Chapter 3.5 — Transpose, Trace ও Special Matrices (matrix-দের পারিবারিক অ্যালবাম)¶
🎯 এই chapter-এ যা শিখবে¶
- Transpose(ট্রান্সপোজ) \(A^\top\) — row আর column-এর ভূমিকা বদল; কেন এটা "একই data, অন্য প্রশ্ন"
- Trace(ট্রেস) — diagonal-এর যোগফল, আর তার ছোট্ট অলৌকিকতা: \(\operatorname{tr}(AB) = \operatorname{tr}(BA)\)
- বিশেষ matrix-দের পারিবারিক অ্যালবাম: identity, diagonal, permutation, symmetric, triangular — প্রত্যেকের চেহারা, কাজ আর সুপারপাওয়ার
- Block matrix(ব্লক ম্যাট্রিক্স) — বিশাল matrix-কে ছোট ছোট খণ্ডে ভেঙে "সংখ্যার মতো" গুণ করা
- \((AB)^\top = B^\top A^\top\) — আবার সেই মোজা-জুতা, আর \(A^\top A\) কেন Data Science-এর সবচেয়ে ব্যস্ত matrix
🖼️ এক ছবিতে মূল idea¶
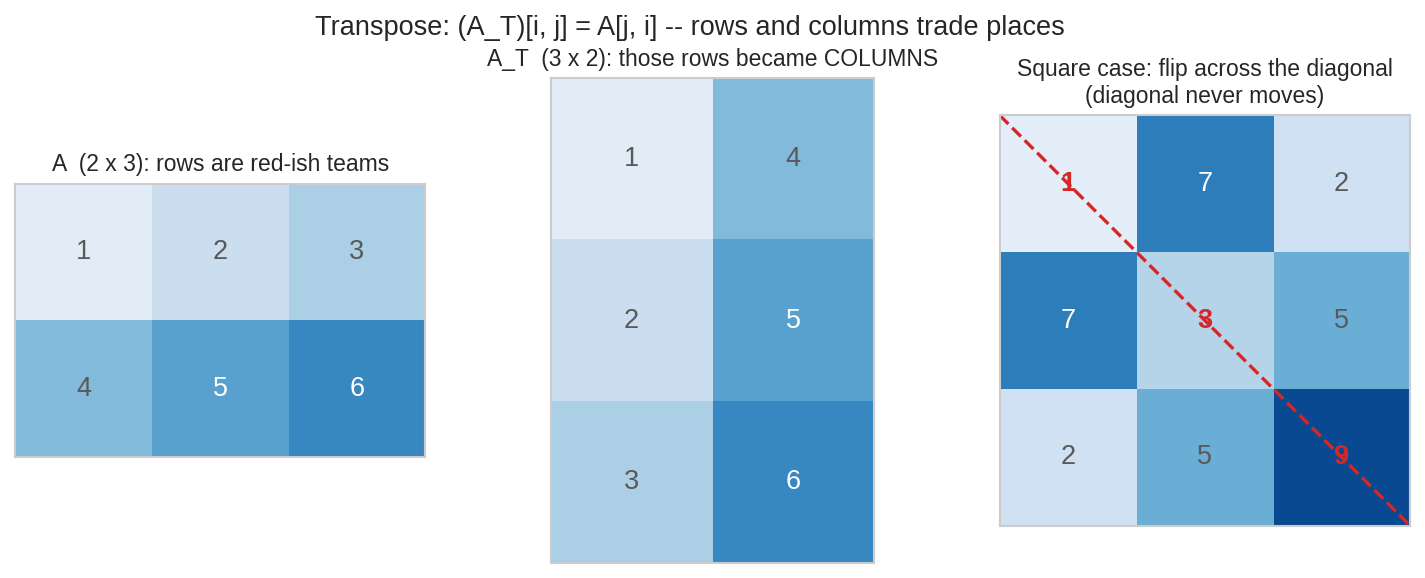
বাঁয়ে \(2\times3\) matrix \(A\); মাঝে তার transpose \(A^\top\) — প্রতিটা row উঠে দাঁড়িয়ে column হয়ে গেছে, আকারও উল্টে \(3\times2\)। ডানে square matrix-এর বেলায় ব্যাপারটা main diagonal(মূল কর্ণ) বরাবর আয়নায় ফেলা — লাল diagonal-এর সংখ্যাগুলো নট নড়নচড়ন। নিয়ম একটাই: \((A^\top)_{ij} = A_{ji}\)।
১. কি? (What)¶
দৈনন্দিন analogy: ধরো একটা attendance খাতা — প্রতি row একজন ছাত্র, প্রতি column একটা বিষয় (গণিত, বাংলা, ইংরেজি), ঘরে ঘরে নম্বর। ক্লাস টিচার পড়েন row ধরে: "রাহুল কেমন করছে সব বিষয়ে?" বিষয়-শিক্ষক পড়েন column ধরে: "গণিতে ক্লাসের অবস্থা কি?" এখন খাতাটাই যদি উল্টে লেখো — প্রতি row একটা বিষয়, প্রতি column একজন ছাত্র — data-র একটা দানাও বদলায়নি, শুধু কোন প্রশ্নটা সহজে পড়া যায় সেটা বদলেছে। এই উল্টে-লেখাটাই transpose।
সংজ্ঞা (Transpose): \(m \times n\) matrix \(A\)-এর transpose হলো \(n \times m\) matrix \(A^\top\), যেখানে
অর্থাৎ \(A\)-র \(i\)-তম row-টাই \(A^\top\)-এর \(i\)-তম column — আর উল্টোটাও।
সংজ্ঞা (Trace): Square matrix \(A\)-এর trace হলো main diagonal-এর entry-গুলোর যোগফল:
Trace-টা প্রথম দেখায় খেলনা মনে হয় — "diagonal যোগ করলাম, তো কি?" কিন্তু দেখবে (§৪.৪) multiplication-এর তুমুল বিশৃঙ্খলার মধ্যেও trace এমন একটা সংখ্যা যে টিকে থাকে — আর Part VI-এ গিয়ে জানবে সে আসলে eigenvalue-দের যোগফল, matrix-এর একটা গোপন আঙুলের ছাপ।
আর এই chapter-এর তৃতীয় চরিত্র — বিশেষ matrix-রা। সাধারণ matrix মানে সাধারণ মানুষ; কিন্তু কিছু matrix-এর চেহারায় এত শৃঙ্খলা যে তাদের সাথে কাজ করা দশগুণ সহজ। গণিতবিদদের কৌশলের অর্ধেকটাই হলো: যেকোনো কঠিন matrix-কে এই সহজ চরিত্রগুলোর সাজে ভেঙে ফেলা (Part V–VI ভর্তি এই খেলা)। তাই আগে পরিবারটাকে চেনা দরকার।
২. দেখতে কেমন?¶
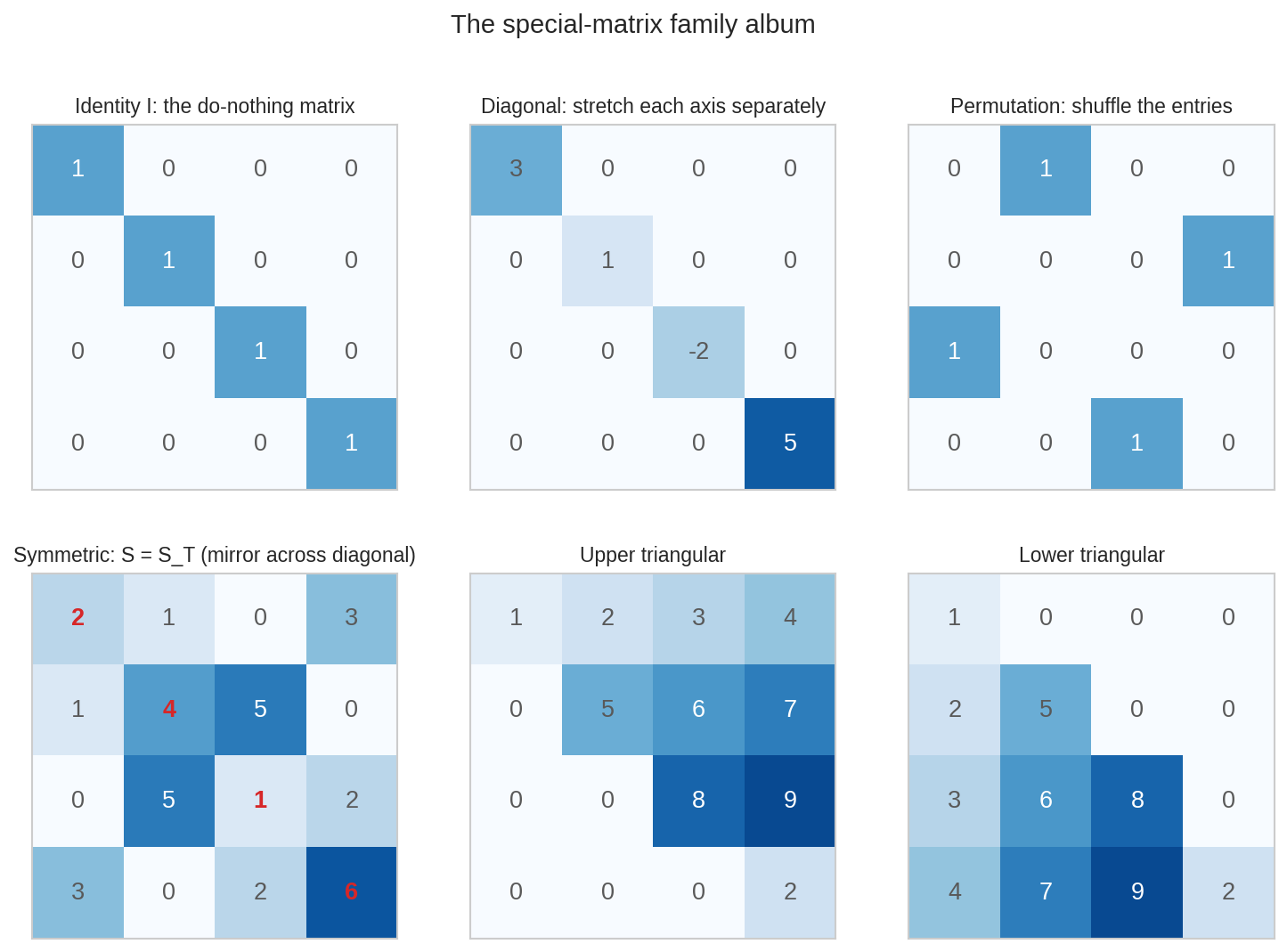
ছয় সদস্যের অ্যালবাম। Identity \(I\): diagonal-এ \(1\), বাকি সব \(0\) — "কিছু কোরো না" matrix। Diagonal: শুধু diagonal-এ প্রাণ — প্রতিটা অক্ষকে আলাদা করে টানা/চাপা। Permutation: প্রতি row ও column-এ ঠিক একটা \(1\) — entry-দের জায়গা বদলের যন্ত্র। Symmetric: diagonal-আয়নায় নিজের প্রতিবিম্ব নিজেই (\(S = S^\top\))। Upper/Lower triangular: diagonal-এর এক পাশ পুরো ফাঁকা — Part II-এর elimination-এর শেষ চেহারাটা মনে করিয়ে দেয়।
শুধু চেহারা নয় — plane-এর ওপর এদের আচরণ-ও দেখে নাও:
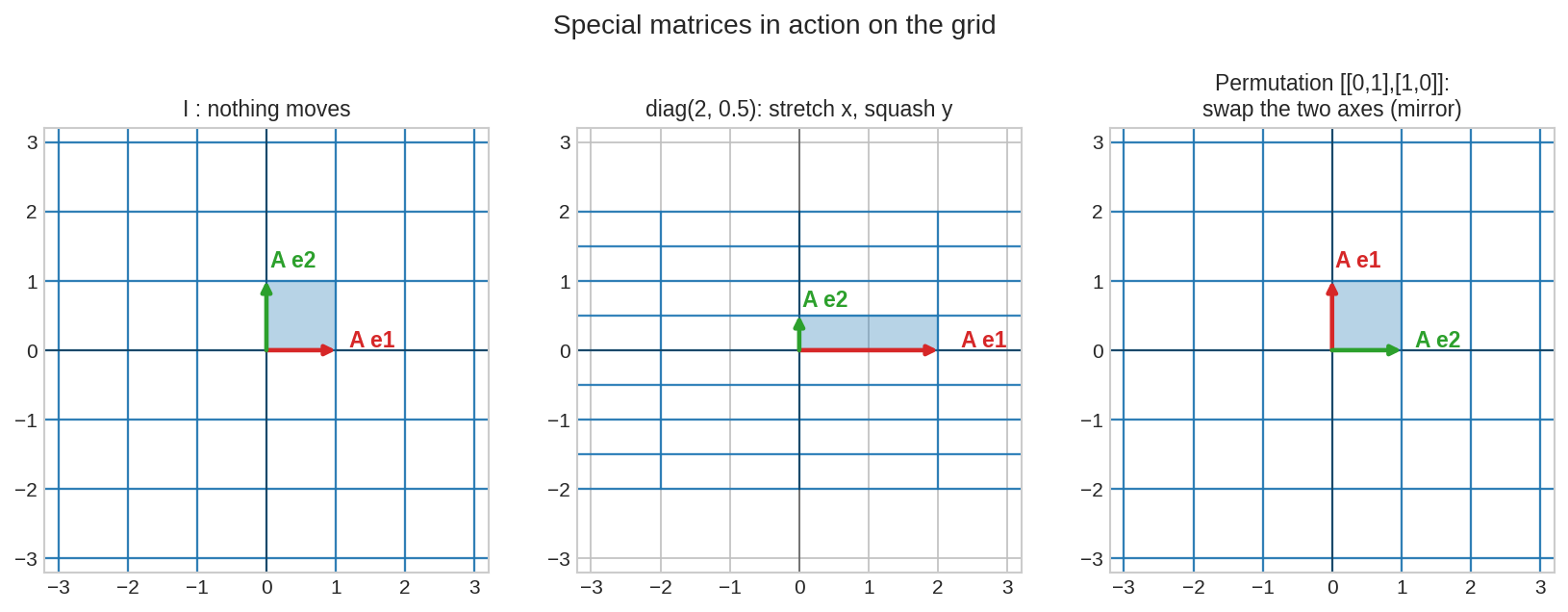
বাঁয়ে \(I\): গ্রিড অনড় — একমাত্র matrix যে সত্যিই "কিছু করে না।" মাঝে \(\operatorname{diag}(2, 0.5)\): অক্ষ বরাবর টানা-চাপা — Chapter 3.2-এর scaling-রা আসলে diagonal পরিবার। ডানে permutation \(\begin{bmatrix}0&1\\1&0\end{bmatrix}\): দুই অক্ষের জায়গা বদল — যেটাকে Chapter 3.1-এ চিনেছিলে \(y=x\) reflection নামে।
৩. কোথায় ইউজ হয়?¶
- Dot product-এর নতুন পোশাক: দুই column vector-এর dot product এখন লেখা যায় \(\mathbf{x}\cdot\mathbf{y} = \mathbf{x}^\top\mathbf{y}\) — Part I-এর সেই হিসাবটা matrix multiplication-এর ভাষায় ঢুকে গেল। এই ছোট্ট পোশাক-বদল পুরো subject-এর notation সচল রাখে।
- Data Science-এর ব্যস্ততম গুণফল \(X^\top X\): dataset \(X\)-এ প্রতি row একটা observation, প্রতি column একটা feature। \(X^\top X\)-এর \((i,j)\) ঘরে বসে feature \(i\) ও feature \(j\)-র dot product — অর্থাৎ পুরো matrix-টা feature-দের পারস্পরিক সম্পর্কের টেবিল (covariance matrix-এর কঙ্কাল, PCA-র শুরু, regression-এর normal equation — সব এখানে)। আর সে সবসময় symmetric (Problem 2-এ প্রমাণ করবে)।
- Permutation: dataset shuffle করা, deck-এর তাস ফেঁটানো, elimination-এ row অদলবদল (Part II-তে করেছিলে!) — সবই permutation matrix-এর গুণ।
- Symmetric matrix সর্বত্র: দূরত্বের টেবিল (ঢাকা→খুলনা = খুলনা→ঢাকা), friendship network-এর adjacency matrix, covariance — সম্পর্ক যেখানে দ্বিমুখী, matrix সেখানে symmetric। Part VI-এ দেখবে symmetric matrix-দের জন্য প্রকৃতি সবচেয়ে সুন্দর উপহারটা রেখেছে (spectral theorem)।
- Block matrix: GPU-তে বিশাল matrix গুণ হয় block-এ ভেঙে (memory-তে ধরে না বলে); deep learning-এর multi-head attention-ও আসলে block-চিন্তা; আর তত্ত্বেও বড় প্রমাণ ছোট block-এ ভাঙলে সহজ হয়।
- Triangular matrix: elimination-এর ফসল (\(LU\) decomposition, Part V) — triangular system solve করা লাগে মাত্র এক পাসে, তাই সংখ্যাগত জগতের প্রিয় চেহারা।
৪. Properties¶
৪.১ Transpose-এর নিয়মকানুন¶
| Property | সূত্র | মন্তব্য |
|---|---|---|
| দুইবার উল্টালে আসল | \((A^\top)^\top = A\) | আয়নার আয়না |
| যোগের সাথে বন্ধুত্ব | \((A + B)^\top = A^\top + B^\top\) | কোনো চমক নেই |
| Scalar | \((cA)^\top = cA^\top\) | কোনো চমক নেই |
| গুণের সাথে মোজা-জুতা | \((AB)^\top = B^\top A^\top\) ⚠️ | ক্রম উল্টে যায় — ঠিক \((AB)^{-1}\)-এর মতো! |
| Inverse-এর সাথে | \((A^{-1})^\top = (A^\top)^{-1}\) | transpose আর inverse-এর ক্রম অদলবদলযোগ্য |
\((AB)^\top = B^\top A^\top\) কেন — আকার দিয়েই প্রথম সন্দেহ: \(A\) হলো \(m\times n\), \(B\) হলো \(n \times p\) হলে \((AB)^\top\) হয় \(p \times m\); আর ডান পাশে \(B^\top A^\top = (p\times n)(n \times m) = p \times m\) ✓ — কিন্তু \(A^\top B^\top\) জোড়াই লাগে না! পুরো প্রমাণটা §৫-এ।
৪.২ Symmetric matrix: \(S^\top = S\)¶
- সংজ্ঞামতেই square হতে হবে, আর \(s_{ij} = s_{ji}\) — উপরের ত্রিভুজ জানলেই নিচেরটা free।
- যেকোনো matrix \(A\)-র জন্য \(A^\top A\) ও \(AA^\top\) দুটোই symmetric — অসামঞ্জস্যপূর্ণ কাঁচামাল থেকেও নিখুঁত প্রতিসাম্য (Problem 2)।
- যেকোনো square matrix ভাঙা যায় symmetric + antisymmetric অংশে (Problem 6) — যেমন যেকোনো function ভাঙে even + odd-এ।
৪.৩ Diagonal, permutation, triangular — কার কি সুপারপাওয়ার¶
- Diagonal: \(\operatorname{diag}(d_1, \dots, d_n)\) দিয়ে গুণ মানে \(i\)-তম অক্ষে \(d_i\) গুণ টান — এতটুকুই। দুই diagonal-এর গুণফল আবার diagonal, আর তারা নিজেদের মধ্যে commute করে (\(D_1D_2 = D_2D_1\) — বিরল সৌজন্য!)। Inverse: \(\operatorname{diag}(1/d_1, \dots, 1/d_n)\) — কোনো \(d_i = 0\) না হলে। Power: \(D^k = \operatorname{diag}(d_1^k, \dots, d_n^k)\) — এই সহজ power-এর লোভেই Part VI-এ সব matrix-কে diagonal বানানোর চেষ্টা করব (diagonalization)!
- Permutation: identity-র row-গুলো ঘুঁটে দিলেই permutation matrix। \(P\mathbf{x}\) মানে \(\mathbf{x}\)-এর entry-দের সেই ঘুঁটুনিতে সাজানো। দুর্দান্ত ধর্ম: \(P^{-1} = P^\top\) — ঘুঁটে ফেরত আনতে transpose-ই যথেষ্ট (Part V-এর orthogonal matrix-দের প্রথম দর্শন)।
- Triangular: গুণেও triangular থাকে; diagonal entry-রা সবাই nonzero হলেই invertible — এক নজরে বলা যায় (Part VI-এ দেখবে determinant = diagonal-এর গুণফল)।
৪.৪ Trace-এর ধর্ম — আর তার ছোট্ট অলৌকিকতা¶
এগুলো সোজা। আসল রত্নটা হলো:
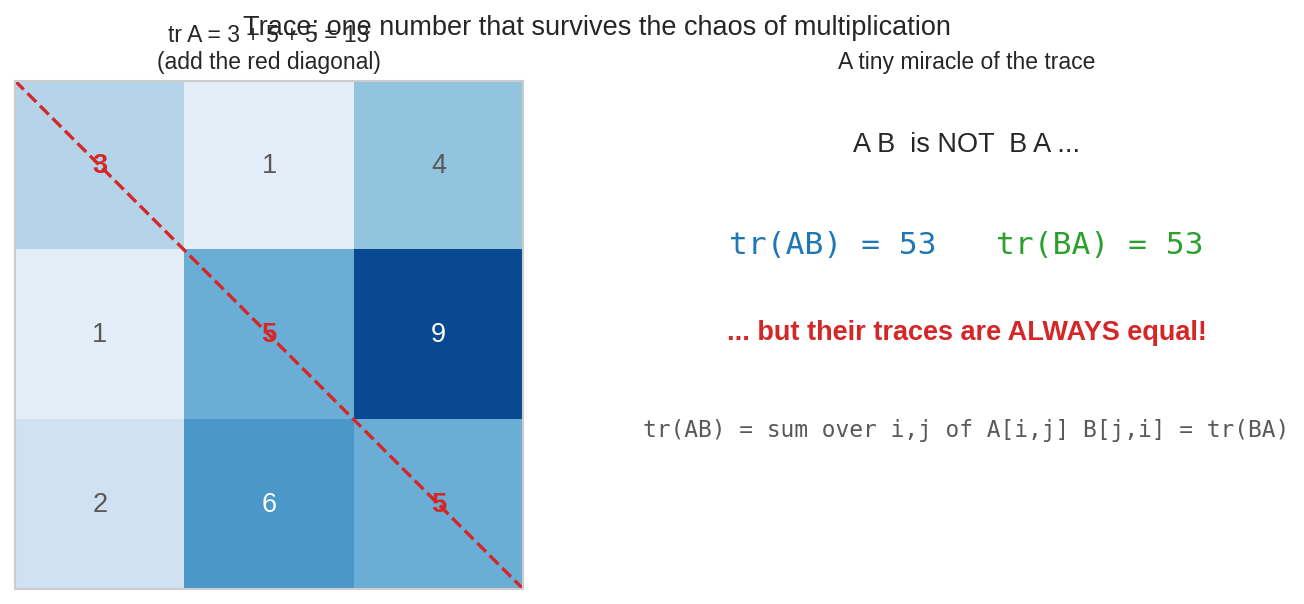
বাঁয়ে: trace মানে লাল diagonal ধরে যোগ — \(\operatorname{tr} = 3+5+5 = 13\)। ডানে: \(AB\) আর \(BA\) পুরোপুরি ভিন্ন matrix, অথচ দুজনের trace হুবহু সমান। প্রমাণটা এক লাইনের (§৫) — কিন্তু ফলটা গভীর: ML-এর কত হিসাব এই এক নিয়মে সস্তা হয়ে যায়।
৪.৫ Block matrix: zoom out করে দেখা¶
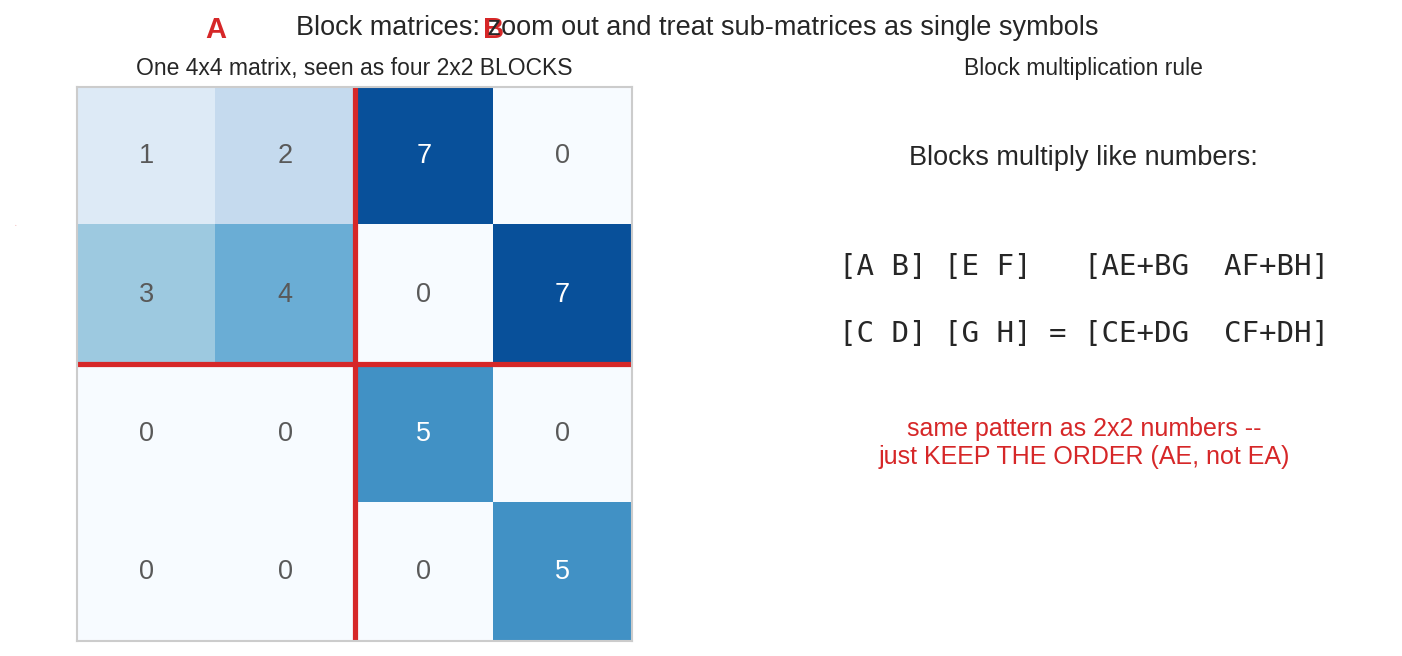
বাঁয়ে: একটা \(4\times4\) matrix-কে লাল দাগে চারটা \(2\times2\) block-এ ভাগ করা হয়েছে। ডানে: জাদুটা — block-রা সংখ্যার মতোই গুণ হয়: \(\begin{bmatrix}A & B\\ C & D\end{bmatrix}\begin{bmatrix}E & F\\ G & H\end{bmatrix} = \begin{bmatrix}AE+BG & AF+BH\\ CE+DG & CF+DH\end{bmatrix}\) — হুবহু \(2\times2\) সংখ্যার নিয়ম, শুধু একটাই সাবধানতা: ভেতরের গুণগুলোর ক্রম বদলানো যাবে না (\(AE\), কখনো \(EA\) নয়), কারণ block-রা তো matrix — commute করে না!
Block-চিন্তার শক্তি: \(\begin{bmatrix}A & 0\\ 0 & B\end{bmatrix}\) আকারের (block diagonal) matrix মানে দুটো স্বাধীন transformation পাশাপাশি চলছে, কেউ কারো এলাকায় ঢোকে না — inverse-ও তখন block ধরে ধরে: \(\begin{bmatrix}A^{-1} & 0\\ 0 & B^{-1}\end{bmatrix}\)।
৫. Intuition — কেন সত্য?¶
\((AB)^\top = B^\top A^\top\) — মোজা-জুতা আবার কেন? Entry ধরে দুই লাইনেই দেখা যায়। \((AB)^\top\)-এর \((i,j)\) ঘরে থাকে \((AB)_{ji}\) = (\(A\)-র \(j\)-তম row) \(\cdot\) (\(B\)-র \(i\)-তম column)। আর \(B^\top A^\top\)-এর \((i,j)\) ঘরে থাকে (\(B^\top\)-এর \(i\)-তম row) \(\cdot\) (\(A^\top\)-এর \(j\)-তম column) = (\(B\)-র \(i\)-তম column) \(\cdot\) (\(A\)-র \(j\)-তম row) — dot product-এর দুই পক্ষ শুধু জায়গা বদল করেছে, ফল একই ✓। গল্পটা আসলে এই: transpose করলে "row-এর চাকরি" আর "column-এর চাকরি" অদলবদল হয়ে যায়, তাই গুণের দুই পক্ষকেও নিজেদের জায়গা বদলাতে হয়।
Transpose-এর আসল পরিচয় (একটু গভীর জল): transpose শুধু "সংখ্যা উল্টে লেখা" নয় — তার একটা জ্যামিতিক চরিত্র আছে। যেকোনো \(\mathbf{x}, \mathbf{y}\)-এর জন্য:
অর্থাৎ dot product-এর এক পাশ থেকে \(A\)-কে অন্য পাশে সরাতে চাইলে তাকে transpose পরে যেতে হয়। \(A^\top\) হলো "dot product-এর আয়নায় \(A\)-র প্রতিবিম্ব।" Part V-এ least squares আর projection-এর পুরো গল্পটা এই এক লাইনের ওপর দাঁড়াবে — এখন শুধু চিনে রাখো।
\(\operatorname{tr}(AB) = \operatorname{tr}(BA)\) — এক লাইনের জাদু: দুটোই আসলে একই যোগফল, শুধু দুই ক্রমে করা:
মাঝের ধাপে শুধু যোগের ক্রম বদলেছে — প্রতিটা টার্ম \(a_{ik}b_{ki}\) দুই হিসাবেই ঠিক একবার করে আসে। \(AB \ne BA\) হওয়ার কারণ ছিল কোন টার্ম কোন ঘরে বসে সেটা বদলে যাওয়া; কিন্তু trace তো সব ঘর দেখে না — সে শুধু মোট যোগফল নেয়, আর মোটটা এক।
Permutation-এ \(P^\top = P^{-1}\) কেন? \(P\)-এর প্রতিটা column একটা \(\mathbf{e}_j\) — শুধু অন্য ক্রমে সাজানো। \(P^\top P\)-এর \((i,j)\) ঘর = (\(P\)-র \(i\)-তম column)\(\cdot\)(\(P\)-র \(j\)-তম column) — ভিন্ন দুটো standard basis vector-এর dot product \(0\), নিজের সাথে নিজের \(1\)। ফলে \(P^\top P = I\) — সংজ্ঞামতেই \(P^\top\) হলো inverse। জ্যামিতিক গল্প: ঘুঁটে দেওয়া জিনিস ফেরত আনতে "কে কোথা থেকে এসেছিল"-র তালিকাটাই উল্টো করে পড়ো — সেটাই transpose।
৬. Code-এ কেমনে লিখে¶
import numpy as np
A = np.array([[1, 2, 3],
[4, 5, 6]])
print(A.T) # transpose: (3, 2) -- .T যথেষ্ট
print(A.shape, A.T.shape) # (2, 3) (3, 2)
# (AB)^T == B^T A^T -- মোজা-জুতা যাচাই
rng = np.random.default_rng(42)
B = rng.integers(0, 5, size=(3, 4))
print(np.array_equal((A @ B).T, B.T @ A.T)) # True
# X^T X সবসময় symmetric -- data matrix দিয়ে পরীক্ষা
X = rng.normal(size=(50, 3)) # ৫০ observation, ৩ feature
G = X.T @ X # 3x3: feature-সম্পর্কের টেবিল
print(np.allclose(G, G.T)) # True -- নিখুঁত প্রতিসাম্য
# trace আর তার অলৌকিকতা
P = rng.normal(size=(4, 4)); Q = rng.normal(size=(4, 4))
print(np.trace(P @ Q), np.trace(Q @ P)) # দুটো একই সংখ্যা!
print(np.allclose(P @ Q, Q @ P)) # False -- অথচ matrix দুটো ভিন্ন
Output ব্যাখ্যা: .T attribute-এই transpose — কোনো কপি পর্যন্ত হয় না, NumPy শুধু "পড়ার দিক" উল্টে দেয় (তাই বিশাল matrix-এও .T ফ্রি!)। মোজা-জুতা নিয়ম আর \(X^\top X\)-এর প্রতিসাম্য দুটোই True। শেষ দুই লাইন সবচেয়ে মজার: P @ Q আর Q @ P ভিন্ন matrix (allclose → False), কিন্তু trace দুটো হুবহু সমান।
# special matrix-রা এক লাইনে
I = np.eye(4) # identity
D = np.diag([3, 1, -2, 5]) # diagonal বানানো
print(np.diag(D)) # diagonal বের করা -- একই ফাংশন, দুই মুখ!
perm = [2, 0, 3, 1] # নতুন ক্রম
P = np.eye(4)[perm] # identity-র row ঘুঁটলেই permutation
x = np.array([10.0, 20.0, 30.0, 40.0])
print(P @ x) # [30. 10. 40. 20.] -- entry ঘুঁটে গেল
print(np.allclose(P.T @ P, np.eye(4))) # True: P^T = P^{-1}
# block matrix জোড়া লাগানো
Z = np.zeros((2, 2)); S = np.array([[0, 1], [1, 0]])
M = np.block([[2 * np.eye(2), Z], [Z, S]])
print(M) # block-diagonal: উপরে scaling, নিচে swap
লক্ষ করো np.diag-এর দুই রূপ: vector দিলে diagonal matrix বানায়, matrix দিলে diagonal বের করে। আর np.eye(4)[perm] — identity-র row-ঘুঁটুনি — permutation matrix বানানোর সবচেয়ে সৎ উপায়: চেহারাতেই সংজ্ঞা।
৭. Worked Examples¶
Example 1 — transpose হাতে-কলমে, আর মোজা-জুতার যাচাই। \(A = \begin{bmatrix}1 & 2\\ 0 & 1\end{bmatrix}\), \(B = \begin{bmatrix}3 & 0\\ 1 & 2\end{bmatrix}\)।
ধাপ ১: \(AB = \begin{bmatrix}(1)(3)+(2)(1) & (1)(0)+(2)(2)\\ (0)(3)+(1)(1) & (0)(0)+(1)(2)\end{bmatrix} = \begin{bmatrix}5 & 4\\ 1 & 2\end{bmatrix}\), তাই \((AB)^\top = \begin{bmatrix}5 & 1\\ 4 & 2\end{bmatrix}\)। ধাপ ২: \(B^\top A^\top = \begin{bmatrix}3 & 1\\ 0 & 2\end{bmatrix}\begin{bmatrix}1 & 0\\ 2 & 1\end{bmatrix} = \begin{bmatrix}3+2 & 0+1\\ 0+4 & 0+2\end{bmatrix} = \begin{bmatrix}5 & 1\\ 4 & 2\end{bmatrix}\) ✓ মিলল। ধাপ ৩ (ভুল পথটাও দেখো): \(A^\top B^\top = \begin{bmatrix}1 & 0\\ 2 & 1\end{bmatrix}\begin{bmatrix}3 & 1\\ 0 & 2\end{bmatrix} = \begin{bmatrix}3 & 1\\ 6 & 4\end{bmatrix}\) — মেলে না! ক্রম না উল্টালে ভুল উত্তর।
Example 2 — কে symmetric, কে নয়, আর কাকে symmetric বানানো যায়। \(S = \begin{bmatrix}2 & 7\\ 7 & -1\end{bmatrix}\), \(T = \begin{bmatrix}1 & 4\\ 2 & 3\end{bmatrix}\)।
ধাপ ১: \(S^\top = \begin{bmatrix}2 & 7\\ 7 & -1\end{bmatrix} = S\) — symmetric ✓ (\(s_{12} = s_{21} = 7\))। \(T^\top = \begin{bmatrix}1 & 2\\ 4 & 3\end{bmatrix} \ne T\) — নয় (\(4 \ne 2\))। ধাপ ২: কিন্তু \(T\) থেকেও প্রতিসাম্য বানানো যায়: \(T^\top T = \begin{bmatrix}1 & 2\\ 4 & 3\end{bmatrix}\begin{bmatrix}1 & 4\\ 2 & 3\end{bmatrix} = \begin{bmatrix}5 & 10\\ 10 & 25\end{bmatrix}\) — symmetric! \((1,2)\) আর \((2,1)\) ঘরে একই \(10\): দুটোই আসলে (\(T\)-এর col\(_1\))\(\cdot\)(\(T\)-এর col\(_2\)) — dot product-এর ক্রম-নিরপেক্ষতাই প্রতিসাম্যের উৎস।
Example 3 — block দিয়ে বড় গুণ ছোট করা। \(M = \begin{bmatrix}2I & 0\\ 0 & S\end{bmatrix}\) যেখানে \(I\) হলো \(2\times2\) identity, \(S = \begin{bmatrix}0 & 1\\ 1 & 0\end{bmatrix}\), \(0\) হলো \(2\times2\) zero block। \(M^2\) বের করি।
ধাপ ১ — block-দের সংখ্যার মতো গুণ:
ধাপ ২ — মানে পড়ো: উপরের block-জগতে "৪ গুণ scaling", নিচের জগতে "দুইবার swap = কিছুই না"। \(4\times4\)-এর ষোলটা ঘরের হিসাব নেমে এলো দুটো \(2\times2\) গল্পে — দুই স্বাধীন উপ-জগৎ, যে যার মতো চলে। এটাই block-diagonal-এর আসল সুখ।
৮. Problems ও Solutions¶
Problem 1. \(A = \begin{bmatrix}1 & 0 & -2\\ 3 & 5 & 4\end{bmatrix}\)। (a) \(A^\top\) লেখো ও আকার বলো। (b) \((A^\top)_{31}\) কত? (c) \(AA^\top\) ও \(A^\top A\)-এর আকার কত — কোনটা feature-সম্পর্ক, কোনটা observation-সম্পর্ক (row = observation ধরে)?
Solution
(a) Row-রা column হয়ে দাঁড়ায়:
(b) \((A^\top)_{31} = A_{13} = -2\) — index দুটো শুধু জায়গা বদল করে।
(c) \(AA^\top\): \((2\times3)(3\times2) = 2\times2\) — দুই row (observation)-এর পারস্পরিক dot product-এর টেবিল। \(A^\top A\): \((3\times2)(2\times3) = 3\times3\) — তিন column (feature)-এর সম্পর্কের টেবিল। একই data, দুই প্রশ্ন — কে কার সাথে মিলছে: মানুষ, না মাপকাঠি?
Problem 2. প্রমাণ করো: যেকোনো matrix \(A\)-র জন্য \(A^\top A\) symmetric। (Hint: \((A^\top A)^\top\) বের করো মোজা-জুতা দিয়ে।)
Solution
Symmetric প্রমাণ করতে হবে মানে দেখাতে হবে transpose করলে নিজেই ফেরে:
প্রথম ধাপে মোজা-জুতা নিয়ম (\((XY)^\top = Y^\top X^\top\), এখানে \(X = A^\top\), \(Y = A\)), দ্বিতীয় ধাপে \((A^\top)^\top = A\)। দুই লাইনে শেষ — আর ফলটা Data Science-এর প্রতিদিনের ভরসা: covariance matrix, normal equation-এর \(X^\top X\), kernel matrix — সবার প্রতিসাম্যের গ্যারান্টি এই দুই লাইন। (একই যুক্তিতে \(AA^\top\)-ও symmetric।)
Problem 3. \(A = \begin{bmatrix}2 & 1\\ 0 & 3\end{bmatrix}\), \(B = \begin{bmatrix}1 & 4\\ 2 & 1\end{bmatrix}\)। (a) \(\operatorname{tr}(A)\), \(\operatorname{tr}(B)\), \(\operatorname{tr}(A+B)\) বের করে যোগ-নিয়ম যাচাই করো। (b) \(AB\) ও \(BA\) পুরো বের করে দেখাও matrix দুটো ভিন্ন কিন্তু trace সমান। (c) \(\operatorname{tr}(AB) = \operatorname{tr}(A)\operatorname{tr}(B)\) হয় কি?
Solution
(a) \(\operatorname{tr}(A) = 2 + 3 = 5\), \(\operatorname{tr}(B) = 1 + 1 = 2\); \(A + B = \begin{bmatrix}3 & 5\\ 2 & 4\end{bmatrix}\), trace \(= 7 = 5 + 2\) ✓।
(b)
সম্পূর্ণ ভিন্ন matrix; কিন্তু \(\operatorname{tr}(AB) = 4 + 3 = 7\) আর \(\operatorname{tr}(BA) = 2 + 5 = 7\) — সমান ✓।
(c) না: \(\operatorname{tr}(A)\operatorname{tr}(B) = 5 \times 2 = 10 \neq 7\)। Trace যোগে বন্ধু, গুণে নয় — সে শুধু \(AB \leftrightarrow BA\) অদলবদলটা মাফ করে।
Problem 4. Permutation matrix \(P = \begin{bmatrix}0 & 1 & 0\\ 0 & 0 & 1\\ 1 & 0 & 0\end{bmatrix}\)। (a) \(P\begin{bmatrix}a\\ b\\ c\end{bmatrix}\) কত — ঘুঁটুনিটা কি? (b) \(P^2\) ও \(P^3\) বের করো। (c) \(P^{-1}\) কে? — \(P^\top\) বের করে দেখাও সে-ই।
Solution
(a) Row picture-এ: ১ম output = ২য় entry, ২য় output = ৩য় entry, ৩য় output = ১ম entry:
— সবাই এক ঘর করে এগিয়ে এলো (cyclic shift)।
(b) আরেকবার ঘোরাও: \(P^2\begin{bmatrix}a\\b\\c\end{bmatrix} = \begin{bmatrix}c\\ a\\ b\end{bmatrix}\), অর্থাৎ \(P^2 = \begin{bmatrix}0 & 0 & 1\\ 1 & 0 & 0\\ 0 & 1 & 0\end{bmatrix}\); আর তৃতীয়বারে সবাই বাড়ি: \(P^3 = I\) — তিনজনের গোল-চক্কর তিন ধাপে সম্পূর্ণ।
(c) \(P^3 = I\) মানে \(P \cdot P^2 = I\), তাই \(P^{-1} = P^2\)। আর
— ঘুঁটে ফেরানোর তালিকা = transpose, হিসাব ছাড়াই।
Problem 5. Column vector \(\mathbf{x} = \begin{bmatrix}1\\ 2\end{bmatrix}\), \(\mathbf{y} = \begin{bmatrix}3\\ -1\end{bmatrix}\)। (a) \(\mathbf{x}^\top\mathbf{y}\) বের করো — এটা কি? (b) \(\mathbf{x}\mathbf{y}^\top\) বের করো — আকার কত? (c) দুটোর এত পার্থক্য কেন — আকারের হিসাব দিয়ে ব্যাখ্যা করো।
Solution
(a) \(\mathbf{x}^\top\mathbf{y} = (1\times2)(2\times1) = 1\times1\) — একটা সংখ্যা: \((1)(3) + (2)(-1) = 1\)। এটাই dot product \(\mathbf{x}\cdot\mathbf{y}\), matrix-পোশাকে।
(b) \(\mathbf{x}\mathbf{y}^\top = (2\times1)(1\times2) = 2\times2\) — আস্ত একটা matrix:
(একে বলে outer product(বাইরের গুণফল); লক্ষ করো এর column-রা সব \(\mathbf{x}\)-এর গুণিতক — plane-চুপসানো singular matrix! Part VI-এ rank-1 matrix নামে বড় ভূমিকায় ফিরবে।)
(c) ভেতরের মাপ মেলা-না-মেলার খেলা: \(\mathbf{x}^\top\mathbf{y}\)-তে ভেতরে \(2, 2\) — সব চুপসে \(1\times1\); \(\mathbf{x}\mathbf{y}^\top\)-তে ভেতরে \(1, 1\) — বাইরে ছড়িয়ে \(2\times2\)। একই দুই vector, শুধু transpose কার গায়ে — আর ফল সংখ্যা বনাম matrix!
Problem 6. যেকোনো square matrix \(A\)-কে লেখা যায় \(A = S + K\), যেখানে \(S = \frac{A + A^\top}{2}\) আর \(K = \frac{A - A^\top}{2}\)। (a) দেখাও \(S\) symmetric আর \(K^\top = -K\) (antisymmetric)। (b) \(A = \begin{bmatrix}3 & 5\\ 1 & 2\end{bmatrix}\) ভেঙে দেখাও। (c) \(K\)-র diagonal-এ কি বসতে বাধ্য?
Solution
(a)
আর \(S + K = \frac{A + A^\top + A - A^\top}{2} = A\) ✓ — ভাগাভাগি নিখুঁত।
(b) \(A^\top = \begin{bmatrix}3 & 1\\ 5 & 2\end{bmatrix}\):
যাচাই: \(S + K = \begin{bmatrix}3 & 5\\ 1 & 2\end{bmatrix} = A\) ✓।
(c) \(K^\top = -K\) মানে diagonal-এ \(k_{ii} = -k_{ii}\), অর্থাৎ \(2k_{ii} = 0\) — diagonal-এ শূন্য ছাড়া কিছু বসতেই পারে না। (b)-তে তাই-ই দেখা গেছে। (এই ভাঙা-বিদ্যার দাম Part VI-এ: symmetric অংশ "টান", antisymmetric অংশ "ঘূর্ণি" — প্রতিটা transformation-এর দুই মেজাজ।)
Problem 7 (সত্য/মিথ্যা — কারণসহ)। (a) Diagonal matrix-রা সবসময় সবার সাথে commute করে। (b) দুটো symmetric matrix-এর গুণফল সবসময় symmetric। (c) Triangular matrix invertible কিনা বলতে diagonal দেখাই যথেষ্ট।
Solution
(a) মিথ্যা। নিজেদের মধ্যে commute করে ঠিকই, কিন্তু সবার সাথে না: \(D = \begin{bmatrix}2 & 0\\ 0 & 3\end{bmatrix}\), \(S = \begin{bmatrix}1 & 1\\ 0 & 1\end{bmatrix}\) নাও — Chapter 3.3-এর Problem 4-এই দেখেছিলে \(DS = \begin{bmatrix}2 & 2\\ 0 & 3\end{bmatrix} \neq \begin{bmatrix}2 & 3\\ 0 & 3\end{bmatrix} = SD\)। (সবার সাথে commute করে কেবল \(cI\) — uniform scaling-রা।)
(b) মিথ্যা। \(A = \begin{bmatrix}1 & 0\\ 0 & -1\end{bmatrix}\), \(B = \begin{bmatrix}0 & 1\\ 1 & 0\end{bmatrix}\) — দুজনেই symmetric, কিন্তু \(AB = \begin{bmatrix}0 & 1\\ -1 & 0\end{bmatrix}\) — symmetric নয় (\(1 \ne -1\))! আসলে \((AB)^\top = B^\top A^\top = BA\); সেটা \(AB\)-র সমান হবে তখনই যখন \(A, B\) commute করে — যা বিশেষ সৌভাগ্য।
(c) সত্য। Triangular matrix-এ elimination আগেই সারা: diagonal-এর প্রতিটা entry nonzero হলে প্রতিটা pivot বহাল — সমাধান সবসময় একটাই, matrix invertible। কোনো diagonal entry \(0\) হলে সেই ধাপে pivot হারায় — singular। (Part VI-এ এক লাইনে বলবে: triangular-এর determinant = diagonal-এর গুণফল।)
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ ঠিক ধারণা |
|---|---|
| \((AB)^\top = A^\top B^\top\) | মোজা-জুতা: \((AB)^\top = B^\top A^\top\) — inverse-এর মতোই ক্রম উল্টায় |
| "Transpose করলে data বদলে যায়" | একটা সংখ্যাও বদলায় না — শুধু row-প্রশ্ন আর column-প্রশ্ন জায়গা বদল করে |
| \(\operatorname{tr}(AB) = \operatorname{tr}(A)\operatorname{tr}(B)\) | না — trace গুণে ভাঙে না; তার একমাত্র গুণ-জাদু \(\operatorname{tr}(AB) = \operatorname{tr}(BA)\) |
| "Symmetric matrix মানে সব entry সমান-টমান কিছু" | মানে শুধু \(a_{ij} = a_{ji}\) — diagonal-আয়নায় মিলে যাওয়া; আর সংজ্ঞাটা কেবল square-এ খাটে |
| Block গুণে \(AE\)-কে \(EA\) লিখে ফেলা | Block-রা matrix — ক্রম পবিত্র; সংখ্যার প্যাটার্ন ধার নাও, সংখ্যার স্বাধীনতা নয় |
| \(\mathbf{x}^\top\mathbf{y}\) আর \(\mathbf{x}\mathbf{y}^\top\) গুলিয়ে ফেলা | প্রথমটা সংখ্যা (dot product), দ্বিতীয়টা আস্ত matrix (outer product) — আকার লিখলেই ধরা পড়ে |
১০. এক নজরে¶
| ধারণা | সারকথা |
|---|---|
| Transpose | \((A^\top)_{ij} = A_{ji}\); row ↔ column; \((AB)^\top = B^\top A^\top\) |
| Trace | diagonal-যোগ; linear; \(\operatorname{tr}(AB) = \operatorname{tr}(BA)\) — বিশৃঙ্খলায় টিকে থাকা সংখ্যা |
| Identity \(I\) | কিছু-না-করা matrix; গুণের \(1\) |
| Diagonal | অক্ষ ধরে টানা-চাপা; নিজেদের মধ্যে commute; power/inverse ঘরে ঘরে |
| Permutation | entry-ঘুঁটুনি; \(P^\top = P^{-1}\) |
| Symmetric | \(S = S^\top\); \(A^\top A\) সবসময় symmetric — Data Science-এর ব্যস্ততম চেহারা |
| Triangular | এক পাশ ফাঁকা; diagonal nonzero ⟺ invertible |
| Block | টুকরো-কে সংখ্যার মতো গুণ — শুধু ক্রম অটুট রেখো |
পরের chapter-এর সেতু: পাঁচ chapter ধরে আমরা "matrix মানে linear transformation" মন্ত্র জপছি — কিন্তু linear শব্দটার আনুষ্ঠানিক সংজ্ঞা এখনো বাকি! কোন দুটো শর্ত মানলে একটা transformation-কে linear বলা যায়, গ্রিডলাইন সোজা-সমান্তরাল থাকার সাথে সেই শর্তের সম্পর্ক কি, আর কেন প্রতিটা linear transformation-ই একটা matrix — পরের chapter-এ Part III-এর এই শেষ গিঁটটা বাঁধব।
📓 Notebook Project¶
notebooks/part-03/ch05-project.ipynb — Special-matrix চিড়িয়াখানা: scratch-এ transpose ও trace লিখে NumPy-র সাথে মিলানো, permutation matrix দিয়ে ছবির row-ঘুঁটুনি (আর \(P^\top\) দিয়ে ফেরত আনা!), আর data matrix থেকে \(X^\top X\)-এর প্রতিসাম্য-পরীক্ষা।