Chapter 5.1 — Orthogonality and Projection (অর্থোগোনালিটি ও প্রজেকশন)¶
Part V-এর মূল থিম: ছায়া ফেলার গণিত। এই পাঁচটা chapter-এ আমরা একটাই ছবি বারবার আঁকবো — একটা vector আরেকটা vector-এর (বা একটা subspace-এর) ওপর ছায়া ফেলছে। সেই ছায়াটার নামই Projection(প্রজেকশন)। বিশ্বাস করো বা না করো — Machine Learning-এর regression, ডেটা fitting, এমনকি Google-এর ranking-এর পেছনেও এই ছায়ার গণিতই কাজ করে।
🎯 এই chapter-এ যা শিখবে¶
- Orthogonal(অর্থোগোনাল — লম্ব/পার্পেন্ডিকুলার) মানে কি, আর dot product দিয়ে সেটা কিভাবে এক লাইনে চেক করা যায়
- Projection(প্রজেকশন) মানে "ছায়া" — একটা vector-কে আরেকটা vector-এর দিকে ফেলা ছায়ার সূত্র geometric-ভাবে নিজে derive করা
- \(b = b_{\parallel} + b_{\perp}\) — যেকোনো vector-কে "সমান্তরাল অংশ + লম্ব অংশ"-এ ভাঙার কৌশল
- Projection কেন সবচেয়ে কাছের বিন্দু দেয় — এই একটা কথাই পরের চার chapter-এর ভিত্তি
- NumPy দিয়ে projection হিসাব ও ছবি আঁকা
🖼️ এক ছবিতে মূল idea¶
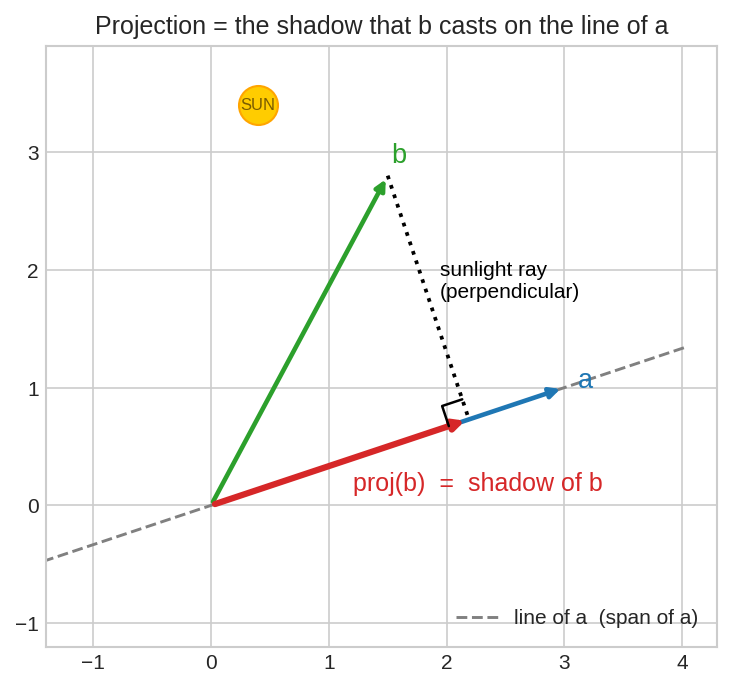
সূর্য ঠিক মাথার ওপর থেকে আলো ফেলছে \(a\)-এর লাইনের ওপর লম্বভাবে। সবুজ vector \(b\)-এর ছায়া পড়েছে লাল অংশটুকুতে — এটাই projection। খেয়াল করো, ছায়ার ডগা থেকে \(b\)-এর ডগা পর্যন্ত ডটেড লাইনটা \(a\)-এর লাইনের ওপর ঠিক \(90°\)-তে দাঁড়িয়ে আছে।
১. কি? (What)¶
দৈনন্দিন analogy: দুপুরের রোদে তোমার ছায়া¶
কল্পনা করো তুমি দুপুর ১২টায় খোলা মাঠে দাঁড়িয়ে আছো। সূর্য একদম মাথার ওপরে, আলো পড়ছে মাটির ওপর লম্বভাবে। তোমার শরীর যদি একটু হেলে থাকে (একটা তির্যক vector), মাটিতে তোমার ছায়াটা হবে তোমার শরীরের মাটি-বরাবর অংশটুকু। শরীরের যে অংশ সোজা ওপরের দিকে, সেটা ছায়ায় ধরাই পড়ে না।
Linear Algebra-র ভাষায়:
- মাটি = যে লাইনের (বা plane-এর) ওপর ছায়া ফেলছি
- তুমি = vector \(b\)
- ছায়া = \(b\)-এর Projection(প্রজেকশন)
- সূর্যের আলোর রশ্মি = লম্ব দিক — এ কারণেই বলা হয় Orthogonal Projection(অর্থোগোনাল প্রজেকশন)
আগে সংজ্ঞা দুটো, তারপর সূত্র¶
Orthogonal(অর্থোগোনাল): দুটি vector \(u\) ও \(v\) orthogonal, যদি তাদের Dot Product(ডট প্রোডাক্ট — Chapter 1.3-এ শিখেছো) শূন্য হয়:
"Orthogonal" শব্দটা গ্রিক orthos (সোজা/খাড়া) + gonia (কোণ) থেকে এসেছে — মানে স্রেফ "সমকোণে থাকা"। Perpendicular(পার্পেন্ডিকুলার)-এর formal ভাই।
Projection(প্রজেকশন): vector \(b\)-এর, nonzero vector \(a\)-এর লাইনের ওপর projection হলো \(a\)-এর লাইনে সেই বিন্দু যেটা \(b\)-এর সবচেয়ে কাছে। সূত্রটা (একটু পরেই নিজে বানাবো):
ভয় পেয়ো না — এটা আসলে দুই ধাপের গল্প: \(\frac{a^T b}{a^T a}\) একটা সাধারণ সংখ্যা (কতটুকু \(a\) লাগবে), আর সেই সংখ্যা দিয়ে \(a\)-কে গুণ করলেই ছায়া পাওয়া যায়।
Residual — ছায়ায় যা ধরা পড়েনি¶
ছায়া তো পেলাম; কিন্তু \(b\)-এর যে অংশটুকু ছায়ায় ধরা পড়লো না, সেটার নাম Residual(রেসিডুয়াল — অবশিষ্ট):
এই \(e\)-ই Part V-এর secret hero। Chapter 5.4-এ দেখবে, Least Squares-এর পুরো ব্যাপারটাই হলো "এই residual-টাকে যতটা সম্ভব ছোট করো।"
২. দেখতে কেমন?¶
দৃশ্য ১: কোণ আর dot product-এর সম্পর্ক¶
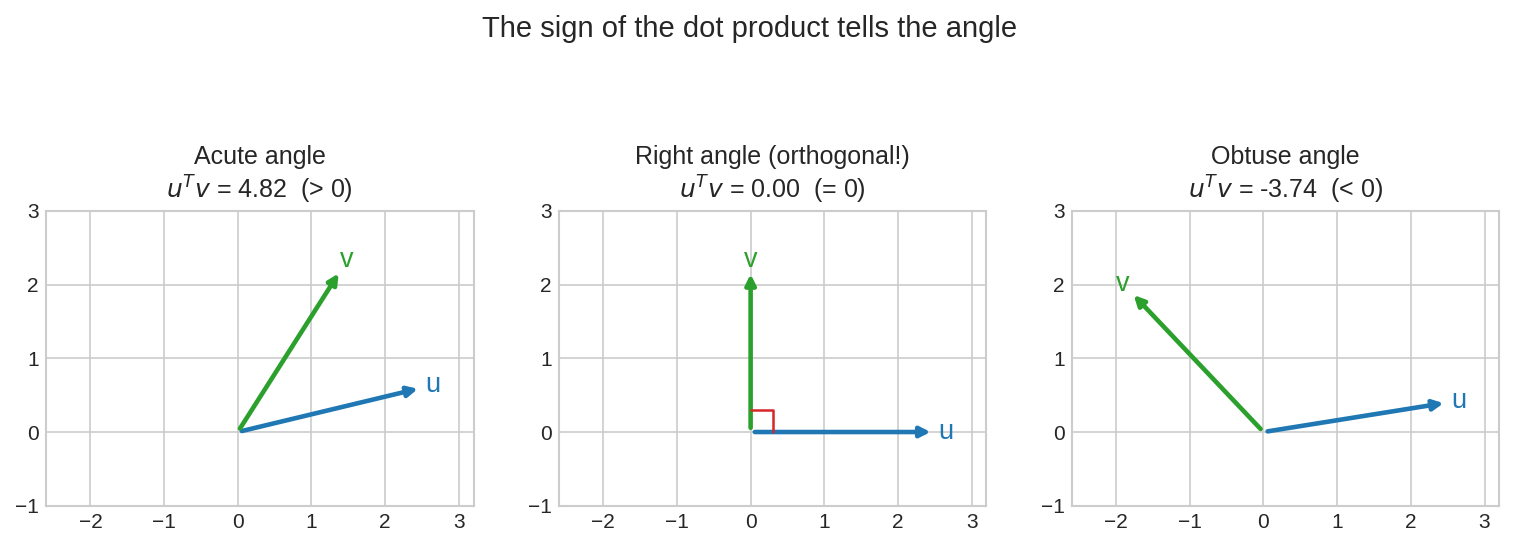
বাঁ দিকে সূক্ষ্মকোণ (acute angle): \(u^T v > 0\)। মাঝে সমকোণ: \(u^T v = 0\) — এটাই orthogonality। ডানে স্থূলকোণ (obtuse): \(u^T v < 0\)। অর্থাৎ dot product-এর চিহ্নটাই বলে দেয় দুটো vector একে অপরের "দিকে" না "বিপরীতে"।
দৃশ্য ২: ভাঙা যায় দুই টুকরোয়¶
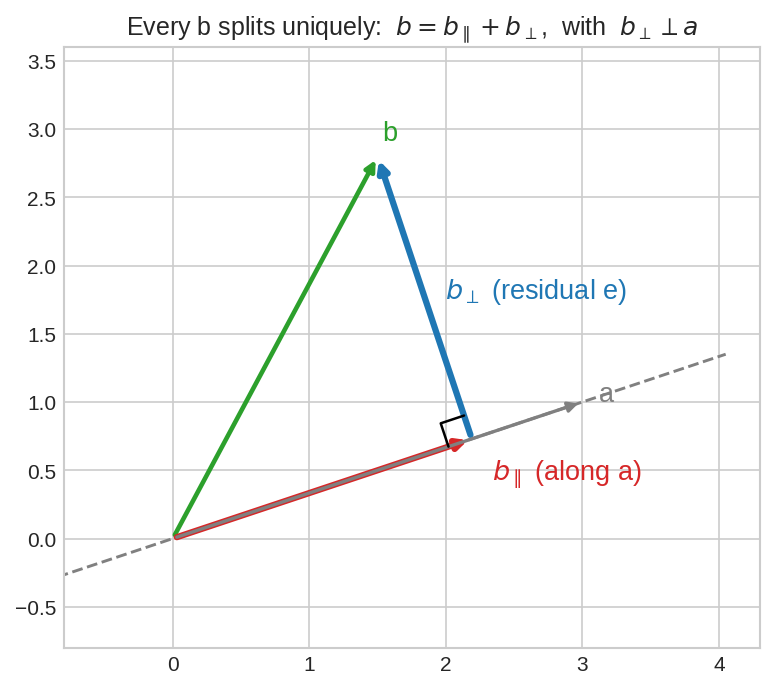
সবুজ \(b\)-কে ভাঙা হয়েছে দুই টুকরোয়: লাল \(b_{\parallel}\) (\(a\)-এর দিক বরাবর — এটাই ছায়া) আর নীল \(b_{\perp}\) (\(a\)-এর ওপর লম্ব — এটাই residual \(e\))। দুটো জুড়লে আবার \(b\) ফিরে আসে।
দৃশ্য ৩: 3D-তেও একই গল্প — plane-এর ওপর ছায়া¶
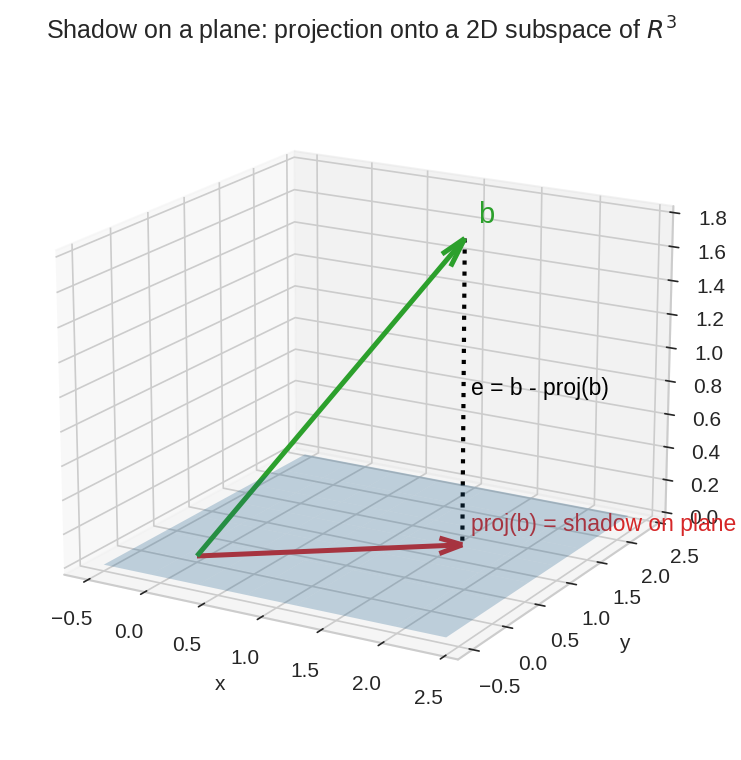
এবার মাটিটা সত্যিকারের "মাটি" — একটা 2D plane, \(\mathbb{R}^3\)-এর ভেতরে। সবুজ \(b\) plane-এর বাইরে ভেসে আছে, লাল তীরটা plane-এর ওপর তার ছায়া, আর ডটেড লাইনটা (\(e\)) plane-এর ওপর লম্ব। Chapter 5.4-এ ঠিক এই ছবিটাই হবে Least Squares-এর প্রাণ।
৩. কোথায় ইউজ হয়?¶
বাস্তব জীবনে:
- GPS আর ম্যাপ: তুমি রাস্তা থেকে একটু দূরে দাঁড়িয়ে আছো — ম্যাপ app তোমাকে রাস্তার সবচেয়ে কাছের বিন্দুতে "snap" করে দেখায়। ওই snap-টাই projection।
- ফিজিক্স: ঢালু রাস্তায় গাড়ির ওজনের কতটুকু রাস্তা-বরাবর টানছে (গড়িয়ে নামাচ্ছে) আর কতটুকু রাস্তার ওপর চাপ দিচ্ছে — force vector-এর projection ভাঙা।
- অডিও ইঞ্জিনিয়ারিং: একটা রেকর্ডিং থেকে নির্দিষ্ট frequency-র "উপাদান" আলাদা করা মানে সেই frequency-র দিকের ওপর signal-এর projection নেওয়া।
Data Science / ML-এ:
- Regression (Chapter 5.4–5.5): ডেটার prediction মানে target vector \(y\)-এর, feature-দের span-এর ওপর projection। Least squares = ছায়া ফেলা। এই এক বাক্য মাথায় গেঁথে নাও।
- Cosine Similarity: দুটি document/word embedding কতটা "একই দিকে" — সেটা মাপে projection-এর আত্মীয় \(\cos\theta = \frac{u^Tv}{\|u\|\|v\|}\) দিয়ে। Orthogonal মানে সম্পূর্ণ "সম্পর্কহীন"।
- PCA (Part VI-এ আসবে): হাজার-dimension-এর ডেটাকে সবচেয়ে "তথ্যবহুল" ২–৩টা দিকের ওপর project করে ছবি আঁকা।
- Gram–Schmidt (পরের chapter): এলোমেলো feature-দের থেকে "একে অপরের সাথে সম্পর্কহীন" feature বানানো — বারবার projection বিয়োগ করে।
৪. Properties¶
Property 1 — Orthogonality হলো Pythagoras-এর আধুনিক রূপ¶
যদি \(u \perp v\) হয়, তাহলে:
মিনি-derivation (Chapter 1.4-এর norm-এর নিয়ম দিয়ে):
মাঝের term-টা মরে যায় — ঠিক এই কারণেই orthogonality এত আরামদায়ক। ২৫০০ বছরের পুরনো Pythagoras আসলে একটা dot product-এর গল্প ছিল!
Property 2 — Zero vector সবার সাথে orthogonal¶
\(0^T v = 0\) সব \(v\)-এর জন্য। তাই সংজ্ঞামতে \(0\) সবার সাথে লম্ব। (একটু অদ্ভুত শোনায়, কিন্তু theory-তে এটা দরকারি — পরের chapter-গুলোতে কাজে লাগবে।)
Property 3 — Projection-এর residual সবসময় লম্ব¶
মিনি-proof:
অর্থাৎ সূত্রটা "design-by-construction" — residual-কে লম্ব বানানোর জন্যই coefficient-টা ঠিক \(\frac{a^Tb}{a^Ta}\) হতে বাধ্য।
Property 4 — দুইবার ছায়া ফেললে নতুন কিছু ঘটে না (Idempotence)¶
ছায়ার আবার ছায়া ফেললে ছায়াটাই থাকে:
কারণ \(\text{proj}_a(b)\) তো ইতিমধ্যেই \(a\)-এর লাইনে শুয়ে আছে — লাইনের ওপরের জিনিসের ছায়া সে নিজেই। এই ধর্মের নাম Idempotent(আইডেমপোটেন্ট), Chapter 5.4-এ projection matrix \(P^2 = P\) আকারে ফিরে আসবে।
Property 5 — Scaling-এ ছায়া বদলায় না (\(a\)-এর দিক-ই আসল)¶
\(a\)-কে \(2a\) বা \(-3a\) করলেও projection একই থাকে:
ছায়া নির্ভর করে লাইনটার ওপর, লাইনের ওপরে আঁকা তীরের দৈর্ঘ্যের ওপর নয়। বিশেষত \(a\) যদি Unit Vector(ইউনিট ভেক্টর — দৈর্ঘ্য ১) হয়, সূত্র সুন্দর হয়ে যায়: \(\text{proj}_a(b) = (a^Tb)\,a\)।
৫. Intuition — কেন সত্য? (সূত্রটা নিজে বানাই)¶
সূত্র মুখস্থ নয় — এসো নিজে আবিষ্কার করি। প্রশ্নটা হলো: \(a\)-এর লাইনের ওপর কোন বিন্দুটা \(b\)-এর সবচেয়ে কাছে?
ধাপ ১: লাইনের ওপর যেকোনো বিন্দু লেখা যায় \(x\,a\) আকারে, যেখানে \(x\) একটা সংখ্যা (কতগুণ \(a\))। আমরা খুঁজছি সেই \(x\), যার জন্য দূরত্ব \(\|xa - b\|\) সবচেয়ে ছোট।
ধাপ ২ (geometric যুক্তি — 3Blue1Brown স্টাইল): কল্পনা করো তুমি লাইন ধরে হাঁটছো, হাতে একটা রাবার ব্যান্ডের এক মাথা, অন্য মাথা \(b\)-তে বাঁধা। যতক্ষণ ব্যান্ডটা লাইনের সাথে তির্যক হয়ে আছে, ততক্ষণ লাইন-বরাবর একটু সরলে ব্যান্ড আরো ছোট করা যায়। ব্যান্ড আর ছোট করা যায় না ঠিক তখনই, যখন ব্যান্ডটা লাইনের ওপর লম্ব — কারণ তখন যেদিকেই সরো, ব্যান্ড লম্বা-ই হবে। কাজেই সবচেয়ে কাছের বিন্দুতে:
ধাপ ৩: এবার শুধু \(x\)-এর জন্য সমাধান:
ব্যস! projection-এর সূত্র geometric যুক্তি থেকেই বেরিয়ে এলো:
Calculus-ও একই কথা বলে — দূরত্বের বর্গটা \(x\)-এর একটা Parabola(প্যারাবোলা):
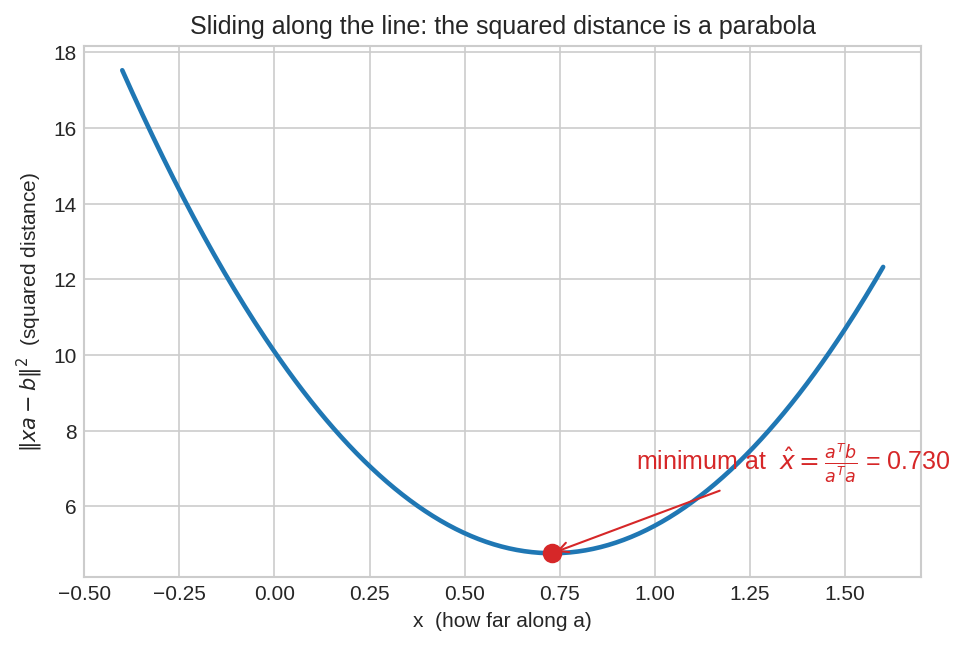
লাইন ধরে সরতে থাকলে দূরত্বের বর্গ একটা মসৃণ পেয়ালার মতো নামে-ওঠে; পেয়ালার তলা ঠিক \(\hat{x} = \frac{a^Tb}{a^Ta}\)-তে। \(f'(x)=0\) করলে একই উত্তর।
এই "লম্ব হলেই সবচেয়ে কাছে" নীতিটাকে সম্মান করে ডাকা হয় Orthogonality Principle(অর্থোগোনালিটি প্রিন্সিপল) — Part V-এ এটাই আমাদের সংবিধান।
৬. Code-এ কেমনে লিখে¶
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
# দুটি vector
a = np.array([3.0, 1.0])
b = np.array([1.5, 2.8])
# ---- Projection: তিন লাইনের গল্প ----
x_hat = (a @ b) / (a @ a) # কতটুকু a লাগবে (একটা সংখ্যা)
p = x_hat * a # ছায়া (projection vector)
e = b - p # residual (ছায়ায় যা ধরা পড়েনি)
print(f"x_hat = {x_hat:.4f}") # 0.7300
print(f"p = {p}") # [2.19 0.73]
print(f"e = {e}") # [-0.69 2.07]
print(f"a.e = {a @ e:.2e}") # ~0 → residual লম্ব!
print(f"Pythagoras check: {np.linalg.norm(b)**2:.4f} "
f"= {np.linalg.norm(p)**2 + np.linalg.norm(e)**2:.4f}")
# ---- ছবি ----
fig, ax = plt.subplots(figsize=(6, 5))
for v, c, name in [(a, 'gray', 'a'), (b, '#2ca02c', 'b'),
(p, '#d62728', 'proj'), ]:
ax.annotate('', xy=v, xytext=(0, 0),
arrowprops=dict(arrowstyle='-|>', color=c, lw=2))
ax.text(*v * 1.08, name, color=c, fontsize=13)
ax.plot([b[0], p[0]], [b[1], p[1]], 'k:', lw=1.5) # লম্ব ডটেড লাইন
ax.set_aspect('equal'); ax.set_xlim(-1, 4); ax.set_ylim(-1, 3.5)
plt.show()
Output ব্যাখ্যা:
x_hat = 0.73মানে ছায়াটা \(a\)-এর দৈর্ঘ্যের \(73\%\) জায়গায় পড়েছে।a @ eপ্রায় \(0\) (floating point-এ \(10^{-16}\)-এর মতো) — Property 3 কোড নিজেই প্রমাণ করলো।- Pythagoras check-এ দুই পাশ মিলে যায়: \(\|b\|^2 = \|p\|^2 + \|e\|^2\) — কারণ \(p \perp e\)।
একটা সতর্কতা: a @ b হলো NumPy-তে dot product (Python 3.5+)। পুরনো কোডে np.dot(a, b) দেখবে — একই জিনিস।
৭. Worked Examples¶
Example 1 — হাতে হাতে projection¶
\(a = (4, 0)\), \(b = (3, 5)\)। ছায়া কত?
ধাপ ১: \(a^Tb = 4\cdot3 + 0\cdot5 = 12\) ধাপ ২: \(a^Ta = 16 + 0 = 16\) ধাপ ৩: \(\hat{x} = 12/16 = 0.75\) ধাপ ৪: \(\text{proj}_a(b) = 0.75\,(4,0) = (3, 0)\)
চোখ বন্ধ করেও বোঝা যায়: \(a\) তো x-অক্ষ বরাবর, তাই \(b=(3,5)\)-এর ছায়া হবে স্রেফ তার x-অংশ — \((3,0)\)। সূত্র আর intuition হাত মেলালো। Residual: \(e = (3,5)-(3,0) = (0,5)\), স্পষ্টতই \(a\)-এর ওপর লম্ব।
Example 2 — orthogonal কি না চেক + একটা অজানা বের করা¶
\(u = (2, -1, 3)\) ও \(v = (1, 5, k)\) কখন orthogonal?
Orthogonal হতে হলে \(-3 + 3k = 0 \Rightarrow k = 1\)। অর্থাৎ \(v=(1,5,1)\) হলে দুজন ঠিক সমকোণে। \(k\) এর একটু এদিক-ওদিক হলেই কোণ সূক্ষ্ম (\(k>1\)) বা স্থূল (\(k<1\)) হয়ে যায়।
Example 3 — ঢালু রাস্তায় গাড়ি (force ভাঙা)¶
একটা গাড়ির ওজন force \(F = (0, -10)\) (সোজা নিচে, একক kN)। রাস্তার ঢালের দিক \(d = (2, -1)\) (ডানে-নিচে)। রাস্তা-বরাবর টান কত?
ধাপ ১: \(d^TF = 0\cdot2 + (-10)(-1) = 10\) ধাপ ২: \(d^Td = 4 + 1 = 5\) ধাপ ৩: \(\text{proj}_d(F) = \frac{10}{5}(2,-1) = (4, -2)\)
রাস্তা-বরাবর টানের মাত্রা \(\|(4,-2)\| = \sqrt{20} \approx 4.47\) kN — এটাই গাড়িকে গড়িয়ে নামাতে চায়। বাকি অংশ \(F - (4,-2) = (-4,-8)\) রাস্তার ওপর লম্ব চাপ — ব্রেক আর টায়ারের ঘর্ষণ এটার ওপরই নির্ভর করে।
৮. Problems ও Solutions¶
Problem 1. নিচের জোড়াগুলোর কোনগুলো orthogonal? (a) \((1,2)\) ও \((-4,2)\) (b) \((3,0,1)\) ও \((1,5,-3)\) (c) \((1,1,1,1)\) ও \((1,-1,1,-1)\)
Solution
প্রতিটির dot product হিসাব করি:
(a) \(1\cdot(-4) + 2\cdot2 = -4+4 = 0\) ✓ orthogonal
(b) \(3\cdot1 + 0\cdot5 + 1\cdot(-3) = 3+0-3 = 0\) ✓ orthogonal
(c) \(1-1+1-1 = 0\) ✓ orthogonal
তিনটাই orthogonal! (c)-র জোড়াটা বিশেষ — এরকম \(\pm1\)-এর orthogonal পরিবার দিয়ে তৈরি হয় Hadamard matrix, যেটা টেলিযোগাযোগে (CDMA) ব্যবহৃত হয়।
Problem 2. \(b = (2, 6)\)-এর projection বের করো \(a = (1, 1)\)-এর লাইনের ওপর। Residual \(e\)-ও বের করো এবং দেখাও \(a^Te = 0\)।
Solution
যাচাই: \(a^Te = 1\cdot(-2) + 1\cdot2 = 0\) ✓
জ্যামিতিক অর্থ: \(45°\) লাইনের ওপর \((2,6)\)-এর ছায়া পড়ে \((4,4)\)-এ — লক্ষ্য করো \((4,4)\) হলো \(2\) আর \(6\)-এর গড় \(4\) দিয়ে গড়া। \((1,1)\)-এর ওপর projection মানেই আসলে গড় করা — Chapter 5.4-এ এই চমকটা আবার আসবে।
Problem 3. (Pythagoras উল্টোদিকে) দেখাও: যদি \(\|u+v\|^2 = \|u\|^2 + \|v\|^2\) হয়, তাহলে \(u \perp v\) হতেই হবে।
Solution
Norm-এর সংজ্ঞা খুলে লিখি:
দেওয়া শর্ত অনুযায়ী এটা \(\|u\|^2 + \|v\|^2\)-এর সমান। দুই পাশ থেকে \(\|u\|^2 + \|v\|^2\) বাদ দিলে:
অর্থাৎ \(u \perp v\)। ∎
তাই Pythagoras আসলে "যদি এবং কেবল যদি" (if and only if): সমকোণ ⇔ বর্গের যোগফল মিলে যাওয়া।
Problem 4. \(a\) ও \(b\) দুটোই nonzero। দেখাও যে residual-এর দৈর্ঘ্য \(\|e\| = \|b\|\,|\sin\theta|\), যেখানে \(\theta\) হলো \(a\) ও \(b\)-এর মধ্যকার কোণ। (VMLS exercise 12.1-এর আদলে)
Solution
ছায়ার ছবিটা মনে করো: \(b\), তার ছায়া \(p\), আর residual \(e\) মিলে একটা সমকোণী ত্রিভুজ, যার Hypotenuse(অতিভুজ) হলো \(b\)।
সমকোণী ত্রিভুজের ত্রিকোণমিতি থেকে:
- ছায়ার (ভূমির) দৈর্ঘ্য: \(\|p\| = \|b\|\,|\cos\theta|\)
- লম্বের দৈর্ঘ্য: \(\|e\| = \|b\|\,|\sin\theta|\)
Algebra দিয়েও করা যায়: Pythagoras (Property 1) থেকে
যেখানে \(\|p\| = \frac{|a^Tb|}{\|a\|} = \|b\||\cos\theta|\) এসেছে dot product-এর সংজ্ঞা \(a^Tb = \|a\|\|b\|\cos\theta\) থেকে। ∎
মানে: \(\theta\) ছোট হলে (প্রায় এক দিকে) ছায়া প্রায় পুরো \(b\)-কে ধরে ফেলে, ভুল (\(e\)) সামান্য। \(\theta = 90°\) হলে ছায়া শূন্য — \(a\) দিয়ে \(b\)-এর কিছুই ব্যাখ্যা করা যায় না।
Problem 5. \(\mathbb{R}^3\)-এ \(b = (1, 2, 3)\)-কে ভাঙো \(a = (1, 0, 1)\)-এর সমান্তরাল ও লম্ব দুই অংশে।
Solution
যাচাই ১: \(a^T b_{\perp} = -1 + 0 + 1 = 0\) ✓ যাচাই ২: \(b_{\parallel} + b_{\perp} = (1,2,3) = b\) ✓ যাচাই ৩ (Pythagoras): \(\|b\|^2 = 14\), আর \(\|b_\parallel\|^2 + \|b_\perp\|^2 = 8 + 6 = 14\) ✓
Problem 6. (সবচেয়ে কাছের প্রমাণ, algebra দিয়ে) লাইনের যেকোনো বিন্দু \(xa\)-এর জন্য দেখাও:
যেখানে \(p = \text{proj}_a(b)\), \(e = b - p\)। এর থেকে কী সিদ্ধান্তে আসা যায়?
Solution
কৌশল: \(xa - b\)-কে ভেঙে লিখি দুই টুকরোয়:
এখন \((xa - p)\) হলো \(a\)-এর লাইন-বরাবর একটা vector (দুটোই লাইনে আছে), আর \(e\) লাইনের ওপর লম্ব (Property 3)। তাই এরা orthogonal, এবং Pythagoras প্রয়োগ করা যায়:
সিদ্ধান্ত: ডান পাশের \(\|e\|^2\) অংশটা \(x\)-এর ওপর নির্ভরই করে না — ওটা fixed "ভাড়া"। শুধু \(\|xa-p\|^2\) অংশটা কমানো যায়, আর সেটা সবচেয়ে ছোট (শূন্য) হয় ঠিক তখন, যখন \(xa = p\)। অর্থাৎ projection-ই লাইনের ওপর সবচেয়ে কাছের বিন্দু — অন্য কোনো প্রার্থীর জেতার সুযোগই নেই। এই যুক্তিটাই Chapter 5.4-এ matrix আকারে ফিরে আসবে। ∎
Problem 7. Standard basis vector \(e_1 = (1,0,0)\), \(e_2 = (0,1,0)\), \(e_3 = (0,0,1)\)-এর ওপর \(b = (b_1, b_2, b_3)\)-এর projection কী কী? এর থেকে coordinate-এর নতুন ব্যাখ্যা দাও।
Solution
\(e_1\)-এর ওপর:
একইভাবে \(e_2\), \(e_3\)-এর ওপর projection যথাক্রমে \((0,b_2,0)\) ও \((0,0,b_3)\)।
নতুন ব্যাখ্যা: একটা vector-এর coordinate গুলো আসলে standard axis-গুলোর ওপর তার ছায়া। আর তিনটা ছায়া যোগ করলে পুরো vector ফিরে আসে:
এটা সম্ভব হলো কারণ axis-গুলো পরস্পর orthogonal। পরের chapter-এ দেখবে — যেকোনো orthonormal basis-এই এই জাদুটা কাজ করে, আর সেজন্যই আমরা Gram–Schmidt দিয়ে এমন basis বানাতে শিখবো।
Problem 8. (ধাঁধা) \(u\) vector-টা \(v_1\) ও \(v_2\) দুটোর সাথেই orthogonal। দেখাও, \(v_1\) ও \(v_2\)-এর যেকোনো linear combination \(c_1v_1 + c_2v_2\)-এর সাথেও \(u\) orthogonal। এর geometric মানে কী?
Solution
Dot product-এর linearity (Chapter 1.3) ব্যবহার করি:
Geometric মানে: \(u\) যদি দুটো vector-এর সাথে লম্ব হয়, তাহলে সে তাদের পুরো span-এর (তাদের টানা plane-এর) সাথেই লম্ব। ছাদের দুটো ভিন্ন দিকের কার্নিশের সাথে খুঁটি লম্ব হলে, খুঁটিটা গোটা ছাদের সাথেই লম্ব। এই পর্যবেক্ষণটাই Chapter 5.3-এর Orthogonal Complement-এর বীজ।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "Projection মানে \(b\)-কে ছোট করা" | Projection \(b\)-এর দৈর্ঘ্য কমাতেও পারে, নাও পারে — এমনকি \(b\) লাইনেই শুয়ে থাকলে ছায়া \(b\) নিজেই (\(\hat{x}\) ঋণাত্মকও হতে পারে!)। আসল কথা: ছায়া সবসময় \(a\)-এর লাইনে থাকে। |
| "\(\text{proj}_a(b)\) আর \(\text{proj}_b(a)\) একই জিনিস" | মোটেই না! প্রথমটা \(a\)-এর লাইনে, দ্বিতীয়টা \(b\)-এর লাইনে থাকে; দৈর্ঘ্যও আলাদা (\(\frac{a^Tb}{\|a\|}\) বনাম \(\frac{a^Tb}{\|b\|}\))। ছায়া কার ওপর পড়ছে সেটাই আসল। |
| "\(u^Tv = 0\) মানে \(u\) বা \(v\)-এর একটা zero vector" | দুটো দিব্যি nonzero হয়েও লম্ব হতে পারে: \((1,0)\) ও \((0,1)\)। সংখ্যার গুণে \(xy=0 \Rightarrow x=0\) বা \(y=0\) — vector-এ এই নিয়ম খাটে না। |
| "সূত্রে \(a^Ta\) দিয়ে ভাগ করতে ভুলে যাওয়া: \(\text{proj} = (a^Tb)\,a\)" | এটা শুধু তখন ঠিক যখন \(\|a\| = 1\)। সাধারণ \(a\)-এর জন্য \(a^Ta\) দিয়ে ভাগ বাধ্যতামূলক — নাহলে \(a\)-এর দৈর্ঘ্য দুইবার গুণে ঢুকে যায় (Property 5 দেখো)। |
| "Residual \(e = p - b\) না \(b - p\), কী যায় আসে" | দিক আলাদা হলেও \(\|e\|\) একই, তাই দূরত্বের হিসাবে সমস্যা নেই; কিন্তু চিহ্নের হিসাব (যেমন কোন পাশে ভুল) করতে গেলে convention ঠিক রাখো। আমরা সবসময় লিখবো \(e = b - p\): "আসল মাইনাস ছায়া"। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| Orthogonal | \(u^Tv = 0\) | সমকোণ, dot product-এর চিহ্ন = কোণের ধরন |
| Projection (ছায়া) | \(\text{proj}_a(b) = \dfrac{a^Tb}{a^Ta}\,a\) | দুপুরের রোদে মাটিতে ছায়া |
| Residual | \(e = b - \text{proj}_a(b)\), সর্বদা \(a \perp e\) | ছায়ায় ধরা-না-পড়া খাড়া অংশ |
| Decomposition | \(b = b_{\parallel} + b_{\perp}\) (unique) | ভাঙো, কাজ করো, জোড়ো |
| Pythagoras | \(u\perp v \Rightarrow \|u+v\|^2 = \|u\|^2+\|v\|^2\) | সমকোণী ত্রিভুজ |
| Closest point | projection-ই লাইনের সবচেয়ে কাছের বিন্দু | টানটান রাবার ব্যান্ড লম্ব হলে সবচেয়ে ছোট |
পরের chapter-এর সেতু: এক লাইনের ওপর ছায়া ফেলা শিখলে। কিন্তু যদি অনেকগুলো এলোমেলো, তির্যক vector থাকে — তাদের সবাইকে সুন্দর, পরস্পর-লম্ব, দৈর্ঘ্য-১ vector-এ সাজানো যায় কি? যায় — বারবার ছায়া বিয়োগ করে। সেই algorithm-এর নাম Gram–Schmidt, আর তার matrix-রূপ QR Decomposition — Chapter 5.2-এ দেখা হচ্ছে।
📓 Notebook Project¶
notebooks/part-05/ch01-project.ipynb — projection-কে scratch-এ implement করে GPS "snap-to-road" simulator বানাবে: এলোমেলো অবস্থান থেকে রাস্তার (লাইনের) সবচেয়ে কাছের বিন্দু খুঁজে ছবি আঁকা, সাথে Pythagoras আর orthogonality-র numerical যাচাই।