Chapter 3.6 — Linear Transformation, Formally (linearity-র আসল সংজ্ঞা)¶
🎯 এই chapter-এ যা শিখবে¶
- Linear transformation(রৈখিক রূপান্তর)-এর আনুষ্ঠানিক সংজ্ঞা — মাত্র দুটো শর্ত: additivity ও homogeneity
- সেই দুই শর্তের জ্যামিতিক চেহারা: গ্রিডলাইন সোজা, সমান্তরাল ও সমান-দূরত্বে থাকে, আর origin অনড়
- এক নজরে linear/না-linear চেনার কৌশল — আর স্কুলের "\(y = mx + c\) মানেই linear" ধারণাটা কোথায় ভাঙে
- Part III-এর মুকুট-উপপাদ্য: প্রতিটা linear transformation-ই একটা matrix — কেন, কিভাবে matrix-টা বানায়
- Linearity কত বড় পরিবার: derivative, integral, expectation — Data Science-এর অর্ধেক জগৎ আসলে linear
🖼️ এক ছবিতে মূল idea¶
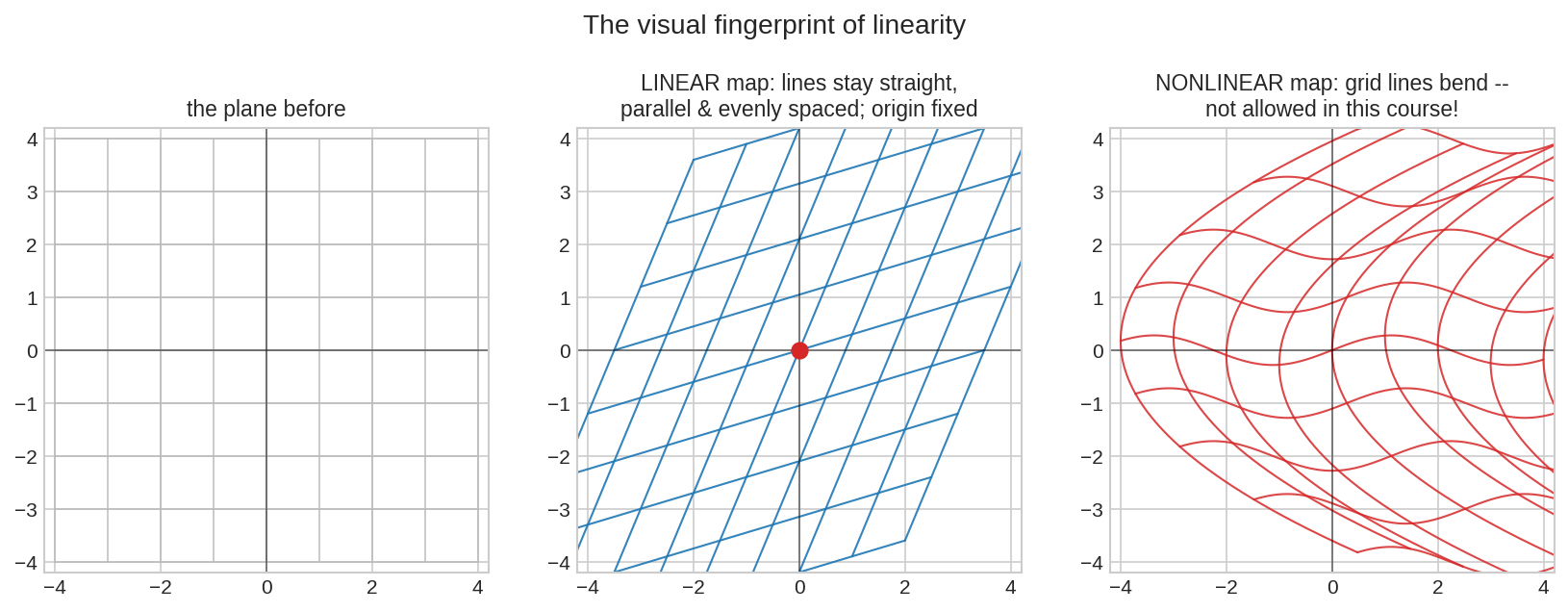
বাঁয়ে বিশ্রামরত plane। মাঝে একটা linear map — গ্রিডলাইন হেলেছে, চেপেছে, কিন্তু প্রতিটা লাইন এখনো নিখুঁত সোজা, সমান্তরালরা সমান্তরাল, ঘরগুলো সমান মাপের, আর লাল origin ঠায় বসে আছে। ডানে একটা nonlinear map — লাইনগুলো ঢেউ খেয়ে বেঁকে গেছে; এই কোর্সের transformation-দের জন্য ওটা নিষিদ্ধ এলাকা। এই chapter-এ শিখব: "বাঁকেনি" কথাটার সঠিক গাণিতিক রূপ ঠিক দুটো সমীকরণ।
১. কি? (What)¶
পাঁচটা chapter ধরে আমরা বলে আসছি "matrix মানে linear transformation" — কিন্তু একটা দেনা জমে আছে: linear শব্দটার আদালত-গ্রাহ্য সংজ্ঞা। আজ শোধের দিন। আর মজাটা হলো — এতদিনের সব ছবি (সোজা গ্রিড, অনড় origin, column-মন্ত্র) এই এক সংজ্ঞা থেকেই গড়িয়ে বেরোবে।
দৈনন্দিন analogy: একটা দোকানকে "ন্যায্য" বলব কখন? (১) দুই ব্যাগ আলাদা আলাদা কিনলে যে দাম, একসাথে কিনলেও সেই দাম — যোগে কারচুপি নেই; (২) তিনগুণ মাল কিনলে ঠিক তিনগুণ দাম — স্কেলে কারচুপি নেই (কোনো "৩টা কিনলে ১টা ফ্রি" নাটক নেই)। Linear transformation হলো vector-জগতের সেই কারচুপিহীন দোকান।
সংজ্ঞা: একটা function \(L : \mathbb{R}^n \to \mathbb{R}^m\)-কে linear transformation বলব যদি সব vector \(\mathbf{u}, \mathbf{v}\) আর সব সংখ্যা \(c\)-এর জন্য:
দুটো শর্তের সুর একই: "আগে মেশাও পরে transform করো" = "আগে transform করো পরে মেশাও।" শর্ত ১ যোগ নিয়ে বলে, শর্ত ২ scaling নিয়ে। দুটোকে এক লাইনে গেঁথেও লেখা যায় — linear হওয়া মানে linear combination-এর ভেতর দিয়ে নির্বিঘ্নে হেঁটে যাওয়া:
এই এক লাইনের নামই superposition(উপরিপাতন) নীতি — physics-এ তরঙ্গ, circuit-এ current, statistics-এ expectation — যেখানেই এই নীতি খাটে, সেখানেই linear algebra ঢুকে পড়ে।
Chapter 3.1-এর §৪.৩-এ আমরা প্রমাণ ছাড়া বলেছিলাম matrix-গুণ এই দুই নিয়ম মানে। খেয়াল করো আজকের সংজ্ঞাটা উল্টো দিক থেকে আসছে: matrix-এর নামগন্ধ নেই — শুধু function আর দুটো শর্ত। Chapter-এর শেষে দেখব দুই রাস্তা একই জায়গায় মেশে: শর্ত-মানা প্রতিটা function-ই আসলে ছদ্মবেশী matrix।
২. দেখতে কেমন?¶
দুটো শর্তের প্রত্যেকটার একটা করে ছবি আছে — আর দুটোই "সমান্তরাল-জগতের" গল্প।
শর্ত ১-এর ছবি — parallelogram বেঁচে থাকে:
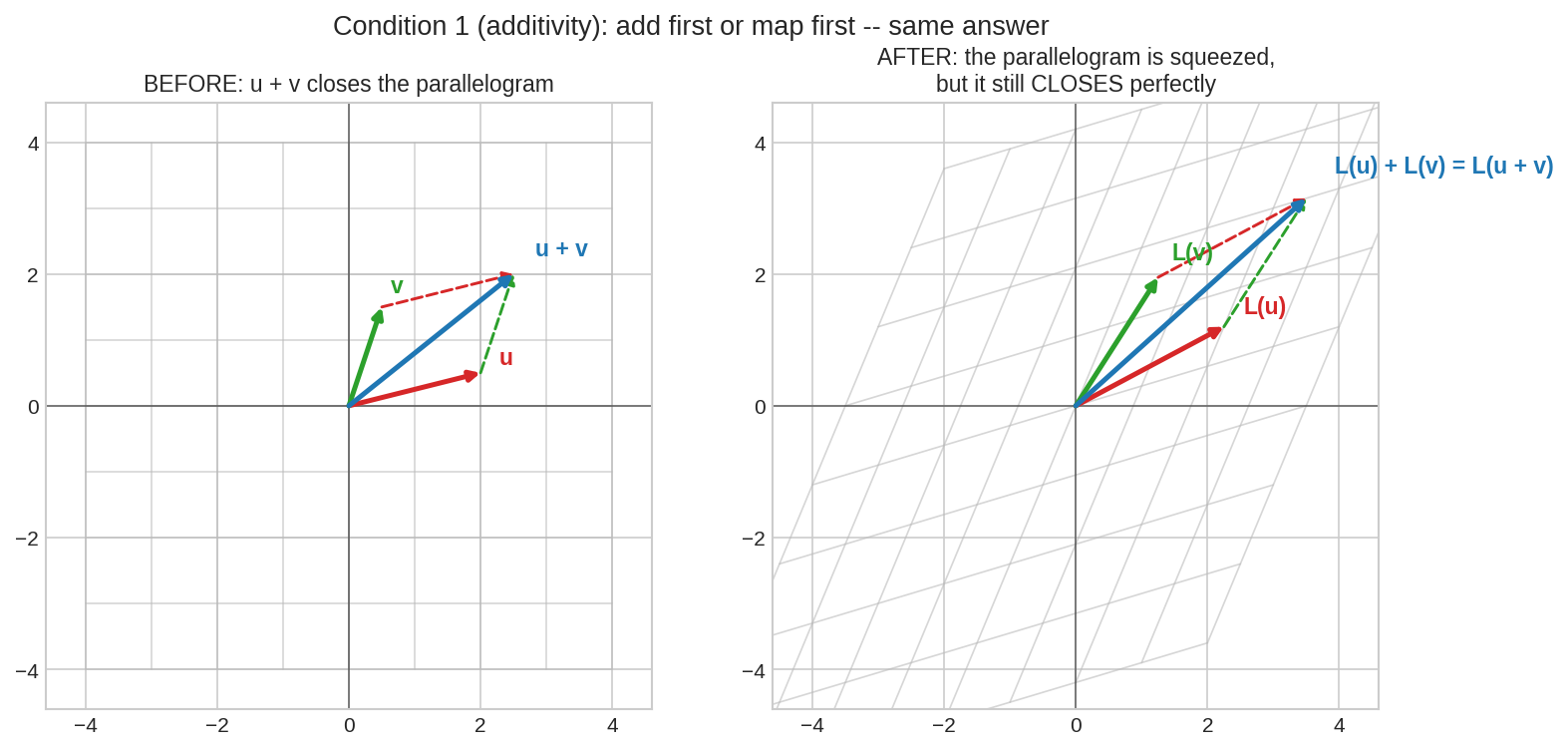
বাঁয়ে: \(\mathbf{u} + \mathbf{v}\) মানে Part I-এর parallelogram-নিয়ম — দুই তীরের কোনাকুনি। ডানে: transformation-এর পরে \(L(\mathbf{u})\) আর \(L(\mathbf{v})\) দিয়ে গড়া parallelogram চাপা-হেলানো হয়ে গেছে, কিন্তু এখনো নিখুঁতভাবে বন্ধ হয় — তার কোনাকুনিটাই ঠিক \(L(\mathbf{u}+\mathbf{v})\)। যোগের জ্যামিতি transformation-কে অক্ষত পার হয়।
শর্ত ২-এর ছবি — একই লাইনে, একই অনুপাতে:
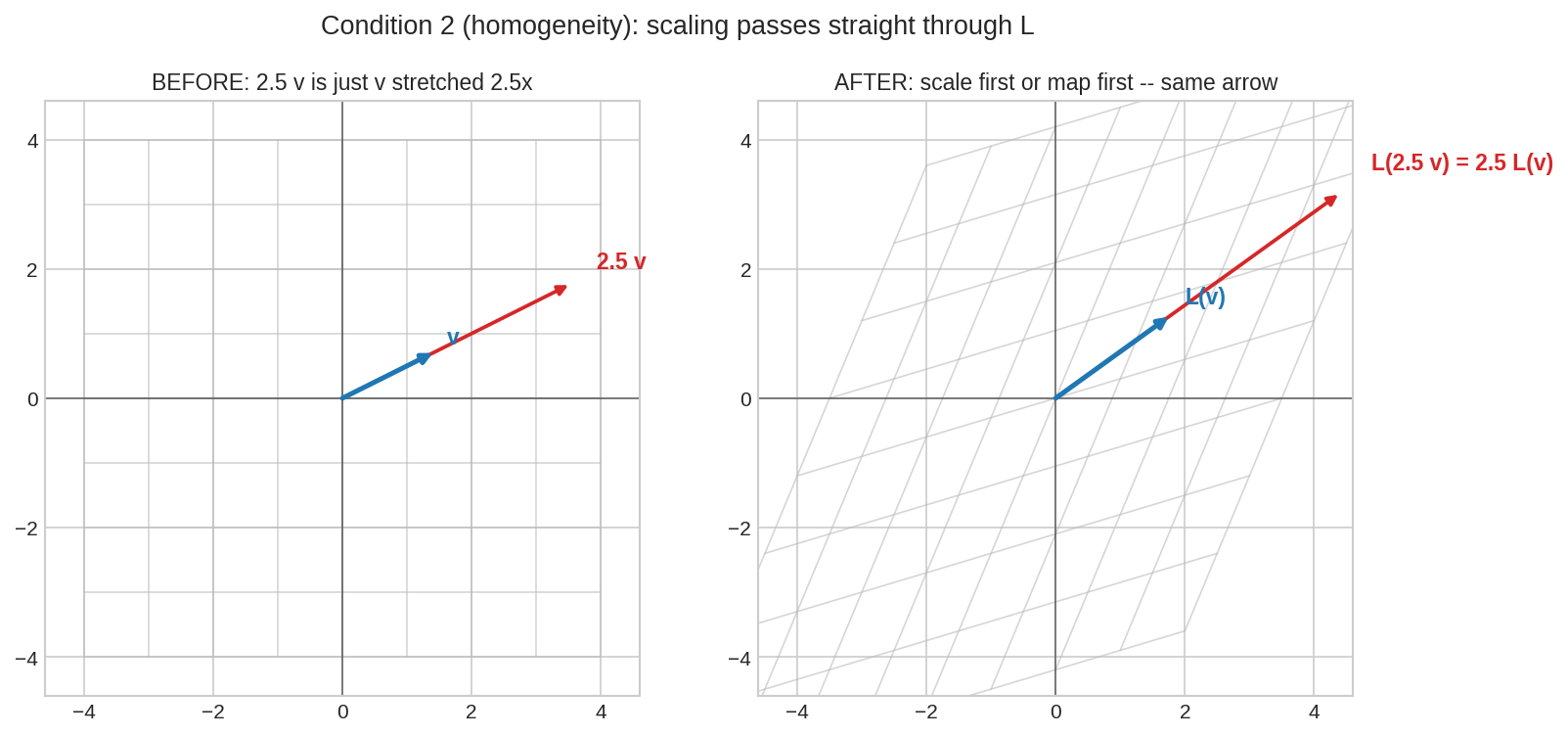
বাঁয়ে: \(2.5\mathbf{v}\) মানে \(\mathbf{v}\)-এরই লাইনে আড়াই গুণ লম্বা তীর। ডানে: map করার পরেও \(L(2.5\mathbf{v})\) হলো ঠিক \(L(\mathbf{v})\)-এর লাইনে আড়াই গুণ — অনুপাতটা transformation ভাঙতে পারে না। এ কারণেই সমান-দূরত্বের গ্রিডলাইন সমান-দূরত্বেই থাকে: \(\mathbf{v}, 2\mathbf{v}, 3\mathbf{v}, \dots\) সমান ধাপে ছিল, \(L(\mathbf{v}), 2L(\mathbf{v}), 3L(\mathbf{v}), \dots\)-ও সমান ধাপেই।
আর দুই শর্ত মিলে যে চেহারাটা দাঁড়ায়, সেটাই opening figure-এর মাঝের প্যানেল: সোজা লাইন সোজা থাকে (লাইন মানে \(\mathbf{p} + t\mathbf{d}\) — linearity তাকে \(L(\mathbf{p}) + t\,L(\mathbf{d})\) বানায়, যেটাও একটা লাইন), সমান্তরাল থাকে সমান্তরাল (একই \(\mathbf{d}\), ভিন্ন \(\mathbf{p}\)), ব্যবধান থাকে সমান (homogeneity), আর origin থাকে origin-এই (§৪.১-এ প্রমাণ)। 3Blue1Brown-এর সেই বিখ্যাত বাক্য — "grid lines remain parallel and evenly spaced" — আসলে এই দুই সমীকরণের ছবি-অনুবাদ।
৩. কোথায় ইউজ হয়?¶
- Calculus-এর দুই স্তম্ভই linear! Derivative: \((f + g)' = f' + g'\) আর \((cf)' = cf'\) — হুবহু শর্ত ১, ২। Integral-ও তাই। তাই derivative-কেও matrix দিয়ে লেখা যায় (Worked Example 3-এ সত্যিই লিখব!) — আর এই সংযোগই পরে Fourier, differential equation-এ linear algebra-র প্রবেশপথ।
- Expectation (Part VII-এর নায়ক): \(E[X + Y] = E[X] + E[Y]\), \(E[cX] = cE[X]\) — সম্ভাবনার গড় একটা linear operator। Statistics-এর অর্ধেক প্রমাণ এই linearity-র কাঁধে চড়ে।
- Image filter/convolution: blur, sharpen, edge-detect — সবই linear: দুই ছবি যোগ করে filter চালাও, বা আলাদা চালিয়ে যোগ করো — একই ফল। এজন্যই convolution-কে (বিশাল) matrix হিসেবে লেখা যায়, CNN-এর তত্ত্ব সেখান থেকেই।
- Neural network-এর দুই মেরু: প্রতিটা layer-এর \(W\mathbf{x}\) অংশ linear; কিন্তু ReLU-র মতো activation ইচ্ছা করেই nonlinear — কারণ linear-এর পর linear চাপালে ফল আবার linear (Problem 5), পুরো গভীর network চুপসে একটা matrix হয়ে যেত! কোথায় linearity চাই আর কোথায় ভাঙতে চাই — এই বোঝাটাই deep learning-এর নকশা।
- Signal processing-এর superposition: দুই সুর একসাথে বাজাও — speaker-এর (আদর্শ) response দুই আলাদা response-এর যোগ। যন্ত্র nonlinear হয়ে গেলে যা শোনো তার নাম distortion!
৪. Properties¶
৪.১ ছোট কিন্তু ধারালো: \(L(\mathbf{0}) = \mathbf{0}\)¶
প্রমাণ এক লাইনে — homogeneity-তে \(c = 0\) বসাও:
অর্থাৎ origin নড়ল মানেই linear নয় — আর কিছু দেখারই দরকার নেই। এটাই সবচেয়ে সস্তা আর সবচেয়ে ধারালো test:
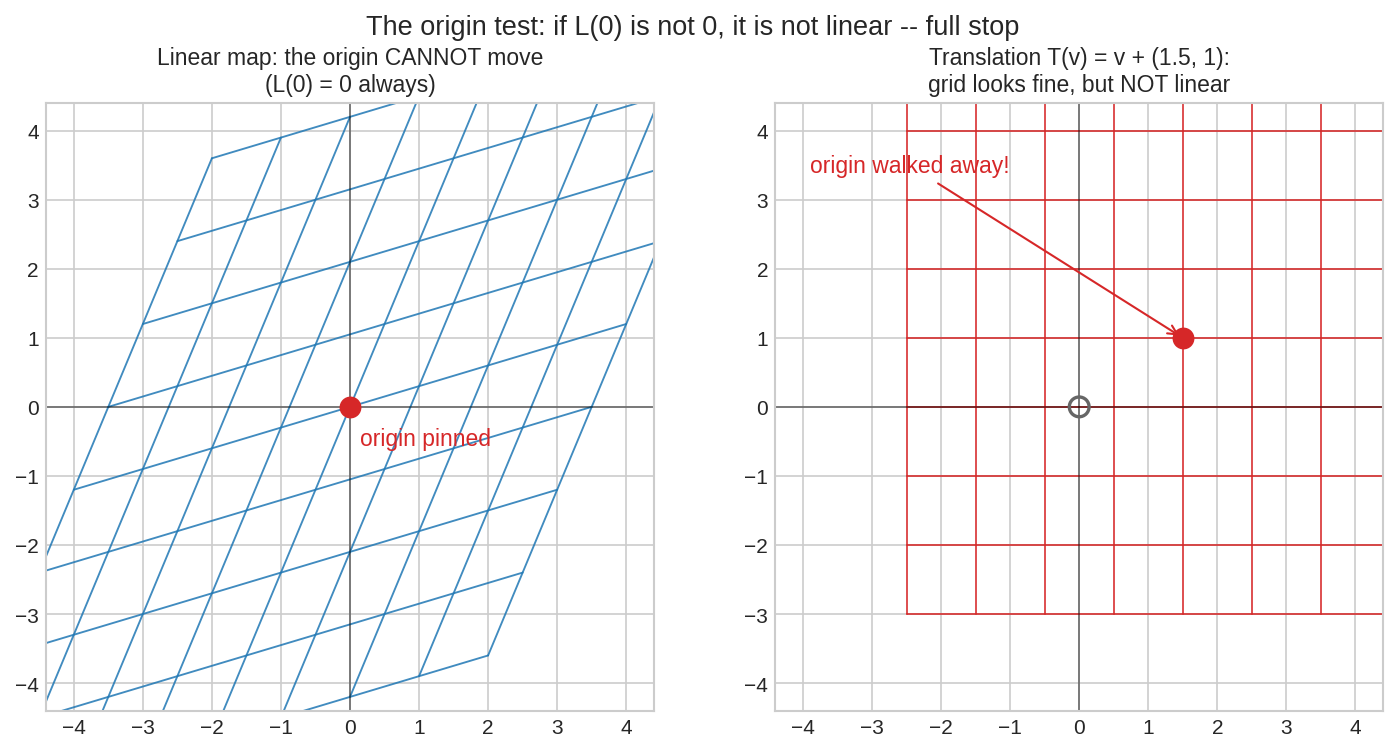
বাঁয়ে: linear map — লাল origin পিন-করা। ডানে: translation \(T(\mathbf{v}) = \mathbf{v} + (1.5, 1)\) — গ্রিড দেখো, সোজা-সমান্তরাল-সমান, সব ঠিকঠাক! কিন্তু origin হেঁটে চলে গেছে \((1.5, 1)\)-এ। শুধু গ্রিডের চেহারায় ভুলো না — origin test-এ সে ফেল, অতএব linear নয়, অতএব কোনো matrix তাকে লিখতে পারে না। (Chapter 3.1-এ এই কথাটাই ছুঁয়ে গিয়েছিলাম; এখন হাতে প্রমাণ।)
৪.২ দুই শর্তের সমান দুই পাল্লা — একটাও ছাড় নেই¶
দুটো শর্ত একটার থেকে আরেকটা আসে না — প্রত্যেকে আলাদা পাহারাদার:
- \(f(x, y) = (x + y^2,\; y)\): origin ঠিক আছে (\(f(0,0) = (0,0)\)), কিন্তু \(f(2(0,1)) = f(0,2) = (4, 2)\) আর \(2f(0,1) = 2(1,1) = (2,2)\) — homogeneity ফেল। Nonlinear।
- \(f(x) = |x|\) (\(\mathbb{R} \to \mathbb{R}\)): \(|x + y| \le |x| + |y|\) — যোগে মাঝে মাঝে মেলে, কিন্তু \(f(-3) = 3 \neq -3 = (-1)f(3)\) — ঋণাত্মক scaling-এ ধরা। Nonlinear।
৪.৩ Linear-দের বংশরক্ষা¶
- Composition: \(L, M\) linear হলে \(M \circ L\) (আগে \(L\) পরে \(M\))-ও linear (Problem 5) — এজন্যই matrix-গুণ আবার matrix দেয়, Chapter 3.3-এর পুরো গল্পটা সম্ভব হয়।
- যোগ ও scalar গুণ: \(L + M\), \(cL\)-ও linear — linear map-রা নিজেরাই একটা vector space গড়ে (PhD-পথের প্রথম উঁকি: function-রাও vector!)।
- Inverse: invertible linear map-এর উল্টোটাও linear — undo বোতামও পরিবারেই থাকে।
৪.৪ মুকুট-উপপাদ্য: linear ⟺ matrix¶
উপপাদ্য: \(L : \mathbb{R}^n \to \mathbb{R}^m\) linear হলে ঠিক একটাই \(m \times n\) matrix \(A\) আছে যার জন্য সব \(\mathbf{x}\)-এ \(L(\mathbf{x}) = A\mathbf{x}\); আর \(A\)-র \(j\)-তম column হলো \(L(\mathbf{e}_j)\)। উল্টোদিকে, প্রতিটা matrix-গুণই linear।
অর্থাৎ "linear transformation" আর "matrix" একই মুদ্রার দুই পিঠ: একটা হলো ধারণা (শর্ত-মানা function), আরেকটা তার সংখ্যায়-লেখা ঠিকানা (basis-দের গন্তব্যের তালিকা)। প্রমাণ §৫-এ — Part III-এর সব সুতো ওখানে এক গিঁটে বাঁধা পড়বে।
৫. Intuition — কেন সত্য?¶
কেন দুটো তীরই পুরো plane-এর ভাগ্য লিখে দেয়? এটাই মুকুট-উপপাদ্যের প্রাণ, আর যুক্তিটা তিন লাইনের। যেকোনো \(\mathbf{x} = (x_1, \dots, x_n)\)-কে basis-এ ভাঙো: \(\mathbf{x} = x_1\mathbf{e}_1 + \cdots + x_n\mathbf{e}_n\)। এবার \(L\) চালাও আর দুই শর্তকে পরপর কাজ করতে দাও:
ডান পাশে যা দাঁড়াল সেটা পড়ে দেখো: "\(L(\mathbf{e}_j)\)-গুলোকে column বানিয়ে সাজানো matrix"-এর সাথে \(\mathbf{x}\)-এর গুণ — হুবহু Chapter 3.1-এর column picture! অতএব \(A = \big[\,L(\mathbf{e}_1) \;\; L(\mathbf{e}_2) \;\cdots\; L(\mathbf{e}_n)\,\big]\) নিলেই \(L(\mathbf{x}) = A\mathbf{x}\)। আর \(A\) অনন্য, কারণ column-গুলো \(L\)-ই ঠিক করে দিয়েছে — পছন্দের কোনো জায়গা নেই।
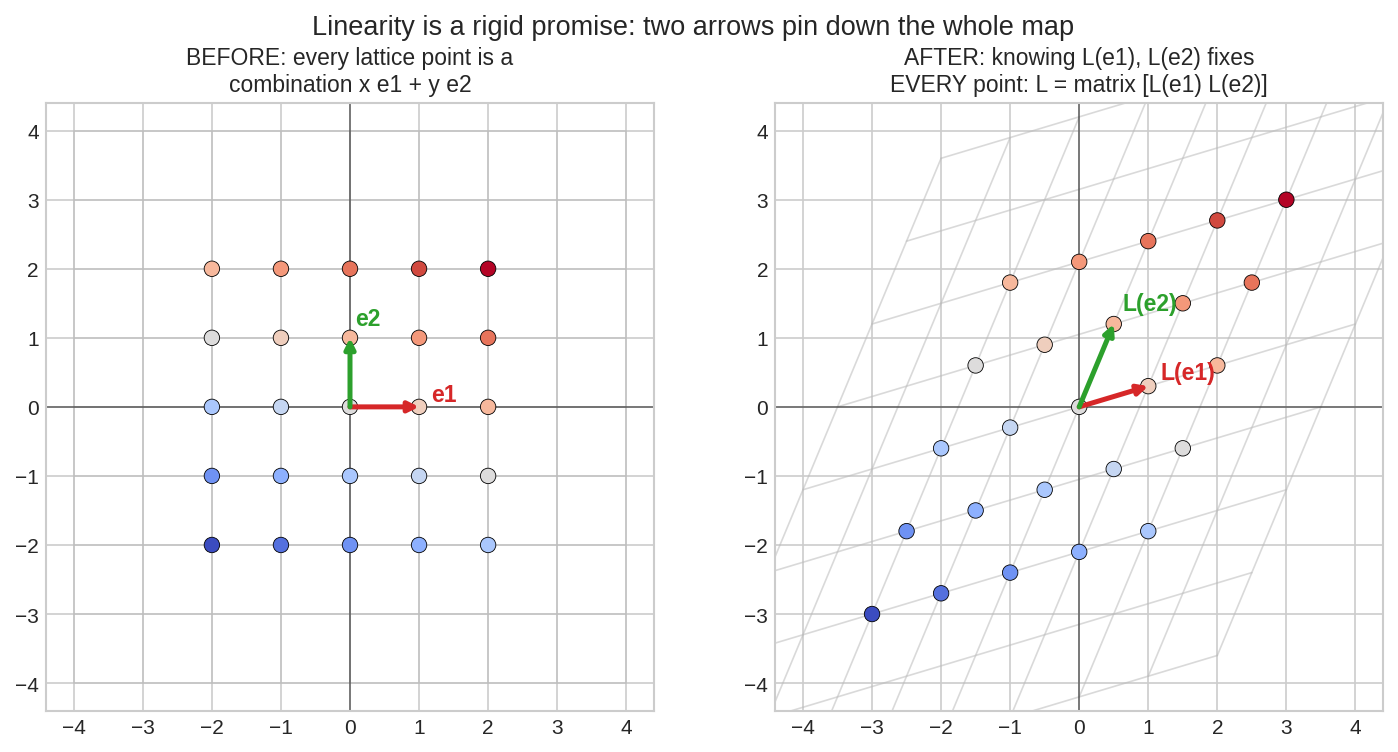
বাঁয়ে: প্রতিটা lattice বিন্দু আসলে একটা recipe — "এত ধাপ \(\mathbf{e}_1\), অত ধাপ \(\mathbf{e}_2\)।" ডানে: transformation-এর পর রঙে-রঙে মিলিয়ে দেখো — প্রতিটা বিন্দু গেছে সেই একই recipe মেনে, শুধু নতুন তীর \(L(\mathbf{e}_1), L(\mathbf{e}_2)\) ধরে। Linearity একটা কঠিন প্রতিশ্রুতি: দুটো তীরের গন্তব্য বললেই অসীম প্লেনের প্রতিটা বিন্দুর গন্তব্য লেখা হয়ে যায়।
এখানে থেমে একটা দার্শনিক শ্বাস নাও: একটা function-এর কথা ভাবো \(\mathbb{R}^2 \to \mathbb{R}^2\) — তার স্বাধীনতা অসীম, প্রতিটা বিন্দুকে যেখানে খুশি পাঠাতে পারে। Linearity সেই অসীম স্বাধীনতাকে নামিয়ে আনে মাত্র ৪টা সংখ্যায় (\(2\times2\) matrix)। এই নাটকীয় সংকোচনই linear algebra-র শক্তির উৎস: অল্প সংখ্যায় পুরো transformation ধরা যায়, computer-এ রাখা যায়, compose করা যায়, undo করা যায়। আর এই সংকোচনের দামও আছে — বাঁকানো, ভাঁজ করা, origin সরানো নিষেধ। Data Science-এর অর্ধেক কৌশল হলো জগতের বাঁকা সমস্যাকে (অন্তত টুকরো টুকরো করে) এই সোজা জগতে টেনে আনা।
স্কুলের "linear"-এর সাথে বিরোধটা মিটিয়ে নিই: স্কুলে \(y = mx + c\)-কে linear function বলে, কারণ graph-টা সরলরেখা। কিন্তু আজকের সংজ্ঞায় \(f(x) = mx + c\) (\(c \ne 0\)) linear নয় — \(f(0) = c \neq 0\), origin test-এ ফেল! এ ধরনের map-এর সঠিক নাম affine(অ্যাফাইন): একটা linear অংশ + একটা ধাক্কা (translation)। Neural network-এর \(W\mathbf{x} + \mathbf{b}\)-ও তাই আসলে affine — ML সাহিত্যে "linear layer" নামটা একটু আলগা ব্যবহার। পার্থক্যটা জানা থাকলে আর গোলমাল হবে না: linear = কারচুপিহীন দোকান, affine = কারচুপিহীন দোকান + ঢোকার ফি।
৬. Code-এ কেমনে লিখে¶
import numpy as np
rng = np.random.default_rng(42)
def is_linear(f, n=2, trials=200, tol=1e-9):
"""f: R^n -> R^m কে দুই শর্তের random জেরা — statistical লিটমাস test"""
for _ in range(trials):
u, v = rng.normal(size=n), rng.normal(size=n)
c = rng.normal()
if not np.allclose(f(u + v), f(u) + f(v), atol=tol): # শর্ত ১
return False
if not np.allclose(f(c * u), c * f(u), atol=tol): # শর্ত ২
return False
return True
# সন্দেহভাজনদের লাইন-আপ
suspects = {
"f(x,y) = (x+y, x-2y)": lambda v: np.array([v[0] + v[1], v[0] - 2*v[1]]),
"rotation 30 deg": lambda v: np.array([[0.866, -0.5], [0.5, 0.866]]) @ v,
"translation v + (1,1)": lambda v: v + np.array([1.0, 1.0]),
"f(x,y) = (x*y, y)": lambda v: np.array([v[0] * v[1], v[1]]),
"f(x,y) = (|x|, y)": lambda v: np.array([abs(v[0]), v[1]]),
}
for name, f in suspects.items():
print(f"{name:>24}: {'LINEAR' if is_linear(f) else 'not linear'}")
Output ব্যাখ্যা: প্রথম দুজন LINEAR — একটা হাতে-লেখা সূত্র, একটা rotation matrix। বাকি তিনজন not linear: translation ধরা পড়ে origin-দোষে, \(xy\)-ওয়ালা ধরা পড়ে additivity-তে, \(|x|\) ধরা পড়ে ঋণাত্মক \(c\)-তে। লক্ষ করো — ২০০টা random জেরায় পাস করা প্রমাণ নয় (প্রমাণ কাগজে-কলমে), কিন্তু ফেল করা মানে নিশ্চিত nonlinear: একটাই পাল্টা-উদাহরণ যথেষ্ট।
# মুকুট-উপপাদ্য কোডে: linear function থেকে matrix উদ্ধার
def matrix_of(f, n=2):
"""column j = f(e_j) — সংজ্ঞাটাই কোড"""
return np.column_stack([f(np.eye(n)[:, j]) for j in range(n)])
f = suspects["f(x,y) = (x+y, x-2y)"]
A = matrix_of(f)
print(A) # [[ 1. 1.] [ 1. -2.]]
x = rng.normal(size=2)
print(np.allclose(f(x), A @ x)) # True — f আর 'A দিয়ে গুণ' অবিচ্ছেদ্য
matrix_of ফাংশনটা এক লাইনে মুকুট-উপপাদ্য: basis vector-গুলো ঢুকিয়ে output-গুলো column-এ সাজাও — ব্যস, function-টার "ঠিকানা" উদ্ধার। শেষ লাইন সাক্ষী: যেকোনো \(\mathbf{x}\)-এ f(x) আর A @ x অভিন্ন।
৭. Worked Examples¶
Example 1 — সংজ্ঞা ধরে ধরে linear প্রমাণ, তারপর matrix উদ্ধার। \(L(x, y) = (3x - y,\; 2y)\) কি linear? হলে matrix কত?
ধাপ ১ (শর্ত ১): \(\mathbf{u} = (u_1, u_2)\), \(\mathbf{v} = (v_1, v_2)\) নিলে:
ধাপ ২ (শর্ত ২): \(L(c\mathbf{v}) = (3cv_1 - cv_2,\; 2cv_2) = c\,(3v_1 - v_2,\; 2v_2) = c\,L(\mathbf{v})\) ✓ — linear। ধাপ ৩ (matrix): column-মন্ত্র: \(L(\mathbf{e}_1) = L(1,0) = (3, 0)\); \(L(\mathbf{e}_2) = L(0,1) = (-1, 2)\):
যাচাই: \(A\begin{bmatrix}x\\y\end{bmatrix} = \begin{bmatrix}3x - y\\ 2y\end{bmatrix}\) ✓। ভবিষ্যতের শর্টকাটও দেখে রাখো: প্রতিটা output-উপাংশ যদি input-উপাংশগুলোর "সংখ্যা-গুণ-চলক যোগফল" হয় (কোনো \(x^2\), \(xy\), \(|x|\), ধ্রুবক নেই) — linear, আর সহগগুলোই matrix-এর row।
Example 2 — নিরীহ চেহারার প্রতারক। \(T(x, y) = (x + 1,\; y)\) — মোটে "১ ঘর ডানে সরানো।" Linear?
ধাপ ১ (সবচেয়ে সস্তা test): \(T(0, 0) = (1, 0) \neq (0,0)\) — origin নড়ে গেছে। এখানেই শেষ: linear নয়। ধাপ ২ (কৌতূহলে আরেকটা শর্তও ভাঙি): \(T(2(1,0)) = T(2,0) = (3,0)\), কিন্তু \(2\,T(1,0) = 2(2,0) = (4,0)\) — homogeneity-ও ফেল। ধাপ ৩ (শিক্ষা): fig04-এর সেই গল্প — গ্রিড সোজা-সমান্তরাল রেখেও linear না হওয়া যায়। ছবির test-এ origin-এর দিকে তাকানো বাধ্যতামূলক। (\(T\) affine; graphics-এ একে matrix বানাতে চাইলে একটা মাত্রা বাড়িয়ে \(3\times3\) "homogeneous coordinates"-এ যেতে হয় — সে গল্প Part VIII-এ।)
Example 3 — matrix-এর সীমানা ছাড়িয়ে: derivative একটা matrix! জগতে vector মানে শুধু তীর না — polynomial-রাও vector-এর মতো আচরণ করে (যোগ করা যায়, scale করা যায়)। Degree \(\le 2\)-এর polynomial \(p(x) = a + bx + cx^2\)-কে লিখি coordinate-রূপে \((a, b, c)\)। এখন \(L = \frac{d}{dx}\) (derivative) নাও।
ধাপ ১ (linear তো?): \((p + q)' = p' + q'\), \((cp)' = cp'\) — calculus-এর প্রথম পাঠ; দুই শর্তই মানে ✓। ধাপ ২ (basis-দের গন্তব্য): basis: \(1, x, x^2\) অর্থাৎ \((1,0,0), (0,1,0), (0,0,1)\)। \(\frac{d}{dx}(1) = 0 \mapsto (0,0,0)\); \(\frac{d}{dx}(x) = 1 \mapsto (1,0,0)\); \(\frac{d}{dx}(x^2) = 2x \mapsto (0,2,0)\)। ধাপ ৩ (column-এ সাজাও):
যাচাই: \(p(x) = 5 + 3x + 4x^2 \mapsto (5, 3, 4)\); \(D(5,3,4)^\top = (3, 8, 0)\) — মানে \(3 + 8x\); হাতে derivative: \(p'(x) = 3 + 8x\) ✓! শিক্ষা: Calculus-এর যন্ত্রও matrix-এ ধরা দিল — কারণ সে linear। লক্ষ করো \(D\)-র তৃতীয় row পুরো শূন্য (degree কমে যায় — তথ্য হারায়!), তাই \(D\) singular: integration-এ সেই হারানো ধ্রুবক \(+C\) ফেরে না। Chapter 3.4-এর singular-গল্প calculus-এও খাটে!
৮. Problems ও Solutions¶
Problem 1. কোনগুলো linear? না হলে কোন শর্ত ভাঙে, একটা সংখ্যার পাল্টা-উদাহরণসহ: (a) \(f(x, y) = (2x, x + y)\) (b) \(f(x, y) = (x^2, y)\) (c) \(f(x, y) = (x + 2, y)\) (d) \(f(x, y) = (y, 0)\)
Solution
(a) Linear — প্রতিটা output সহগ-যোগফল (\(2x\) এবং \(x+y\)); matrix \(\begin{bmatrix}2 & 0\\ 1 & 1\end{bmatrix}\)।
(b) Nonlinear — homogeneity ফেল: \(f(2(1,0)) = f(2, 0) = (4, 0)\) কিন্তু \(2f(1,0) = (2, 0)\)। বর্গটাই অপরাধী।
(c) Nonlinear — origin test: \(f(0,0) = (2, 0) \ne (0,0)\); এটা affine (linear + ধাক্কা)।
(d) Linear — অবাক লেগেছে? \(f(\mathbf{u}+\mathbf{v}) = (u_2 + v_2, 0) = f(\mathbf{u}) + f(\mathbf{v})\) ✓, homogeneity-ও ✓। Matrix: \(\begin{bmatrix}0 & 1\\ 0 & 0\end{bmatrix}\) — singular, কিন্তু singular হওয়া আর nonlinear হওয়া সম্পূর্ণ আলাদা দোষ! (Projection-রাও linear ছিল, মনে আছে?)
Problem 2. একটা linear map \(L\) সম্পর্কে জানা: \(L(\mathbf{e}_1) = (2, 1)\) আর \(L(\mathbf{e}_2) = (0, -3)\)। (a) \(L\)-এর matrix লেখো। (b) \(L(4, 5)\) বের করো — দুইভাবে: matrix-গুণে আর সরাসরি linearity দিয়ে।
Solution
(a) গন্তব্যরা column-এ:
(b) Matrix-পথ: \(A\begin{bmatrix}4\\5\end{bmatrix} = \begin{bmatrix}(2)(4) + (0)(5)\\ (1)(4) + (-3)(5)\end{bmatrix} = \begin{bmatrix}8\\ -11\end{bmatrix}\)
Linearity-পথ: \((4,5) = 4\mathbf{e}_1 + 5\mathbf{e}_2\), তাই
দুই পথ একই — কারণ matrix-গুণ সংজ্ঞাই হয়েছে linearity-র হিসাবটা মুখস্থ করার জন্য।
Problem 3. \(L\) linear, আর জানা আছে \(L(1, 1) = (2, 3)\) ও \(L(1, -1) = (0, 1)\) — খেয়াল করো এবার basis vector-দের গন্তব্য সরাসরি দেওয়া নেই! (a) \(L(3, 1)\) বের করো। (b) \(L\)-এর matrix উদ্ধার করো।
Solution
(a) \((3,1)\)-কে জানা দুই vector-এর combination হিসেবে লেখো: \((3,1) = a(1,1) + b(1,-1)\) দিলে \(a + b = 3\), \(a - b = 1\) — অর্থাৎ \(a = 2, b = 1\)। এবার linearity:
(b) Basis-দের গন্তব্য উদ্ধার করি একই কৌশলে: \(\mathbf{e}_1 = \frac{(1,1) + (1,-1)}{2}\), তাই
যাচাই: \(A(3,1)^\top = (4, 7)\) ✓। শিক্ষাটা দামি: যেকোনো দুটো স্বাধীন vector-এর গন্তব্য জানলেই পুরো linear map জানা হয়ে যায় — standard basis বিশেষ কেউ না, শুধু সুবিধাজনক (Part IV-এ "basis বদল"-এর বীজ এটাই)।
Problem 4. দুই লাইনে প্রমাণ করো: (a) \(L(\mathbf{0}) = \mathbf{0}\) additivity থেকেও আসে (homogeneity না ছুঁয়ে)। (b) \(L(-\mathbf{v}) = -L(\mathbf{v})\)।
Solution
(a) \(\mathbf{0} + \mathbf{0} = \mathbf{0}\), তাই additivity দিলে:
দুই পাশ থেকে \(L(\mathbf{0})\) বিয়োগ করো: \(\mathbf{0} = L(\mathbf{0})\) ✓। (একটা সমীকরণ নিজের সাথেই নিজেকে ধরিয়ে দিল!)
(b) Homogeneity-তে \(c = -1\): \(L(-\mathbf{v}) = L((-1)\mathbf{v}) = (-1)L(\mathbf{v}) = -L(\mathbf{v})\) ✓। জ্যামিতি: উল্টো তীর map হয়ে উল্টো তীরই থাকে — এজন্যই linear ছবিগুলো origin-এর দুই পাশে সবসময় প্রতিসম।
Problem 5. \(L\) ও \(M\) দুটোই linear। প্রমাণ করো composition \(N(\mathbf{x}) = M(L(\mathbf{x}))\)-ও linear। এই ফলটা Chapter 3.3-এর কোন কথার "আসল কারণ"?
Solution
দুই শর্ত সরাসরি:
(প্রথমে \(L\)-এর additivity, তারপর \(M\)-এর।) একইভাবে:
তাহলে \(N\) linear — আর মুকুট-উপপাদ্য মতে তার নিজেরও একটা matrix আছে। এটাই সেই গ্যারান্টি যার জোরে Chapter 3.3 বলতে পেরেছিল "দুই matrix পরপর চালানোর মোট প্রভাবও একটা matrix" — সেই মোট matrix-এর নামই আমরা দিয়েছিলাম গুণফল \(BA\)। Composition আগে, multiplication তার হিসাব-রক্ষক — যুক্তির আসল ক্রমটা এই।
Problem 6. গড়-machine: \(g(x_1, x_2, x_3) = \frac{x_1 + x_2 + x_3}{3}\) (\(\mathbb{R}^3 \to \mathbb{R}\))। (a) \(g\) linear প্রমাণ করো। (b) তার matrix (এখানে একটা row vector!) লেখো। (c) Data Science-এ এই "matrix হিসেবে গড়" দেখাটা কি কাজে দেয়?
Solution
(a)
\(g(c\mathbf{v}) = \frac{c v_1 + cv_2 + cv_3}{3} = c\,g(\mathbf{v})\) ✓ — linear।
(b) \(g(\mathbf{e}_j) = \frac{1}{3}\) প্রতিটার জন্য; column-রা (এখানে \(1\times1\) করে) সাজালে:
— গড় মানে একটা row vector দিয়ে গুণ! (\(\mathbb{R}^n \to \mathbb{R}\) প্রতিটা linear map-ই এমন "কোনো fixed vector-এর সাথে dot product" — Part V-এ এর নাম হবে dual/functional।)
(c) গড় linear বলেই: "আগে দুই dataset মিশিয়ে গড়" = "দুই গড়ের (weighted) মিশ্রণ" — MapReduce-ধাঁচের distributed হিসাব সম্ভব; expectation-এর linearity-ও এরই বড় ভাই; আর moving average / smoothing filter-রা সব matrix — তাই তাদের compose, undo, বিশ্লেষণ সব linear algebra দিয়েই চলে।
Problem 7 (সত্য/মিথ্যা — কারণসহ)। (a) গ্রিডলাইন সোজা-সমান্তরাল রাখা প্রতিটা map-ই linear। (b) \(L\) linear আর \(L(\mathbf{v}) = \mathbf{0}\) কোনো \(\mathbf{v} \neq \mathbf{0}\)-র জন্য — এমন হতেই পারে না। (c) \(f(x,y) = (x + y + xy,\; 0)\)-এর জন্য \(f(\mathbf{0}) = \mathbf{0}\), তাই সে linear।
Solution
(a) মিথ্যা। Translation-ই পাল্টা-উদাহরণ (fig04): গ্রিড নিখুঁত, কিন্তু origin সরে — linear নয়। সঠিক বাক্য: সোজা-সমান্তরাল-সমান গ্রিড এবং অনড় origin ⟺ linear।
(b) মিথ্যা। Projection \(\begin{bmatrix}1 & 0\\ 0 & 0\end{bmatrix}\) পুরোপুরি linear, অথচ \((0, 5) \mapsto (0,0)\)। শূন্যে-পাঠানো nonzero vector-দের থাকা মানে singular হওয়া (Chapter 3.4) — linearity-র লঙ্ঘন নয়। (এই "শূন্যে যাওয়া দল"-এর নাম Part IV-এ হবে null space।)
(c) মিথ্যা। Origin test প্রয়োজনীয় শর্ত, যথেষ্ট নয় — পাস করলেই পার পাওয়া যায় না। ধরা যাক \(\mathbf{u} = (1,0), \mathbf{v} = (0,1)\): \(f(\mathbf{u}+\mathbf{v}) = f(1,1) = (1+1+1, 0) = (3,0)\), কিন্তু \(f(\mathbf{u}) + f(\mathbf{v}) = (1,0)+(1,0) = (2, 0)\) — additivity ভাঙল (\(xy\) টার্মের কারসাজি)। Origin ঠিক থাকা সত্ত্বেও nonlinear।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ ঠিক ধারণা |
|---|---|
| "\(y = mx + c\) linear — স্কুলে তো তাই শিখেছি" | \(c \neq 0\) হলে সেটা affine: origin test ফেল; linear মানে \(L(\mathbf{0}) = \mathbf{0}\) বাধ্যতামূলক |
| "গ্রিড সোজা-সমান্তরাল দেখলেই linear" | Translation-ও তেমন গ্রিড দেয়; origin অনড় আছে কিনা দেখতেই হবে |
| "Origin ঠিক আছে, ব্যস — linear" | Origin test প্রয়োজনীয় কিন্তু যথেষ্ট নয়: \(f(x,y)=(xy, 0)\)-জাতীয়রা এখানেই লুকায়; দুই শর্ত পুরো check করো |
| এক শর্ত check করেই রায় দেওয়া | দুটো শর্ত স্বাধীন পাহারাদার — \(\vert x\vert\) ধরা পড়ে শুধু ঋণাত্মক \(c\)-তে, \(x+y^2\) ধরা পড়ে scaling-এ |
| "Singular matrix মানে বুঝি linear-ও না" | Singular হওয়া (তথ্য হারানো) আর nonlinear হওয়া (নিয়ম ভাঙা) — সম্পূর্ণ আলাদা দোষ; projection singular কিন্তু ষোলো আনা linear |
| "Linearity মানে সরলরেখার graph" | Linearity মানে superposition: \(L(a\mathbf{u} + b\mathbf{v}) = aL(\mathbf{u}) + bL(\mathbf{v})\) — সংজ্ঞাটা সমীকরণে, ছবিতে নয় |
১০. এক নজরে¶
| ধারণা | সারকথা |
|---|---|
| Linear-এর সংজ্ঞা | \(L(\mathbf{u}+\mathbf{v}) = L(\mathbf{u})+L(\mathbf{v})\) এবং \(L(c\mathbf{v}) = cL(\mathbf{v})\) |
| এক-লাইনে রূপ | Superposition: \(L(a\mathbf{u} + b\mathbf{v}) = aL(\mathbf{u}) + bL(\mathbf{v})\) |
| জ্যামিতিক অনুবাদ | গ্রিড সোজা + সমান্তরাল + সমান-দূরত্ব + origin অনড় |
| সস্তা test | \(L(\mathbf{0}) \neq \mathbf{0}\) হলেই বাতিল; সমান হলে বাকি শর্ত দেখো |
| মুকুট-উপপাদ্য | Linear ⟺ matrix; column \(j\) = \(L(\mathbf{e}_j)\); matrix-টা অনন্য |
| Affine | Linear + translation (\(W\mathbf{x} + \mathbf{b}\)) — কাছের আত্মীয়, কিন্তু linear নয় |
| বড় পরিবার | Derivative, integral, expectation, convolution — সব linear operator |
পরের Part-এর সেতু: Part III সম্পূর্ণ — matrix এখন তোমার কাছে জীবন্ত: সে transform করে (3.1–3.2), compose হয় (3.3), কখনো undo হয় কখনো হয় না (3.4), তার পরিবার-পরিজন চেনা (3.5), আর আজ তার আত্মপরিচয়ও প্রমাণিত (3.6)। কিন্তু ঝুলে আছে সবচেয়ে টানটান প্রশ্নগুলো: singular matrix ঠিক কতটুকু তথ্য গেলে — সেই হারানোর মাপ কি? সব সম্ভব output-এর জগৎটা (column-দের span) কত বড়? শূন্যে-চুপসে-যাওয়া দলটার চেহারা কি? Part IV-এ এই প্রশ্নগুলোর নাম হবে rank, column space, null space — matrix-এর এক্স-রে রিপোর্ট।
📓 Notebook Project¶
notebooks/part-03/ch06-project.ipynb — Linearity detector: random-জেরা দিয়ে যেকোনো function-এর linearity test, linear প্রমাণিতদের থেকে matrix স্বয়ংক্রিয় উদ্ধার (\(L(\mathbf{e}_j)\) column-এ), আর linear বনাম nonlinear map-এর গ্রিড-বিকৃতির পাশাপাশি ছবি।