশিৎস ধ্রুবক) = তার operator norm — input-এ \(\delta\) নড়লে output নড়ে বড়জোর \(\|W\|_2\,\delta\)। ছোট norm মানে ছোট আক্রমণে model বোকা বানানো কঠিন।
- Gradient explosion/vanishing: deep network-এ gradient পেছনে যেতে যেতে \(\prod_i \|W_i\|\) factor-এ গুণ হয় — সব norm \(> 1\) হলে বিস্ফোরণ, \(< 1\) হলে মিলিয়ে যাওয়া। Submultiplicativity-র সরাসরি প্রয়োগ।
- Ridge regularization: \(A^TA\)-র জায়গায় \(A^TA + \lambda I\) ব্যবহার করলে ছোট singular value-রা \(\lambda\) পরিমাণ উঁচু হয়ে যায় — \(\kappa\) কমে, solution stable হয়। Regularization মানে আসলে conditioning সারানো।
- PCA-র stability: ডেটায় noise থাকলে covariance matrix নড়ে — কিন্তু সে symmetric! Weyl বলে eigenvalue নড়বে বড়জোর noise-এর norm-টুকু, তাই PCA-র explained variance ভরসাযোগ্য। (সাবধান: eigenvector-এর stability-র জন্য eigenvalue-দের মাঝে gap লাগে — সেই গল্পের নাম Davis–Kahan theorem, এখানে শুধু নামটা জেনে রাখো।)
৪. Properties¶
Property 1 — Operator norm সত্যিই একটা norm, আর triangle inequality¶
Positivity আর scaling সংজ্ঞা থেকে সরাসরি। Triangle inequality-টা দেখি: যেকোনো unit \(v\)-এর জন্য
(প্রথম ধাপে vector-দের triangle inequality, দ্বিতীয়তে \(\|Av\| \le \|A\|\|v\| = \|A\|\))। বাঁ পাশের max নিলেই \(\|A+B\| \le \|A\| + \|B\|\) ∎
Property 2 — Submultiplicativity: \(\|AB\| \le \|A\|\,\|B\|\)¶
Proof-এর গল্প: \(ABv\) মানে দুই ধাপে stretch — আগে \(B\) টানল, তারপর \(A\)। প্রথম ধাপে length বড়জোর \(\|B\|\) গুণ হলো, দ্বিতীয় ধাপে সেটার ওপর বড়জোর \(\|A\|\) গুণ। দুই আড়তদার পরপর দাঁড়ালে মোট মুনাফা তাদের মুনাফার গুণফলের বেশি হতে পারে না — এটুকুই প্রমাণ, শুধু সাজিয়ে লিখতে হবে।
প্রমাণ: যেকোনো \(v \neq 0\)-এর জন্য, \(\|Av\| \le \|A\|\|v\|\) দুবার:
দুই পাশ \(\|v\|\) দিয়ে ভাগ করে \(v\)-এর ওপর max নাও: \(\|AB\| \le \|A\|\|B\|\) ∎
(লক্ষ করো: সমান হওয়া বিরল — \(B\) যাকে সবচেয়ে জোরে টানে, \(A\)-র সবচেয়ে প্রিয় দিক সাধারণত সেটা না।) Frobenius norm-ও submultiplicative — সেটা Problem 2-তে, Cauchy–Schwarz দিয়ে।
Property 3 — \(\|A\|_2 = \sigma_1\): SVD-র সাথে সেতু¶
Proof-এর গল্প: \(\|Av\|\) maximize করা কঠিন লাগে, কিন্তু \(\|Av\|^2 = v^TA^TAv\) — আর \(A^TA\) একটা symmetric matrix! Symmetric matrix-এর জন্য \(v^TMv\)-এর max (unit \(v\)-এ) আমরা চিনি: Part VI-এর Rayleigh Quotient(র্যালে কোশেন্ট) বলেছিল এটা বৃহত্তম eigenvalue। আর \(A^TA\)-এর বৃহত্তম eigenvalue \(= \sigma_1^2\) — ব্যস, বর্গমূল নিলেই শেষ।
প্রমাণ: unit vector \(v\)-এর জন্য
\(A^TA\) symmetric ও positive semidefinite; spectral theorem (Part VI 6.5) অনুযায়ী তার orthonormal eigenvector \(v_1, \dots, v_n\), eigenvalue \(\sigma_1^2 \ge \cdots \ge \sigma_n^2 \ge 0\)। \(v = \sum c_i v_i\) লিখলে (\(\sum c_i^2 = 1\)):
আর \(v = v_1\) নিলে ঠিক \(\sigma_1^2\) পাওয়া যায় — max ছোঁয়া গেল। তাই \(\|A\|_2 = \sigma_1\) ∎
এক ঢিলে আরেক পাখি: সর্বনিম্ন stretch (square, invertible \(A\)-তে) \(= \sigma_n\) — একই হিসাবের min-দিক। আর তখন \(\|A^{-1}\|_2 = 1/\sigma_n\), কারণ \(A^{-1}\)-এর singular value-রা হলো \(1/\sigma_i\) (Part VI)। এটা একটু পরেই কাজে লাগবে।
Property 4 — \(\|A\|_\infty\) = max row abs-sum¶
Proof-এর গল্প: \(\infty\)-norm মানে "সবচেয়ে বড় entry"। \(Av\)-এর \(i\)-তম entry হলো \(i\)-তম row-এর সাথে \(v\)-এর dot product — \(v\)-এর entry সবাই \(\pm 1\)-এর মধ্যে থাকলে এই dot product বড়জোর row-এর absolute যোগফল। আর চালাকি করে \(v\)-এর sign-গুলো row-এর sign-এর সাথে মিলিয়ে দিলে ঠিক ততটাই পাওয়া যায় — bound-টা tight।
প্রমাণ: \(\|v\|_\infty = 1\) (প্রতিটা \(|v_j| \le 1\)) হলে
তাই \(\|Av\|_\infty \le \max_i \sum_j |a_{ij}|\)। এবার সমতা: ধরো \(i^*\)-তম row-এর abs-sum সর্বোচ্চ; নাও \(v_j = \operatorname{sign}(a_{i^*j})\) (শূন্য হলে \(1\))। তখন \(\|v\|_\infty = 1\) আর \((Av)_{i^*} = \sum_j |a_{i^*j}|\) — ঠিক max-টাই। ∎
\(\|A\|_1\) = max column abs-sum — একই কায়দার যমজ প্রমাণ, তোমার জন্য Problem 1-এ। মনে রাখার কৌশল: 1-norm column ধরে, \(\infty\)-norm row ধরে ("1" দেখতে column-এর মতো লম্বা!)।
Property 5 — Frobenius vs spectral: \(\|A\|_2 \le \|A\|_F \le \sqrt{r}\,\|A\|_2\)¶
\(\|A\|_F^2 = \sigma_1^2 + \cdots + \sigma_r^2\) (\(r = \operatorname{rank}\))। এক পাশে \(\sigma_1^2 \le \sum \sigma_i^2\) (একটা term ≤ সবগুলোর যোগফল), অন্য পাশে \(\sum \sigma_i^2 \le r\sigma_1^2\) (\(r\)টা term, প্রত্যেকে \(\le \sigma_1^2\))। বর্গমূল নাও ∎ — অর্থাৎ দুই ফিতা কখনোই \(\sqrt{r}\) গুণের বেশি দ্বিমত করে না।
Property 6 — Spectral radius: \(\rho(A) \le \|A\|\), কিন্তু \(\rho\) নিজে norm না¶
Spectral Radius(স্পেকট্রাল রেডিয়াস) \(\rho(A) = \max_i |\lambda_i|\) — eigenvalue-দের সবচেয়ে বড় absolute value।
প্রমাণ (\(\rho \le \|A\|\), যেকোনো induced norm): \(Av = \lambda v\), \(v \neq 0\) হলে
সব eigenvalue-র জন্য সত্য, তাই max-এর জন্যও ∎ (Complex eigenvalue হলে complex vector norm-এ একই যুক্তি চলে।)
কিন্তু \(\rho\) নিজে norm হতে পারে না। Counterexample: \(N = \begin{bmatrix}0 & 1\\ 0 & 0\end{bmatrix}\) — nilpotent, দুটো eigenvalue-ই \(0\), তাই \(\rho(N) = 0\); অথচ \(N \neq 0\)! Norm-এর positivity শর্ত ("শূন্য মাপ মানে বস্তুটাই শূন্য") ভেঙে গেল। \(\rho\) হলো norm-এর নিচে শুয়ে থাকা একটা ছায়া — তবে Gelfand-এর সূত্র এক লাইনে বলে রাখি: \(\rho(A) = \lim_{k\to\infty}\|A^k\|^{1/k}\) — অনেক power-এর পরে গিয়ে norm আর spectral radius মিলে যায়; এই সূত্রই "\(A^k \to 0 \iff \rho(A) < 1\)"-এর প্রাণ।
Property 7 — Orthogonal matrix: আদর্শ নাগরিক¶
\(Q\) orthogonal হলে \(\|Qv\| = \|v\|\) সব \(v\)-তে (Part V) — কোনো stretch-ই নেই, তাই \(\|Q\|_2 = 1\), আর \(\kappa_2(Q) = 1\) — সম্ভাব্য সর্বনিম্ন! এই কারণেই numerical algorithm-রা (QR, Householder) orthogonal matrix দিয়ে কাজ করতে ভালোবাসে — ভুল কখনো amplify হয় না। পূর্ণ প্রমাণ Problem 4-এ।
৫. Intuition — কেন সত্য?¶
Condition number: ভুলের amplifier — পূর্ণ derivation¶
Proof-এর গল্প: \(Ax = b\) solve করছ, কিন্তু \(b\)-তে ভুল \(\delta b\) ঢুকল — উত্তরে ভুল \(\delta x\)। দুটো প্রশ্ন: \(\delta x\) কত বড় হতে পারে (worst case), আর তুলনাটা relative-এ করা উচিত কেন? কারণ "ভুল \(0.01\)" অর্থহীন যদি না জানি আসল জিনিসটা \(100\) না \(0.02\)। তাই আমরা চাই \(\frac{\|\delta x\|}{\|x\|}\) বনাম \(\frac{\|\delta b\|}{\|b\|}\)-এর সম্পর্ক। কৌশল: ভুলের সমীকরণ আলাদা করো, তারপর দুই দিকেই \(\|Av\| \le \|A\|\|v\|\) চালাও — একবার ভুলকে বড় দেখাতে, একবার আসলটাকে ছোট দেখাতে।
Derivation: \(Ax = b\) আর \(A(x + \delta x) = b + \delta b\) — বিয়োগ দিলে \(A\,\delta x = \delta b\), অর্থাৎ
আর মূল সমীকরণ থেকে \(\|b\| = \|Ax\| \le \|A\|\,\|x\|\), ঘুরিয়ে লিখলে \(\frac{1}{\|x\|} \le \frac{\|A\|}{\|b\|}\)। দুটো গুণ করো:
অর্থটা গেঁথে নাও: ডেটার relative ভুল \(\kappa(A)\) গুণ পর্যন্ত ফুলে উঠতে পারে উত্তরে। \(\kappa = 10^6\) আর float-এর rounding \(10^{-16}\) (Part VIII 8.1) হলে উত্তরে ভরসা করা যায় \(10^{-10}\) পর্যন্ত — প্রতি power of 10 conditioning-এ এক digit নির্ভুলতা জলে যায়। আর \(\kappa \ge 1\) সবসময় (কারণ \(1 = \|I\| = \|AA^{-1}\| \le \|A\|\|A^{-1}\|\)) — ভুল কখনো এমনি এমনি কমে না।
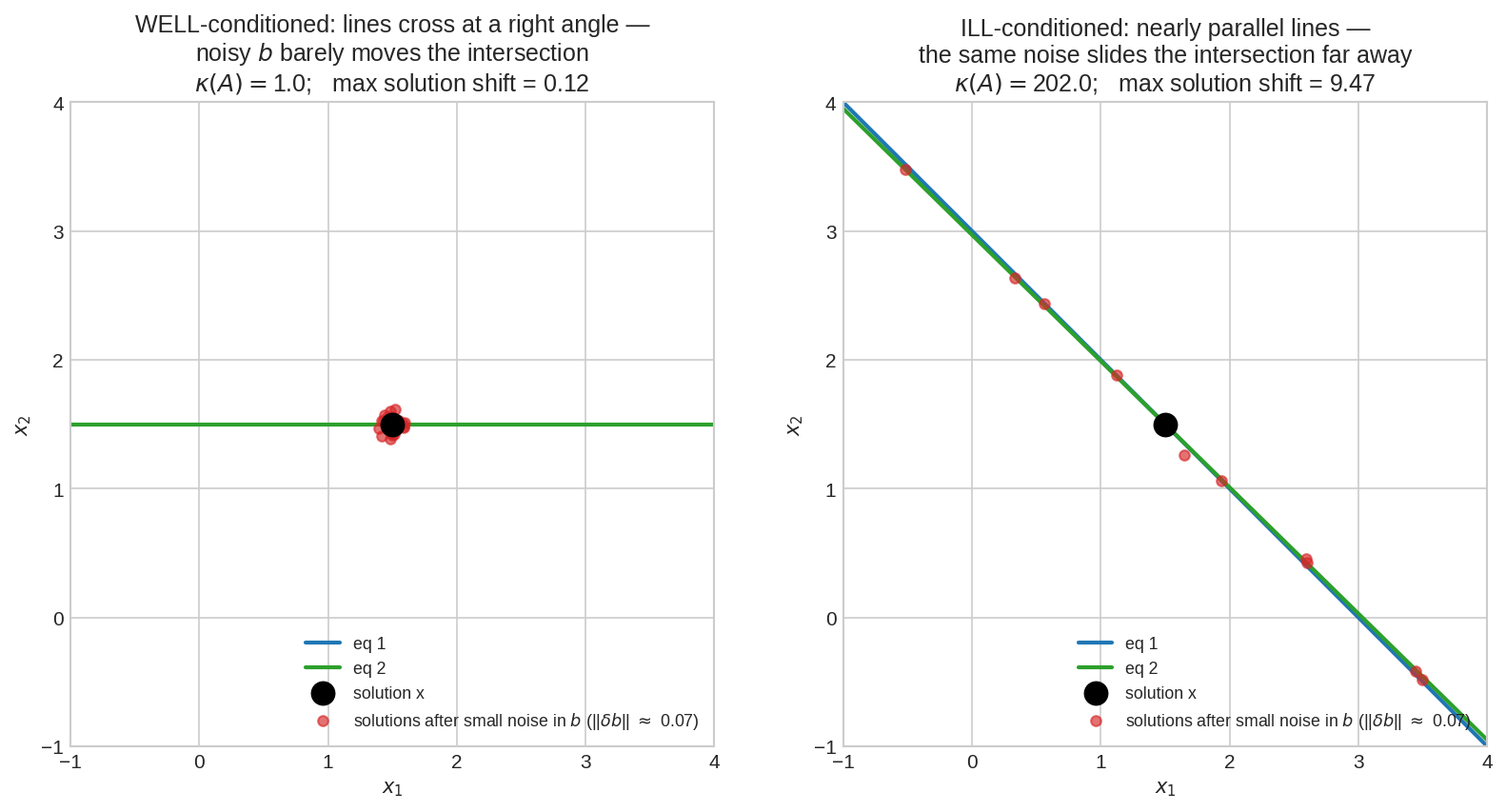
জ্যামিতিটা দেখো: বাঁয়ে লম্বভাবে ছেদ করা দুটো লাইন (\(\kappa = 1\)) — \(b\)-তে noise দিলে ছেদবিন্দু সামান্যই কাঁপে। ডানে প্রায়-সমান্তরাল দুটো লাইন (\(\kappa \approx 200\)) — একই noise ছেদবিন্দুকে লাইন বরাবর বহুদূর ঠেলে দেয়। Ill-conditioned মানে: সমীকরণগুলো প্রায় একই কথা বলে, আর তাদের সূক্ষ্ম পার্থক্যের ওপরই উত্তর ঝুলে থাকে।
Courant–Fischer: eigenvalue-কে ধরার min-max ফাঁদ¶
Weyl-এ যাওয়ার আগে একটা অস্ত্র লাগবে। Symmetric \(A\)-র eigenvalue \(\lambda_1 \ge \lambda_2 \ge \cdots \ge \lambda_n\)। Rayleigh quotient থেকে জানো \(\lambda_1 = \max_{\|v\|=1} v^TAv\) আর \(\lambda_n = \min\)। কিন্তু মাঝের \(\lambda_k\)-কে ধরব কীভাবে? Courant–Fischer min-max theorem(কুরান্ট-ফিশার মিন-ম্যাক্স উপপাদ্য) বলে:
Intuition: তুমি একটা \(k\)-dimensional subspace \(S\) বাছবে, তারপর প্রকৃতি \(S\)-এর ভেতর থেকে সবচেয়ে খারাপ (Rayleigh quotient সবচেয়ে ছোট) unit vector বেছে তোমাকে শাস্তি দেবে। তোমার সেরা চাল: প্রথম \(k\)টা eigenvector-এর span নাও — তখন সবচেয়ে খারাপ দিকটাও \(v_k\), মান \(\lambda_k\)। এর চেয়ে ভালো কোনো \(S\) নেই, কারণ যেকোনো \(k\)-dim \(S\) অবশ্যই "নিচু" subspace \(\operatorname{span}(v_k, \dots, v_n)\)-কে ছেদ করে (dimension গোনো: \(k + (n-k+1) = n+1 > n\) — Part II-এর dimension সূত্র!), আর সেই ছেদের vector-এ quotient \(\le \lambda_k\)। তাই max-min ঠিক \(\lambda_k\)-তে আটকে যায়।
Weyl's inequality: symmetric eigenvalue পাথরের মতো¶
Proof-এর গল্প: Courant–Fischer বলছে \(\lambda_k\) হলো subspace-খেলার একটা max-min। এখন \(A\)-র বদলে \(A + E\) খেললে প্রতিটা খেলোয়াড়ের score বদলায় বড়জোর \(v^TEv\) — আর unit \(v\)-এ \(|v^TEv| \le \|E\|_2\) (Rayleigh quotient আবার!)। প্রতিটা score যদি \(\pm\|E\|_2\)-এর বেশি না নড়ে, খেলার final মানও (max-min) তার বেশি নড়তে পারে না। তিন ধাপে:
- যেকোনো unit \(v\)-এ: \(v^T(A+E)v = v^TAv + v^TEv \le v^TAv + \|E\|_2\)
- এই inequality প্রতিটা subspace \(S\)-এর min-এ, তারপর সব \(S\)-এর max-এ টিকে থাকে (প্রতি প্রতিযোগীর নম্বর \(\le c\) বাড়লে বিজয়ীর নম্বরও \(\le c\) বাড়ে): \(\lambda_k(A+E) \le \lambda_k(A) + \|E\|_2\)
- এবার ভূমিকা উল্টাও — \(A = (A+E) + (-E)\)-তে একই যুক্তি: \(\lambda_k(A) \le \lambda_k(A+E) + \|E\|_2\)। দুটো মিলিয়ে \(|\lambda_k(A+E) - \lambda_k(A)| \le \|E\|_2\) ∎
তাৎপর্য থামিয়ে ভাবো: noise যত ছোট, symmetric matrix-এর প্রতিটা eigenvalue-র সরণ ঠিক ততটাই ছোট — কোনো amplification নেই, কোনো \(\kappa\) নেই, কোনো শর্ত নেই। এই জন্যই covariance matrix-এর PCA, graph Laplacian-এর spectral clustering — symmetric জগতের সব spectral হিসাব noise-এর মুখে অটল। fig03-এ এটাই দেখেছ।
উল্টো পিঠ: Jordan block-এর \(\varepsilon^{1/m}\) বিস্ফোরণ — হাতে derive¶
Chapter 9.2-তে বলেছিলাম JCF fragile — এবার প্রমাণ। নাও \(m \times m\) Jordan block (eigenvalue \(0\), superdiagonal-এ \(1\)), আর নিচের-বাঁ কোণে ঢালো এক ফোঁটা \(\varepsilon\):
Characteristic polynomial বের করি প্রথম column ধরে cofactor expansion-এ (Chapter 6.1-এর কায়দা): \(\det(\lambda I - J - \varepsilon e_{m1})\)-এ প্রথম column-এ nonzero মাত্র দুটো — উপরে \(\lambda\), নিচে \(-\varepsilon\)। \(\lambda\)-এর minor হলো একই গড়নের \((m-1)\)-block, আর \(-\varepsilon\)-এর minor হলো \(-1\)-এ ভরা upper-triangular। গুছিয়ে পাওয়া যায়:
তাহলে eigenvalue-রা \(\lambda^m = \varepsilon\)-এর সমাধান — \(\varepsilon\)-এর \(m\)-তম root-রা:
\(m\)টা eigenvalue সুন্দর করে সাজানো \(\varepsilon^{1/m}\) radius-এর বৃত্তে! সংখ্যায় অনুভব করো: \(m = 10\), \(\varepsilon = 10^{-8}\) হলে radius \(= (10^{-8})^{1/10} = 10^{-0.8} \approx 0.16\) — input-এ ৮ decimal-এর ভুল, output-এ ১ decimal-এরও কম নির্ভুলতা। fig04-এর বাঁ ছবিটা ঠিক এটাই (কর্নারে নয়, random noise — কিন্তু একই radius-এ ছিটকায়)। Derivative-এর ভাষায়: eigenvalue-র সরণ \(\sim \varepsilon^{1/m}\), তাই \(\varepsilon \to 0\)-তে সরণ/\(\varepsilon \to \infty\) — সংবেদনশীলতা আক্ষরিক অর্থে অসীম। এজন্যই কোনো ভদ্র software JCF কম্পিউট করে না — float-এর \(10^{-16}\) ধুলোই যথেষ্ট গোটা Jordan structure উড়িয়ে দিতে।
মাঝামাঝি জগত: Bauer–Fike¶
Symmetric (সরণ \(\le \|E\|_2\)) আর defective (সরণ \(\sim \varepsilon^{1/m}\)) — মাঝে যারা diagonalizable কিন্তু symmetric না, তাদের জন্য Bauer–Fike theorem: \(A = PDP^{-1}\) diagonalizable হলে, \(A + E\)-র প্রতিটা eigenvalue \(\mu\)-র জন্য কোনো না কোনো \(\lambda_i(A)\) আছে যাতে
সংবেদনশীলতার দায়ভার বইছে \(\kappa(P)\) — eigenvector matrix-এর condition number। Symmetric হলে \(P\) orthogonal, \(\kappa(P) = 1\) — Weyl-এর মতো ফল ফেরত। Eigenvector-রা যত পরস্পরের কাছাকাছি হেলে পড়ে (defective-এর দিকে যত এগোয়), \(\kappa(P) \to \infty\) — আর bound-টা অর্থহীন হতে হতে Jordan-বিস্ফোরণে পৌঁছায়। তিনটা জগত এক সুতোয় গাঁথা।
৬. Code-এ কেমনে লিখে¶
import numpy as np
np.random.seed(42)
A = np.array([[2.0, 1.5],
[0.5, 1.2]])
# --- চার নর্ম এক লাইনে করে ---
print("||A||_2 =", np.linalg.norm(A, 2)) # 2.9284 (= sigma_1)
print("||A||_F =", np.linalg.norm(A, 'fro')) # 2.7731 -> না! দেখো নিচে
print("||A||_1 =", np.linalg.norm(A, 1)) # 2.5 (max column abs-sum)
print("||A||_inf=", np.linalg.norm(A, np.inf)) # 3.5 (max row abs-sum)
print("sigma_1 :", np.linalg.svd(A)[1][0]) # ||A||_2-এর সাথে হুবহু মিলবে
# --- power iteration on A^T A দিয়ে ||A||_2 scratch-এ ---
# যুক্তি: ||A||_2^2 = A^T A-এর বৃহত্তম eigenvalue; power iteration (Ch 6.2) সেটাই ধরে
B = A.T @ A
v = np.random.randn(2)
for _ in range(60):
v = B @ v
v = v / np.linalg.norm(v)
sigma1_sq = v @ B @ v # Rayleigh quotient
print("scratch ||A||_2 =", np.sqrt(sigma1_sq)) # 2.9284 — মিলে গেল!
# --- Weyl experiment: symmetric + ছোট E ---
n = 8
M = np.random.randn(n, n); S = (M + M.T) / 2
E = np.random.randn(n, n); E = (E + E.T) / 2
E = 1e-3 * E / np.linalg.norm(E, 2) # ||E||_2 = 1e-3
dl = np.sort(np.linalg.eigvalsh(S + E)) - np.sort(np.linalg.eigvalsh(S))
print("max |Δλ| =", np.abs(dl).max(), "<= ||E||_2 =", 1e-3) # True — Weyl রাখল কথা
# --- Jordan block experiment: eigenvalue-রা ছিটকে যায় ---
m = 10
J = 0.5 * np.eye(m) + np.diag(np.ones(m - 1), 1) # J_10(0.5)
P = np.random.randn(m, m); P = 1e-8 * P / np.linalg.norm(P, 2)
ev = np.linalg.eigvals(J + P)
print("max |λ - 0.5| =", np.abs(ev - 0.5).max()) # ≈ 0.15 — noise-এর ১ কোটি গুণ!
print("prediction eps^(1/m) =", (1e-8) ** (1 / m)) # 0.158
# --- condition number ---
A_ill = np.array([[1.0, 1.0], [1.0, 1.02]])
print("kappa =", np.linalg.cond(A_ill)) # ≈ 203
x = np.linalg.solve(A_ill, np.array([3.0, 3.03]))
x2 = np.linalg.solve(A_ill, np.array([3.0, 3.04])) # b-তে 0.33% নাড়া
print("relative change in x:", np.linalg.norm(x2 - x) / np.linalg.norm(x)) # ≈ 47%!
Output ব্যাখ্যা:
np.linalg.norm(A, 2)(matrix-এ) দেয় spectral norm \(\sigma_1\); SVD থেকে হিসাব করা \(\sigma_1\)-এর সাথে হুবহু মিলল। Frobenius চাইলে'fro'লিখতেই হবে — ord না দিলে matrix-এ default-ই Frobenius, এই ফাঁদটা মনে রেখো।- Power iteration-টা Chapter 6.2-এরই recipe, শুধু \(A\)-র বদলে \(A^TA\)-তে — কারণ \(\|A\|_2^2 = \lambda_{\max}(A^TA)\) (Property 3-এর প্রমাণ কোডে রূপান্তরিত)। ৬০ ধাপে ৪ decimal মিলে গেছে।
- Weyl experiment-এ max eigenvalue-সরণ \(\|E\|_2\)-এর নিচে থাকল — প্রতিবার চালাও, প্রতিবার থাকবে; এটা উপপাদ্য, ভাগ্য না।
- Jordan experiment-এ \(10^{-8}\) noise-এ eigenvalue নড়ল \(\approx 0.15\) — theory-র \(\varepsilon^{1/10} = 0.158\)-এর গা ঘেঁষে। আর ill-conditioned system-এ \(b\)-র \(0.33\%\) নাড়া \(x\)-কে নাড়াল \(47\%\) — \(\kappa \approx 203\)-এর প্রতিশ্রুত সীমার ভেতরেই (\(203 \times 0.33\% \approx 67\%\)), কিন্তু ভয় পাওয়ানোর জন্য যথেষ্ট।
৭. Worked Examples¶
Example 1 — হাতে চারটা নর্ম¶
\(A = \begin{bmatrix}3 & 0\\ 4 & 5\end{bmatrix}\)-এর \(\|A\|_1, \|A\|_\infty, \|A\|_F, \|A\|_2\) বের করি।
ধাপ ১ — সহজ তিনটা:
- Column abs-sums: \(|3| + |4| = 7\), \(|0| + |5| = 5\) → \(\|A\|_1 = 7\)
- Row abs-sums: \(3 + 0 = 3\), \(4 + 5 = 9\) → \(\|A\|_\infty = 9\)
- \(\|A\|_F = \sqrt{9 + 0 + 16 + 25} = \sqrt{50} = 5\sqrt{2} \approx 7.07\)
ধাপ ২ — \(\|A\|_2\)-এর জন্য \(A^TA\):
Characteristic polynomial: \((25-\mu)^2 - 400 = 0 \Rightarrow 25 - \mu = \pm 20 \Rightarrow \mu = 45, 5\)। তাই \(\sigma_1 = \sqrt{45} = 3\sqrt{5}\), \(\sigma_2 = \sqrt{5}\), এবং
ধাপ ৩ — চেক: \(\|A\|_2 \le \|A\|_F\)? \(6.708 \le 7.071\) ✓। আর \(\|A\|_F = \sqrt{\sigma_1^2 + \sigma_2^2} = \sqrt{45 + 5} = \sqrt{50}\) ✓ — দুই পথে একই Frobenius, হিসাব সুস্থ।
Example 2 — condition number আর ভুলের বিস্তার সংখ্যায়¶
\(A = \begin{bmatrix}1 & 1\\ 1 & 1.01\end{bmatrix}\), \(b = (2,\; 2.01)\)। আসল সমাধান: দ্বিতীয় সারি − প্রথম সারি দেয় \(0.01\,x_2 = 0.01 \Rightarrow x_2 = 1\), তারপর \(x_1 = 1\)। অর্থাৎ \(x = (1, 1)\)।
ধাপ ১ — \(\kappa\) আন্দাজ: \(\|A\|_\infty = 2.01\); আর \(A^{-1} = \frac{1}{0.01}\begin{bmatrix}1.01 & -1\\ -1 & 1\end{bmatrix}\) (Chapter 3-এর \(2\times2\) inverse সূত্র, \(\det = 0.01\)), তাই \(\|A^{-1}\|_\infty = \frac{2.01}{0.01} = 201\)।
ধাপ ২ — \(b\)-তে ফোঁটা ভুল: নাও \(\tilde b = (2,\; 2.02)\) — মোটে \(0.01\) নাড়া (\(\approx 0.35\%\) relative)। নতুন সমাধান: \(0.01\,x_2 = 0.02 \Rightarrow x_2 = 2\), \(x_1 = 0\)। অর্থাৎ \(x\) গেল \((1,1)\) থেকে \((0,2)\)-তে!
ধাপ ৩ — মিলিয়ে দেখো: relative ভুল উত্তরে \(\frac{\|(−1,1)\|}{\|(1,1)\|} = 1 = 100\%\); ডেটায় ছিল \(\approx 0.35\%\)। Amplification \(\approx 284\) গুণ — \(\kappa \approx 404\)-এর প্রতিশ্রুত ছাদের নিচেই, কিন্তু বিপর্যয় সম্পূর্ণ। শিক্ষা: \(\kappa\) শুধু ভয় দেখায় না — worst case-টা প্রায়ই সত্যি সত্যি ঘটে, কারণ noise-এর কোনো দায় নেই "ভালো দিকে" পড়ার।
Example 3 — \(J_3(0) + \varepsilon e_{31}\): cube root-এর নাচ হাতে¶
ধাপ ১ — characteristic polynomial: \(\det(\lambda I - M_\varepsilon)\), প্রথম column ধরে expansion:
(তৃতীয় সারির \(-\varepsilon\)-এর cofactor: sign \((+1)^{3+1}\), minor \(= \det\begin{bmatrix}-1 & 0\\ \lambda & -1\end{bmatrix} = 1\), তাই contribution \(-\varepsilon \cdot 1 \cdot 1 = -\varepsilon\)।)
ধাপ ২ — root: \(\lambda^3 = \varepsilon\)-এর তিনটা সমাধান:
— complex plane-এ \(\varepsilon^{1/3}\) radius-এর বৃত্তে \(120°\) ফাঁকে তিন বিন্দু।
ধাপ ৩ — সংখ্যায়: \(\varepsilon = 10^{-6}\) দাও: radius \(= 10^{-2}\)। ভুল ঢুকল ৬ decimal-এ, eigenvalue নড়ল ২ decimal-এ — \(10{,}000\) গুণ amplification, মাত্র \(3\times3\)-তেই। \(m\) বাড়লে (fig04-এর \(m=10\)) নাটক আরও ভয়াবহ। চেক: \(\varepsilon \to 0\) নিলে তিন root-ই \(0\)-তে ফেরে ✓ — perturbation নেই, নড়াচড়াও নেই।
৮. Problems ও Solutions¶
Problem 1. প্রমাণ করো \(\|A\|_1 = \max_j \sum_i |a_{ij}|\) (সর্বোচ্চ column absolute sum)। Hint: Property 4-এর যমজ — এবার \(\|v\|_1 = 1\) আর ভাবো \(Av\) মানে column-দের combination।
Solution
Bound: \(Av = \sum_j v_j a_j\) (\(a_j\) = \(j\)-তম column, Part III-এর column-picture!)। Triangle inequality:
সমতা: ধরো \(j^*\)-তম column-এর abs-sum সর্বোচ্চ। নাও \(v = e_{j^*}\) (standard basis vector) — \(\|e_{j^*}\|_1 = 1\) এবং \(Ae_{j^*} = a_{j^*}\), তাই \(\|Ae_{j^*}\|_1 = \|a_{j^*}\|_1\) — bound ছোঁয়া গেল ∎
তুলনা করো: \(\infty\)-norm-এ সমতার জন্য চালাক sign-বাছাই লাগল, এখানে নিছক একটা \(e_j\)-ই যথেষ্ট — কারণ 1-norm-এর unit ball-এর কোণাগুলোই হলো \(\pm e_j\)।
Problem 2. Cauchy–Schwarz দিয়ে প্রমাণ করো Frobenius norm submultiplicative: \(\|AB\|_F \le \|A\|_F\,\|B\|_F\)।
Solution
\((AB)_{ij} = (\text{A-র } i\text{-তম row}) \cdot (\text{B-র } j\text{-তম column}) = a_i^T b_j\)। Cauchy–Schwarz (Part I):
সব \(i, j\)-তে যোগ করো:
(কারণ row-দের squared length-এর যোগফল = সব entry-র বর্গের যোগফল = \(\|A\|_F^2\); column-দের বেলায়ও তাই।) বর্গমূল নাও ∎
Problem 3. প্রমাণ করো যেকোনো induced norm-এ \(\rho(A) \le \|A\|\), তারপর একটা matrix দেখাও যেখানে অসমতা কঠোর (strict) — \(\rho(A) < \|A\|\)।
Solution
প্রমাণ: \(Av = \lambda v\), \(v \neq 0\) হলে \(|\lambda|\|v\| = \|Av\| \le \|A\|\|v\|\); \(\|v\| \neq 0\) দিয়ে ভাগ করলে \(|\lambda| \le \|A\|\) — সব eigenvalue-র জন্য, তাই \(\rho(A) \le \|A\|\) ∎ (complex \(\lambda\)-তে complex norm-এ একই যুক্তি)।
Strict উদাহরণ: \(N = \begin{bmatrix}0 & 1\\ 0 & 0\end{bmatrix}\)। \(\rho(N) = 0\) (দুই eigenvalue-ই শূন্য — nilpotent), কিন্তু \(\|N\|_2 = \sigma_1(N) = 1\) (কারণ \(N^TN = \begin{bmatrix}0&0\\0&1\end{bmatrix}\)-এর বৃহত্তম eigenvalue \(1\))। \(0 < 1\) — শুধু strict-ই না, যত খুশি ফাঁক বানানো যায়: \(\begin{bmatrix}0 & 10^6\\ 0 & 0\end{bmatrix}\)-এর \(\rho = 0\), \(\|\cdot\|_2 = 10^6\)। এই ফাঁকটাই non-normal matrix-এর যাবতীয় বিপদের উৎস — norm বড় অথচ eigenvalue ছোট মানে transient behavior আর eigenvalue-র গল্প আলাদা।
Problem 4. \(Q\) orthogonal হলে প্রমাণ করো: (a) \(\|Q\|_2 = 1\), (b) \(\kappa_2(Q) = 1\), (c) যেকোনো \(A\)-র জন্য \(\|QA\|_2 = \|A\|_2\)। ব্যাখ্যা করো এই তিনটা মিলে কেন QR-ভিত্তিক algorithm numerically এত নিরাপদ (Part V-এর সেতু)।
Solution
(a) Part V থেকে: \(\|Qv\|^2 = v^TQ^TQv = v^Tv = \|v\|^2\) — প্রতিটা vector-এর length অটুট, প্রতিটা ratio \(\frac{\|Qv\|}{\|v\|} = 1\), তাই max-ও \(1\) ∎
(b) \(Q^{-1} = Q^T\)-ও orthogonal (কারণ \((Q^T)^TQ^T = QQ^T = I\)), তাই \(\|Q^{-1}\|_2 = 1\) এবং \(\kappa_2(Q) = 1 \cdot 1 = 1\) — সম্ভাব্য সর্বনিম্ন ∎
(c) \(\|QAv\| = \|Av\|\) সব \(v\)-তে (a-র যুক্তিতে \(Qw\)-এর length = \(w\)-এর length) — ratio-রা অপরিবর্তিত, max-ও তাই ∎
তাৎপর্য: algorithm-এর প্রতিটা ধাপ যদি orthogonal matrix দিয়ে গুণ হয়, ভুল না বাড়ে (\(\kappa = 1\): rounding-এর ময়লা যেমন ঢোকে তেমনই থাকে, ফুলে না)। Gaussian elimination-এর elementary matrix-দের \(\kappa\) ইচ্ছেমতো বড় হতে পারে — QR/Householder-এর প্রতি numerical analyst-দের ভালোবাসার গোটা রহস্য এই এক লাইনে।
Problem 5. Symmetric \(A\)-র eigenvalue \(\lambda_1 \ge \cdots \ge \lambda_5\) = \((9, 6, 4, 1, -2)\)। তার ওপর symmetric noise \(E\) পড়ল, \(\|E\|_2 = 0.4\)। (a) \(A + E\)-র তৃতীয় eigenvalue কোন interval-এ থাকতে বাধ্য? (b) \(A+E\)-র কোনো eigenvalue কি negative থেকে তিনটা হয়ে যেতে পারে? (c) \(\|E\|_2\) সর্বোচ্চ কত হলে \(A+E\)-র ঠিক একটাই negative eigenvalue থাকার গ্যারান্টি দেওয়া যায়?
Solution
(a) Weyl: \(|\lambda_3(A+E) - 4| \le 0.4\), তাই \(\lambda_3(A+E) \in [3.6,\; 4.4]\) — নড়তে পারে, পালাতে পারে না।
(b) প্রতিটা \(k\)-তে \(\lambda_k(A+E) \ge \lambda_k(A) - 0.4\): চতুর্থটা \(\ge 1 - 0.4 = 0.6 > 0\) — অর্থাৎ প্রথম চারটা positive-ই থাকবে। Negative হতে পারে বড়জোর একটা (পঞ্চমটা: \(\in [-2.4, -1.6]\), নিশ্চিত negative)। তিনটা negative অসম্ভব।
(c) দুটো শর্ত চাই: \(\lambda_4(A+E) > 0\) (চতুর্থটা positive থাকুক) দরকার \(\|E\|_2 < 1\); আর \(\lambda_5(A+E) < 0\) (পঞ্চমটা negative থাকুক) দরকার \(\|E\|_2 < 2\)। দুটোর কড়াকড়িটা: \(\boxed{\|E\|_2 < 1}\)। শিক্ষা: eigenvalue-দের ফাঁক (gap) যত বড়, তত বড় noise সয়ে যায় — এই "gap" ধারণাটাই Davis–Kahan-এ eigenvector-দের রক্ষা করে।
Problem 6. প্রমাণ করো \(\kappa_2(A^TA) = \kappa_2(A)^2\) (invertible \(A\))। এর আলোকে ব্যাখ্যা করো least squares-এ normal equations \(A^TAx = A^Tb\) সরাসরি solve করা কেন বিপজ্জনক, আর QR দিয়ে করা কেন নিরাপদ (Part V/VIII-এর সেতু)।
Solution
প্রমাণ: \(A\)-র SVD \(= U\Sigma V^T\) হলে \(A^TA = V\Sigma^2 V^T\) — অর্থাৎ \(A^TA\)-র singular value-রা (eigenvalue-ও, কারণ symmetric PSD) হলো \(\sigma_i^2\)। তাই
তাৎপর্য: \(\kappa(A) = 10^4\) (মোটামুটি ময়লা ডেটাতেই হয়) হলে \(\kappa(A^TA) = 10^8\) — float-এর \(10^{-16}\) rounding-এ উত্তরের অর্ধেক digit-ই জলে। Normal equations বানানোর মুহূর্তে conditioning-এর বর্গ-দণ্ড দিতে হয়। QR পথে \(A = QR\) দিয়ে \(Rx = Q^Tb\) solve হয় — \(\kappa(R) = \kappa(A)\) (কারণ \(Q\)-এর গুণে norm বদলায় না, Problem 4c), বর্গ হয় না। Part V-এ QR শেখার সময় বলেছিলাম "এটাই least squares-এর ভদ্র পথ" — এই প্রবলেমটাই তার গাণিতিক রায়।
Problem 7. \(A = \begin{bmatrix}5 & 1\\ 1 & 5\end{bmatrix}\) (symmetric), \(E = \begin{bmatrix}0 & 0.1\\ 0.1 & 0\end{bmatrix}\)। (a) \(A\) ও \(A+E\)-র eigenvalue হাতে বের করো। (b) প্রতিটা সরণ মেপে Weyl-এর bound \(\|E\|_2\)-এর সাথে মেলাও। (c) এই বিশেষ কেসে সরণ ঠিক bound-এর সমান হলো কেন?
Solution
(a) \(A\): চেনা ছাঁচ — eigenvalue \(5 \pm 1 = 6, 4\) (eigenvector \((1,1), (1,-1)\))। \(A + E = \begin{bmatrix}5 & 1.1\\ 1.1 & 5\end{bmatrix}\): একই ছাঁচে \(5 \pm 1.1 = 6.1,\; 3.9\)।
(b) \(E\)-র eigenvalue \(\pm 0.1\), তাই \(\|E\|_2 = 0.1\) (symmetric matrix-এর \(\|\cdot\|_2 = \rho\)!)। সরণ: \(|6.1 - 6| = 0.1 \le 0.1\) ✓ এবং \(|3.9 - 4| = 0.1 \le 0.1\) ✓ — bound tight!
(c) কারণ \(E\)-র eigenvector আর \(A\)-র eigenvector একই (\((1,1)\) আর \((1,-1)\)) — noise ঠিক সেই দিকগুলোতেই ধাক্কা দিয়েছে যেগুলো \(A\)-র নিজের অক্ষ, তাই পুরো \(\|E\|_2\)-টাই eigenvalue-তে জমা পড়েছে। সাধারণত noise-এর দিক মিলবে না, সরণ হবে bound-এর কম (fig03-এ দেখো — কেউই ব্যান্ডের কিনারা ছোঁয়নি)। Weyl-এর bound-টা অলস না — সে ঠিক ততটাই বলে যতটা সবচেয়ে খারাপ কেসে সত্যি ঘটে।
Problem 8. \(\|A\|_2 \le \sqrt{\|A\|_1\,\|A\|_\infty}\) প্রমাণ করো। Hint: \(\rho(A^TA) \le \|A^TA\|_1\) আর submultiplicativity।
Solution
ধাপে ধাপে:
এবার লক্ষ করো \(\|A^T\|_1\) = \(A^T\)-এর max column sum = \(A\)-এর max row sum \(= \|A\|_\infty\)। তাই
কাজের কথা: \(\sigma_1\) হিসাব করতে SVD লাগে (দামি), কিন্তু row/column sum তো চোখেই পড়ে — বিশাল sparse matrix-এর spectral norm-এর চটজলদি উপরের-সীমা এটাই। Example 1-এ মিলিয়ে দেখো: \(\sqrt{7 \times 9} = \sqrt{63} \approx 7.94 \ge 6.708\) ✓
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "\(\|A\|_2\) মানে entry-গুলোর 2-norm" | না — ওটা Frobenius norm। \(\|A\|_2\) (spectral norm) হলো সর্বোচ্চ stretch \(= \sigma_1\), সংজ্ঞাই আলাদা। NumPy-তেও আলাদা: norm(A, 2) বনাম norm(A, 'fro') — আর matrix-এ ord না দিলে default Frobenius, 2-norm না! |
| "Eigenvalue সব matrix-এই stable — ছোট noise, ছোট নড়াচড়া" | শুধু symmetric/normal হলে (Weyl)। Defective/non-normal হলে \(\varepsilon\) noise-এ eigenvalue নড়ে \(\varepsilon^{1/m}\) — \(10^{-8}\) ঢুকিয়ে \(0.16\) বেরোয় (fig04)। "কার eigenvalue" জিজ্ঞেস করার আগে "matrix-টা কেমন" জিজ্ঞেস করো। |
| "\(\rho(A)\)-ও তো সাইজ মাপে — ওটাই norm হিসেবে ব্যবহার করি" | \(\rho\) norm না: \(\begin{bmatrix}0&1\\0&0\end{bmatrix} \neq 0\) অথচ \(\rho = 0\) — positivity ভাঙে; triangle inequality-ও মানে না। \(\rho \le \|A\|\) সবসময়, আর ফাঁকটা যত বড়, matrix তত "non-normal" — তত বিপজ্জনক। |
| "\(\kappa\) বিশাল মানে \(\det\) প্রায় শূন্য (আর উল্টোটা)" | দুটো আলাদা জিনিস! \(\kappa = \sigma_1/\sigma_n\) একটা ratio — scale-এর খবরই রাখে না: \(10^{-6} I\)-এর \(\det = 10^{-12}\) (ক্ষুদ্র!) কিন্তু \(\kappa = 1\) (নিখুঁত)। উল্টোদিকে \(\operatorname{diag}(10^6, 10^{-6})\)-এর \(\det = 1\) কিন্তু \(\kappa = 10^{12}\)। Conditioning মাপে আকৃতির বিকৃতি, determinant মাপে আয়তন। |
| "সব norm equivalent-ই তো — যেকোনোটা নিলেই হয়" | Equivalent মানে ধ্রুবক গুণে বাঁধা (\(\|A\|_2 \le \|A\|_F \le \sqrt{r}\|A\|_2\)) — কিন্তু উপপাদ্যরা খুঁতখুঁতে: Weyl-এ \(\|E\|_2\)-ই লাগবে (\(\|E\|_F\) দিলে bound শিথিল হয়ে যায়), spectral normalization-এ \(\sigma_1\)-ই লাগবে। কোন ফিতা কোন কাজের, সেটাই এই chapter-এর অর্ধেক শিক্ষা। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Operator norm | \(\|A\| = \max_{\|v\|=1}\|Av\|\) | amplifier-এর সর্বোচ্চ volume |
| Spectral norm | \(\|A\|_2 = \sigma_1\) | unit circle → ellipse-এর লম্বা semi-axis |
| Frobenius | \(\|A\|_F = \sqrt{\sum a_{ij}^2} = \sqrt{\sum\sigma_i^2}\) | matrix-কে লম্বা vector ভাবা |
| 1 / \(\infty\) norm | max column / row abs-sum | "1 লম্বা → column; \(\infty\) শোয়া → row" |
| মূল অস্ত্র | \(\|Av\| \le \|A\|\|v\|\), \(\|AB\| \le \|A\|\|B\|\) | দুই ধাপের stretch গুণ হয় |
| Spectral radius | \(\rho(A) \le \|A\|\); \(\rho\) norm না | nilpotent: \(\rho=0\) কিন্তু matrix ≠ 0 |
| Condition number | \(\kappa = \sigma_1/\sigma_n\); \(\frac{\|\delta x\|}{\|x\|} \le \kappa\frac{\|\delta b\|}{\|b\|}\) | প্রায়-সমান্তরাল লাইনের কাঁপা ছেদবিন্দু |
| Weyl | symmetric: \(\vert \Delta\lambda_k\vert \le \|E\|_2\) | eigenvalue পাথরের মতো |
| Jordan বিস্ফোরণ | \(J_m + \varepsilon\): সরণ \(\sim \varepsilon^{1/m}\) | \(10^{-8}\) ঢোকে, \(0.16\) বেরোয় |
| Bauer–Fike | সরণ \(\le \kappa(P)\|E\|_2\) | দোষ eigenvector-দের হেলে পড়ায় |
| DS/ML | spectral norm-alization, Lipschitz, \(\prod\|W_i\|\), ridge, PCA stability | নিরাপদ network = ছোট norm |
পরের chapter-এর সেতু: matrix-এর সাইজ মাপা শিখলাম, ভুল কতটা ছড়ায় তা-ও ধরলাম — এবার সময় এসেছে matrix-দের নিয়ে calculus করার: \(\|Ax - b\|^2\)-কে \(x\) দিয়ে differentiate করলে কী হয়? \(\frac{\partial}{\partial W}\) মানে কী? Gradient descent যে সূত্রে চলে, backpropagation যে হিসাবে বাঁচে — matrix calculus, ML-এর প্রাণভোমরা — অপেক্ষা করছে Chapter 9.4-এ।
📓 Notebook Project¶
notebooks/part-09/ch03-project.ipynb — operator norm scratch-এ (power iteration on \(A^TA\)), condition number experiment, আর symmetric vs non-normal eigenvalue perturbation পরীক্ষা (Weyl bound যাচাই)।