Chapter 9.5 — Random Matrix Theory-র পরিচয় (র্যান্ডম ম্যাট্রিক্স তত্ত্ব)¶
একটা মজার পরীক্ষা ভাবো। কাগজে (বা কম্পিউটারে) \(100 \times 100\)-টা ঘর আঁকো, আর প্রতিটা ঘরে একটা করে সম্পূর্ণ এলোমেলো সংখ্যা বসাও — coin toss, dice, Gaussian, যা খুশি। শুধু একটা শর্ত: matrix-টা symmetric রাখো (\(a_{ij} = a_{ji}\))। এবার এই matrix-এর \(100\)টা eigenvalue বের করো। প্রশ্ন: eigenvalue-গুলো সংখ্যারেখার কোথায় পড়বে? সাধারণ বুদ্ধি বলে — "সংখ্যাগুলোই তো এলোমেলো, eigenvalue-ও যেখানে খুশি পড়বে।" অথচ প্রকৃতি বলে অন্য কথা: eigenvalue-রা নিজেদের সাজিয়ে নেয় একটা নিখুঁত অর্ধবৃত্তের ভেতরে — প্রতিবার, যেকোনো randomness-এ, একই অর্ধবৃত্ত। এত বিশৃঙ্খলা মিলে জন্ম দেয় এত নিশ্চয়তার! তোমার যদি Central Limit Theorem-এর কথা মনে পড়ে — হাজারটা এলোমেলো সংখ্যার গড় সবসময় একই ঘণ্টা-রেখায় (bell curve) গিয়ে বসে — তাহলে ঠিক পথেই আছো: Random Matrix Theory(র্যান্ডম ম্যাট্রিক্স থিওরি) হলো CLT-র matrix-জগতের বড় ভাই। আর গল্পের শেষ মোচড়টা data scientist-দের জন্য: এই তত্ত্বই বলে দেয় তোমার PCA-র কোন component সত্যিকারের সংকেত আর কোনটা noise-এর ভেলকি।
🎯 এই chapter-এ যা শিখবে¶
- Wigner Matrix(উইগনার ম্যাট্রিক্স)-এর সংজ্ঞা, আর \(1/\sqrt{n}\) scaling-এর রহস্য — trace দিয়ে দুই লাইনের হিসাব
- Semicircle Law(সেমিসার্কেল ল): এলোমেলো symmetric matrix-এর eigenvalue histogram কেন অর্ধবৃত্ত — moment method আর Catalan Number(কাতালান নাম্বার)-এর প্রমাণ-গল্প
- Marchenko–Pastur Law(মার্চেঙ্কো–পাস্তুর ল): pure noise-এর sample covariance-এর eigenvalue-রা কোথায় ছড়ায় — \(\gamma = p/n\)-এর খেলা
- PCA-র ফাঁদ: high dimension-এ noise-ও "important component" সাজে — MP edge দিয়ে আসল-নকল আলাদা করা
- Spiked Model(স্পাইকড মডেল) ও BBP Transition(বিবিপি ট্রানজিশন): সংকেত কত জোরালো হলে noise-এর ভিড় থেকে মাথা তোলে — একটা আসল phase transition
🖼️ এক ছবিতে মূল idea¶
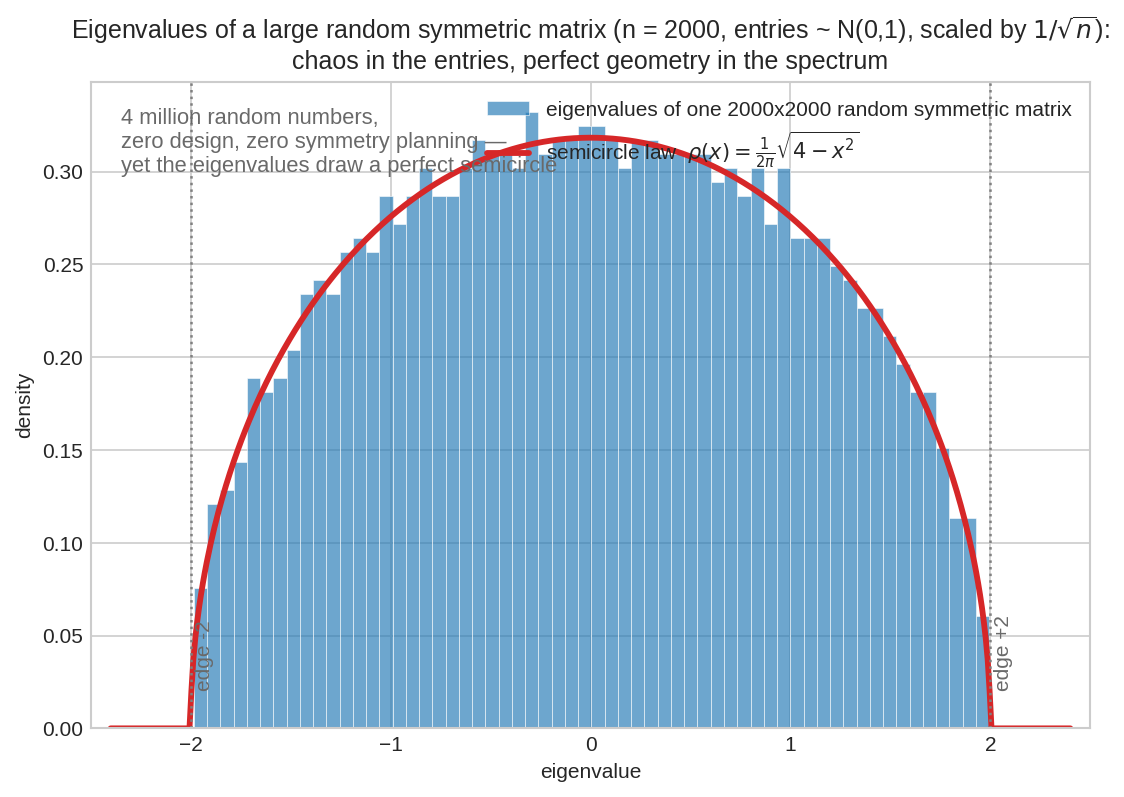
একটা \(2000 \times 2000\) symmetric matrix — ৪০ লক্ষ সংখ্যার প্রতিটা আলাদা করে এলোমেলো, কোনো নকশা নেই। অথচ তার eigenvalue-দের histogram (নীল) বসে গেছে হুবহু লাল রেখাটার ওপর: \(\rho(x) = \frac{1}{2\pi}\sqrt{4 - x^2}\) — একটা নিখুঁত অর্ধবৃত্ত, প্রান্ত ঠিক \(-2\) আর \(+2\)-এ। বিশৃঙ্খলার ভেতরে লুকিয়ে থাকা জ্যামিতি — এটাই এই chapter-এর নায়ক।
১. কি? (What)¶
দৈনন্দিন analogy: ভিড়ের নিশ্চয়তা¶
একজন মানুষের উচ্চতা আগে থেকে বলা অসম্ভব। কিন্তু দশ লক্ষ মানুষের উচ্চতার histogram আঁকো — প্রতিবার একই ঘণ্টা-রেখা। ব্যক্তি অনিশ্চিত, ভিড় নিশ্চিত — এটাই Central Limit Theorem-এর দর্শন। Random Matrix Theory ঠিক একই প্রশ্ন করে, শুধু "সংখ্যার ভিড়"-এর বদলে "matrix-এর ভিড়" নিয়ে: একটা বিশাল matrix-এর entry-রা এলোমেলো হলে তার eigenvalue-দের ভিড় দেখতে কেমন? উত্তর: entry-দের খুঁটিনাটি যা-ই হোক (Gaussian, coin flip, যা খুশি — শুধু mean \(0\), variance \(1\) হলেই চলে), eigenvalue-দের histogram যায় একটাই universal আকৃতিতে। এই "খুঁটিনাটি-নিরপেক্ষতা"-কে বলে Universality(ইউনিভার্সালিটি) — RMT-র সবচেয়ে গভীর বিস্ময়।
এক অনুচ্ছেদ ইতিহাস: Wigner-এর দুঃসাহসী চাল¶
১৯৫০-এর দশকে পদার্থবিদ Eugene Wigner ইউরেনিয়ামের মতো ভারী পরমাণুর নিউক্লিয়াসের energy level হিসাব করতে চাইছিলেন। Quantum mechanics বলে (Chapter 6.2-তে ছুঁয়ে এসেছি): energy level-গুলো হলো একটা বিশেষ operator-এর — Hamiltonian(হ্যামিলটোনিয়ান)-এর — eigenvalue। সমস্যা: শত শত nucleon-এর জটে সেই Hamiltonian লেখা মানুষের সাধ্যের বাইরে। Wigner-এর চাল ছিল বেপরোয়া: "Hamiltonian-টা জানি না? তাহলে ধরে নিই সেটা একটা random symmetric matrix!" — যুক্তি: এত জটিল system-এ নির্দিষ্ট entry-গুলো তো একরকম এলোমেলোই, শুধু symmetry-টুকু (physics-এর দাবি) রাখা চাই। আশ্চর্যের বিষয়, এই "অজ্ঞতার model" আসল নিউক্লিয়াসের level-এর পরিসংখ্যান চমৎকার ধরে ফেললো — আর জন্ম নিলো একটা আস্ত গণিত-শাখা, যেটা আজ number theory থেকে শুরু করে deep learning-এর গবেষণা পর্যন্ত সবখানে হাজির।
সংজ্ঞা: Wigner Matrix¶
একটা \(n \times n\) Wigner Matrix \(W\) বানাও এভাবে:
- Diagonal-এর ওপরের অংশে (\(i < j\)) প্রতিটা entry \(w_{ij}\) স্বাধীনভাবে (iid) নাও — mean \(\mathbb{E}[w_{ij}] = 0\), variance \(\mathbb{E}[w_{ij}^2] = 1\);
- Symmetric করো: \(w_{ji} = w_{ij}\) (diagonal entry-রাও mean \(0\), finite variance);
- পুরোটাকে ভাগ করো \(\sqrt{n}\) দিয়ে:
Symmetric কেন চাই? Part VI-এর Spectral Theorem মনে করো — symmetric matrix-এর সব eigenvalue real, তাই তাদের histogram আঁকা যায় সংখ্যারেখায়। (Symmetric না হলে eigenvalue-রা complex plane-এ ছড়ায় — সেও এক সুন্দর গল্প, কিন্তু আজ নয়।)
কেন \(\sqrt{n}\) দিয়ে ভাগ? — trace-এর দুই লাইনের হিসাব¶
Proof-এর গল্প: scaling-টা কোথা থেকে এলো সেটা অনুমানের ব্যাপার না — নিজেই বের করা যায়। কৌশলটা Part VI-এর সেই পুরনো সেতু: \(\operatorname{tr}(W^2) = \sum_i \lambda_i^2\) (trace = eigenvalue-দের power-এর যোগফল)। তাহলে "eigenvalue-রা গড়ে কত বড়?" প্রশ্নটা হয়ে যায় "\(\operatorname{tr}(W^2)\) কত?" — আর trace তো স্রেফ entry-দের হিসাব, expectation নেওয়া পানির মতো সোজা। চলো করি।
ধরো আগে scaling ছাড়া matrix-টা \(H\) (entries variance \(1\))। তাহলে
Expectation নাও: প্রতিটা \(\mathbb{E}[h_{ij}^2] = 1\), আর term আছে \(n^2\)-টা:
অর্থাৎ scaling ছাড়া একটা "সাধারণ" eigenvalue-এর আকার \(\sqrt{n}\)-এর মতো বাড়তে থাকে — histogram প্রতিবার পালিয়ে যায়, কোনো সীমায় স্থির হয় না। এবার \(W = H/\sqrt{n}\) নিলে প্রতিটা eigenvalue \(\sqrt{n}\) ভাগ হয়, তাই
Eigenvalue-দের গড় বর্গ ঠিক \(1\)-এ স্থির — না বাড়ে, না মিলিয়ে যায়। এই একটা হিসাবই বলে দেয় \(\sqrt{n}\)-ই একমাত্র সঠিক জানালা: এর কমে ভাগ করলে ছবি ফেটে বেরিয়ে যায়, বেশিতে ভাগ করলে সব শূন্যে চুপসে যায়। (এই যুক্তিটাই Problem 2-এ তুমি নিজে গুছিয়ে লিখবে।)
Semicircle Law-এর statement¶
Wigner's Semicircle Law: উপরের শর্ত মানা Wigner matrix \(W\)-এর eigenvalue-দের histogram (আনুষ্ঠানিক নাম Empirical Spectral Distribution(এমপিরিক্যাল স্পেকট্রাল ডিস্ট্রিবিউশন)), \(n \to \infty\)-তে যায় একটা নির্দিষ্ট density-তে:
Graph-টা ব্যাসার্ধ-\(2\) অর্ধবৃত্তের মতো (উচ্চতা \(\pi\) দিয়ে ভাগ করা, যাতে মোট area \(1\) হয় — Worked Example 1-এ যাচাই করবে)। তিনটা কথা খেয়াল করো:
- প্রান্ত ধারালো: \(\pm 2\)-এর বাইরে (\(n\to\infty\)-তে) কোনো eigenvalue নেই। "এলোমেলো মানেই যেখানে-খুশি" — ধারণাটা এখানেই মরে যায়।
- Universal: entry-রা Gaussian, \(\pm 1\) coin flip, বা uniform — যা-ই হোক, একই অর্ধবৃত্ত। শুধু mean \(0\), variance \(1\) (আর moment-এর কিছু মৃদু শর্ত) লাগে।
- Deterministic সীমা: একেকটা random matrix-এর histogram একটা নির্দিষ্ট, অ-random রেখায় গিয়ে বসে — randomness বড় আকারে নিজেকেই বাতিল করে দেয়।
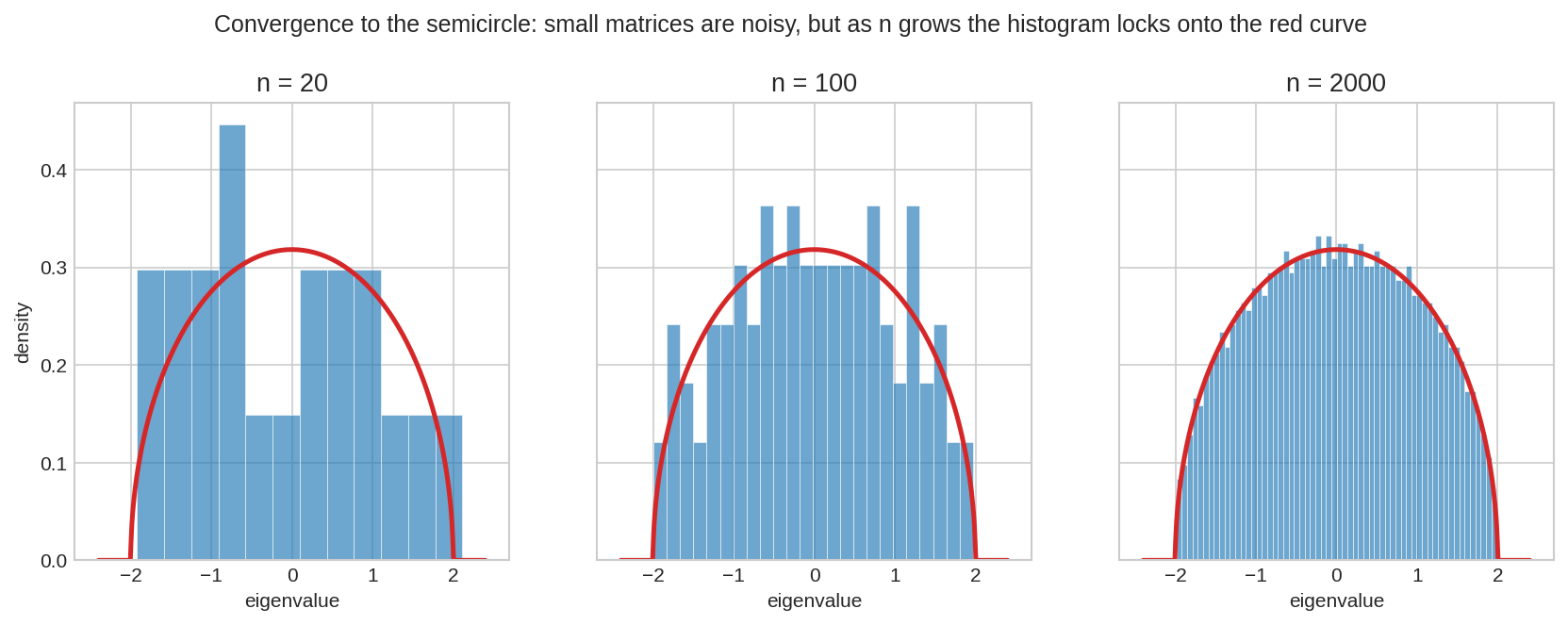
একই রেসিপি, তিনটা আকার: \(n = 20\)-এ histogram এবড়োখেবড়ো, \(n = 100\)-এ আকৃতি ফুটতে শুরু করেছে, আর \(n = 2000\)-এ লাল অর্ধবৃত্তের সাথে প্রায় মিশে গেছে। CLT-তে যেমন sample বাড়ালে ঘণ্টা-রেখা ফোটে, এখানে matrix বাড়ালে অর্ধবৃত্ত ফোটে।
২. দেখতে কেমন?¶
দৃশ্য ১: covariance-এর জগতে — Marchenko–Pastur¶
Semicircle সুন্দর, কিন্তু data science-এর আসল প্রশ্নটা একটু অন্য matrix নিয়ে। তোমার কাছে data matrix \(X\) আছে — \(n\)টা sample (row), \(p\)টা feature (column)। Chapter 6.7-এ শিখেছো: PCA দাঁড়িয়ে আছে sample covariance matrix-এর ওপর:
এখন ধরো data-টা pure noise: \(X\)-এর প্রতিটা entry iid, mean \(0\), variance \(1\)। তাহলে সত্যিকারের (population) covariance হলো identity — অর্থাৎ আসল eigenvalue সবগুলোই ঠিক \(1\)। প্রশ্ন: \(S\)-এর (sample!) eigenvalue-রাও কি \(1\)-এর কাছেই থাকবে?
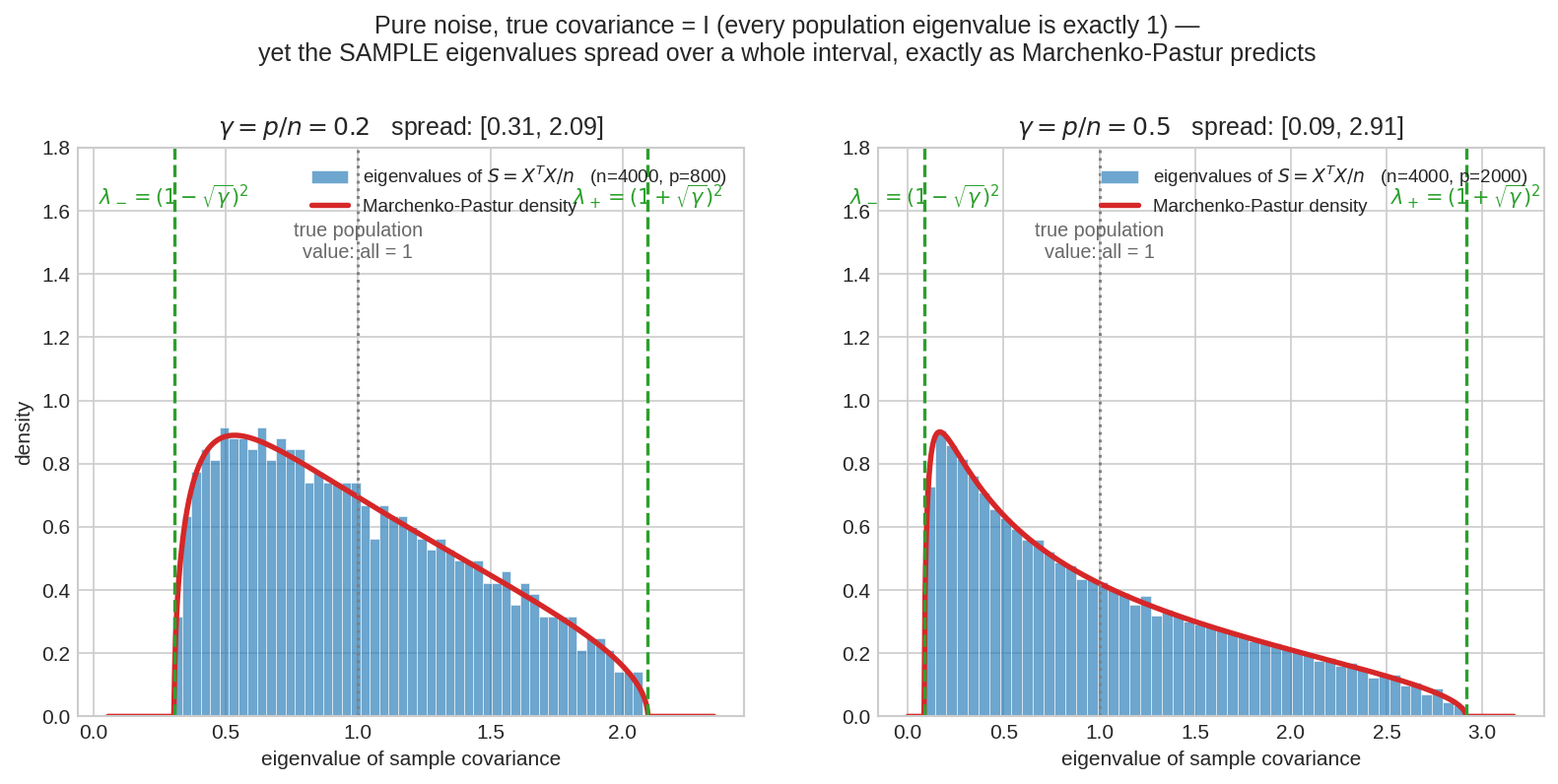
দুই panel-এই data সম্পূর্ণ noise, আসল উত্তর "সব eigenvalue \(= 1\)" (ধূসর ডটেড লাইন)। অথচ sample eigenvalue-রা ছড়িয়ে পড়েছে গোটা একটা interval-এ — বাঁয়ে \(\gamma = 0.2\)-তে \([0.31, 2.09]\), ডানে \(\gamma = 0.5\)-এ \([0.09, 2.91]\)। লাল রেখা Marchenko–Pastur density, সবুজ ড্যাশ তার প্রান্ত \(\lambda_\pm = (1 \pm \sqrt{\gamma})^2\) — theory আর simulation হুবহু মিলে গেছে।
Marchenko–Pastur Law: \(n, p \to \infty\) কিন্তু অনুপাত \(p/n \to \gamma \in (0, 1]\) স্থির থাকলে, \(S\)-এর eigenvalue histogram যায়
density-তে (\(\lambda_- \le \lambda \le \lambda_+\)-এ; বাইরে শূন্য)। মানে: population-এ এক বিন্দুতে জমাট ভর (\(1\)-এ), sample-এ সেটা গলে ছড়িয়ে পড়া একটা স্তূপ।
দৃশ্য ২: \(\gamma\) ঘোরালে কী হয় — এক নব, তিন জগৎ¶
\(\gamma = p/n\) হলো "feature বনাম sample"-এর অনুপাত — RMT-র সবচেয়ে গুরুত্বপূর্ণ নব:
| \(\gamma\) | প্রান্ত \([\lambda_-, \lambda_+]\) | মানে |
|---|---|---|
| \(\gamma \to 0\) (\(p \ll n\)) | \([1, 1]\)-এ চুপসে যায় | Sample covariance \(\approx\) population — classical statistics-এর স্বর্গ |
| \(\gamma = 0.25\) | \([0.25, 2.25]\) | Eigenvalue-রা \(9\) গুণ পর্যন্ত ফারাকে — বিশ্বাসযোগ্যতা কমছে |
| \(\gamma = 1\) (\(p = n\)) | \([0, 4]\) | চরম বিস্তার; শূন্যের গা-ঘেঁষা eigenvalue-ও আছে |
| \(\gamma > 1\) (\(p > n\)) | ওপরের bulk + \(0\)-তে জমাট ভর | \(X^TX/n\)-এর rank \(\le n < p\) (Part IV!) — অন্তত \(p - n\)টা eigenvalue ঠিক \(0\) |
শেষ সারিটা Part IV-এর rank-এর সরাসরি উত্তরাধিকার: \(p \times p\) matrix \(S = X^TX/n\)-এর rank কখনোই \(n\)-এর বেশি না, তাই \(p > n\) হলে অন্তত \(p - n\)টা eigenvalue বাধ্যতামূলকভাবে শূন্য — ভগ্নাংশে \(1 - 1/\gamma\) (Problem 4)। "feature বেশি, sample কম" জগতে covariance matrix জন্ম থেকেই singular — modern genomics/finance-এর নিত্যদিনের মাথাব্যথা।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- নিউক্লিয়ার physics (জন্মস্থান): ভারী নিউক্লিয়াসের energy level-এর ফাঁকগুলোর পরিসংখ্যান random matrix-এর eigenvalue-ফাঁকের সাথে মিলে যায় — Wigner-এর মূল আবিষ্কার।
- Wireless/MIMO communication: \(p\)টা transmit ও \(n\)টা receive antenna-র channel matrix কার্যত random; কতটা তথ্য পাঠানো যাবে (capacity) সেই হিসাব সরাসরি Marchenko–Pastur integral — তোমার ফোনের 5G-র নকশায় RMT বসে আছে।
- Number theory-র রহস্য: Riemann zeta function-এর zero-দের ফাঁকের পরিসংখ্যানও random matrix-এর সাথে মেলে — গণিতের সবচেয়ে বিখ্যাত অমীমাংসিত সমস্যার সাথে RMT-র গোপন যোগাযোগ।
Data Science / ML-এ:
- Covariance denoising (finance): \(500\)টা stock, \(2\) বছরের daily return (\(n \approx 500\)) — \(\gamma \approx 1\)! Sample covariance-এর বেশিরভাগ eigenvalue তখন MP-bulk-এর noise। Portfolio বানানোর আগে bulk-এর ভেতরের eigenvalue-দের ছেঁটে (shrink করে) নেওয়া এখন quant finance-এর standard পদ্ধতি।
- "PCA-তে কয়টা component রাখবো?" — চিরন্তন প্রশ্নের RMT-উত্তর: MP upper edge \(\lambda_+\)-এর ওপরে যে-কয়টা eigenvalue, সে-কয়টা । Scree plot-এর "elbow খোঁজা"-র চেয়ে অনেক নীতিনিষ্ঠ নিয়ম (§৫-এ পুরো গল্প)।
- Deep learning-এর গবেষণা: neural network-এর weight matrix আর Hessian-এর eigenvalue spectrum-কে MP-র সাথে তুলনা করে গবেষকরা মাপেন network কতটা "শিখেছে" — training-এর আগে spectrum প্রায় pure MP, training-এর পরে bulk থেকে spike বেরিয়ে আসে (ঠিক আমাদের fig05-এর ছবি!)।
- Random features ও sketching: Chapter 8.4-এ দেখেছো বিশাল matrix-কে random projection দিয়ে ছোট করা যায় — সেই কৌশল কতটা তথ্য বাঁচায়/হারায়, তার সূক্ষ্ম হিসাব MP-র মতো spectral law দিয়েই হয়।
- Signal detection: radar, EEG, genomics — সবখানে একই প্রশ্ন: "এই বড় eigenvalue-টা কি সত্যি, নাকি noise?" উত্তরের যন্ত্রটাই এই chapter।
৪. Properties¶
Property 1 — Semicircle: মোট ভর \(1\), mean \(0\), variance \(1\)¶
প্রথমটা Worked Example 1-এ হাতে হাতে integrate করবো; দ্বিতীয়টা ফ্রি (density টা \(x = 0\)-এর সাপেক্ষে symmetric, তাই odd moment সব শূন্য); তৃতীয়টা Worked Example 2 — আর সেটা মিলে যায় §১-এর trace-হিসাব \(\frac{1}{n}\mathbb{E}[\operatorname{tr}(W^2)] = 1\)-এর সাথে। Theory নিজের সাথে নিজে consistent — সবসময় এই চেকগুলো করো।
Property 2 — Semicircle-এর even moment-রা Catalan number¶
\(C_0 = 1\) (মোট ভর), \(C_1 = 1\) (variance), \(C_2 = 2\) (fourth moment) — এই সংখ্যাগুলোই semicircle-এর fingerprint, আর §৫-এর প্রমাণ-গল্পের নায়ক। তুলনার জন্য: Gaussian-এর fourth moment \(3\), semicircle-এর \(2\) — অর্ধবৃত্তের "লেজ" নেই বলে সে ঘণ্টা-রেখার চেয়ে চাপা।
Property 3 — MP edges-এর sanity check¶
\(\lambda_\pm = (1 \pm \sqrt{\gamma})^2\) সূত্রটা মুখস্থের আগে যাচাই করো:
- \(\gamma \to 0\): \(\lambda_\pm \to (1 \pm 0)^2 = 1\) — দুই প্রান্ত মিলে যায় \(1\)-এ, ছড়ানো উধাও। কম feature, অঢেল sample = classical জগৎ ✓
- \(\gamma = 1\): \(\lambda_- = 0\), \(\lambda_+ = 4\) — bulk ছোঁয় শূন্যকে, আর সবচেয়ে বড় noise-eigenvalue আসল মানের চার গুণ! এই কেসে density-টা সুন্দর হয়ে যায়: \(\rho(\lambda) = \frac{1}{2\pi\lambda}\sqrt{\lambda(4-\lambda)} = \frac{1}{2\pi}\sqrt{\frac{4-\lambda}{\lambda}}\), আর substitution \(\lambda = x^2\) করলে singular value-দের (\(x = \sqrt{\lambda}\)) density হয় \(\frac{1}{\pi}\sqrt{4 - x^2}\) on \([0,2]\) — quarter-circle law, semicircle-এরই অর্ধেক ভাঁজ! দুই আইন আসলে এক পরিবারের।
- প্রস্থ: \(\lambda_+ - \lambda_- = 4\sqrt{\gamma}\) — ছড়ানোর পরিমাণ \(\sqrt{\gamma}\)-র সমানুপাতিক। \(\gamma\) চার ভাগ কমাও, বিস্তার অর্ধেক।
Property 4 — সবচেয়ে বড় eigenvalue প্রান্তে লেগে থাকে¶
শুধু histogram নয়, একক eigenvalue-ও আইন মানে: Wigner-এর \(\lambda_{\max} \to 2\), আর MP-তে \(\lambda_{\max} \to \lambda_+\) (প্রায় নিশ্চিতভাবে)। প্রান্তের চারপাশের ওঠানামাটাও বিখ্যাত (Tracy–Widom distribution — নামটুকুই থাক, গল্প graduate-এ)। কাজের কথা: finite \(n\)-এ \(\lambda_+\)-এর সামান্য ওপরে eigenvalue দেখা যেতেই পারে — তাই বাস্তব cutoff নেওয়া হয় \(\lambda_+\)-এর একটু ওপরে।
Property 5 — Universality: বিস্তারিত ভুলে যাও¶
Semicircle আর MP — দুটোই entry-র distribution-এর খুঁটিনাটির ওপর নির্ভর করে না; লাগে শুধু iid, mean \(0\), নির্দিষ্ট variance। এই জন্যই আইন দুটো এত ব্যবহারযোগ্য: তোমার data-র noise ঠিক Gaussian না হলেও (বাস্তবে কখনোই হয় না) MP edge দিব্যি কাজ করে। CLT-র সাথে মিলটা আবারো: গড়ের ঘণ্টা-রেখাও individual distribution ভুলে যায়।
৫. Intuition — কেন সত্য?¶
Moment method: histogram-কে ধরা হয় তার moment দিয়ে¶
Proof-এর গল্প: একটা distribution-কে চেনার এক উপায় তার সব moment (\(\int x^k \rho\,dx\)) মিলিয়ে দেখা — দুই distribution-এর সব moment এক (আর moment-রা বেশি দ্রুত না বাড়লে) হলে distribution-ও এক। আমাদের হাতে eigenvalue-দের moment মাপার নিখুঁত যন্ত্র আগে থেকেই আছে — Part VI-এর trace-সেতু:
তাহলে প্ল্যান তিন ধাপের: (ক) \(\frac{1}{n}\mathbb{E}[\operatorname{tr}(W^{2k})]\)-কে entry-দের ভাষায় খুলে হিসাব করো; (খ) দেখাও উত্তরটা Catalan number \(C_k\); (গ) semicircle-এর moment-ও \(C_k\) (Property 2) — অতএব eigenvalue-histogram আর semicircle-এর সব moment এক, distribution-ও এক ∎। Odd moment দুই পক্ষেই শূন্য (sign-symmetry), তাই even-গুলোই যথেষ্ট। এবার ধাপ (ক)-(খ)-র ভেতরের যন্ত্রটা দেখি — সেখানে অপেক্ষা করছে chapter-এর সবচেয়ে সুন্দর ছবিটা: algebra হয়ে যায় পথ-গোনা।
Trace-এর power খুললে (Part III-এর matrix-গুণের সংজ্ঞা):
প্রতিটা term-কে ছবি হিসেবে পড়ো: \(i_1 \to i_2 \to \cdots \to i_{2k} \to i_1\) — matrix-এর index-দের গ্রাফে \(2k\) ধাপের একটা বন্ধ পথ (closed walk)। এখন দুটো পর্যবেক্ষণ সব ঠিক করে দেয়:
- একলা edge মরে যায়: entry-রা independent, mean \(0\)। পথের কোনো edge \(\{i, j\}\) যদি ঠিক একবার ব্যবহৃত হয়, expectation-এ সেই \(\mathbb{E}[w_{ij}] = 0\) factor হয়ে গোটা term-টা শূন্য। বাঁচতে হলে প্রতিটা edge কমপক্ষে দুবার হাঁটতে হবে।
- হিসাবের বাজেট: \(2k\) ধাপে প্রতিটা edge \(\ge 2\) বার মানে distinct edge \(\le k\)টা, ঘোরা যায় \(\le k+1\)টা vertex। \(n\) বিশাল হলে সবচেয়ে বেশি সংখ্যক vertex-পছন্দওয়ালা পথই গণনায় জেতে (\(n^{k+1}\)টা উপায় বনাম বাকিদের \(n^k\) বা কম) — আর \(1/\sqrt{n}^{2k} \cdot \frac1n = n^{-(k+1)}\) scaling ঠিক এদেরই টিকিয়ে রাখে। এই বিজয়ী পথগুলো হলো: প্রতিটা edge ঠিক দুবার, আর পথটা কোনো লুপ বানায় না — মানে পথটা একটা গাছ (tree) বেয়ে ওঠা-নামা।
তাহলে সীমায় বেঁচে থাকে শুধু "জোড়-মেলানো, গাছ-আকৃতির" পথ — আর এমন পথের সংখ্যাই হলো বিখ্যাত Catalan number \(C_k\) (উঁচু-নিচু ধাপের balanced sequence গোনার সেই সংখ্যা — bracket মেলানো, পাহাড়-পথ, binary tree — combinatorics-এর সর্বত্র সে হাজির)। ফলাফল:
Randomness থেকে জ্যামিতি আসার আসল রহস্যটা তাহলে combinatorics: অগণিত random term-এর ভিড়ে expectation survive করে শুধু কাঠামোওয়ালা (জোড়-মেলানো) term-রা, আর তাদের গোনাগুনতি-ই অর্ধবৃত্তের সমীকরণ লিখে দেয়।
\(k = 1\): পূর্ণ প্রমাণ, চার লাইনে¶
\(C_1 = 1\) দাবি। সরাসরি:
(এটাই §১-এর scaling-হিসাব, এখন moment-চশমায়: \(2\)-ধাপের বন্ধ পথ মানেই একটা edge-এ গিয়ে ফিরে আসা — জোড়-মেলানো ছাড়া উপায়ই নেই, তাই সবাই বাঁচে, উত্তর \(1\)।)
\(k = 2\): sketch — কেন ঠিক \(2\)¶
\(4\)-ধাপের বন্ধ পথ, প্রতি edge দুবার, tree-আকৃতি — কয় রকম? ছবি আঁকো: (i) \(i \to j \to i \to k \to i\) — কেন্দ্র \(i\) থেকে দুটো আলাদা ডাল \(j\) আর \(k\)-তে ঢুঁ মারা; (ii) \(i \to j \to k \to j \to i\) — এক ডাল বেয়ে দুই ধাপ গভীরে গিয়ে ফেরা। ব্যস, এই দুটোই (\(i \to j \to i \to j \to i\)-ও আছে, কিন্তু তার vertex মোটে ২টা — \(n^2 \ll n^3\), সীমায় হারিয়ে যায়)। প্রতিটার vertex-পছন্দ \(\sim n^3\), scaling \(n^{-3}\) — প্রত্যেকে দেয় ঠিক \(1\)। যোগফল \(\boxed{2} = C_2\) ✓ — semicircle-এর fourth moment-ও \(2\) (Problem 3-এ integrate করে মেলাবে)। বাকি সব \(k\)-র জন্য একই নাট্য — শুধু tree-গোনা বড় হয়, আর সেই গোনার সাধারণ উত্তরই \(C_k\); পূর্ণ বিবরণ graduate probability-র বইয়ে (roadmap: Catalan recursion \(C_{k+1} = \sum C_j C_{k-j}\) ↔ গাছের প্রথম ডাল কোথায় ফেরে সেই ভাগ)।
MP কেন আলাদা আকৃতি?¶
\(S = X^TX/n\)-এ randomness ঢোকে বর্গ করা আকারে — \(X\)-এর মাধ্যমে, দুই স্তর গুণ হয়ে। তাই পথ-গোনার নাটকটা এখানে চলে দুই ধরনের vertex-এর (sample-index আর feature-index) bipartite মঞ্চে, আর গোনা যায় ভিন্ন — উত্তর আসে \(\gamma\)-নির্ভর এক পরিবারে: Marchenko–Pastur। কিন্তু \(\gamma = 1\)-এ quarter-circle-এর সাথে semicircle-এর মিল (Property 3) মনে করিয়ে দেয়: দুই আইন একই moment-method গাছের দুই ডাল।
PCA-র ফাঁদ — ছবিতে¶
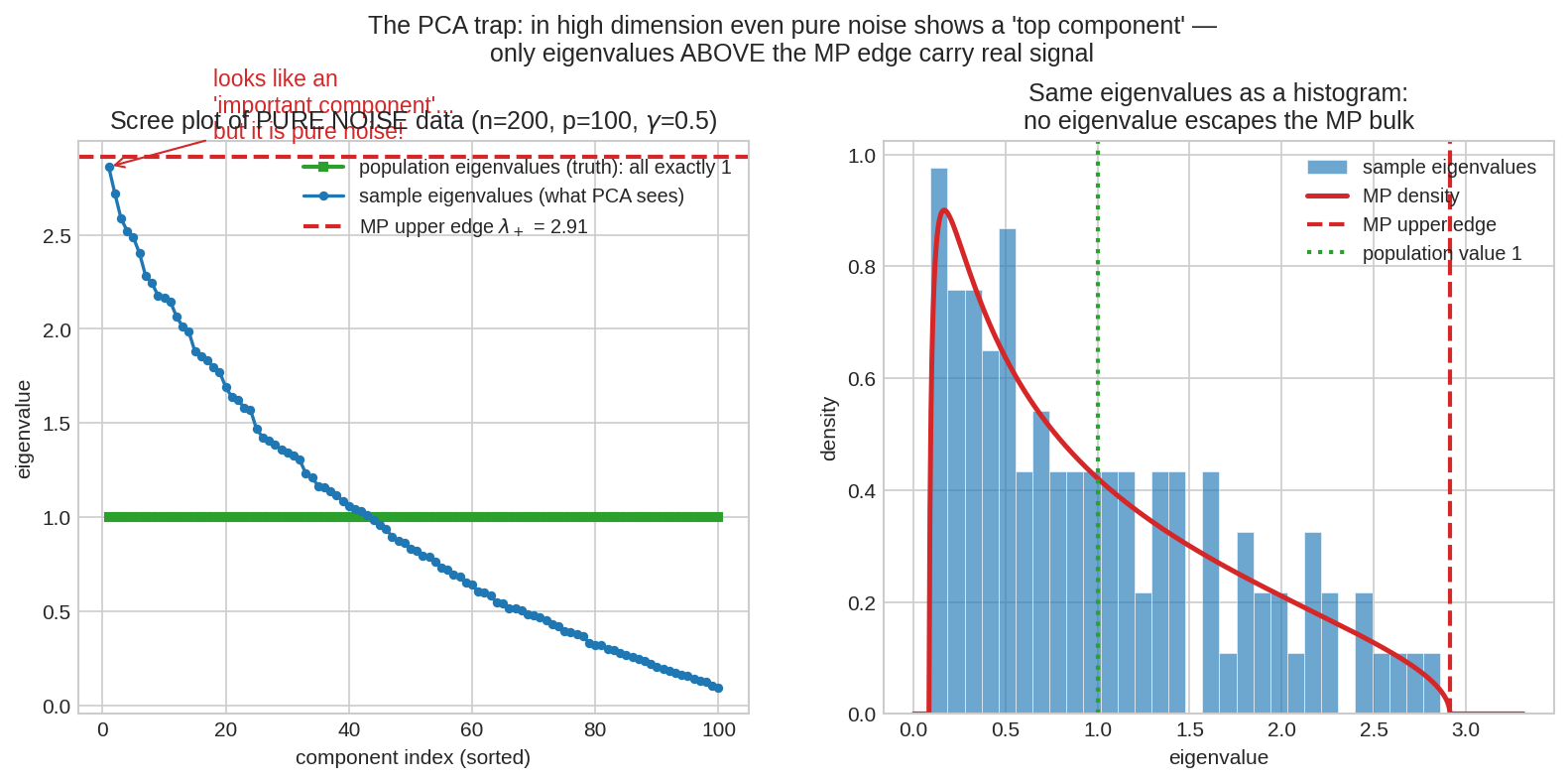
বাঁয়ে pure noise-এর (\(n=200\), \(p=100\)) scree plot: আসল population eigenvalue সব ঠিক \(1\) (সবুজ), অথচ sample eigenvalue-রা (নীল) \(2.9\) থেকে \(0.1\) পর্যন্ত ঢালু সিঁড়ি বানিয়েছে — উপরেরগুলো দেখতে হুবহু "গুরুত্বপূর্ণ component"-এর মতো! ডানে একই সংখ্যাগুলোর histogram: সবটাই MP-bulk-এর ভেতরে, লাল ড্যাশ (\(\lambda_+\)) কেউ পেরোয়নি। নিয়ম: যে eigenvalue MP edge পেরোয়নি, সে noise — যত লোভনীয়ই দেখাক।**
Scree plot-এ "প্রথম কয়েকটা eigenvalue বড়, তারপর ঢালু" দেখেই component রাখা — high dimension-এ এটা আত্মপ্রবঞ্চনা, কারণ noise নিজেই ওরকম ঢালু সিঁড়ি বানায় (MP density-র ডান লেজটাই সিঁড়ির উপরের ধাপ)। RMT-র denoising নিয়ম তাই এক লাইনের: \(\lambda_+ = (1+\sqrt{\gamma})^2\) হিসাব করো; এর ওপরের eigenvalue = সংকেত, ভেতরের সব = noise, ছেঁটে ফেলো বা shrink করো।
Spiked model ও BBP: সংকেত কখন ধরা দেয়?¶
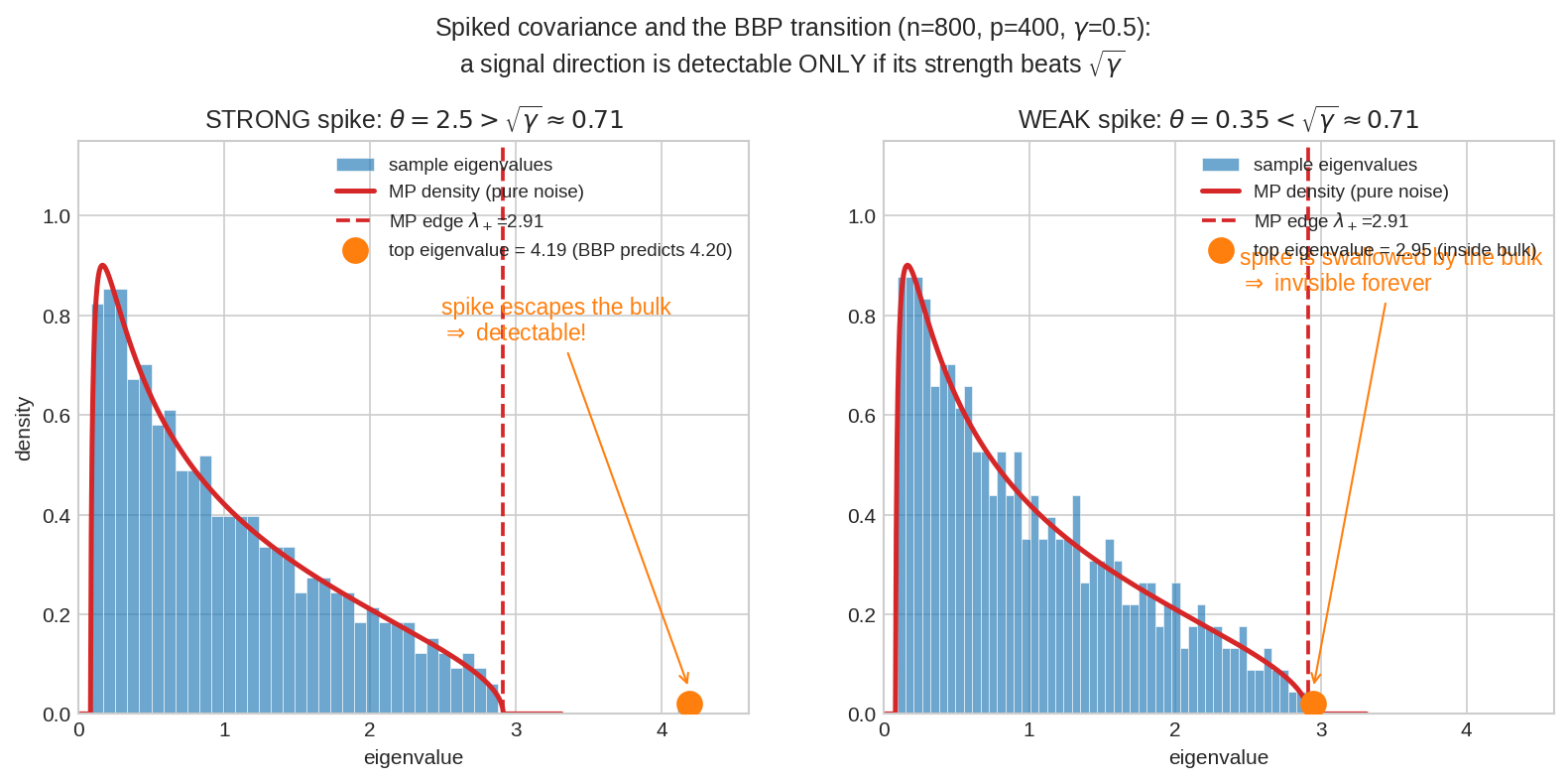
Population covariance-এ একটাই সত্যিকারের দিক জোরদার করা: \(\Sigma = I + \theta\,uu^T\)। বাঁয়ে \(\theta = 2.5\) (জোরালো সংকেত): শীর্ষ eigenvalue MP-bulk ছেড়ে বাইরে একা দাঁড়িয়ে — BBP-র ভবিষ্যদ্বাণী \((1+\theta)(1+\gamma/\theta) = 4.2\)-এর গা-ঘেঁষে। ডানে \(\theta = 0.35\) (দুর্বল): spike-টা bulk-এর পেটের ভেতরে হারিয়ে গেছে — histogram pure noise-এর থেকে আলাদা করার উপায়ই নেই।
ধরো noise-এর ভেতরে একটা আসল সংকেত-দিক আছে: population covariance \(\Sigma = I + \theta\,uu^T\) — কোনো এক দিক \(u\)-তে variance \(1 + \theta\), বাকি সব \(1\)। এটাই spiked covariance model। প্রশ্ন: sample-এ এই spike দেখা যাবে?
BBP transition (Baik–Ben Arous–Péché, 2005) উত্তর দেয় নাটকীয় ভাষায়:
দ্বিতীয় লাইনটা ভালো করে পড়ো — ওটা "কষ্ট করে খুঁজলে পাওয়া যাবে" বলছে না; বলছে দুর্বল spike-ওয়ালা data আর pure noise-এর spectrum সীমায় হুবহু এক। সংকেত \(\sqrt{\gamma}\)-র নিচে হলে যত ডেটাই ঘাঁটো (ঐ \(\gamma\) ধরে রেখে), eigenvalue দেখে noise থেকে আলাদা করা অসম্ভব — এটা তথ্যের মৌলিক সীমা, algorithm-এর দুর্বলতা নয়। পদার্থবিজ্ঞানের ভাষায় এ এক আসল phase transition(ফেজ ট্রানজিশন): \(\theta\)-নব ঘোরাতে ঘোরাতে \(\sqrt{\gamma}\) পার হওয়ামাত্র system-এর আচরণ হঠাৎ বদলে যায় — বরফ গলার মতো, মাঝামাঝি কিছু নেই। আর নীতিকথাটা মন খারাপ-করা রকমের বাস্তব: high dimension-এ (\(\gamma\) বড়) threshold-ও উঁচু — feature বাড়িয়ে sample না বাড়ালে দুর্বল সংকেতেরা একে একে অদৃশ্য হয়ে যায়।
৬. Code-এ কেমনে লিখে¶
import numpy as np
rng = np.random.default_rng(42)
# ---------- ১. Wigner matrix + semicircle ----------
n = 2000
G = rng.standard_normal((n, n))
W = (G + G.T) / np.sqrt(2) # symmetric, entry variance 1
W /= np.sqrt(n) # সেই জাদুর scaling
eigs = np.linalg.eigvalsh(W) # symmetric-এর জন্য eigvalsh: দ্রুত + সব real
print("eigenvalue range:", eigs.min(), eigs.max())
# ~ -2.0 থেকে ~ +2.0 ← semicircle-এর প্রান্ত!
print("mean of λ²:", np.mean(eigs**2)) # ≈ 1.0 ← trace-হিসাবের যাচাই
# semicircle density-র সাথে histogram-এর তুলনা (সংখ্যায়)
hist, edges = np.histogram(eigs, bins=40, range=(-2, 2), density=True)
mid = (edges[:-1] + edges[1:]) / 2
rho = np.sqrt(4 - mid**2) / (2 * np.pi)
print("max |hist - semicircle|:", np.abs(hist - rho).max()) # ছোট (~0.01-0.02)
# ---------- ২. Marchenko–Pastur: pure noise-এর covariance ----------
def mp_edges(gamma):
return (1 - np.sqrt(gamma))**2, (1 + np.sqrt(gamma))**2
n_s, p = 4000, 2000 # gamma = 0.5
X = rng.standard_normal((n_s, p))
S = X.T @ X / n_s
lam = np.linalg.eigvalsh(S)
lm, lp = mp_edges(p / n_s)
print("MP edges (theory):", lm, lp) # 0.0858..., 2.9142...
print("sample min/max :", lam.min(), lam.max()) # প্রায় একই!
# ---------- ৩. Spiked covariance: সংকেত কখন ধরা পড়ে ----------
gamma = p / n_s
for theta in [2.5, 0.35]: # জোরালো বনাম দুর্বল spike
Z = rng.standard_normal((n_s, p))
Z[:, 0] *= np.sqrt(1 + theta) # শুধু প্রথম দিকের variance = 1+theta
top = np.linalg.eigvalsh(Z.T @ Z / n_s)[-1]
bbp = (1 + theta) * (1 + gamma / theta) if theta > np.sqrt(gamma) else lp
tag = "DETECTABLE" if top > lp * 1.02 else "hidden in bulk"
print(f"theta={theta}: top eig={top:.3f}, BBP predicts {bbp:.3f} -> {tag}")
Output ব্যাখ্যা:
- Wigner-এর eigenvalue-রা সত্যিই \([-2, 2]\)-এর ভেতরে, আর \(\overline{\lambda^2} \approx 1\) — §১-এর trace-হিসাব যন্ত্রে যাচাই হলো। Histogram আর semicircle-এর ফারাক \(n=2000\)-এই সেন্টিমিটার-মাপের।
eigvalsh(h = Hermitian) ব্যবহার করো symmetric matrix-এ — সাধারণeig-এর চেয়ে কয়েকগুণ দ্রুত, আর উত্তর গ্যারান্টিড real ও sorted। \(n=2000\)-এও কয়েক সেকেন্ড।- MP-র প্রান্ত theory বলেছিল \([0.0858, 2.914]\) — simulation দিলো প্রায় হুবহু। কোনো fitting নেই — সূত্রে \(\gamma\) বসাও, প্রকৃতি মেনে চলে।
- Spike experiment-এ \(\theta = 2.5 > \sqrt{0.5} \approx 0.707\): top eigenvalue \(\approx 4.2\), MP edge \(2.91\)-এর অনেক বাইরে — DETECTABLE। আর \(\theta = 0.35 < 0.707\): top eigenvalue bulk-এর ঠোঁটে (\(\approx 2.9\)) — pure noise থেকে অবিচ্ছেদ্য। BBP-র রায় কোডে হাতেনাতে।
৭. Worked Examples¶
Example 1 — Semicircle-এর মোট ভর \(1\): integrate করে দেখা¶
দাবি: \(\displaystyle\int_{-2}^{2} \frac{1}{2\pi}\sqrt{4 - x^2}\,dx = 1\)।
ধাপ ১ — substitution বাছাই: \(\sqrt{4 - x^2}\) দেখলেই trig-substitution: \(x = 2\sin t\), তাহলে \(dx = 2\cos t\,dt\), আর সীমা: \(x=-2 \Rightarrow t = -\pi/2\), \(x = 2 \Rightarrow t = \pi/2\)।
ধাপ ২ — root সরল করা: \(\sqrt{4 - 4\sin^2 t} = 2\sqrt{1 - \sin^2 t} = 2\cos t\) (এই range-এ \(\cos t \ge 0\), তাই absolute value-এর ঝামেলা নেই)।
ধাপ ৩ — বসিয়ে দাও:
ধাপ ৪ — half-angle: \(\cos^2 t = \frac{1 + \cos 2t}{2}\):
ধাপ ৫ — তাহলে \(\int \rho = \frac{1}{2\pi} \cdot 2\pi = 1\) ✓। (জ্যামিতিক শর্টকাট-চেক: ব্যাসার্ধ-\(2\) অর্ধবৃত্তের area \(= \frac{1}{2}\pi \cdot 2^2 = 2\pi\) — একই উত্তর। তাই তো \(2\pi\) দিয়েই ভাগ!)
Example 2 — Semicircle-এর variance \(= 1\) (এবং \(= C_1\))¶
দাবি: \(\displaystyle m_2 = \int_{-2}^{2} x^2\,\frac{\sqrt{4-x^2}}{2\pi}\,dx = 1\)।
ধাপ ১ — একই substitution \(x = 2\sin t\): \(x^2 = 4\sin^2 t\), বাকি অংশ Example 1 থেকেই জানা (\(\sqrt{\cdot}\,dx = 4\cos^2 t\,dt\)):
ধাপ ২ — double angle দুইবার: \(\sin t\cos t = \frac{\sin 2t}{2}\), তাই \(\sin^2 t \cos^2 t = \frac{\sin^2 2t}{4} = \frac{1 - \cos 4t}{8}\):
অর্থ: semicircle-এর variance \(1\) — ঠিক যা \(\frac1n\mathbb{E}[\operatorname{tr}(W^2)] \to 1\) (আমাদের scaling-হিসাব) দাবি করেছিল, আর moment-ভাষায় \(m_2 = C_1 = 1\) ✓। তিনটা সম্পূর্ণ আলাদা রাস্তা — integral, trace, পথ-গোনা — একই সংখ্যায় মিললো। গণিত যখন সুস্থ থাকে, এমনই হয়।
Example 3 — MP edge হাতে-কলমে: \(n = 100\), \(p = 50\), আর একটা সন্দেহভাজন eigenvalue¶
পরিস্থিতি: তোমার data-তে \(n = 100\)টা sample, \(p = 50\)টা feature। Sample covariance-এর সবচেয়ে বড় eigenvalue এলো \(2.9\)। এটা কি আসল component?
ধাপ ১ — \(\gamma\): \(\gamma = p/n = 50/100 = 0.5\)।
ধাপ ২ — MP edges: \(\sqrt{\gamma} = \sqrt{0.5} \approx 0.7071\):
অর্থাৎ pure noise-ই eigenvalue ছড়াবে প্রায় \([0.09,\ 2.91]\) জুড়ে।
ধাপ ৩ — রায়: \(2.9 < 2.914 = \lambda_+\) — সন্দেহভাজন eigenvalue-টা MP bulk-এর ভেতরেই। এমন মান pure noise থেকেই দিব্যি আসে; একে "প্রধান component" বলে কিছু বানানো যাবে না। (উল্টোদিকে \(3.8\) পেলে? \(\lambda_+\)-এর স্পষ্ট ওপরে — সংকেত হিসেবে নেওয়া যেত, আর BBP-সূত্র উল্টে চালিয়ে \(\theta\)-ও আন্দাজ করা যেত।) খেয়াল করো \(n = 100\) মোটেও ছোট sample না — কিন্তু \(\gamma = 0.5\) হওয়াতেই noise এত বিস্তৃত। Sample-সংখ্যা না, অনুপাতটাই আসল।
৮. Problems ও Solutions¶
Problem 1. \(\gamma = 1/4\)-এর জন্য Marchenko–Pastur-এর দুই প্রান্ত \(\lambda_\pm\) বের করো। তারপর বলো: \(n = 400\) sample, \(p = 100\) feature-এর pure-noise data-য় sample covariance-এর eigenvalue-রা মোটামুটি কোন range-এ থাকবে, আর \(2.5\)-এর একটা eigenvalue পেলে সিদ্ধান্ত কী হবে?
Solution
\(\sqrt{\gamma} = 1/2\), তাই
\(p/n = 100/400 = 1/4 = \gamma\) ✓ — তাই noise-eigenvalue-রা থাকবে প্রায় \([0.25,\ 2.25]\)-এ।
\(2.5 > 2.25 = \lambda_+\) — eigenvalue-টা bulk-এর বাইরে, অতএব একে সত্যিকারের সংকেত (আসল component) হিসেবে নেওয়া যায়। প্রান্তের খুব গা-ঘেঁষা হলে (যেমন \(2.3\)) সাবধানি হওয়া ভালো — finite \(n\)-এ প্রান্ত সামান্য ঝাপসা (Property 4)।
Problem 2. প্রমাণ করো: \(W\) Wigner matrix হলে (entries variance \(1\), scaling \(1/\sqrt n\)) \(\;\frac{1}{n}\mathbb{E}[\operatorname{tr}(W^2)] = 1\) — প্রতিটা ধাপের যুক্তিসহ। তারপর এক বাক্যে বলো এটা কেন প্রমাণ করে যে \(1/\sqrt{n}\)-ই "সঠিক" scaling।
Solution
\(W = H/\sqrt n\) লিখি, যেখানে \(h_{ij}\)-রা mean \(0\), variance \(1\), আর \(h_{ji} = h_{ij}\)। Matrix-গুণের সংজ্ঞা থেকে
(শেষ ধাপে symmetry: \(h_{ji} = h_{ij}\))। Expectation linear, আর \(\mathbb{E}[h_{ij}^2] = 1\) প্রতিটার জন্য; term মোট \(n^2\)টা:
এক বাক্যে: যেহেতু \(\operatorname{tr}(W^2) = \sum\lambda_i^2\), এই ফলাফল বলে eigenvalue-দের গড় বর্গ \(n\)-নিরপেক্ষভাবে \(1\)-এ স্থির — \(\sqrt{n}\)-এর চেয়ে কম ভাগে এই গড় \(\infty\)-তে উড়ে যেত, বেশি ভাগে \(0\)-তে চুপসে যেত; কেবল \(1/\sqrt n\)-ই histogram-কে একটা nontrivial সীমায় দাঁড় করায়।
Problem 3. Semicircle density-র fourth moment \(\displaystyle m_4 = \int_{-2}^{2}x^4\,\frac{\sqrt{4-x^2}}{2\pi}\,dx\) হিসাব করে দেখাও \(m_4 = 2 = C_2\)। (Hint: \(x = 2\sin t\), তারপর \(\sin^4 t\cos^2 t\)-কে power-reduction-এ ভাঙো; Example 2-এর ফলাফল পুনর্ব্যবহারও চলে।)
Solution
\(x = 2\sin t\): \(x^4 = 16\sin^4 t\), আর \(\sqrt{4-x^2}\,dx = 4\cos^2 t\,dt\) (Example 1)। তাহলে
লিখি \(\sin^4 t\cos^2 t = \sin^2 t\,(\sin^2 t \cos^2 t) = \sin^2 t\cdot\frac{\sin^2 2t}{4}\)। আবার \(\sin^2 t = \frac{1-\cos 2t}{2}\), তাই
দ্বিতীয় term-টা odd ঘূর্ণির integral: \(\int_{-\pi/2}^{\pi/2}\cos 2t\sin^2 2t\,dt = \left[\frac{\sin^3 2t}{6}\right]_{-\pi/2}^{\pi/2} = 0\)। প্রথমটায় \(\sin^2 2t = \frac{1 - \cos 4t}{2}\):
অতএব \(m_4 = \frac{32}{\pi}\cdot\frac{\pi}{16} = 2 = C_2\) ✓ — moment method-এর পথ-গোনা (\(k=2\)-এর দুটো tree-পথ) আর এই integral একই উত্তরে মিললো।
Problem 4. \(\gamma = p/n > 1\) (feature > sample) হলে দেখাও sample covariance \(S = X^TX/n\)-এর eigenvalue-দের অন্তত \(1 - \frac{1}{\gamma}\) ভগ্নাংশ ঠিক শূন্য। (Hint: Part IV-এর rank-যুক্তি — \(\operatorname{rank}(X^TX) = \operatorname{rank}(X)\)।)
Solution
Part IV থেকে: \(\operatorname{rank}(X^TX) = \operatorname{rank}(X) \le \min(n, p) = n\) (যেহেতু \(p > n\))। \(S\) হলো \(p\times p\) symmetric matrix যার rank \(\le n\)।
Spectral theorem: symmetric matrix-এর rank = nonzero eigenvalue-র সংখ্যা। তাই nonzero eigenvalue \(\le n\)টা, অর্থাৎ শূন্য eigenvalue \(\ge p - n\)টা।
ভগ্নাংশে:
যেমন \(\gamma = 2\) (feature দ্বিগুণ) হলে অন্তত অর্ধেক eigenvalue ঠিক \(0\) — covariance matrix জন্মগতভাবে singular, inverse নেই, তাই এই জগতে regularization/shrinkage ছাড়া উপায় নেই। (MP theory-ও ঠিক এটাই বলে: \(\gamma > 1\)-এ density-তে \(0\) বিন্দুতে \(1 - 1/\gamma\) ভরের একটা জমাট অংশ বসে।)
Problem 5. Data-তে \(n = 900\), \(p = 400\)। Population covariance-এ একটা spike আছে: এক দিকের variance \(1 + \theta\), বাকি সব \(1\)। (a) Detectability threshold \(\sqrt{\gamma}\) কত? (b) \(\theta = 0.5\) আর \(\theta = 1.2\) — কোনটা ধরা পড়বে? (c) যেটা ধরা পড়বে তার sample-এ top eigenvalue প্রায় কত আসবে (BBP), আর MP edge কত?
Solution
(a) \(\gamma = 400/900 = 4/9\), তাই threshold \(\sqrt{\gamma} = 2/3 \approx 0.667\)।
(b) \(\theta = 0.5 < 2/3\) — bulk-এ ডুবে যাবে, ধরা পড়বে না (কোনো পদ্ধতিতেই না — eigenvalue দেখে)। \(\theta = 1.2 > 2/3\) — ধরা পড়বে।
(c) MP edge: \(\lambda_+ = (1 + 2/3)^2 = 25/9 \approx 2.78\)। BBP:
তাহলে top eigenvalue আসবে \(\approx 3.01\), যা \(2.78\)-এর স্পষ্ট ওপরে — আলাদা করে চেনা যাবে। (\(\theta = 0.5\) হলে top eigenvalue যেত \(\lambda_+ \approx 2.78\)-এই — pure noise-এর সমান, চেনার উপায় নেই।)
Problem 6. (Simulation) কোড লিখে যাচাই করো: \(n = 1000\)-এর একটা Wigner matrix-এর (i) সব eigenvalue \([-2.2, 2.2]\)-এর ভেতরে কিনা, (ii) eigenvalue-দের গড় বর্গ \(\approx 1\) কিনা, (iii) \(x^4\)-এর গড় (empirical fourth moment) \(\approx C_2 = 2\) কিনা।
Solution
import numpy as np
rng = np.random.default_rng(42)
n = 1000
G = rng.standard_normal((n, n))
W = (G + G.T) / np.sqrt(2) / np.sqrt(n)
lam = np.linalg.eigvalsh(W)
print("(i) min, max:", lam.min().round(3), lam.max().round(3))
print("(ii) mean λ² :", np.mean(lam**2).round(4))
print("(iii) mean λ⁴ :", np.mean(lam**4).round(4))
(i) min, max: -1.996 1.995 # সবাই [-2.2, 2.2]-এর ভেতরে ✓
(ii) mean λ² : 0.9995 # ≈ 1 = C₁ ✓ (trace-হিসাব)
(iii) mean λ⁴ : 1.9986 # ≈ 2 = C₂ ✓ (Catalan!)
Problem 7. এক সহকর্মী বললো: "আমার \(p = 200\) feature, \(n = 300\) sample-এর ডেটায় PCA করে প্রথম ৫টা eigenvalue পেলাম \(3.5,\ 3.1,\ 2.9,\ 2.6,\ 2.4\) — পাঁচটাই বেশ বড়, পাঁচটা component-ই রাখবো।" MP edge হিসাব করে তার scree-plot-পড়া শুধরে দাও।
Solution
\(\gamma = 200/300 = 2/3\), \(\sqrt{\gamma} \approx 0.8165\):
রায়: \(3.5 > 3.30\) — শুধু প্রথম eigenvalue-টাই MP edge-এর ওপরে; \(3.1, 2.9, 2.6, 2.4\) সবগুলোই noise-bulk-এর সীমার ভেতরে (\(\gamma = 2/3\)-এ pure noise-ই \(3.3\) পর্যন্ত eigenvalue ছড়ায়!)। "বেশ বড় দেখাচ্ছে" আর "সংকেত" এক কথা নয় — উঁচু \(\gamma\)-তে noise নিজেই বড় বড় eigenvalue বানায় (fig04-এর ফাঁদ)। সুপারিশ: ১টা component রাখো; বাকিগুলো রাখতে চাইলে eigenvalue-র বাইরের প্রমাণ লাগবে (যেমন cross-validation, বা domain knowledge)।
Problem 8. Semicircle law-এ entry-দের কোন কোন শর্ত লাগে — আর কোনগুলো লাগে না? নিচের প্রতিটা matrix-এর জন্য বলো তার eigenvalue histogram semicircle হবে কি না, না হলে কী হবে: (a) entries iid Gaussian কিন্তু matrix অ-symmetric; (b) entries iid \(\pm 1\) coin flip, symmetric, \(/\sqrt n\); (c) \(S = X^TX/n\) যেখানে \(X\)-এর entry iid Gaussian।
Solution
(a) Symmetric নয় — eigenvalue-রা real-ই থাকবে না, complex plane-এ ছড়াবে (সীমায় একটা ভরাট বৃত্তে — circular law; এ গল্প এই বইয়ের বাইরে)। Semicircle হবে না; semicircle-এর জন্য symmetry অপরিহার্য।
(b) হবে! Gaussian লাগে না — universality (Property 5): iid, mean \(0 = \mathbb{E}[\pm 1]\), variance \(1 = \mathbb{E}[(\pm1)^2]\) — সব শর্ত পূরণ। Coin flip-এর matrix আর Gaussian-এর matrix, সীমায় একই অর্ধবৃত্ত।
(c) এটা covariance-গড়নের matrix — eigenvalue সব \(\ge 0\) (positive semidefinite, Part VI), semicircle তো \([-2,2]\)-এ symmetric — মিলবেই না। সঠিক সীমা Marchenko–Pastur, \(\gamma = p/n\) অনুযায়ী। শিক্ষা: "random matrix মানেই semicircle" না — matrix-এর গড়ন ঠিক করে কোন আইন খাটবে।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "Sample covariance \(\approx\) population covariance — sample যথেষ্ট হলেই" | শর্তটা "sample যথেষ্ট" নয়, "feature-এর তুলনায় sample যথেষ্ট": \(\gamma = p/n \approx 0\) লাগবে। \(n = 10{,}000\)-ও যথেষ্ট নয় যদি \(p = 5{,}000\) হয় — তখন eigenvalue-রা \([0.09, 2.91]\)-এ ছড়াবে, আসল মান \(1\) হলেও। |
| "বড় eigenvalue মানেই signal/important component" | High dimension-এ pure noise-ই \(\lambda_+ = (1+\sqrt\gamma)^2\) পর্যন্ত eigenvalue বানায় (\(\gamma=1\)-এ \(4\) পর্যন্ত!)। MP edge-এর ওপরে না উঠলে বড়ত্বের কোনো দাম নেই — fig04-এর scree-plot ফাঁদ মনে রাখো। |
| "RMT একটা theoretical কৌতূহল — বাস্তবে লাগে না" | Finance-এর covariance denoising, PCA-র component বাছাই, 5G/MIMO-র capacity, deep learning-এর spectrum diagnostics — সবগুলোতে MP edge আর BBP আজ রোজকার যন্ত্র। বরং উল্টোটা সত্য: high-dim data-য় RMT না জানলে ভুল সিদ্ধান্ত প্রায় নিশ্চিত। |
| "যেকোনো random matrix-এর eigenvalue semicircle মানে" | Semicircle-এর দাবি: symmetric + iid + mean 0 + finite variance + \(1/\sqrt n\)। Covariance-গড়ন (\(X^TX/n\)) দিলে MP; symmetry ছাড়লে circular law; ভারী লেজের (infinite variance) entry দিলে অন্য জগৎ। আগে matrix-এর গড়ন চেনো, তারপর আইন। |
| "আরো data (n বাড়ানো) নিলেই PCA-র সমস্যা মিটে যাবে" | \(n\)-এর সাথে \(p\)-ও বাড়লে (আধুনিক data-র স্বভাব) \(\gamma\) স্থির থাকে — MP-র ছড়ানো আর BBP-র threshold একটুও নড়ে না। \(\theta < \sqrt\gamma\)-এর spike অনন্ত data-তেও অদৃশ্য: এটা তথ্যের সীমা, computation-এর নয়। মুক্তি একটাই: \(\gamma\) কমাও (feature বাছাই/কমাও, বা সত্যিই \(p\) স্থির রেখে \(n\) বাড়াও)। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Wigner matrix | symmetric, iid, mean \(0\), var \(1\), \(\times\frac{1}{\sqrt n}\) | "Hamiltonian জানি না? Random ধরো!" |
| Scaling-এর কারণ | \(\frac1n\mathbb{E}[\operatorname{tr}(W^2)] = 1\) | trace-সেতু: গড় \(\lambda^2\) স্থির রাখো |
| Semicircle law | \(\rho(x) = \frac{1}{2\pi}\sqrt{4-x^2}\) on \([-2,2]\) | বিশৃঙ্খলার ভেতরে নিখুঁত অর্ধবৃত্ত — matrix-জগতের CLT |
| প্রমাণের যন্ত্র | moment method: \(\frac1n\mathbb{E}[\operatorname{tr}(W^{2k})] \to C_k\) | পথ-গোনা → জোড়-মেলানো tree → Catalan |
| Marchenko–Pastur | \(\rho_{MP}(\lambda) = \frac{\sqrt{(\lambda_+-\lambda)(\lambda-\lambda_-)}}{2\pi\gamma\lambda}\), \(\lambda_\pm = (1\pm\sqrt\gamma)^2\) | population-এর এক বিন্দু, sample-এ গলে-যাওয়া স্তূপ |
| \(\gamma\)-র নব | \(\gamma\to0\): classical; \(\gamma\) বড়: বিপর্যয়; \(\gamma>1\): \(1-\frac1\gamma\) ভর \(0\)-তে | feature বনাম sample-এর অনুপাতই সব |
| PCA denoising | \(\lambda > \lambda_+\) = signal; নইলে noise | scree-plot-এর ঢালু সিঁড়ি noise-ও বানায় |
| BBP transition | spike \(1+\theta\) ধরা পড়ে iff \(\theta > \sqrt\gamma\); তখন \(\lambda \to (1+\theta)(1+\frac\gamma\theta)\) | দুর্বল সংকেত অনন্ত ডেটাতেও অদৃশ্য — phase transition |
| DS/ML | portfolio denoising, component count, NN spectra, MIMO | high-dim জগতে চোখের বদলে RMT-চশমা |
পরের chapter-এর সেতু: এই chapter-এ আমরা matrix-জগতের একেবারে সীমানায় পৌঁছে গেছি — \(n \to \infty\)-র বিশাল random matrix, আর সেখানে randomness নিজেই আইন হয়ে দাঁড়িয়েছে। কিন্তু এতদূর এসেও আমাদের সব data ছিলো দ্বিমাত্রিক টেবিল: row আর column। বাস্তবের data প্রায়ই তার চেয়ে মোটা — একটা রঙিন ছবি (উচ্চতা × প্রস্থ × রঙ), একটা ভিডিও (+ সময়), user × movie × সময়ের rating। দুই index-এ আর কুলোয় না — এবার মাত্রা বাড়াই: tensor। Matrix-এর কোন কোন অস্ত্র (rank, decomposition, SVD-র আত্মীয়রা) tensor-জগতে টিকে থাকে আর কোথায় সব নিয়ম ভেঙে পড়ে — Chapter 9.6-এ।
📓 Notebook Project¶
notebooks/part-09/ch05-project.ipynb — Wigner semicircle ও Marchenko–Pastur simulation: histogram vs theoretical density, আর MP edge দিয়ে spiked covariance-এ "আসল" PCA component আলাদা করা।