Chapter 8.1 — Floating Point, Conditioning ও Stability (কম্পিউটারে গণিত কেন ভুল হয়)¶
Part VII পর্যন্ত আমরা গণিত করেছি এক নিখুঁত স্বর্গে — যেখানে \(\frac{1}{3}\) ঠিক \(\frac{1}{3}\), আর \(0.1 + 0.2\) ঠিক \(0.3\)। এবার নামবো মাটিতে: কম্পিউটারের ভেতরে। সেখানে সংখ্যা রাখার জায়গা মাত্র ৬৪ bit, অধিকাংশ সংখ্যা রাখাই যায় না, প্রতিটা যোগ-গুণে একটু একটু করে ধুলো জমে — আর কখনো কখনো সেই ধুলো জমে পাহাড় হয়ে সঠিক উত্তরটাই গিলে ফেলে। Python খুলে
0.1 + 0.2 == 0.3লিখলে উত্তর আসেFalse— এই chapter শেষে তুমি শুধু জানবেই না কেন, বরং বলতে পারবে ভুলটা ঠিক কত বড়, কখন ভয়ংকর, আর কখন নিরীহ। এটাই Numerical Linear Algebra(নিউমেরিক্যাল লিনিয়ার অ্যালজেব্রা)-র প্রবেশদ্বার — fast.ai-এর course আর Trefethen–Bau বইয়ের প্রথম পাঠও ঠিক এখান থেকেই শুরু।
🎯 এই chapter-এ যা শিখবে¶
- Floating Point(ফ্লোটিং পয়েন্ট) সংখ্যা আসলে কী — কেন \(0.1 + 0.2 \neq 0.3\), আর কেন তবু বিমানের হিসাব ঠিক থাকে
- Machine Epsilon(মেশিন এপসাইলন) \(\approx 2.2 \times 10^{-16}\) — কম্পিউটারের "সবচেয়ে ছোট দেখার ক্ষমতা"
- Condition Number(কন্ডিশন নাম্বার) \(\kappa(A) = \sigma_1/\sigma_n\) — সমস্যাটা নিজে কতটা স্পর্শকাতর, তার geometric ছবি
- Catastrophic Cancellation(ক্যাটাস্ট্রফিক ক্যানসেলেশন) — প্রায়-সমান দুই সংখ্যার বিয়োগ কীভাবে নিমেষে সব digit মুছে দেয়
- Stability(স্ট্যাবিলিটি) বনাম Conditioning — "algorithm-এর দোষ" আর "সমস্যার দোষ" আলাদা করে চেনা
🖼️ এক ছবিতে মূল idea¶
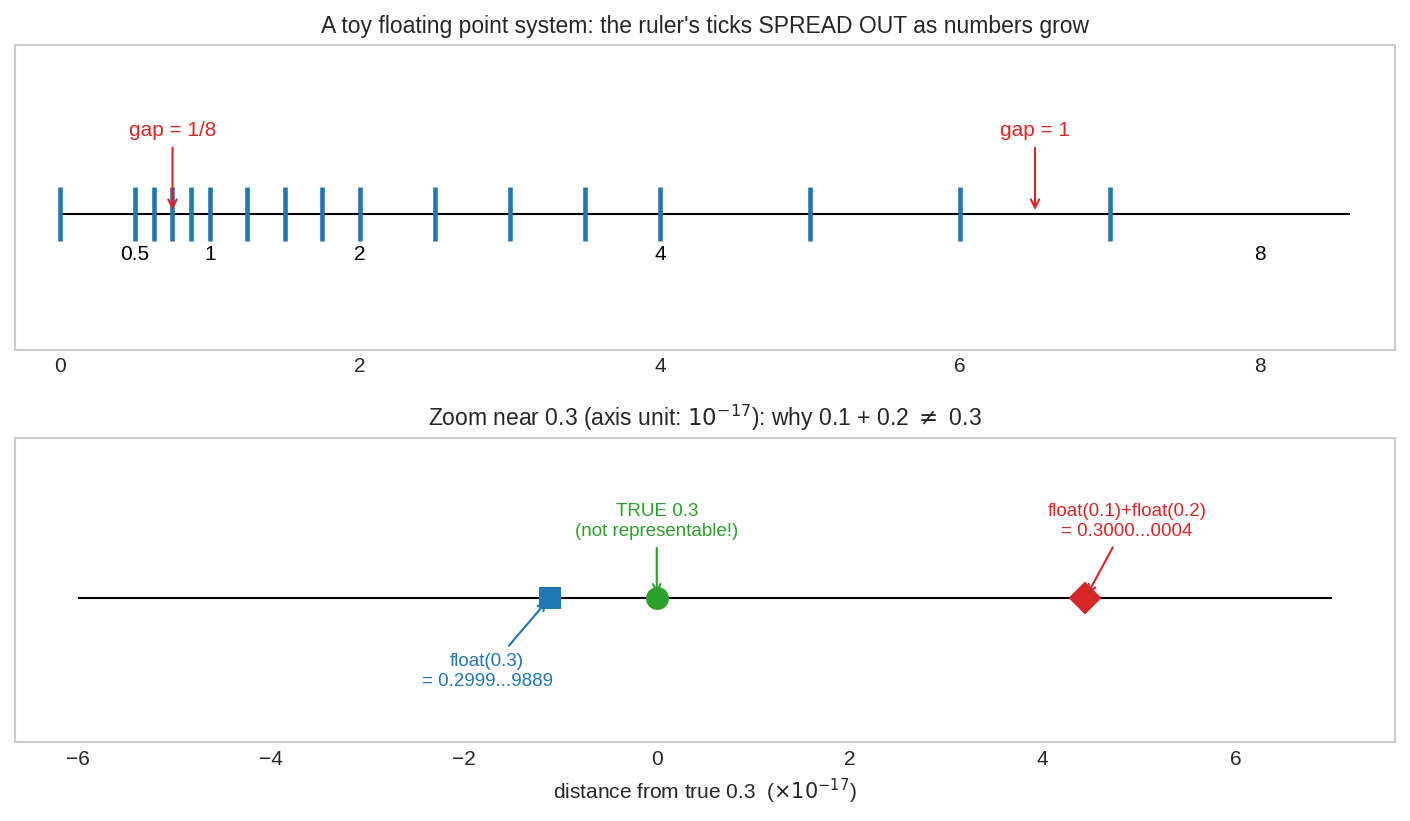
কম্পিউটারের সংখ্যারেখা আসলে একটা অসম-দাগের রুলার (ওপরে): ছোট সংখ্যার দিকে দাগ ঘন, বড়র দিকে ফাঁকা — দাগের মাঝের কোনো সংখ্যাই সে লিখতে পারে না। নিচে \(10^{-17}\) স্কেলে zoom: সত্যিকারের \(0.3\) (সবুজ) কোনো দাগে পড়েনি, তাই 0.3 লিখলে পাও কাছের দাগ (নীল), আর 0.1+0.2 হিসাব করলে পাও অন্য কাছের দাগ (লাল) — দুটো আলাদা দাগ, তাই False।
১. কি? (What)¶
দৈনন্দিন analogy: তিন-ঘর ক্যালকুলেটর¶
ধরো তোমার কাছে এমন এক খাতা, যেখানে যেকোনো সংখ্যা লেখার জন্য বরাদ্দ মাত্র তিনটা ঘর + একটা দশমিকের অবস্থান। তুমি লিখতে পারো \(1.23\), \(45.6\), \(0.00789\) (\(7.89 \times 10^{-3}\) আকারে) — অর্থাৎ তিনটা significant digit(সিগনিফিক্যান্ট ডিজিট) আর একটা exponent। এবার \(\frac{1}{3}\) লিখতে বললে? তুমি লিখবে \(0.333\) — কাছাকাছি, কিন্তু ঠিক নয়। \(12.34 + 0.005\)? উত্তর \(12.345\)-এর জায়গা নেই — লিখবে \(12.3\); ছোট সংখ্যাটা হাওয়ায় মিলিয়ে গেলো।
কম্পিউটার ঠিক এই খাতাটাই — শুধু দশমিকের বদলে binary(বাইনারি), আর তিন ঘরের বদলে ৫২টা ঘর। একে বলে Floating Point(ফ্লোটিং পয়েন্ট — ভাসমান দশমিক) ব্যবস্থা: দশমিক বিন্দুটা "ভেসে" যেখানে দরকার সেখানে বসে, তাই একই ৬৪ bit-এ \(10^{-300}\) থেকে \(10^{300}\) পর্যন্ত সংখ্যা ধরা যায় — কিন্তু সবসময় ওই ৫২-ঘরের সীমার ভেতরে।
সংজ্ঞা¶
IEEE 754 double precision(ডাবল প্রিসিশন) — Python-এর float, NumPy-র float64 — একটা সংখ্যাকে রাখে এই আকারে:
- Sign(সাইন): ১ bit — ধনাত্মক না ঋণাত্মক
- Mantissa(ম্যান্টিসা): ৫২ bit — সংখ্যার "অঙ্কগুলো", binary-তে; সামনের \(1.\) ফ্রি (সবসময় থাকে বলে রাখা লাগে না)
- Exponent(এক্সপোনেন্ট): ১১ bit — দশমিক বিন্দু কোথায় ভাসছে
এবার রহস্যভেদ: দশমিকে \(0.1 = \frac{1}{10}\) খুব ভদ্র সংখ্যা, কিন্তু binary-তে হর \(10 = 2 \times 5\)-এর মধ্যে ওই \(5\)-টাই সর্বনাশ করে — \(\frac{1}{10}\) binary-তে অসীম আবর্তক ভগ্নাংশ: \((0.0001100110011\overline{0011}\ldots)_2\)। ৫২ ঘরের খাতায় অসীম লেখা যায় না, তাই কম্পিউটার রাখে সবচেয়ে কাছের ভাসমান-দাগটা:
\(0.2\) আর \(0.3\)-ও তা-ই — প্রত্যেকে একটু একটু ভেজাল। ভেজাল \(0.1\) + ভেজাল \(0.2\) যোগ করে, ফলটাকে আবার কাছের দাগে গোল করে কম্পিউটার পায় এক দাগ; আর সরাসরি 0.3 লিখলে পায় আরেক দাগ। দুই দাগের ফারাক মাত্র \(5.5 \times 10^{-17}\) — কিন্তু == অপারেটর তো আর "প্রায় সমান" বোঝে না!
Machine Epsilon(মেশিন এপসাইলন): \(1\)-এর পরের representable সংখ্যাটার দূরত্ব —
এর মানে: double precision-এ প্রতিটা সংখ্যা সর্বোচ্চ আপেক্ষিক ভুল \(\varepsilon_{\text{mach}}/2\) নিয়ে রাখা যায়, আর প্রতিটা যোগ-বিয়োগ-গুণ-ভাগের ফলও একই মানের আপেক্ষিক গোলযোগে গোল হয়। এক লাইনে: কম্পিউটার প্রায় ১৬টা দশমিক digit পর্যন্ত সৎ।
২. দেখতে কেমন?¶
দৃশ্য ১: অসম রুলার — gap বাড়ে সংখ্যার সাথে¶
Opening figure-এর ওপরের প্যানেলটা আবার দেখো: একটা খেলনা float ব্যবস্থা (mantissa-তে মাত্র ২ bit)। \([0.5, 1)\) অঞ্চলে দাগগুলোর ফাঁক \(\frac{1}{8}\), আর \([4, 8)\) অঞ্চলে ফাঁক \(1\) — সংখ্যা যত বড়, প্রতিবেশী তত দূরে। আসল double-এও একই গল্প, শুধু ফাঁকগুলো আপেক্ষিকভাবে \(\sim\varepsilon_{\text{mach}}\)।
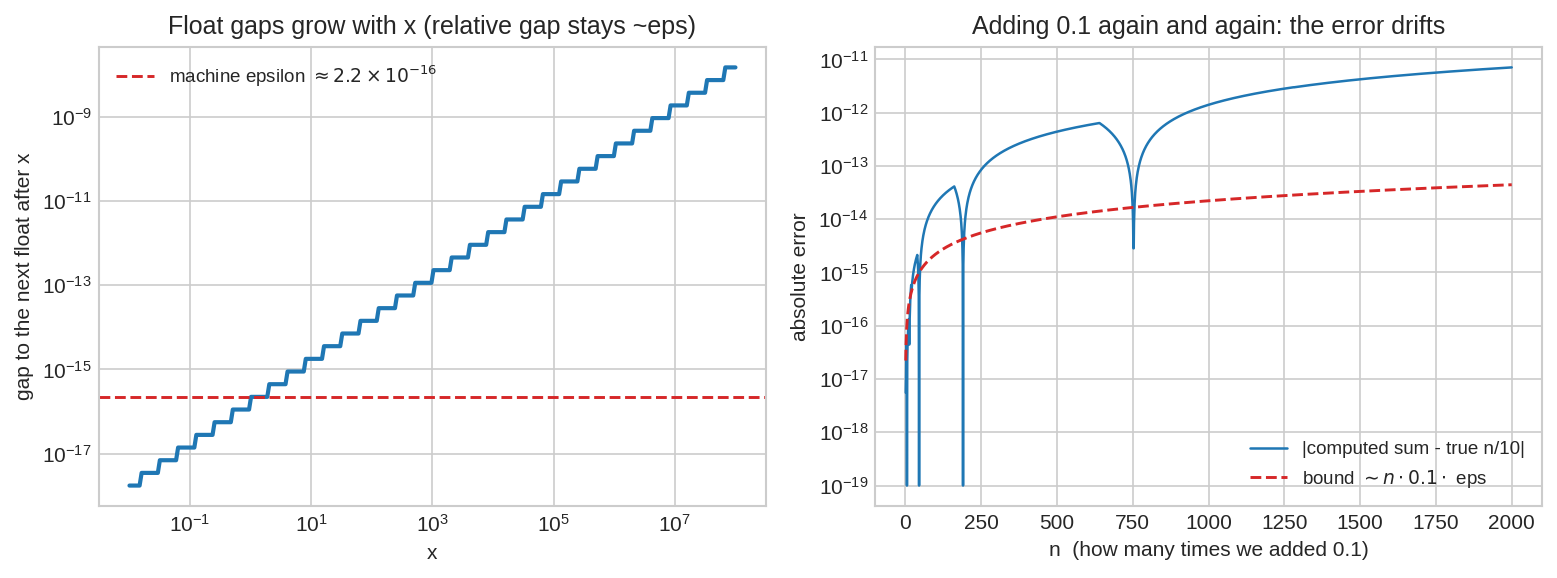
বাঁয়ে: \(x\)-এর পরের float-টার দূরত্ব (np.spacing) — সংখ্যা \(10\) গুণ বড় হলে ফাঁকও \(10\) গুণ — আপেক্ষিক ফাঁক সবসময় \(\approx \varepsilon_{\text{mach}}\)। ডানে: \(0.1\) বারবার যোগ করলে জমতে-থাকা ভুল — \(2000\) বার যোগের পরেও ভুল \(\sim 10^{-13}\), তুচ্ছ; কিন্তু শূন্য নয়, আর == দিয়ে ধরা পড়ার মতো যথেষ্ট।
দৃশ্য ২: Conditioning — সমস্যা নিজেই কতটা নড়বড়ে¶
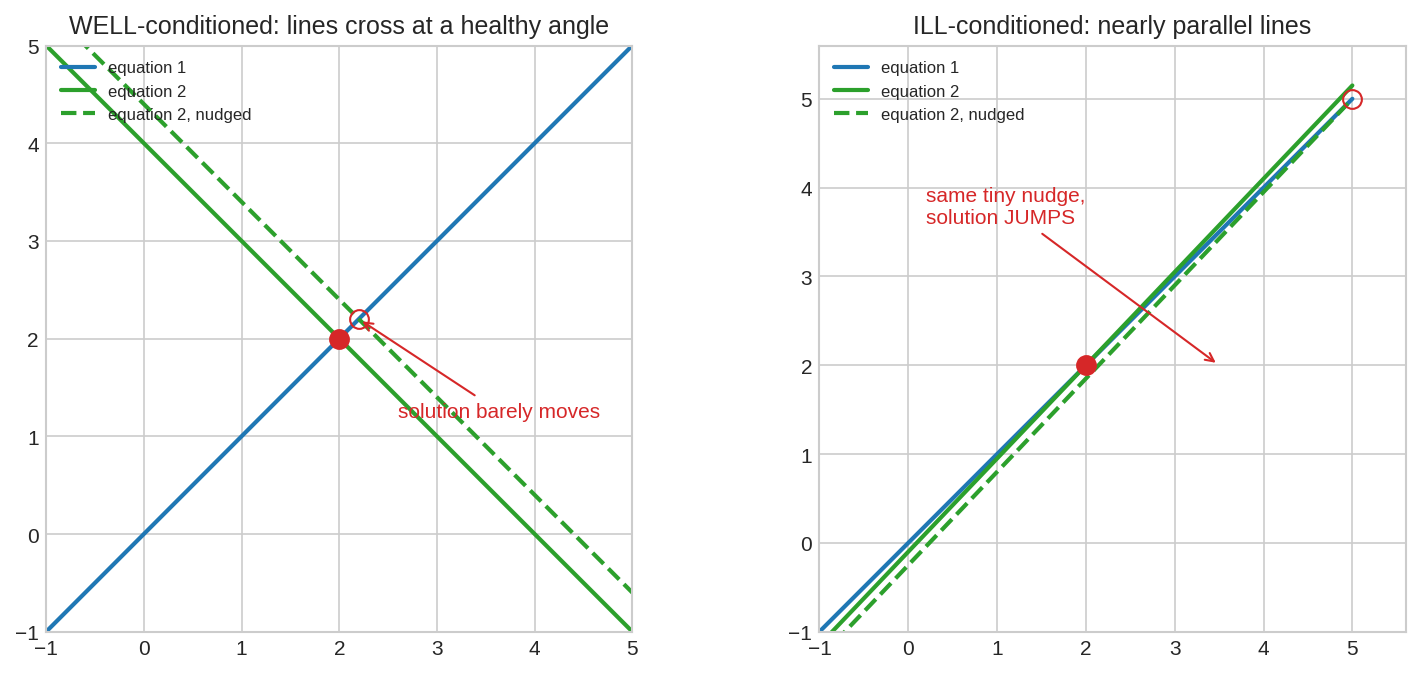
দুই সমীকরণের ছেদবিন্দুই \(Ax = b\)-এর সমাধান (Chapter 2.1-এর row picture)। বাঁয়ে লাইন দুটো স্বাস্থ্যকর কোণে কাটে — একটা লাইন সামান্য নাড়ালে (ড্যাশ) ছেদবিন্দু সামান্যই সরে। ডানে লাইন দুটো প্রায় সমান্তরাল — একই মাপের নাড়ায় ছেদবিন্দু লাফ দেয় বহুদূর। এই দ্বিতীয় দশার নামই ill-conditioned।
দৃশ্য ৩: Condition number-এর আসল চেহারা — বৃত্ত থেকে ডিম¶
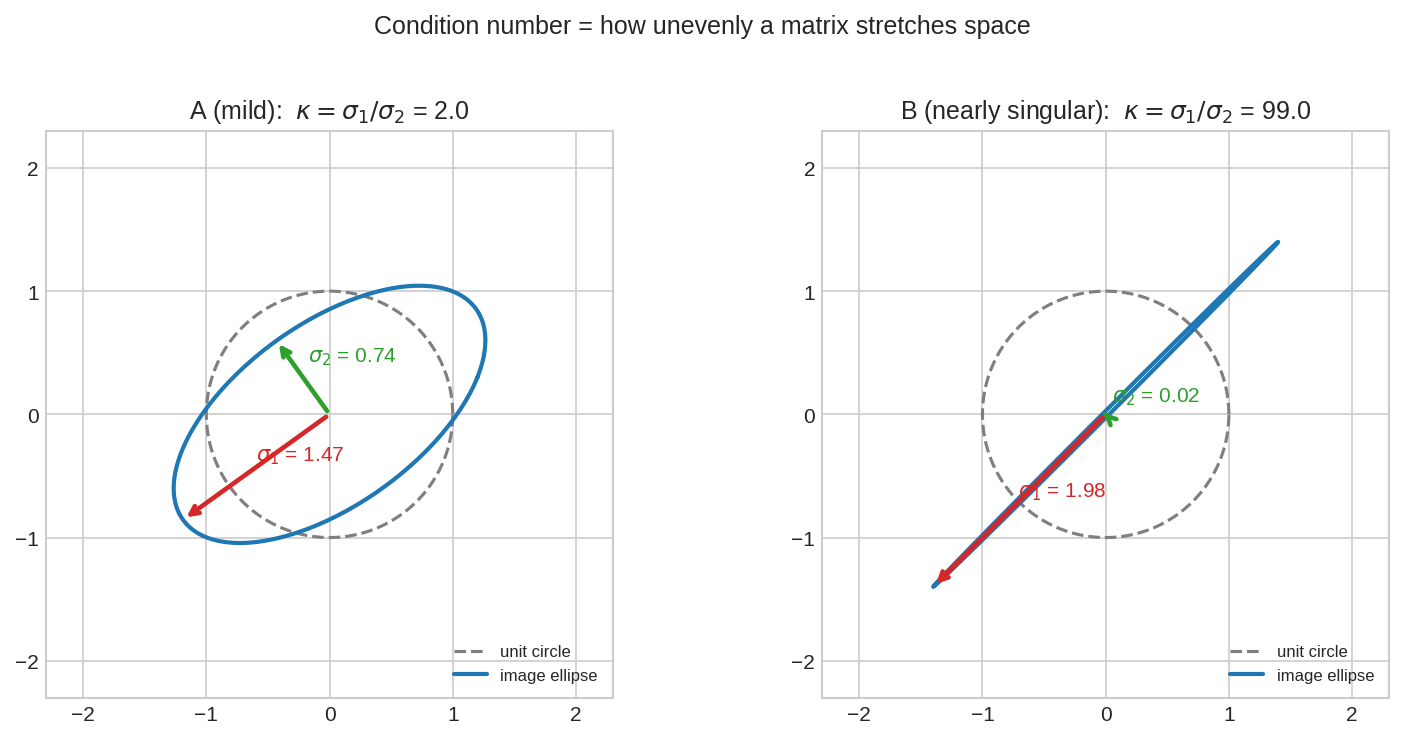
Part VI-এর SVD মনে করো: যেকোনো matrix unit circle-কে ellipse বানায়, যার আধা-অক্ষগুলো singular value \(\sigma_1 \ge \sigma_2\)। বাঁয়ের matrix সব দিক মোটামুটি সমান টানে (\(\kappa \approx 2\)); ডানেরটা এক দিকে টানে \(\sigma_1 \approx 2\), আরেক দিকে চ্যাপ্টা করে \(\sigma_2 \approx 0.02\)-তে (\(\kappa \approx 99\)) — প্রায় singular। এই "কত অসমান টান"-এর অনুপাতই condition number।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে (এবং বাস্তব দুর্ঘটনায়):
- Patriot missile (১৯৯১): সময় গোনা হতো \(0.1\) সেকেন্ডের টিকে — সেই না-লেখা-যাওয়া binary \(0.1\)-এর ভুল \(100\) ঘণ্টায় জমে \(0.34\) সেকেন্ড; radar ভুল জায়গায় খুঁজলো, missile miss করলো — ২৮ জন নিহত। "\(10^{-8}\)-এর ভুল তুচ্ছ" — যতক্ষণ না তুমি তাকে কোটিবার জমতে দাও।
- Ariane 5 রকেট (১৯৯৬): সংখ্যা রাখার জায়গা উপচে (overflow) \(37\) সেকেন্ডে \(37\) কোটি ডলারের রকেট আত্মধ্বংস।
- Vancouver Stock Exchange index (১৯৮২): প্রতিটা লেনদেনে index-কে তিন decimal-এ truncate (গোল না করে কেটে ফেলা) করা হতো; ২২ মাসে index অর্ধেক "হারিয়ে" গেলো — গণিতের বাজারে ধস নয়, rounding-এর!
- তোমার ব্যাংক: টাকার হিসাব float-এ করা হয় না — decimal/integer type-এ হয়, ঠিক এই chapter-এর ভয়গুলোর কারণে।
Data Science / ML-এ:
- Deep learning-এর
float32/float16/bfloat16: GPU-তে জায়গা ও গতির জন্য আরো কম ঘরের খাতা — mixed precision training পুরোটাই "কোথায় কতটুকু ভুল সইবে"-র খেলা। - Loss
NaNহয়ে যাওয়া: overflow/underflow-এর ক্লাসিক লক্ষণ — softmax-এ \(e^{1000}\), log-এ \(\log(0)\); চিকিৎসা (log-sum-exp trick) এই chapter-এরই কৌশল। - Feature scaling: unscaled feature-এ \(X^TX\)-এর condition number আকাশ ছোঁয় — gradient descent ধীর, সমাধান অবিশ্বস্ত (Chapter 5.4-এর সেই সাবধানবাণী)।
np.allcloseকেন আছে: দুটো float array কখনোই==দিয়ে মেলাবে না — এই chapter-এর পরে তুমি জানো কেন।
৪. Properties¶
Property 1 — Rounding-এর মৌলিক গ্যারান্টি¶
যেকোনো বাস্তব সংখ্যা \(x\) (range-এর ভেতরে) কম্পিউটারে ঢুকলে হয় \(\text{fl}(x)\), যেখানে
আর প্রতিটা মৌলিক operation (\(+, -, \times, \div\))-এর ফলও ঠিক-উত্তর-তারপর-গোল:
অর্থ: এক-একটা ধাপ কখনোই \(10^{-16}\) আপেক্ষিক ভুলের বেশি করে না। বিপদ আসে ভুল জমে বা ফুলে উঠলে — সেটাই পরের property-গুলোর বিষয়।
Property 2 — Float-এর পাটিগণিত স্কুলের নিয়ম মানে না¶
- Associativity ভাঙে:
(0.1 + 0.2) + 0.3 != 0.1 + (0.2 + 0.3)— প্রতি ধাপের গোল-করা ভিন্ন পথে ভিন্ন ফল দেয়। - বড় + ছোট = বড়: \(10^{16} + 1 = 10^{16}\) (float-এ) — ছোটটা gap-এর নিচে চাপা পড়ে। এ জন্যই অনেক ছোট সংখ্যা যোগ করার সময় ছোট থেকে বড় ক্রমে যোগ করা ভালো।
- বিয়োগে digit-হত্যা: প্রায়-সমান দুটো সংখ্যার বিয়োগে সামনের মিলে-যাওয়া digit-গুলো কেটে যায়, পেছনের আবর্জনা-digit সামনে উঠে আসে (Property 4)।
Property 3 — Condition number: সমস্যার নিজস্ব "ভুল-বিবর্ধক"¶
\(Ax = b\)-তে input \(b\)-কে একটু নাড়ালে সমাধান \(x\) কতটা নড়ে? Perturbation(পারটার্বেশন — সূক্ষ্ম নাড়া) \(\delta b\) দিলে \(A(x + \delta x) = b + \delta b\), অর্থাৎ \(\delta x = A^{-1}\delta b\)। আপেক্ষিক নড়াচড়ার অনুপাত:
এই \(\kappa(A)\)-ই Condition Number — Part VI-এর singular value দিয়ে: সবচেয়ে বড় টান ভাগ সবচেয়ে ছোট টান। ধর্মগুলো:
- \(\kappa(A) \ge 1\) সবসময়; \(\kappa = 1\) কেবল orthogonal matrix-দের (তারা নিখুঁত — শুধু ঘোরায়, টানে না)
- \(\kappa(A)\) scale-নিরপেক্ষ: \(\kappa(10A) = \kappa(A)\) — determinant-এর মতো ধোঁকা দেয় না (ছোট \(\det\) মানেই খারাপ নয়!)
- \(A\) singular-এর যত কাছে, \(\kappa\) তত বড়; singular হলে \(\kappa = \infty\)
Property 4 — আঙুলের নিয়ম: কত digit হারাবে¶
Double-এ পুঁজি ১৬ digit। \(\kappa = 10^4\) হলে ভরসাযোগ্য থাকে \(\approx 12\) digit — চলনসই। \(\kappa = 10^{16}\) (Hilbert matrix-রা এমন) হলে ভরসাযোগ্য digit শূন্য — উত্তর পুরোটাই সন্দেহজনক, যত ভালো algorithm-ই হোক।
Property 5 — Stability: algorithm-এর সততা¶
একই সমস্যা, দুই formula — এক ফল দেয় না (opening-এর naive বনাম stable মনে করো)। পার্থক্যটা algorithm-এর। একটা algorithm Backward Stable(ব্যাকওয়ার্ড স্টেবল) যদি তার দেওয়া উত্তর হয় একটু-নাড়ানো প্রশ্নের নিখুঁত উত্তর:
তখন মোট ভুলের সোনার সূত্র:
ভুল = সমস্যার স্পর্শকাতরতা × যন্ত্রের সূক্ষ্মতা। Algorithm ভালো হলে তার নিজের কোনো দোষ যোগ হয় না — সে শুধু \(\kappa\)-র অনিবার্য মাশুলটুকু দেয়।
৫. Intuition — কেন সত্য?¶
Condition number-এর geometric গল্প: চ্যাপ্টা ডিম উল্টে দেখা¶
Figure 4-এর ছবিটা মনে আনো। \(A\) unit circle-কে বানায় ellipse: লম্বা অক্ষ \(\sigma_1\), খাটো অক্ষ \(\sigma_n\)। এখন \(Ax = b\) সমাধান করা মানে উল্টো পথে হাঁটা: \(b\) থেকে \(x = A^{-1}b\)।
উল্টো পথে কী হয়? \(A\) যে দিকটা \(\sigma_n\)-গুণ চ্যাপ্টা করেছিল, \(A^{-1}\) সেই দিকে \(\frac{1}{\sigma_n}\)-গুণ টেনে লম্বা করে। ধরো \(\sigma_n = 10^{-6}\)। তাহলে \(b\)-এর গায়ে ওই চ্যাপ্টা দিকে লেগে-থাকা \(10^{-16}\) মাপের rounding-ধুলোও \(A^{-1}\)-এর হাতে পড়ে \(10^{-16} \times 10^{6} = 10^{-10}\) হয়ে যায় — ধুলো ফুলে উঠলো দশ লাখ গুণ! আর আপেক্ষিক হিসাবে ফোলার মাত্রাটা ঠিক \(\frac{\sigma_1}{\sigma_n} = \kappa\)।
তাই ill-conditioned মানে: matrix-টা কোনো এক দিকে প্রায়-মেরে-ফেলে (singular-এর কিনারে), আর সমাধান করতে গেলে সেই আধমরা দিকের noise-ই দানব হয়ে ফিরে আসে। এটা algorithm-এর দোষ নয় — প্রশ্নটার শরীরেই রোগ। ডাক্তার (algorithm) যত ভালোই হোক, রোগী (matrix) মরণাপন্ন হলে চিকিৎসার সীমা আছে।
Cancellation-এর গল্প: দুই লম্বা লাঠির ফারাক মাপা¶
\(1.234567890123456\underline{7}\) আর \(1.234567890123455\underline{9}\) — দুটোই ১৬-digit নিখুঁত। বিয়োগ দাও: \(0.0000000000000008\)। সামনের ১৫টা digit কেটে গেলো, রইলো একটা মাত্র অর্থবহ digit — আর ওই শেষ digit-গুলো তো এমনিতেই rounding-এর কুয়াশায় ছিল! আপেক্ষিক ভুল লাফিয়ে গেলো \(10^{-16}\) থেকে প্রায় \(1\)-এ। বিয়োগ নিজে কোনো ভুল করেনি (Property 1 মেনেই চলেছে) — সে শুধু আগে-থেকে-থাকা ভুলটাকে আপেক্ষিকভাবে বিশাল বানিয়ে দিয়েছে, কারণ উত্তরটাই ছোট। এ জন্যই নাম catastrophic cancellation — কাটাকাটিটাই সর্বনাশ।
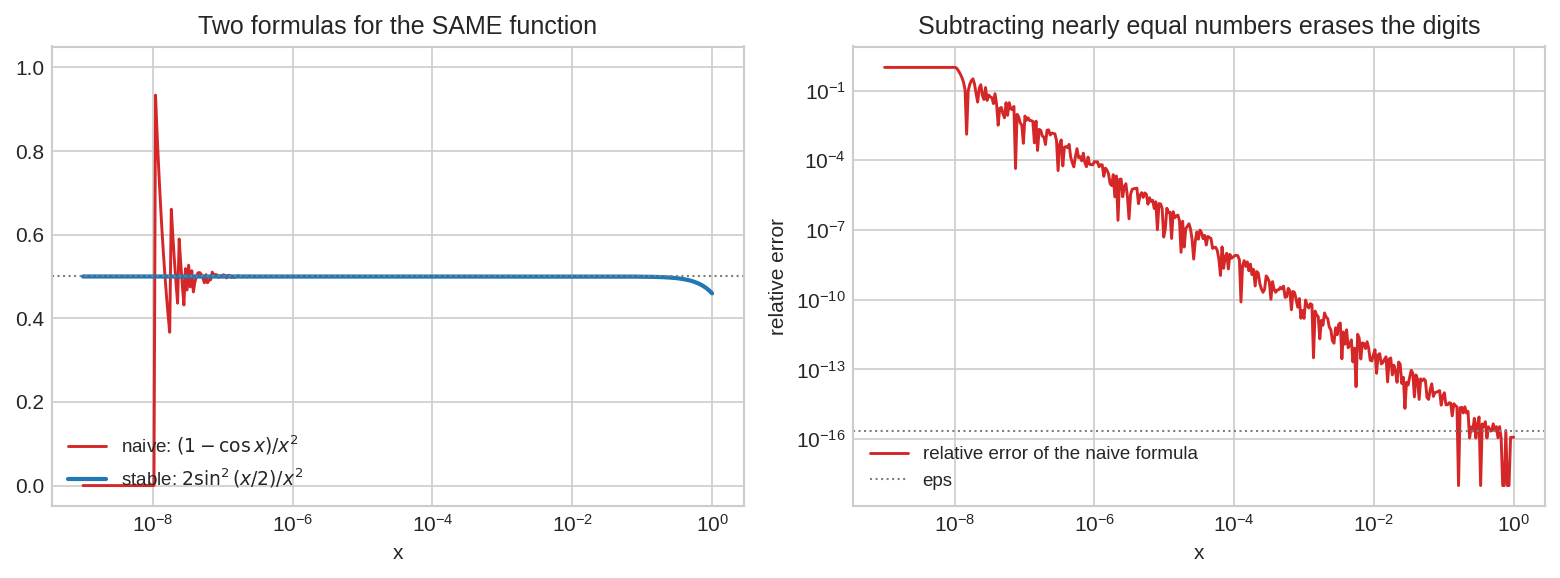
একই ফাংশন \(f(x) = \frac{1-\cos x}{x^2}\) দুই সূত্রে। গণিতে দুটো অভিন্ন; কম্পিউটারে \(x < 10^{-4}\) হতেই naive সূত্র (লাল) কাঁপতে শুরু করে, \(x \approx 10^{-8}\)-এ পুরো ভুল (\(1 - \cos x\) underflow করে \(0\)!)। Stable সূত্র \(\frac{2\sin^2(x/2)}{x^2}\) (নীল) — বিয়োগই নেই, তাই শান্ত। ডানে: naive-এর আপেক্ষিক ভুল \(x\) কমার সাথে কীভাবে \(\varepsilon_{\text{mach}}\) থেকে \(1\) পর্যন্ত ওঠে।
Stability বনাম Conditioning — দুই অপরাধী আলাদা করো¶
| ভালো-conditioned সমস্যা | Ill-conditioned সমস্যা | |
|---|---|---|
| Stable algorithm | নিখুঁত ফল ✅ | ফল খারাপ, কিন্তু দোষ সমস্যার — এর চেয়ে ভালো সম্ভবই না |
| Unstable algorithm | ফল খারাপ — দোষ algorithm-এর, বদলাও! | দ্বিগুণ সর্বনাশ ❌ |
এই ২×২ টেবিলটা মাথায় গেঁথে নাও — সামনের তিন chapter-এ বারবার ফিরবে: LU pivoting ছাড়া unstable (8.2), normal equations \(\kappa\)-কে বর্গ করে (8.2), power method stable কিন্তু ধীর হতে পারে (8.3)।
৬. Code-এ কেমনে লিখে¶
import numpy as np
# --- রহস্য ১: 0.1 + 0.2 ---
print(0.1 + 0.2) # 0.30000000000000004
print(0.1 + 0.2 == 0.3) # False
print(f"{0.1:.20f}") # 0.10000000000000000555 <- আসল সংরক্ষিত মান
print(f"{0.3:.20f}") # 0.29999999999999998890
# সঠিক অভ্যাস: tolerance দিয়ে তুলনা
print(abs((0.1 + 0.2) - 0.3) < 1e-9) # True
print(np.isclose(0.1 + 0.2, 0.3)) # True
# --- মেশিনের চোখের ক্ষমতা ---
print(np.finfo(float).eps) # 2.220446049250313e-16
# --- রহস্য ২: catastrophic cancellation ---
x = 1e-8
naive = (1 - np.cos(x)) / x**2 # বিয়োগে digit-হত্যা
stable = 2 * np.sin(x/2)**2 / x**2 # বিয়োগ নেই
print("naive :", naive) # 0.0 <- ১০০% ভুল!
print("stable:", stable) # 0.5 <- সঠিক
# --- রহস্য ৩: conditioning ---
A = np.array([[1.0, 1.0],
[1.0, 1.0001]]) # প্রায় সমান্তরাল দুই সারি
b = np.array([2.0, 2.0001])
print("cond =", np.linalg.cond(A)) # 40002.0...
x1 = np.linalg.solve(A, b)
b2 = b + np.array([0.0, 0.0002]) # b-তে সূক্ষ্ম নাড়া
x2 = np.linalg.solve(A, b2)
print("x1 =", x1) # [1. 1.]
print("x2 =", x2) # [-1. 3.] <- সমাধান লাফিয়ে গেলো!
Output ব্যাখ্যা:
0.1-এর ভেতরের আসল মানটা%.20fফরম্যাটে ধরা পড়লো — Python সাধারণত সবচেয়ে ছোট unambiguous রূপ দেখায় বলে ভেজালটা লুকানো থাকে।naiveদিলো0.0— কারণ \(\cos(10^{-8})\) float-এ ঠিক \(1\); বিয়োগে সব digit গেলো।stableদিলো নির্ভুল0.5।- \(\kappa \approx 4 \times 10^4\) matrix-এ \(b\)-এর \(7 \times 10^{-5}\) আপেক্ষিক নাড়ায় সমাধান নড়লো \(200\%\) — বিবর্ধন \(\approx 2.8 \times 10^4\), প্রায় \(\kappa\)-র সমান। সূত্র মিলে গেলো হাতে-নাতে।
৭. Worked Examples¶
Example 1 — তিন-digit খাতায় quadratic formula ভেঙে পড়া¶
সমীকরণ: \(x^2 - 100x + 1 = 0\)। সত্যিকারের মূল দুটো: \(x_1 \approx 99.98999\ldots\), \(x_2 \approx 0.0100001\ldots\)।
ধাপ ১ — পরিচিত সূত্রে, ৫-digit হিসাবে: \(\sqrt{b^2 - 4ac} = \sqrt{10000 - 4} = \sqrt{9996} \approx 99.980\)।
ধাপ ২ — বড় মূল: \(x_1 = \frac{100 + 99.980}{2} = 99.990\) ✅ (যোগ — কোনো বিপদ নেই)
ধাপ ৩ — ছোট মূল: \(x_2 = \frac{100 - 99.980}{2} = \frac{0.020}{2} = 0.010\) — মাত্র ২টা ভরসাযোগ্য digit! (\(100\) আর \(99.980\) প্রায় সমান — cancellation।)
ধাপ ৪ — Stable বিকল্প: Vieta-র সূত্র \(x_1 x_2 = c/a = 1\), তাই
— বিয়োগ এড়িয়ে পুরো precision ফেরত। শিক্ষা: একই গণিতের অনেক চেহারা; কম্পিউটারের জন্য বাছতে হয় বিয়োগ-এড়ানো চেহারাটা।
Example 2 — condition number হাতে হিসাব¶
\(A = \begin{bmatrix} 1 & 1 \\ 1 & 1.0001 \end{bmatrix}\) (Code section-এর matrix)।
ধাপ ১: \(A^TA = \begin{bmatrix} 2 & 2.0001 \\ 2.0001 & 2.00020001 \end{bmatrix}\); এর eigenvalue-রা \(\lambda = \sigma^2\) (Part VI)।
ধাপ ২: trace \(\approx 4.0002\), \(\det(A) = 1.0001 - 1 = 10^{-4}\), তাই \(\det(A^TA) = 10^{-8}\)।
ধাপ ৩: \(\lambda_1 \approx 4.0002\) (প্রায় পুরো trace), \(\lambda_2 = \frac{10^{-8}}{4.0002} \approx 2.5 \times 10^{-9}\)।
ধাপ ৪: \(\kappa = \sqrt{\lambda_1/\lambda_2} \approx \sqrt{1.6 \times 10^9} \approx 4.0 \times 10^4\) — NumPy-র cond-এর সাথে মিললো ✅
লক্ষ করো: \(\det = 10^{-4}\) শুনতে "ছোট কিন্তু ঠিকঠাক" লাগে; আসল গল্পটা বলে \(\kappa\) — এই matrix চার decimal digit খেয়ে ফেলবে।
Example 3 — যোগের ক্রমেই উত্তর বদলায়¶
\(10^{16} + 1 - 10^{16}\) — বাঁ থেকে ডানে: \(10^{16} + 1 = 10^{16}\) (gap \(= 2\), তাই \(1\) চাপা পড়লো), তারপর \(-10^{16}\) দিলে উত্তর \(\mathbf{0}\)। অথচ \(10^{16} - 10^{16} + 1\) ক্রমে করলে \(\mathbf{1}\) — সঠিক।
শিক্ষা: float-এ যোগ associative না। বহু সংখ্যা যোগে (যেমন loss-এর gradient accumulate) ছোটগুলো আগে যোগ করা, বা Kahan summation / math.fsum ব্যবহার — এগুলো এই একটা ছবির-ই প্রতিকার।
৮. Problems ও Solutions¶
Problem 1. Python-এ 0.5 + 0.25 == 0.75 চালালে True আসে, অথচ 0.1 + 0.2 == 0.3 আসে False — ব্যাখ্যা করো। কোন দশমিক ভগ্নাংশগুলো float-এ নিখুঁত রাখা যায়?
Solution
Float-এর mantissa হলো base-2 ভগ্নাংশ। \(0.5 = 2^{-1}\), \(0.25 = 2^{-2}\), \(0.75 = 2^{-1} + 2^{-2}\) — সবগুলোই \(2\)-এর ঘাতের সসীম যোগফল, তাই ৫২ bit-এ নিখুঁত বসে; যোগফলও নিখুঁত, তুলনা True।
নিখুঁত রাখা যায় ঠিক সেই ভগ্নাংশগুলো যাদের লঘিষ্ঠ আকারের হর \(2\)-এর ঘাত: \(\frac{p}{2^k}\) (এবং mantissa ৫২ bit-এ ধরে)। \(0.1 = \frac{1}{10}\)-এর হরে \(5\) আছে — binary-তে অসীম আবর্তক, তাই ভেজাল অনিবার্য।
শিক্ষা: দশমিকে "গোলগাল" মানেই binary-তে গোলগাল নয় — কম্পিউটারের চোখে \(0.1\) হলো \(\frac{1}{3}\)-এর মতোই অসীম দশা।
Problem 2. float64-এ \(10^{16} + 1 == 10^{16}\) সত্য কেন? \(10^{16}\)-এর কাছে পরপর দুই float-এর gap আন্দাজ করো, আর বলো ঠিক কোন মাত্রার সংখ্যা থেকে "পূর্ণসংখ্যা যোগ করলেও টের পাওয়া যায় না" শুরু হয়।
Solution
আপেক্ষিক gap \(\approx \varepsilon_{\text{mach}} = 2^{-52}\), তাই \(x = 10^{16}\)-এর কাছে পরম gap:
(\(10^{16} \approx 2^{53.15}\); \(2^{53}\) পেরোলে gap \(= 2\)।) \(+1\) দিলে ফল দুই দাগের মাঝে পড়ে এবং কাছের দাগ \(10^{16}\)-এই ফিরে যায়।
সীমানা: \(2^{53} = 9{,}007{,}199{,}254{,}740{,}992 \approx 9 \times 10^{15}\) — এর নিচে সব পূর্ণসংখ্যা float-এ নিখুঁত; এর ওপরে জোড়-বিজোড়ও আর আলাদা থাকে না। (JavaScript-এর Number.MAX_SAFE_INTEGER ঠিক \(2^{53} - 1\) — এই কারণেই!)
Problem 3. \(f(x) = \sqrt{x + 1} - \sqrt{x}\), বড় \(x\)-এর জন্য (যেমন \(x = 10^{12}\))। (a) সরাসরি সূত্রে কী বিপদ? (b) বীজগণিতে রূপান্তর করে stable সূত্র বানাও। (c) দুই সূত্রে \(x = 10^{12}\)-এর মান আন্দাজ করো।
Solution
(a) \(\sqrt{10^{12} + 1}\) আর \(\sqrt{10^{12}} = 10^6\) মিলবে প্রায় ১২ digit পর্যন্ত — বিয়োগে সেই digit-গুলো কেটে catastrophic cancellation; থাকবে মোটে ~৪ digit।
(b) Conjugate দিয়ে গুণ:
— বিয়োগ উধাও, শুধু যোগ আর ভাগ; পুরো ১৬ digit বাঁচে।
(c) Stable সূত্রে: \(\frac{1}{2 \times 10^6 + \text{(ক্ষুদ্র)}} \approx 5.0 \times 10^{-7}\) — নির্ভুল। Naive সূত্রে উত্তরের প্রথম ৪-৫ digit ঠিক থাকলেও বাকিটা আবর্জনা; আরো বড় \(x\)-এ (যেমন \(10^{16}\)) naive দেবে flat \(0\)।
Problem 4. \(A = \begin{bmatrix} 1 & 1 \\ 1 & 1+\epsilon \end{bmatrix}\), \(\epsilon > 0\) ছোট। দেখাও \(\kappa(A) \approx \frac{4}{\epsilon}\) (মাত্রার হিসাবে), এবং \(\epsilon = 10^{-12}\) হলে double precision-এ সমাধানের কয়টা digit ভরসাযোগ্য?
Solution
Example 2-এর পথ ধরে: \(A^TA\)-এর trace \(= 4 + O(\epsilon)\), আর \(\det(A) = \epsilon\) বলে \(\det(A^TA) = \epsilon^2\)।
Eigenvalue দুটো: \(\lambda_1 \approx 4\), \(\lambda_2 \approx \frac{\epsilon^2}{4}\)। অতএব
(\(\epsilon = 10^{-4}\)-এ এটা দেয় \(4 \times 10^4\) — Code section-এর cond-এর সাথে মেলে ✓)
\(\epsilon = 10^{-12}\) হলে \(\kappa \approx 4 \times 10^{12}\); হারানো digit \(\approx \log_{10}\kappa \approx 12.6\)। ভরসাযোগ্য থাকলো \(16 - 12.6 \approx \mathbf{3}\) digit। Matrix-টা দেখতে নিরীহ — কিন্তু তার দুই column প্রায় একই দিকে (প্রায় সমান্তরাল লাইন), আর সেটাই রোগ।
Problem 5. Variance-এর দুই সূত্র: (i) \(\frac{1}{n}\sum(x_i - \bar{x})^2\), (ii) \(\frac{1}{n}\sum x_i^2 - \bar{x}^2\)। ডেটা: \(x = (10^8, 10^8 + 1, 10^8 + 2)\)। কোন সূত্র কম্পিউটারে বিপজ্জনক আর কেন? (এই ফাঁদটা বাস্তব library-তেও ধরা পড়েছিল!)
Solution
সত্যিকারের variance: \(\bar{x} = 10^8 + 1\), deviation \((-1, 0, 1)\), variance \(= \frac{2}{3}\)।
সূত্র (ii) বিপজ্জনক: \(\sum x_i^2 \approx 3 \times 10^{16}\) আর \(n\bar{x}^2 \approx 3 \times 10^{16}\) — দুটো বিশাল, প্রায় সমান সংখ্যার বিয়োগে উত্তর মোটে \(\sim 1\) মাপের। \(10^{16}\) মাপের সংখ্যায় float-এর gap-ই \(\approx 2\) — অর্থাৎ উত্তরের চেয়ে বড়! ফল: শূন্য, ভুল, এমনকি ঋণাত্মক variance-ও আসতে পারে।
সূত্র (i) নিরাপদ: আগে গড় বিয়োগ — deviation-গুলো ছোট (\(-1, 0, 1\)), তাদের বর্গের যোগে কোনো cancellation নেই।
শিক্ষা: "গণিতে সমান" দুই সূত্রের computational চরিত্র আকাশ-পাতাল। বড় সংখ্যার জগতে আগে center করো, পরে বর্গ — Statistics curriculum-এর one-pass variance আলোচনাও মনে করো।
Problem 6. তোমার বন্ধু বললো: "আমার matrix-এর \(\det(A) = 10^{-20}\), তাই এটা ভয়ানক ill-conditioned।" যুক্তিটা ভুল কেন? এমন একটা \(100 \times 100\) matrix দাও যার determinant \(10^{-20}\)-এরও ছোট কিন্তু \(\kappa = 1\) (নিখুঁত conditioned), আর এমন ধারণা দাও কোন matrix-এর \(\det = 1\) কিন্তু \(\kappa\) বিশাল।
Solution
Counter-example 1: \(A = \frac{1}{2}I_{100}\)। তখন \(\det(A) = 2^{-100} \approx 8 \times 10^{-31}\) — অতি ক্ষুদ্র! কিন্তু সব singular value সমান (\(\frac{1}{2}\)), তাই \(\kappa = 1\) — এর চেয়ে সুস্থ matrix হয় না; সমাধান মানে স্রেফ \(2\) দিয়ে গুণ।
Counter-example 2: \(A = \begin{bmatrix} 10^{8} & 0 \\ 0 & 10^{-8} \end{bmatrix}\); \(\det = 1\) — "সুন্দর"! কিন্তু \(\kappa = \frac{10^8}{10^{-8}} = 10^{16}\) — double precision-এ কার্যত singular।
মূল কথা: determinant scale-এর দাস (\(\det(cA) = c^n\det A\)), conditioning scale-নিরপেক্ষ। Singular-এর "কাছে" থাকা মাপে singular value-দের অনুপাত — determinant নয়। "Determinant ছোট = খারাপ matrix" হলো এই chapter-এর সবচেয়ে জনপ্রিয় ভুল ধারণা।
Problem 7. Backward stability-র সূত্র \(\frac{\|\hat x - x\|}{\|x\|} \lesssim \kappa(A)\,\varepsilon_{\text{mach}}\) ব্যবহার করে: (a) \(\kappa = 10^{10}\) matrix double-এ solve করলে কত digit পাবে? (b) একই matrix float32-এ (\(\varepsilon \approx 6 \times 10^{-8}\))? (c) deep learning-এ কেন তবু float16 চলে — এক লাইনে।
Solution
(a) আপেক্ষিক ভুল \(\lesssim 10^{10} \times 2.2 \times 10^{-16} \approx 2 \times 10^{-6}\) — প্রায় ৫–৬ digit ঠিক।
(b) float32-এ: \(10^{10} \times 6 \times 10^{-8} \approx 600\) — আপেক্ষিক ভুল \(1\)-এর অনেক ওপরে; অর্থাৎ একটাও digit ভরসাযোগ্য নয়, ফল সম্পূর্ণ আবর্জনা। একই সমস্যা, শুধু precision বদলে সমাধান সম্ভব-অসম্ভবের সীমা পেরোলো।
(c) Neural network training-এ আমরা \(Ax=b\)-এর ১৬-digit উত্তর চাই না — চাই মোটামুটি সঠিক দিকের gradient; SGD-র নিজের noise-ই এত বেশি যে rounding noise তাতে চাপা পড়ে যায় (তবু loss-scaling-এর মতো সাবধানতা লাগে overflow/underflow ঠেকাতে)।
Problem 8. (কোডে) \(n = 5, \ldots, 13\)-এর জন্য Hilbert matrix \(H_{ij} = \frac{1}{i+j-1}\) বানাও; জানা \(x_{\text{true}} = (1,\ldots,1)\) থেকে \(b = Hx_{\text{true}}\) বানিয়ে np.linalg.solve(H, b) করো; আপেক্ষিক ভুল আর \(\kappa(H)\varepsilon_{\text{mach}}\) পাশাপাশি ছাপো। সূত্রের ভবিষ্যদ্বাণী মেলে?
Solution
import numpy as np
from scipy.linalg import hilbert
eps = np.finfo(float).eps
for n in range(5, 14):
H = hilbert(n)
x_true = np.ones(n)
b = H @ x_true
x = np.linalg.solve(H, b)
err = np.linalg.norm(x - x_true) / np.linalg.norm(x_true)
bound = np.linalg.cond(H) * eps
print(f"n={n:2d} cond={np.linalg.cond(H):9.2e} "
f"error={err:9.2e} kappa*eps={bound:9.2e}")
Output-এর ধরন: প্রতি ধাপে \(\kappa\) প্রায় \(\times 20\) বাড়ে; error-ও প্রায় সেই তালে বাড়ে এবং সবসময় \(\kappa\varepsilon\) bound-এর নিচে/আশেপাশে থাকে। \(n = 12\)–\(13\)-এ \(\kappa > 10^{16} = 1/\varepsilon\) — bound \(> 1\), অর্থাৎ কোনো digit-এরই গ্যারান্টি নেই; বাস্তবেও error \(\sim 1\) মাপে পৌঁছে যায়।
শিক্ষা: সূত্রটা শুধু তত্ত্ব নয় — এক লাইনের পরীক্ষায় নিজের চোখে দেখা যায়। আর Hilbert matrix হলো ill-conditioning-এর জাদুঘর: দেখতে নিষ্পাপ ভগ্নাংশের টেবিল, ভেতরে \(\kappa\)-দানব।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "float-এর ভুল মানে কম্পিউটার random ভুল করে" | কিছুই random নয় — প্রতিটা rounding IEEE 754-এর নির্ধারিত (deterministic) নিয়মে হয়; একই হিসাব বারবার চালালে হুবহু একই উত্তর। ভুলটা সসীম-ঘরের খাতার অনিবার্য পরিণাম, খামখেয়ালি নয়। |
"দুটো float == দিয়ে মেলানো যাবে না — কখনোই" |
প্রায়-ঠিক, তবে সূক্ষ্মতা আছে: পূর্ণসংখ্যা (\(< 2^{53}\)), \(2\)-এর ঘাতের ভগ্নাংশ, আর সরাসরি assign-করা মান ==-এ নিরাপদ। হিসাবের ফলাফল মেলাতে সবসময় np.isclose/np.allclose (tolerance ভেবে-চিন্তে)। |
| "\(\det(A) \approx 0\) মানেই matrix ill-conditioned" | না — Problem 6 দেখো: \(\det\) scale-এর দাস, \(\kappa\) নয়। Singular-নৈকট্যের সৎ মাপ \(\kappa = \sigma_1/\sigma_n\); NumPy-তে np.linalg.cond। |
| "ভুল উত্তর মানেই algorithm খারাপ" | আগে জিজ্ঞেস করো \(\kappa\) কত। \(\kappa\varepsilon_{\text{mach}}\) মাপের ভুল সমস্যার প্রাপ্য — পৃথিবীর সেরা algorithm-ও এর নিচে নামাতে পারে না। Algorithm-কে দোষ দাও কেবল ভুল এর চেয়ে অনেক বড় হলে (তখন সে unstable)। |
| "বেশি precision (float128) নিলেই সব সমাধান" | Precision বাড়ানো \(\varepsilon\) কমায়, কিন্তু \(\kappa\) কমায় না — ill-conditioned সমস্যা ill-conditioned-ই থাকে; খরচ বাড়ে, রোগ সারে না। আসল চিকিৎসা: সমস্যাটাই নতুন করে সাজানো (scaling, regularization, orthogonal পথ — পরের chapter-গুলো)। |
| "ছোট সংখ্যার ভুল, জমলেও ছোটই থাকবে" | Patriot missile-এর ২৮টা প্রাণ বলছে অন্য কথা: \(10^{-8}\)-এর ভুল \(\times\) কোটি পুনরাবৃত্তি = দৃশ্যমান বিপর্যয়। আর cancellation হলে তো এক ধাপেই আপেক্ষিক ভুল \(10^{-16}\) থেকে \(1\)-এ লাফায়। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Floating point | \(\pm(1.b_1\ldots b_{52})_2 \times 2^e\) | অসম-দাগের রুলার — বড় সংখ্যায় ফাঁকা দাগ |
| \(0.1+0.2\neq 0.3\) | \(0.1\) binary-তে অসীম আবর্তক | তিন ভেজাল সংখ্যার যোগ ≠ চতুর্থ ভেজাল |
| Machine epsilon | \(\varepsilon_{\text{mach}} = 2^{-52} \approx 2.2\times10^{-16}\) | ১৬ digit-এর সততা |
| Condition number | \(\kappa(A) = \sigma_1/\sigma_n \ge 1\) | বৃত্ত → কতটা চ্যাপ্টা ডিম |
| ভুলের সোনার সূত্র | \(\text{rel. error} \lesssim \kappa(A)\,\varepsilon_{\text{mach}}\) | হারানো digit \(\approx \log_{10}\kappa\) |
| Cancellation | প্রায়-সমানের বিয়োগ = digit-হত্যা | দুই লম্বা লাঠির ফারাক ফিতায় মাপা |
| Stability | উত্তর = কাছের প্রশ্নের নিখুঁত উত্তর | দোষ কার — রোগীর না ডাক্তারের? |
পরের chapter-এর সেতু: ভাষা শিখলাম — এবার কাজ। \(Ax = b\) তো Part II-তেই "শেখা শেষ"; কিন্তু ১০ লাখ সমীকরণ, একই \(A\)-তে হাজারটা \(b\), আর ৯৯.9% শূন্যে ভরা matrix এলে elimination-কে নতুন চোখে দেখতে হয়: LU/Cholesky/QR-এর কে কখন, flop গোনা, sparse-এর জগত, আর সেই বিখ্যাত আদেশ — inverse কখনো নেবে না। Chapter 8.2: Solving Ax = b বাস্তবে।
📓 Notebook Project¶
notebooks/part-08/ch01-project.ipynb — নিজের হাতে একটা খেলনা float-ব্যবস্থা বানিয়ে তার সংখ্যারেখা আঁকবে, cancellation-এর দুই সূত্রের দ্বৈরথ চালাবে, আর Hilbert matrix-এ \(\kappa\varepsilon\) সূত্রের ভবিষ্যদ্বাণী হাতে-নাতে যাচাই করবে।