Chapter 9.4 — Matrix Calculus (ম্যাট্রিক্স ক্যালকুলাস)¶
আধুনিক deep learning-এর পুরো গল্পটা এক বাক্যে: "loss কমাও।" আর কিছু কমাতে হলে জানতে হয় কোন দিকে গেলে কমে — অর্থাৎ derivative নিতে হয়। সমস্যা একটাই: স্কুলের ক্যালকুলাসে চলক ছিল একটা সংখ্যা \(x\), আর এখন চলক হলো লক্ষ-কোটি সংখ্যাভর্তি vector আর matrix — একটা GPT-র ওজন \(W\)-দের সবগুলো মিলে শত-কোটি চলক! ভয়ের কিছু নেই: এক-চলকের derivative-এর মূল idea-টা — "ফাংশনের best linear approximation" — হুবহু একই থাকে, শুধু 'ঢাল-সংখ্যা'-র জায়গা নেয় Gradient(গ্রেডিয়েন্ট) vector আর Jacobian(জ্যাকোবিয়ান) matrix। আর সবচেয়ে মজার খবর: Part III-এ শেখা "matrix = transformation" আর "matrix multiplication = composition" — এই দুটো পুরনো বন্ধুই এখানে chain rule হয়ে ফিরে আসবে, আর তাদের কাঁধে চড়েই আমরা backpropagation(ব্যাকপ্রোপাগেশন) — অর্থাৎ PyTorch-এর হৃদপিণ্ড — নিজ হাতে derive করবো। এটা এই Part-এর flagship chapter — সিটবেল্ট বাঁধো।
🎯 এই chapter-এ যা শিখবে¶
- এক-চলকের ঢাল → Directional Derivative(ডিরেকশনাল ডেরিভেটিভ) → Gradient \(\nabla f\): "derivative মানে best linear approximation" — আসল সংজ্ঞাটা
- Jacobian matrix = "প্রতিটা বিন্দুতে map-টার নিজস্ব local matrix", আর Hessian(হেসিয়ান) = gradient-এর Jacobian — Part VI 6.5-এর PD/saddle-এর সাথে সেতু
- মৌলিক সূত্রগুলো হাতে derive: \(\nabla(a^Tx) = a\), \(\nabla(x^TAx) = (A+A^T)x\), chain rule \(J_{f\circ g} = J_f\, J_g\)
- Flagship 1: least squares-এর gradient থেকে normal equations — Part V-এর projection-ছবি আর ক্যালকুলাস একই উত্তরে মেলে!
- Flagship 2: 2-layer neural net-এর সব gradient ধাপে ধাপে — backprop = reverse-mode chain rule, "error নামে transpose-এর সিঁড়ি বেয়ে"
- Numerical gradient check — নিজের backprop-কে অন্ধবিশ্বাস না করে যাচাই করার পেশাদার কৌশল
🖼️ এক ছবিতে মূল idea¶
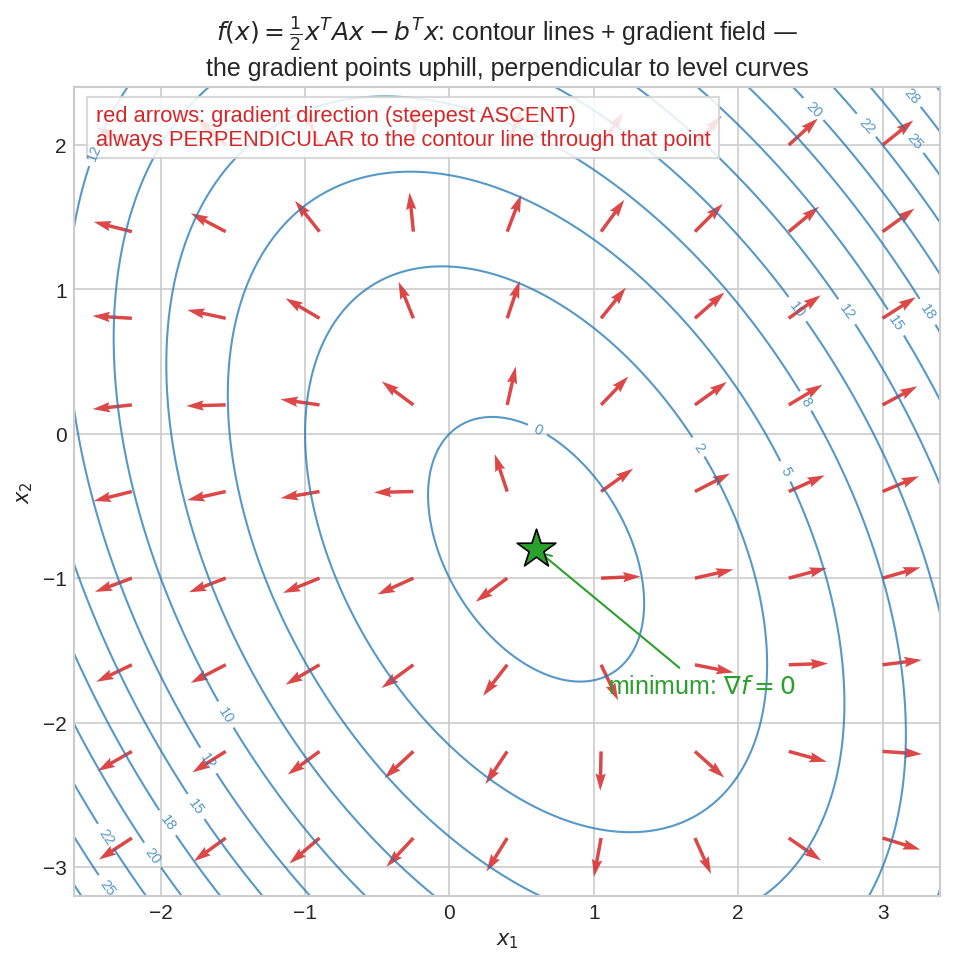
একটা quadratic function \(f(x) = \frac12 x^TAx - b^Tx\)-এর contour(কনট্যুর) রেখা (নীল) আর প্রতিটা বিন্দুতে তার gradient (লাল তীর)। দুটো জিনিস লক্ষ করো: gradient সবসময় সবচেয়ে খাড়া ওঠার দিকে দেখায়, আর সে সবসময় contour রেখার লম্ব। সবুজ তারায় \(\nabla f = 0\) — সেখানেই minimum। "loss কমাও" মানে লাল তীরের উল্টো দিকে হাঁটো — এটুকুই gradient descent-এর পুরো দর্শন।
১. কি? (What)¶
দৈনন্দিন analogy: কুয়াশায় পাহাড় থেকে নামা¶
তুমি ঘন কুয়াশায় এক পাহাড়ের গায়ে দাঁড়িয়ে। চারপাশ দেখা যায় না, কিন্তু পায়ের নিচের ঢাল-টা টের পাও। এক-চলকের জগতে পাহাড় ছিল একটা রেখা — ঢাল একটাই সংখ্যা \(f'(x)\)। কিন্তু এখন পাহাড়টা দ্বিমাত্রিক জমির ওপর (\(x_1, x_2\) দুই দিকেই হাঁটা যায়): উত্তরে গেলে হয়তো চড়াই, পূর্বে গেলে উৎরাই, উত্তর-পূর্বে গেলে মাঝামাঝি। অর্থাৎ প্রতিটা দিকের নিজস্ব ঢাল আছে। প্রশ্ন: এতগুলো ঢালের খবর একসাথে বহন করে কে?
উত্তর: একটাই vector — gradient। সে এমন এক জাদুকরী তীর, যাকে জিজ্ঞেস করলেই যেকোনো দিকের ঢাল বলে দিতে পারে (dot product দিয়ে — Part II!), আর নিজে সবসময় সবচেয়ে খাড়া চড়াইয়ের দিকে তাক করে থাকে।
সংজ্ঞাটা সাবধানে বানাই: linear approximation-ই আসল derivative¶
গল্পটা আগে শোনো। স্কুলে শিখেছো \(f'(x) = \lim_{h\to0}\frac{f(x+h)-f(x)}{h}\)। কিন্তু \(x\) vector হলে "\(h\) দিয়ে ভাগ" অর্থহীন — vector দিয়ে ভাগ হয় না! তাই সংজ্ঞাটাকে এমনভাবে নতুন করে লিখতে হবে যেখানে ভাগ নেই। কৌশল: ভাগের সমীকরণটাকে গুণের ভাষায় উল্টে লেখো — \(f(x+h) \approx f(x) + f'(x)\,h\)। এই রূপে \(f'(x)\)-এর কাজ হলো "ছোট \(h\)-এর জন্য \(f\)-এর পরিবর্তনের best linear অনুমান দেওয়া" — আর linear জিনিস তো আমরা vector-matrix জগতে চিনিই!
সংজ্ঞা। \(f: \mathbb{R}^n \to \mathbb{R}\)-এর \(x\) বিন্দুতে gradient হলো সেই vector \(\nabla f(x) \in \mathbb{R}^n\) যার জন্য ছোট সরণ \(h \in \mathbb{R}^n\)-এ
— ডান পাশের ভুলটা \(\|h\|\)-এর তুলনায়ও দ্রুত শূন্যে যায়। এক লাইনে: gradient হলো \(f\)-এর পরিবর্তনের best linear approximation-এর coefficient vector। হিসাবের সুবিধায় দেখা যায় এর component-গুলো ঠিক partial derivative:
আর যেকোনো unit দিক \(u\)-তে ঢাল (directional derivative) \(= \nabla f^T u\) — Cauchy–Schwarz (Part II) বলে এটা সবচেয়ে বড় হয় যখন \(u\) ঠিক \(\nabla f\)-এর দিকে। তাই gradient = সবচেয়ে খাড়া ওঠার দিক, আর contour-রেখা ধরে হাঁটলে \(f\) বদলায় না বলে সেই দিকে \(\nabla f^T u = 0\) — অর্থাৎ gradient contour-এর লম্ব (fig01-এ যা দেখলে)।
Jacobian: যখন output-ও vector¶
Map-টা যদি \(F: \mathbb{R}^n \to \mathbb{R}^m\) হয় (vector ঢোকে, vector বেরোয়), best linear approximation-টা হবে একটা matrix:
এটাই Jacobian। Part III-এ শিখেছিলে "matrix মানে জায়গার linear রূপান্তর" — Jacobian সেই কথারই স্থানীয় সংস্করণ: nonlinear map-ও প্রতিটা বিন্দুর আশেপাশে ছোট জানালায় একটা matrix-এর মতোই আচরণ করে, আর সেই local matrix-টাই Jacobian। পুরো ক্যালকুলাসের সবচেয়ে সুন্দর বাক্য সম্ভবত এটাই।
Hessian: gradient-এরও derivative আছে¶
\(\nabla f: \mathbb{R}^n \to \mathbb{R}^n\) নিজেই একটা vector→vector map — তার Jacobian-কে বলে Hessian:
মিশ্র partial-দের ক্রম বদলানো যায় (\(f\) যথেষ্ট মসৃণ হলে), তাই \(H_{ij} = H_{ji}\) — Hessian সবসময় symmetric। আর symmetric matrix মানেই Part VI 6.5-এর দরজা খুলে গেলো: real eigenvalue, orthogonal eigenvector, positive definite কি না — সব প্রশ্ন করা যাবে। Critical point-এ (\(\nabla f = 0\)) Hessian-ই বলে দেয় সেটা বাটি না জিনের আসন (saddle) — §২-এ ছবি।
একটা সৎ স্বীকারোক্তি: layout convention¶
Matrix calculus-এর বইপত্রে একটা কুখ্যাত গোলমাল আছে: কেউ gradient-কে column লেখে (denominator layout), কেউ row (numerator layout)। দুটোই ব্যবহারে আছে, ফলে এক বইয়ের সূত্র আরেক বইয়ে transpose হয়ে যায়! আমরা এই বইয়ে convention ঠিক করে নিচ্ছি: gradient সবসময় column vector (variable-এর shape-এর সমান), আর \(F:\mathbb{R}^n\to\mathbb{R}^m\)-এর Jacobian \(m \times n\)। অন্য বই আলাদা হতে পারে — ভয় নেই: সন্দেহ হলেই dimension মেলাও। Dimension-check এই chapter-এ আমাদের সবচেয়ে বিশ্বস্ত অস্ত্র হবে।
২. দেখতে কেমন?¶
দৃশ্য ১: Jacobian — বাঁকা map-এর ভেতরে লুকানো local matrix¶
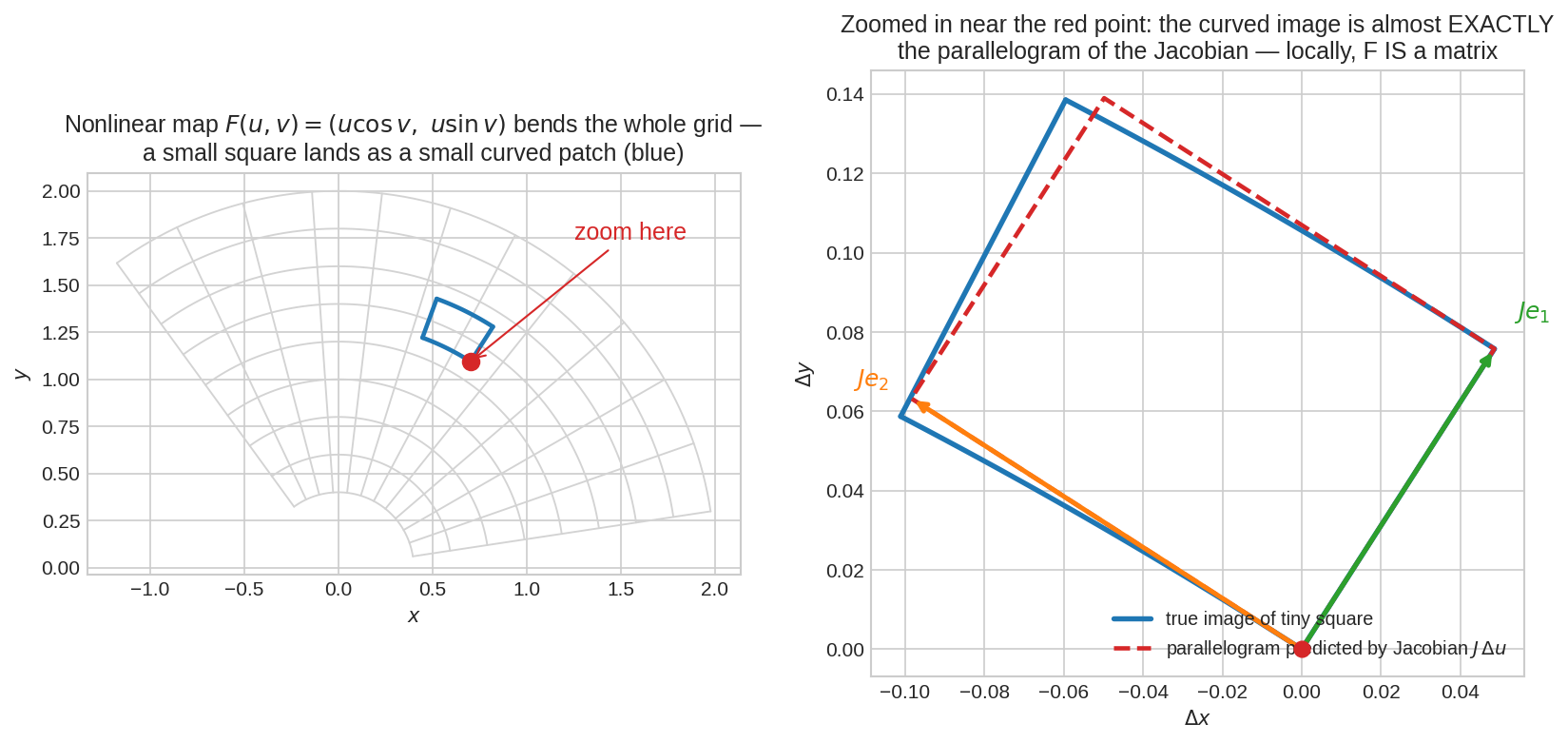
বাঁয়ে nonlinear map \(F(u,v) = (u\cos v,\ u\sin v)\) পুরো grid-কে পাখার মতো বাঁকিয়ে দিয়েছে — একটা ছোট নীল বর্গ গিয়ে পড়েছে বাঁকানো টুকরো হয়ে। ডানে লাল বিন্দুর কাছে zoom: বাঁকা টুকরোটা প্রায় নিখুঁতভাবে মিলে গেছে Jacobian matrix-এর বানানো parallelogram-এর (লাল ড্যাশ) সাথে — যার বাহু \(Je_1\), \(Je_2\) (Part III-এর "basis vector কোথায় যায়" ছবিটা মনে করো!)। ছোট জানালায় প্রতিটা মসৃণ map-ই linear — সেই linear map-টার নাম Jacobian।**
দৃশ্য ২: Hessian gallery — critical point-এর তিন চেহারা¶
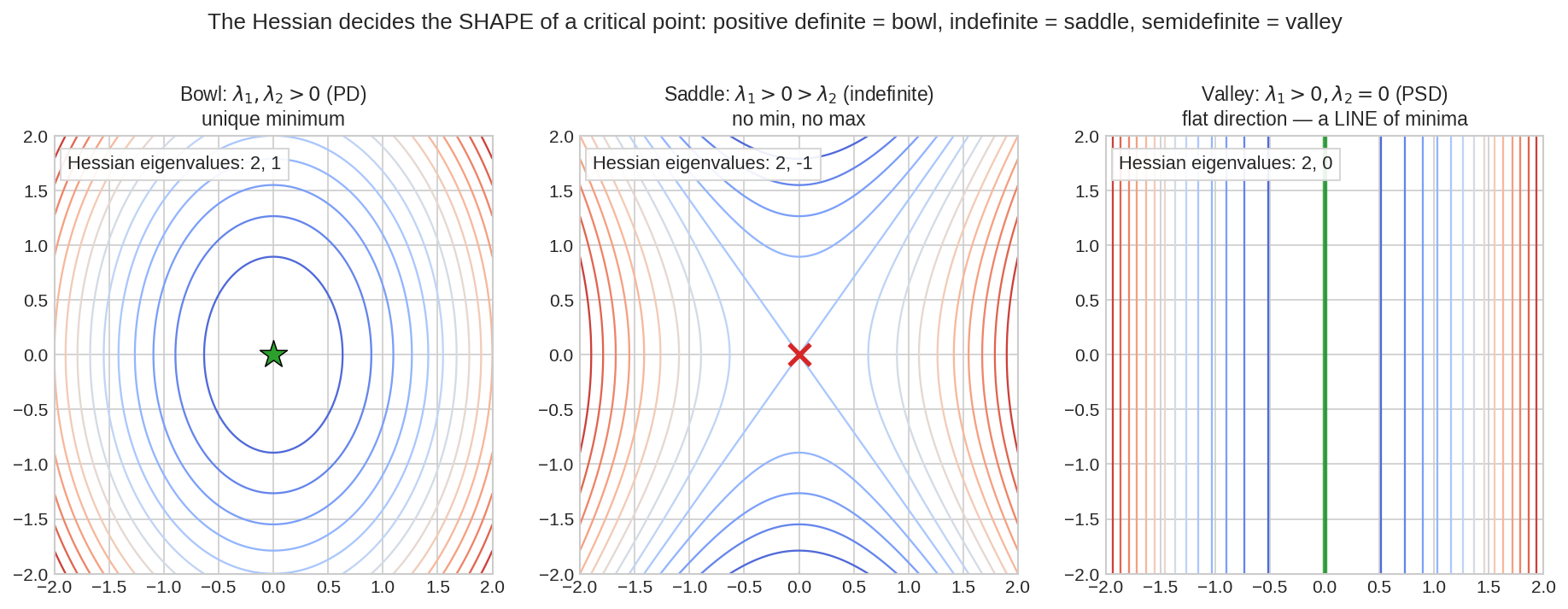
তিনটা quadratic surface-এর contour, প্রতিটার Hessian-এর eigenvalue লেখা আছে। বাঁয়ে দুই eigenvalue-ই ধনাত্মক — positive definite, বাটি (bowl), সবুজ তারায় একটাই minimum। মাঝে একটা ধনাত্মক একটা ঋণাত্মক — indefinite, saddle: এক দিকে উঠছে, আরেক দিকে নামছে, লাল ক্রসের বিন্দুটা minimum নয়। ডানে একটা eigenvalue শূন্য — positive semidefinite, উপত্যকা (valley): মেঝে বরাবর গোটা একটা লাইনের সবাই minimum। Part VI 6.5-এ PD/PSD চিনেছিলে বিমূর্তভাবে — এই তো তাদের চেহারা!
Deep learning-এর loss landscape-এ কোটি-মাত্রার এই তিন চেহারাই মিশে থাকে — gradient descent বাটিতে আরাম পায়, saddle-এ ধীর হয়, valley-তে গড়িয়ে বেড়ায়।
৩. কোথায় ইউজ হয়?¶
এক কথায়: যেখানে কিছু minimize/maximize হচ্ছে, সেখানেই matrix calculus।
- Deep learning-এর প্রতিটা training step: loss \(L(W_1, W_2, \dots)\)-এর প্রতিটা weight matrix-এর সাপেক্ষে gradient লাগে — backprop সেগুলোই হিসাব করে, আর optimizer (\(W \leftarrow W - \eta\, \partial L/\partial W\)) সেগুলো দিয়েই হাঁটে। GPT train করা মানে এই chapter-এর সূত্র শত-কোটিবার চালানো।
- Logistic regression: cross-entropy loss-এর \(\nabla_w\) বের করলে পাওয়া যায় অপূর্ব পরিষ্কার রূপ \((\sigma(w^Tx) - y)\,x\) — "ভুলের পরিমাণ × input" (Worked Example 2-এ derive করবো)।
- Gaussian MLE(এমএলই): data-র likelihood maximize করতে গিয়ে \(\nabla_\mu\), \(\nabla_\Sigma\) লাগে — সেখানে হাজির হয় আমাদের বোনাস রত্ন \(\nabla_X \log\det X = X^{-T}\); সমাধানে বেরোয় "sample mean, sample covariance" — ক্যালকুলাস প্রমাণ করে দেয় সহজ উত্তরটাই সেরা।
- PCA-as-optimization: "unit vector \(v\)-তে projected variance \(v^T S v\) maximize করো" — Lagrange multiplier দিয়ে \(\nabla(v^TSv - \lambda v^Tv) = 0\) লিখলেই বেরোয় \(Sv = \lambda v\) — eigenvalue সমীকরণ! Part VII-এর PCA আর এই chapter-এর \(\nabla(x^TAx) = 2Ax\) সূত্র এক সুতোয় বাঁধা।
- Physics-informed neural nets / scientific ML: differential equation-কে loss-এ ঢুকিয়ে net train করা হয় — সেখানে input-এর সাপেক্ষেও derivative লাগে; autograd-এর reverse ও forward mode দুটোই খেলে।
- Optimization-এর গোটা শাস্ত্র: Newton-এর method-এ Hessian, convexity-চেক-এ Hessian PSD কি না, convergence-এর গতি Hessian-এর eigenvalue-ratio (condition number — Part VIII-এ ফিরবে) — সব এই chapter-এর যন্ত্রপাতি।
৪. Properties — মৌলিক সূত্রগুলো নিজ হাতে¶
প্রতিটা সূত্র আমরা derive করবো — মুখস্থ নয়। কৌশল দুটোই বারবার: component ধরে খোলা, আর শেষে dimension-check।
সূত্র 1 — \(\nabla(a^T x) = a\)¶
Proof-এর গল্প: \(a^Tx\) হলো সবচেয়ে সরল linear function — আর "linear function-এর best linear approximation সে নিজেই।" তাই উত্তর \(a\) ছাড়া আর কী হতে পারে? তবু component ধরে সৎভাবে দেখি।
Dimension-check: \(x \in \mathbb{R}^n\), তাই gradient-ও \(n\)-vector — \(a\) ঠিক তাই ✓। (একই যুক্তিতে \(\nabla(x^Ta) = a\) — scalar-এর transpose সে নিজেই।)
সূত্র 2 — \(\nabla(x^TAx) = (A + A^T)x\)¶
Proof-এর গল্প: \(x^TAx = \sum_{i,j} A_{ij}x_ix_j\) — প্রতিটা term-এ \(x\) দুইবার আছে (একবার \(x_i\), একবার \(x_j\) হয়ে)। এক-চলকের \(\frac{d}{dx}x^2 = 2x\)-এ "২"-টা আসে এই দুইবার-উপস্থিতি থেকেই। এখানেও তাই দুটো অবদান আসবে — একটা \(A\) থেকে, একটা \(A^T\) থেকে।
\(x_k\)-এর সাপেক্ষে partial নিই। \(\sum_{i,j}A_{ij}x_ix_j\)-তে \(x_k\) আছে যেসব term-এ: \(i = k\) হলে (\(A_{kj}x_kx_j\)) আর \(j = k\) হলে (\(A_{ik}x_ix_k\)):
Dimension-check: \((A+A^T)x\) হলো \(n\times n\) গুণ \(n\)-vector \(= n\)-vector ✓। ML-এ প্রায় সব quadratic form-এর \(A\) symmetric (covariance, \(A^TA\), Hessian) — তাই কাজেকর্মে \(2Ax\)-ই দেখবে বেশি; কিন্তু \(A\) asymmetric হলে \(2Ax\) লেখা ভুল (Common ভুল §৯)।
সূত্র 3 — \(J(Ax) = A\)¶
Proof-এর গল্প: আবার সেই এক লাইনের দর্শন — linear map-এর local linear approximation সে নিজেই, সব জায়গায়।
\(F(x) = Ax\) হলে \(F_i = \sum_j A_{ij}x_j\), তাই \(\partial F_i/\partial x_j = A_{ij}\) — Jacobian-টা হুবহু \(A\) ✓। Dimension: \(A \in \mathbb{R}^{m\times n}\), Jacobian-ও \(m\times n\) ✓।
সূত্র 4 — Chain rule: \(J_{f\circ g}(x) = J_f(g(x))\; J_g(x)\)¶
Proof-এর গল্প: Part III-এ শিখেছিলে matrix multiplication = transformation-এর composition। এখন ভাবো: \(g\) স্থানীয়ভাবে matrix \(J_g\), \(f\) স্থানীয়ভাবে matrix \(J_f\) — তাহলে "আগে \(g\), পরে \(f\)" জিনিসটা স্থানীয়ভাবে কী matrix? অবশ্যই দুটোর গুণফল! Chain rule কোনো নতুন নিয়ম নয় — "composition = গুণ"-এরই ক্যালকুলাস সংস্করণ।
আধা-formal হিসাব, approximation সাজিয়ে:
Best linear approximation-এর matrix-টা পড়ে নাও: \(\boxed{J_{f\circ g} = J_f(g(x))\,J_g(x)}\) ✓
Dimension-check: \(g:\mathbb{R}^n\to\mathbb{R}^p\), \(f:\mathbb{R}^p\to\mathbb{R}^m\) হলে \(J_f\) হলো \(m\times p\), \(J_g\) হলো \(p\times n\) — গুণফল \(m\times n\), ঠিক \(f\circ g:\mathbb{R}^n\to\mathbb{R}^m\)-এর Jacobian-এর মাপ ✓। ক্রমটা লক্ষ করো: বাইরের ফাংশন বাঁয়ে — matrix গুণের মতোই ডান থেকে বাঁয়ে পড়ো।
সূত্র 5 (বোনাস রত্ন) — trace আর log-det¶
Proof-এর গল্প (\(\operatorname{tr}\)): \(\operatorname{tr}(AX) = \sum_{i,j} A_{ij}X_{ji}\) — প্রতিটা \(X_{ji}\) ঠিক একবার আসে, coefficient \(A_{ij}\)। তাহলে \(\partial/\partial X_{ji} = A_{ij}\) — অর্থাৎ gradient matrix-এর \((j,i)\) ঘরে বসে \(A_{ij}\):
Statement + intuition (\(\log\det\)): \(\boxed{\nabla_X \log\det X = X^{-T}}\)। Intuition: Part VI-এ det = volume factor; \(\log\det\)-এর পরিবর্তন মাপে "volume কত শতাংশ বাড়লো", আর সেই হিসাবের প্রতি-দিক-প্রতি হার বহন করে \(X^{-1}\) (transpose-টা আমাদের layout convention-এর উপহার)। পূর্ণ প্রমাণ Problem 6-এ guided ধাপে — Gaussian MLE আর information theory-তে এই সূত্র রোজ লাগে।
সূত্রের সাথে বাঁচার নিয়ম¶
সব সূত্রের ওপরে একটাই ছাতা: "gradient-এর shape = variable-এর shape।" \(x\in\mathbb{R}^n\) হলে \(\nabla_x\) হবে \(n\)-vector; \(W\in\mathbb{R}^{m\times n}\) হলে \(\nabla_W\) হবে \(m\times n\) matrix। কোনো derivation শেষে shape না মিললে উত্তর ভুল — এটা শতভাগ নির্ভরযোগ্য আলার্ম।
৫. Intuition — কেন সত্য? (দুই flagship derivation)¶
Flagship 1: Least squares — ক্যালকুলাস আর জ্যামিতির মিলন¶
Proof-এর গল্প: Part V 5.4-এ আমরা \(Ax \approx b\)-এর best solution পেয়েছিলাম ছবি এঁকে — \(b\)-কে column space-এ project করে, "error লম্ব হতে হবে" শর্ত থেকে normal equations। আজ সম্পূর্ণ ভিন্ন রাস্তায় হাঁটবো: loss-টা লিখে, gradient নিয়ে, শূন্য বসিয়ে। দুই ভিন্ন সভ্যতা — জ্যামিতি আর ক্যালকুলাস — একই সমীকরণে পৌঁছালে বুঝবে সত্যটা গভীর।
Loss: \(L(x) = \|Ax - b\|^2\)। পথ ১ — expand করে:
এখন §৪-এর সূত্র বসাও: প্রথম term-এ সূত্র 2 (\(A^TA\) symmetric!) দেয় \(2A^TAx\); দ্বিতীয় term \(-2(A^Tb)^Tx\)-এ সূত্র 1 দেয় \(-2A^Tb\); ধ্রুবক \(b^Tb\)-র gradient শূন্য:
পথ ২ — chain rule দিয়ে (backprop-এর মহড়া): ভেতরের map \(r(x) = Ax - b\) (Jacobian \(= A\), সূত্র 3), বাইরের \(s(r) = \|r\|^2\) (gradient \(= 2r\))। Chain rule (gradient-রূপে ভেতরের Jacobian-এর transpose বাঁয়ে বসে — Problem 7-এ কেন):
শূন্য বসাও: \(\nabla L = 0 \Rightarrow \boxed{A^TA\,x = A^Tb}\) — normal equations! Part V 5.4-এর projection-ছবি যে উত্তর দিয়েছিল, ক্যালকুলাস অক্ষরে অক্ষরে সেটাই দিলো। আর এটা যে সত্যিই minimum (maximum বা saddle নয়): Hessian \(= 2A^TA\), আর যেকোনো \(v\)-এর জন্য \(v^T(2A^TA)v = 2\|Av\|^2 \ge 0\) — positive semidefinite ⟹ \(L\) convex ⟹ critical point-ই global minimum। Part VI 6.5-এর PSD এখানে জীবন বাঁচালো।
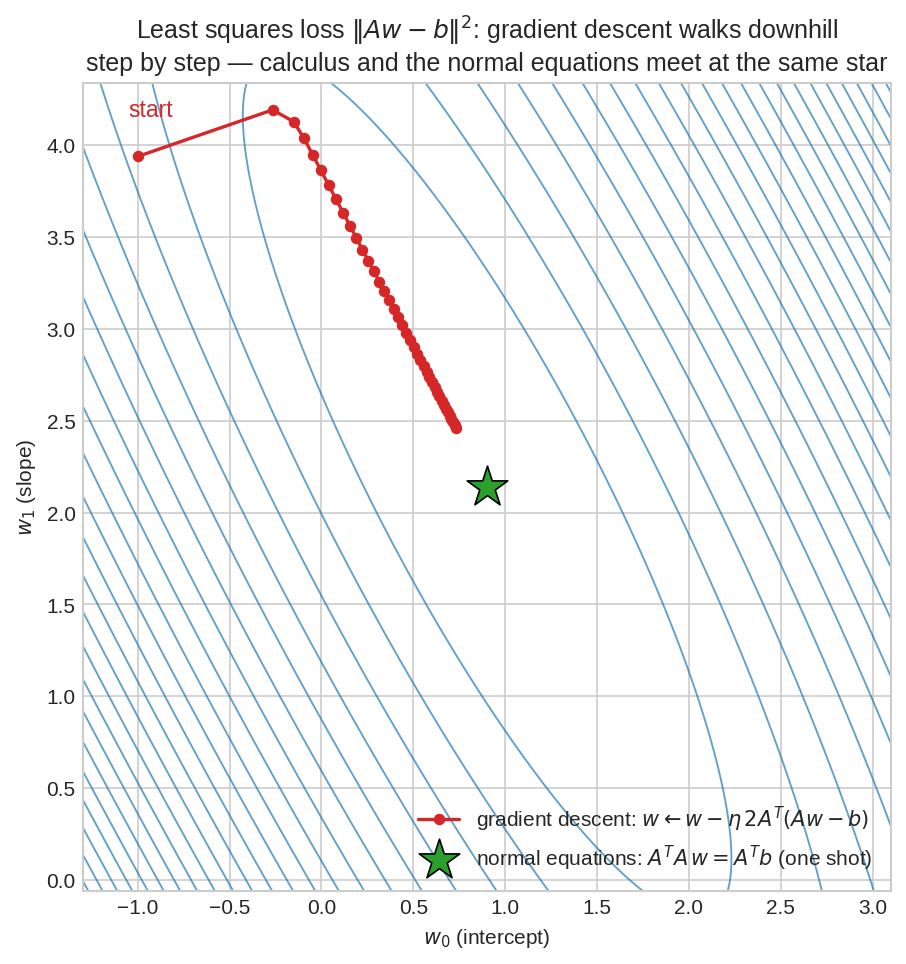
Least squares loss-এর contour-এ দুই প্রতিযোগী: লাল বিন্দু-পথ হলো gradient descent — প্রতি ধাপে \(w \leftarrow w - \eta\,2A^T(Aw-b)\), contour-এর লম্ব দিকে নেমে নেমে এগোয়; সবুজ তারা হলো normal equations-এর এক-শটের উত্তর। দুজনেই একই জায়গায় পৌঁছায় — ছোট প্রবলেমে সরাসরি solve সস্তা, কোটি-প্যারামিটারে ধাপে ধাপে নামাই একমাত্র উপায়।
Ridge regression এক লাইনে: loss-এ \(\lambda\|x\|^2\) যোগ করো (Part V-এর regularization)। \(\nabla\|x\|^2 = 2x\) (Problem 1), তাই
\(\lambda > 0\) হলে \(A^TA + \lambda I\) সবসময় invertible (Problem 3-এ PD-যুক্তি) — ridge-এর উত্তর কখনো অনির্ণেয় হয় না।
Flagship 2: Backpropagation — error নামে transpose-এর সিঁড়ি বেয়ে¶
Proof-এর গল্প: একটা 2-layer neural net আসলে ফাংশনের একটা লাইন: \(x \to W_1x \to \sigma(\cdot) \to W_2(\cdot) \to\) loss। Chain rule বলে সবগুলোর Jacobian গুণ করলেই gradient। কিন্তু কোন ক্রমে গুণ করবো? দেখবে, শেষ (loss) থেকে শুরু করে পেছন দিকে গুণ করাটাই বিস্ময়করভাবে সস্তা — আর প্রতিটা linear ধাপ পেছোতে গিয়ে হাজির হবে \(W^T\)। এই "পেছন থেকে, transpose বেয়ে" হিসাবটারই বিখ্যাত নাম backpropagation।
Setup (forward pass, নোটেশন জমাই):
এখানে \(x\in\mathbb{R}^{n_0}\), \(W_1\in\mathbb{R}^{n_1\times n_0}\), \(W_2\in\mathbb{R}^{n_2\times n_1}\), আর \(\sigma\) elementwise (যেমন ReLU)। চাই: \(\partial L/\partial W_1\) আর \(\partial L/\partial W_2\)। এখন পেছন থেকে, এক ধাপ এক লাইন — প্রতি লাইনের পাশে তার মানে:
ধাপ ১: \(\dfrac{\partial L}{\partial \hat y} = \hat y - y\) — error vector নিজেই; যাত্রা শুরু হয় "কতটা ভুল করলাম" দিয়ে। (\(\frac12\)-টা এই ২-কে খেয়ে নিলো।)
ধাপ ২: \(\dfrac{\partial L}{\partial W_2} = (\hat y - y)\,h^T\) — outer product(আউটার প্রোডাক্ট)! Dimension-check করো: \((\hat y - y)\) হলো \(n_2\times1\), \(h^T\) হলো \(1\times n_1\), গুণফল \(n_2\times n_1\) — ঠিক \(W_2\)-এর shape ✓। (কেন: \(\hat y = W_2h\)-তে \(W_2\)-এর \((i,j)\) ঘর শুধু \(\hat y_i\)-কে ছোঁয়, হার \(h_j\) — তাই \(\partial L/\partial (W_2)_{ij} = (\hat y - y)_i h_j\)।) অর্থ: "output-এর error × input-এর সাক্ষ্য" — যে input বড় ছিল, তার weight-এর দায়ও বড়।
ধাপ ৩: \(\dfrac{\partial L}{\partial h} = W_2^T(\hat y - y)\) — error এক তলা নিচে নামলো, আর নামার মই হলো \(W_2^T\)। Forward-এ \(h\) গিয়েছিল \(W_2\) চড়ে; backward-এ credit/blame ফেরে \(W_2^T\) চড়ে। Dimension: \(n_1\times n_2\) গুণ \(n_2\)-vector \(= n_1\)-vector \(= h\)-এর shape ✓
ধাপ ৪: \(\dfrac{\partial L}{\partial z_1} = W_2^T(\hat y - y) \odot \sigma'(z_1)\) — elementwise ফটক \(\sigma\) পেরোতে elementwise গুণ (\(\odot\)): যে neuron-এ \(\sigma\)-এর ঢাল শূন্য (ReLU-র বন্ধ ঘর), তার ভেতরে কোনো blame ঢোকে না। (\(\sigma\) elementwise বলে তার Jacobian diagonal — Problem 4 — diagonal matrix-এ গুণ মানেই elementwise গুণ।)
ধাপ ৫: \(\dfrac{\partial L}{\partial W_1} = \left[\dfrac{\partial L}{\partial z_1}\right] x^T\) — ধাপ ২-এর হুবহু পুনরাবৃত্তি, এক তলা নিচে: "এই তলার error × এই তলার input।" Dimension: \(n_1\times1\) গুণ \(1\times n_0 = n_1\times n_0 = W_1\)-এর shape ✓
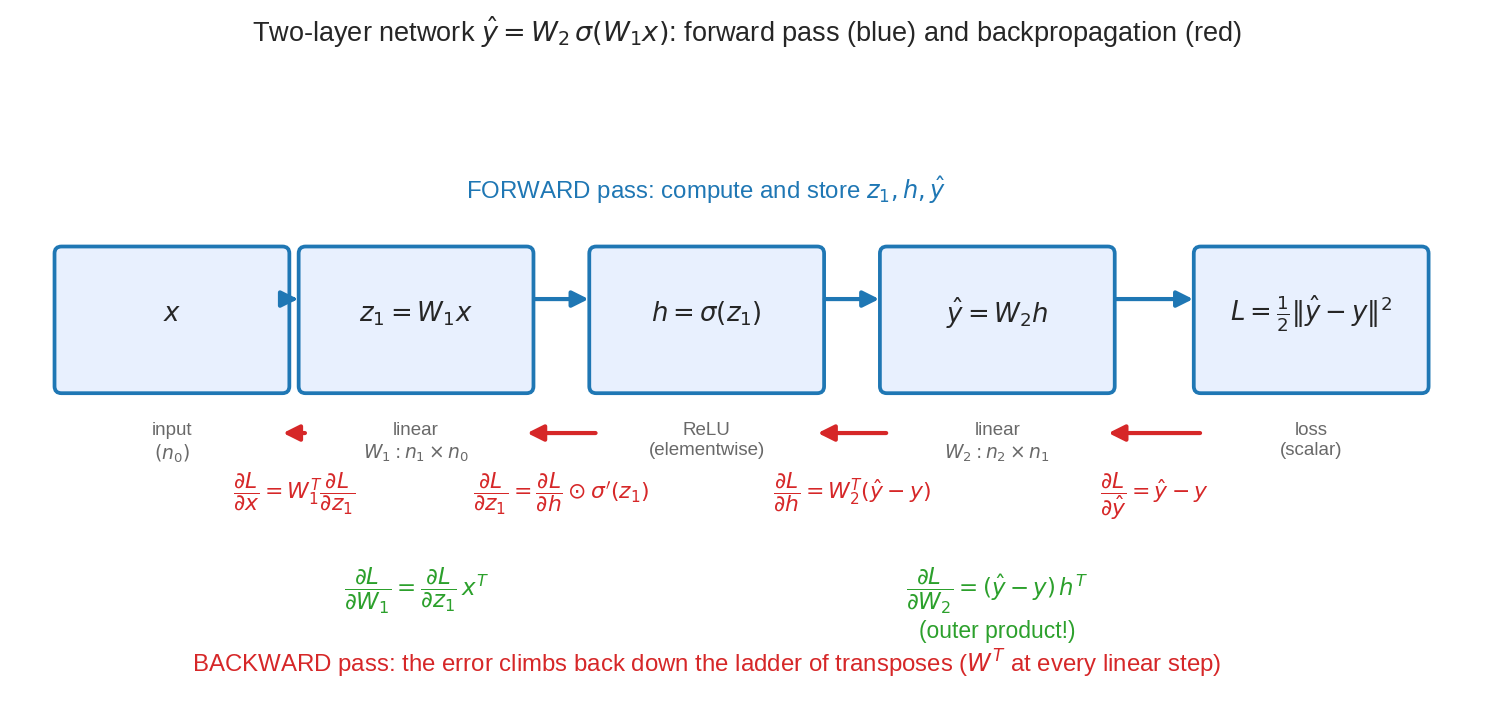
পুরো হিসাবটা এক ছবিতে: ওপরে নীল তীরে forward pass (\(z_1, h, \hat y\) হিসাব করে জমিয়ে রাখো), নিচে লাল তীরে backward pass — error পেছনে transpose-এর সিঁড়ি বেয়ে নামে, আর প্রতিটা linear তলায় নেমে সবুজ outer product-এ জমা হয় সেই তলার weight-এর gradient। এটাই backpropagation — পুরোটা এই chapter-এর চার-পাঁচটা সূত্রের সাজানো প্রয়োগ।
কেন "পেছন থেকে"? — reverse mode-এর অর্থনীতি¶
Chain rule তো বলে শুধু "Jacobian-গুলো গুণ করো": \(\nabla_x L = J_1^T J_2^T \cdots J_k^T \nabla_{\text{out}} L\)-জাতীয় একটা লম্বা গুণফল। Matrix multiplication associative (Part III) — যেকোনো ক্রমে গুণতে পারো, উত্তর এক। কিন্তু খরচ এক নয়!
- Forward mode: input-এর দিক থেকে গুণতে থাকলে মাঝপথে জমে matrix×matrix গুণফল — লক্ষ-মাত্রার স্তরে অসম্ভব দামি; input-এর প্রতিটা component-এর জন্য আলাদা pass লাগে।
- Reverse mode: loss scalar, তাই শেষ প্রান্তের gradient একটা মাত্র vector। পেছন থেকে গুণলে প্রতিটা ধাপ হয় (matrix)\(^T\)×(vector) — সস্তা! পুরো \(\nabla L\) (সব কোটি প্যারামিটারের) মেলে একটাই backward pass-এ, খরচ মোটামুটি forward pass-এরই কয়েক গুণ।
মূলমন্ত্র: Jacobian matrix-টা কখনো পুরো বানিয়ো না — শুধু vector-Jacobian product (\(J^Tv\)) হিসাব করো। \(W_2^T(\hat y - y)\) ঠিক তাই ছিল। Output scalar (loss!) হলে reverse mode জেতে; input কম output অনেক হলে forward mode জেতে। PyTorch/JAX-এর autograd(অটোগ্র্যাড) = এই reverse-mode chain rule-এর যত্নে লেখা রূপ — loss.backward() ডাকা মানে ওপরের পাঁচটা ধাপই চালানো।
নিজের backprop-কে বিশ্বাস কোরো না: numerical gradient check¶
হাতে-লেখা gradient-এ index-ভুল পৃথিবীর সবচেয়ে সাধারণ bug। যাচাইয়ের অস্ত্র central difference(সেন্ট্রাল ডিফারেন্স):
Taylor expand করলে বেজোড় term-গুলো কেটে যায় — ভুল \(O(h^2)\) (এক-পাশের difference-এর \(O(h)\)-এর চেয়ে ঢের ভালো)। কিন্তু \(h\) যত ছোট তত ভালো নয়: খুব ছোট \(h\)-এ \(f(x+he_i)\) আর \(f(x-he_i)\) প্রায় সমান — বিয়োগে floating-point-এর rounding ভুল জিতে যায় (catastrophic cancellation — Part VIII-এ পূর্ণ গল্প)।
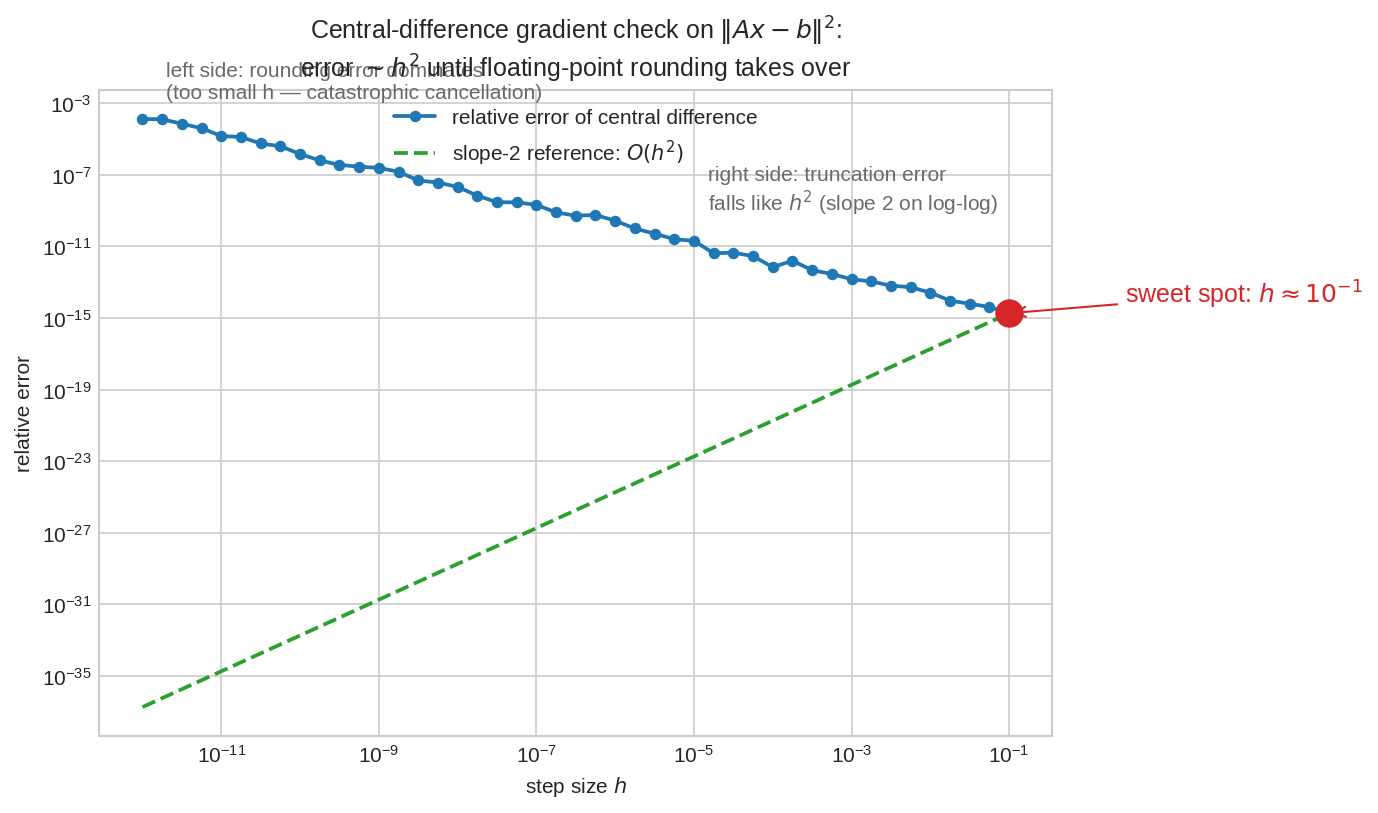
Central difference-এর relative error বনাম \(h\), log-log scale-এ। ডান দিকে error নামছে ঠিক slope-২ সরলরেখায় (\(O(h^2)\) — সবুজ reference), তারপর \(h\approx10^{-5}\)-এর সুবর্ণবিন্দু পেরিয়ে বাঁয়ে rounding error-এর রাজত্বে আবার উঠে যাচ্ছে। শিক্ষা: \(h \approx 10^{-5}\) নাও, \(10^{-12}\) নয় — আর নিজের analytic gradient-এর সাথে relative error \(10^{-7}\)-এর নিচে মিললে ঘুমোতে যাও।
৬. Code-এ কেমনে লিখে¶
import numpy as np
np.random.seed(42)
# ---------- ১) সূত্র যাচাই: numerical vs analytic ----------
def num_grad(f, x, h=1e-5):
"""Central difference gradient — সব সূত্রের বিচারক।"""
g = np.zeros_like(x)
for i in range(x.size):
e = np.zeros_like(x); e[i] = h
g[i] = (f(x + e) - f(x - e)) / (2 * h)
return g
n = 5
a, x = np.random.randn(n), np.random.randn(n)
A = np.random.randn(n, n) # ইচ্ছা করেই asymmetric!
print(np.allclose(num_grad(lambda v: a @ v, x), a)) # True: ∇(aᵀx)=a
print(np.allclose(num_grad(lambda v: v @ A @ v, x),
(A + A.T) @ x)) # True: (A+Aᵀ)x
print(np.allclose(num_grad(lambda v: v @ A @ v, x), 2 * A @ x)) # False! 2Ax ভুল
# ---------- ২) Least squares: gradient descent vs normal equations ----------
m, k = 50, 3
X = np.random.randn(m, k); b = np.random.randn(m)
w = np.zeros(k)
eta = 0.5 / np.linalg.norm(X.T @ X, 2) # নিরাপদ step size
for t in range(500):
w -= eta * 2 * X.T @ (X @ w - b) # ∇L = 2Aᵀ(Ax−b)
w_ne = np.linalg.solve(X.T @ X, X.T @ b) # normal equations
print("GD vs normal eq mismatch:", np.linalg.norm(w - w_ne)) # ~1e-8: একই তারা
# ---------- ৩) ২-layer net: manual backprop + gradient check ----------
n0, n1, n2 = 4, 6, 3
W1, W2 = np.random.randn(n1, n0) * 0.5, np.random.randn(n2, n1) * 0.5
xin, y = np.random.randn(n0), np.random.randn(n2)
def forward(W1, W2):
z1 = W1 @ xin
h = np.maximum(z1, 0) # ReLU
yhat = W2 @ h
return z1, h, yhat, 0.5 * np.sum((yhat - y) ** 2)
z1, h, yhat, L = forward(W1, W2)
# --- backward: chapter-এর ৫টা ধাপ হুবহু ---
dyhat = yhat - y # ধাপ ১
dW2 = np.outer(dyhat, h) # ধাপ ২: outer product!
dh = W2.T @ dyhat # ধাপ ৩: transpose-এর সিঁড়ি
dz1 = dh * (z1 > 0) # ধাপ ৪: ⊙ σ'(z1)
dW1 = np.outer(dz1, xin) # ধাপ ৫
# --- gradient check: প্রতিটা W-entry-তে central difference ---
def num_grad_W(which, h=1e-6):
W = (W1 if which == 1 else W2).copy()
G = np.zeros_like(W)
for idx in np.ndindex(W.shape):
Wp, Wm = W.copy(), W.copy()
Wp[idx] += h; Wm[idx] -= h
Lp = forward(Wp, W2)[3] if which == 1 else forward(W1, Wp)[3]
Lm = forward(Wm, W2)[3] if which == 1 else forward(W1, Wm)[3]
G[idx] = (Lp - Lm) / (2 * h)
return G
for name, ana, numg in [("dW1", dW1, num_grad_W(1)), ("dW2", dW2, num_grad_W(2))]:
rel = np.linalg.norm(ana - numg) / (np.linalg.norm(ana) + np.linalg.norm(numg))
print(f"{name} relative error: {rel:.2e}") # দুটোই < 1e-8 ✓
Output ব্যাখ্যা:
- প্রথম ব্লকে তিনটা যাচাই: \(\nabla(a^Tx)=a\) ✓, \(\nabla(x^TAx)=(A+A^T)x\) ✓, আর ইচ্ছা করে ভুল সূত্র \(2Ax\) পরীক্ষা করলে
False— numerical check মিথ্যা ধরে ফেলে, কারণ \(A\)-টা asymmetric বানানো। - দ্বিতীয় ব্লকে ৫০০ ধাপের gradient descent আর এক-লাইনের normal equations-এর ফারাক \(\sim10^{-8}\) — fig04-এর দুই প্রতিযোগী কোডেও একই তারায় মিললো।
- তৃতীয় ব্লক হলো chapter-এর মুকুট: backward pass-এর পাঁচ লাইন ঠিক §৫-এর পাঁচ ধাপ। শেষে relative error \(<10^{-8}\) — আমাদের হাতে-derive-করা backprop নির্ভুল। নিজের প্রজেক্টে সবসময় এই চেক লেখো — পেশাদারদের অভ্যাস।
৭. Worked Examples¶
Example 1 — সাধারণ quadratic-এর সম্পূর্ণ ময়নাতদন্ত¶
\(f(x) = x^TAx + b^Tx + c\), যেখানে \(A = \begin{bmatrix}2&0\\0&1\end{bmatrix}\) (symmetric, PD), \(b = (-4, -2)\), \(c = 5\)। Gradient, Hessian, আর minimum বের করি।
ধাপ ১ — Gradient (সূত্র 1 + 2): \(A\) symmetric, তাই
ধাপ ২ — Hessian: gradient-এর Jacobian: \(\nabla f\) linear in \(x\), তার matrix \(2A = \begin{bmatrix}4&0\\0&2\end{bmatrix}\) — symmetric ✓, eigenvalue \(4, 2 > 0\) ⟹ positive definite ⟹ bowl (fig03-এর বাঁ ছবি)।
ধাপ ৩ — Minimum: \(\nabla f = 0 \Rightarrow 2Ax = -b \Rightarrow x^* = -\frac12A^{-1}b = (1, 1)\)। PD Hessian বলে এটা unique global minimum। মান: \(f(1,1) = (2+1) + (-4-2) + 5 = 2\)।
চেক: \(x^*\)-এর আশেপাশে যেকোনো দিকে সরলে \(f\) বাড়ে — যেমন \(f(1.1, 1) = 2.42 - 6.4 + 5 + 1.0\cdot1 = 2.02 > 2\) ✓
Example 2 — Logistic loss-এর gradient: ML-এর রোজকার রুটি¶
এক data point \((x, y)\), \(y \in \{0,1\}\); model: \(p = \sigma(w^Tx)\) যেখানে \(\sigma(t) = \frac{1}{1+e^{-t}}\); loss: \(\ell(w) = -\big[y\log p + (1-y)\log(1-p)\big]\)। চাই \(\nabla_w \ell\)।
ধাপ ১ — Chain-টা চিনে নিই: \(w \xrightarrow{\;t = w^Tx\;} t \xrightarrow{\;\sigma\;} p \xrightarrow{\;\ell\;} \text{loss}\) — তিনটা সরল ধাপ।
ধাপ ২ — প্রতিটা ধাপের derivative: \(\frac{d\ell}{dp} = -\frac{y}{p} + \frac{1-y}{1-p}\); sigmoid-এর বিখ্যাত পরিচয় \(\sigma' = \sigma(1-\sigma)\), তাই \(\frac{dp}{dt} = p(1-p)\); আর \(\nabla_w t = x\) (সূত্র 1)।
ধাপ ৩ — গুণ (chain rule):
কী অসাধারণ সরল রূপ! "ভুলের পরিমাণ (\(p-y\)) × input (\(x\))" — backprop-এর ধাপ ২/৫-এর outer-product ছন্দটাই, এক নিউরনের সংস্করণে। এই একটা সূত্রেই চলে পৃথিবীর সব logistic regression।
Example 3 — ছোট সংখ্যায় এক পূর্ণ forward + backward¶
2D input, 2 hidden (ReLU), 1 output। \(W_1 = \begin{bmatrix}1&0\\-1&2\end{bmatrix}\), \(W_2 = \begin{bmatrix}1&1\end{bmatrix}\), \(x = (1, 2)\), target \(y = 1\), loss \(\frac12(\hat y - y)^2\)।
Forward:
Loss \(= \frac12(4-1)^2 = 4.5\)।
Backward, পাঁচ ধাপ:
- \(\dfrac{\partial L}{\partial \hat y} = \hat y - y = 3\)
- \(\dfrac{\partial L}{\partial W_2} = 3\cdot h^T = \begin{bmatrix}3 & 9\end{bmatrix}\) — shape \(1\times2 = W_2\)-এর shape ✓
- \(\dfrac{\partial L}{\partial h} = W_2^T\cdot3 = \begin{bmatrix}3\\3\end{bmatrix}\)
- \(z_1 = (1,3)\) — দুটোই \(>0\), তাই ReLU-র ঢাল \((1,1)\): \(\dfrac{\partial L}{\partial z_1} = \begin{bmatrix}3\\3\end{bmatrix}\odot\begin{bmatrix}1\\1\end{bmatrix} = \begin{bmatrix}3\\3\end{bmatrix}\)
- \(\dfrac{\partial L}{\partial W_1} = \begin{bmatrix}3\\3\end{bmatrix}x^T = \begin{bmatrix}3&6\\3&6\end{bmatrix}\) — shape \(2\times2\) ✓
চেক (এক ঘর numerical): \((W_1)_{11}\)-কে \(1 \to 1.001\) করলে \(z_1 = (1.001, 3)\), \(\hat y = 4.001\), loss \(= \frac12(3.001)^2 = 4.503002\) — বৃদ্ধির হার \(\approx \frac{4.503-4.5}{0.001} = 3.0\) ✓ আমাদের \(\partial L/\partial(W_1)_{11} = 3\)-এর সাথে হুবহু মিল।
৮. Problems ও Solutions¶
Problem 1. Component ধরে প্রমাণ করো: (a) \(\nabla\|x\|^2 = 2x\); (b) \(\nabla(x^TAx) = (A+A^T)x\) — সূত্র 2-এর প্রতিটা ধাপ নিজে লিখে। তারপর (a)-কে (b)-র বিশেষ কেস হিসেবে চেনাও।
Solution
(a) \(\|x\|^2 = \sum_i x_i^2\), তাই \(\frac{\partial}{\partial x_k}\sum_i x_i^2 = 2x_k\) (শুধু \(i=k\) term-টাই \(x_k\) ছোঁয়) — সব \(k\) জড়ো করলে \(\nabla\|x\|^2 = 2x\) ∎
(b) \(x^TAx = \sum_{i,j}A_{ij}x_ix_j\)। \(\frac{\partial}{\partial x_k}\) নিলে product rule-মতে দুই দল term বাঁচে: \(i = k\): \(\sum_j A_{kj}x_j = (Ax)_k\); এবং \(j = k\): \(\sum_i A_{ik}x_i = (A^Tx)_k\)। যোগফল \((Ax + A^Tx)_k\) — অর্থাৎ \(\nabla(x^TAx) = (A + A^T)x\) ∎
সংযোগ: \(\|x\|^2 = x^TIx\), আর \(I + I^T = 2I\), তাই (b) থেকে \(\nabla = 2Ix = 2x\) — (a) মিলে গেলো ✓
Problem 2. \(f(x) = \|Ax - b\|^2\)-এর gradient chain rule দিয়ে derive করো (ভেতরের map, বাইরের map আলাদা করে লিখে), তারপর Hessian বের করে দেখাও \(f\) convex।
Solution
ভেতরে \(r(x) = Ax - b\), Jacobian \(J_r = A\) (সূত্র 3)। বাইরে \(s(r) = \|r\|^2\), \(\nabla s = 2r\) (Problem 1a)। Gradient-রূপে chain rule: \(\nabla f = J_r^T\,\nabla s\big|_{r=Ax-b} = A^T\cdot2(Ax-b) = 2A^T(Ax-b)\) ∎
Hessian: \(\nabla f = 2A^TAx - 2A^Tb\) হলো \(x\)-এর linear function — তার Jacobian \(H = 2A^TA\)। যেকোনো \(v\)-তে \(v^THv = 2\|Av\|^2 \ge 0\) ⟹ PSD ⟹ convex ∎ (Part VI 6.5: \(A^TA\)-জাতীয় matrix সবসময় PSD — এখানেই তার প্রতিদান।)
Problem 3. Ridge loss \(L(x) = \|Ax-b\|^2 + \lambda\|x\|^2\) (\(\lambda > 0\))। (a) \(\nabla L\) বের করে normal equation-রূপ \((A^TA + \lambda I)x = A^Tb\) derive করো। (b) প্রমাণ করো \(A^TA + \lambda I\) সবসময় invertible — এমনকি \(A\)-এর column dependent হলেও।
Solution
(a) Problem 1a ও 2 জুড়ে: \(\nabla L = 2A^T(Ax-b) + 2\lambda x\)। শূন্য বসাও:
(b) যেকোনো \(v \ne 0\)-এর জন্য:
অর্থাৎ matrix-টা positive definite — আর PD matrix-এর সব eigenvalue \(>0\), determinant \(>0\), singular হওয়ার উপায় নেই (Part VI 6.5) ∎ অর্থ: সাধারণ least squares-এ \(A^TA\) singular হতে পারে (collinear feature); \(\lambda I\) যোগ করা মানে প্রতিটা eigenvalue-কে \(\lambda\) ধাক্কা দিয়ে শূন্য থেকে সরানো — regularization-এর বীজগণিতীয় চেহারা।
Problem 4. \(\sigma\) একটা elementwise function: \(F(x) = (\sigma(x_1), \dots, \sigma(x_n))\)। প্রমাণ করো \(F\)-এর Jacobian diagonal matrix \(\operatorname{diag}(\sigma'(x_1), \dots, \sigma'(x_n))\), এবং ব্যাখ্যা করো backprop-এর ধাপ ৪-এ diagonal-এ গুণ কেন elementwise গুণ (\(\odot\)) হয়ে যায়।
Solution
\(F_i = \sigma(x_i)\) শুধু \(x_i\)-র ওপর নির্ভর করে, তাই
— অর্থাৎ \(J = \operatorname{diag}(\sigma'(x_1),\dots,\sigma'(x_n))\) ∎
Backprop-এ লাগে \(J^Tv = \operatorname{diag}(\sigma'(x))\,v\) — diagonal matrix-এ গুণ মানে \(i\)-তম ঘরে \(\sigma'(x_i)v_i\): এটাই elementwise গুণ \(\sigma'(x)\odot v\)। তাই কোডে কখনো \(n\times n\) diagonal matrix বানাতে হয় না — এক লাইনের dh * sigma_prime(z) যথেষ্ট (Jacobian না-বানানোর মূলমন্ত্রের ছোট্ট উদাহরণ)।
Problem 5. প্রমাণ করো \(\nabla_X \operatorname{tr}(X^TX) = 2X\) — component ধরে। তারপর ব্যাখ্যা করো এটা আসলে Problem 1a-রই matrix-সংস্করণ কেন।
Solution
\(\operatorname{tr}(X^TX) = \sum_{i,j} X_{ij}^2\) — সব entry-র বর্গের যোগফল (Frobenius norm-এর বর্গ!)।
Dimension-check: gradient-এর shape \(= X\)-এর shape ✓
সংযোগ: \(\operatorname{tr}(X^TX) = \|X\|_F^2\) হলো "matrix-কে লম্বা vector ভাবলে তার \(\|\cdot\|^2\)" — তাই উত্তরও Problem 1a-র \(2x\)-এর মতোই \(2X\)। Matrix calculus-এর অনেক সূত্রই আসলে vector সূত্রের ছদ্মবেশ।
Problem 6 (guided). প্রমাণ করবো \(\nabla_X \log\det X = X^{-T}\) (\(X\) invertible, \(\det X > 0\))। ধাপগুলো পূরণ করো: (a) দেখাও cofactor expansion (Part VI 6.1) থেকে \(\frac{\partial \det X}{\partial X_{ij}} = C_{ij}\) (cofactor)। (b) adjugate সূত্র \(X^{-1} = \frac{1}{\det X}\operatorname{adj}(X)\) আর \(\operatorname{adj}(X) = C^T\) ব্যবহার করে শেষ করো।
Solution
(a) \(i\)-তম row ধরে cofactor expansion: \(\det X = \sum_j X_{ij}C_{ij}\) — এখানে cofactor \(C_{ij}\)-রা \(i\)-তম row-এর কোনো entry-র ওপর নির্ভর করে না (তারা বাকি matrix থেকে আসে)। তাই \(\det X\) হলো \(X_{ij}\)-এর linear function, coefficient \(C_{ij}\):
(b) Chain rule (এক-চলকের): \(\frac{\partial \log\det X}{\partial X_{ij}} = \frac{1}{\det X}C_{ij}\)। Matrix আকারে জড়ো করলে ডান পাশে \(\frac{1}{\det X}C = \frac{1}{\det X}\operatorname{adj}(X)^T = (X^{-1})^T\):
কোথায় লাগে: Gaussian log-likelihood-এ \(-\frac12\log\det\Sigma\) term-এর \(\nabla_\Sigma\) — MLE-তে sample covariance বেরিয়ে আসার পেছনের ইঞ্জিন।
Problem 7. \(L\)-layer network: \(h_0 = x\), \(z_\ell = W_\ell h_{\ell-1}\), \(h_\ell = \sigma(z_\ell)\) (\(\ell = 1,\dots,L\); শেষ layer-এ \(\sigma\) = identity ধরো), loss \(L = \frac12\|h_L - y\|^2\)। \(\delta_\ell := \partial L/\partial z_\ell\) নোটেশনে general backprop recursion-টা লেখো, আর প্রতিটা \(W_\ell\)-এর gradient।
Solution
শুরু (শেষ layer): \(\delta_L = h_L - y\) (identity output-এ \(\sigma' = 1\))।
Recursion (পেছন দিকে, \(\ell = L-1, \dots, 1\)):
— error এক তলা নামে \(W^T\) বেয়ে, তারপর সেই তলার activation-ফটকে \(\odot\) ছাঁকনি।
Weight gradient (প্রতি তলায়):
— "এই তলার error × এই তলার input"-এর outer product। Dimension-check: \(\delta_\ell \in \mathbb{R}^{n_\ell}\), \(h_{\ell-1} \in \mathbb{R}^{n_{\ell-1}}\), গুণফল \(n_\ell \times n_{\ell-1} = W_\ell\)-এর shape ✓
এই তিন লাইনই যেকোনো গভীরতার fully-connected net-এর সম্পূর্ণ backprop — §৫-এর 2-layer হিসাবটা এরই \(L=2\) কেস। আর লক্ষ করো প্রতিটা ধাপ vector-Jacobian product: কোথাও কোনো পূর্ণ Jacobian তৈরি হয়নি।
Problem 8. তোমার বন্ধু gradient check করছে \(h = 10^{-12}\) দিয়ে, আর অভিযোগ করছে "আমার backprop ভুল — relative error \(10^{-2}\)!" fig06-এর আলোকে ব্যাখ্যা করো আসল সমস্যা কী, আর কী করা উচিত।
Solution
সমস্যা backprop-এ না-ও থাকতে পারে — \(h = 10^{-12}\)-তে central difference নিজেই অচল! \(f(x+he_i)\) আর \(f(x-he_i)\) তখন এত কাছাকাছি যে float64-এর ~১৬ অঙ্কের নির্ভুলতায় বিয়োগফলের প্রায় সব significant digit মুছে যায় (catastrophic cancellation) — fig06-এর বাঁ দিকের ঊর্ধ্বমুখী অংশ।
করণীয়: \(h \approx 10^{-5}\) থেকে \(10^{-6}\) নাও (সেখানে truncation \(O(h^2)\) আর rounding-এর ভারসাম্য) — তারপরও error \(>10^{-5}\) থাকলে তবেই backprop-এ bug খোঁজো। আর তুলনা সবসময় relative error-এ করো: \(\frac{\|g_{\text{ana}} - g_{\text{num}}\|}{\|g_{\text{ana}}\| + \|g_{\text{num}}\|}\) — gradient-এর মাপ যেন বিচারকে না ঠকায়।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "Gradient-এর shape নিয়ে পরে ভাবা যাবে" | Gradient-এর shape সবসময় variable-এর shape — \(x\) vector হলে \(\nabla_x\) vector, \(W\) matrix হলে \(\nabla_W\) matrix। প্রতি লাইনে dimension-check করো; না মিললে ওখানেই bug। |
| "\(\nabla(x^TAx) = 2Ax\) — সবসময়" | শুধু \(A\) symmetric হলে। সাধারণ নিয়ম \((A + A^T)x\) — asymmetric \(A\)-তে \(2Ax\) লিখলে numerical check-ই ধরে ফেলবে (§৬-এর কোডে দেখেছো)। |
| "Backprop বুঝতে পুরো Jacobian matrix লিখে গুণ করি" | ধারণা বুঝতে ঠিক আছে, কোডে সর্বনাশ: hidden layer \(10^4\) হলে এক layer-এর Jacobian-ই \(10^4\times10^4 = 10^8\) সংখ্যা — memory blow-up। সবসময় vector-Jacobian product: \(W^Tv\), \(\sigma'\odot v\) — matrix-free। |
| "Gradient check-এ \(h\) যত ছোট, তত নিখুঁত" | না — \(h\) খুব ছোট হলে rounding error জিতে যায় (fig06-এর বাঁ দিক)। মিষ্টি জায়গা \(h\approx10^{-5}\); error মাপো relative scale-এ। |
| "Forward mode আর reverse mode তো একই chain rule — যেকোনোটা নিলেই হয়" | উত্তর এক, খরচ আকাশপাতাল। Loss scalar ⟹ reverse mode এক pass-এ সব gradient (তাই training-এ backprop); input কম, output ঢের বেশি হলে forward mode জেতে। ভুল mode = হাজার গুণ ধীর। |
| "অন্য বইয়ের সূত্রের সাথে transpose মিলছে না — নিশ্চয় কেউ ভুল" | কেউ ভুল না — layout convention আলাদা (numerator vs denominator)। আমাদের নিয়ম: gradient column, shape = variable-এর shape। অচেনা সূত্র দেখলে dimension মিলিয়ে নিজের convention-এ অনুবাদ করো। |
১০. এক নজরে¶
| ধারণা | বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Derivative-এর আসল সংজ্ঞা | \(f(x+h)\approx f(x) + \nabla f^Th\) — best linear approximation | কুয়াশার পাহাড়ে পায়ের তলার ঢাল |
| Gradient | সবচেয়ে খাড়া ওঠার দিক, contour-এর লম্ব; shape \(=\) variable-এর shape | fig01-এর লাল তীর |
| Jacobian | nonlinear map-এর "প্রতি বিন্দুতে নিজস্ব local matrix" (\(m\times n\)) | ছোট জানালায় সব map-ই linear (fig02) |
| Hessian | gradient-এর Jacobian; symmetric; PD=bowl, indef=saddle, PSD=valley | fig03-এর তিন চেহারা (Part VI 6.5) |
| Chain rule | \(J_{f\circ g} = J_f\,J_g\) — composition = গুণ (Part III) | Jacobian-দের মালা, ডান→বাঁ |
| Least squares | \(\nabla\|Ax-b\|^2 = 2A^T(Ax-b) = 0 \Rightarrow A^TAx = A^Tb\) | ক্যালকুলাস আর projection (Part V 5.4) একই তারায় |
| Ridge | \((A^TA+\lambda I)x = A^Tb\); \(\lambda>0\) ⟹ সবসময় PD, invertible | eigenvalue-দের \(\lambda\)-ধাক্কা |
| Backprop | \(\delta_\ell = (W_{\ell+1}^T\delta_{\ell+1})\odot\sigma'(z_\ell)\); \(\partial L/\partial W_\ell = \delta_\ell h_{\ell-1}^T\) | error নামে transpose-এর সিঁড়ি বেয়ে; gradient = error×input |
| Reverse mode | scalar loss ⟹ এক backward pass-এ সব gradient; Jacobian কখনো বানাই না | vector-Jacobian product-ই সব |
| Gradient check | central difference, error \(O(h^2)\), \(h\approx10^{-5}\) | fig06-এর V-আকৃতি |
সূত্রের cheat-sheet:
| \(f\) | \(\nabla f\) | শর্ত/নোট |
|---|---|---|
| \(a^Tx\) | \(a\) | — |
| \(\|x\|^2\) | \(2x\) | — |
| \(x^TAx\) | \((A+A^T)x\) | symmetric হলে \(2Ax\) |
| \(\|Ax-b\|^2\) | \(2A^T(Ax-b)\) | Hessian \(2A^TA \succeq 0\) |
| \(\|Ax-b\|^2 + \lambda\|x\|^2\) | \(2A^T(Ax-b) + 2\lambda x\) | \(\lambda>0\): সবসময় PD |
| \(Ax\) (Jacobian) | \(A\) | linear-এর J সে নিজেই |
| \(\operatorname{tr}(AX)\) | \(A^T\) | — |
| \(\operatorname{tr}(X^TX)\) | \(2X\) | \(=\|X\|_F^2\) |
| \(\log\det X\) | \(X^{-T}\) | \(X\) invertible |
পরের chapter-এর সেতু: আজ শিখলে gradient-রা কীভাবে loss-এর পাহাড় বেয়ে নামে। কিন্তু কোটি-মাত্রার সেই পাহাড়টা দেখতে কেমন? Saddle বেশি না minimum বেশি? Hessian-এর eigenvalue-রা কীভাবে ছড়িয়ে থাকে? আশ্চর্যের কথা — এত জটিল প্রশ্নের উত্তর দিতে পারে এলোমেলো matrix-এর গণিত: বিশাল random matrix-এর eigenvalue-রা মেনে চলে অদ্ভুত সুন্দর সব নিয়ম (semicircle!), আর deep net-এর initialization থেকে loss landscape — সবখানে তাদের ছায়া। Chapter 9.5: Random Matrix Theory — gradient-রা যেখানে নামে, সেই জমিনের জরিপ।
📓 Notebook Project¶
notebooks/part-09/ch04-project.ipynb — ২-layer neural net-এর সব gradient হাতে-derive করা সূত্রে implement, central-difference numerical gradient check, তারপর মিনি gradient descent দিয়ে train।