Chapter 7.4 — k-means Clustering + Graph Matrices & PageRank (কে-মিনস ক্লাস্টারিং + গ্রাফ ম্যাট্রিক্স ও পেজর্যাঙ্ক)¶
Chapter 7.3-এর শেষে বলেছিলাম: এতদিন data-র সাথে সবসময় একটা label বা target ছিল — supervised জগৎ। আজ আমরা label ছাড়া কাজ করবো — unsupervised learning(আনসুপারভাইজড লার্নিং)। হাজারো গ্রাহক, কেউ বলে দেয়নি কে কোন দলে; লক্ষ web-page, কেউ চিহ্নিত করেনি কোনটা গুরুত্বপূর্ণ। তবু শুধু data-র গঠন থেকে দল খুঁজে বের করা যায় (k-means), আর network-এর তীর থেকে গুরুত্ব বের করা যায় (PageRank) — যে গণিতে Google-এর জন্ম। দুটোই দাঁড়িয়ে আছে সেই চেনা linear algebra-র ওপর: দূরত্ব, গড়, matrix, eigenvector।
🎯 এই chapter-এ যা শিখবে¶
- k-means Clustering(কে-মিনস ক্লাস্টারিং): label ছাড়া data-কে \(k\) দলে ভাগ করা; representative(রিপ্রেজেন্টেটিভ) ও clustering objective \(J^{clust}\)
- Lloyd's algorithm(লয়েডস অ্যালগরিদম): "নিকটতমে বরাদ্দ / গড়ে সরানো" — কেন প্রতি ধাপে objective কমে
- Graph(গ্রাফ) ও তার matrix-ভাষা: Adjacency matrix(অ্যাডজেসেন্সি ম্যাট্রিক্স) \(A\), Degree matrix(ডিগ্রি ম্যাট্রিক্স) \(D\), Laplacian(ল্যাপ্লাসিয়ান) \(L = D - A\)
- Laplacian-এর জাদু: row sum শূন্য, \(\mathbf{1}\) সর্বদা eigenvector (\(\lambda = 0\)), zero eigenvalue-র সংখ্যা = connected component-এর সংখ্যা
- PageRank(পেজর্যাঙ্ক): web-কে Markov matrix ভেবে power iteration দিয়ে গুরুত্ব-eigenvector বের করা — Google-এর মূল ধারণা
🖼️ এক ছবিতে মূল idea¶
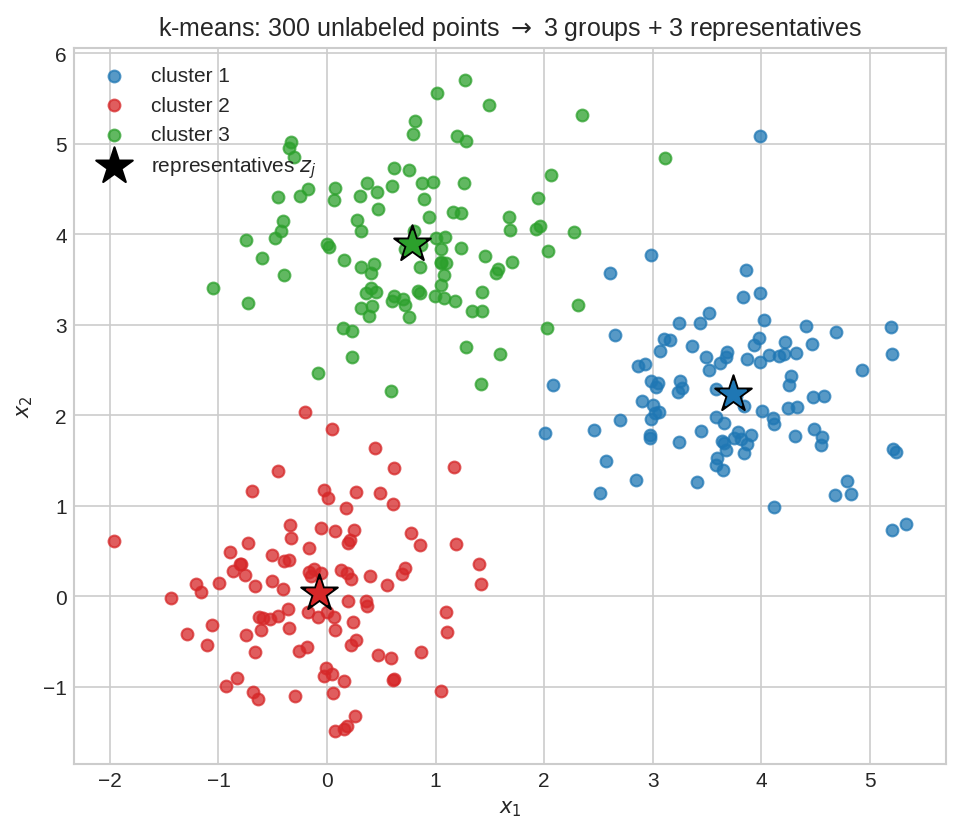
৩০০টা label-বিহীন বিন্দু (কেউ বলেনি কে কোন দলে)। k-means নিজে থেকে ৩টা দল খুঁজে বের করলো (রঙ), আর প্রতিটা দলের জন্য একটা প্রতিনিধি \(z_j\) (কালো তারা — দলের গড়-বিন্দু) দিলো। কোনো শিক্ষক ছিল না, তবু গঠন উঠে এলো — এটাই unsupervised learning-এর সৌন্দর্য।
১. কি? (What)¶
দৈনন্দিন analogy: মেলায় হারানো বন্ধুদের খোঁজা¶
ভাবো এক বিশাল মেলায় তোমাদের ৩০ জন বন্ধু ছড়িয়ে গেছে, ফোন নেই। তুমি ৩টা মিটিং-পয়েন্ট ঠিক করতে চাও, যেন প্রত্যেকে সবচেয়ে কাছের পয়েন্টে গিয়ে জড়ো হতে পারে আর মোট হাঁটার দূরত্ব কম হয়। কৌশল: (১) এলোমেলো ৩টা পয়েন্ট বসাও, (২) প্রত্যেকে নিকটতম পয়েন্টে যাক, (৩) প্রতি দলের মাঝখানে পয়েন্টটা সরিয়ে নাও, (৪) আবার (২)। কয়েকবারেই স্থির — এটাই k-means।
সংজ্ঞা: k-means clustering¶
\(N\)টা vector \(x^{(1)}, \dots, x^{(N)}\) (কোনো label নেই)। লক্ষ্য: এদের \(k\)টা cluster(ক্লাস্টার) বা দলে ভাগ করা, আর প্রতি দলের একটা representative \(z_1, \dots, z_k\) (প্রতিনিধি vector) বাছা, যেন প্রতিটা বিন্দু তার নিজের দলের প্রতিনিধির কাছাকাছি থাকে। গণিতে objective — clustering cost \(J^{clust}\):
যেখানে \(c_i \in \{1, \dots, k\}\) হলো বিন্দু \(i\)-র বরাদ্দ দল, আর \(z_{c_i}\) সেই দলের প্রতিনিধি। মানে: প্রতিটা বিন্দু থেকে তার প্রতিনিধির দূরত্ব-বর্গের গড় — যত ছোট, তত ভালো clustering।
সংজ্ঞা: graph ও তার matrix¶
একটা graph হলো কিছু node(নোড) বা vertex (বিন্দু) আর তাদের সংযোগকারী edge(এজ) বা রেখা — বন্ধুত্বের network, রাস্তার মানচিত্র, web-page-এর link। এই সংযোগ-তথ্যকে matrix-এ ধরা যায়:
- Adjacency matrix \(A\): \(A_{ij} = 1\) যদি node \(i\) ও \(j\)-এর মধ্যে edge থাকে, নাহলে \(0\)।
- Degree matrix \(D\): diagonal matrix, \(D_{ii} =\) node \(i\)-র degree (কয়টা edge লাগানো)।
- Graph Laplacian \(L = D - A\): এই একটা matrix-এ graph-এর গোটা গঠন লুকিয়ে — connectivity, cluster, flow, সব।
২. দেখতে কেমন?¶
দৃশ্য ১: k-means-এর নাচ — assign ও move¶
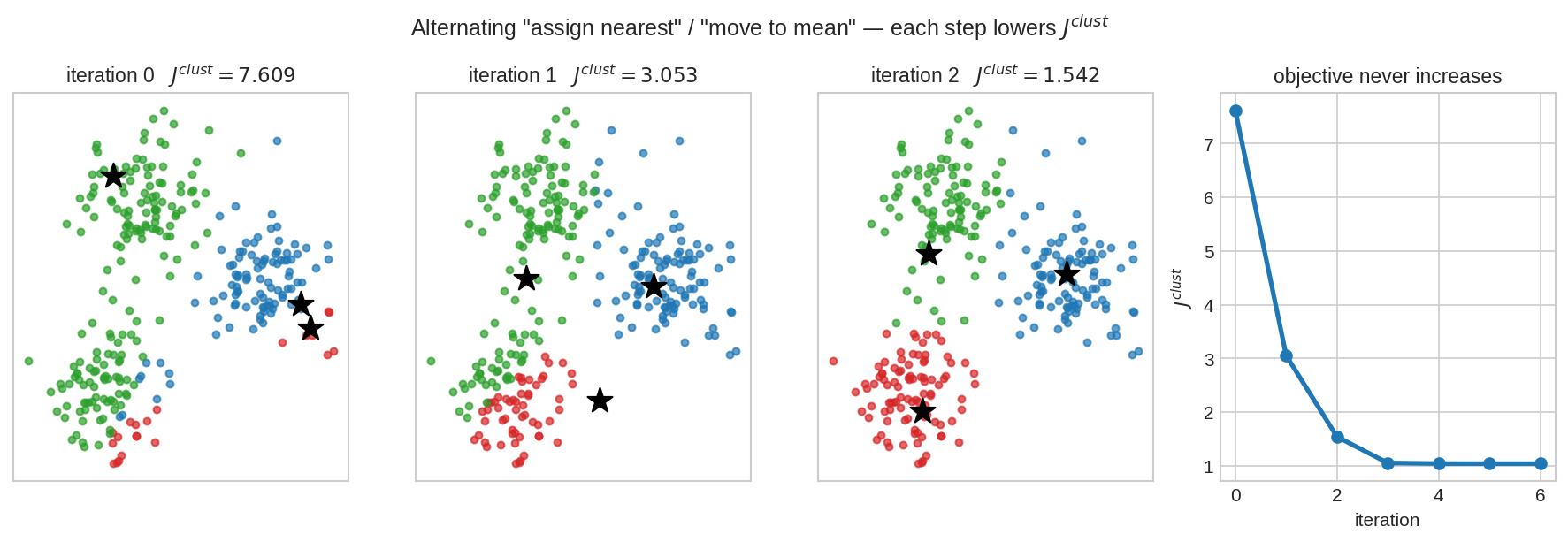
বাঁ থেকে ডানে iteration 0, 1, 2 — প্রতিবার (১) প্রতিটা বিন্দু নিকটতম তারায় বরাদ্দ হয় (রঙ বদলায়), (২) প্রতিটা তারা তার দলের গড়ে সরে যায়। সবচেয়ে ডানের লেখচিত্রে \(J^{clust}\) — খেয়াল করো এটা কখনো বাড়ে না, শুধু কমে বা স্থির থাকে। কয়েক ধাপেই তলানিতে; সেখানে থামে।
দৃশ্য ২: graph ও তার adjacency matrix¶
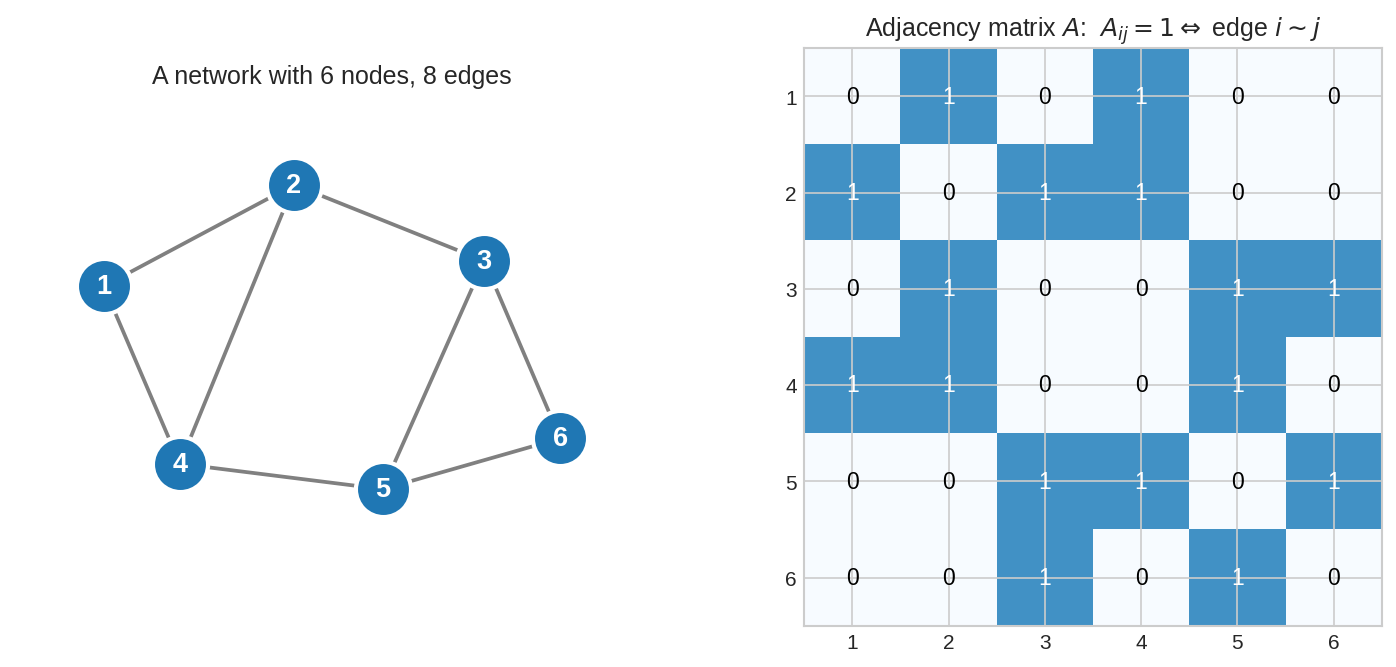
বাঁয়ে ৬টা node, ৮টা edge-এর একটা network। ডানে তার adjacency matrix \(A\) — \(A_{ij} = 1\) (নীল ঘর) মানে node \(i\) ও \(j\)-এর মধ্যে edge আছে। খেয়াল করো matrix-টা symmetric (\(A_{ij} = A_{ji}\)) কারণ edge দ্বিমুখী (undirected)। এক নজরে graph-এর পুরো সংযোগ-তথ্য এই সংখ্যার ঘরে বন্দি — ছবি আর matrix একই জিনিসের দুই রূপ।
দৃশ্য ৩: তিন matrix — D, A, L¶
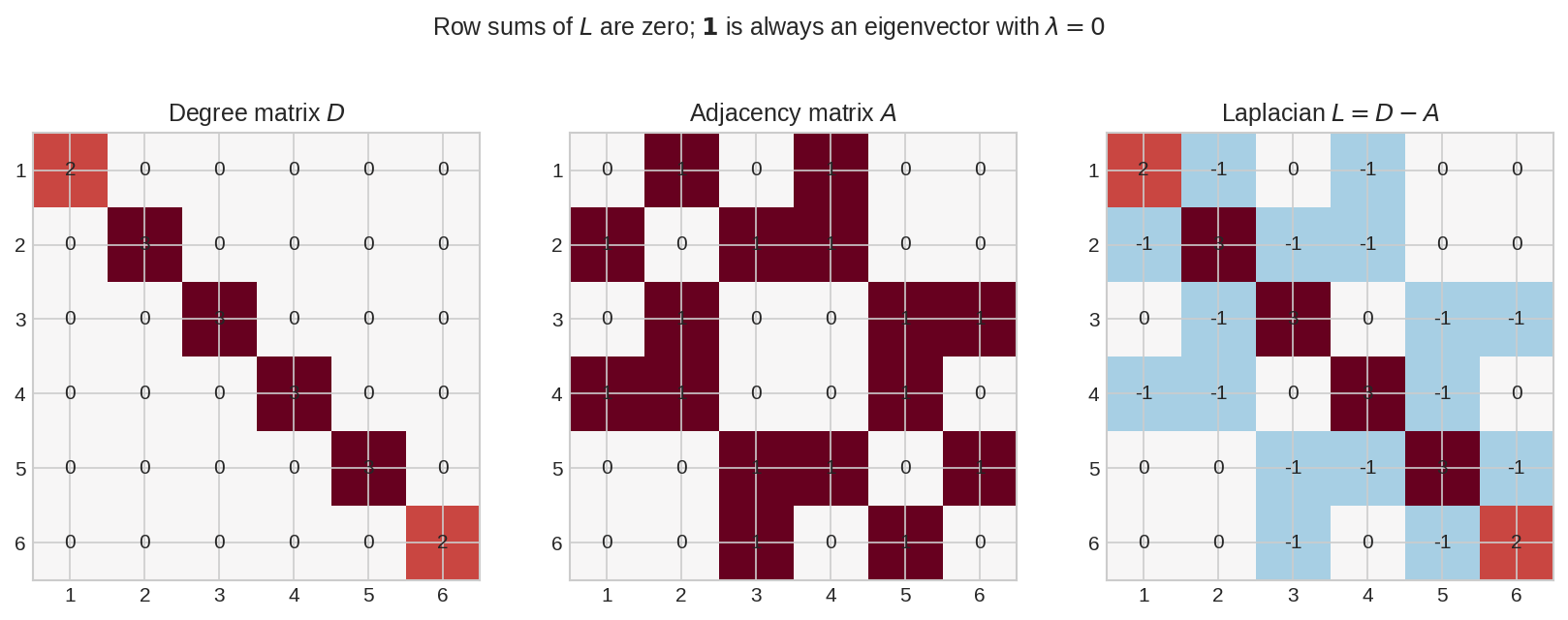
একই graph-এর তিন matrix পাশাপাশি: degree \(D\) (diagonal-এ প্রতি node-এর সংযোগ-সংখ্যা), adjacency \(A\), আর Laplacian \(L = D - A\)। Laplacian-এর diagonal ধনাত্মক (degree), off-diagonal ঋণাত্মক (edge থাকলে \(-1\))। প্রতিটা row-এর যোগফল ঠিক শূন্য — এই ছোট্ট তথ্যটাই Laplacian-এর সব জাদুর উৎস।
দৃশ্য ৪: PageRank — কে কতটা গুরুত্বপূর্ণ¶
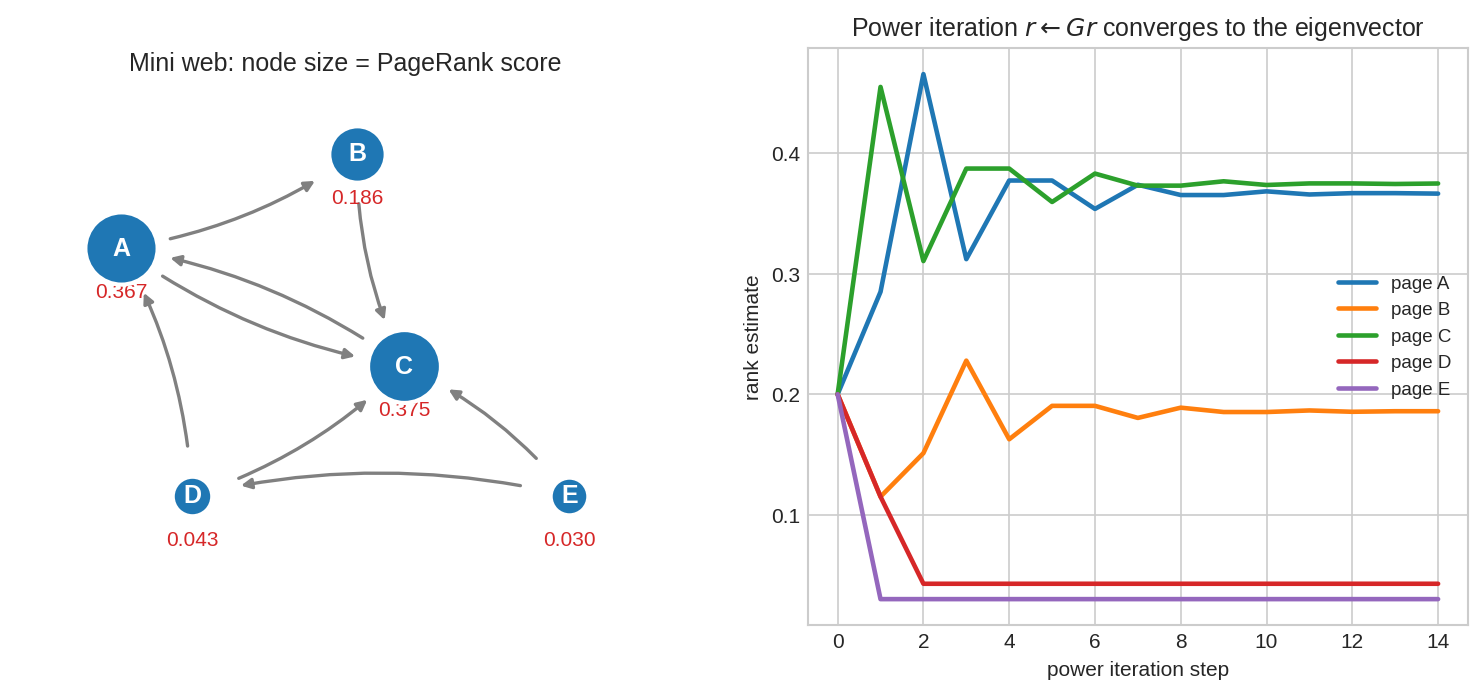
বাঁয়ে ৫টা page-এর একটা mini web; তীর = link (একমুখী, directed)। প্রতিটা node-এর আকার = তার PageRank score — যত বড়, তত গুরুত্বপূর্ণ। খেয়াল করো C সবচেয়ে বড়: অনেকে C-কে link করে, আর যারা link করে তারাও গুরুত্বপূর্ণ। ডানে power iteration \(r \leftarrow Gr\)-এর ধাপে ধাপে convergence — কয়েক ধাপেই score স্থির হয়ে যায় (eigenvector-এ পৌঁছায়)।
৩. কোথায় ইউজ হয়?¶
k-means বাস্তব জীবনে:
- গ্রাহক-বিভাজন (customer segmentation): কেনাকাটার ধরন দিয়ে গ্রাহকদের দলে ভাগ — কে "সাশ্রয়ী", কে "বিলাসী" — কোনো label ছাড়াই marketing-এর ভিত্তি।
- ছবি সংকোচন (image compression): একটা ছবির লক্ষ লক্ষ রঙকে \(k=16\)টা প্রতিনিধি রঙে ভাগ করা — প্রতিটা pixel-কে তার নিকটতম প্রতিনিধি-রঙে বদলে দিলে ফাইল ছোট।
- নথি সংগঠন (document clustering): হাজারো খবর/কাগজকে বিষয় অনুযায়ী দলে ভাগ, কেউ topic লিখে না দিলেও।
Graph/PageRank বাস্তব জীবনে:
- সার্চ ইঞ্জিন: Google-এর মূল ধারণা — কোন web-page গুরুত্বপূর্ণ তা ঠিক করা তাদের link-গঠন দিয়ে। "গুরুত্বপূর্ণরা যাকে link করে সে গুরুত্বপূর্ণ।"
- সামাজিক network: কে "প্রভাবশালী", কীভাবে খবর/রোগ ছড়ায়, কোন দল আলাদা — সব graph Laplacian ও eigenvector থেকে।
- সুপারিশ (recommendation): "যারা এটা কিনেছে তারা ওটাও কিনেছে" — একটা bipartite graph-এ random walk।
Data Science / ML-এ:
- k-means সবচেয়ে বেশি ব্যবহৃত clustering algorithm; scikit-learn-এর
KMeans, প্রায় প্রতিটা EDA (exploratory analysis)-এর প্রথম হাতিয়ার। - Spectral clustering(স্পেকট্রাল ক্লাস্টারিং): graph Laplacian-এর eigenvector দিয়ে ক্লাস্টারিং — k-means-এর চেয়েও শক্তিশালী, নন-গোলাকার দল খুঁজতে পারে।
- Graph Neural Networks (GNN): আধুনিক deep learning-এর হটকেক; ভিত্তি ঠিক এই adjacency/Laplacian matrix।
- PageRank-এর সাধারণীকরণ: eigenvector centrality — যেকোনো network-এ node-এর গুরুত্ব মাপার সর্বজনীন হাতিয়ার।
৪. Properties¶
Property 1 — প্রতিনিধি সবসময় দলের গড় (centroid)¶
\(J^{clust}\)-এ যদি দল-বরাদ্দ \(c_i\) স্থির রেখে শুধু প্রতিনিধি \(z_j\) সেরা করতে চাই, উত্তর হলো সেই দলের গড় (mean/centroid):
কারণ \(\sum_{i \in G_j}\|x^{(i)} - z\|^2\) minimize করে ঠিক গড় (Part V-এর "গড়ই সবচেয়ে কাছের বিন্দু" — এক-মাত্রা least squares!)। এজন্যই নাম "k-means": \(k\)টা mean। fig02-এর তারা প্রতিবার দলের ভরকেন্দ্রে সরে।
Property 2 — Lloyd's algorithm প্রতি ধাপে \(J^{clust}\) কমায়¶
দুই ধাপ পালা করে: - Assign: প্রতিটা বিন্দুকে নিকটতম প্রতিনিধিতে বরাদ্দ — এতে \(J^{clust}\) কমে বা সমান (প্রতিটা বিন্দু কাছেরটা বাছে)। - Update: প্রতিটা প্রতিনিধিকে দলের গড়ে সরানো — এতেও \(J^{clust}\) কমে বা সমান (Property 1)।
দুই ধাপই objective কমায়, আর \(J^{clust} \geq 0\) (নিচে বাঁধা), তাই algorithm অবশ্যই থামে (converge করে)। fig02-এর ডান লেখচিত্রে এই একমুখী পতন।
Property 3 — k-means local minimum-এ আটকায় (global নয়)¶
\(J^{clust}\) কমে, কিন্তু সবসময় সেরা clustering-এ পৌঁছায় না — শুরুর এলোমেলো প্রতিনিধি খারাপ হলে খারাপ জায়গায় আটকে যায় (local minimum)। সমাধান: কয়েকবার ভিন্ন এলোমেলো শুরু দিয়ে চালাও, সবচেয়ে ছোট \(J^{clust}\)-ওয়ালাটা বাছো (n_init — scikit-learn-এ default)।
Property 4 — Laplacian-এর row sum শূন্য, তাই \(\mathbf{1}\) eigenvector¶
\(L = D - A\)। যেকোনো row \(i\)-র যোগফল: \(D_{ii} - \sum_j A_{ij} = (\text{degree } i) - (\text{degree } i) = 0\) (কারণ \(D_{ii}\) ঠিক node \(i\)-র edge-সংখ্যা, আর \(\sum_j A_{ij}\)-ও তাই)। তাই:
মানে all-ones vector \(\mathbf{1}\) সবসময় \(L\)-এর eigenvector, eigenvalue \(0\)। প্রতিটা graph-এই এটা সত্য, ব্যতিক্রম নেই।
Property 5 — zero eigenvalue-র সংখ্যা = connected component-এর সংখ্যা¶
\(L\)-এর eigenvalue-গুলো সবসময় \(\geq 0\) (positive semidefinite)। আর \(\lambda = 0\)-র multiplicity (কয়টা zero eigenvalue) ঠিক সমান graph-এর connected component-এর সংখ্যার। graph যদি এক-টুকরো (connected), তবে ঠিক একটা zero eigenvalue। §৬-এর কোডে eigenvalue [0, 1, 3, 3, 4, 5] — একটাই শূন্য, তাই graph connected। এই সম্পর্কই spectral clustering-এর ভিত্তি।
Property 6 — PageRank হলো একটা eigenvector সমস্যা¶
PageRank score-এর vector \(r\) সন্তুষ্ট করে \(Gr = r\) — অর্থাৎ \(r\) হলো Google matrix \(G\)-র eigenvalue-\(1\) eigenvector (steady-state)। \(G\) একটা Markov matrix (column sum \(1\), পরের chapter-এর নায়ক), তাই সবসময় একটা eigenvalue \(1\) থাকে, আর তার eigenvector-ই আমরা খুঁজি — power iteration দিয়ে।
৫. Intuition — কেন সত্য?¶
কেন k-means কাজ করে: দুই সহজ প্রশ্নের পালা¶
পুরো clustering সমস্যাটা কঠিন কারণ দল-বরাদ্দ আর প্রতিনিধি — দুটো একসাথে বের করতে হয়। k-means চালাকিটা: একটা স্থির রেখে অন্যটা সহজে সমাধান করো, তারপর পালা বদলাও। - প্রতিনিধি জানা থাকলে "কোন দল?" — সহজ, নিকটতমটা। - দল জানা থাকলে "কোথায় প্রতিনিধি?" — সহজ, গড় (Property 1)।
প্রতিবার একটা সহজ উপ-সমস্যা নিখুঁত সমাধান করছি, তাই objective কখনো বাড়ে না। এই "alternating minimization" কৌশল সারা ML জুড়ে (EM algorithm, matrix factorization) ঘুরে আসবে।
Laplacian-এর গভীর অর্থ: "পার্থক্যের শক্তি"¶
যেকোনো vector \(f\) (প্রতি node-এ একটা সংখ্যা, যেন উচ্চতা)-এর জন্য একটা সুন্দর পরিচয়:
মানে \(L\) মাপে প্রতিবেশী node-দের মানের পার্থক্যের বর্গের যোগফল — একটা "মসৃণতা-মাপক"। যদি সব node-এ \(f\) সমান (\(f = \mathbf{1}\)-এর গুণিতক), পার্থক্য শূন্য, তাই \(f^TLf = 0\) — সেজন্যই \(\mathbf{1}\)-এর eigenvalue \(0\) (Property 4)। আর graph যদি দুই বিচ্ছিন্ন টুকরো হয়, দুই টুকরোয় দুই আলাদা constant দিলেও পার্থক্য শূন্য — দুটো স্বাধীন zero eigenvector, তাই Property 5। এই "পার্থক্য কমাও" দৃষ্টিভঙ্গিই graph-এর cluster খুঁজে দেয়।
PageRank-এর intuition: বিরক্ত সার্ফার¶
কল্পনা করো এক ব্যক্তি এলোমেলোভাবে web ঘুরছে — প্রতি page থেকে সে সমান সম্ভাবনায় একটা outgoing link ধরে পরের page-এ যায়। মাঝে মাঝে (সম্ভাবনা \(1-\alpha\)) সে বিরক্ত হয়ে যেকোনো random page-এ লাফ দেয় ("teleport", dead-end এড়াতে)। বহুক্ষণ ঘোরার পর সে কোন page-এ কতটা সময় কাটায় — সেটাই PageRank। গুরুত্বপূর্ণ page (যাকে অনেকে, বিশেষত অন্য গুরুত্বপূর্ণরা link করে) সে বেশি ঘোরে। গাণিতিকভাবে এই "দীর্ঘকালীন সময়-ভাগ" হলো transition matrix-এর steady-state eigenvector — power iteration ঠিক সেই ঘোরাঘুরিরই সিমুলেশন।
কেন power iteration eigenvector খুঁজে দেয়¶
\(r\)-কে বারবার \(G\) দিয়ে গুণলে (\(r, Gr, G^2r, \dots\)) — যে eigenvector-এর eigenvalue সবচেয়ে বড় (এখানে \(\lambda = 1\)), সেই দিকটাই টিকে থাকে, বাকি সব দিক (\(|\lambda| < 1\)) ম্লান হয়ে যায় প্রতি গুণে। কয়েক ধাপেই \(r\) dominant eigenvector-এ স্থির (fig05 ডান)। Part VI-এর eigenvector এখানে সরাসরি Google-এর ইঞ্জিন — আর Chapter 7.5-এ এই power iteration-ই Markov steady state হয়ে ফিরবে।
৬. Code-এ কেমনে লিখে¶
import numpy as np
np.random.seed(42)
# ============ Part A: k-means scratch-এ ============
def kmeans(X, k, iters=30, seed=0):
rng = np.random.default_rng(seed)
Z = X[rng.choice(len(X), k, replace=False)].copy() # random init
for it in range(iters):
D = np.linalg.norm(X[:, None, :] - Z[None, :, :], axis=2) # দূরত্ব
c = np.argmin(D, axis=1) # নিকটতমে বরাদ্দ
J = np.mean(np.min(D, axis=1) ** 2) # J^clust
Znew = np.array([X[c == j].mean(0) if np.any(c == j) else Z[j]
for j in range(k)]) # গড়ে সরাও
if np.allclose(Znew, Z):
print(f"converged at iteration {it}"); break
Z = Znew
return c, Z, J
centers = np.array([[0, 0], [3.6, 2.2], [0.8, 4.0]])
X = np.vstack([np.random.randn(100, 2) * 0.75 + c for c in centers])
c, Z, J = kmeans(X, 3, seed=1)
print("final J^clust:", round(J, 3))
print("found centers:\n", Z[np.argsort(Z[:, 0])].round(2))
# ============ Part B: graph Laplacian ============
edges = [(0, 1), (0, 3), (1, 2), (1, 3), (2, 4), (2, 5), (3, 4), (4, 5)]
n = 6
Adj = np.zeros((n, n))
for i, j in edges:
Adj[i, j] = Adj[j, i] = 1
Deg = np.diag(Adj.sum(1))
L = Deg - Adj
print("\nL row sums (should be 0):", L.sum(1))
w = np.linalg.eigvalsh(L) # symmetric => real eigenvalues
print("L eigenvalues:", w.round(2))
print("# connected components:", int(np.sum(np.abs(w) < 1e-9)))
# ============ Part C: PageRank via power iteration ============
links = {0: [1, 2], 1: [2], 2: [0], 3: [0, 2], 4: [2, 3]}
N = 5
M = np.zeros((N, N)) # column-stochastic link matrix
for j, outs in links.items():
for i in outs:
M[i, j] = 1.0 / len(outs)
alpha = 0.85
G = alpha * M + (1 - alpha) / N * np.ones((N, N)) # Google matrix
r = np.ones(N) / N
for _ in range(60):
r = G @ r # power iteration
print("\nPageRank:", r.round(3), " (sum =", round(r.sum(), 3), ")")
print("ranking :", [ "ABCDE"[i] for i in np.argsort(-r)])
Output ব্যাখ্যা:
- k-means: ৬-৭ iteration-এ converge;
final J^clust ≈ 1.04। খুঁজে-পাওয়া center[[-0.07, 0.04], [0.78, 3.9], [3.74, 2.23]]— আসল center \((0,0), (0.8, 4.0), (3.6, 2.2)\)-এর প্রায় হুবহু। label ছাড়াই সঠিক দল উদ্ধার। - Laplacian: row sum সব
0.0(Property 4)। eigenvalue[0, 1, 3, 3, 4, 5]— ঠিক একটা শূন্য, তাই graph এক-টুকরো (connected),# connected components: 1(Property 5)। - PageRank:
[0.367, 0.186, 0.375, 0.043, 0.03], যোগফল ঠিক \(1\) (probability distribution)। RankingC > A > B > D > E— C সবচেয়ে গুরুত্বপূর্ণ, কারণ A, B, D — তিনজনেই C-কে link করে, আর A নিজেও গুরুত্বপূর্ণ। "গুরুত্বপূর্ণরা যাকে দেখায়, সে গুরুত্বপূর্ণ।"
৭. Worked Examples¶
Example 1 — এক-মাত্রায় k-means হাতে-কলমে¶
Data: \(2, 4, 10, 12\) (এক-মাত্রা), \(k = 2\)। প্রাথমিক প্রতিনিধি \(z_1 = 3, z_2 = 11\)।
Iteration 1 — assign: প্রতিটা বিন্দু নিকটতম \(z\)-তে। \(2 \to z_1\) (\(|2-3|=1 < |2-11|\)), \(4 \to z_1\), \(10 \to z_2\), \(12 \to z_2\)। দল: \(\{2, 4\}\) ও \(\{10, 12\}\)।
Iteration 1 — update: \(z_1 = (2+4)/2 = 3\), \(z_2 = (10+12)/2 = 11\)। প্রতিনিধি বদলায়নি!
থামলো: পরের assign আবার একই দল দেবে — converge। \(J^{clust} = \frac{1}{4}[(2-3)^2 + (4-3)^2 + (10-11)^2 + (12-11)^2] = \frac{1}{4}(1+1+1+1) = 1\)।
দুই সহজ ধাপে স্থির — এক-মাত্রায় k-means-এর পুরো নাচ।
Example 2 — ছোট graph-এর Laplacian¶
তিন node, edge: \(1\)–\(2\), \(2\)–\(3\) (একটা পথ, "path graph")।
যাচাই: প্রতি row-এর যোগফল \(0\) ✓ (\(1-1+0\), \(-1+2-1\), \(0-1+1\))। তাই \(L\mathbf{1} = 0\) — \(\mathbf{1}\) eigenvector, \(\lambda = 0\)।
Eigenvalue বের করো: characteristic polynomial থেকে \(\lambda = 0, 1, 3\)। ঠিক একটা শূন্য → graph connected (Property 5, এক-টুকরো path)। middle node (\(2\))-এর degree সবচেয়ে বেশি, তাই সে "কেন্দ্র"।
Example 3 — PageRank এক ধাপ হাতে¶
তিন page: A→B, A→C, B→C, C→A (teleport বাদে সরল কেস, \(\alpha = 1\))।
Link matrix \(M\) (column = কোথা থেকে, প্রতিটা column-এর যোগফল \(1\)):
শুরু \(r_0 = (1/3, 1/3, 1/3)\)।
এক ধাপেই C এগিয়ে (কারণ A ও B দুজনেই C-কে link করে)। বারবার চালালে steady-state eigenvector-এ পৌঁছাবে — C সবচেয়ে গুরুত্বপূর্ণ থাকবে। এটাই fig05-এর power iteration-এর হাতে-কলমে প্রথম ধাপ।
৮. Problems ও Solutions¶
Problem 1. Data: \(1, 2, 9, 10, 11\) (এক-মাত্রা), \(k = 2\), প্রাথমিক \(z_1 = 1.5, z_2 = 10\)। এক পূর্ণ k-means iteration চালাও (assign + update), নতুন প্রতিনিধি ও \(J^{clust}\) বের করো।
Solution
Assign: \(1 \to z_1\), \(2 \to z_1\), \(9 \to z_2\) (\(|9-10|=1 < |9-1.5|\)), \(10 \to z_2\), \(11 \to z_2\)। দল: \(\{1,2\}\) ও \(\{9,10,11\}\)।
Update: \(z_1 = (1+2)/2 = 1.5\); \(z_2 = (9+10+11)/3 = 10\)। (এবারও বদলায়নি — already converged।)
\(J^{clust}\): \(\frac{1}{5}[(1-1.5)^2 + (2-1.5)^2 + (9-10)^2 + (10-10)^2 + (11-10)^2] = \frac{1}{5}[0.25 + 0.25 + 1 + 0 + 1] = \frac{2.5}{5} = 0.5\)।
দুই ভালো-আলাদা দল, তাই প্রথম iteration-এই স্থির।
Problem 2. একটা graph-এ ৪ node, edge: \(1\)–\(2\), \(3\)–\(4\) (দুটো আলাদা জোড়া, কোনো সংযোগ নেই)। (a) \(A, D, L\) লেখো। (b) \(L\)-এর row sum যাচাই করো। (c) কয়টা zero eigenvalue আশা করো আর কেন?
Solution
(a)
(প্রতি node-এর degree \(1\), তাই \(D = I\)।)
(b) প্রতি row-এর যোগফল: \(1-1=0\), ইত্যাদি — সব \(0\) ✓।
(c) graph দুই বিচ্ছিন্ন টুকরো (\(\{1,2\}\) ও \(\{3,4\}\)), তাই Property 5 অনুসারে দুটো zero eigenvalue। যাচাই: \(L\) block-diagonal, প্রতি \(2\times 2\) block-এর eigenvalue \(\{0, 2\}\), মিলিয়ে \(\{0, 0, 2, 2\}\) — সত্যিই দুটো শূন্য। zero eigenvalue গোনা = component গোনা।
Problem 3. Property 4 প্রমাণ করো: যেকোনো graph-এ \(L\mathbf{1} = 0\), অর্থাৎ \(\mathbf{1}\) সবসময় \(L\)-এর eigenvector eigenvalue \(0\) নিয়ে।
Solution
\(L = D - A\)। \((L\mathbf{1})_i = \sum_j L_{ij}\cdot 1 = \sum_j L_{ij}\) = row \(i\)-র যোগফল।
Row \(i\)-র যোগফল \(= D_{ii} - \sum_j A_{ij}\)। এখন \(D_{ii}\) (সংজ্ঞা অনুযায়ী) = node \(i\)-র degree = node \(i\) থেকে যতগুলো edge = \(\sum_j A_{ij}\) (row \(i\)-তে যতগুলো \(1\))। তাই:
সংজ্ঞা অনুযায়ী \(\mathbf{1}\) eigenvector, eigenvalue \(0\) ∎। অর্থ: সব node-এ একই মান দিলে "পার্থক্য" শূন্য, তাই Laplacian তাকে "শূন্য শক্তি" দেয় — Intuition-এর \(f^TLf = \sum(f_i-f_j)^2\) দৃষ্টিভঙ্গি।
Problem 4. k-means কেন global optimum-এ পৌঁছায় না তার একটা উদাহরণ দাও (Property 3)। কীভাবে সমস্যা এড়াবে?
Solution
উদাহরণ: Data চারটা বিন্দু: \(0, 1, \; 10, 11\) (দুই স্পষ্ট জোড়া), \(k = 2\)। যদি খারাপ init দাও — \(z_1 = 0.5\) (প্রথম জোড়ার মাঝে) কিন্তু \(z_2 = 5.5\) (মাঝখানে, কোনো দলে না) — assign করলে \(0, 1 \to z_1\) আর \(10, 11 \to z_2\); তখন update ঠিক জায়গায় নিয়ে আসে। কিন্তু অন্য খারাপ init, যেমন \(z_1 = 0.5, z_2 = 1.5\) (দুটোই বাঁ জোড়ার কাছে) হলে একটা প্রতিনিধি ডান জোড়াকে টানতে গিয়ে দল ভুলভাবে ভাগ হয়ে বাজে local minimum-এ আটকাতে পারে (বিশেষত বেশি cluster/মাত্রায় সাধারণ ঘটনা)।
সমাধান: (১) কয়েকবার (যেমন ১০ বার) ভিন্ন random init দিয়ে চালাও, সবচেয়ে ছোট \(J^{clust}\)-ওয়ালা বাছো (scikit-learn-এর n_init)। (২) k-means++ init: প্রতিনিধিগুলো ইচ্ছে করে দূরে দূরে বসাও — খারাপ শুরুর সম্ভাবনা কমে।
Problem 5. PageRank-এ teleport term \((1-\alpha)/N \cdot \mathbf{1}\mathbf{1}^T\) কেন লাগে? \(\alpha = 1\) (teleport ছাড়া) হলে কী সমস্যা?
Solution
সমস্যা (\(\alpha = 1\)): যদি কোনো page-এর outgoing link না থাকে (dangling node), তার column-এ সব শূন্য — random surfer সেখানে আটকে যায়, probability হারিয়ে যায় (\(M\) আর column-stochastic থাকে না)। এমনকি সব page-এ link থাকলেও, graph যদি এমন হয় যে একটা অংশে ঢুকলে আর বেরোনো যায় না ("spider trap"), surfer সেখানেই জমে যায় — ranking বিকৃত।
Teleport-এর উদ্ধার: সম্ভাবনা \(1-\alpha\)-তে surfer যেকোনো page-এ লাফ দেয় (\(\frac{1}{N}\mathbf{1}\))। এতে (১) dangling/trap থেকে বেরোনো যায়, (২) Google matrix \(G = \alpha M + \frac{1-\alpha}{N}\mathbf{1}\mathbf{1}^T\)-এর প্রতিটা entry কঠোরভাবে ধনাত্মক — Perron-Frobenius উপপাদ্য নিশ্চিত করে একটাই ধনাত্মক steady-state eigenvector আছে, আর power iteration তাতে পৌঁছায়। \(\alpha = 0.85\) Google-এর ঐতিহাসিক মান।
Problem 6. (কোডে) একটা "star graph" বানাও — center node (\(0\)) বাকি ৪ node (\(1,2,3,4\))-এর সবার সাথে যুক্ত, কিন্তু বাইরের node-রা পরস্পর যুক্ত নয়। Laplacian-এর eigenvalue বের করে ব্যাখ্যা করো।
Solution
import numpy as np
n = 5
Adj = np.zeros((n, n))
for j in [1, 2, 3, 4]:
Adj[0, j] = Adj[j, 0] = 1 # center সবার সাথে
Deg = np.diag(Adj.sum(1))
L = Deg - Adj
print("degrees:", Adj.sum(1)) # [4, 1, 1, 1, 1]
print("eigenvalues:", np.linalg.eigvalsh(L).round(3))
[0, 1, 1, 1, 5]। ব্যাখ্যা: একটা শূন্য → graph connected (এক-টুকরো)। Largest eigenvalue \(5 = n\) (star-এর বৈশিষ্ট্য)। মাঝের তিনটা \(1\) (repeated) — বাইরের symmetric node-দের সমতার প্রতিফলন। eigenvalue-র গঠন graph-এর জ্যামিতি ফাঁস করে দেয়।
Problem 7. \(J^{clust}\) কেন সবসময় \(k\) বাড়ালে কমে? তাহলে \(k = N\) (প্রতি বিন্দু নিজেই নিজের দল) বাছলেই কি সেরা? সমস্যাটা কোথায়?
Solution
কেন কমে: বেশি প্রতিনিধি মানে প্রতিটা বিন্দুর নিকটতম প্রতিনিধি আরও কাছে থাকার সুযোগ — তাই \(J^{clust}\) একঘেয়েভাবে \(k\)-র সাথে কমে। \(k = N\)-এ প্রতিটা বিন্দু নিজেই প্রতিনিধি, দূরত্ব \(0\), \(J^{clust} = 0\) — "নিখুঁত"।
সমস্যা: এটা অর্থহীন — কোনো দল বানানোই হলো না, প্রতিটা বিন্দু আলাদা! এটা ridge-এর overfitting-এর যমজ: fit-error শূন্য কিন্তু কোনো structure শেখা হয়নি। সমাধান: \(k\) নিজেই একটা knob (hyperparameter)। "elbow method" — \(J^{clust}\) vs \(k\) আঁকো; যেখানে কমার হার হঠাৎ শ্লথ হয় (কনুই), সেই \(k\) বাছো — data-র আসল দল-সংখ্যার ইঙ্গিত। Chapter 7.2-এর \(\lambda\)-র মতোই, চরম নয়, ভারসাম্য।
Problem 8. ধারণাগত: k-means (unsupervised) আর Chapter 7.1-এর least squares classifier (supervised)-এর মূল পার্থক্য কী? কোন পরিস্থিতিতে কোনটা লাগবে?
Solution
- Classifier (supervised): training-এ প্রতিটা বিন্দুর সাথে label দেওয়া (\(+1/-1\), বা digit)। model শেখে "feature → label" mapping, নতুন বিন্দুর label predict করে।
- k-means (unsupervised): কোনো label নেই। model শুধু data-র গঠন থেকে দল খুঁজে বের করে — দলগুলোর কোনো পূর্ব-নির্ধারিত "নাম" নেই।
কখন কোনটা: - Label আছে ও নতুন data-র label চাই (spam/ham, রোগ আছে/নেই) → classifier। - Label নেই, শুধু structure/দল আবিষ্কার করতে চাই (গ্রাহক-বিভাজন, বিষয়-খোঁজা) → k-means।
সংযোগ: প্রায়ই k-means দিয়ে দল খুঁজে, তারপর দলগুলোকে মানুষে নাম দিয়ে (labeling) — unsupervised থেকে supervised-এ যাওয়ার সেতু। দুই জগৎ একে অন্যের পরিপূরক।
৯. Common ভুল¶
| ❌ ভুল ধারণা | ✅ সঠিক ধারণা |
|---|---|
| "k-means সবসময় সেরা clustering দেয়" | না — সে local minimum-এ আটকায় (Property 3)। শুরুর random init-এর ওপর নির্ভরশীল; কয়েকবার চালিয়ে সেরাটা বাছতে হয় (n_init)। |
| "বেশি cluster (\(k\) বড়) মানে ভালো" | \(J^{clust}\) \(k\)-র সাথে শুধু কমে; \(k=N\)-এ শূন্য কিন্তু অর্থহীন (Problem 7)। elbow method দিয়ে যুক্তিসঙ্গত \(k\) বাছো। |
| "Adjacency আর Laplacian একই তথ্য, তাই যেকোনোটা" | তথ্য এক, কিন্তু Laplacian \(L = D-A\)-এর eigen-গঠন (row sum \(0\), PSD, component-গোনা) সরাসরি cluster/connectivity ফাঁস করে — \(A\) একা তা পারে না। |
| "PageRank শুধু কতজন link করে গোনে" | না! গুরুত্ব recursive — কে link করছে তার নিজের গুরুত্বও গোনে। এজন্যই eigenvector, সাধারণ গণনা নয় (Property 6)। কম কিন্তু গুরুত্বপূর্ণ link > অনেক কিন্তু তুচ্ছ link। |
| "power iteration একটা approximation, ভুল উত্তর দেয়" | না — সে dominant eigenvector-এ নিখুঁতভাবে পৌঁছায় (কয়েক ধাপে, গোটা matrix invert না করেই)। বড় web-এ eigenvector বের করার একমাত্র বাস্তব উপায় এটাই। |
| "unsupervised মানে কোনো objective নেই" | আছে — k-means minimize করে \(J^{clust}\), PageRank খোঁজে eigenvector। label নেই মানে objective নেই নয়; objective শুধু data-র নিজস্ব গঠন থেকে আসে। |
১০. এক নজরে¶
| ধারণা | সূত্র / বক্তব্য | মনে রাখার ছবি |
|---|---|---|
| k-means objective | \(J^{clust} = \frac1N\sum_i\|x^{(i)} - z_{c_i}\|^2\) | দূরত্ব-বর্গের গড় কমাও |
| Lloyd's algorithm | assign নিকটতমে / update গড়ে — পালা করে | fig02-এর নাচ |
| প্রতিনিধি = গড় | \(z_j = \text{mean of cluster } j\) | k-means |
| Adjacency \(A\) | \(A_{ij}=1 \Leftrightarrow\) edge; symmetric (undirected) | graph = matrix |
| Laplacian \(L = D-A\) | row sum \(0\); \(L\mathbf{1}=0\); PSD | পার্থক্যের শক্তি \(\sum(f_i-f_j)^2\) |
| zero eigenvalue-গোনা | = connected component-সংখ্যা | graph কয় টুকরো |
| PageRank | \(Gr = r\), dominant eigenvector; power iteration | বিরক্ত random surfer |
পরের chapter-এর সেতু: PageRank-এ একটা মূল্যবান জিনিস চোখে পড়লো — Google matrix \(G\)-র প্রতিটা column-এর যোগফল \(1\), আর power iteration \(r \leftarrow Gr\) একটা steady-state-এ থামে। এই "column sum \(1\)" matrix-এর একটা নাম আছে: Markov matrix, আর তার steady-state এক গভীর গল্প। কালকের আবহাওয়া আজকেরটার ওপর নির্ভর করে — এই "সম্ভাবনার বিবর্তন" কীভাবে সবসময় একটা স্থির ভারসাম্যে পৌঁছায়, আর সময়কে অবিচ্ছিন্ন করলে (\(e^{At}\) — matrix exponential) কী হয় — সেটাই Chapter 7.5, Part VII-এর সমাপ্তি।
📓 Notebook Project¶
notebooks/part-07/ch04-project.ipynb — তিন মিনি-প্রকল্প: (১) k-means scratch-এ লিখে synthetic দল উদ্ধার + একটা ছোট ছবিকে \(k\)-রঙে compress করা, (২) একটা graph-এর \(A, D, L\) বানিয়ে eigenvalue থেকে connected component গোনা ও spectral cluster-এর ঝলক, (৩) mini web-এ PageRank power iteration চালিয়ে ranking বের করা ও \(\alpha\) বদলালে কী হয় দেখা — unsupervised জগতের হাতে-কলমে সফর।