Chapter 6.4 — Symmetric Matrices ও Spectral Theorem (স্পেকট্রাল থিওরেম)¶
আগের দুই chapter-এ eigenvalue-eigenvector-এর জগতে ঢুকেছি, আর diagonalization দিয়ে matrix-কে সহজ রূপে দেখতে শিখেছি। কিন্তু সেখানে দুটো কাঁটা ছিলো: eigenvalue complex হয়ে যেতে পারে, আর eigenvector-এর matrix \(X\)-এর inverse বের করার ঝামেলা। আজকের chapter-এর ঘোষণা: matrix-টা যদি symmetric হয় — \(A^T = A\) — তাহলে দুটো কাঁটাই ভোজবাজির মতো উধাও। সব eigenvalue real, eigenvector-রা পরস্পর লম্ব, আর inverse-এর জায়গায় শুধু transpose। এই ফলটার নাম Spectral Theorem(স্পেকট্রাল থিওরেম) — অনেকের মতে পুরো linear algebra-র সবচেয়ে সুন্দর theorem। আর সবচেয়ে বড় কথা: data science-এ তুমি যত matrix-এর মুখোমুখি হবে, তার সিংহভাগ symmetric — তাই এই theorem-টা তোমার প্রতিদিনের হাতিয়ার হতে যাচ্ছে।
🎯 এই chapter-এ যা শিখবে¶
- Symmetric Matrix(সিমেট্রিক ম্যাট্রিক্স) recap — \(A^T = A\), আর বাস্তবে সে কেন সর্বত্র (covariance, adjacency, Hessian, Gram)
- দুই miracle-এর proof: symmetric matrix-এর সব eigenvalue real, আর ভিন্ন eigenvalue-এর eigenvector-রা পরস্পর orthogonal
- Spectral Theorem: \(A = Q\Lambda Q^T\) — orthogonal \(Q\) দিয়ে diagonalization; inverse লাগে না, transpose-ই যথেষ্ট
- Spectral Decomposition(স্পেকট্রাল ডিকম্পোজিশন): \(A = \sum_i \lambda_i q_iq_i^T\) — matrix ভেঙে projection-দের ওজনদার যোগফল
- Orthogonal diagonalization হাতে-কলমে করার ধাপ (repeated eigenvalue-এ Gram–Schmidt-এর ভূমিকা সহ)
🖼️ এক ছবিতে মূল idea¶
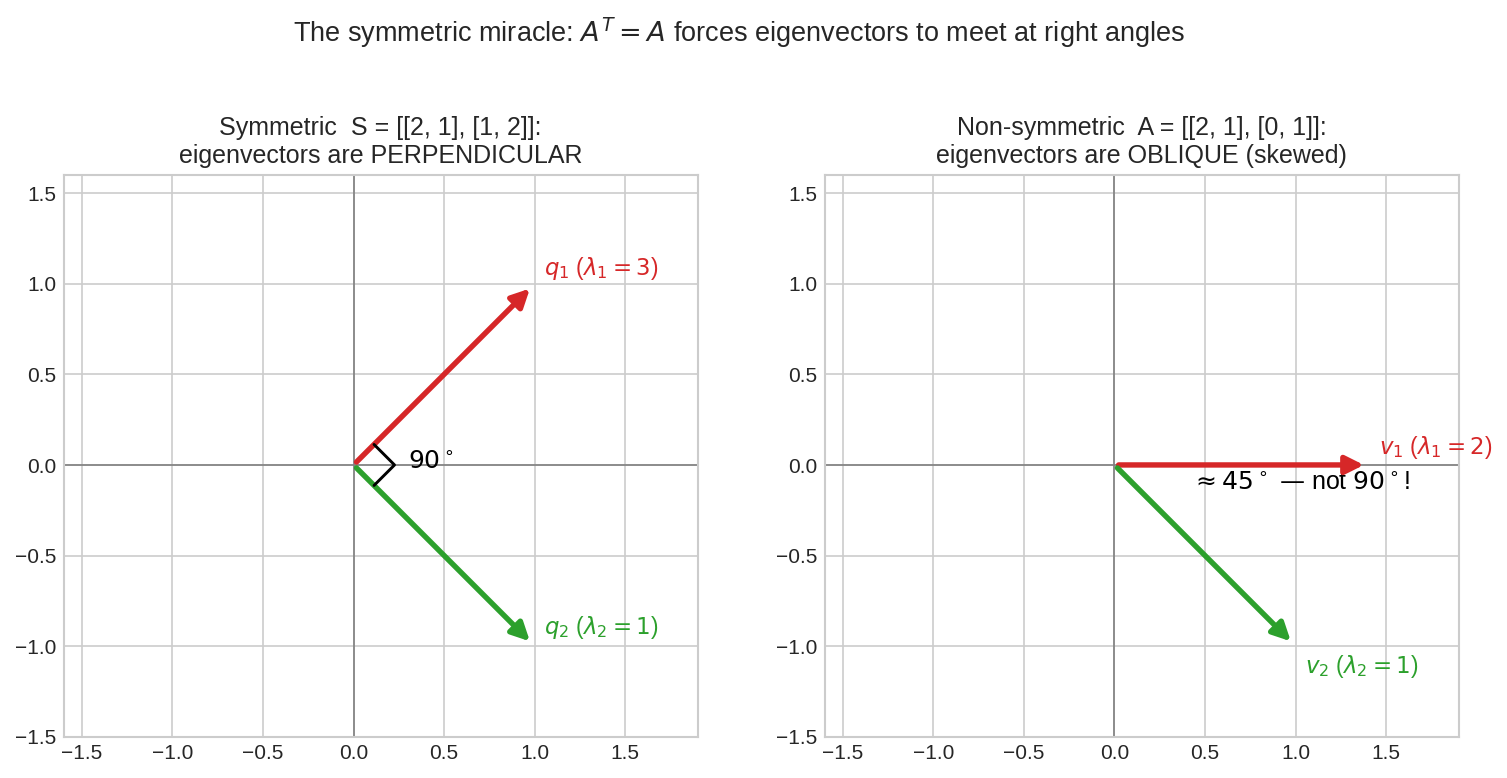
বাঁয়ে symmetric matrix \(S = \begin{bmatrix}2&1\\1&2\end{bmatrix}\)-এর দুই eigenvector — নিখুঁত \(90°\)-তে দাঁড়িয়ে (কোণার ছোট্ট বর্গটা লক্ষ করো)। ডানে non-symmetric \(A = \begin{bmatrix}2&1\\0&1\end{bmatrix}\)-এর eigenvector-রা তির্যক — মাত্র \(45°\)। \(A^T = A\) শর্তটা eigenvector-দের জোর করে লম্ব করে দেয় — এটাই এই chapter-এর কেন্দ্রীয় বিস্ময়।
১. কি? (What)¶
দৈনন্দিন analogy: দূরত্বের টেবিল¶
ধরো তিনটা শহরের পারস্পরিক দূরত্বের টেবিল বানালে — ঢাকা, চট্টগ্রাম, সিলেট:
ঢাকা→চট্টগ্রাম যত দূর, চট্টগ্রাম→ঢাকা-ও ঠিক তত — তাই \((1,2)\) entry আর \((2,1)\) entry সমান। পুরো টেবিলটা তার নিজের আয়না-প্রতিবিম্ব: main diagonal বরাবর ভাঁজ করলে দুই পাশ মিলে যায়। এটাই symmetric matrix।
সংজ্ঞা¶
Symmetric Matrix: square matrix \(A\) যার জন্য
Transpose (Part II) মানে row-column অদলবদল — symmetric মানে অদলবদলে কিছুই বদলায় না। লক্ষ করো: symmetric হতে হলে matrix-কে square হতেই হবে (নাহলে \(A^T\)-এর আকারই আলাদা)।
বাস্তবে symmetric matrix কোথা থেকে আসে? (চার মহারথী)¶
সম্পর্ক যেখানে দ্বিমুখী — "আমার সাথে তোমার যা, তোমার সাথে আমারও তা" — সেখানেই symmetric matrix জন্মায়:
- Covariance Matrix(কোভেরিয়েন্স ম্যাট্রিক্স): feature \(i\) আর feature \(j\)-এর একসাথে-ওঠানামার মাপ \(\text{Cov}(x_i, x_j) = \text{Cov}(x_j, x_i)\) — order-এ কিছু আসে যায় না। ডেটার পুরো "আকৃতি" ধরা থাকে এই symmetric matrix-এ — PCA (Chapter 6.7) একেই diagonalize করবে।
- Adjacency Matrix(অ্যাডজেসেন্সি ম্যাট্রিক্স): undirected graph-এ node \(i\)–node \(j\) সংযোগ থাকলে দুই দিকেই থাকে — friendship network, রাস্তার map।
- Hessian(হেসিয়ান): multivariable function-এর second derivative-দের matrix; \(\frac{\partial^2 f}{\partial x \partial y} = \frac{\partial^2 f}{\partial y \partial x}\) (mixed partial-এর সমতা) — তাই সবসময় symmetric। Optimization-এ "bowl না saddle" প্রশ্নের উত্তর এর eigenvalue-এ (Chapter 6.5-এর গল্প)।
- Gram Matrix \(A^TA\): যেকোনো (এমনকি rectangular!) \(A\)-এর জন্য \((A^TA)^T = A^T(A^T)^T = A^TA\) — নিজে থেকেই symmetric। Part V-এর normal equations-এ একে দেখেছো; Chapter 6.6-এ SVD-র হৃদপিণ্ডও এই \(A^TA\)।
মনে রাখার সূত্র: পৃথিবী symmetric matrix পছন্দ করে, কারণ পৃথিবীর অনেক সম্পর্কই পারস্পরিক।
২. দেখতে কেমন?¶
দৃশ্য ১: unit circle → ellipse — axis-aligned stretch, ঘোরানো চশমায়¶
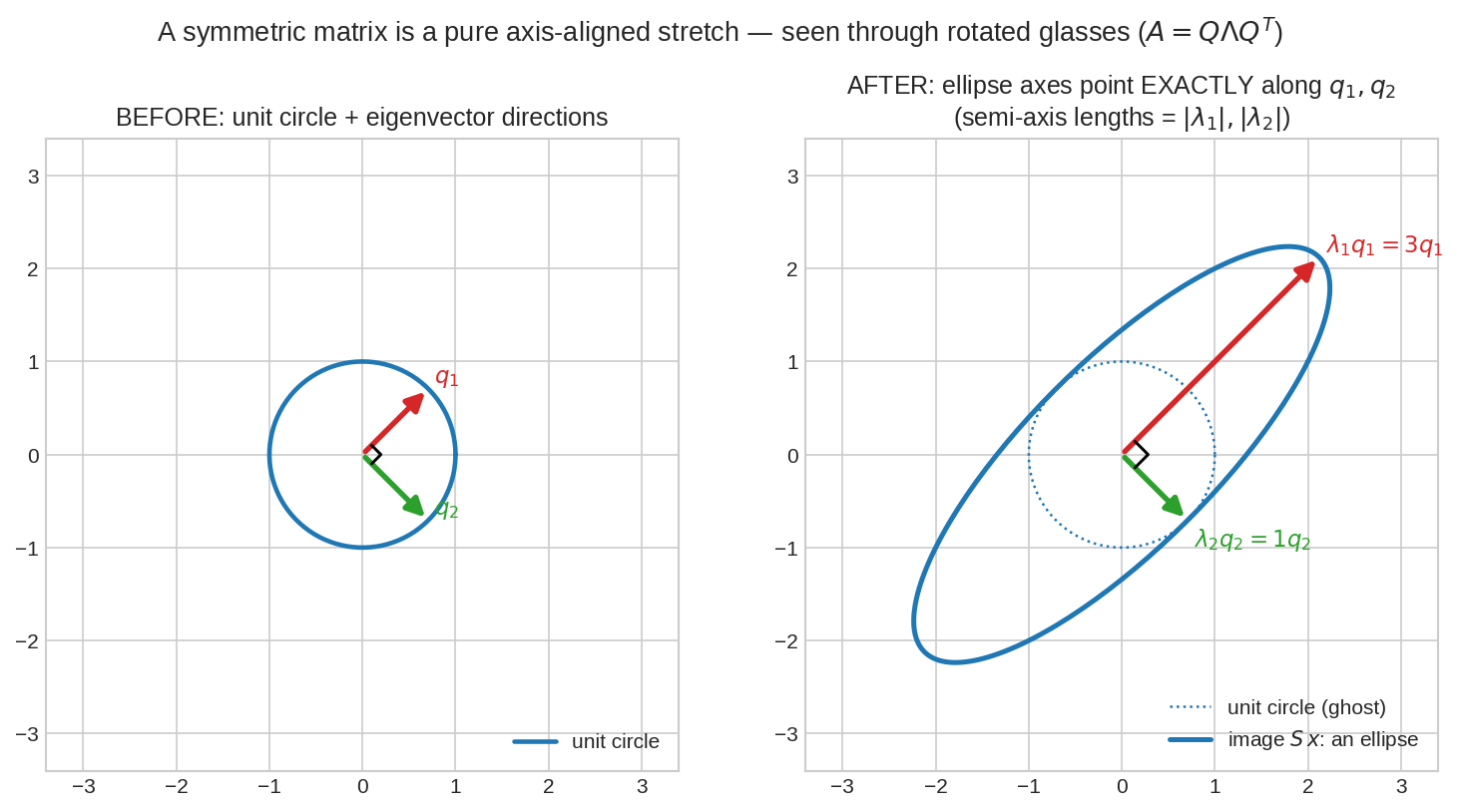
Symmetric \(S\) unit circle-কে পাঠায় একটা ellipse-এ — আর ellipse-এর axis দুটো পড়ে ঠিক eigenvector-দের গায়ে, semi-axis-এর দৈর্ঘ্য \(|\lambda_1| = 3\) আর \(|\lambda_2| = 1\)। অর্থাৎ symmetric matrix মানে: কোনো ঘূর্ণি-প্যাঁচ নেই, শুধু দুটো লম্ব দিকে সোজাসুজি টানা — দিক দুটো standard axis না হয়ে একটু ঘোরানো, এই যা।
Chapter 6.2-তে দেখেছিলে সাধারণ matrix circle-কে বিকৃত করে ঘুরিয়ে-পেঁচিয়ে। Symmetric matrix ভদ্রলোক: সে শুধু stretch করে, লম্ব দিক বরাবর। "ঘোরানো চশমা" পরে (মানে \(q_1, q_2\) axis ধরে) তাকালে সে নিছক diagonal matrix \(\Lambda\)।
দৃশ্য ২: Orthogonal matrix \(Q\) — যে ঘোরায় কিন্তু ভাঙে না¶
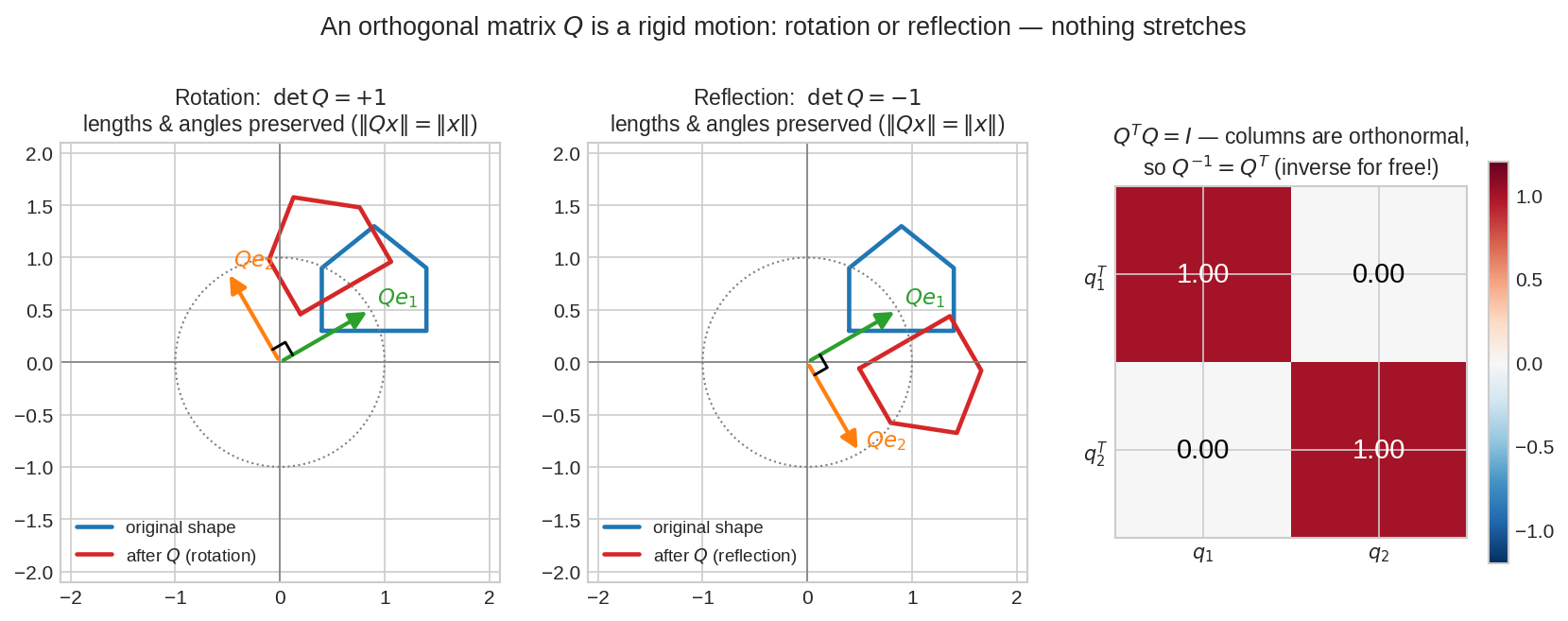
Orthogonal Matrix(অর্থোগোনাল ম্যাট্রিক্স) \(Q\) মানে rigid motion — rotation (\(\det Q = +1\)) বা reflection (\(\det Q = -1\))। ঘরের ছবিটা ঘুরলো/উল্টালো, কিন্তু দৈর্ঘ্য-কোণ-আকৃতি অটুট। ডানে \(Q^TQ = I\)-এর heatmap: column-রা orthonormal বলে transpose-ই inverse।
Part V-এর orthonormal basis মনে করো: \(Q\)-এর column \(q_1, \dots, q_n\) সবাই unit length, সবাই পরস্পর লম্ব। তখন:
Inverse বিনামূল্যে — Gaussian elimination নেই, সূত্র নেই, শুধু ফ্লিপ। আর \(\|Qx\|^2 = x^TQ^TQx = x^Tx = \|x\|^2\) — দৈর্ঘ্য বাঁচে, কোণও বাঁচে (dot product অটুট)। Spectral Theorem-এ ঠিক এই \(Q\)-ই আসবে eigenvector নিয়ে।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- কম্পন ও কাঠামো: সেতু/ভবনের stiffness matrix symmetric — তার real eigenvalue-রাই natural frequency, eigenvector-রা কম্পনের mode। Real হওয়াটা এখানে জীবন-মরণ: complex frequency মানে হিসাবের অর্থই থাকে না।
- Quantum mechanics: observable মানেই symmetric (Hermitian) operator — eigenvalue real হতেই হবে, কারণ measurement-এর ফল বাস্তব সংখ্যা। Spectral Theorem এখানে পদার্থবিজ্ঞানের axiom-প্রায়।
- জরিপ/দূরত্ব টেবিল: শহরের দূরত্ব, molecule-এ atom-দের interaction — সব symmetric।
Data Science / ML-এ:
- PCA-র ভিত: covariance matrix সবসময় symmetric ⟹ Spectral Theorem গ্যারান্টি দেয় — real variance-মান (eigenvalue) আর লম্ব principal direction (eigenvector) সবসময় পাওয়া যাবে। Chapter 6.7 পুরোটা এই ভিতের ওপর দাঁড়াবে।
- Spectral Clustering(স্পেকট্রাল ক্লাস্টারিং): graph-এর Graph Laplacian(গ্রাফ লাপ্লাসিয়ান) \(L = D - W\) symmetric; তার ছোট eigenvalue-এর eigenvector-রা graph-এর "প্রাকৃতিক টুকরো" চিনিয়ে দেয় — নামের "spectral"-টা এসেছেই Spectral Theorem থেকে।
- Kernel methods: SVM-এর kernel matrix \(K_{ij} = k(x_i, x_j) = k(x_j, x_i)\) — symmetric; তার eigen-জগতেই kernel trick-এর গণিত।
- Optimization: Newton's method-এর Hessian, natural gradient-এর Fisher information — সব symmetric; তাদের eigenvalue-এর sign-ই বলে দেয় নামছি না উঠছি (Chapter 6.5)।
এক কথায়: ML-এ eigenvalue নিয়ে যত কাজ, তার ৯০% symmetric matrix-এর ওপরে — আর সেখানে Spectral Theorem-এর সব সুবিধা ফ্রি।
৪. Properties¶
Property 1 — Miracle ১: সব eigenvalue real¶
\(A^T = A\) (real entries) হলে \(A\)-এর প্রতিটি eigenvalue real সংখ্যা।
\(2\times 2\)-তে সরাসরি দেখা যায়। General symmetric \(\begin{bmatrix}a & b\\ b & d\end{bmatrix}\)-এর characteristic polynomial:
Square root-এর ভেতরটা দুই বর্গের যোগফল — কখনো negative হয় না ⟹ \(\lambda\) সবসময় real ∎। (Chapter 6.2-এর rotation matrix-এর সাথে তুলনা করো: সেখানে off-diagonal ছিলো \(-b\) আর \(b\) — বিপরীত চিহ্ন — আর root-এর ভেতরে \(-b^2\) ঢুকে eigenvalue complex হয়ে গিয়েছিলো। Symmetry-ই সেই বিপদ আটকায়।)
General \(n \times n\) proof-ও ছোট (complex dot product দিয়ে) — Problem 5-এ তুমি নিজেই করবে।
Property 2 — Miracle ২: ভিন্ন eigenvalue-এর eigenvector পরস্পর লম্ব¶
\(Ax = \lambda x\), \(Ay = \mu y\) এবং \(\lambda \neq \mu\) হলে \(x^Ty = 0\)।
Proof (\(x^TAy\) trick — দুই পথে এক সংখ্যা): সংখ্যা \(x^TAy\)-কে দুইভাবে হিসাব করো।
পথ ১ — \(A\) ডানে কাজ করুক: \(x^TAy = x^T(\mu y) = \mu\, x^Ty\)
পথ ২ — \(A\) বাঁয়ে কাজ করুক: \(x^TAy = (A^Tx)^Ty = (Ax)^Ty = \lambda\, x^Ty\) — মাঝখানে ঠিক এখানেই symmetry ব্যবহার হলো: \(A^T = A\)।
দুই পথ একই সংখ্যা, তাই বিয়োগ করলে:
\(\lambda \neq \mu\) বলে \(\mu - \lambda \neq 0\) ⟹ \(x^Ty = 0\) ∎। Eigenvector-রা লম্ব হতে বাধ্য — চাইলেও তির্যক হতে পারবে না।
Property 3 — Spectral Theorem (মূল theorem)¶
যেখানে \(Q\) orthogonal (\(Q^TQ = I\), column-রা \(A\)-এর orthonormal eigenvector) আর \(\Lambda\) diagonal (entry-রা real eigenvalue)। প্রতিটি real symmetric matrix orthogonally diagonalizable — কোনো ব্যতিক্রম নেই, এমনকি repeated eigenvalue-এও (defective হওয়ার ভয় নেই — Chapter 6.3-এর সেই দুঃস্বপ্ন এখানে অসম্ভব)।
উল্টো দিকটাও ফাউ পাওনা: \(A = Q\Lambda Q^T\) আকারে লেখা গেলে \(A^T = (Q\Lambda Q^T)^T = Q\Lambda^T Q^T = Q\Lambda Q^T = A\) — অর্থাৎ এই আকারে লেখা যায় কেবল symmetric matrix-ই। Chapter 6.3-এর \(A = X\Lambda X^{-1}\)-এর সাথে পার্থক্যটা দেখো:
| সাধারণ diagonalization | Spectral Theorem | |
|---|---|---|
| কোন matrix | diagonalizable হলে | যেকোনো symmetric |
| Eigenvalue | complex হতে পারে | সব real |
| Eigenvector matrix | \(X\), invertible হলেই হলো | \(Q\), orthogonal |
| Inverse | \(X^{-1}\) হিসাব করতে হয় | \(Q^{-1} = Q^T\) — ফ্রি |
Property 4 — Spectral decomposition: projection-দের ওজনদার যোগফল¶
\(Q\)-এর column ধরে ধরে \(Q\Lambda Q^T\) গুণফলটা খুলে ফেললে (column–row expansion, Part II):
চিনতে পারছো \(q_iq_i^T\)-কে? Part V-এর projection matrix! Unit vector \(q\)-এর লাইনে ছায়া ফেলার মেশিন \(P = qq^T\) ফিরে এলো। তাহলে symmetric matrix মানে:
— \(n\)টা লম্ব লাইনে ছায়া ফেলো, প্রতিটা ছায়াকে \(\lambda_i\) গুণ ওজন দাও, যোগ করো। ব্যস, এটাই \(A\)-এর সম্পূর্ণ কর্মপদ্ধতি: \(Ax = \sum_i \lambda_i (q_i^Tx)\, q_i\)।
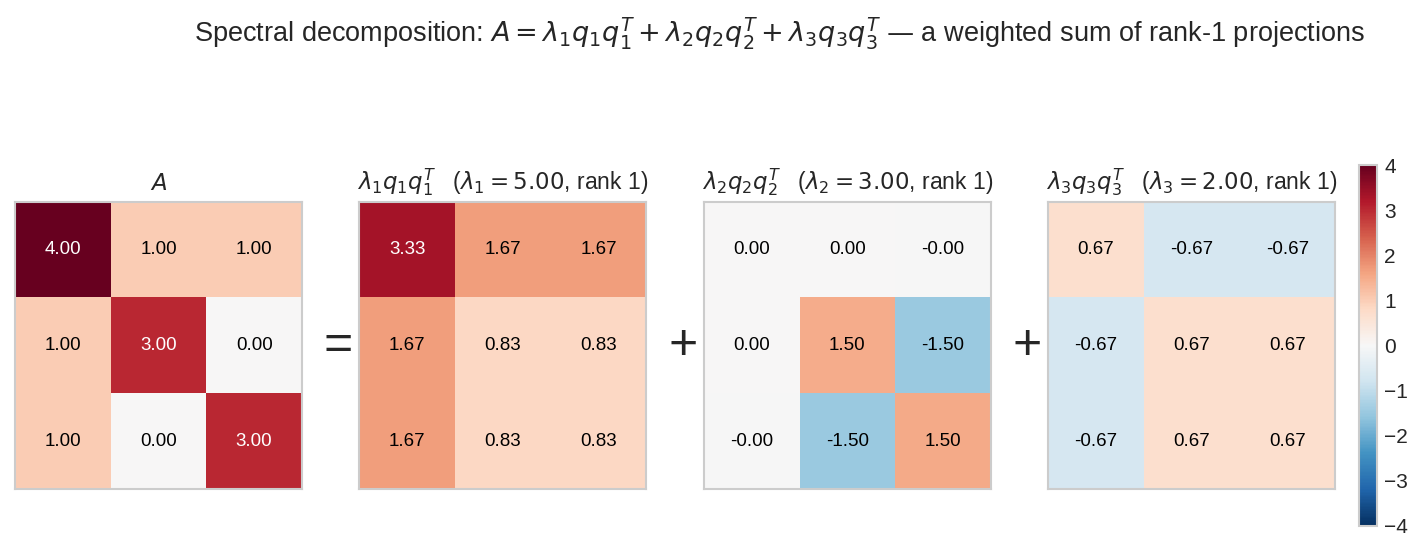
\(3\times3\) symmetric \(A\) ভেঙে গেলো তিনটা rank-1 টুকরোয় — প্রতিটা টুকরো \(\lambda_i q_iq_i^T\) একেকটা weighted projection। Heatmap-এ দেখো: টুকরোগুলোর entry-wise যোগফল হুবহু \(A\)। সবচেয়ে বড় \(\lambda\)-র টুকরোটাই \(A\)-এর "প্রধান চরিত্র"।
Property 5 — Eigenvalue-রাই symmetric matrix-এর পুরো পরিচয়¶
Spectral decomposition থেকে সরাসরি:
- \(\det A = \lambda_1\lambda_2\cdots\lambda_n\), \(\;\text{trace}(A) = \lambda_1 + \cdots + \lambda_n\) (Chapter 6.2-এর ফল, এখানে সব real)
- \(A\) invertible \(\iff\) কোনো \(\lambda_i = 0\) নয়; আর \(A^{-1} = Q\Lambda^{-1}Q^T = \sum_i \frac{1}{\lambda_i}q_iq_i^T\)
- \(A^k = Q\Lambda^kQ^T\) — power নেওয়া মানে শুধু eigenvalue-দের power (Chapter 6.3-এর কৌশল, এখন আরো সস্তা)
- Best rank-k approximation-এর teaser: টুকরোগুলোকে \(|\lambda|\) অনুসারে সাজিয়ে প্রথম \(k\)টা রাখলে যে matrix পাও, সেটাই \(A\)-এর সেরা rank-\(k\) সংস্করণ। মাত্র কয়েকটা \(\lambda q q^T\) দিয়েই \(A\)-এর প্রায় পুরোটা — data compression-এর বীজমন্ত্র। Chapter 6.6-এ SVD এই idea-টাকেই যেকোনো matrix-এ ছড়িয়ে দেবে।
৫. Intuition — কেন সত্য?¶
Spectral Theorem কেন খাটে — সিঁড়ি-ভাঙা যুক্তি (Guest-এর পথ)¶
দুই miracle থেকে theorem পর্যন্ত পৌঁছানোর যুক্তিটা একটা সিঁড়ির মতো — এক ধাপ নামো, ছোট একই সমস্যা পাও, আবার নামো:
ধাপ ১: যেকোনো matrix-এর অন্তত একটা eigenvalue আছে (characteristic polynomial-এর root); symmetric-এ সেটা real (Miracle ১)। তার unit eigenvector \(q_1\) নাও।
ধাপ ২: \(q_1\)-কে সম্প্রসারণ করে \(\mathbb{R}^n\)-এর একটা orthonormal basis বানাও — ঠিক এখানেই Part V-এর Gram–Schmidt দরকার: \(q_1\)-এর সাথে যেকোনো independent vector-দের নিয়ে লম্ব-করণ। এই basis-এর matrix \(P\) orthogonal।
ধাপ ৩: \(P^TAP\) হিসাব করো। প্রথম column হয় \((\lambda_1, 0, \dots, 0)^T\) — কারণ \(Aq_1 = \lambda_1 q_1\) আর বাকি \(q_i \perp q_1\)। এখন মোক্ষম চাল: \(P^TAP\) নিজেও symmetric (\((P^TAP)^T = P^TA^TP = P^TAP\))! তাই প্রথম column শূন্য মানে প্রথম row-ও শূন্য:
ধাপ ৪: ভেতরে রয়ে গেলো \((n-1)\times(n-1)\) symmetric \(\hat{A}\) — একই সমস্যা, এক size ছোট। তার ওপর একই কৌশল, আবার, আবার... \(n\) ধাপে পুরো diagonal ∎
লক্ষ করো symmetry দুই জায়গায় জীবন বাঁচালো: eigenvalue real রাখলো (ধাপ ১), আর "column শূন্য ⟹ row-ও শূন্য" উপহার দিলো (ধাপ ৩)। Non-symmetric matrix-এ দ্বিতীয়টা ভেঙে পড়ে — উপরের ত্রিভুজে "আবর্জনা" জমে থাকে।
জ্যামিতিক অর্থ: প্রতিটি symmetric matrix আসলে "ঘোরাও–টানো–ফেরত ঘোরাও"¶
\(A = Q\Lambda Q^T\)-কে ডান থেকে বাঁয়ে পড়ো — \(x\)-এর ওপর তিন ধাপে কাজ:
- \(Q^Tx\): ঘোরানো চশমা পরো — \(x\)-কে eigenvector-coordinate-এ প্রকাশ (rigid rotation, কিছু ভাঙে না)
- \(\Lambda(\cdot)\): এখন সবচেয়ে সহজ কাজটা করো — প্রতিটা axis বরাবর \(\lambda_i\) গুণ stretch
- \(Q(\cdot)\): চশমা খোলো — আগের জগতে ফেরত
তাই fig02-এর ellipse: symmetric matrix-এর সব "জটিলতা" আসলে শুধু কোন লম্ব দিকে কত টান — এর বেশি কিছু নয়। Diagonal matrix যেমন সহজ, symmetric matrix ঠিক ততটাই সহজ — শুধু তার নিজের (ঘোরানো) axis-এ দাঁড়িয়ে দেখতে হয়। 3Blue1Brown-এর ভাষায়: symmetric matrix হলো "a diagonal matrix wearing a rotation costume"।
Orthogonal diagonalization-এর রেসিপি (হাতে করার ধাপ)¶
- Characteristic polynomial \(\det(A - \lambda I) = 0\) থেকে eigenvalue বের করো (সব real আসবে — না এলে হিসাবে ভুল!)
- প্রতিটি \(\lambda\)-র জন্য \(N(A - \lambda I)\) থেকে eigenvector
- ভিন্ন eigenvalue-এর eigenvector এমনিতেই লম্ব (Miracle ২) — শুধু normalize করো
- Repeated eigenvalue? তার eigenspace-এর dimension symmetric matrix-এ সবসময় multiplicity-র সমান (defect নেই) — কিন্তু \(N(A-\lambda I)\) থেকে পাওয়া basis vector-রা নিজেদের মধ্যে লম্ব না-ও হতে পারে। তখন Gram–Schmidt (Chapter 5.2) চালিয়ে ওই eigenspace-এর ভেতরে orthonormal basis বানাও — eigenspace-এর ভেতরের যেকোনো vector-ই eigenvector, তাই লম্ব-করণে eigenvector-ত্ব হারায় না
- Normalized eigenvector-দের column বানিয়ে \(Q\); চেক: \(Q^TQ = I\) এবং \(Q^TAQ = \Lambda\)
৬. Code-এ কেমনে লিখে¶
import numpy as np
np.random.seed(42)
A = np.array([[4., 1., 1.],
[1., 3., 0.],
[1., 0., 3.]])
print("symmetric?", np.allclose(A, A.T)) # True
# --- symmetric matrix-এর জন্য বিশেষ routine: eigh (h = Hermitian/symmetric) ---
lam, Q = np.linalg.eigh(A) # eigenvalue ছোট→বড় sorted, Q orthogonal
print("eigenvalues:", lam) # [2. 3. 5.] ← সব real!
# --- Q সত্যিই orthogonal? ---
print("Q^T Q = I ?", np.allclose(Q.T @ Q, np.eye(3))) # True
print("Q Lambda Q^T = A ?", np.allclose(Q @ np.diag(lam) @ Q.T, A)) # True
# --- spectral decomposition: rank-1 টুকরোয় ভাঙা ---
pieces = [lam[i] * np.outer(Q[:, i], Q[:, i]) for i in range(3)]
print("sum of rank-1 pieces = A ?", np.allclose(sum(pieces), A)) # True
for i, P in enumerate(pieces):
print(f"piece {i}: rank = {np.linalg.matrix_rank(P)}, weight = {lam[i]:.2f}")
# --- eig বনাম eigh: কেন eigh? ---
lam2, X = np.linalg.eig(A) # general routine
print("eig :", np.sort(lam2.real)) # একই উত্তর, কিন্তু dtype জেনে রাখো
# eigh: দ্রুততর, eigenvalue গ্যারান্টিড real ও sorted, Q গ্যারান্টিড orthogonal
Output ব্যাখ্যা:
eighsymmetric matrix-এর জন্য বিশেষভাবে বানানো — Spectral Theorem-কে সে ধরেই নেয়, তাই ফল real ও sorted, আর \(Q\) নিখুঁত orthogonal। Symmetric matrix-এ সবসময়eighব্যবহার করো,eigনয় — দ্রুত এবং নিরাপদ।- তিনটা rank-1 piece-এর যোগফল মেশিন-নির্ভুলতায় \(A\) — spectral decomposition কোডে ধরা।
np.outer(q, q)হলো \(qq^T\) — Part V-এর সেই projection matrix এক লাইনে।
৭. Worked Examples¶
Example 1 — \(2\times2\) orthogonal diagonalization, পুরোটা হাতে¶
ধাপ ১ — eigenvalue: \(\det(A - \lambda I) = (5-\lambda)^2 - 4 = 0 \Rightarrow 5 - \lambda = \pm 2 \Rightarrow \lambda_1 = 7,\; \lambda_2 = 3\)। দুটোই real ✓
ধাপ ২ — eigenvector: \(\lambda_1 = 7\): \((A - 7I)x = \begin{bmatrix}-2 & 2\\ 2 & -2\end{bmatrix}x = 0 \Rightarrow x_1 = (1, 1)^T\) \(\lambda_2 = 3\): \((A - 3I)x = \begin{bmatrix}2 & 2\\ 2 & 2\end{bmatrix}x = 0 \Rightarrow x_2 = (1, -1)^T\)
ধাপ ৩ — লম্বতা চেক (Miracle ২): \(x_1^Tx_2 = 1 - 1 = 0\) ✓ — চাইতে হয়নি, এমনিই লম্ব।
ধাপ ৪ — normalize ও \(Q\):
যাচাই: \(Q\Lambda Q^T = \frac{1}{2}\begin{bmatrix}1&1\\1&-1\end{bmatrix}\begin{bmatrix}7&0\\0&3\end{bmatrix}\begin{bmatrix}1&1\\1&-1\end{bmatrix} = \frac{1}{2}\begin{bmatrix}7&3\\7&-3\end{bmatrix}\begin{bmatrix}1&1\\1&-1\end{bmatrix} = \frac{1}{2}\begin{bmatrix}10&4\\4&10\end{bmatrix} = A\) ✓
Example 2 — Spectral decomposition ও তার ব্যবহার¶
Example 1-এর \(A\)-কে টুকরোয় ভাঙি:
যোগ করে দেখো: \(\begin{bmatrix}5&2\\2&5\end{bmatrix}\) ✓। প্রথম টুকরো \(q_1q_1^T\) হলো \((1,1)\)-লাইনে projection, দ্বিতীয়টা \((1,-1)\)-লাইনে — দুই লম্ব ছায়া, ওজন \(7\) আর \(3\)।
Powers ফ্রি: \(A^{10} = 7^{10}q_1q_1^T + 3^{10}q_2q_2^T\)। লক্ষ করো \(7^{10} \approx 2.8\times10^8\) বনাম \(3^{10} \approx 5.9\times10^4\) — বড় power-এ প্রথম টুকরোটাই রাজত্ব করে; \(A^{10} \approx 7^{10}q_1q_1^T\), ভুল মাত্র \(0.02\%\)। এটাই "dominant eigenvalue সব খায়" — আর best rank-1 approximation-এর প্রথম দর্শন।
Example 3 — Repeated eigenvalue: Gram–Schmidt মাঠে নামে¶
ধাপ ১: প্রতি row-এর যোগফল \(4\) ⟹ \(x_1 = (1,1,1)^T\) eigenvector, \(\lambda_1 = 4\)। বাকি দুটোর জন্য: \(\text{trace} = 6 = 4 + \lambda_2 + \lambda_3\), আর \(\det A = 4\) (হিসাব করলে) \(= 4\lambda_2\lambda_3\) ⟹ \(\lambda_2 = \lambda_3 = 1\) — repeated!
ধাপ ২: \(\lambda = 1\)-এর eigenspace: \((A - I)x = 0\) মানে \(x_1 + x_2 + x_3 = 0\) (তিনটা row-ই এক সমীকরণ) — একটা plane, dimension \(2\) = multiplicity ✓ (symmetric-এ defect হয় না)। Basis: \(u = (1, -1, 0)^T\), \(v = (1, 0, -1)^T\) — কিন্তু \(u^Tv = 1 \neq 0\), নিজেদের মধ্যে লম্ব নয়!
ধাপ ৩ — Gram–Schmidt (Chapter 5.2): \(q_2 = \frac{1}{\sqrt2}(1,-1,0)^T\); তারপর
\(w\) এখনো plane \(x_1+x_2+x_3=0\)-এর ভেতরে (যোগফল \(0\) ✓) — তাই এখনো eigenvector।
ধাপ ৪: \(q_1 = \frac{1}{\sqrt3}(1,1,1)^T\) এমনিতেই plane-এর সাথে লম্ব (Miracle ২: \(4 \neq 1\))।
শিক্ষা: repeated eigenvalue এলে symmetric matrix তোমাকে একটা গোটা eigenspace উপহার দেয় — তার ভেতরে লম্ব basis বেছে নেওয়ার দায়িত্ব তোমার, আর সেই কাজের যন্ত্রই Gram–Schmidt।
৮. Problems ও Solutions¶
Problem 1. কোনগুলো symmetric? Symmetric-গুলোর eigenvalue বের না করেই বলো সেগুলো real হবে কি না, আর কেন।
Solution
\(A\): \(a_{12} = a_{21} = -2\) ✓ symmetric ⟹ eigenvalue real (Miracle ১), হিসাব ছাড়াই নিশ্চিত।
\(B\): \(b_{12} = 4 \neq -4 = b_{21}\) — not symmetric। আসলে এটা rotation-scaling ধাঁচের; eigenvalue \(1 \pm 4i\) — complex! Symmetry ভাঙলেই real-এর গ্যারান্টি উধাও।
\(C\): symmetric ✓ — eigenvalue real হবেই (বাস্তবে \(\pm 1\); eigenvector \((1,1)\) ও \((1,-1)\) — লম্ব ✓)।
\(D\): \(d_{12} = 5 \neq 0 = d_{21}\) — not symmetric। মজার ব্যাপার: এর eigenvalue তবু real (\(2, 2\)) — কিন্তু eigenvector মাত্র এক লাইনে (defective!)। শিক্ষা: symmetric ⟹ real eigenvalue, কিন্তু real eigenvalue ⟹ symmetric নয়; আর symmetric না হলে defect-এর বিপদও ফিরে আসে।
Problem 2 (proof-based). \(A\) symmetric, \(Ax = \lambda x\), \(Ay = \mu y\), \(\lambda \neq \mu\)। \(x^TAy\) trick ব্যবহার করে প্রমাণ করো \(x \perp y\)। তারপর দেখাও proof-টার ঠিক কোন লাইনে \(A^T = A\) ব্যবহার হয়েছে — অর্থাৎ non-symmetric matrix-এ argument-টা কোথায় ভেঙে পড়ে।
Solution
সংখ্যা \(s = x^TAy\) দুইভাবে হিসাব করি।
পথ ১ (\(A\) ডানের \(y\)-কে খায়): \(s = x^T(Ay) = x^T(\mu y) = \mu\,(x^Ty)\)
পথ ২ (\(A\)-কে বাঁয়ে পাঠাই): \(s = (x^TA)y = (A^Tx)^Ty \overset{\color{red}{A^T=A}}{=} (Ax)^Ty = (\lambda x)^Ty = \lambda\,(x^Ty)\)
বিয়োগ: \(0 = s - s = (\mu - \lambda)(x^Ty)\); যেহেতু \(\mu \neq \lambda\), তাই \(x^Ty = 0\) ∎
কোথায় symmetry: পথ ২-এর লাল ধাপে — \((A^Tx)^T\)-কে \((Ax)^T\) লেখার সময়। Non-symmetric হলে সেখানে আসে \(A^Tx\), যেটা \(\lambda x\) নয় (\(A^T\)-এর eigenvector আলাদা হতে পারে) — সমীকরণ আর মেলে না। প্রমাণ fig01-এর ডান panel-এর সাক্ষ্যের সাথে মিলছে: non-symmetric-এ eigenvector-রা সত্যিই তির্যক।
Problem 3 (orthogonal diagonalization হাতে). \(A = \begin{bmatrix}1 & 3\\ 3 & 1\end{bmatrix}\)-কে orthogonally diagonalize করো: \(Q\) ও \(\Lambda\) বের করে \(Q^TQ = I\) এবং \(A = Q\Lambda Q^T\) যাচাই করো।
Solution
Eigenvalue: \(\det(A - \lambda I) = (1-\lambda)^2 - 9 = 0 \Rightarrow 1 - \lambda = \pm 3 \Rightarrow \lambda_1 = 4,\; \lambda_2 = -2\) (দুটোই real ✓; negative হতে বাধা নেই — real মানেই positive নয়!)
Eigenvector: \(\lambda_1 = 4\): \(\begin{bmatrix}-3&3\\3&-3\end{bmatrix}x = 0 \Rightarrow x_1 = (1,1)^T\)। \(\lambda_2 = -2\): \(\begin{bmatrix}3&3\\3&3\end{bmatrix}x = 0 \Rightarrow x_2 = (1,-1)^T\)। চেক: \(x_1^Tx_2 = 0\) ✓
Normalize:
যাচাই: \(Q^TQ = \frac12\begin{bmatrix}1&1\\1&-1\end{bmatrix}\begin{bmatrix}1&1\\1&-1\end{bmatrix} = \frac12\begin{bmatrix}2&0\\0&2\end{bmatrix} = I\) ✓
Problem 4 (spectral decomposition rebuild). Problem 3-এর \(A\)-এর spectral decomposition \(A = \lambda_1q_1q_1^T + \lambda_2q_2q_2^T\) লিখে entry ধরে ধরে যোগ করে দেখাও যে \(A\) ফেরত আসে। তারপর শুধু প্রথম টুকরো \(\lambda_1q_1q_1^T\) রাখলে কোন matrix পাও, আর সেটা \(A\) থেকে "কতদূরে"?
Solution
প্রথম টুকরো একা: \(A_1 = \begin{bmatrix}2&2\\2&2\end{bmatrix}\) — rank 1। ভুল: \(A - A_1 = \begin{bmatrix}-1&1\\1&-1\end{bmatrix} = \lambda_2q_2q_2^T\) — ঠিক ফেলে-দেওয়া টুকরোটাই, যার "size" \(|\lambda_2| = 2\)।
গভীর পাঠ: ভুলটা সবসময় ফেলে-দেওয়া টুকরোদের যোগফল, আর তার মাপ ফেলে-দেওয়া \(|\lambda|\)-দের ওপর — তাই ছোট \(|\lambda|\)-র টুকরো ফেললে ক্ষতি কম। এখানে \(|\lambda_2|/|\lambda_1| = 1/2\) — বেশ বড়, তাই approximation মোটা দাগের; Example 2-এর \(7\) বনাম \(3\)-এর power-জগতে কিন্তু ব্যবধানটা ফুলেফেঁপে উঠেছিলো। Chapter 6.6-এ এই "কোন টুকরো রাখবো" খেলাই হবে SVD-র image compression।
Problem 5 (proof-based, Guest review 1-এর আদলে). সব eigenvalue real — general proof। \(A\) real symmetric, \(Ax = \lambda x\), যেখানে হয়তো \(\lambda \in \mathbb{C}\), \(x \in \mathbb{C}^n\), \(x \neq 0\)। Complex conjugate \(\bar{x}\) নিয়ে সংখ্যা \(\bar{x}^TAx\) বিবেচনা করে দেখাও \(\lambda = \bar{\lambda}\), অর্থাৎ \(\lambda\) real।
Solution
প্রস্তুতি: \(z = a + bi\) হলে \(\bar{z}z = a^2 + b^2 \geq 0\) — real। তাই \(\bar{x}^Tx = \sum_i \bar{x}_ix_i = \sum_i |x_i|^2 > 0\) (কারণ \(x \neq 0\)) — positive real সংখ্যা।
দুই পথে \(\bar{x}^TAx\):
পথ ১: \(\bar{x}^TAx = \bar{x}^T(\lambda x) = \lambda\,(\bar{x}^Tx)\)
পথ ২: \(Ax = \lambda x\)-এর conjugate নাও: \(A\bar{x} = \bar{\lambda}\bar{x}\) (কারণ \(A\) real — conjugate-এ অটুট)। তাহলে
বিয়োগ: \(0 = (\lambda - \bar{\lambda})(\bar{x}^Tx)\); যেহেতু \(\bar{x}^Tx > 0\), তাই \(\lambda = \bar{\lambda}\) ⟹ \(\lambda\)-র imaginary part শূন্য ⟹ \(\lambda\) real ∎
লক্ষ করো: এটা Problem 2-এর যমজ ভাই — একই "এক সংখ্যা, দুই পথ" কৌশল; শুধু \(y\)-এর জায়গায় \(\bar{x}\)। Symmetry দুই miracle-এরই একমাত্র জ্বালানি।
Problem 6. \(Q\) orthogonal হলে প্রমাণ করো: (a) \(\|Qx\| = \|x\|\) সব \(x\)-এর জন্য, (b) \(Q\)-এর প্রতিটি (real) eigenvalue \(\pm 1\), (c) \(\det Q = \pm 1\)। ব্যাখ্যা করো (a) কেন fig04-এর "দৈর্ঘ্য অটুট" ছবির সাথে মেলে।
Solution
(a) \(\|Qx\|^2 = (Qx)^T(Qx) = x^T\underbrace{Q^TQ}_{I}x = x^Tx = \|x\|^2\) ✓ — rigid motion, fig04-এর ঘরের আকার তাই বদলায়নি।
(b) \(Qx = \lambda x\), \(x \neq 0\) হলে (a) থেকে: \(\|x\| = \|Qx\| = \|\lambda x\| = |\lambda|\|x\| \Rightarrow |\lambda| = 1\)। Real eigenvalue হলে \(\lambda = \pm 1\) ∎ (rotation-এর ক্ষেত্রে eigenvalue complex হতে পারে — \(e^{\pm i\theta}\) — কিন্তু তখনও \(|\lambda| = 1\): unit circle-এর ওপরেই।)
(c) \(\det(Q^TQ) = \det I = 1\); আর \(\det(Q^T) = \det Q\) (Chapter 6.1), তাই \((\det Q)^2 = 1 \Rightarrow \det Q = \pm 1\) ∎ — \(+1\) = rotation, \(-1\) = reflection (fig04-এর দুই panel)।
সংযোগ: এই তিন ধর্মই বলছে \(Q\) কিছু "নষ্ট" করে না — দৈর্ঘ্য না, আয়তন না (মাত্র sign)। তাই \(A = Q\Lambda Q^T\)-এ সব stretching-এর দায় একা \(\Lambda\)-র; \(Q\) শুধু মঞ্চ ঘোরায়।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "Symmetric মানে eigenvalue positive" | না — শুধু real-এর গ্যারান্টি; negative/শূন্য দিব্যি হতে পারে (Problem 3-এ \(\lambda = -2\))। Positive-এর জন্য চাই positive definite — সেটা Chapter 6.5। |
| "সব eigenvector orthogonal — যেভাবেই বের করি" | ভিন্ন eigenvalue-এর eigenvector-রা automatic লম্ব; কিন্তু repeated eigenvalue-এর eigenspace থেকে এলোমেলো basis নিলে লম্ব না-ও হতে পারে — নিজে Gram–Schmidt চালাতে হয় (Example 3)। eigh অবশ্য সব করে দেয়। |
| "Orthogonal matrix মানে symmetric matrix" | দুটো সম্পূর্ণ আলাদা ক্লাব: orthogonal ⟹ \(Q^TQ = I\) (rigid motion), symmetric ⟹ \(A^T = A\) (pure stretch)। Spectral Theorem-এ দুজনেই অভিনয় করে — \(Q\) ঘোরায়, \(\Lambda\) (symmetric-এর আত্মা) টানে। খুব কম matrix-ই দুটোই (যেমন \(I\), reflection)। |
| "\(A = Q\Lambda Q^{-1}\) আর \(Q\Lambda Q^T\) — লিখতে যা-ই হোক" | লেখাটা এক জিনিসই (\(Q^{-1} = Q^T\)), কিন্তু হিসাবের জগতে আকাশ-পাতাল: \(Q^T\) ফ্রি আর নির্ভুল; general \(X^{-1}\) ব্যয়বহুল আর ill-conditioned হতে পারে। Symmetric দেখলেই eigh/transpose-এর রাস্তা ধরো। |
| "Non-symmetric matrix-এও eigenvector-রা মোটামুটি লম্বই হবে" | না — ইচ্ছামতো তির্যক হতে পারে (fig01-এর ডান panel; প্রায় সমান্তরাল-ও সম্ভব)। প্রায়-সমান্তরাল eigenvector মানে \(X^{-1}\) বিস্ফোরক — সেজন্যই non-symmetric eigenvalue-হিসাব কাঁপা-কাঁপা, আর symmetric-eরটা পাথরের মতো stable। |
| "Spectral decomposition-এর টুকরো \(q_iq_i^T\) vectors" | না — প্রতিটা \(q_iq_i^T\) একটা \(n\times n\) matrix (rank 1): \(q_i\)-লাইনে projection মেশিন। \(\lambda_i\) ওজন দিয়ে \(n\)টা মেশিন যোগ করলে \(A\) (fig03)। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Symmetric matrix | \(A^T = A\) | diagonal বরাবর আয়না |
| Miracle ১ | সব eigenvalue real | \(\sqrt{b^2 + (\frac{a-d}{2})^2}\) — negative হতে পারে না |
| Miracle ২ | ভিন্ন \(\lambda\)-র eigenvector লম্ব | fig01-এর \(90°\) চিহ্ন |
| Spectral Theorem | \(A = Q\Lambda Q^T\), \(Q^TQ = I\) | ঘোরাও → টানো → ফেরত ঘোরাও |
| Spectral decomposition | \(A = \sum_i \lambda_i q_iq_i^T\) | projection-দের ওজনদার যোগফল |
| Orthogonal \(Q\) | \(Q^{-1} = Q^T\), \(\|Qx\| = \|x\|\) | rigid motion — কিছু ভাঙে না |
| Repeated \(\lambda\) | eigenspace-এ Gram–Schmidt | লম্ব basis বেছে নাও |
| DS/ML | covariance, Laplacian, kernel, Hessian — সব symmetric | PCA-র দরজা |
পরের chapter-এর সেতু: Spectral Theorem বললো symmetric matrix-এর eigenvalue সব real — কিন্তু real মানে positive, negative, শূন্য সবই হতে পারে। এই sign-গুলোই পরের গল্পের নায়ক: সব \(\lambda > 0\) হলে matrix-টা একটা নিখুঁত "পেয়ালা" (bowl) — আর কোনোটা negative হলে saddle, অর্থাৎ ঘোড়ার জিন। Least squares-এর \(A^TA\) কেন সবসময় ভদ্র, optimization-এ minimum চেনার শর্ত কী, আর \(x^TAx\) নামের quadratic form জিনিসটা কী — Chapter 6.5: Positive Definite Matrices & Quadratic Forms।
📓 Notebook Project¶
notebooks/part-06/ch04-project.ipynb — random symmetric matrix বানিয়ে eigenvector-দের পারস্পরিক লম্বতা (\(Q^TQ = I\)) সংখ্যায় যাচাই; spectral decomposition-কে rank-1 টুকরোয় ভেঙে টুকরো জুড়ে \(A\) rebuild; আর ছোট \(|\lambda|\)-র টুকরো এক এক করে বাদ দিলে \(A\)-এর কতটা হারায় তার পরীক্ষা — best rank-\(k\) approximation-এর হাতেখড়ি।