Chapter 3.3 — Matrix Multiplication = Composition of Functions (গুণ মানে পরপর চালানো)¶
🎯 এই chapter-এ যা শিখবে¶
- Matrix multiplication-এর "অদ্ভুত" row-column নিয়মটা কোথা থেকে আসে — মুখস্থ নয়, composition(সংযোজন) থেকে নিজে derive করবে
- \(BA\) মানে "আগে \(A\), পরে \(B\)" — ডান থেকে বাঁয়ে পড়ার রহস্য
- কেন \(AB \neq BA\) — ছবিসহ, হাতে-নাতে
- Shape rule: \((m\times n)(n \times p) = (m \times p)\) — কোন গুণ বৈধ, কোনটা নিষিদ্ধ
- Associativity \((AB)C = A(BC)\) কেন প্রমাণ ছাড়াই সুস্পষ্ট — যদি composition দিয়ে ভাবো
🖼️ এক ছবিতে মূল idea¶
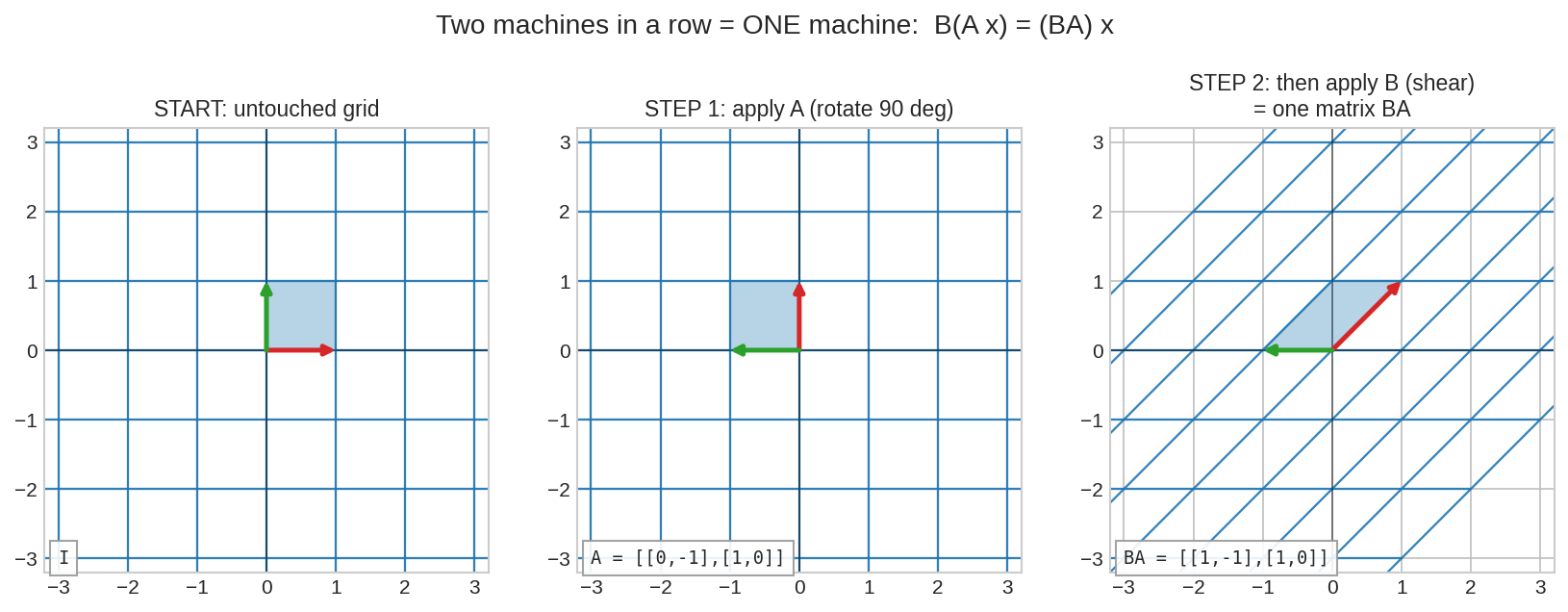
বাঁয়ে অক্ষত গ্রিড। মাঝে: matrix \(A\) (rotation) চালানো হলো। ডানে: তার ফলের ওপর matrix \(B\) (shear) চালানো হলো। মোট প্রভাবটা এক লাফেই পাওয়া যায় একটামাত্র matrix দিয়ে — তার নাম \(BA\)। Matrix multiplication এই "মোট প্রভাব" হিসাব করার মেশিন।
১. কি? (What)¶
স্কুল-কলেজে matrix multiplication শেখানো হয় একটা রহস্যময় হাতের কসরত হিসেবে: "row ধরো, column ধরো, গুণ করে যোগ করো..." — কেউ বলে না কেন। আজ সেই দেনা শোধ হবে।
দৈনন্দিন analogy: তোমার ফোনে দুটো ছবি-filter আছে: filter \(A\) = "৯০° ঘোরাও", filter \(B\) = "হেলিয়ে দাও (shear)"। তুমি পরপর দুটোই লাগালে: আগে \(A\), তারপর \(B\)। এখন প্রশ্ন — এই দুই-ধাপ কম্বোটা কি একটা একক filter হিসেবে বিক্রি করা যায়? অবশ্যই! প্রতিটা pixel কোথা থেকে কোথায় যায় তার সামগ্রিক নিয়ম তো একটাই। সেই কম্বো-filter-এর নামই product matrix \(BA\)।
সংজ্ঞা: \(A\) ও \(B\) দুটো transformation হলে তাদের composition হলো "আগে \(A\), তারপর \(B\)" — ফাংশনের ভাষায় \(\mathbf{x} \mapsto B(A\mathbf{x})\)। Matrix multiplication is composition of functions (Guest বই এই বাক্যটা অধ্যায়ের নামই করে দিয়েছে): \(BA\) হলো সেই একক matrix যে এক লাফে composition-এর কাজটা করে:
ডান থেকে বাঁয়ে পড়ো! \(BA\) মানে আগে \(A\) (ডানেরটা), পরে \(B\) (বাঁয়েরটা)। অদ্ভুত লাগছে? ফাংশনের দিকে তাকাও: \(f(g(x))\)-এও \(g\) আগে কাজ করে, যদিও লেখা হয় ডানে — কারণ input \(\mathbf{x}\) ঢোকে ডান দিক থেকে, আর যার গা ঘেঁষে ঢোকে তার কাজই আগে। Matrix-রা ফাংশনেরই এই অভ্যাস উত্তরাধিকারে পেয়েছে।
২. দেখতে কেমন?¶
২.১ Composition-এর তিন-ধাপ ছবি¶
উপরের opening figure-টা আবার দেখো: গ্রিড → (\(A\): rotate) → (\(B\): shear)। এবার সবচেয়ে গুরুত্বপূর্ণ পরীক্ষা — ক্রম উল্টে দিলে কি হয়?
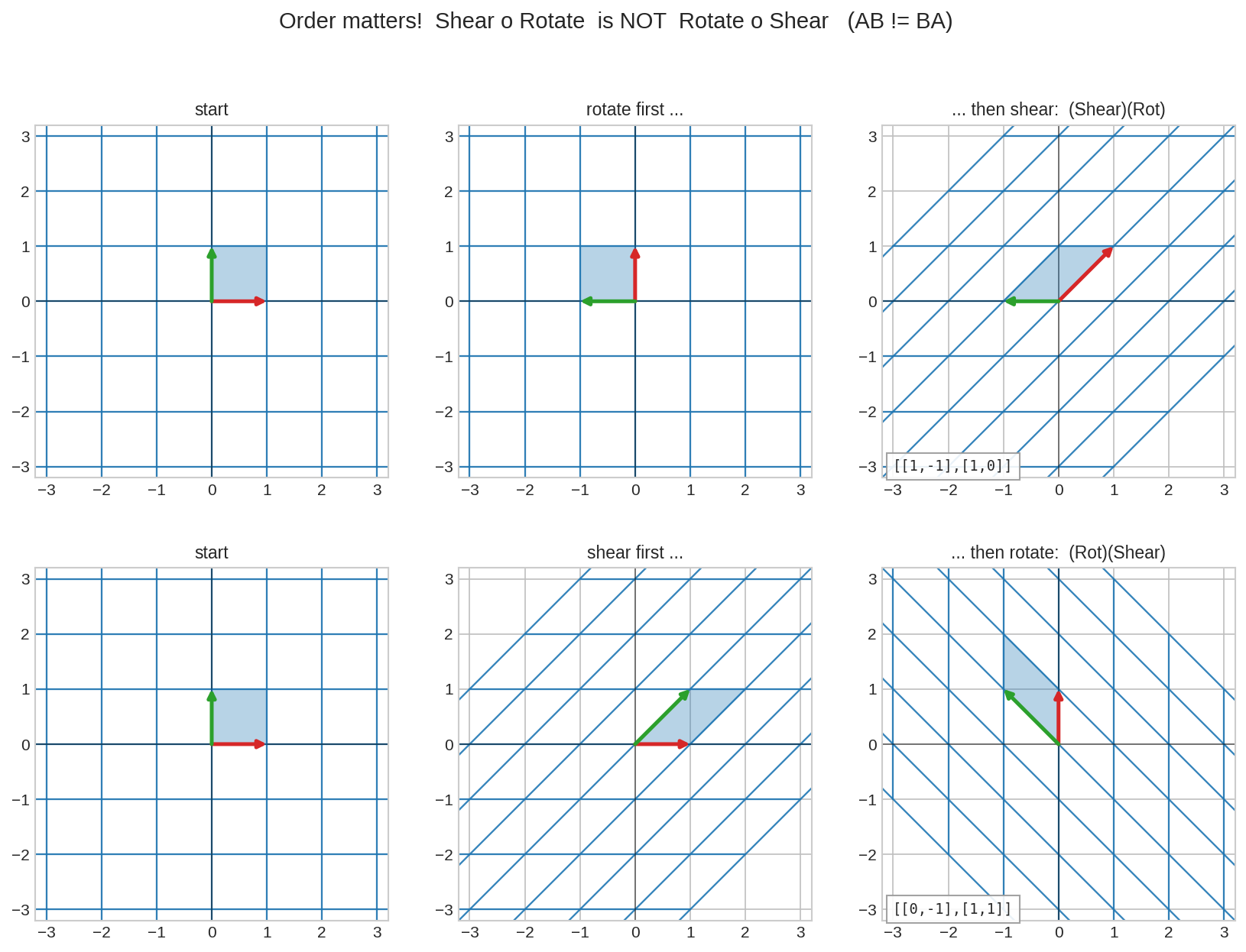
উপরের সারি: আগে rotate, পরে shear। নিচের সারি: আগে shear, পরে rotate। শেষ কলামের দুটো গ্রিড মিলছে না! জামা পরে কোট, আর কোট পরে জামা — এক জিনিস না। এজন্যই matrix-দের জগতে \(AB \neq BA\) — এটা কোনো ত্রুটি নয়, transformation-এর স্বভাব।
২.২ সংখ্যার স্তরে: কোন entry কোথা থেকে¶

\((BA)\)-র \((1,2)\) entry পেতে: \(B\)-র ১ম row (লাল) আর \(A\)-র ২য় column (সবুজ) নিয়ে dot product: \(1\cdot6 + 2\cdot8 = 22\)। প্রতিটা entry-ই এমন একটা row-column সাক্ষাৎ।
২.৩ নিয়মটার জন্ম কোথায়¶
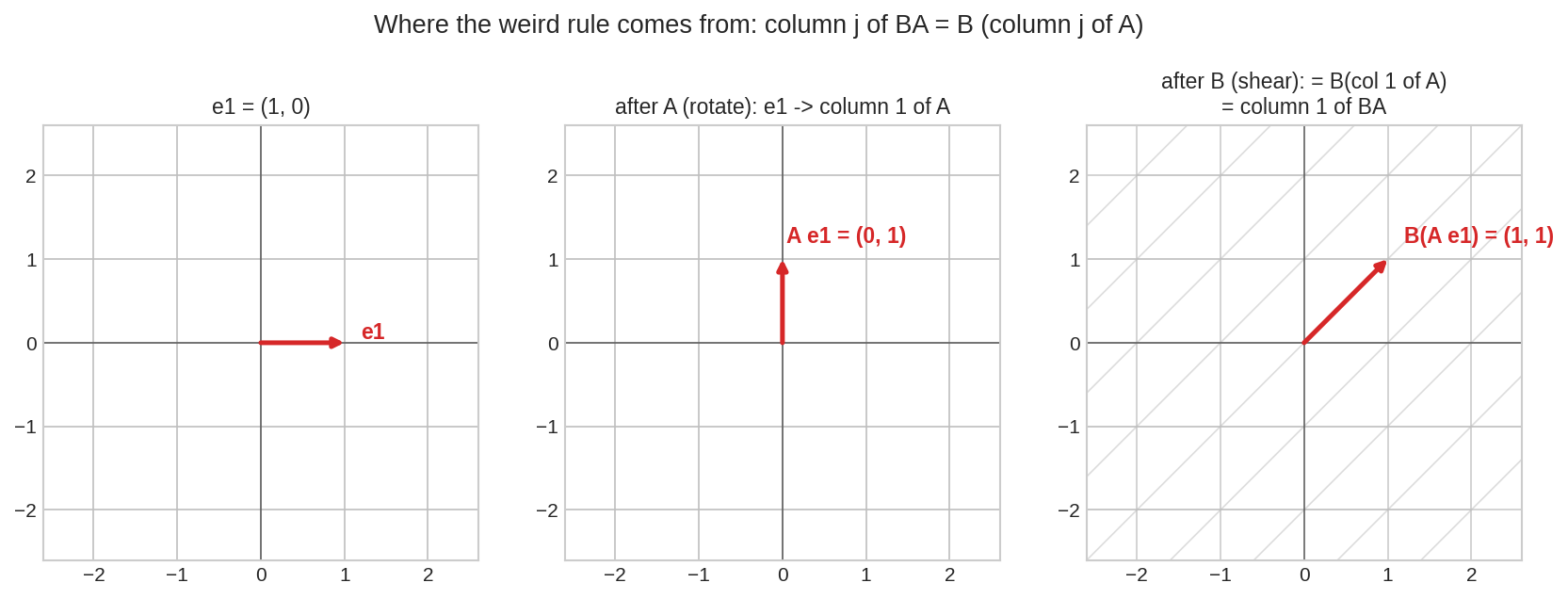
\(\mathbf{e}_1\)-কে অনুসরণ করো: \(A\) তাকে পাঠায় \(A\)-র ১ম column-এ; তারপর \(B\) সেই vector-কে transform করে। ফল = \(BA\)-র ১ম column। পুরো গুণের নিয়ম এই এক বাক্যের পুনরাবৃত্তি।
৩. কোথায় ইউজ হয়?¶
- Computer graphics pipeline: একটা 3D মডেল স্ক্রিনে আসা পর্যন্ত ৪–৫টা transformation পার হয় (model → world → camera → projection)। প্রতি ফ্রেমে লক্ষ বিন্দুতে ৫টা matrix চালানোর বদলে matrix-গুলো আগে নিজেদের মধ্যে গুণ করে একটা বানিয়ে নেওয়া হয় — তারপর প্রতি বিন্দুতে মোটে একটা গুণ। এই optimization-টাই আধুনিক গেমের প্রাণ।
- Neural network: layer-এর পর layer মানে matrix-এর পর matrix: \(W_3(W_2(W_1\mathbf{x}))\)। (মাঝে nonlinearity না দিলে পুরো deep network চুপসে একটাই matrix \(W_3W_2W_1\) হয়ে যায় — এটাই activation function থাকার গণিত-কারণ!)
- Robotics: কাঁধ → কনুই → কবজি — প্রতিটা জয়েন্টের rotation matrix; হাতের আঙুলের অবস্থান = সব matrix-এর product।
- Markov chain (Part VII): আজকের আবহাওয়া→কালকের সম্ভাবনা একটা matrix \(P\); সাত দিন পরের সম্ভাবনা \(P^7\) — সাতবার composition।
- Data pipeline: standardize → rotate (PCA) → project — পরপর linear ধাপ মানেই পেছনে matrix product।
৪. Properties¶
৪.১ নিয়মটা (এবার অর্থসহ)¶
\(B\) হলো \(m \times n\), \(A\) হলো \(n \times p\)। তাহলে \(BA\) হলো \(m \times p\), আর:
তিনটা সমতুল্য পাঠ — তিনটাই দরকারি:
- Entry view: \((BA)_{ij}\) = row-column dot product (হাত-হিসাবের জন্য)।
- Column view: \(BA\)-র \(j\)-তম column \(= B \cdot(A\text{-র } j\text{-তম column})\) (বোঝার জন্য)।
- Machine view: \(BA\) = "আগে \(A\) পরে \(B\)" এক প্যাকেটে (design-এর জন্য)।
৪.২ Shape rule — ভেতরের সংখ্যা মিলতেই হবে¶
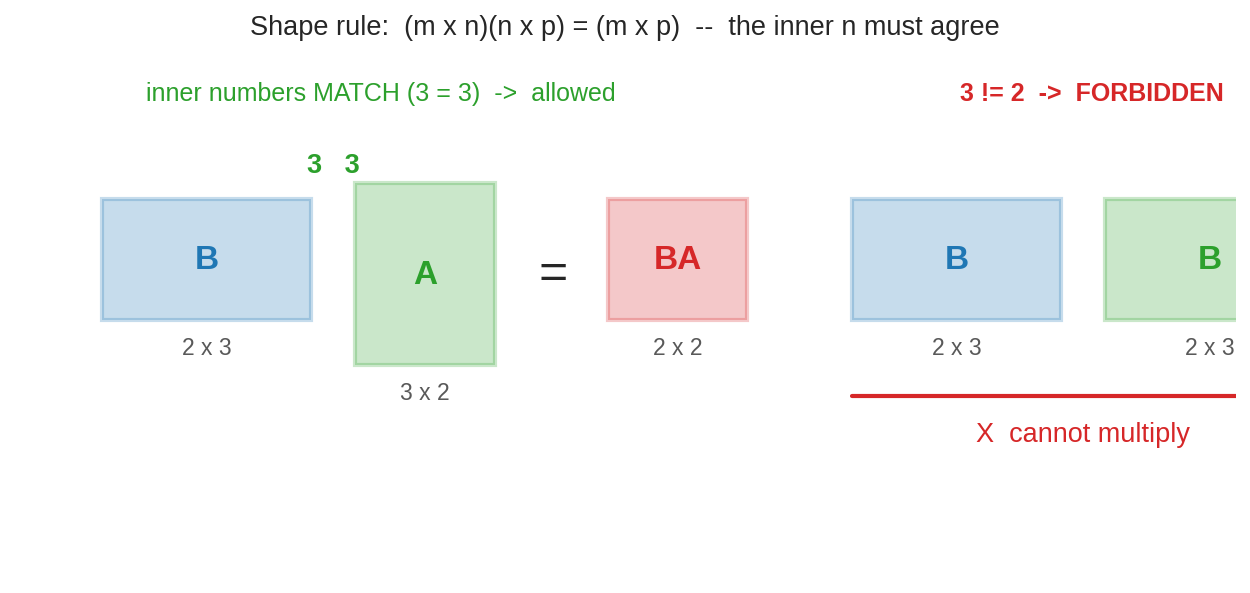
\((2\times 3)(3\times 2)\) → বৈধ, ফল \(2\times2\)। কিন্তু \((2\times3)(2\times3)\) → নিষিদ্ধ। কারণটা machine-ভাষায় পরিষ্কার: \(A\)-র output যে space-এ, \(B\)-র input সেই space-এ না হলে পাইপ জোড়া লাগে না।
৪.৩ Algebra-র নিয়মকানুন¶
| Property | সূত্র | কেন (composition-যুক্তি) |
|---|---|---|
| Associative(সংযোজনশীল) | \((AB)C = A(BC)\) | দুটোই মানে "আগে \(C\), পরে \(B\), পরে \(A\)" — ধাপের ক্রম একই, শুধু বন্ধনী কোথায় তা প্রশ্নই অবান্তর |
| Distributive(বণ্টনশীল) | \(A(B + C) = AB + AC\) | linearity থেকে সরাসরি |
| Commutative নয় | সাধারণত \(AB \neq BA\) | জামা-কোট! (§২.১-এর ছবি) |
| Identity | \(IA = AI = A\) | "কিছু কোরো না" মেশানো কিছু বদলায় না |
| Zero divisor ⚠️ | \(AB = 0\) হতে পারে যদিও \(A, B \neq 0\) | দুই projection মিলে সব গিলে ফেলতে পারে (Problem 6) |
Associativity-টা এক মুহূর্ত দাঁড়িয়ে উপভোগ করো: entry-সূত্র দিয়ে প্রমাণ করতে গেলে দুই পাতার sum-এর জঙ্গল। আর composition দিয়ে ভাবলে — প্রমাণের কিছু নেই-ই: তিনটা ধাপ পরপর ঘটে, বন্ধনী শুধু দেখার ভঙ্গি। ভালো দৃষ্টিভঙ্গি কঠিন প্রমাণকে বিনামূল্যের বানিয়ে দেয় — এটা তার সেরা উদাহরণ।
৪.৪ Power: বারবার একই transformation¶
\(A^2 = AA\), \(A^3 = AAA\), ... — একই মেশিন বারবার। যেমন \(R_{30°}^{12} = R_{360°} = I\): বারো বার ৩০° ঘুরলে পুরো এক পাক। আর projection-এর \(P^2 = P\) — আগের chapter-এর idempotent ধর্মটা এখন multiplication-এর ভাষায় লেখা।
৫. Intuition — কেন সত্য?¶
এবার সেই প্রতিশ্রুত derivation — row-column নিয়মটা কোথা থেকে এলো। আমরা শুধু দুটো জিনিস জানি: (১) \(BA\)-র সংজ্ঞা: \((BA)\mathbf{x} = B(A\mathbf{x})\); (২) আগের দুই chapter-এর মূলমন্ত্র: যেকোনো matrix-এর \(j\)-তম column = সে \(\mathbf{e}_j\)-কে যেখানে পাঠায়।
ধাপ ১: \(BA\)-র \(j\)-তম column জানতে হলে দেখতে হবে \(BA\) মেশিনটা \(\mathbf{e}_j\)-কে কোথায় পাঠায়: \((BA)\mathbf{e}_j = B(A\mathbf{e}_j)\)।
ধাপ ২: কিন্তু \(A\mathbf{e}_j\) তো চেনা — \(A\)-র \(j\)-তম column, নাম দিই \(\mathbf{a}_j\)। অতএব:
ধাপ ৩: \(B\mathbf{a}_j\) একটা সাধারণ matrix-vector গুণ, যার row picture আমরা জানি: \(i\)-তম entry \(= (B\)-র \(i\)-তম row\()\cdot \mathbf{a}_j\)। অতএব:
ব্যস — কুখ্যাত নিয়মটা দুই লাইনে নিজেই বেরিয়ে এলো! কেউ এটা আবিষ্কার করে বলেনি "চলো ছাত্রদের কষ্ট দিই"; নিয়মটা composition-এর একমাত্র সম্ভব রূপ। সংখ্যায় একবার দেখা যাক (opening figure-এর জোড়া): \(A = \begin{bmatrix}0 & -1\\ 1 & 0\end{bmatrix}\) (rotate \(90°\)), \(B = \begin{bmatrix}1 & 1\\ 0 & 1\end{bmatrix}\) (shear)।
যাচাই (column-গল্পে): \(\mathbf{e}_1\) rotate হয়ে \((0,1)\), তারপর shear-এ \((0+1, 1) = (1,1)\) — \(BA\)-র ১ম column ✓। \(\mathbf{e}_2\) rotate হয়ে \((-1, 0)\), shear-এ \((-1+0, 0) = (-1, 0)\) — ২য় column ✓।
আর উল্টো ক্রমে: \(AB = \begin{bmatrix}0 & -1\\ 1 & 1\end{bmatrix} \neq BA\) — জামা-কোট, সংখ্যাতেও।
৬. Code-এ কেমনে লিখে¶
import numpy as np
A = np.array([[0.0, -1.0], [1.0, 0.0]]) # rotate 90°
B = np.array([[1.0, 1.0], [0.0, 1.0]]) # shear
# composition দুইভাবে — ফল এক হওয়া চাই
x = np.array([2.0, 1.0])
two_steps = B @ (A @ x) # আগে A, পরে B — ধাপে ধাপে
one_step = (B @ A) @ x # আগে গুণে এক matrix, তারপর এক লাফ
print(two_steps, one_step) # [1. 3.] [1. 3.] -- হুবহু এক!
print(B @ A) # [[ 1. -1.] [ 1. 0.]]
print(A @ B) # [[ 0. -1.] [ 1. 1.]] -- ভিন্ন! AB != BA
# associativity-র পরীক্ষা: তিনটা random matrix
rng = np.random.default_rng(42)
P, Q, R = rng.normal(size=(3, 4, 4))
print(np.allclose((P @ Q) @ R, P @ (Q @ R))) # True
# power: 12 বার 30° = 360° = identity
th = np.pi / 6
R30 = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]])
print(np.round(np.linalg.matrix_power(R30, 12), 10)) # identity!
Output ব্যাখ্যা: two_steps আর one_step — দুটোই [1. 3.]; composition আর product একই জিনিস, কোডে প্রমাণ। B @ A ও A @ B ভিন্ন — non-commutativity নিজের চোখে। allclose(...) → True: বন্ধনী যেখানেই দাও ফল এক। শেষ লাইনে matrix_power(R30, 12) দেয় নিখুঁত identity matrix — বারো পা-এ পুরো এক চক্কর।
⚠️ Performance note: B @ (A @ x) (দুইটা matrix-vector গুণ) সাধারণত (B @ A) @ x-এর (একটা matrix-matrix + একটা matrix-vector) চেয়ে সস্তা — কিন্তু লাখো \(\mathbf{x}\)-এ একই জোড়া চালাতে হলে আগে BA বানিয়ে নেওয়াই জেতে। Associativity মানে উত্তর এক, খরচ ভিন্ন — এই ফাঁকটাই graphics/ML-এর বহু optimization।
৭. Worked Examples¶
Example 1 — হাতে পুরো একটা গুণ। \(B = \begin{bmatrix}1 & 2\\ 3 & 4\end{bmatrix}\), \(A = \begin{bmatrix}5 & 6\\ 7 & 8\end{bmatrix}\); \(BA\) বের করি।
ধাপ ১ — আকার: \((2\times2)(2\times2) \to 2\times2\) ✓। ধাপ ২ — চারটা row-column সাক্ষাৎ:
ধাপ ৩ — spot-যাচাই (column view): \(BA\)-র ১ম column \(= B\begin{bmatrix}5\\7\end{bmatrix} = 5\begin{bmatrix}1\\3\end{bmatrix} + 7\begin{bmatrix}2\\4\end{bmatrix} = \begin{bmatrix}19\\43\end{bmatrix}\) ✓।
Example 2 — design problem: কম্বো transformation বানaও। এমন এক matrix চাই যেটা আগে \(x\)-axis-এ reflect করে, তারপর \(90°\) (কাঁটার বিপরীতে) ঘোরায়।
ধাপ ১: Reflection \(F = \begin{bmatrix}1 & 0\\ 0 & -1\end{bmatrix}\), rotation \(R = \begin{bmatrix}0 & -1\\ 1 & 0\end{bmatrix}\)। ধাপ ২: "আগে \(F\), পরে \(R\)" \(\Rightarrow\) product-এ \(F\) ডানে: \(M = RF\)।
ধাপ ৩ — চিনতে পারছ? এটা \(y=x\) রেখায় reflection (Chapter 3.1, Example 1)! Reflect + rotate = অন্য এক reflect — transformation-দের জগতে এমন চমক অহরহ। যাচাই: \((1, 0) \xrightarrow{F} (1,0) \xrightarrow{R} (0,1)\) — আর \(M\mathbf{e}_1 = (0,1)\) ✓।
Example 3 — আয়তাকার আকারের composition। \(A = \begin{bmatrix}1 & 0 & 2\\ 0 & 1 & 1\end{bmatrix}\) (\(3\)D→\(2\)D), \(B = \begin{bmatrix}1 & 1\\ 0 & 1\\ 1 & 0\end{bmatrix}\) (\(2\)D→\(3\)D)। \(AB\) ও \(BA\) দুটোই বৈধ কি? আকার কত?
ধাপ ১: \(AB\): \((2\times3)(3\times2) \to 2\times2\) ✓ — 2D→3D→2D যাত্রা।
ধাপ ২: \(BA\): \((3\times2)(2\times3) \to 3\times3\) ✓ — 3D→2D→3D যাত্রা। ধাপ ৩ — শিক্ষা: দুটোই বৈধ কিন্তু আকারই আলাদা (\(2\times2\) বনাম \(3\times3\)) — commutativity-র প্রশ্নই ওঠে না। ভেতর দিয়ে 2D-র সরু পাইপ পেরোনো \(BA\) কখনোই পুরো 3D ফেরত পাবে না — এই "সরু পাইপের ক্ষতি"-র হিসাবই Part IV-এর rank।
৮. Problems ও Solutions¶
Problem 1. \(P = \begin{bmatrix}2 & 0\\ 1 & 3\end{bmatrix}\), \(Q = \begin{bmatrix}1 & -1\\ 2 & 0\end{bmatrix}\)। \(PQ\) ও \(QP\) দুটোই বের করো এবং দেখাও তারা ভিন্ন।
Solution
\(PQ \neq QP\) — একটা entry-ও মেলে না। (Composition-ভাষায়: "আগে \(Q\)-স্টাইলে মোচড়াও পরে \(P\)-স্টাইলে" ≠ উল্টোটা।)
Problem 2. আকারগুলো দেখে বলো কোন product বৈধ, বৈধ হলে ফলের আকার: \(A\) হলো \(3\times2\), \(B\) হলো \(2\times5\), \(C\) হলো \(3\times5\)। (a) \(AB\) (b) \(BA\) (c) \(BC\) (d) \(C^\top\) ব্যবহার না করে \(A\)-র সাথে \(C\)-কে জুড়ার কোনো বৈধ ক্রম আছে কি? (e) \(ABB\)?
Solution
(a) \(AB\): \((3\times2)(2\times5)\) — ভেতরে \(2=2\) ✓ → ফল \(3\times5\)।
(b) \(BA\): \((2\times5)(3\times2)\) — ভেতরে \(5 \neq 3\) ✗ নিষিদ্ধ।
(c) \(BC\): \((2\times5)(3\times5)\) — \(5\neq3\) ✗ নিষিদ্ধ।
(d) \(AC\): \((3\times2)(3\times5)\) ✗; \(CA\): \((3\times5)(3\times2)\) ✗ — কোনো ক্রমেই না। (\(C\)-র input space \(\mathbb{R}^5\), output \(\mathbb{R}^3\); \(A\)-র input \(\mathbb{R}^2\), output \(\mathbb{R}^3\) — পাইপ কোনোভাবেই জোড়ে না।)
(e) \(ABB\) মানে \(A(BB)\); কিন্তু \(BB\): \((2\times5)(2\times5)\) ✗ — নিষিদ্ধ। (Square না হলে নিজের সাথেও গুণ চলে না!)
Problem 3. \(R_\alpha R_\beta = R_{\alpha+\beta}\) — "আগে \(\beta\) ঘোরো পরে \(\alpha\)" মানে মোট \(\alpha + \beta\) ঘোরা। বাঁ পাশ গুণ করে দেখাও ডান পাশ বেরিয়ে আসে, এবং বলো কোন বিখ্যাত ত্রিকোণমিতিক সূত্র free-তে প্রমাণ হয়ে গেল।
Solution
\((1,1)\) entry: \(\cos\alpha\cos\beta - \sin\alpha\sin\beta\); \((2,1)\) entry: \(\sin\alpha\cos\beta + \cos\alpha\sin\beta\)। অন্যদিকে
জ্যামিতি বলছে দুটো matrix সমান (পরপর ঘোরা = মোট ঘোরা)। Entry মিলালে:
— ত্রিকোণমিতির angle-addition formula দুটো, যেগুলো স্কুলে রক্ত জল করে মুখস্থ করেছিলে, matrix composition থেকে বিনামূল্যে! (আর \(R_\alpha R_\beta = R_\beta R_\alpha\) — rotation-রা নিজেদের মধ্যে commute করে; সব জোড়া অবাধ্য নয়।)
Problem 4. \(D = \begin{bmatrix}2 & 0\\ 0 & 3\end{bmatrix}\), \(S = \begin{bmatrix}1 & 1\\ 0 & 1\end{bmatrix}\)। (a) \(DS\) ও \(SD\) বের করো। (b) দুটোর \((1,2)\) entry আলাদা কেন, transformation-ভাষায় ব্যাখ্যা করো।
Solution
(a)
(b) \((1,2)\) entry হলো "\(\mathbf{e}_2\)-র শেষ ঠিকানার \(x\)-অংশ।"
- \(DS\) (আগে shear, পরে scale): \(\mathbf{e}_2 \xrightarrow{S} (1, 1) \xrightarrow{D} (2, 3)\) — shear তাকে \(x\)-এ \(1\) সরিয়েছিল, scale সেটাকে \(\times2\) করে \(2\)।
- \(SD\) (আগে scale, পরে shear): \(\mathbf{e}_2 \xrightarrow{D} (0, 3) \xrightarrow{S} (0 + 3, 3) = (3,3)\) — আগে লম্বা হয়ে গেছে বলে shear-এর ঠেলা (\(x \mathrel{+}= y\)) এবার \(3\)।
Scale আগে না পরে — shear-এর ঠেলার মাপই বদলে যায়। Non-commutativity কোনো বিমূর্ত ব্যাপার না; প্রতিটা entry-র পেছনে গল্প আছে।
Problem 5. Projection \(P = \begin{bmatrix}1 & 0\\ 0 & 0\end{bmatrix}\) ও rotation \(R = \begin{bmatrix}0 & -1\\ 1 & 0\end{bmatrix}\)। (a) \(PR\) ও \(RP\) বের করো। (b) \(PRP\) কত? (c) \((PR)^2\) হিসাব করে দেখাও সেটা zero matrix — অথচ \(PR \ne 0\)!
Solution
(a)
(আবারও অসমান — এবং দুটোই "চ্যাপ্টানো + ঘোরানো"র ভিন্ন ভিন্ন মিশেল।)
(b)
গল্পটা দেখো: \(P\) সব ফেলে দেয় \(x\)-axis-এ → \(R\) সেই লাইনটা ঘুরিয়ে করে \(y\)-axis → শেষ \(P\) আবার \(x\)-axis-এ ছায়া ফেলে, কিন্তু \(y\)-axis-এর ছায়া \(x\)-axis-এ শুধুই origin। সব ধ্বংস।
(c)
অথচ \(PR \neq 0\)! সংখ্যায় \(x^2 = 0 \Rightarrow x = 0\), কিন্তু matrix-এ না — এমন matrix-কে বলে nilpotent(শূন্যঘাতী)। সংখ্যার অভ্যাস matrix-এ অন্ধভাবে খাটে না — এই chapter-এর বড় সতর্কবার্তা।
Problem 6. ভুল খোঁজো: এক ছাত্র লিখেছে, "\((A + B)^2 = A^2 + 2AB + B^2\)।" (a) কোথায় ভুল? সঠিক বিস্তারটা লেখো। (b) \(A = \begin{bmatrix}1 & 1\\ 0 & 1\end{bmatrix}\), \(B = \begin{bmatrix}1 & 0\\ 1 & 1\end{bmatrix}\) দিয়ে সংখ্যায় দেখাও দুই পাশে ভিন্ন ফল।
Solution
(a)
\(AB \neq BA\) বলে \(AB + BA\)-কে \(2AB\) লেখা যায় না — স্কুল-algebra-র অভ্যাসটাই ফাঁদ।
(b) \(A + B = \begin{bmatrix}2 & 1\\ 1 & 2\end{bmatrix}\), তাই \((A+B)^2 = \begin{bmatrix}5 & 4\\ 4 & 5\end{bmatrix}\)।
অন্যদিকে: \(A^2 = \begin{bmatrix}1 & 2\\ 0 & 1\end{bmatrix}\), \(B^2 = \begin{bmatrix}1 & 0\\ 2 & 1\end{bmatrix}\), \(AB = \begin{bmatrix}2 & 1\\ 1 & 1\end{bmatrix}\), সুতরাং
(সঠিকটা: \(A^2 + AB + BA + B^2\), যেখানে \(BA = \begin{bmatrix}1 & 1\\ 1 & 2\end{bmatrix}\) — যোগ করলে \(\begin{bmatrix}5&4\\4&5\end{bmatrix}\) ✓)
Problem 7 (challenge)। \(A = \begin{bmatrix}1 & 1\\ 0 & 1\end{bmatrix}\) (shear)। (a) \(A^2, A^3\) বের করে \(A^n\)-এর একটা কাঠামো অনুমান করো। (b) অনুমানটা induction-এ প্রমাণ করো। (c) জ্যামিতিকভাবে ফলটা কেন "স্পষ্ট" ছিল?
Solution
(a)
(b) Base case \(n=1\) ✓। ধরো \(A^n = \begin{bmatrix}1 & n\\ 0 & 1\end{bmatrix}\); তাহলে
Induction সম্পূর্ণ।
(c) Shear-এর গল্প: এক ধাপে \(\mathbf{e}_2\)-র মাথা ডানে \(1\) ঘর হেলে। \(n\) বার হেললে \(n\) ঘর — ব্যস, \((1,2)\) entry-তে \(n\)। জ্যামিতি আগে বলেছিল উত্তর, algebra পরে সই করেছে মাত্র।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ ঠিক ধারণা |
|---|---|
| \(AB\) মানে "আগে \(A\), পরে \(B\)" | উল্টো! Input ডান দিক থেকে ঢোকে: \(AB\mathbf{x}\) মানে আগে \(B\), পরে \(A\) |
| \(AB = BA\) ধরে নিয়ে সরল করা | সাধারণত \(AB \ne BA\); commute করে শুধু বিশেষ জোড়া (যেমন দুই rotation, দুই diagonal) |
| \((A+B)^2 = A^2 + 2AB + B^2\) | \(= A^2 + AB + BA + B^2\) — মাঝের দুটো আলাদা জিনিস |
| \(AB = 0 \Rightarrow A = 0\) বা \(B = 0\) | মিথ্যা: nonzero matrix-দের গুণেও শূন্য আসতে পারে (Problem 5) |
| Element-wise গুণ করা: \((AB)_{ij} = A_{ij}B_{ij}\) | ওটা Hadamard গুণ (NumPy-র *), composition নয়; matrix গুণ মানে row·column |
| "\(m\times n\) আর \(m \times n\) গুণ করা যায় — আকার তো একই!" | মিলতে হবে ভেতরের মাপ: প্রথমটার column-সংখ্যা = দ্বিতীয়টার row-সংখ্যা |
১০. এক নজরে¶
| ধারণা | সারকথা |
|---|---|
| \(BA\)-র মানে | "আগে \(A\), পরে \(B\)" — composition এক প্যাকেটে; ডান→বাঁ পড়ো |
| Entry নিয়ম | \((BA)_{ij} = (\text{row } i \text{ of } B)\cdot(\text{col } j \text{ of } A)\) |
| নিয়মের উৎস | \(BA\)-র col \(j\) \(= B(A\mathbf{e}_j) = B\cdot(\text{col}_j \text{ of } A)\) — linearity থেকে বাধ্যতামূলক |
| Shape rule | \((m\times n)(n\times p) = m \times p\); ভেতরের \(n\) মিলতেই হবে |
| Commutative? | না — জামা-কোট; তবে associative ও distributive ঠিকই |
| চমক | \(AB = 0\) সম্ভব nonzero \(A,B\) দিয়ে; \((PR)^2=0\) সম্ভব; স্কুল-algebra সাবধানে |
পরের chapter-এর সেতু: Composition পারলে স্বাভাবিক পরের প্রশ্ন — উল্টোপথে হাঁটা যায় কি? \(A\) চালিয়ে ফেলেছি; এমন কোনো matrix আছে কি যে চালালে সব আগের জায়গায় ফেরে? অর্থাৎ এমন \(B\) যে \(BA = I\)? পরের chapter-এ এই "undo বোতাম" — inverse matrix — আর সেই করুণ কাহিনি: কার undo আছে, কার চিরতরে নেই।
📓 Notebook Project¶
notebooks/part-03/ch03-project.ipynb — scratch-এ নিজের matmul লিখে NumPy-র সাথে race, composition-শৃঙ্খল দিয়ে অ্যানিমেশন-ফ্রেম বানানো, আর \(AB\) বনাম \(BA\)-র ছবি-প্রমাণ।