Chapter 5.5 — Least Squares Data Fitting (লিস্ট স্কোয়ার্স ডেটা ফিটিং — ডেটায় মডেল বসানো)¶
আগের chapter-এ আমরা যন্ত্রটা বানিয়েছি: \(\min_\theta \|A\theta - y\|^2\), আর তার উত্তর normal equations। এই chapter-এ যন্ত্রটাকে ছেড়ে দেবো সত্যিকারের ডেটার মাঠে — আর দেখবো Machine Learning-এর সবচেয়ে পুরনো, সবচেয়ে বেশি ব্যবহৃত algorithm-টা আসলে আমাদের চেনা least squares-ই, শুধু \(A\) matrix-টা বানানো হয় ডেটা থেকে। সাথে শিখবো ML-এর সবচেয়ে গুরুত্বপূর্ণ সতর্কবাণী: ডেটা মুখস্থ করা আর ডেটা বোঝা এক জিনিস নয় (overfitting), আর তার সততা-পরীক্ষা train/validation split। (VMLS Chapter 13-এর পথ ধরে, আমাদের নিজের গল্পে।)
🎯 এই chapter-এ যা শিখবে¶
- Data Fitting(ডেটা ফিটিং): feature \(x\) আর outcome \(y\)-এর সম্পর্ককে মডেল \(\hat{f}(x) = \theta_1 f_1(x) + \cdots + \theta_p f_p(x)\) দিয়ে ধরা — আর সেটা যে হুবহু least squares problem
- Straight-line fit থেকে Polynomial Fit(পলিনোমিয়াল ফিট) — degree বাড়ালে কী পাই, কী হারাই
- Overfitting(ওভার-ফিটিং): train error সবসময় কমে, কিন্তু আসল পরীক্ষায় (unseen data) মডেল ফেল করে কেন
- Train/Validation Split(ট্রেন/ভ্যালিডেশন বিভাজন): মডেলের সততা যাচাইয়ের সবচেয়ে সরল, সবচেয়ে কার্যকর কৌশল
- Feature Engineering(ফিচার ইঞ্জিনিয়ারিং): \(A\)-এর column নিজে বানানো — standardization, hinge/piecewise-linear, log transform, one-hot encoding
🖼️ এক ছবিতে মূল idea¶
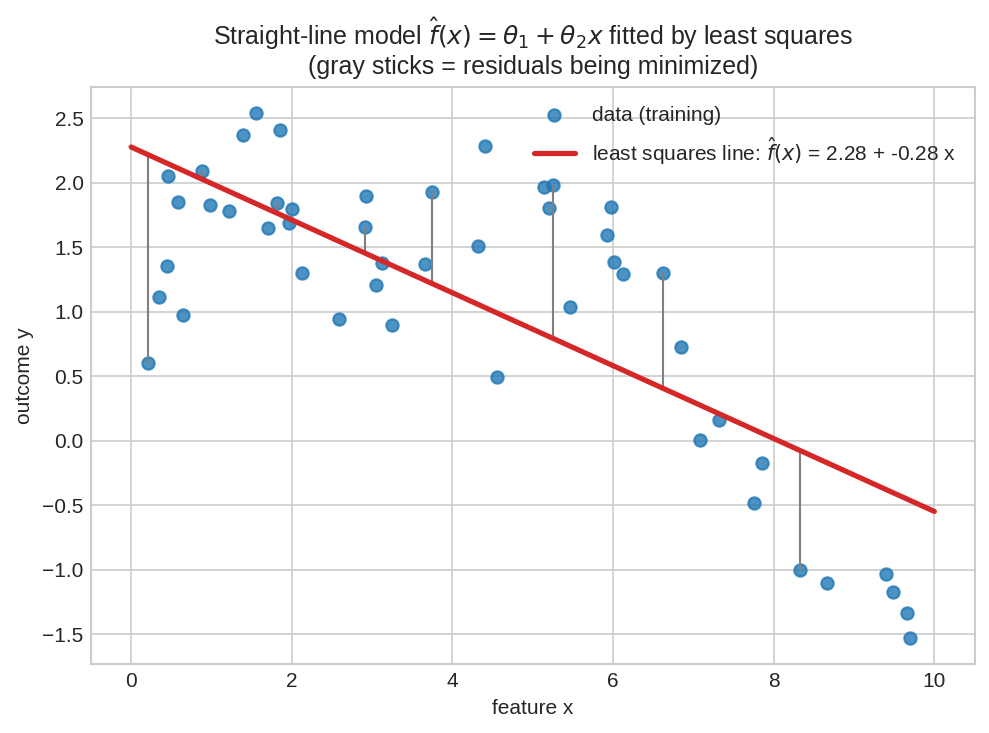
এটাই data fitting-এর পুরো খেলা এক ছবিতে: নীল বিন্দুগুলো ডেটা \((x^{(i)}, y^{(i)})\), লাল লাইনটা মডেল \(\hat{f}(x) = \theta_1 + \theta_2 x\)। ধূসর কাঠিগুলো প্রতিটা বিন্দুর prediction error — least squares ঠিক সেই \(\theta\) বেছে নেয় যাতে এই কাঠিগুলোর বর্গের যোগফল সবচেয়ে ছোট হয়। আগের chapter-এর \(\min\|A\theta - y\|^2\), শুধু \(A\) এখন ডেটা থেকে বানানো।
১. কি? (What)¶
দৈনন্দিন analogy: দর্জির ফিতা¶
দর্জি তোমার জামা বানায় কীভাবে? সে তোমার পুরো শরীর কপি করে না — কয়েকটা মাপ নেয় (বুক, কাঁধ, হাতা), তারপর সেই মাপে একটা ছাঁচ (মডেল) বানায়। ছাঁচটা নিখুঁত নয় — কোথাও একটু ঢিলে, কোথাও একটু টাইট — কিন্তু মোটের ওপর সবচেয়ে ভালো fit। Data fitting ঠিক তাই: হাজারটা ডেটা বিন্দু কপি না করে অল্প কয়েকটা সংখ্যা (\(\theta_1, \dots, \theta_p\)) দিয়ে তাদের ধরনটা ধরা। আর "মোটের ওপর সবচেয়ে ভালো" মাপা হয় — অনুমান করতেই পারছো — ভুলের বর্গের যোগফলে।
সংজ্ঞা: উপকরণগুলো চিনে নিই¶
ধরো আমাদের বিশ্বাস, একটা সংখ্যা (বা vector) \(x\) আর একটা সংখ্যা \(y\) কোনো অজানা সম্পর্কে বাঁধা: \(y \approx f(x)\)।
- \(x\): Feature(ফিচার — বৈশিষ্ট্য) বা independent variable — যা আমরা জানি (পড়ার ঘণ্টা, বাড়ির আয়তন, আজকের তাপমাত্রা)
- \(y\): Outcome(আউটকাম — ফলাফল) বা response variable — যা অনুমান করতে চাই (পরীক্ষার নম্বর, বাড়ির দাম, কালকের তাপমাত্রা)
- Data(ডেটা): \(N\)টা মাপা জোড়া \((x^{(1)}, y^{(1)}), \dots, (x^{(N)}, y^{(N)})\) — superscript \((i)\) মানে \(i\)-তম নমুনা
\(f\) কে আমরা চিনি না — তাই বানাই তার একটা অনুমান, Model(মডেল) \(\hat{f}\), আর তার prediction \(\hat{y} = \hat{f}(x)\)। এই বইয়ের (এবং VMLS-এর) কেন্দ্রীয় মডেল-পরিবার:
- \(f_1, \dots, f_p\): Basis Function(বেসিস ফাংশন) — আমরা আগে থেকে বেছে নিই (যেমন \(1, x, x^2\))
- \(\theta_1, \dots, \theta_p\): Parameter(প্যারামিটার) — ডেটা থেকে শেখা হয়
মডেলটাকে বলে Linear in the Parameters(প্যারামিটারে লিনিয়ার) — খেয়াল করো, \(x\)-এ nonlinear হতে কোনো বাধা নেই (\(x^2\), \(\sin x\), \(\max(x-3, 0)\) — সব চলবে!), শুধু \(\theta\)-গুলো ঢুকেছে সরলভাবে। এটাই এই chapter-এর সবচেয়ে বড় চাবি।
Data fitting = least squares (এক লাইনের রূপান্তর)¶
\(i\)-তম নমুনায় মডেলের prediction: \(\hat{y}^{(i)} = \theta_1 f_1(x^{(i)}) + \cdots + \theta_p f_p(x^{(i)})\) — এটা \(\theta\)-এর linear combination! তাহলে \(N \times p\) matrix বানাও:
— একে বলে Design Matrix(ডিজাইন ম্যাট্রিক্স); এর \(j\)-তম column হলো "\(j\)-তম basis function, সব ডেটায় মূল্যায়িত"। তখন সব prediction একসাথে \(\hat{y}^d = A\theta\), আর Prediction Error(প্রেডিকশন এরর) বা residual-দের vector \(r^d = y^d - \hat{y}^d\)। ভুলের বর্গের যোগফল minimize করা মানে:
— হুবহু আগের chapter! (\(A\)-এর column independent ধরে।) মডেলের মান মাপার মিটার: RMS Error(আরএমএস এরর) \(= \sqrt{\frac{1}{N}\sum_i (r^{(i)})^2}\) — "গড়ে কত ভুল করি"। শুধু চিহ্নের পোশাক বদলেছে: আগের \(x\) (অজানা) এখন \(\theta\), আগের \(b\) (লক্ষ্য) এখন \(y^d\) — কারণ data fitting-এর জগতে \(x\) নামটা feature-এর দখলে।
২. দেখতে কেমন?¶
দৃশ্য ১: একই ডেটা, চার রকম polynomial — সরল থেকে পাগলাটে¶
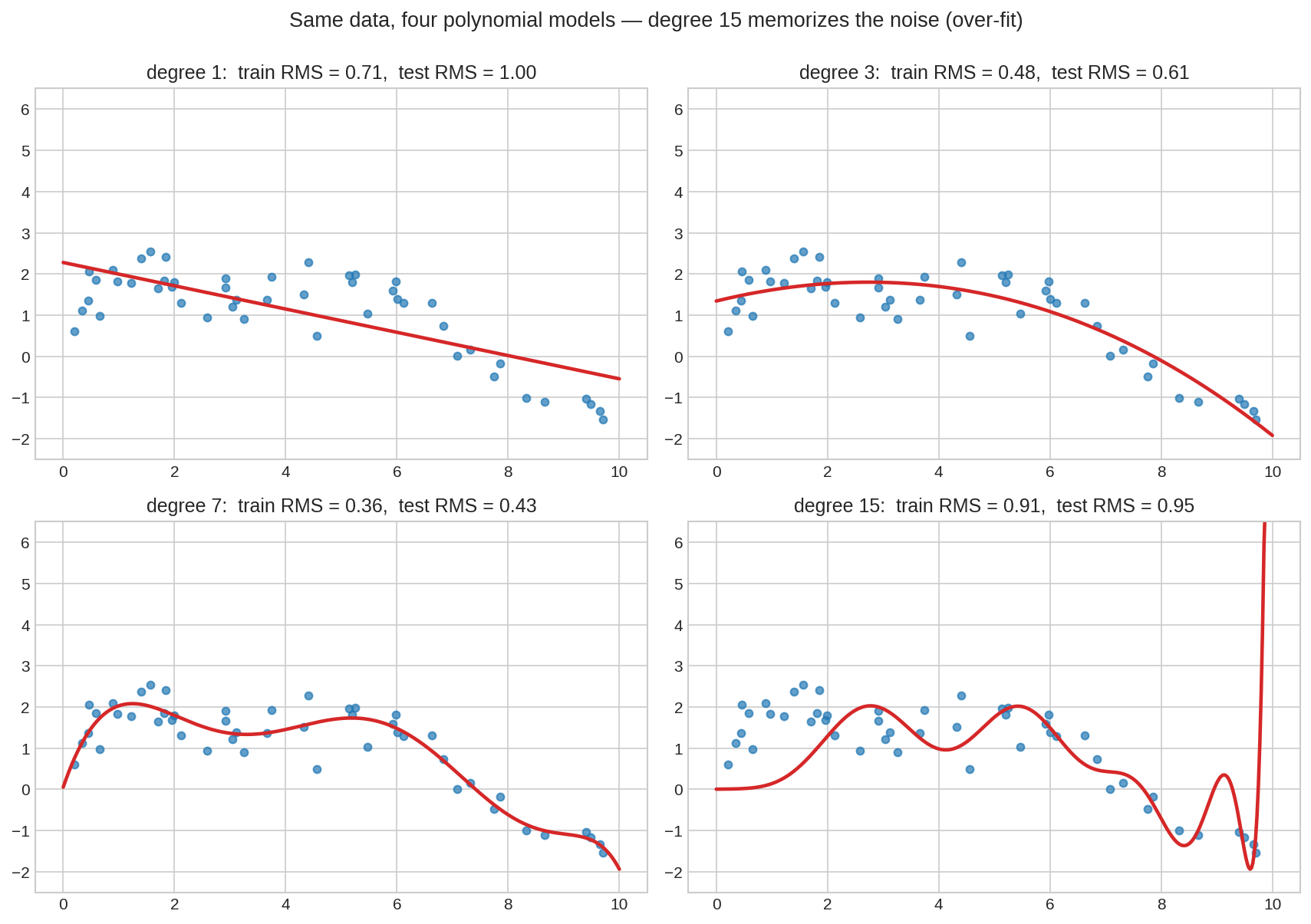
একই ৪৮টা training বিন্দুতে degree \(1, 3, 7, 15\)-এর polynomial fit। Degree 1 ডেটার বাঁক ধরতে পারছে না (under-fit), degree 3–7 ধরনটা সুন্দর ধরেছে, আর degree 15 প্রতিটা এলোমেলো noise-এর পেছনে দৌড়ে কুৎসিতভাবে দুলছে (over-fit)। লক্ষ করো: train RMS ধারাবাহিকভাবে কমলেও test RMS degree 15-তে খারাপ হয়ে গেছে।
দৃশ্য ২: Validation curve — এই chapter-এর সবচেয়ে গুরুত্বপূর্ণ ছবি¶
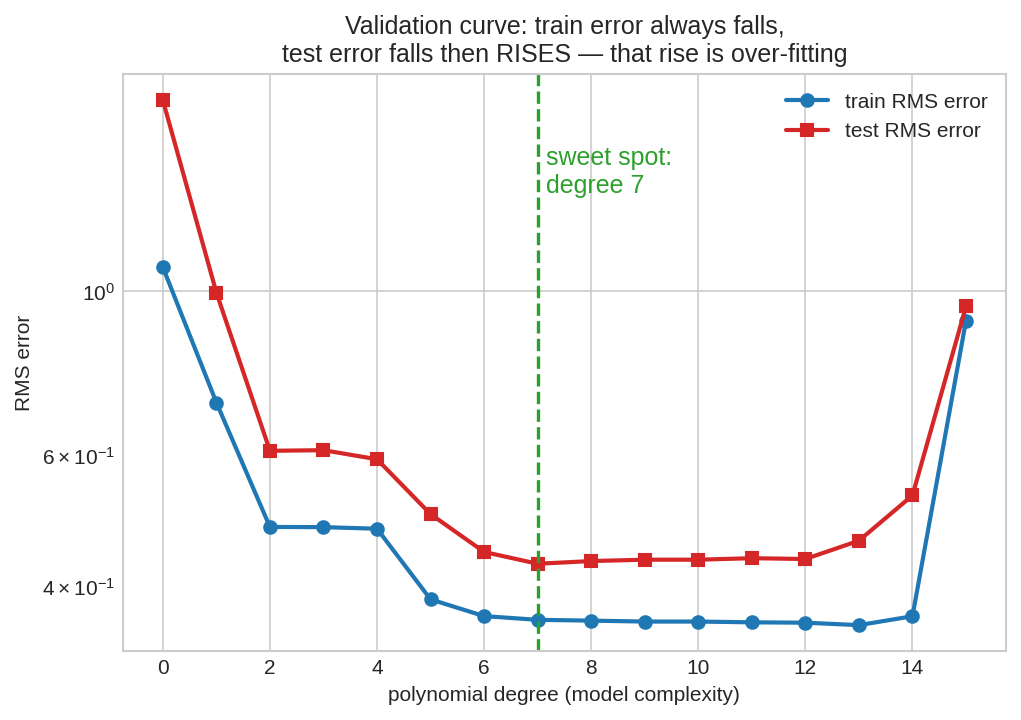
Degree (মডেলের জটিলতা) বাড়ার সাথে দুটো error-এর গল্প: নীল train RMS সবসময় নামে (কেন — Property 3), কিন্তু লাল test RMS নামে-তারপর-ওঠে। ওই ওঠাটাই overfitting-এর স্বাক্ষর। সবুজ ডটেড লাইনের কাছের অঞ্চলটাই "sweet spot" — যথেষ্ট জটিল যেন ধরন ধরা যায়, যথেষ্ট সরল যেন noise মুখস্থ না হয়।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে (সবগুলোই আক্ষরিক অর্থে এই chapter-এর গণিত):
- বাড়ির দাম: আয়তন আর bedroom সংখ্যা থেকে দামের regression — VMLS-এ Sacramento-র ৭৭৪টা বাড়িতে fit করা মডেলের RMS error $74.8k, যেখানে constant মডেলের (গড় দামের) $112.8k — দুটো feature-ই দামের অনুমান অনেকখানি শুধরে দেয়।
- Finance-এর \(\alpha\) আর \(\beta\): পুরো বাজারের return থেকে একটা শেয়ারের return-এর straight-line fit — ঢাল \(\beta\) (বাজারের সাথে দুলুনি), intercept-এর বাড়তি অংশ \(\alpha\)। Wall Street-এর দৈনন্দিন শব্দ দুটো আসলে least squares-এর \(\theta_2\) আর \(\theta_1\)!
- Trend আর season: বছরের পর বছর জ্বালানি খরচের Trend Line(ট্রেন্ড লাইন), কিংবা মাসিক ট্র্যাফিকের "গ্রীষ্মে বাড়ে-শীতে কমে" ঢেউ — linear trend + periodic component, দুটোই basis function সাজিয়ে এক least squares।
- আবহাওয়া: Auto-regressive(অটো-রিগ্রেসিভ — AR) মডেল — আগের \(M\) ঘণ্টার তাপমাত্রা থেকে পরের ঘণ্টার অনুমান; VMLS-এর LAX উদাহরণে গড়-দিয়ে-অনুমানের ভুল \(3.05°\)F, আর \(M=8\)-এর AR মডেলের মাত্র \(1.01°\)F।
Data Science / ML-এ:
- Linear Regression — ML-এর "hello world", আর এই chapter-টাই তার সম্পূর্ণ গণিত। sklearn-এর
LinearRegression().fit(X, y)ভেতরে ঠিক এই least squares-ই চালায়। - Feature engineering — Kaggle প্রতিযোগীদের গোপন অস্ত্র: ভালো column বানাতে পারাই অর্ধেক জয়; §৪-এ দেখবে কেন এটা "নতুন algorithm" নয়, শুধু \(A\)-এর নতুন column।
- Train/validation/test split — deep learning-সহ সব ML-এর প্রমিত সততা-পরীক্ষা; জন্ম এখানেই।
- Overfitting — ML engineer-এর নিত্যদিনের শত্রু; এই chapter-এর ছোট্ট polynomial-ই তার সবচেয়ে পরিষ্কার প্রদর্শনী।
৪. Properties¶
Property 1 — সবচেয়ে সরল মডেল: constant fit = গড়, আর তার RMS error = std¶
\(p = 1\), \(f_1(x) = 1\): মডেল একটাই সংখ্যা। তখন \(A = \mathbf{1}\), আর আগের chapter-এর Example 2 থেকেই জানি \(\hat{\theta}_1 = \operatorname{avg}(y^d)\)। তার RMS error:
অর্থ: standard deviation মানেই "constant মডেলের ভুল" — এটাই সব মডেলের benchmark। তোমার শখের মডেলের RMS error যদি \(\operatorname{std}(y^d)\)-এর কাছাকাছি হয়, সে গড়ের চেয়ে কিছুই শেখেনি।
Property 2 — Straight-line fit-এর সুন্দর সূত্র¶
\(f_1 = 1, f_2 = x\): মডেল \(\hat{f}(x) = \theta_1 + \theta_2 x\)। Normal equations হাতে ভেঙে (Problem 2) পাওয়া যায়:
যেখানে \(\rho\) হলো \(x^d, y^d\)-এর correlation coefficient (Part I-এর angle/cosine-এর জ্ঞাতি)। ফলাফল দুটো রত্ন: (ক) best line সবসময় ডেটার ভরকেন্দ্র \((\operatorname{avg}(x^d), \operatorname{avg}(y^d))\) দিয়ে যায়; (খ) ঢালের চিহ্ন = correlation-এর চিহ্ন।
Property 3 — Degree বাড়ালে train error কখনো বাড়ে না (nested মডেল)¶
Degree \(r\)-এর প্রতিটা polynomial, degree \(s > r\)-এরও polynomial (উঁচু coefficient শূন্য ধরে)। অর্থাৎ ছোট মডেলের পুরো পছন্দ-তালিকা বড় মডেলের ভেতরে — minimum তো ছোট হবেই (বা সমান):
ফাঁদটা এখানেই: এই যুক্তি শুধু training ডেটায় খাটে। "তাহলে degree যত পারো বাড়াও" — এই লোভের চিকিৎসা Property 5।
Property 4 — Feature engineering: নতুন algorithm নয়, \(A\)-এর নতুন column¶
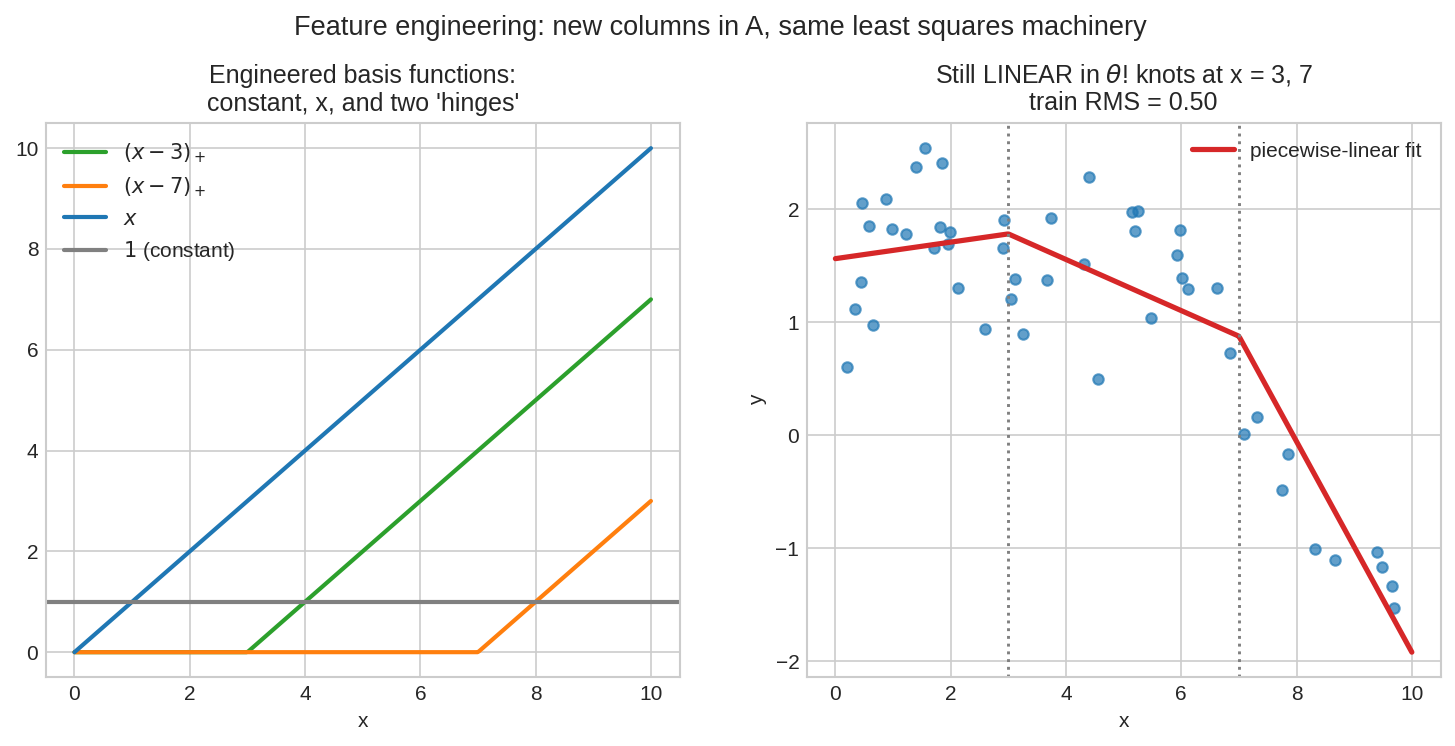
বাঁয়ে: চারটা basis function — \(1\), \(x\), আর দুটো "hinge" \((x-3)_+, (x-7)_+\) (যেখানে \((u)_+ = \max(u, 0)\))। ডানে: এই চার column-এর least squares fit — ভাঁজওয়ালা লাইন, যার হাঁটু (knot) \(x=3, 7\)-এ। Nonlinear চেহারা, কিন্তু \(\theta\)-তে সম্পূর্ণ linear — তাই সেই একই normal equations।
\(f_j\) যা খুশি হতে পারে — এ থেকেই গোটা কৌশল-পরিবার (সবার বিচারক অবশ্যই validation, Property 5):
| কৌশল | কী করে | কখন |
|---|---|---|
| Standardization(স্ট্যান্ডার্ডাইজেশন) / z-score | \(\tilde{x} = (x - b)/a\) — গড় \(\approx 0\), std \(\approx 1\) | প্রায় সবসময়, প্রথম ধাপ (prediction বদলায় না — Problem 5!) |
| Log Transform(লগ ট্রান্সফর্ম) | \(\tilde{x} = \log(x)\) বা \(\log(x+1)\) | মান positive ও বিশাল রেঞ্জে ছড়ানো (ওয়েবসাইট ভিজিট, দাম) |
| Winsorizing(উইনসরাইজিং) | চরম মানদের থ্রেশহোল্ডে ছেঁটে দেওয়া | সন্দেহজনক outlier/ভুল entry |
| Hinge / piecewise-linear | \((x - a)_+\) column যোগ | সম্পর্কের ঢাল মাঝপথে বদলায় |
| One-hot Encoding(ওয়ান-হট এনকোডিং) | categorical মানকে 0/1 column-এ ভাঙা | "বিভাগ", "বার", "রঙ" — সংখ্যা-নয় এমন feature (Problem 6) |
Property 5 — Train/test split: মডেলের আসল বিচার unseen ডেটায়¶
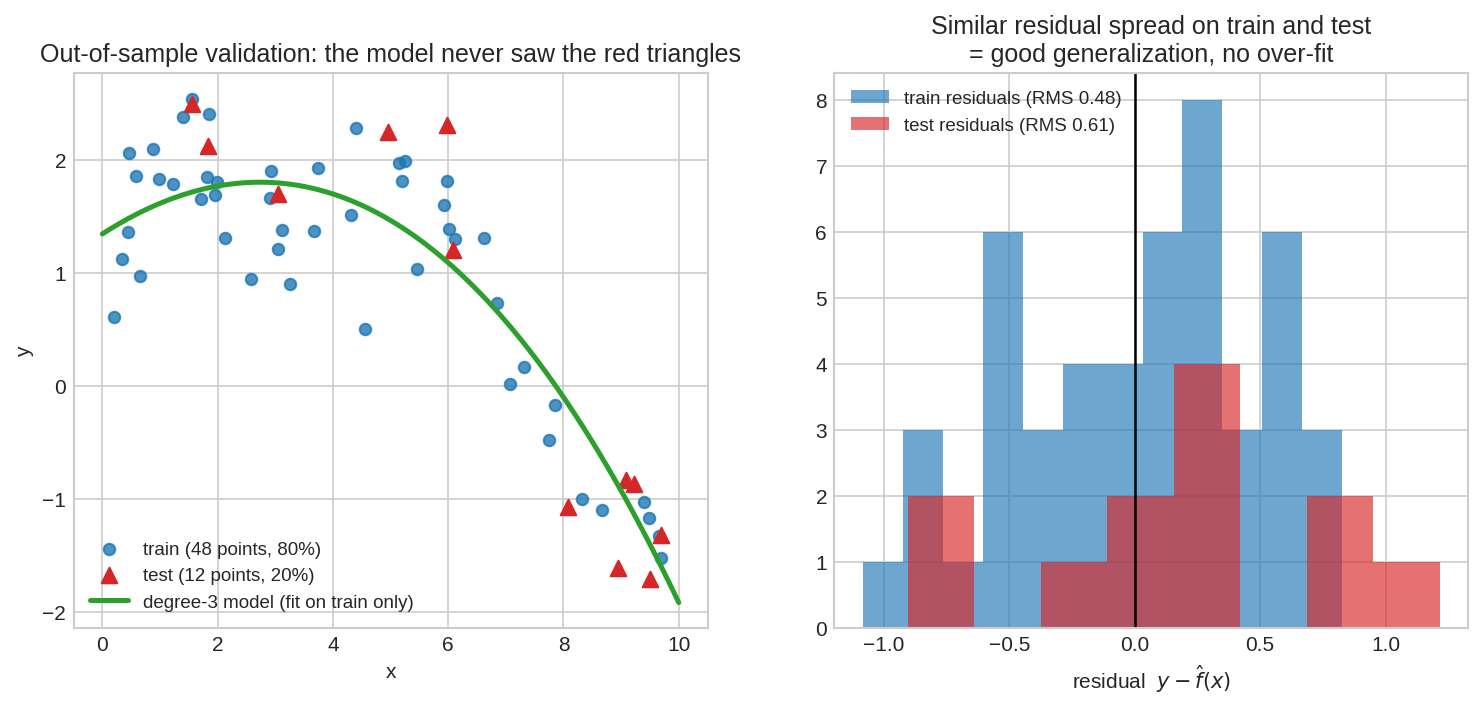
বাঁয়ে: ডেটার \(80\%\) (নীল) দিয়ে মডেল শেখানো, বাকি \(20\%\) (লাল ত্রিভুজ) লুকিয়ে রাখা — মডেল এদের কখনো দেখেনি। ডানে: দুই দলের residual-এর ছড়ানো প্রায় সমান — এটাই সুস্থ মডেলের লক্ষণ।
নিয়মটা তিন বাক্যে: (১) ডেটা এলোমেলোভাবে ভাগ করো — Training Set(ট্রেনিং সেট) \(\sim 80\%\), Test/Validation Set(টেস্ট/ভ্যালিডেশন সেট) \(\sim 20\%\)। (২) \(\hat{\theta}\) শেখো শুধু train থেকে। (৩) মডেল বাছো test RMS দেখে। যদি test RMS \(\approx\) train RMS — মডেলের Generalization(জেনারালাইজেশন — অদেখাকে সামলানোর ক্ষমতা) ভালো; যদি test RMS \(\gg\) train RMS — over-fit, মডেল ডেটা বোঝেনি, মুখস্থ করেছে। আরো মজবুত সংস্করণ: Cross-validation(ক্রস-ভ্যালিডেশন) — ডেটাকে ৫/১০ ভাঁজে ভাগ করে প্রতিবার এক ভাঁজ লুকিয়ে বাকিতে শেখা, তারপর গড়।
৫. Intuition — কেন সত্য?¶
Overfitting-এর জ্যামিতি: স্বাধীনতা বনাম শৃঙ্খলা¶
Column space-এর চোখে দেখো। \(y^d \in \mathbb{R}^N\) (\(N = 48\)), আর মডেলের সব সম্ভাব্য prediction \(A\theta\) বাস করে \(C(A)\)-তে — মাত্র \(p\)-মাত্রার subspace। Least squares \(y^d\)-কে সেখানে project করে (আগের chapter!)।
- \(p\) ছোট (সরল মডেল): \(C(A)\) সরু — ডেটার আসল ধরনটাও আঁটে না → under-fit, দুই error-ই বড়।
- \(p\) বাড়াও: subspace মোটা হয়, ছায়া \(y^d\)-এর কাছে সরে — train error নামে (Property 3-এর জ্যামিতিক রূপ)।
- \(p = N\): \(C(A) = \mathbb{R}^N\) (Problem 4) — ছায়া আর ছায়া নেই, \(A\hat\theta = y^d\) হুবহু! Train error শূন্য।
কিন্তু \(y^d = (\text{আসল ধরন}) + (\text{noise})\)। \(p\) যত বাড়ে, subspace-টা noise-অংশটুকুও ধরে ফেলার জায়গা পেয়ে যায় — মডেল শিখে ফেলে ওই নমুনার এলোমেলো কাঁপুনি, যা নতুন ডেটায় আর ফিরে আসে না। নতুন নমুনায় নতুন noise — মুখস্থ-করা পুরনো noise তখন উল্টো বোঝা। Train error মাপে "ছায়া কত কাছে", test error মাপে "ধরনটা ধরেছি কিনা" — দুটো এক নয়, আর ফারাকটাই overfitting।
আরেকটা চোখ: noise-এর মেঝে¶
আমাদের synthetic ডেটায় noise-এর std \(0.45\)। কোনো মডেল — যত চালাকই হোক — test RMS এর নিচে নামাতে পারবে না, কারণ নতুন বিন্দুর noise-টা মৌলিকভাবে অননুমেয়। §৬-এর টেবিলে দেখবে best test RMS \(\approx 0.43\) — মেঝে ছুঁয়ে ফেলেছে। কিন্তু train RMS \(0.36\) পর্যন্ত নেমেছে — মেঝের নিচে! ওই বাড়তি নামাটুকুই মুখস্থবিদ্যা: মডেল training noise-কে "ব্যাখ্যা" করছে, যেটা ব্যাখ্যার জিনিসই না।
কেন validation কাজ করে¶
Test set-এর বিন্দুরা মডেল-শেখার হিসাবে ঢোকেনি, তাই মডেলের কাছে তারা ভবিষ্যতের ডেটার প্রতিনিধি — "ভবিষ্যৎ আজকের মতোই হবে" এই একটাই অনুমান। ব্যাপারটা সৎ পরীক্ষার মতো: প্রশ্নপত্র আগে দেখে ফেললে ১০০ পাওয়াটা মেধার প্রমাণ নয় — আর test set বারবার দেখে মডেল বাছতে থাকলে সেই প্রশ্নফাঁসই ঘটে (Common ভুল ৪ দেখো)।
৬. Code-এ কেমনে লিখে¶
import numpy as np
np.random.seed(42)
# লুকানো সত্য (বাস্তবে কেউ জানে না): বাঁকানো + ঢেউ + noise
def truth(x):
return 1.0 + 0.5*x - 0.08*x**2 + 0.6*np.sin(1.4*x)
N = 60
x = np.sort(np.random.uniform(0, 10, N))
y = truth(x) + np.random.normal(0, 0.45, N) # noise-এর std = 0.45
# --- train/test split: 80% শেখা, 20% লুকানো পরীক্ষা ---
idx = np.random.permutation(N)
tr, te = np.sort(idx[:48]), np.sort(idx[48:])
x_tr, y_tr, x_te, y_te = x[tr], y[tr], x[te], y[te]
def fit_poly(x, y, deg):
A = np.vander(x, deg + 1, increasing=True) # design matrix: column j = x^j
theta, *_ = np.linalg.lstsq(A, y, rcond=None)
return theta
def predict(theta, x):
return np.vander(x, len(theta), increasing=True) @ theta
def rms(u):
return np.sqrt(np.mean(u**2))
print(f"benchmark: constant model RMS = std(y_tr) = {y_tr.std():.3f}")
print(f"{'degree':>6} {'train RMS':>10} {'test RMS':>10}")
for d in [0, 1, 2, 3, 5, 7, 10, 15]:
th = fit_poly(x_tr, y_tr, d)
print(f"{d:>6} {rms(y_tr - predict(th, x_tr)):>10.3f} {rms(y_te - predict(th, x_te)):>10.3f}")
Output:
benchmark: constant model RMS = std(y_tr) = 1.078
degree train RMS test RMS
0 1.078 1.811
1 0.708 0.996
2 0.481 0.609
3 0.481 0.611
5 0.384 0.501
7 0.361 0.429
10 0.359 0.435
15 0.913 0.954
Output ব্যাখ্যা:
- Degree 0 ঠিক Property 1: train RMS \(=\) std \(= 1.078\) — benchmark।
- Train কলামটা (প্রায়) একমুখী নামছে — Property 3 চোখের সামনে। ব্যতিক্রম degree 15: train-ও বেড়ে গেছে! কারণ \(x^{15}\) পর্যন্ত raw Vandermonde column-রা প্রায়-dependent —
lstsq-ও হিমশিম খায় (আগের chapter-এর numerical সতর্কতা; প্রতিকার: standardization, Problem 5)। - Test কলামে U-এর তলা degree \(\approx 7\)-এ (\(0.429\)) — noise-এর মেঝে \(0.45\)-এর কাছেই, যেমন Intuition বলেছিল। এর পরে জটিলতা বাড়িয়ে কিছুই পাওয়ার নেই।
np.vander(x, p, increasing=True)এক লাইনে design matrix বানায় — এই matrix-এর নামই Vandermonde Matrix(ভ্যান্ডারমন্ড ম্যাট্রিক্স)।- Model বাছার নিয়ম কোডে এক লাইন:
best = degrees[np.argmin(test_rms)]— কখনোইtrain_rmsনয়।
৭. Worked Examples¶
Example 1 — পড়ার ঘণ্টা থেকে নম্বর: straight-line fit হাতে¶
৪ জন ছাত্রের দৈনিক পড়ার ঘণ্টা \(x^d = (1, 2, 3, 4)\), নম্বর \(y^d = (40, 50, 55, 75)\)। মডেল \(\hat{f}(x) = \theta_1 + \theta_2 x\)।
ধাপ ১ — গড়: \(\operatorname{avg}(x^d) = 2.5\), \(\operatorname{avg}(y^d) = 55\)।
ধাপ ২ — বিচ্যুতি: \(x^d - 2.5 = (-1.5, -0.5, 0.5, 1.5)\); \(y^d - 55 = (-15, -5, 0, 20)\)।
ধাপ ৩ — ঢাল (Property 2-এর সূত্র):
ধাপ ৪ — intercept: \(\hat{\theta}_1 = 55 - 11 \times 2.5 = 27.5\)। মডেল: \(\hat{y} = 27.5 + 11x\)।
যাচাই: \(\hat{y}^d = (38.5, 49.5, 60.5, 71.5)\), \(r^d = (1.5, 0.5, -5.5, 3.5)\) — যোগফল \(0\) ✓ (constant column-এর সাথে লম্ব), \(\sum x_i r_i = 1.5 + 1 - 16.5 + 14 = 0\) ✓ (\(x\)-column-এর সাথেও)। RMS error \(= \sqrt{45/4} \approx 3.35\), যেখানে benchmark \(\operatorname{std}(y^d) \approx 12.75\) — লাইনটা গড়ের চেয়ে চারগুণ ভালো। ভবিষ্যদ্বাণী: দৈনিক ৫ ঘণ্টা পড়লে \(\hat{y} = 27.5 + 55 = 82.5\)।
Example 2 — ৩ বিন্দুতে quadratic: যখন fit নিখুঁত হয়ে যায়¶
ডেটা \((0, 1), (1, 3), (2, 9)\); মডেল \(\hat{f}(x) = \theta_1 + \theta_2 x + \theta_3 x^2\) (\(p = N = 3\))।
তাই least squares নয়, সরাসরি solve: প্রথম সারি \(\Rightarrow \theta_1 = 1\); বাকি দুটো \(\Rightarrow \theta_2 + \theta_3 = 2\), \(2\theta_2 + 4\theta_3 = 8\) \(\Rightarrow \theta_3 = 2, \theta_2 = 0\)।
মডেল \(\hat{f}(x) = 1 + 2x^2\), residual শূন্য — তিনটা বিন্দুই লাইনের ওপরে। শুনতে দারুণ, কিন্তু এখন জানো এটা সন্দেহের কারণও: \(p = N\) হলে শূন্য train error সবসময়ই আসে — ডেটা যা-ই হোক। ডেটায় noise থাকলে ওই নিখুঁত fit-টা noise-সহ মুখস্থ।
Example 3 — Hinge feature: ভাঁজওয়ালা লাইন হাতে fit করা¶
ডেটা: \(x^d = (0, 1, 2, 3)\), \(y^d = (0, 1, 2, 1)\) — বাড়ছিল, তারপর পড়ে গেলো। Basis: \(f_1 = 1,\; f_2 = x,\; f_3 = (x - 2)_+\)।
Normal equations ভাঙি: তৃতীয় সমীকরণ \(\theta_1 + 3\theta_2 + \theta_3 = 1 \Rightarrow \theta_3 = 1 - \theta_1 - 3\theta_2\)। প্রথমটায় বসাও: \(3\theta_1 + 3\theta_2 = 3\); দ্বিতীয়টায়: \(3\theta_1 + 5\theta_2 = 5\)। বিয়োগে \(\theta_2 = 1\), তাই \(\theta_1 = 0\), \(\theta_3 = -2\)।
মডেল: \(\hat{f}(x) = x - 2(x-2)_+\) — অর্থাৎ \(x \le 2\)-তে ঢাল \(1\), তারপরে ঢাল \(1 - 2 = -1\)। চারটা বিন্দুই হুবহু মিলে যায় (residual \(0\)) — এবার সেটা ভালো খবর, কারণ ডেটার আসল ধরনটাই ভাঁজওয়ালা ছিল। শিক্ষা: সঠিক basis বাছলে অল্প parameter-এই চমৎকার fit — feature engineering-এর পুরো দর্শন।
৮. Problems ও Solutions¶
Problem 1. রিকশা-ভাড়ার ডেটা: দূরত্ব (km) \(x^d = (1, 2, 3, 4)\), ভাড়া (টাকা) \(y^d = (30, 42, 50, 62)\)। Straight-line মডেল fit করো, residual-দের দুটো লম্বতা-চেক করো, আর ৬ km-এর ভাড়া অনুমান করো।
Solution
গড়: \(\bar{x} = 2.5\), \(\bar{y} = 46\)। বিচ্যুতি: \((-1.5, -0.5, 0.5, 1.5)\) ও \((-16, -4, 4, 16)\)।
মডেল: \(\hat{y} = 20 + 10.4x\) — "উঠতেই ২০ টাকা, তারপর প্রতি km-এ ১০.৪০"।
যাচাই: \(\hat{y}^d = (30.4, 40.8, 51.2, 61.6)\), \(r^d = (-0.4, 1.2, -1.2, 0.4)\); \(\sum r_i = 0\) ✓, \(\sum x_i r_i = -0.4 + 2.4 - 3.6 + 1.6 = 0\) ✓ — residual দুই column-এর সাথেই লম্ব, normal equations জীবন্ত।
Prediction: \(\hat{y}(6) = 20 + 62.4 = 82.4\) টাকা। (সতর্কতা: \(x = 6\) ডেটার সীমার বাইরে — extrapolation সবসময় বাড়তি ঝুঁকি।)
Problem 2. Straight-line fit-এর normal equations-এর প্রথম সমীকরণটা লিখে দেখাও \(\hat{\theta}_1 = \operatorname{avg}(y^d) - \hat{\theta}_2\operatorname{avg}(x^d)\), আর ব্যাখ্যা করো কেন এর মানে: best line সবসময় ভরকেন্দ্র \((\bar{x}, \bar{y})\) দিয়ে যায়।
Solution
\(A = [\mathbf{1}\;\; x^d]\) নিয়ে \(A^TA\hat{\theta} = A^Ty^d\)-এর প্রথম সারি (অর্থাৎ \(\mathbf{1}^T\) দিয়ে গুণ):
(দুই পাশ \(N\) দিয়ে ভাগ করেছি।) এখন লাইনে \(x = \bar{x}\) বসাও: \(\hat{f}(\bar{x}) = \hat{\theta}_1 + \hat{\theta}_2\bar{x} = \bar{y}\) — ভরকেন্দ্র লাইনের ওপরেই ∎
Geometric পাঠ: প্রথম normal equation মানে \(\mathbf{1}^Tr^d = 0\) — residual-দের গড় শূন্য। মডেল গড়ে-ওঠা ভুল করে না; ভুলগুলো ওপরে-নিচে কাটাকাটি।
Problem 3. (VMLS 13.1-এর constant fit) \(y^d = (2, 4, 9)\)-তে constant মডেল \(\hat{f}(x) = \theta_1\) least squares-এ fit করো। দেখাও RMS error \(= \operatorname{std}(y^d)\), আর relative error \(\operatorname{rms}(r^d)/\operatorname{rms}(y^d)\) হিসাব করো।
Solution
\(A = \mathbf{1}\) (৩×১), তাই \(\hat{\theta}_1 = \frac{\mathbf{1}^Ty^d}{\mathbf{1}^T\mathbf{1}} = \frac{15}{3} = 5\) — গড়।
Residual: \(r^d = (2-5, 4-5, 9-5) = (-3, -1, 4)\); \(\operatorname{rms}(r^d) = \sqrt{\frac{9 + 1 + 16}{3}} = \sqrt{\frac{26}{3}} \approx 2.94\)।
আর সংজ্ঞা অনুযায়ীই \(\operatorname{std}(y^d) = \operatorname{rms}(y^d - \bar{y}\mathbf{1}) = \sqrt{26/3}\) — হুবহু এক ∎
Relative error: \(\operatorname{rms}(y^d) = \sqrt{(4 + 16 + 81)/3} = \sqrt{101/3} \approx 5.80\), তাই \(2.94/5.80 \approx 0.51\) — মডেল ডেটাকে "৫১% ভুলে" ধরে। পাঠ: যেকোনো fancy মডেলকে আগে এই সংখ্যার সাথে লড়তে হবে — std-ই benchmark, এবং এই অনুপাত ছোট করাই খেলা।
Problem 4. \(N\)টা ভিন্ন \(x\)-মানে degree \(N-1\) polynomial fit করলে train error সবসময় শূন্য — প্রমাণ করো। (Hint: square Vandermonde matrix-এর null space।) তারপর ব্যাখ্যা করো: এটা কেন উদযাপনের নয়, সতর্কতার সংকেত।
Solution
এখানে \(A\) হলো \(N \times N\) Vandermonde, \(A_{ij} = (x^{(i)})^{j-1}\)। ধরো \(A\theta = 0\) কোনো \(\theta\)-এর জন্য। তার মানে polynomial \(q(t) = \theta_1 + \theta_2 t + \cdots + \theta_N t^{N-1}\)-এর মান \(N\)টা ভিন্ন বিন্দু \(x^{(1)}, \dots, x^{(N)}\)-এ শূন্য — অথচ \(q\)-এর degree \(\le N - 1\)। Algebra-র মৌলিক সত্য: degree \(\le N-1\)-এর nonzero polynomial-এর root বড়জোর \(N-1\)টা। সুতরাং \(q\) zero polynomial, অর্থাৎ \(\theta = 0\) — \(N(A) = \{0\}\), \(A\) invertible (Part IV-এর ভাষায় full rank)।
তাহলে \(\theta = A^{-1}y^d\) নিলেই \(A\theta = y^d\) হুবহু — residual শূন্য, train RMS \(= 0\) ∎
কেন সতর্কতা: শূন্যটা এলো ডেটার সাথে মডেলের মিল থেকে নয়, শুধু গোনাগুনতি থেকে (\(p = N\)) — \(y^d\)-তে যা-ই থাকুক (খাঁটি noise হলেও!) fit নিখুঁত হতো। যে প্রশংসা সবাই পায়, সেটা কোনো প্রশংসাই না। ছবিতে এরই চেহারা fig 2-এর degree-15 প্যানেল: বিন্দু ছুঁতে গিয়ে মাঝখানে উদ্দাম দোলা। আসল বিচার তাই বাইরের ডেটায় — validation।
Problem 5. Standardization প্রমাণ: মডেল A-তে basis \(\{1, x\}\), মডেল B-তে \(\{1, \tilde{x}\}\) যেখানে \(\tilde{x} = (x - b)/a\), \(a \neq 0\)। দেখাও দুই design matrix-এর column space একই, অতএব least squares prediction \(\hat{y}^d\)-ও একই — শুধু \(\theta\) বদলায়। তাহলে standardize করার লাভ কী?
Solution
\(A_1 = [\mathbf{1}\;\; x^d]\), \(A_2 = [\mathbf{1}\;\; \tilde{x}^d]\) যেখানে \(\tilde{x}^d = \frac{1}{a}x^d - \frac{b}{a}\mathbf{1}\)।
\(A_2\)-এর প্রতিটা column \(A_1\)-এর column-দের combination (আর উল্টোটাও: \(x^d = a\tilde{x}^d + b\mathbf{1}\))। কাজেই \(C(A_1) = C(A_2)\)।
Least squares prediction হলো \(y^d\)-এর ছায়া column space-এ (আগের chapter) — আর ছায়া নির্ভর করে শুধু subspace-এর ওপর, তার basis-এর ওপর নয়। একই subspace \(\Rightarrow\) একই \(\hat{y}^d\), একই residual, একই RMS ∎ (নতুন \(\theta\): \(\hat{\theta}_2' = a\hat{\theta}_2\), \(\hat{\theta}_1' = \hat{\theta}_1 + b\hat{\theta}_2\) — মিলিয়ে দেখো।)
তাহলে লাভ? দুটো: (১) সংখ্যাগত — polynomial-এর মতো derived feature বানানোর আগে \(x\)-কে \([-1, 1]\)-ঘেঁষা রেঞ্জে আনলে Vandermonde-এর column-রা প্রায়-dependent হয় না (§৬-এ degree 15-এর বিপর্যয় মনে করো)। (২) পাঠযোগ্যতা — সব feature এক স্কেলে থাকলে \(\hat{\theta}_j\)-দের আকার তুলনীয় হয়: কোন feature-এর প্রভাব বড়, এক নজরে বোঝা যায়।
Problem 6. একটা delivery service-এর ডেটায় feature "দিন" \(\in \{\)শুক্র, শনি, অন্যান্য\(\}\)। "অন্যান্য"-কে default ধরে one-hot encoding-এ design matrix-এর column সাজাও (constant column সহ), ছোট্ট একটা উদাহরণ-matrix লেখো। তারপর দেখাও: default বাদ না দিয়ে তিনটা indicator column-ই রাখলে (constant-এর সাথে) column-রা linearly dependent হয়ে যায়।
Solution
Feature দুটো: \(f_2(x) = 1\) যদি দিন = শুক্র (নাহলে \(0\)), \(f_3(x) = 1\) যদি দিন = শনি। ধরো ৪টা নমুনা: (বুধ, শুক্র, শনি, শুক্র):
ব্যাখ্যাও সুন্দর: \(\theta_1\) = সাধারণ দিনের ভিত্তিমান, \(\theta_2, \theta_3\) = শুক্র/শনির বাড়তি প্রভাব।
তিনটাই রাখলে: ধরো column-গুলো \(\mathbf{1}, d_{\text{শুক্র}}, d_{\text{শনি}}, d_{\text{অন্য}}\)। প্রতিটা নমুনা ঠিক এক শ্রেণিতে পড়ে, তাই সারিতে সারিতে
— চারটা column-এর একটা nontrivial linear সম্পর্ক (\(\mathbf{1} - d_{\text{শুক্র}} - d_{\text{শনি}} - d_{\text{অন্য}} = 0\))। \(A\)-এর column dependent \(\Rightarrow\) \(A^TA\) singular \(\Rightarrow\) \(\hat{\theta}\) অনন্যভাবে নির্ধারিত নয় (আগের chapter-এর সতর্কতা)। Statistics-এ এর ডাকনাম dummy variable trap। মুক্তি: এক শ্রেণিকে default রেখে \(l\) শ্রেণিতে \(l-1\)টা column ∎
Problem 7. (কোড) §৬-এর ডেটায় degree \(0\) থেকে \(15\) পর্যন্ত সব polynomial fit করে validation curve আঁকার কোড লেখো, best degree টা np.argmin দিয়ে বের করো, আর শেষ সারিতে সেই best মডেলের test RMS-এর সাথে noise-এর std (\(0.45\))-এর তুলনা ছাপো।
Solution
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
def truth(x):
return 1.0 + 0.5*x - 0.08*x**2 + 0.6*np.sin(1.4*x)
N = 60
x = np.sort(np.random.uniform(0, 10, N))
y = truth(x) + np.random.normal(0, 0.45, N)
idx = np.random.permutation(N)
tr, te = np.sort(idx[:48]), np.sort(idx[48:])
def rms(u): return np.sqrt(np.mean(u**2))
degrees = range(16)
tr_rms, te_rms = [], []
for d in degrees:
A_tr = np.vander(x[tr], d + 1, increasing=True)
th, *_ = np.linalg.lstsq(A_tr, y[tr], rcond=None)
tr_rms.append(rms(y[tr] - A_tr @ th))
te_rms.append(rms(y[te] - np.vander(x[te], d + 1, increasing=True) @ th))
best = int(np.argmin(te_rms))
plt.semilogy(degrees, tr_rms, 'o-', label='train RMS')
plt.semilogy(degrees, te_rms, 's-', label='test RMS')
plt.axvline(best, ls='--', color='green')
plt.xlabel('degree'); plt.legend(); plt.show()
print(f"best degree = {best}, test RMS = {te_rms[best]:.3f} (noise floor 0.45)")
Seed 42-এ output: best degree = 7, test RMS = 0.429 — noise-এর মেঝের গা-ঘেঁষা, অর্থাৎ ওই ডেটা থেকে যা শেখার তা শেখা হয়ে গেছে। খেয়াল করো curve-টা fig 3-এরই যমজ — কারণ কোডটাও তা-ই।
একটা সূক্ষ্মতা: best degree বাছতে আমরা test set ব্যবহার করলাম — কড়া নিয়মে এই set-এর নাম তখন validation set, আর চূড়ান্ত রিপোর্টের জন্য তৃতীয় একটা অচেনা set রাখা উচিত (Common ভুল ৪)।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "Train error ছোট মানেই মডেল ভালো" | Train error জটিলতা বাড়ালে এমনিই কমে (Property 3) — মেধার প্রমাণ নয়। মডেলের একমাত্র সৎ বিচারক unseen ডেটার (test/validation) error। |
| "Linear regression মানে শুধু সরলরেখা" | "Linear" শব্দটা \(\theta\)-এর জন্য, \(x\)-এর জন্য নয়! \(x^2\), \(\sin x\), \((x-3)_+\) — basis-এ যা খুশি; মডেল তবু linear in the parameters, আর যন্ত্র সেই একই least squares। |
| "যত বেশি feature/degree, তত ভালো মডেল" | একটা সীমার পরে বাড়তি জটিলতা শুধু noise মুখস্থ করে — test error-এর U-curve ওঠা শুরু করে (fig 3)। সরলতা একটা গুণ; বাড়তি feature-এর প্রমাণ দিতে হয় validation-এ। |
| "Test set-এ বারবার মডেল বাছলেও সে তো unseen-ই" | বারবার test error দেখে সিদ্ধান্ত নিলে তুমি নিজেই test set-কে training-এ ঢুকিয়ে ফেলছো — প্রশ্নফাঁস! কড়া নিয়ম: model বাছাই validation set-এ, চূড়ান্ত রিপোর্ট আলাদা test set-এ (বা cross-validation)। |
| "Zero training error = নিখুঁত মডেল" | \(p = N\) হলে শূন্য train error গণিতের গ্যারান্টি — ডেটা খাঁটি noise হলেও (Problem 4)। শূন্য দেখলে খুশি নয়, সন্দেহ করো। |
| "Standardize করলে মডেলের prediction বদলে যায়" | না — column space একই থাকে, তাই ছায়া তথা prediction অবিকল একই (Problem 5)। বদলায় শুধু \(\theta\)-এর মান: সংখ্যাগত স্থিতি আর পাঠযোগ্যতা বাড়ে, ফল একই। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| মডেল | \(\hat{f}(x) = \sum_j \theta_j f_j(x)\) — linear in \(\theta\) | দর্জির ছাঁচ: অল্প মাপে গোটা শরীর |
| Fitting | \(A_{ij} = f_j(x^{(i)})\), \(\min_\theta\|A\theta - y^d\|^2\) | Chapter 5.4-এর যন্ত্র, ডেটার জ্বালানি |
| Benchmark | constant fit \(=\) গড়, RMS \(=\operatorname{std}(y^d)\) | এর চেয়ে খারাপ মানে কিছুই শেখেনি |
| Straight line | \(\hat{\theta}_2 = \rho\,\frac{\text{std}(y)}{\text{std}(x)}\); line goes through \((\bar{x}, \bar{y})\) | correlation-ই ঢাল |
| Polynomial | \(A\) = Vandermonde; degree \(\uparrow\) \(\Rightarrow\) train RMS \(\downarrow\) | nested subspace-এ মোটা হওয়া ছায়া |
| Overfitting | train RMS \(\ll\) test RMS | noise মুখস্থ, ধরন শেখা হয়নি |
| Validation | ৮০/২০ split; বিচার শুধু test RMS-এ | প্রশ্ন না-দেখে পরীক্ষা |
| Feature engineering | নতুন কৌশল \(=\) \(A\)-এর নতুন column | standardize, log, hinge, one-hot |
পরের Part-এর সেতু: Part V সম্পূর্ণ — লম্বতা, ছায়া, Gram–Schmidt, FTLA, least squares, আর আজকের data fitting: পুরোটা মিলে একটাই গল্প, "ভুলকে লম্ব-জগতে পাঠিয়ে দাও"। কিন্তু একটা প্রশ্ন বারবার এড়িয়ে গেছি: matrix \(A\) নিজে আসলে কী করে — কোন দিকে টানে, কতটা টানে? উত্তর লুকিয়ে আছে কয়েকটা জাদুকরী সংখ্যা আর দিকের মধ্যে। Part VI: Determinants, Eigenvalues ও SVD — linear algebra-র রাজমুকুট, যেখানে pseudo-inverse-এর অসমাপ্ত গল্পটাও শেষ হবে।
📓 Notebook Project¶
notebooks/part-05/ch05-project.ipynb — Part V-এর flagship: বাস্তব-ধাঁচের dataset-এ (ঢাকার ফ্ল্যাটের আয়তন-বয়স-দূরত্ব থেকে দাম) least squares regression সম্পূর্ণ scratch-এ — design matrix, normal equations, train/test split, validation curve — তারপর sklearn-এর LinearRegression-এর সাথে অঙ্কে-অঙ্কে মিলিয়ে দেখা।